台北房价预测
目录
- 1.数据理解
- 1.1分析数据集的基本结构,查询并输出数据的前 10 行和 后 10 行
- 1.2识别并输出所有变量
- 2.数据清洗
- 2.1输出所有变量折线图
- 2.2缺失值处理
- 2.3异常值处理
- 3.数据分析
- 3.1寻找相关性
- 3.2划分数据集
- 4.数据整理
- 4.1数据标准化
- 5.回归预测分析
- 5.1线性回归&岭回归&套索回归
- 6.可视化
- 6.1均分方差
- 6.2平均绝对误差
- 6.3 所有预测值与真实值对比
1.数据理解
from sklearn import model_selection as ms
from sklearn.preprocessing import StandardScaler
from sklearn import linear_model
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import PolynomialFeatures as Poly
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltdata=pd.read_excel("台北房产数据集.xlsx")
1.1分析数据集的基本结构,查询并输出数据的前 10 行和 后 10 行
#前十行
data.head(10)

#后十行
data.tail(10)
1.2识别并输出所有变量
data.dtypes

2.数据清洗
2.1输出所有变量折线图
便于观察观察所有特征的数据。
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 绘制直方图
data.hist(bins=50, figsize=(20,15))



2.2缺失值处理
查看每一列的缺失值
#查看每一列的缺失值
data.isnull().sum()

由于缺失值较少,删除具有缺失值的行不会对数据有太大改变。
#删除具有空值的行
data=data.dropna()
data.shape
#(412, 8)
2.3异常值处理
在上面的直方图中我们可以看到有部分数值是与之前的数值格格不入的;
比如附近便利店的数量达到70多个、单位房价值异常高;
我们把这些异常值的行取平均数填入;
- 先找到数量异常的行
- 再计算该列的平均值
- 最后将该行个数替换为列的平均
#在上面的直方图中我们可以看到有部分数值是与之前的数值格格不入的
#比如附近便利店的数量达到70多个、单位房价值异常高
#我们把这些异常值的行取平均数填入#先找到便利店数量异常的行
data.loc[data['X4 附近便利店家数']>50]
print("异常行的数量:",data.loc[data['X4 附近便利店家数']>50].shape[0])

#将该行便利店个数替换为列的平均值#先计算该列的平均值
shop_avg=(int)(data['X4 附近便利店家数'].mean())
print("附近便利店家数的平均值为:",shop_avg)
data["X4 附近便利店家数"]=data["X4 附近便利店家数"].replace({70:shop_avg})
print("异常行的数量:",data.loc[data['X4 附近便利店家数']>50].shape[0])

#先找到单位面积房价异常的行
data.loc[data['Y 单位面积房价']>100]
# print("异常行的数量:",data.loc[data['Y 单位面积房价']>100].shape[0])

#将该行单位房价替换为列的平均值#先计算该列的平均值
shop_avg=(int)(data['Y 单位面积房价'].mean())
print("单位面积房价的平均值为:",shop_avg)
data["Y 单位面积房价"]=data["Y 单位面积房价"].replace({117.5:shop_avg})
print("异常行的数量:",data.loc[data['Y 单位面积房价']>100].shape[0])

3.数据分析
3.1寻找相关性
由于有些特征可能对房价起不到太大作用,还有可能与目标标签是负相关的关系,放到训练集里面既是浪费算力也会减少模型的准确性。
我们数据分析的第一步就是寻找相关性,相关系数范围 [-1, 1] ,越接近 1 表示有越强的正相关,越接近 -1 表示有越强的负相关:
#寻找相关性,相关系数范围 [-1, 1] ,越接近 1 表示有越强的正相关,越接近 -1 表示有越强的负相关
corr_matrix = data.corr()
corr_matrix

#具体看每个属性与单位面积房价的相关性
corr_matrix["Y 单位面积房价"].sort_values(ascending=False)

由上面相关性可知便利店家数与经纬度的相关性较高,而交易年月虽是正相关,但趋近于零,而负相关的变量我们就不考虑了。
#定义散点图函数
def scatter_figure(th1,th2):data.plot(kind="scatter", x=th1, y=th2)plt.xlabel(th1)plt.ylabel(th2)data.plot(kind="scatter", x=th1, y=th2, alpha=0.3)plt.xlabel(th1)plt.ylabel(th2)
# 经度和单位房价的散点图与高密度点
scatter_figure('X6 经度','Y 单位面积房价')

# 纬度和单位房价的散点图与高密度点
scatter_figure('X5 纬度','Y 单位面积房价')

# 经度和纬度的散点图,查看在哪个区域的房价高低,与高密度点
scatter_figure('X6 经度','X5 纬度')

3.2划分数据集
我们把数据集按照训练集:测试集为7:3进行划分。
而特征值采用附近便利店数与经纬度这三列数据。
#划分数据集
y=data[['Y 单位面积房价']]
x=data[['X4 附近便利店家数','X5 纬度','X6 经度']]
x_train, x_test, y_train, y_test = ms.train_test_split(x, y, random_state=1, test_size=0.3)
x_train.head()

4.数据整理
4.1数据标准化
#标准化
std = StandardScaler()
x_train_std = std.fit_transform(x_train)
x_test_std = std.fit_transform(x_test)
print("标准化之前:\n",x_test)
print("标准化之后:\n",x_test_std)
标准化之前:

标准化之后:

5.回归预测分析
5.1线性回归&岭回归&套索回归
回归预测这一部分我们采用了三种回归模型来训练与预测。
三种模型得分:
#初始化训练器
line = linear_model.LinearRegression()
ridge=linear_model.Ridge()
lasso=linear_model.Lasso()nums=[1,2,3]
for num in nums:#用于生成多项式特征,即将输入数据的特征进行组合,生成新的特征poly= Poly(num) x_train_poly= poly.fit_transform(x_train_std)x_test_poly= poly.transform(x_test_std)line.fit(x_train_poly,y_train)ridge.fit(x_train_poly,y_train)lasso.fit(x_train_poly,y_train)# print("预测值为:",y_pred)# print("模型预测的均方误差:",mean_squared_error(y_test,y_test_pred))print("第{}轮训练结果:".format(num))print("线性回归模型得分:",line.score(x_test_poly,y_test))print("岭回归模型得分:",ridge.score(x_test_poly,y_test))print("套索回归模型得分:",lasso.score(x_test_poly,y_test))print("------------------------------------------------------")#预测
y_test_line_pred=line.predict(x_test_poly)
y_test_ridge_pred=ridge.predict(x_test_poly)
y_test_lasso_pred=lasso.predict(x_test_poly)

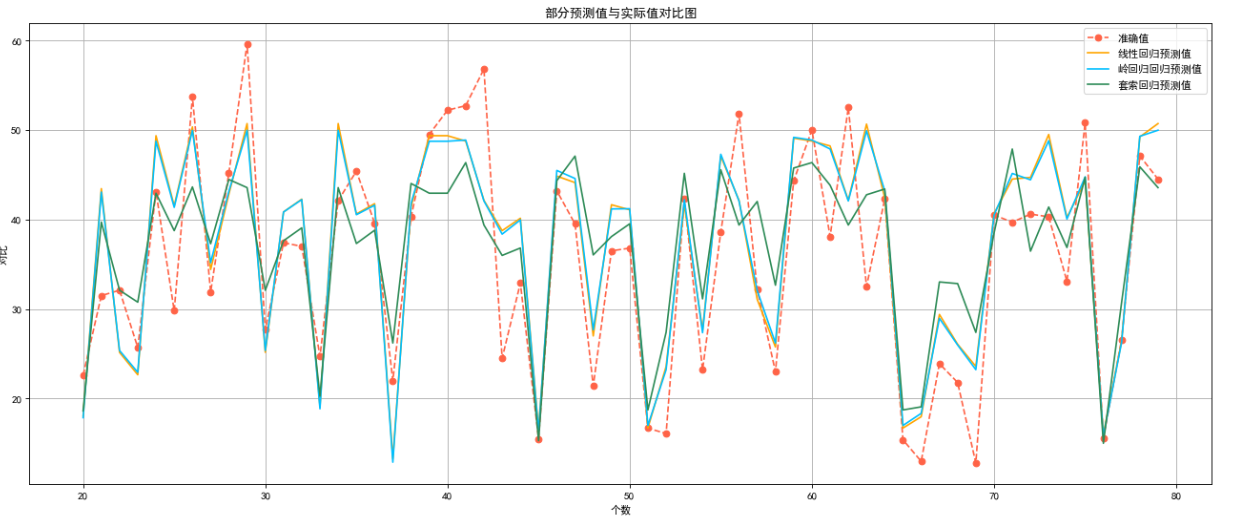
从得分中我们可以看出来线性回归与岭回归模型得分几乎相等,而套索回归模型稍逊色些。
部分预测值与实际值对比:
x=[]
for a in range(60):x.append([a+20])
# print(x)
y_test2=y_test[20:80]
y_line_pred=y_test_line_pred[20:80]
y_ridge_pred=y_test_ridge_pred[20:80]
y_lasso_pred=y_test_lasso_pred[20:80]
#设置图形
plt.figure(figsize=(20,8),dpi=80)
#画图,zoder是控制画图流程的属性,其值越大则表示画图的时间越晚
plt.plot(x,y_test2,color='tomato',linestyle='--',label='准确值',marker='o')
plt.plot(x,y_line_pred,color='orange',label='线性回归预测值')
plt.plot(x,y_ridge_pred,color='deepskyblue',label='岭回归回归预测值')
plt.plot(x,y_lasso_pred,color='seagreen',label='套索回归预测值')plt.xlabel("个数")#给x轴起名字
plt.ylabel("对比")#给y轴起名字
plt.grid() # 设置网格模式
plt.title("部分预测值与实际值对比图")
plt.legend()
#设置每个点上的数值
#展示
plt.show()
6.可视化
# 计算均分方差
train_MSE_line = [mean_squared_error(y_test, [np.mean(y_test)] * len(y_test)),mean_squared_error(y_test, y_test_line_pred)]
train_MSE_ridge = [mean_squared_error(y_test, [np.mean(y_test)] * len(y_test)),mean_squared_error(y_test, y_test_ridge_pred)]
train_MSE_lasso = [mean_squared_error(y_test, [np.mean(y_test)] * len(y_test)),mean_squared_error(y_test, y_test_lasso_pred)]#计算平均绝对误差
train_MAE_line = [mean_absolute_error(y_test, [np.mean(y_test)] * len(y_test)),mean_absolute_error(y_test, y_test_line_pred)]
train_MAE_ridge = [mean_absolute_error(y_test, [np.mean(y_test)] * len(y_test)),mean_absolute_error(y_test, y_test_ridge_pred)]
train_MAE_lasso = [mean_absolute_error(y_test, [np.mean(y_test)] * len(y_test)),mean_absolute_error(y_test, y_test_lasso_pred)]# 绘图函数
def figure(title, *datalist):print(datalist)plt.figure(facecolor='gray', figsize=[16, 8])for v in datalist:plt.plot(v[0], '-', label=v[1], linewidth=2)plt.plot(v[0], 'o')plt.grid()plt.title(title, fontsize=20)plt.legend(fontsize=16)plt.show()
6.1均分方差
# 绘制误差图
#figure(' 均分方差 = %.4f' % (train_MSE_line[-1]), [train_MSE_line, 'MSE'])
figure('line均分方差=%.4f ridge均分方差=%.4f lasso均分方差=%.4f' % (train_MSE_line[-1],train_MSE_ridge[-1],train_MSE_lasso[-1]),[train_MSE_line, '线性回归MSE'],[train_MSE_ridge, '岭回归MSE'],[train_MSE_lasso, '套索MSE'])

6.2平均绝对误差
figure('line平均绝对误差=%.4f ridge平均绝对误差=%.4f lasso平均绝对误差=%.4f' % (train_MAE_line[-1],train_MAE_ridge[-1],train_MAE_lasso[-1]),[train_MAE_line, '线性回归MAE'],[train_MAE_ridge, '岭回归MAE'],[train_MAE_lasso, '套索MAE'])

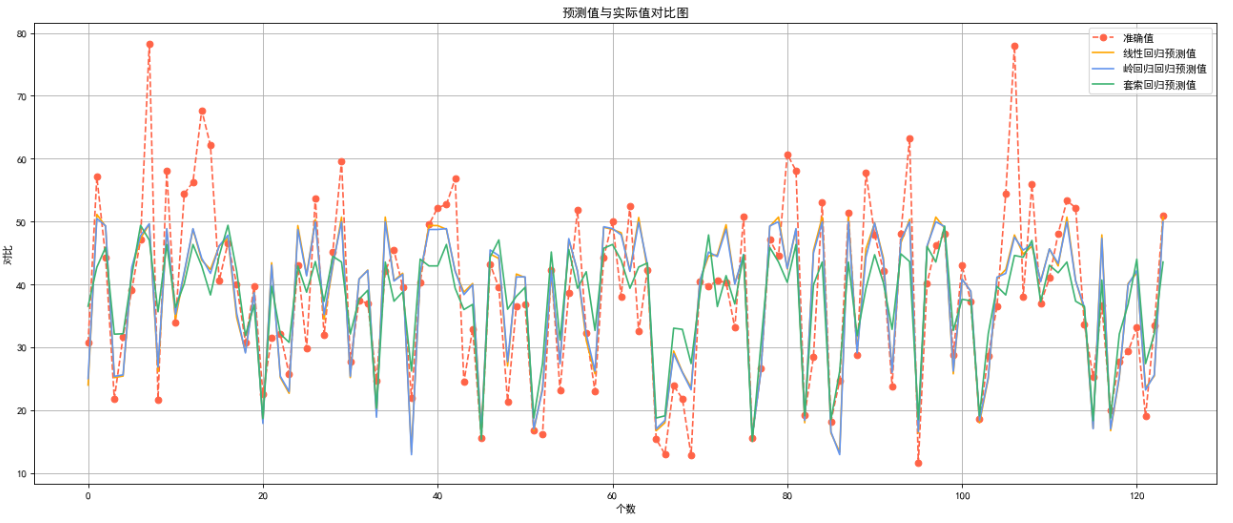
6.3 所有预测值与真实值对比
x=[]
for a in range(124):x.append([a])
#设置图形
plt.figure(figsize=(20,8),dpi=80)
#画图,zoder是控制画图流程的属性,其值越大则表示画图的时间越晚
plt.plot(x,y_test,color='tomato',linestyle='--',label='准确值',marker='o')
plt.plot(x,y_test_line_pred,color='orange',label='线性回归预测值')
plt.plot(x,y_test_ridge_pred,color='cornflowerblue',label='岭回归回归预测值')
plt.plot(x,y_test_lasso_pred,color='mediumseagreen',label='套索回归预测值')plt.xlabel("个数")#给x轴起名字
plt.ylabel("对比")#给y轴起名字
plt.grid() # 设置网格模式
plt.title("预测值与实际值对比图")
plt.legend()
#设置每个点上的数值
#展示
plt.show()
相关文章:
台北房价预测
目录 1.数据理解1.1分析数据集的基本结构,查询并输出数据的前 10 行和 后 10 行1.2识别并输出所有变量 2.数据清洗2.1输出所有变量折线图2.2缺失值处理2.3异常值处理 3.数据分析3.1寻找相关性3.2划分数据集 4.数据整理4.1数据标准化 5.回归预测分析5.1线性回归&…...
9:00进去,9:05就出来了,这问的也太···
从外包出来,没想到死在另一家厂子了。 自从加入这家公司,每天都在加班,钱倒是给的不少,所以也就忍了。没想到8月一纸通知,所有人不许加班,薪资直降30%,顿时有吃不起饭的赶脚。 好在有个兄弟内推…...

debootstrap 构建 RISC-V 64 Ubuntu 根文件系统
debootstrap 构建 Ubuntu RISC-V Linux 根文件系统 flyfish 主机信息 命令 lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04.6 LTS Release: 20.04 Codename: focal制作的根文件系统为 RISC-V 64 Ubuntu 22.04 LTS 1 主机…...
怎么样?)
腾讯云轻量应用服务器(Lighthouse)怎么样?
轻量应用服务器是否好用,小白这么多年的经验来看,跑企业站或博客都没问题,因为小流量站是可以的。但是限制流量的服务器只适合小站。超流量后是要扣费的。简而言之,超过流量是按流量计费的。如果被攻击大概率会欠费。如果是企业用…...

学习 AI 常用的一些专业词汇
学习 AI 常用的一些专业词汇 AI 词汇集 AI 词汇集 神经网络(Neural Network): 由节点(模型参数)和连接(权重)组成的网络结构,用于机器学习与深度学习。 深度学习(Deep Learning): 使用包含多隐藏层神经网络进行表征学习的机器学习方法。 机器学习(Machine Learnin…...

IP协议基础
文章目录 基本概念IP和TCP分别解决什么问题 以下过程都是在网络层完成的网段划分路由路由转发过程路由表 基本概念 主机: 配有IP地址, 但是不进行路由控制的设备。 路由器: 即配有IP地址, 又能进行路由控制。 节点: 主机和路由器的统称。 IP和TCP分别解决什么问题 TCP解决…...

Redis主从复制、哨兵实战
环境:linux centos7.x ,虚拟机3台 版本:redis-6.2.6 1.下载安转redis 下载地址 wget https://download.redis.io/releases/redis-6.2.6.tar.gz解压 tar -zxvf redis-6.2.6.tar.gz移动目录 mv redis-6.2.6 /usr/local/redis编译 cd /usr/…...

README.md编写
一、摘要 项目一般会有个描述文件,对于项目的代码来讲,这个描述就是README.md文件,可以描述各模块功能、目录结构等。该文件可以方便让人快速了解项目的代码结构和功能。当然,若要深层次的了解项目,就得看项目总体的需…...

软件设计证书倒计时28天
从一个月前的果断报考软件设计证书,我没有后悔过。 软件设计证书一个月备考情况: 现在做选择题的正确率可以达到65%。是重复做过两遍历年真题。 接下来是继续做模拟题。 大题的题型基本是都知道, 第一题数据流图,第二题er图&…...

程序员基础的硬件知识(cpu、主板、显卡、内存条等)
一、综合简介 cpu:负责运算数据,就等于你的大脑运算速度。 显卡:本来没有显卡,后来因为大家对图片要求越来越高,视频要求越来越高,啥都让cpu算太累了,于是分出来一个,专门用来计算…...
优化Google Cloud Storage大文件上传和内存溢出
背景 我们的项目每天都会并行上传好几万份文件到下游的GCP Cloud Storage,当文件比较大时,会采用GCP的可续上传方案,通过把文件切分成多个数据块,分多次HTTP请求上传到GCP Bucket,具体可参考https://cloud.google.com…...

chatGPT的prompt技巧
Prompt 公式是 Prompt 的特定格式,通常由三个主要元素组成: 任务:明确而简洁地陈述 Prompt 要求模型生成的内容。指令:模型在生成文本时应遵循的指令。角色:模型在生成文本时应扮演的角色。 指令 Prompt 技术 指令 …...
)
【华为OD机试 2023最新 】统一限载货物数最小值(C语言题解 100%)
文章目录 题目描述输入描述输出描述备注用例题目解析代码思路C语言题目描述 火车站附近的货物中转站负责将到站货物运往仓库,小明在中转站负责调度2K辆中转车(K辆干货中转车,K辆湿货中转车)。 货物由不同供货商从各地发来,各地的货物是依次进站,然后小明按照卸货顺序依…...

ios 在windows chrome 联调
必要条件 1、iOS设备、数据线 2、Node.js 环境 3、Chrome 浏览器 4、电脑登录iTunes 5、手机 Safari 浏览器环境准备 1、安装Node环境参考Node安装的教程,确保终端输入node时可正常使用 2、安装 scoope 以及相关配置为了安装后续需要用的工具 remotedebug-ios-web…...

干翻Mybatis源码系列之第六篇:Mybatis可选缓存概述
前言 一:后续Mybatis我们会研究那些内容? Mybatis核心运行源码分析(前面系列文章已经探讨过) Mybatis中缓存的使用 Mybatis与Spring集成 Mybatis 插件。 Mybatis的插件可以对Mybatis内核功能或者是业务功能进行拓展,…...

如何调教ChatGPT
调教ChatGPT需要进行以下步骤: 收集语料库 首先需要准备一定量的自然语言数据,这些数据可以是文本、对话、新闻等。语料库越大,模型效果通常会越好。 数据预处理 对于收集到的原始语料库需要进行一定的预处理操作,比如去除噪声…...
记一次我的漏洞挖掘实战——某公司的SQL注入漏洞
目录 一、前言 二、挖掘过程 1.谷歌语法随机搜索 2.进入网站 3.注入点检测 3.SQLMAP爆破 (1)爆库 (2)爆表 (3)爆字段 三、总结 一、前言 我是在漏洞盒子上提交的漏洞,上面有一个项目叫…...

代码随想录二刷复习 day1 704二分查找 27 移除元素 977 有序数组的平方
代码如下 func search(nums []int, target int) int { left : 0 right : len(nums)-1 for left < right { middle : (leftright)/2 if target < nums[middle] { //因为上面的判断条件是left < right,所以左右两个边界的值最后都能取到,而此…...

第16章 指令级并行与超标量处理器
处理器体系结构的超标量实现是指常见指令--整数与浮点算术、加载存储和条件分支--可以同时启动,但独立执行。 16.1 概述 超标量方法的本质是能在不同的流水线中独立地并发地执行指令。 在传统的标量组织结构中,其并行性是通过允许许多指令在同一时间处…...

JavaWeb ( 三 ) Web Server 服务器
1.5.Web Server服务器 Web Server 服务器是一种安装在服务器主机上的应用程序, 用于处理客户端(Web浏览器)的请求,并返回响应内容。服务器使用HTTP(超文本传输协议)与客户机浏览器进行信息交流。 简单说就是将http协议的信息翻译成对应开发语言可以处理的对象信息。…...

从内核到应用层:全面解析安卓系统中dmesg和logcat的工作原理与区别
从内核到应用层:全面解析安卓系统中dmesg和logcat的工作原理与区别 在安卓系统开发与调试过程中,日志工具如同开发者的"听诊器",能够精准定位系统运行时的各类问题。对于需要深入系统底层或优化应用性能的开发者而言,掌…...

开源可部署!实时手机检测-通用镜像免配置环境搭建完整指南
开源可部署!实时手机检测-通用镜像免配置环境搭建完整指南 1. 项目简介:一个专为手机检测而生的AI工具 如果你正在寻找一个能快速识别图片中手机的AI工具,并且希望它开箱即用、部署简单,那么你来对地方了。今天要介绍的这个“实…...
)
从DWG到浏览器:揭秘CAD文件网页预览的完整技术链路(VisualizeJS深度解析)
从DWG到浏览器:揭秘CAD文件网页预览的完整技术链路(VisualizeJS深度解析) 在工业设计、建筑规划和机械制造领域,DWG文件作为CAD设计的标准格式,其在线协作需求正以每年37%的速度增长。传统桌面端CAD软件正面临云端转型…...

SpringCloud OpenFeign Content-Length透传陷阱与RequestInterceptor精准拦截方案
1. 当OpenFeign遇上"too many bytes written"异常 最近在重构微服务项目时,我遇到了一个让人头疼的问题:使用OpenFeign进行服务间调用时,时不时会抛出"too many bytes written"的IO异常。刚开始以为是网络问题࿰…...

EcomGPT-7B多语言能力实测:中→英→泰→越四级商品信息流转效果展示
EcomGPT-7B多语言能力实测:中→英→泰→越四级商品信息流转效果展示 1. 项目背景与测试目标 EcomGPT-7B是阿里巴巴IIC实验室专门为电商场景打造的多语言大模型,支持中文、英文、泰语、越南语等多种语言。这个模型特别针对电商领域的特殊需求进行了优化…...

2026智能体技术入门指南:轻松掌握大模型驱动下的工业变革,速收藏!
2025年被称为“智能体元年”,智能体技术凭借其自主性、反应性和社交能力,在工业领域展现出巨大潜力。本文介绍了基于大模型的智能体是什么,以及其在工业场景中的应用,特别是在数据治理和智慧运维方面的革新。智能体通过规划、记忆…...

一次试样失败催生的技术革新:福尔蒂吹瓶专用ACR助剂逆向推演与流变拟合
那年夏天,一家饮料包装厂在调试新产线时遇到个棘手问题:吹瓶过程中频繁出现壁厚不均、肩部发白、甚至局部开裂——同一套模具、同一批PET切片、连温控参数都没动,就是反复试样失败。技术人员查了一周,最后把样本寄到了青岛福尔蒂新…...
零基础入门到精通,收藏这一篇就够了)
IT从业人员能做哪些兼职-总有一款适合你(非常详细)零基础入门到精通,收藏这一篇就够了
作为IT从业者,在闲暇时间可以尝试以下一些兼职: 1. 程序员兼职:在各大IT招聘网站上,有很多针对IT从业者的兼职职位,可以根据自己的技能和时间情况选择相应的岗位,如开发小程序、网站等。 2. IT培训师&…...

终极Mold调试指南:解决链接器问题的7个实用技巧
终极Mold调试指南:解决链接器问题的7个实用技巧 【免费下载链接】mold Mold: A Modern Linker 🦠 项目地址: https://gitcode.com/GitHub_Trending/mo/mold Mold作为一款现代链接器,以其卓越的速度显著提升了开发效率,尤其…...

如何确保Fay数字人框架数据一致性:事务管理终极指南
如何确保Fay数字人框架数据一致性:事务管理终极指南 【免费下载链接】Fay Fay 是一个开源的数字人类框架,集成了语言模型和数字字符。它为各种应用程序提供零售、助手和代理版本,如虚拟购物指南、广播公司、助理、服务员、教师以及基于语音或…...