Mask2Former来了!用于通用图像分割的 Masked-attention Mask Transformer
 原理https://blog.csdn.net/bikahuli/article/details/121991697
原理https://blog.csdn.net/bikahuli/article/details/121991697
源码解析
论文地址:http://arxiv.org/abs/2112.01527
项目地址:https://bowenc0221.github.io/mask2former
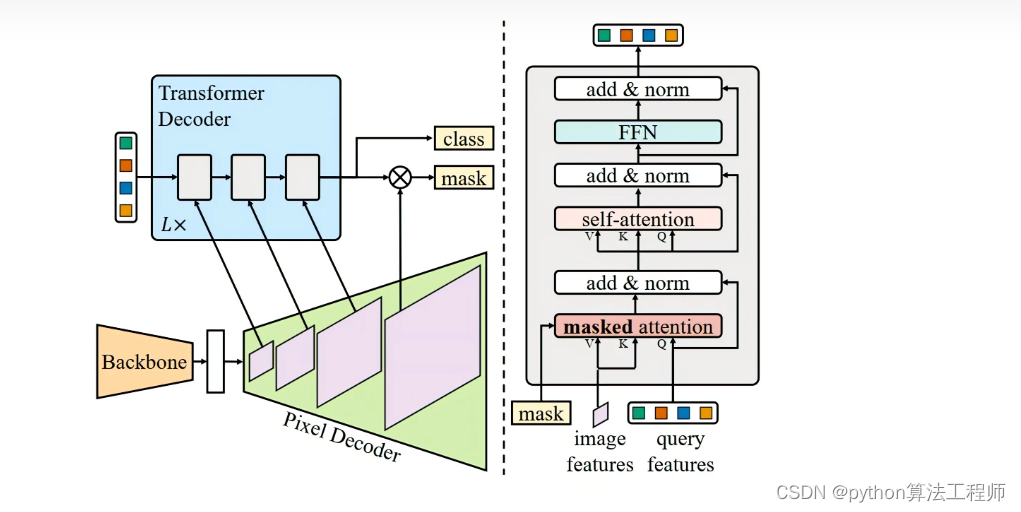
Mask2Former的整体架构由三个组件组成:
-
主干特征提取器:主干特征提取器从输入图像中提取低分辨率特征。在Mask2Former中,主干特征提取器通常是一个Transformer模型,例如ViT、Swin Transformer或RAN等。
-
像素解码器:像素解码器从主干特征提取器的输出中逐渐上采样低分辨率特征,以生成高分辨率的每像素嵌入。在Mask2Former中,像素解码器通常是一个反卷积网络,它使用反卷积操作逐渐将特征图的分辨率恢复到原始图像的大小。
-
Transformer解码器:Transformer解码器对图像特征进行操作以处理对象查询。在Mask2Former中,Transformer解码器通常由多个Transformer层组成,每个层都包含多头自注意力机制和前向神经网络。在解码器中,每个位置的嵌入表示该位置的像素特征,并且可以根据对象查询来预测二元掩码。
总的来说,Mask2Former的整体架构使用Transformer模型来提取图像特征,并使用反卷积网络将分辨率逐渐恢复到原始图像的大小。然后,使用Transformer解码器对图像特征进行操作以处理对象查询,并从每个位置的嵌入中解码二元掩码预测。
什么叫提取低分辨率特征
在深度学习中,特征提取是指从输入数据中提取出具有代表性的特征,以便进行后续的分类、识别、检测等任务。在图像处理中,通常使用卷积神经网络(CNN)来提取图像特征。CNN通过卷积、池化等操作,逐渐将图像特征从原始图像中提取出来。
在Mask2Former中,主干特征提取器用于从输入图像中提取低分辨率特征。这些低分辨率特征通常是指经过一系列卷积、池化等操作后得到的较小尺寸的特征图。这些特征图具有较低的分辨率,但包含了图像的一些基本信息,例如边缘、纹理等。这些低分辨率特征可以作为更高层次的特征提取的输入,以便更好地识别、分类、检测等任务。
在Mask2Former中,主干特征提取器通常是一个Transformer模型,例如ViT、Swin Transformer或RAN等。这些Transformer模型可以利用self-attention机制来捕捉全局的空间关系,从而更好地提取图像特征。
Mask2Former
Mask2Former 是由华中科技大学的研究人员于2021年提出的一种图像分割模型,其论文名为 “Mask2Former: From Masked Self-Attention to Masked Fully Convolution for Few-Shot Image Segmentation”。该模型的主要贡献是将遮盖技术和自注意力机制引入了全卷积网络中,实现了更加高效和准确的图像分割。
Mask2Former 的架构包含了三个主要的模块:遮盖编码器、遮盖解码器和蒸馏模块。其中,遮盖编码器主要负责将输入图像编码为特征向量,遮盖解码器则使用这些特征向量来生成分割掩模,而蒸馏模块则用于进一步优化分割结果。
相比于传统的图像分割模型,Mask2Former 的优点在于它使用了遮盖技术来针对特定对象进行分割,这使得模型在处理小样本和少样本图像时更加高效和准确,并且避免了过度拟合的问题。此外,Mask2Former 在自注意力机制方面的使用也使得模型能够自适应地捕捉图像中的不同特征,从而进一步提高了分割的准确性。
总的来说,Mask2Former 是一种非常有前途的图像分割模型,具有高效、准确和适应性强等优点,可以在很多实际应用场景中得到应用。
据我了解了,Mask2Former 是一种用于通用图像分割的模型,它使用了 Masked-attention Mask Transformer 的架构。这个模型的架构基于自注意力机制,并且使用了遮盖技术来生成分割掩模。相比于传统的基于编码器-解码器的神经网络模型,Mask2Former 在图像分割任务中取得了非常好的结果。
具体来说,Mask2Former 通过遮盖技术将图像中的特定区域(例如一个对象)标记为"masked",然后在模型中使用自注意力机制来生成与这些区域对应的掩模。这些掩模可以用于分割图像中的不同对象。与此同时,Mask2Former 也使用了多尺度特征来提高图像分割的准确性。
总的来说,Mask2Former 是一个非常有前途的图像分割模型,它的性能已经在多个基准数据集上得到了证明,并且在未来的研究中也可能会得到更多的改进和优化。
在 Mask2Former 模型中,自注意力机制主要用于生成与遮盖区域对应的掩模。具体来说,模型首先将输入图像通过遮盖技术处理,将遮盖区域标记为"masked"。然后,模型使用自注意力机制来计算每个位置与所有其他位置之间的注意力得分,从而捕捉图像中不同位置之间的相关性。
在计算注意力得分时,Mask2Former 会使用遮盖掩码来限制注意力的计算范围,只计算那些未被遮盖的部分。这样可以保证模型只关注与遮盖区域相关的特征,从而生成与遮盖区域对应的掩模。具体来说,模型会将注意力得分与遮盖掩码相乘,然后再进行归一化,得到最终的注意力权重。这些权重可以用于加权池化遮盖区域内的特征向量,从而生成与遮盖区域对应的掩模。
由于自注意力机制可以自适应地捕捉图像中不同位置之间的相关性,因此 Mask2Former 可以在生成遮盖掩模时获得更好的效果。同时,使用遮盖技术和自注意力机制可以使模型更加灵活和高效,适用于各种不同的图像分割任务。
Mask2Former 在使用遮盖技术和自注意力机制生成掩模的同时,也使用了多尺度特征来提高图像分割的准确性。具体来说,Mask2Former 通过使用不同的卷积核大小和步长来提取不同尺度的特征,然后将这些特征进行合并,从而得到更加全面和准确的特征表示。
在 Mask2Former 的架构中,遮盖编码器和遮盖解码器都使用了多尺度特征。遮盖编码器中,模型使用了多个不同尺度的卷积核来提取不同尺度的特征,并将这些特征通过残差连接进行融合。这样可以使模型捕捉到不同尺度的特征,从而提高图像分割的准确性。遮盖解码器中,模型也使用了多个不同尺度的特征图来生成最终的分割掩模,从而进一步提高分割的准确性。
同时,Mask2Former 还使用了渐进式训练的技术来进一步优化多尺度特征的使用。具体来说,在训练过程中,模型会先使用较小的图像尺寸进行训练,然后逐渐增加图像尺寸,直到达到目标尺寸。这样可以使模型逐步适应不同尺度的特征,从而提高分割的准确性。
总的来说,Mask2Former 使用多尺度特征来提高图像分割的准确性,这种方法已经被证明在许多图像分割任务中非常有效。
Mask2 Former论文分享
Pixel decoder
“Pixel decoder” 是指一种神经网络结构,通常用于图像分割任务中的解码器部分。在神经网络中,编码器部分通常用于提取输入图像的特征,而解码器部分则用于将这些特征转换成分割掩模或像素级别的预测结果。
在一般的图像分割任务中,解码器通常采用反卷积或上采样等操作来将编码器输出的特征图还原为与输入图像相同大小的分割掩模或像素级别的预测结果。然而,这种方法在一些细节较为复杂的图像分割任务中可能会存在一定的局限性。
为了克服这些局限性,一些研究人员提出了使用 “pixel decoder” 的方法。这种方法通常使用一个完全连接的神经网络层来直接将编码器输出的特征转换成像素级别的预测结果。这种方法可以更好地保留图像的细节信息,并且在一些复杂的图像分割任务中表现更加出色。
总的来说,“pixel decoder” 是一种用于图像分割任务中解码器部分的神经网络结构,可以用于将编码器输出的特征转换成像素级别的预测结果,从而提高图像分割的准确性。
“Pixel decoder” 的基本思想是将编码器输出的特征图转换成像素级别的预测结果,而不是先将特征图上采样到与输入图像相同的大小,再通过卷积操作生成预测结果。这种方法可以更好地保留图像细节,并且在一些复杂的图像分割任务中表现更加出色。
具体来说,“pixel decoder” 通常由一个完全连接的神经网络层组成,该层将编码器输出的特征图转换成像素级别的预测结果。在训练过程中,模型会根据预测结果与真实标签之间的差异来调整神经网络参数,从而最小化损失函数。
与传统的解码器相比,“pixel decoder” 具有以下优点:
-
更好的保留图像细节。由于 “pixel decoder” 直接将特征图转换成像素级别的预测结果,因此可以更好地保留图像的细节信息。
-
更少的计算量。相比传统的解码器,“pixel decoder” 的计算量更小,因为不需要进行上采样或反卷积等操作。
-
更适合复杂的图像分割任务。在一些细节较为复杂的图像分割任务中,传统的解码器可能会存在一定的局限性,而 “pixel decoder” 可以更好地处理这些任务。
总的来说,“pixel decoder” 是一种用于图像分割任务中解码器部分的神经网络结构,可以更好地保留图像细节,并且在一些复杂的图像分割任务中表现更加出色。
遮盖技术
遮盖技术是一种用于图像分割的常见技术,可以用于针对特定对象进行分割。遮盖技术通常通过人工标注的遮盖掩模(即遮盖层)来实现,遮盖层中标记为前景的像素表示需要分割的对象,而标记为背景的像素则表示不需要分割的背景。
在针对特定对象进行分割时,遮盖技术通常使用以下步骤:
-
生成遮盖层:人工标注需要分割的对象,并将其标记为前景。背景则标记为背景。遮盖层可以是二值图像或多值图像。
-
将遮盖层与原始图像合并:将遮盖层与原始图像进行叠加,将遮盖层中标记为前景的像素保留,同时将标记为背景的像素去除或置为0,从而得到一个只包含需要分割对象的图像。
-
使用图像分割算法:将只包含需要分割对象的图像输入图像分割算法中进行分割,从而得到分割掩模或像素级别的预测结果。
在现代的深度学习方法中,遮盖技术通常与卷积神经网络结合使用,以实现端到端的图像分割。例如,Mask R-CNN 就是一种基于遮盖技术和卷积神经网络的图像分割方法,可以在目标检测任务中实现同时检测和分割目标对象。
总的来说,遮盖技术是一种有效的针对特定对象进行图像分割的技术,可以通过人工标注的遮盖层来实现。在现代深度学习方法中,遮盖技术通常与卷积神经网络结合使用,以实现端到端的图像分割。
遮盖编码器
遮盖编码器(Mask Encoder)是一种用于图像分割的神经网络结构,通常用于将输入图像中的每个像素与一个语义类别相关联,从而实现像素级别的图像分割。遮盖编码器通常由编码器和解码器两部分组成,其中编码器用于提取输入图像的特征,解码器则用于将这些特征转换成像素级别的预测结果。
与传统的编码器-解码器模型相比,遮盖编码器在编码器的基础上增加了一个遮盖卷积层,用于将输入图像的遮盖掩模与编码器输出的特征图组合在一起。遮盖卷积层可以将遮盖掩模的信息与输入图像的像素信息相结合,从而提高分割的准确性。
在训练过程中,遮盖编码器通常使用交叉熵损失函数来衡量预测结果与真实标签之间的差异,并通过反向传播算法更新神经网络的参数。在预测过程中,遮盖编码器可以将输入图像的每个像素与一个语义类别相关联,从而实现像素级别的图像分割。
总的来说,遮盖编码器是一种用于图像分割的神经网络结构,可以将输入图像中的每个像素与一个语义类别相关联,从而实现像素级别的图像分割。遮盖编码器通过增加遮盖卷积层将遮盖掩模的信息与输入图像的像素信息相结合,提高了分割的准确性。
如何使用遮盖编码器进行图像分割?
使用遮盖编码器进行图像分割通常需要以下步骤:
-
数据准备:准备用于训练和测试的图像数据集,并对数据进行预处理,例如缩放、裁剪、归一化等操作。同时,需要标注每个图像中需要分割的对象,并将标注结果保存为遮盖掩模的形式。
-
构建遮盖编码器模型:根据任务需要,构建遮盖编码器模型,通常包括编码器、遮盖卷积层和解码器。可以使用现有的深度学习框架(如TensorFlow、PyTorch等)构建模型,并定义损失函数和优化器。
-
训练模型:使用准备好的数据集对遮盖编码器模型进行训练,并根据训练过程中的损失函数变化情况进行调整。在训练过程中,通常需要设置合适的学习率、批次大小、迭代次数等超参数。
-
模型评估和调优:训练完成后,需要对遮盖编码器模型进行评估和调优,以提高分割的准确性。可以使用一些常用的评估指标(如IoU、Dice Coefficient等)来评估模型的性能,并根据评估结果进行调优。
-
预测和应用:训练完成的遮盖编码器模型可以用于对新的图像进行分割。在预测过程中,将输入图像和对应的遮盖掩模输入到遮盖编码器模型中,即可得到像素级别的分割结果。
总的来说,使用遮盖编码器进行图像分割需要进行数据准备、构建模型、训练模型、模型评估和调优、预测和应用等一系列步骤。可以使用现有的深度学习框架和评估指标来简化这个过程,并实现更高效、准确的图像分割。
如何评估遮盖编码器模型的性能?
评估遮盖编码器模型的性能通常需要使用一些常用的图像分割评估指标,包括 Intersection over Union (IoU)、Dice Coefficient、Precision、Recall等指标。
-
Intersection over Union (IoU):IoU是最常用的图像分割评估指标之一,用于衡量预测分割结果与真实分割结果之间的重叠程度。IoU可以表示为预测分割区域与真实分割区域的交集除以它们的并集:IoU = TP / (TP + FP + FN),其中TP表示真正例(预测为正例且真实为正例的像素数),FP表示假正例(预测为正例但真实为负例的像素数),FN表示假反例(预测为负例但真实为正例的像素数)。
-
Dice Coefficient:Dice Coefficient也是一种用于衡量预测分割结果与真实分割结果之间的重叠程度的指标。Dice Coefficient可以表示为2 * TP / (2 * TP + FP + FN)。
-
Precision和Recall:Precision和Recall是分类问题中常用的评估指标,也可以用于评估图像分割模型的性能。Precision表示预测为正例的像素中真正为正例的比例,Recall表示真正为正例的像素中被预测为正例的比例。
-
其他指标:还有一些其他的图像分割评估指标,例如Mean Absolute Error (MAE)、Mean Squared Error (MSE)等,可以根据具体任务需要选择使用。
在实际应用中,通常需要综合考虑以上指标的表现,以选择最适合任务需求的模型。同时,还可以通过可视化分割结果来直观地评估模型的性能。总的来说,评估遮盖编码器模型的性能需要综合考虑多个指标,并根据具体任务需求进行选择。
如何可视化分割结果?
可视化分割结果是评估遮盖编码器模型性能的重要手段之一,它可以帮助我们直观地了解模型的分割效果。以下是一些常用的可视化分割结果的方法:
-
灰度图像可视化:将预测结果转换为灰度图像,其中正例像素为白色,负例像素为黑色。这种方法简单直观,但可能无法区分多个不同类别之间的差异。
-
彩色标记可视化:使用不同颜色的标记来表示不同的类别,例如红色表示人、绿色表示车等。这种方法可以直观地区分不同类别之间的差异,但需要预定义每个类别的颜色。
-
模型输出叠加可视化:将预测结果叠加到原始图像上,以显示预测结果与原始图像之间的对应关系。这种方法可以帮助我们直观地理解模型如何根据输入图像进行分割。
-
边界框可视化:在预测结果中绘制边界框,以显示分割结果的边界。这种方法可以帮助我们直观地了解分割结果的准确性。
总的来说,可视化分割结果是评估遮盖编码器模型性能的重要手段之一。可以使用灰度图像、彩色标记、模型输出叠加、边界框等方法来可视化分割结果,以帮助我们直观地了解模型的分割效果。
遮盖解码器
遮盖解码器(Mask Decoder)是一种用于图像分割的神经网络模型,它通常与遮盖编码器(Mask Encoder)一起使用,可以将输入图像分割成不同的类别。遮盖编码器负责提取图像特征,遮盖解码器则负责对特征进行分类和分割。
遮盖解码器通常包含多个卷积层和上采样层,以逐步扩大特征图的尺寸,并对每个像素进行分类。在每个卷积层中,遮盖解码器会使用卷积核学习特征,同时通过池化操作降低特征图的尺寸。在上采样层中,遮盖解码器使用反卷积或插值等技术来将特征图的尺寸逐步扩大到与输入图像相同的尺寸。
遮盖解码器通常使用交叉熵损失函数来衡量预测结果与真实分割结果之间的差异,并使用反向传播算法来更新模型参数。在训练过程中,遮盖解码器需要同时考虑分类和分割两个任务,以最小化损失函数。
总的来说,遮盖解码器是一种用于图像分割的神经网络模型,它可以将输入图像分割成不同的类别,通常与遮盖编码器一起使用。遮盖解码器通过卷积和上采样等操作来提取特征,并使用交叉熵损失函数来训练模型。
FFN
在深度学习中,FFN通常指的是前馈神经网络(Feedforward Neural Network),也称为多层感知器(Multilayer Perceptron,MLP)。前馈神经网络是一种最基本的神经网络模型之一,由输入层、多个隐藏层和输出层组成,其中每个神经元都与前一层的所有神经元相连。
前馈神经网络的输入通过多个隐藏层进行变换和抽象,最终输出到输出层。在每个隐藏层中,前馈神经网络使用激活函数来将所有输入的加权和转换为非线性输出。常见的激活函数包括sigmoid、ReLU、tanh等。
前馈神经网络通常用于分类和回归等任务,其中分类任务需要输出层使用softmax函数将输出转换为概率分布,而回归任务则使用线性激活函数或其他适当的激活函数。
前馈神经网络可以通过反向传播算法来训练模型,其中反向传播算法通过计算损失函数对模型参数进行更新。在训练过程中,通常使用随机梯度下降(Stochastic Gradient Descent,SGD)或其变种来优化模型参数。
总的来说,前馈神经网络是一种基本的神经网络模型,由输入层、多个隐藏层和输出层组成。前馈神经网络通过激活函数将输入的加权和转换为非线性输出,通常用于分类和回归等任务,并通过反向传播算法进行训练。
蒸馏模块则用于进一步优化分割结果
虽然蒸馏模块主要用于深度神经网络蒸馏,但也可以用于优化分割结果。在图像分割任务中,蒸馏模块通常用于将一个复杂的模型(如ResNet)的知识转移到一个较简单的模型(如MobileNet)中,以提高分割结果的准确性和泛化能力。
具体来说,蒸馏模块的作用是将教师模型的特征表示和预测分布转移到学生模型中。特征表示的转移通常通过让学生模型在相同的输入图像上生成类似于教师模型的特征表示来实现。预测分布的转移通常通过让学生模型在相同的输入图像上生成类似于教师模型的概率预测分布来实现。在训练过程中,蒸馏模块通常使用教师模型的概率预测分布和原始标签之间的KL散度作为知识蒸馏的目标。
通过使用蒸馏模块优化分割结果,可以在不增加模型复杂度的情况下提高模型的准确性和泛化能力。此外,由于学生模型比教师模型更轻量级,因此蒸馏模块还可以减少分割模型的计算和存储需求,从而使得模型在移动设备等资源受限的环境中更容易部署和使用。
当使用蒸馏模块优化分割结果时,通常会对教师模型和学生模型进行一些限制,以确保蒸馏过程的有效性和稳定性。这些限制包括以下几个方面:
-
特征维度的一致性。学生模型生成的特征表示应该与教师模型的特征表示具有相同的维度和通道数。这可以通过在特征提取器中使用相同的卷积核大小和通道数来实现。
-
温度参数的设置。蒸馏过程中使用的温度参数对于学生模型的预测分布具有重要影响。通常,较高的温度参数可以使预测分布更加平滑,从而使学生模型更容易学习教师模型的特征分布。
-
蒸馏损失函数的权重。在知识蒸馏过程中,通常会将KL散度损失函数与交叉熵损失函数相结合,以平衡教师模型的知识转移和原始标签的监督。通常,KL散度损失函数的权重应该比交叉熵损失函数的权重小,以确保学生模型能够学习从教师模型中获得的知识。
-
优化器的选择。与其他深度学习任务一样,选择合适的优化器也是蒸馏模块优化分割结果的关键。通常,可以选择一些先进的优化器,如Adam或者SGD等,以加速训练过程并提高模型的性能。
总之,蒸馏模块可以用于优化分割结果,通过将教师模型的知识转移到学生模型中,并对模型的限制和优化器进行设置,可以提高模型的准确性和泛化能力,减少模型的计算和存储需求,从而使得模型在移动设备等资源受限的环境中更容易部署和使用。
如何使用自注意力机制来生成与这些区域对应的掩模
在图像分割中,我们通常需要生成与不同区域对应的掩模,以标识图像中的不同物体或者场景。为了实现这个目标,我们可以使用自注意力机制来学习每个像素与哪些区域相关,并生成相应的掩模。
具体来说,我们可以使用自注意力机制来计算每个像素与图像中所有像素之间的相关性。在这个过程中,我们可以将每个像素看作一个查询(query)向量、一个键(key)向量和一个值(value)向量,然后计算它们之间的注意力分数。这可以通过以下公式来实现:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中, Q Q Q、 K K K和 V V V分别表示查询、键和值向量, d k d_k dk表示键向量的维度。注意力分数可以看作查询向量与键向量之间的相似度,通过softmax函数归一化得到每个像素与其他像素之间的权重。最后,我们可以将权重与值向量加权求和,得到每个像素的表示向量。这个过程可以看作是对图像中每个像素的信息聚合和压缩,以便于生成相应的掩模。
在生成掩模的过程中,我们可以使用聚类算法或者阈值分割算法来将像素表示向量聚类成不同的区域。然后,我们可以将每个像素所属的区域作为它的掩模标签,并使用这些标签来训练图像分割模型。
总之,自注意力机制可以用于生成与不同区域对应的掩模,以帮助图像分割算法准确地识别和分割不同物体或者场景。通过计算每个像素与其他像素之间的相关性,自注意力机制可以将图像中的信息聚合和压缩,从而生成相应的掩模。
Mask2Former 如何使用了多尺度特征
Mask2Former是一种基于Transformer的图像分割模型,它通过引入多尺度特征来提高分割精度。
具体来说,Mask2Former使用了一组不同尺度的特征图来代表输入图像。这些特征图可以通过在不同层次的卷积网络中提取得到。每个特征图都被送入独立的Transformer编码器中进行编码,并生成相应的位置编码向量。然后,编码器的输出被送入一个Transformer解码器中进行解码,并生成每个像素的掩模标签。
在多尺度特征的使用过程中,Mask2Former使用了两种不同的方法来融合不同尺度的特征。一种方法是通过将不同尺度的特征图堆叠在一起,形成一个更高维度的输入特征,然后将这个特征输入到Transformer编码器中进行处理。这种方法可以帮助模型获取更多的上下文信息,并提高分割的准确性。
另一种方法是通过在Transformer的编码器和解码器之间添加多个跨尺度的注意力模块(cross-scale attention module),以帮助模型在不同尺度的特征之间进行交互和信息传递。在这个过程中,注意力模块可以帮助模型在不同尺度的特征之间学习相关性,并将不同尺度的特征进行融合,以提高分割的准确性。
总之,Mask2Former通过引入多尺度特征来提高分割精度。通过将不同尺度的特征图堆叠在一起或者使用跨尺度的注意力模块,Mask2Former可以帮助模型获取更多的上下文信息,并在不同尺度的特征之间进行交互和信息传递,从而提高分割的准确性。
Mask2Former的示例代码
在Mask2Former的图像分割任务中,我们需要最小化模型预测结果与真实标签之间的差异,常用的损失函数包括交叉熵损失函数和Dice损失函数等。以下是使用交叉熵损失函数进行训练的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader# 定义Mask2Former模型
class Mask2Former(nn.Module):def __init__(self, num_classes, num_layers=12, num_heads=12, hidden_dim=768):super().__init__()# 定义编码器、解码器和特征提取器,与之前的代码相同# 定义编码器self.encoder = nn.ModuleList([nn.TransformerEncoderLayer(d_model=hidden_dim, nhead=num_heads)for _ in range(num_layers)])# 定义解码器self.decoder = nn.ModuleList([nn.TransformerDecoderLayer(d_model=hidden_dim, nhead=num_heads)for _ in range(num_layers)])# 定义特征提取器self.backbone = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, hidden_dim, kernel_size=3, padding=1),nn.ReLU(inplace=True))# 定义位置编码器self.positional_encoding = nn.Embedding(256, hidden_dim)# 定义最终的分类器self.classifier = nn.Conv2d(hidden_dim, num_classes, kernel_size=1)#def forward(self, x):# 提取特征、添加位置编码、编码、解码和分类,与之前的代码相同#return xdef forward(self, x):# 提取特征features = self.backbone(x)# 添加位置编码b, c, h, w = features.size()position_ids = torch.arange(h * w, device=features.device).view(1, h, w)position_ids = self.positional_encoding(position_ids)position_ids = position_ids.expand(b, h, w, -1).permute(0, 3, 1, 2)features = features + position_ids# 编码for layer in self.encoder:features = layer(features)# 解码for layer in self.decoder:features = layer(features, features)# 分类output = self.classifier(features)return output# 定义数据集和数据加载器
train_dataset = MyDataset(train_images, train_masks)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)# 定义模型、损失函数和优化器
model = Mask2Former(num_classes=2)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)# 训练模型
for epoch in range(10):running_loss = 0.0for i, (inputs, labels) in enumerate(train_loader):# 将输入和标签转换为张量,并将其送入GPUinputs = torch.tensor(inputs).float().cuda()labels = torch.tensor(labels).long().cuda()# 向前传播,计算损失函数并更新模型参数optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 计算当前批次的损失函数值running_loss += loss.item()# 输出每个epoch的损失函数值print('Epoch [%d], Loss: %.4f' % (epoch+1, running_loss / len(train_loader)))
在上述代码中,我们定义了Mask2Former模型、数据集、数据加载器、损失函数和优化器,并使用交叉熵损失函数进行训练。在训练过程中,我们首先将输入和标签转换为张量,并将其送入GPU中。然后我们向前传播,计算损失函数并更新模型参数。最后输出每个epoch的损失函数值。
在这段训练模型的代码中,我们使用了一个简单的循环来遍历训练数据集,并对模型进行训练。对于每个批次的数据,我们首先将输入张量和标签张量转换为PyTorch张量,并将它们送入GPU。然后我们执行前向传播,计算损失函数,并执行反向传播和参数更新。最后,我们计算当前批次的损失函数值,并将其累加到running_loss变量中。
在训练过程中,我们使用了一个交叉熵损失函数,它是一种常用的损失函数,用于多分类问题。对于每个像素位置,我们将模型的输出视为一个长度为num_classes的向量,每个维度表示一个类别的概率。然后我们将这个向量与标签张量进行比较,计算交叉熵损失函数。最终的损失函数值是所有像素位置的损失函数值的平均值。
在训练过程中,我们还使用了一个优化器,具体来说是Adam优化器。它是一种常用的优化器,用于随机梯度下降算法。它可以自适应地调整每个参数的学习率,以便更好地适应不同的参数空间。我们还可以调整其他超参数,例如学习率、权重衰减和动量,以获得更好的训练效果。
如果您想使用ViT(Vision Transformer)作为特征提取器,以下是一个可以运行的ViT特征提取器示例代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
from timm.models.vision_transformer import VisionTransformerclass ViTFeatureExtractor(nn.Module):def __init__(self, img_size=256, patch_size=32, in_chans=3, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0):super().__init__()self.patch_size = patch_size# 定义ViT模型self.vit = VisionTransformer(img_size=img_size, patch_size=patch_size, in_chans=in_chans, num_classes=0,embed_dim=embed_dim, depth=depth, num_heads=num_heads, mlp_ratio=mlp_ratio)def forward(self, x):# 将输入图像分割成多个patch,并将它们展平patches = self.extract_patches(x)patches = rearrange(patches, 'b p c h w -> (b p) c h w')# 将patch送入ViT模型中提取特征features = self.vit.forward_features(patches)# 将特征重新排列成二维的形状features = rearrange(features, 'b (h w) c -> b c h w', h=int(x.shape[2] / self.patch_size), w=int(x.shape[3] / self.patch_size))return featuresdef extract_patches(self, x):# 将输入图像分割成多个patch,并将它们展平b, c, h, w = x.shapep = self.patch_sizex = rearrange(x, 'b c (h p1) (w p2) -> (b h w) c p1 p2', p1=p, p2=p)return x# 测试特征提取器
image = torch.randn(1, 3, 256, 256)
feature_extractor = ViTFeatureExtractor()
features = feature_extractor(image)
print(features.shape)
在上述代码中,我们首先定义了一个名为ViTFeatureExtractor的类作为特征提取器。在类的构造函数中,我们定义了ViT模型的各种参数。在forward函数中,我们首先将输入图像分割成多个patch,并将它们展平。然后将patch送入ViT模型中提取特征。最后将特征重新排列成二维的形状并返回。我们还定义了一个名为extract_patches的辅助函数,用于将输入图像分割成多个patch。
在测试特征提取器时,我们首先生成一个随机的输入图像,并将其传递给特征提取器。特征提取器将返回一个形状为(1, 768, 8, 8)的特征张量,其中768表示特征维度,8表示patch的行数和列数。
图像分割的标签张量
在图像分割任务中,标签张量通常是一个与输入图像大小相同的张量,其中每个像素位置都对应着一个标签。标签可以是一个整数,表示像素所属的类别,也可以是一个向量,表示像素在不同通道上的取值。在语义分割任务中,通常使用的是像素级别的标签,即每个像素都被标记为一个类别。
例如,对于一个大小为[H, W]的图像,其标签张量的形状也是[H, W]。对于每个像素位置[i, j],标签张量的值就是该像素所属的类别。例如,如果该像素属于类别0,则标签张量中对应的值就是0。因此,标签张量可以看作是一个二维数组,其中每个元素都表示一个像素的类别。
在训练过程中,我们通常将标签张量转换为分类任务的目标张量,即一个大小为[num_classes, H, W]的张量,其中num_classes是类别的数量。对于每个像素位置[i, j],目标张量的值就是一个长度为num_classes的向量,其中第k个分量表示该像素是否属于第k个类别。例如,如果该像素属于类别0,则目标张量中对应的向量就是[1, 0, 0, …, 0]。这样,我们就可以使用交叉熵损失函数来衡量模型输出与真实标签之间的差异。
vit 提取的特征和cnn提取的特征有什么不同?
ViT(Vision Transformer)和CNN(Convolutional Neural Network)是两种常用的图像特征提取器。它们的主要不同在于特征提取的方式和处理方式。
CNN是一种基于卷积操作的特征提取器,它通过在图像上滑动卷积核来提取局部特征,并通过池化操作来减少特征维度。CNN在处理图像时,能够有效地捕捉局部和全局的特征,同时通过卷积和池化操作,能够对图像进行平移、缩放和旋转等变换不变性的处理。
ViT是一种基于自注意力机制的特征提取器,它将图像分割为多个小块,并将每个小块的像素值作为输入,然后通过多层Transformer模型进行特征提取。在ViT中,每个小块被看作是一个序列,模型通过自注意力机制来计算序列中每个位置之间的关系,并生成对应的特征表示。ViT能够对图像进行全局特征的提取,因此在一些需要对全局特征进行处理的任务上表现较好。
总的来说,CNN在处理图像时更加灵活,能够有效地捕捉局部和全局的特征。而ViT则更加适合处理需要全局特征的任务,例如图像分类和目标检测等任务。但需要注意的是,ViT对输入图像大小和分块大小比较敏感,在实际应用中需要进行调参。
Dice损失函数
Dice损失函数是一种常用的用于图像分割任务的损失函数,它可以衡量模型预测结果与真实标签之间的相似程度。Dice损失函数的计算方式如下:
D i c e L o s s = 1 − 2 ∗ ∑ i = 1 N ( p i ∗ y i ) ∑ i = 1 N p i + ∑ i = 1 N y i DiceLoss = 1 - \frac{2 * \sum_{i=1}^{N}(p_i * y_i)}{\sum_{i=1}^{N}p_i + \sum_{i=1}^{N}y_i} DiceLoss=1−∑i=1Npi+∑i=1Nyi2∗∑i=1N(pi∗yi)
其中, p i p_i pi表示模型的预测结果, y i y_i yi表示真实标签, N N N表示像素数。
Dice损失函数的取值范围在0到1之间,当预测结果与真实标签完全一致时,Dice损失函数取得最小值0;当预测结果与真实标签完全不一致时,Dice损失函数取得最大值1。
在PyTorch中,可以通过以下代码实现Dice损失函数:
import torch
import torch.nn as nnclass DiceLoss(nn.Module):def __init__(self):super(DiceLoss, self).__init__()def forward(self, inputs, targets, smooth=1):# 将输入和标签转换为浮点数张量inputs = inputs.float()targets = targets.float()# 计算分子和分母intersection = (inputs * targets).sum()total = inputs.sum() + targets.sum()# 计算Dice损失函数dice = 1 - (2 * intersection + smooth) / (total + smooth)return dice
在上述代码中,我们定义了一个名为DiceLoss的类,该类继承自nn.Module类。在类的构造函数中,我们没有定义任何参数。在forward函数中,我们首先将输入和标签转换为浮点数张量。然后我们计算分子和分母,并使用上述公式计算Dice损失函数。最后将计算结果返回。
需要注意的是,由于Dice损失函数的计算过程中存在除法操作,因此在分母为0的情况下会出现NaN值。为了避免这种情况,我们通常会在分母中添加一个平滑项,如上述代码中的smooth参数。
Mask2Former 的 backbone 可以使用那些?
Mask2Former是一种基于Transformer的图像分割模型,它可以使用各种不同的Transformer架构作为其backbone。在实践中,常用的Transformer架构包括:
-
Vision Transformer (ViT):ViT是一种基于self-attention机制的Transformer模型,专门设计用于图像分类任务。它将图像划分为一个个小的patch,并在每个patch上应用Transformer模型。然后,将Transformer输出的特征向量输入到一个全连接层中,以进行分类。在Mask2Former中,可以使用ViT作为backbone,将其应用于图像分割任务。
-
Swin Transformer:Swin Transformer是一种基于多层分层注意力机制的Transformer模型,专门设计用于处理大尺寸图像。它将图像划分为多个不同大小的区域,并在每个区域上应用Transformer模型。然后,通过多层分层注意力机制将不同区域的特征进行融合。在Mask2Former中,可以使用Swin Transformer作为backbone,以处理大尺寸图像的分割任务。
-
Residual Attention Network (RAN):RAN是一种基于残差连接和注意力机制的卷积神经网络。它通过在不同层次上应用注意力机制来提取图像的空间特征,并通过残差连接来保留图像的语义信息。在Mask2Former中,可以使用RAN作为backbone,以提取图像的空间特征并进行分割。
除了以上提到的Transformer架构,还可以使用其他的Transformer架构作为Mask2Former的backbone,以适应不同的图像分割任务和数据集。
当使用Transformer作为图像分割模型的backbone时,通常需要考虑以下几个方面:
-
输入图像的划分:与传统的卷积神经网络不同,Transformer模型不能直接处理整个图像。因此,需要将输入图像划分为多个小的区域,例如ViT中的patch,Swin Transformer中的window等。这些小的区域可以通过重叠或不重叠的方式进行划分,以便在不同的区域上应用Transformer模型。
-
特征融合:与卷积神经网络不同,Transformer模型在不同区域上提取的特征向量是独立的,需要进行特征融合才能得到整个图像的特征表示。在Swin Transformer中,使用多层分层注意力机制来融合不同区域的特征。而在ViT中,则使用全局平均池化来融合不同patch的特征。
-
多尺度特征提取:在处理尺寸较大的图像时,需要考虑多尺度特征提取的问题。一种常见的方法是使用不同大小的patch或window来提取不同尺度的特征。在Swin Transformer中,通过层次化的window划分来处理多尺度图像。在ViT中,则可以使用不同大小的patch来提取不同尺度的特征。
-
位置编码:为了在Transformer模型中引入位置信息,需要对输入的区域或patch进行位置编码。常用的位置编码方法包括绝对位置编码和相对位置编码等。
总之,使用Transformer作为图像分割模型的backbone可以有效地利用self-attention机制来提取图像的空间信息,从而获得更好的分割性能。同时,需要考虑输入图像的划分、特征融合、多尺度特征提取和位置编码等问题,以便更好地适应不同的图像分割任务和数据集。
CNN以及Transformer特征图可视化
相关文章:
Mask2Former来了!用于通用图像分割的 Masked-attention Mask Transformer
原理https://blog.csdn.net/bikahuli/article/details/121991697 源码解析 论文地址:http://arxiv.org/abs/2112.01527 项目地址:https://bowenc0221.github.io/mask2former Mask2Former的整体架构由三个组件组成: 主干特征提取器ÿ…...

【量化课程】01_投资与量化投资
文章目录 1.1 什么是投资1.1.1 经济意义上的投资1.1.2 投资的分类1.1.3 金融投资1.1.4 个人投资者投资品种1.1.5 投资VS投机 1.2 股票投资的基本流程1.3 常见的股票投资分析流派1.3.1 投资者分析流派 1.4 什么是量化投资1.4.1 量化投资基本概念1.4.2 量化投资的优势1.4.3 量化投…...

SpringBoot实现导出Excel功能
1 问题背景 需求要做一个导出excel的功能 2 前言 本篇着重阐述后端怎么实现,前端实现的部分只会粗略阐述。该实现方案是经过生产环境考验的,不是那些拿来练手的小demo。本文阐述的方案可以借鉴用来做毕设或者加到自己玩的项目中去。再次声明,…...

NSSCTF之Misc篇刷题记录⑧
NSSCTF之Misc篇刷题记录 [MMACTF 2015]welcome[广东强网杯 2021 团队组]欢迎参加强网杯[虎符CTF 2022]Plain Text[SWPUCTF 2021 新生赛]原来你也玩原神[SWPUCTF 2021 新生赛]我flag呢?[鹤城杯 2021]New MISC NSSCTF平台:https://www.nssctf.cn/ PS&…...

从零开始学习Linux运维,成为IT领域翘楚(七)
文章目录 🔥Linux下常用软件安装_JDK和Tomcat安装🔥Linux下常用软件安装_MySQL安装🔥Linux下常用软件安装_MySQL卸载 🔥Linux下常用软件安装_JDK和Tomcat安装 Jdk 安装 解压jdk安装包 tar -zxvf jdk-8u201-linux-x64.tar.gz -C/…...

优漫动游设计APP的UI界面需要注意哪些问题?
一、加载 加载时间的长短,很大程度的决定了用户体验是否有所提升,虽然理想中的页面加载出来应该一秒就够了,但是设计师不要忽略网络问题!如果网速不够的话,页面加载三五秒都算是快的了,所以在用户等待的过程中&a…...

面试 004
什么是 Java 内存结构 Java 内存结构就是 JVM 的运行书数据区的内存结构: 里面有堆、虚拟机栈、本地方法栈、程序计数器; 虚拟机栈:里面的数据结构是栈帧,存放了方法名,局部变量等信息 方法区在 1.8 的时候…...

CCF-202206-2-寻宝!大冒险!
目录 题目背景 问题描述 一、思路: 二、实现方法(C) 2.1、方法一(int储存) 思路: C实现如下: 2.2、方法二(结构体储存) 思路: 注意:边界…...
二叉搜索树中的众数
1题目 给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。 如果树中有不止一个众数,可以按 任意顺序 返回。 假定 BST 满足如下定义&…...

认识JSP
什么是JSP? JSP(Java Server Pages)是一种类似于HTML的标记语言,用于创建动态Web页面。与HTML不同的是,JSP页面中可以嵌入Java代码,由Web服务器在动态页面中生成HTML代码,从而实现Web应用程序的前端交互效…...
MySQL数据管理
一、MySQL数据库管理 1、库和表 行(记录):用来描述一个对象的信息 列(字段):用来描述对象的一个属性 2、常用的数据类型 int :整型 float :单精度浮点 4字节32位 double &…...
第十九章 Unity 其他 API
本节介绍一些其他经常使用的Unity类。首先,我们回顾一下Vector3向量类,它既可以表示方向,也可以表示大小。它在游戏中可以用来表示角色的位置,物体的移动/旋转,设置两个游戏对象之间的距离。在我们之前的课程中&#x…...

sha256算法详解,用C语言模拟sha256算法
SHA-256是一种加密算法,它可以将任意长度的数据块计算出一个固定长度的输出值,通常是256位。SHA-256具有以下特点: 1. 固定输出长度:SHA-256的输出长度为256位,不受输入数据的长度限制。 2. 不可逆性:SHA-256采用单向哈希函数,即无法从输出值反向推出输入数据。 3. 抗…...

前端技术未来发展展望
前端技术在未来的发展中将继续保持快速、变化多样和创新性强的趋势。以下是我认为前端技术未来发展的几个方向: 框架和库的演进:框架和库的更新换代将继续加速。React、Vue、Angular等主流框架的更新周期将会缩短,同时各自的生态系统也将更加…...

第四十六天|dp
今天的题还是完全背包的题 139. Word Break 这道题其实用deque也能做,但是需要cache去记录之前尝试过的值,.相对简单的办法就是用完全背包了 这道题worddict就是物品.我们的dp[i]代表到i为止是不是能满足题意分成segmentation 处置化全为false,但是dp[0]True.这是因为为0时…...
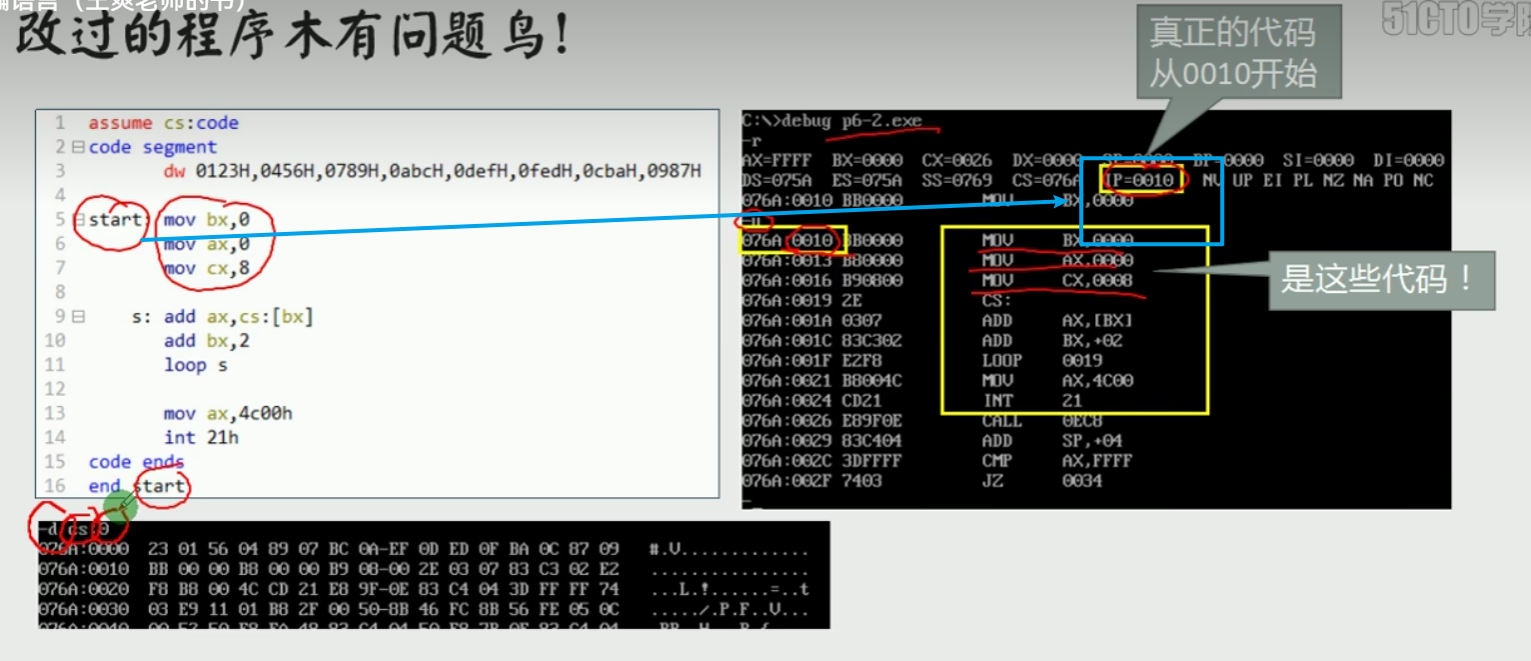
汇编语言-复习自用
本文用于自我复习汇编语言,参考b站一位老师的讲解整理而成,感谢老师的无私付出视频链接链接 文章目录 1.第一章1.1计算机组成1.2读取1.3 寄存器及数据存储1.4 mov和and指令1.5 确定物理地址1.6 内存分段表示法1.7debug使用1.8CS:IP1.9jmp指令改变csip1.1…...

Android moneky自动点击应用设想
近期又有人发错私密消息到群聊天里,造成巨大反应的事件,可谓是一失手成大恨,名利受损。 而如果手机里安装一个monkey自动点击程序,没事的时候,跑跑monkey,倒一杯茶,静静的看手机屏幕在那里点击&…...
16.基于主从博弈理论的共享储能与综合能源微网优化运行研究
说明书 MATLAB代码:基于主从博弈理论的共享储能与综合能源微网优化运行研究 关键词:主从博弈 共享储能 综合能源微网 优化调度 参考文档:《基于主从博弈理论的共享储能与综合能源微网优化运行研究》完全复现 仿真平台:MATLAB …...

使用 ESP32 设计智能手表第 2 部分 - 环境光和心率传感器
我们研究了如何为我们的智能手表项目制作一些有趣的表盘。在这一部分中,我们将研究如何将一些传感器连接到我们的智能手表,并将连接 BH1750 环境光传感器和 MAX30102 心率传感器。我们将分别研究这些模块中的每一个的接口。 先决条件——安装必要的库 本文下方提供的 GitHub …...

分布式事务 --- 理论基础、Seata架构、部署
一、分布式事务问题 1.1、本地事务 本地事务,也就是传统的单机事务。在传统数据库事务中,必须要满足四个原则: 1.2、分布式事务 分布式事务,就是指不是在单个服务或单个数据库架构下,产生的事务,例如&am…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...