解决使用CLIP模型时TypeError: Cannot handle this data type: (1, 1, 224, 224), |u1
想提供Huggingface的transformer库实现多模态模型CLIP的推断,结果报错
(myenv) root@d27d1ff1836c:/home/model_test# python3 CLIP.py
ftfy or spacy is not installed using BERT BasicTokenizer instead of ftfy.
Traceback (most recent call last):
File “/home/model_test/myenv/lib/python3.8/site-packages/PIL/Image.py”, line 3089, in fromarray
mode, rawmode = _fromarray_typemap[typekey]
KeyError: ((1, 1, 224, 224), ‘|u1’)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File “CLIP.py”, line 87, in
inputs = processor(text=text, images=image, return_tensors=“pt”, padding=True)
File “/home/model_test/myenv/lib/python3.8/site-packages/transformers/models/clip/processing_clip.py”, line 148, in call
image_features = self.feature_extractor(images, return_tensors=return_tensors, **kwargs)
File “/home/model_test/myenv/lib/python3.8/site-packages/transformers/models/clip/feature_extraction_clip.py”, line 146, in call
images = [self.resize(image=image, size=self.size, resample=self.resample) for image in images]
File “/home/model_test/myenv/lib/python3.8/site-packages/transformers/models/clip/feature_extraction_clip.py”, line 146, in
images = [self.resize(image=image, size=self.size, resample=self.resample) for image in images]
File “/home/model_test/myenv/lib/python3.8/site-packages/transformers/models/clip/feature_extraction_clip.py”, line 199, in resize
image = self.to_pil_image(image)
File “/home/model_test/myenv/lib/python3.8/site-packages/transformers/image_utils.py”, line 78, in to_pil_image
return PIL.Image.fromarray(image)
File “/home/model_test/myenv/lib/python3.8/site-packages/PIL/Image.py”, line 3092, in fromarray
raise TypeError(msg) from e
TypeError: Cannot handle this data type: (1, 1, 224, 224), |u1
以下注释掉的部分是出错的代码,而没被注释的代码是不出错的代码,最大的区别是没出错的代码没有进行图像预处理
by the way,出错的代码是GPT4给我的(改了10几次还是出错,看来训练数据有问题),而没出错的代码是newbing给我的,一次做对。文末给出提示词。
# import os
# import requests
# import torch
# import numpy as np
# from PIL import Image
# from torchvision import transforms
# from transformers import CLIPProcessor, CLIPFeatureExtractor, CLIPModel# os.environ["TRANSFORMERS_CACHE"] = "https://mirrors.tuna.tsinghua.edu.cn/hugging-face-models"# # 定义图像预处理操作
# preprocess = transforms.Compose([
# transforms.Resize(256),
# transforms.CenterCrop(224),
# transforms.ToTensor(),
# transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
# ])# # 加载预训练模型的处理器和模型
# processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# feature_extractor = CLIPFeatureExtractor.from_pretrained("openai/clip-vit-base-patch32")
# model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")# # 定义图像路径
# image_path = "images/photo-1.jpg"# # 如果图像不存在,则从网上下载一张
# if not os.path.exists(image_path):
# image_url = "https://images.unsplash.com/photo-1501594907352-04cda38ebc29"
# response = requests.get(image_url)
# with open(image_path, "wb") as f:
# f.write(response.content)# # 加载图像并执行预处理
# image = Image.open(image_path).convert("RGB")# # 修改 1:将 PIL 图像转换为 NumPy 数组,并确保数据类型为 uint8
# image_array = np.array(image).astype(np.uint8)# # 修改 2:检查图像数组的形状,如果需要,调整为 (H, W, C) 或 (H, W)
# image_shape = image_array.shape
# if len(image_shape) == 3 and image_shape[2] == 1:
# image_array = image_array.reshape(image_shape[0], image_shape[1])
# elif len(image_shape) == 4:
# image_array = image_array.transpose(1, 2, 0)# # 修改 3:将 NumPy 数组转回 PIL 图像
# image = Image.fromarray(image_array)# # 对图像进行预处理
# image_tensor = preprocess(image)
# # 修改:将图像张量从 (C, H, W) 转换为 (H, W, C),然后再转回 (C, H, W)
# image_np = image_tensor.numpy().transpose(1, 2, 0)
# image_np = image_np.astype(np.uint8) # 确保数据类型为 uint8
# image_tensor = torch.from_numpy(image_np.transpose(2, 0, 1))
# image_batch = image_tensor.unsqueeze(0)# # 定义输入文本
# texts = ["a cat", "a dog"]# # 预处理输入(文本和图像)
# text_inputs = processor(text=texts, return_tensors="pt", padding=True)
# image_inputs = feature_extractor(images=image_batch, return_tensors="pt")# # 获取特征
# with torch.no_grad():
# outputs = model(text_inputs, image_inputs)# image_features = outputs.image_embeds
# text_features = outputs.text_embeds# # 计算文本和图像特征之间的余弦相似度
# similarity = text_features.numpy().dot(image_features.numpy().T)
# similarity = torch.from_numpy(similarity)# # 输出相似度
# print("Cosine similarity between the image and text inputs:", similarity.numpy())# from transformers import CLIPProcessor, CLIPModel
# import torch# processor = CLIPProcessor.from_pretrained('openai/clip-vit-base-patch32')
# model = CLIPModel.from_pretrained('openai/clip-vit-base-patch32')# text = ["Hello, my dog is cute", "I love my cat"]
# image = torch.randn(2, 3, 224, 224)
# inputs = processor(text=text, images=image, return_tensors="pt", padding=True)# outputs = model(**inputs)
# print(outputs.logits.shape)
from transformers import CLIPProcessor, CLIPModel
from PIL import Imagemodel = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")image_path = "images/photo-1.jpg"
image = Image.open(image_path)
text = ["这是一只狗", "这是一只猫", "这是一辆汽车"]inputs = processor(text=text, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)print(probs)
正确代码输出如下:
(myenv) root@d27d1ff1836c:/home/model_test# python3 CLIP.py
ftfy or spacy is not installed using BERT BasicTokenizer instead of ftfy.
/home/model_test/myenv/lib/python3.8/site-packages/transformers/feature_extraction_utils.py:158: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at …/torch/csrc/utils/tensor_new.cpp:201.)
tensor = as_tensor(value)
tensor([[0.6413, 0.2198, 0.1389]], grad_fn=)
newbing prompt:
请使用huggingface提供的transformer中的多模态模型CLIP,用简洁的代码实现CLIP模型的核心功能
已发送电子邮件. 请使用huggingface提供的transformer中的多模态模型CLIP,用简洁的代码实现CLIP模型的核心功能
您好,这是Bing。您可以使用Hugging Face提供的Transformers库中的CLIP模型来实现您所需的功能。下面是一个简单的示例代码,它展示了如何使用Transformers库中的CLIP模型来实现其核心功能:
from transformers import CLIPProcessor, CLIPModelmodel = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")image = ... # 加载图像
text = ... # 输入文本inputs = processor(text=text, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
希望这对您有所帮助!
我希望你给我一个可以运行的代码,而不是伪代码,我图像的路径是image_path = “images/photo-1.jpg”,而文本你可以随机找几个句子
已发送电子邮件. 我希望你给我一个可以运行的代码,而不是伪代码,我图像的路径是image_path = “images/photo-1.jpg”,而文本你可以随机找几个句子
您好,这是Bing。下面是一个可以运行的示例代码,它展示了如何使用Transformers库中的CLIP模型来实现其核心功能:
from transformers import CLIPProcessor, CLIPModel
from PIL import Imagemodel = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")image_path = "images/photo-1.jpg"
image = Image.open(image_path)
text = ["这是一只狗", "这是一只猫", "这是一辆汽车"]inputs = processor(text=text, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)print(probs)
请注意,您需要安装Transformers库和Pillow库才能运行此代码。希望这对您有所帮助!
相关文章:
, |u1)
解决使用CLIP模型时TypeError: Cannot handle this data type: (1, 1, 224, 224), |u1
想提供Huggingface的transformer库实现多模态模型CLIP的推断,结果报错 (myenv) rootd27d1ff1836c:/home/model_test# python3 CLIP.py ftfy or spacy is not installed using BERT BasicTokenizer instead of ftfy. Traceback (most recent call last): File “/hom…...
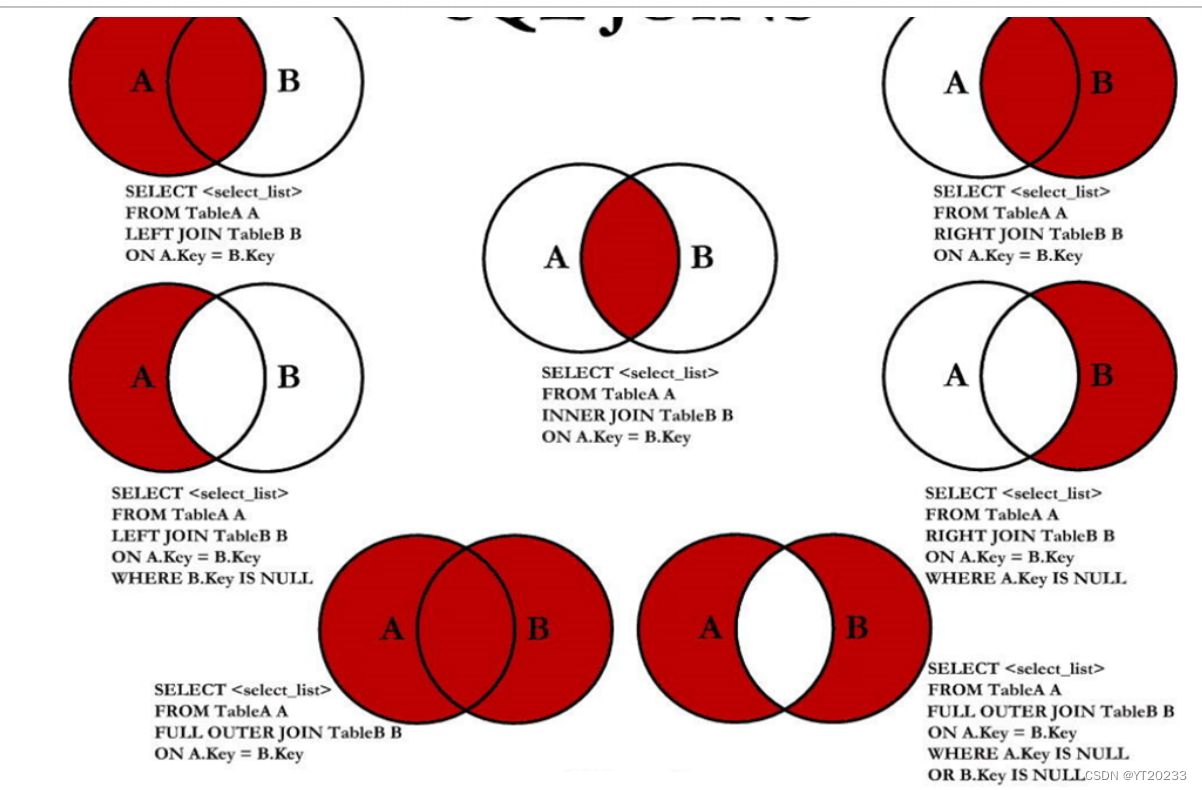
Mysql第二章 多表查询的操作
这里写自定义目录标题 一 外连接与内连接的概念sql99语法实现 默认是内连接sql99语法实现左外连接,把没有部门的员工也查出来sql99语法实现右外连接,把没有人的部门查出来sql99语法实现满外连接,mysql不支持这样写mysql中如果要实现满外连接的…...

ESP32-CAM:TinyML 图像分类——水果与蔬菜
目录 故事 硬件参数: 在 Arduino IDE 上安装 ESP32-Cam 使用 BLINK 测试电路板 测试无线网络 运行您的 Web 服务器 水果与蔬菜-图像分类 下载数据集 使用 Edge Impulse Studio 训练模型...
如何防止订单重复支付
想必大家对在线支付都不陌生,今天和大家聊聊如何防止订单重复支付。 看看订单支付流程 我们来看看,电商订单支付的简要流程: 订单钱包支付流程 从下单/计算开始: 下单/结算:这一步虽然不是直接的支付起点,但…...

不是那么快乐的五一
大家好,我是记得诚。 五一假期结束了,明天开始上班了。 这个假期没休息好,也没出去玩。 放假前一天,接到通知让加班。 第一天就去公司加班了,属实很难受,我心想如果别人有了出远门的安排,还…...

Maven命令和配置详解
Maven命令和配置详解 1. pom基本结构2. build基本结构3. Maven命令详解3.1 打包命令3.2 常用命令3.3 批量修改版本-父子pom4. Maven配置详解4.1 settings.xml4.2 项目内的maven工程结构Maven POM构建生命周期工程实践1. pom基本结构 <?xml versi...
P3029 [USACO11NOV]Cow Lineup S 双指针 单调队列
“五一”小长假来了趟上海,在倒数第二天终于有时间做了一会儿题目,A了之后过来写一篇题解 【问题描述】 农民约翰雇一个专业摄影师给他的部分牛拍照。由于约翰的牛有好多品种,他喜欢他的照片包含每个品种的至少一头牛。 约翰的牛都站在一条沿…...
)
数据结构与算法之链表: Leetcode 83. 删除排序链表中的重复元素 (Typescript版)
删除排序链表中的重复元素 https://leetcode.cn/problems/remove-duplicates-from-sorted-list/ 描述 给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 示例 1 输入:head [1,1,2] 输出&…...
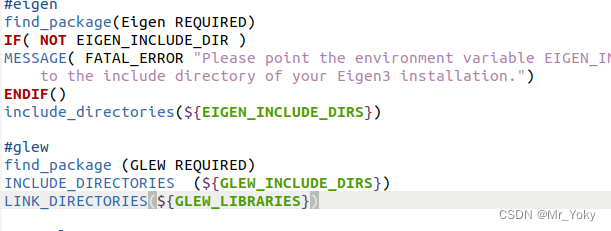
ubuntu16.04升级到20.04后报错 By not providing “FindEigen.cmake“
编译问题: CMake Error at modules/perception/lidar/CMakeLists.txt:14 (find_package): By not providing "FindEigen.cmake" in CMAKE_MODULE_PATH this project has asked CMake to find a package configuration file provided by "Eigen&…...
设计模式——模板方法模式
是什么? 在我们的实际开发中尝尝会遇到这种问题:在设计一个系统时知道了算法所需要的关键步骤,而且确定了这些步骤的执行顺序,但是某些步骤的具体实现还不知道,或者说某些步骤的实现与具体的环境相关,例如每…...
15 | Qt的自定义信号
1 前提 Qt 5.14.2 2 具体操作 2.1 自定义信号 2.1.1 UI界面设置 2.1.1.1 widget.ui 2.1.1.2 setdialog.ui 2.1.2 headers 2.1.2.1 widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget>QT_BEGIN_NAMESPACE namespace Ui {class Widget; } QT_END_NAMESP…...

线性表,顺序表,链表
线性表 线性表(linear list)是n个具有相同特性的数据元素的有限序列 线性表是一种在实际中广泛使 用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串... 线性表在逻辑上是线性结构,也就说是连续的一条直线 …...

洛谷 P2782 友好城市 线性DP 最长上升子序列 二分查找 lower_bound
🍑 算法题解专栏 🍑 洛谷:友好城市 题目描述 有一条横贯东西的大河,河有笔直的南北两岸,岸上各有位置各不相同的N个城市。北岸的每个城市有且仅有一个友好城市在南岸,而且不同城市的友好城市不相同。每对…...
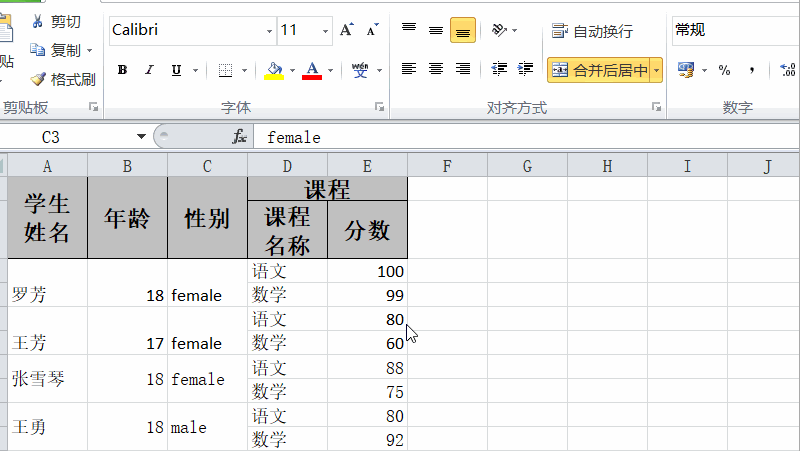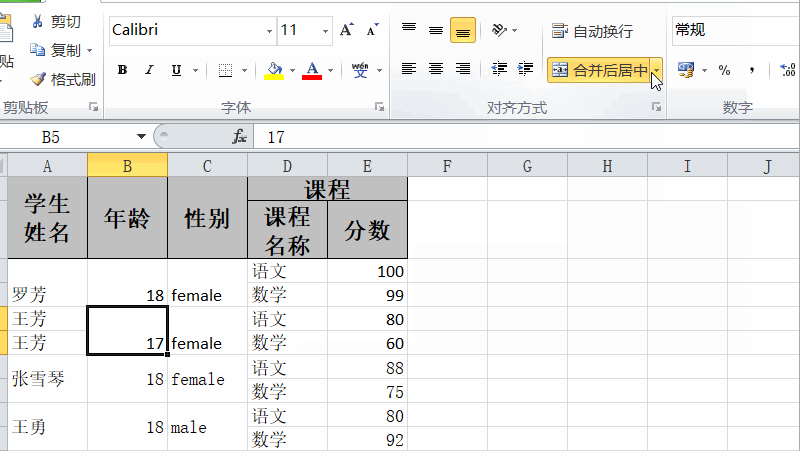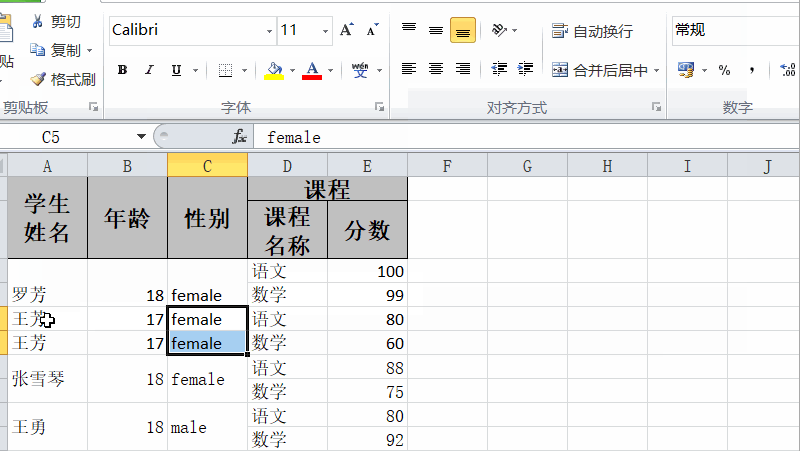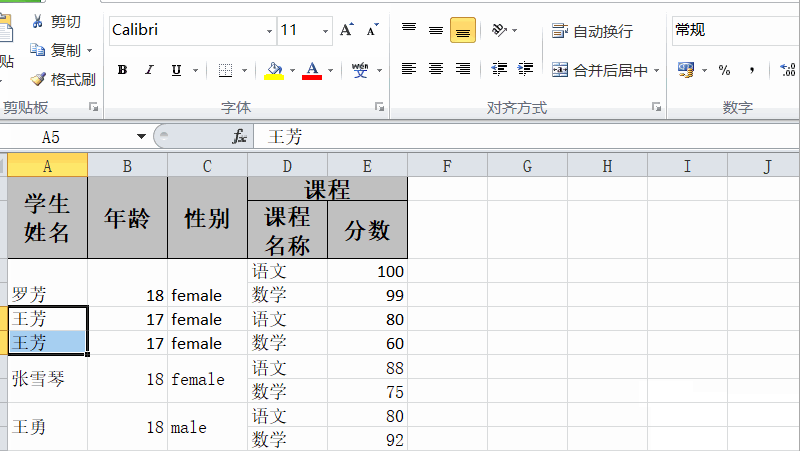
easyexcel读取excel合并单元格数据
普通的excel列表,easyexcel读取是没有什么问题的。但是,如果有合并单元格,那么它读取的时候,能获取数据,但是数据是不完整的。如下所示的单元格数据: 我们通过简单的异步读取,最后查看数据内容&…...

2023哪款蓝牙耳机性价比高?200左右高性价比蓝牙耳机推荐
现如今的蓝牙耳机越来越多,人们在选择时不免纠结,不知道选什么蓝牙耳机比较好?针对这个问题,我来给大家推荐几款性价比高的蓝牙耳机,一起来看看吧。 一、南卡小音舱Lite2蓝牙耳机 参考价:299 蓝牙版本&am…...
)
Java代码弱点与修复之——Masked Field(掩码字段)
弱点描述 MF: Masked Field (FB.MF_CLASS_MASKS_FIELD) 是 FindBugs 代码分析工具的一个警告信息, 属于中风险的代码弱点。 Masked Field,翻译过来是掩码字段, 字段可以理解为属性, 那么掩码是什么意思呢? 掩码是什么? 掩码是一串二进制代码对目标字段进行位与运算,屏…...
(8))
C语言编程入门之刷题篇(C语言130题)(8)
(题目标题可以直接跳转此题链接) BC72 平均身高 描述 从键盘输入5个人的身高(米),求他们的平均身高(米)。 输入描述: 一行,连续输入5个身高(范围0.00~2.00…...

QML动画类型总结
目录 一 常用动画 二 特殊场景动画 一 常用动画 有几种类型的动画,每一种都在特定情况下都有最佳的效果,下面列出了一些常用的动画: 1、PropertyAnimation(属性动画)- 使用属性值改变播放的动画; 2、Num…...
编译一个魔兽世界开源服务端Windows需要安装什么环境
编译一个魔兽世界开源服务端Windows需要安装什么环境 大家好我是艾西,去年十月份左右wy和bx发布了在停服的公告。当时不少小伙伴都在担心如果停服了怎么办,魔兽这游戏伴随着我们渡过了太多的时光。但已经发生的事情我们只能顺其自然的等待GF的消息就好了…...

HTML5字体集合的实践经验
随着互联网的发展,网站已成为人们获取信息和交流的重要平台。而一个好的网站,不仅需要有美观的界面,还需要有良好的用户体验。其中,字体是影响用户体验的一个重要因素。下面就让我们来看看HTML字体集合的相关内容。 HTML字体集合是…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...

Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement
Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement 1. LAB环境2. L2公告策略2.1 部署Death Star2.2 访问服务2.3 部署L2公告策略2.4 服务宣告 3. 可视化 ARP 流量3.1 部署新服务3.2 准备可视化3.3 再次请求 4. 自动IPAM4.1 IPAM Pool4.2 …...