深入理解SeaTunnel:易用、高性能、支持实时流式和离线批处理的海量数据集成平台
深入理解SeaTunnel:易用、高性能、支持实时流式和离线批处理的海量数据集成平台
- 一、认识SeaTunnel
- 二、SeaTunnel 系统架构、工作流程与特性
- 三、SeaTunnel工作架构
- 四、部署SeaTunnel
- 1.安装Java
- 2.下载SeaTunnel
- 3.安装连接器
- 五、快速启动作业
- 1.添加作业配置文件以定义
- 2.运行 SeaTunnel
- 六、SeaTunnel集成flink
- 1.部署和配置Flink
- 2.添加作业配置文件以定义
- 3.运行SeaTunnel
- 七、SeaTunnel集成Spark
- 1.部署和配置Spark
- 2.添加作业配置文件以定义
- 3.运行SeaTunnel
- 八、运行命令
一、认识SeaTunnel
- SeaTunnel 是一个非常易用、高性能、支持实时流式和离线批处理的海量数据集成平台,架构于 Apache Spark 和 Apache Flink 之上,支持海量数据的实时同步与转换。
SeaTunnel专注于数据集成和数据同步,主要解决数据集成领域的常见问题:
- 数据源多样:常用的数据源有数百种,版本不兼容。随着新技术的出现,出现了更多的数据源。用户很难找到能够全面快速支持这些数据源的工具。
- 复杂同步场景:数据同步需要支持离线-全量同步、离线-增量同步、CDC、实时同步、全库同步等多种同步场景。
- 资源需求高:现有的数据集成和数据同步工具往往需要大量的计算资源或JDBC连接资源来完成海量小表的实时同步。这在一定程度上加重了企业的负担。
- 缺乏质量和监控:数据集成和同步过程经常会丢失或重复数据。同步过程缺乏监控,无法直观了解任务过程中数据的真实情况。
- 技术栈复杂:企业使用的技术组件各不相同,用户需要针对不同的组件开发相应的同步程序来完成数据集成。
- 管理维护困难:受限于不同的底层技术组件(Flink/Spark),离线同步和实时同步往往是分开开发和管理的,增加了管理和维护的难度。
二、SeaTunnel 系统架构、工作流程与特性
SeaTunnel 系统架构图:
- Input/Source[数据源输入] -> Filter/Transform[数据处理] -> Output/Sink[结果输出]

上图为 SeaTunnel 的整个工作流程,数据处理流水线由多个过滤器构成,以满足多种数据处理需求。如果用户习惯了 SQL,也可以直接使用 SQL 构建数据处理管道,更加简单高效。目前,SeaTunnel 支持的过滤器列表也在扩展中。
SeaTunnel的特点:
- 丰富且可扩展的Connector:SeaTunnel提供了不依赖于特定执行引擎的Connector API。基于此API开发的连接器(Source、Transform、Sink)可以运行在很多不同的引擎上,比如目前支持的SeaTunnel Engine、Flink、Spark。
- Connector插件:插件式的设计让用户可以很方便的开发自己的Connector,并集成到SeaTunnel项目中。目前,SeaTunnel 已支持 100 多个 Connector,而且数量还在激增。
- 批流融合:基于SeaTunnel Connector API开发的Connector,完美兼容离线同步、实时同步、全量同步、增量同步等场景。大大降低了管理数据集成任务的难度。
- 支持分布式快照算法,保证数据一致性。
- 多引擎支持:SeaTunnel默认使用SeaTunnel Engine进行数据同步。同时,SeaTunnel也支持使用Flink或Spark作为Connector的执行引擎,以适配企业现有的技术组件。SeaTunnel 支持多个版本的 Spark 和 Flink。
- JDBC多路复用,数据库日志多表解析:SeaTunnel支持多表或全库同步,解决了JDBC连接过多的问题;支持多表或全库日志读取和解析,解决了CDC多表同步场景需要重复读取和解析日志的问题。
- 高吞吐低延迟:SeaTunnel支持并行读写,提供高吞吐低延迟稳定可靠的数据同步能力。
- 完善的实时监控:SeaTunnel支持数据同步过程中每一步的详细监控信息,让用户轻松了解同步任务读写的数据量、数据大小、QPS等信息。
- 支持两种作业开发方式:编码和画布设计:提供了作业的可视化管理、调度、运行和监控能力。
三、SeaTunnel工作架构
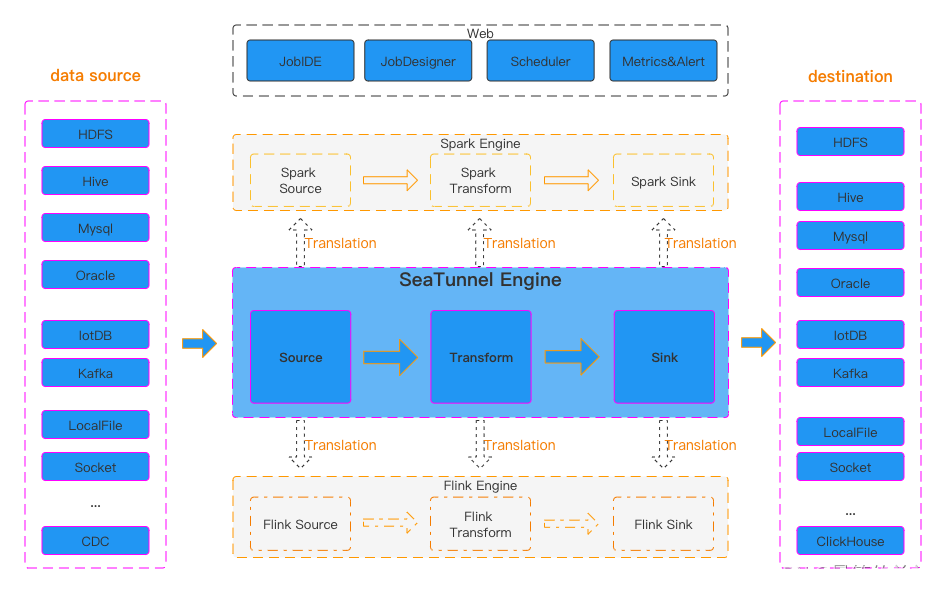
SeaTunnel的运行过程如上图所示。
- 用户配置作业信息,选择执行引擎提交作业。
- Source Connector负责并行读取数据并将数据发送给下游Transform或直接发送给Sink,Sink将数据写入目的地。值得注意的是,无论是Source还是Transform和Sink,都可以很方便的自行开发扩展。
- SeaTunnel 是一个 EL(T) 数据集成平台。因此,在SeaTunnel中,Transform只能用于对数据进行一些简单的转换,例如将某列的数据转换为大写或小写,更改列名,或者将一列拆分为多列。
- SeaTunnel 使用的默认引擎是SeaTunnel Engine。如果您选择使用Flink或Spark引擎,SeaTunnel会将Connector打包成Flink或Spark程序提交给Flink或Spark运行。
- Source Connectors SeaTunnel 支持从各种关系数据库、图形数据库、NoSQL 数据库、文档数据库和内存数据库中读取数据。HDFS等各种分布式文件系统。S3、OSS等多种云存储。同时我们也支持很多常见的SaaS服务的数据读取。
- 转换连接器如果源和接收器之间的架构不同,您可以使用转换连接器更改从源读取的架构,使其与接收器架构相同。
- Sink Connector SeaTunnel 支持向各种关系数据库、图数据库、NoSQL 数据库、文档数据库和内存数据库写入数据。HDFS等各种分布式文件系统。S3、OSS等多种云存储。同时我们也支持向很多常见的SaaS服务写入数据。
四、部署SeaTunnel
1.安装Java
- 安装Java8以上版本
2.下载SeaTunnel
export version="2.3.1"
wget "https://archive.apache.org/dist/incubator/seatunnel/${version}/apache-seatunnel-incubating-${version}-bin.tar.gz"
tar -xzvf "apache-seatunnel-incubating-${version}-bin.tar.gz"
3.安装连接器
从2.2.0-beta开始,二进制包默认不提供connector依赖,所以第一次使用时,我们需要执行如下命令安装connector:(当然你也可以手动下载connector从https://repo.maven.apache.org/maven2/org/apache/seatunnel/下载,然后手动移动到connectors/seatunnel目录)。
sh bin/install-plugin.sh 2.3.1
如果需要指定connector的版本,以2.3.0-beta为例,我们需要执行
sh bin/install-plugin.sh 2.3.1
通常你不需要所有的连接器插件,所以你可以通过配置指定你需要的插件config/plugin_config,比如你只需要connector-console插件,那么你可以修改plugin_config为
--connectors-v2--
connector-console
--end--
如果你想让示例应用程序正常工作,你需要添加以下插件
--connectors-v2--
connector-fake
connector-console
--end--
您可以在${SEATUNNEL_HOME}/connectors/plugins-mapping.properties下找到所有支持的连接器和相应的 plugin_config 配置名称。
提示:
如果想通过手动下载connector的方式安装connector插件,需要特别注意以下几点
connectors目录包含以下子目录,如果不存在,需要手动创建
seatunnel
如果想手动安装V2 connector插件,只需要下载自己需要的V2 connector插件,放到seatunnel目录下即可
五、快速启动作业
1.添加作业配置文件以定义
编辑config/v2.batch.config.template,决定了seatunnel启动后数据输入、处理、输出的方式和逻辑。下面是一个配置文件的例子,和上面提到的例子应用是一样的。
env {execution.parallelism = 1job.mode = "BATCH"
}source {FakeSource {result_table_name = "fake"row.num = 16schema = {fields {name = "string"age = "int"}}}
}sink {Console {}
}
2.运行 SeaTunnel
可以通过以下命令启动应用程序
cd "apache-seatunnel-incubating-${version}"
./bin/seatunnel.sh --config ./config/v2.batch.config.template -e local
查看输出:运行命令时,您可以在控制台中看到它的输出。您可以认为这是命令运行成功与否的标志。
SeaTunnel 控制台会打印一些日志如下:
2022-12-19 11:01:45,417 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - output rowType: name<STRING>, age<INT>
2022-12-19 11:01:46,489 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=1: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: CpiOd, 8520946
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=2: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: eQqTs, 1256802974
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=3: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: UsRgO, 2053193072
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=4: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: jDQJj, 1993016602
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=5: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: rqdKp, 1392682764
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=6: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: wCoWN, 986999925
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=7: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: qomTU, 72775247
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=8: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: jcqXR, 1074529204
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=9: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: AkWIO, 1961723427
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=10: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: hBoib, 929089763
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=11: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: GSvzm, 827085798
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=12: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: NNAYI, 94307133
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=13: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: EexFl, 1823689599
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=14: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: CBXUb, 869582787
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=15: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: Wbxtm, 1469371353
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=16: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: mIJDt, 995616438
六、SeaTunnel集成flink
1.部署和配置Flink
下载Flink,Flink版本要求>=1.12.0
配置 SeaTunnel:更改设置config/seatunnel-env.sh,它基于您的引擎在部署时安装的路径。更改FLINK_HOME为 Flink 部署目录。
2.添加作业配置文件以定义
编辑config/v2.streaming.conf.template,决定了seatunnel启动后数据输入、处理、输出的方式和逻辑。下面是一个配置文件的例子,和上面提到的例子应用是一样的。
env {execution.parallelism = 1job.mode = "BATCH"
}source {FakeSource {result_table_name = "fake"row.num = 16schema = {fields {name = "string"age = "int"}}}
}sink {Console {}
}
3.运行SeaTunnel
flink1.12.x和flink1.14.x
cd "apache-seatunnel-incubating-${version}"
./bin/start-seatunnel-flink-13-connector-v2.sh --config ./config/v2.streaming.conf.template
flink1.15.x和flink1.16.x
cd "apache-seatunnel-incubating-${version}"
./bin/start-seatunnel-flink-15-connector-v2.sh --config ./config/v2.streaming.conf.template
查看输出:运行命令时,您可以在控制台中看到它的输出。您可以认为这是命令运行成功与否的标志。
SeaTunnel 控制台会打印一些日志如下:
2022-12-19 11:01:45,417 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - output rowType: name<STRING>, age<INT>
2022-12-19 11:01:46,489 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=1: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: CpiOd, 8520946
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=2: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: eQqTs, 1256802974
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=3: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: UsRgO, 2053193072
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=4: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: jDQJj, 1993016602
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=5: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: rqdKp, 1392682764
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=6: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: wCoWN, 986999925
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=7: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: qomTU, 72775247
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=8: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: jcqXR, 1074529204
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=9: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: AkWIO, 1961723427
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=10: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: hBoib, 929089763
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=11: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: GSvzm, 827085798
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=12: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: NNAYI, 94307133
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=13: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: EexFl, 1823689599
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=14: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: CBXUb, 869582787
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=15: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: Wbxtm, 1469371353
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=16: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: mIJDt, 995616438
七、SeaTunnel集成Spark
1.部署和配置Spark
下载Spark(要求版本>=2.4.0)
配置 SeaTunnel:更改设置config/seatunnel-env.sh,它基于您的引擎在部署时安装的路径。更改SPARK_HOME为 Spark 部署目录。
2.添加作业配置文件以定义
编辑config/seatunnel.streaming.conf.template,决定了seatunnel启动后数据输入、处理、输出的方式和逻辑。下面是一个配置文件的例子,和上面提到的例子应用是一样的。
env {execution.parallelism = 1job.mode = "BATCH"
}source {FakeSource {result_table_name = "fake"row.num = 16schema = {fields {name = "string"age = "int"}}}
}sink {Console {}
}3.运行SeaTunnel
可以通过以下命令启动应用程序
Spark2.4.x
cd "apache-seatunnel-incubating-${version}"
./bin/start-seatunnel-spark-2-connector-v2.sh \
--master local[4] \
--deploy-mode client \
--config ./config/seatunnel.streaming.conf.template
spark3.xx
cd "apache-seatunnel-incubating-${version}"
./bin/start-seatunnel-spark-3-connector-v2.sh \
--master local[4] \
--deploy-mode client \
--config ./config/seatunnel.streaming.conf.template
查看输出:运行命令时,您可以在控制台中看到它的输出。您可以认为这是命令运行成功与否的标志。
SeaTunnel 控制台会打印一些日志如下:
fields : name, age
types : STRING, INT
row=1 : elWaB, 1984352560
row=2 : uAtnp, 762961563
row=3 : TQEIB, 2042675010
row=4 : DcFjo, 593971283
row=5 : SenEb, 2099913608
row=6 : DHjkg, 1928005856
row=7 : eScCM, 526029657
row=8 : sgOeE, 600878991
row=9 : gwdvw, 1951126920
row=10 : nSiKE, 488708928
row=11 : xubpl, 1420202810
row=12 : rHZqb, 331185742
row=13 : rciGD, 1112878259
row=14 : qLhdI, 1457046294
row=15 : ZTkRx, 1240668386
row=16 : SGZCr, 94186144
八、运行命令
Spark2:
bin/start-seatunnel-spark-2-connector-v2.sh --config config/v2.batch.config.template -m local -e client
Spark3:
bin/start-seatunnel-spark-3-connector-v2.sh --config config/v2.batch.config.template -m local -e client
Flink13和Flink14:
bin/start-seatunnel-flink-13-connector-v2.sh --config config/v2.batch.config.template
Flink15和Flink16:
bin/start-seatunnel-flink-15-connector-v2.sh --config config/v2.batch.config.template
相关文章:
深入理解SeaTunnel:易用、高性能、支持实时流式和离线批处理的海量数据集成平台
深入理解SeaTunnel:易用、高性能、支持实时流式和离线批处理的海量数据集成平台 一、认识SeaTunnel二、SeaTunnel 系统架构、工作流程与特性三、SeaTunnel工作架构四、部署SeaTunnel1.安装Java2.下载SeaTunnel3.安装连接器 五、快速启动作业1.添加作业配置文件以定义…...

项目上线 | 兰精携手盖雅工场,数智驱动绿色转型
近年来,纺织纤维行业零碳行动如火如荼。作为低碳环保消费新时尚引领者,同时也是纤维领域隐形冠军,兰精在推进绿色发展的同时,也在不断向内探索企业数字化转型之道,以此反哺业务快速扩张。 数智转型,管理先…...
102-Linux_I/O复用方法之poll
文章目录 1.poll系统调用的作用2.poll的原型3.poll支持的事件类型4.poll实现TCP服务器(1)服务器端代码:(2)客户端代码:(3)运行结果截图: 1.poll系统调用的作用 poll 系统调用和 select 类似,也是在指定时间内轮询一定数量的文件描述符,以测试其中是否有…...
【VAR模型 | 时间序列】帮助文档:VAR模型的引入和Python实践(含源代码)
向量自回归 (VAR) 是一种随机过程模型,用于捕获多个时间序列之间的线性相互依赖性。 VAR 模型通过允许多个进化变量来概括单变量自回归模型(AR 模型)。 VAR 中的所有变量都以相同的方式进入模型:每个变量都有一个方程式ÿ…...
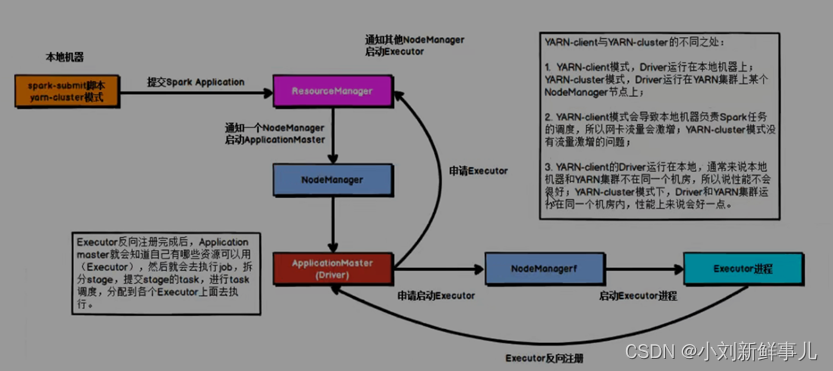
Spark任务提交流程
1. yarn-client Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯,申请启动ApplicationMaster; 随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的…...
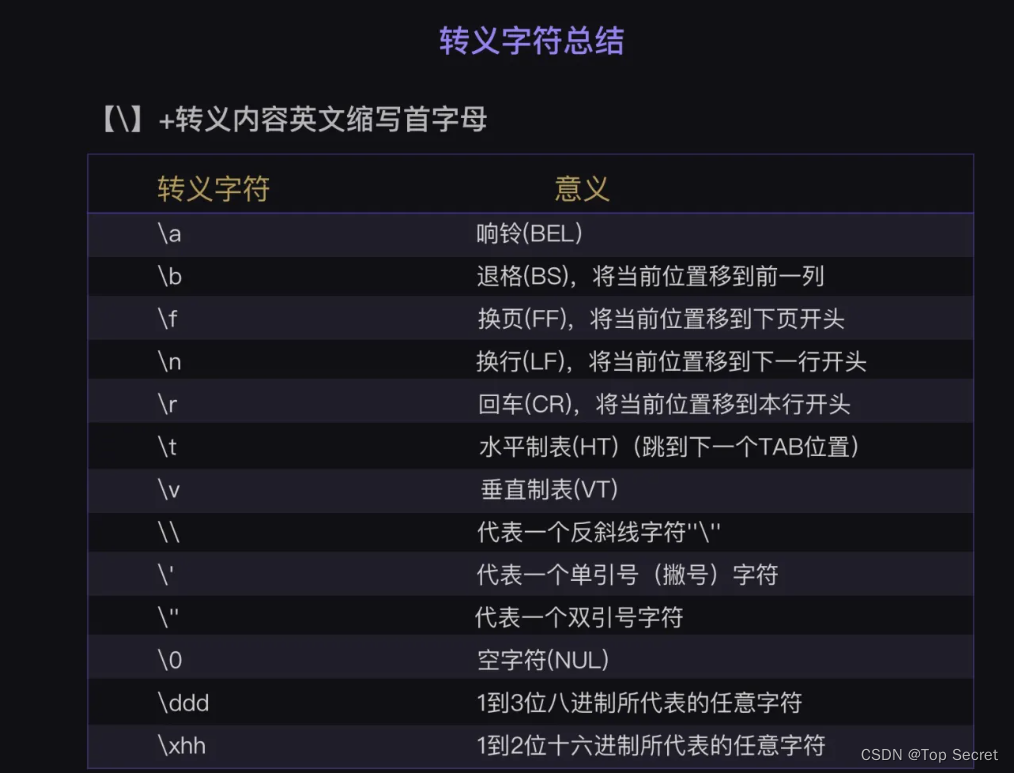
python相对路径与绝对路径
9.1 Python 绝对路径与相对路径 - 知乎 (zhihu.com) 目录 1. 绝对路径 1.1 概念 1.2 用绝对路径打开文件 1.2 相对路径 1.3 python路径表示的斜杠问题 1. 绝对路径 1.1 概念 绝对路径 指完整的描述文件位置的路径。绝对路径就是文件或文件夹在硬盘上的完整路径。 在 Win…...
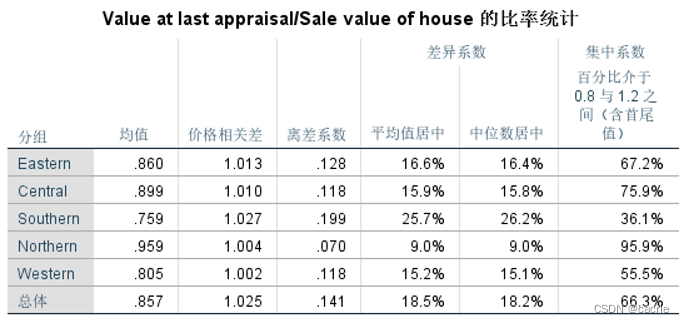
SPSS如何进行基本统计分析之案例实训?
文章目录 0.引言1.描述性分析2.频数分析3.探索分析4.列联表分析5.比率分析 0.引言 因科研等多场景需要进行数据统计分析,笔者对SPSS进行了学习,本文通过《SPSS统计分析从入门到精通》及其配套素材结合网上相关资料进行学习笔记总结,本文对基本…...
)
Python项目实战篇——常用验证码标注和识别(需求分析和实现思路)
前言:验证码识别和标注是现在网络安全中的一个重要任务,尤其是在一些电商平台和在线支付等场景中,验证码的安全性至关重要。本文将介绍如何使用Python实现常用的验证码标注和识别,以便为自己的项目提供参考。 一、需求分析 1、验证…...
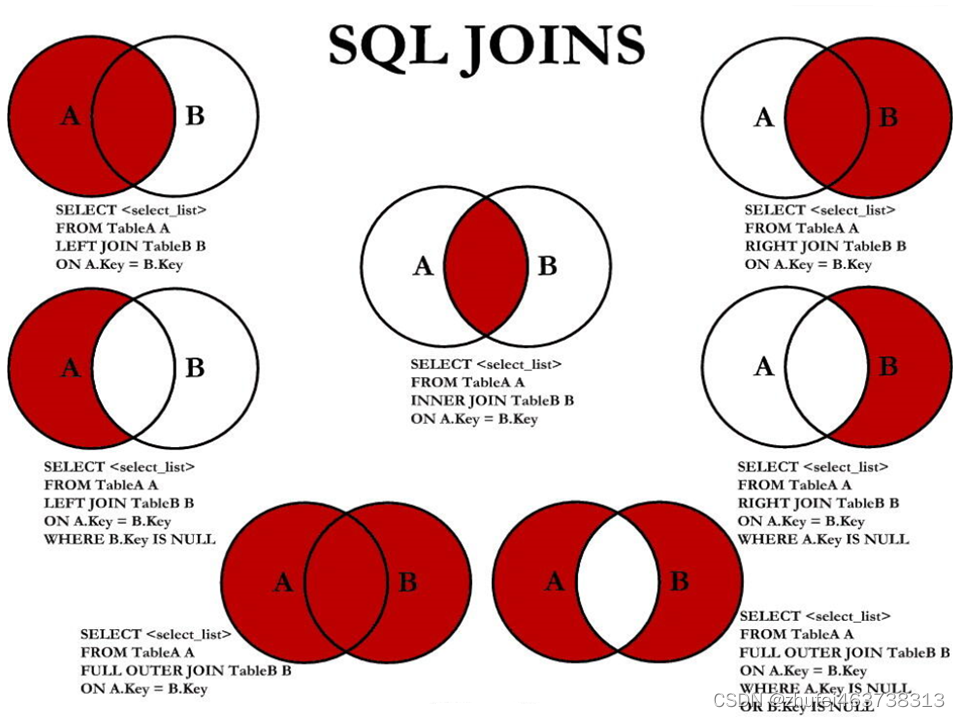
MySQL基础(六)多表查询
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。 前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,这个关联字段可能建立了外键,…...
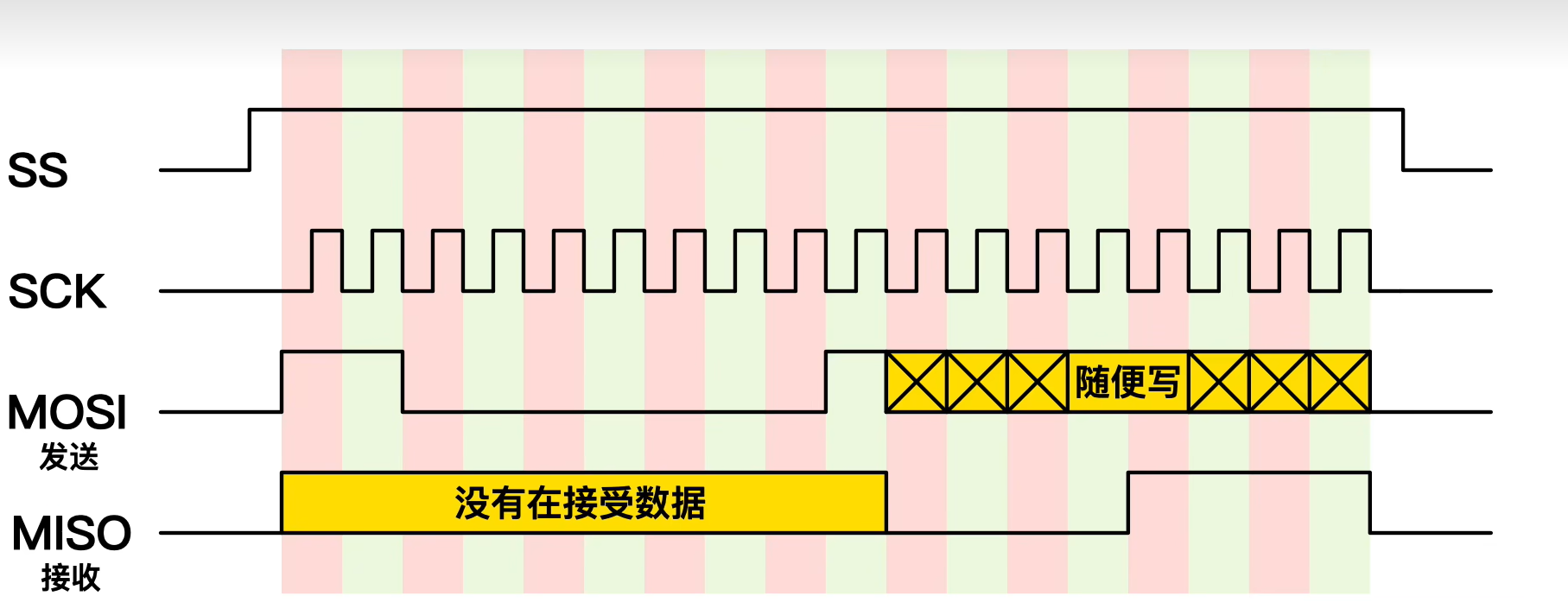
零死角玩转stm32中级篇3-SPI总线
本篇博文目录: 一.基础知识1.什么是SPI2.SPI和IIC有什么不同3.SPI的优缺点4.SPI是怎么实现通信的5.SPI 数据传输的步骤6.SPI菊花链7.通过SPI实现数据的读和写 二.STM32F103C8T6芯片SPI协议案例代码 一.基础知识 1.什么是SPI SPI(Serial Peripheral Interface&#…...
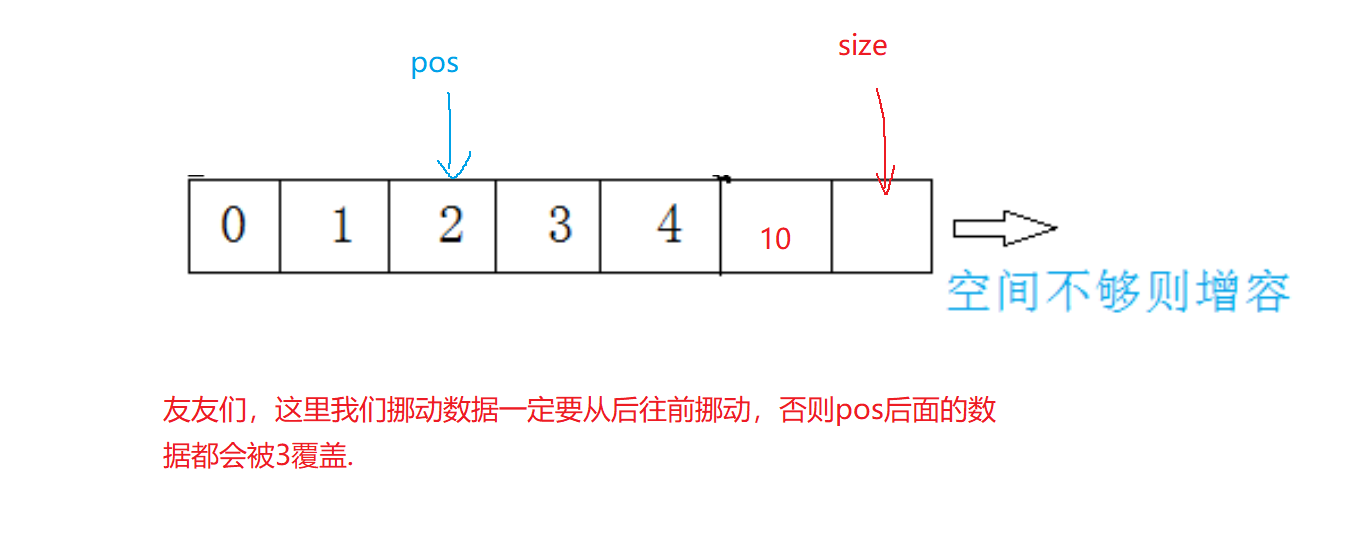
顺序表功能实现(入手版详解)
🍉博客主页:阿博历练记 📖文章专栏:数据结构与算法 🚚代码仓库:阿博编程日记 🌹欢迎关注:欢迎友友们点赞收藏关注哦 文章目录 🍓前言✨顺序表🔍1.顺序表的整体…...
)
Java 中的线程是什么,如何创建和管理线程-下(十三)
书接上文 CompletableFuture CompletableFuture 是 Java 8 中新增的类,提供了更为强大的异步编程支持。它可以将多个异步任务组合成一个整体,并且可以处理异常情况。 例如,可以使用 CompletableFuture 来实现异步任务的串行执行࿱…...

为什么我的Windows 10 便签不支持更改字体?
Windows便签是一款常用的记录工具,可以帮助我们快速记录一些重要的信息。在使用Windows便签时,如果你想要更好地呈现你的信息,可以通过设置字体来达到这个效果。本文将介绍Windows便签字体设置的相关知识,希望对你有所帮助。 1、打…...
野火STM32电机系列(六)Cubemx配置ADC规则和注入通道
前文已经配置了GPIO、编码器 本节讲解CubeMXADC规则和注入通道 本文adc注入通道采用定时器触发,因此在上文定时器配置的基础上进行 常规信号(温度等)使用带DMA的常规通道连续采样 注入采样由定时器触发,采集电机三相电流&…...

预制菜,巨头们的新赛场
俗话说“民以食为天”,饮食对于大众的重要性自然是无需赘述。然而,随着生活节奏的加快,越来越多年轻人没有时间和精力去烹制菜肴,这也是外卖行业持续火热的重要原因之一。尽管如此,随着消费者健康意识的持续提升&#…...

英语语法第一章之英语语法综述
英语的任何句型基本都可以翻译成 什么怎么样 ,在这里什么就是我们常说的主语,而怎么样就是我们常说的谓语; 可能有些小伙伴会反问,不是主谓宾吗?别急等我慢慢讲解 在这里谓语也有很有多的不同的动作 可以独立完成的动作 句型&am…...
ChatGPT被淘汰了?Auto-GPT到底有多强
大家好,我是可夫小子,关注AIGC、读书和自媒体。解锁更多ChatGPT、AI绘画玩法。 说Auto-GPT淘汰了ChatGPT了,显然是营销文案里面的标题党。毕竟它还是基于ChatGPT的API,某种意义只是基于ChatGPT能力的应用。但最近,Auto…...
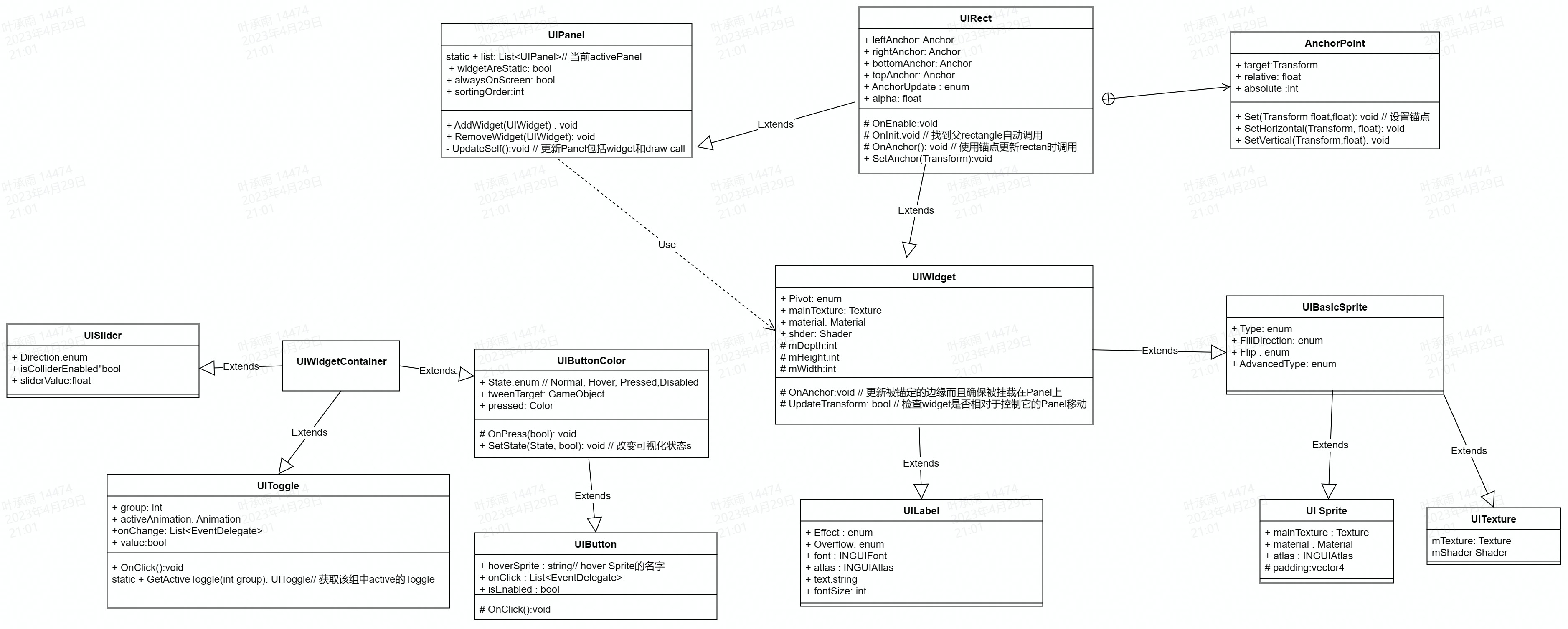
unity NGUI使用方法
基本用法 很多基本模块比如按钮、slider等都能从Prefab中直接拖拽到场景中实现,但都需要有一个Collider(Prefab已经自带) 因为不仅是UI,所有带有Collider的游戏物体都能接收到OnClick, OnPress这样的事件——前提是需…...
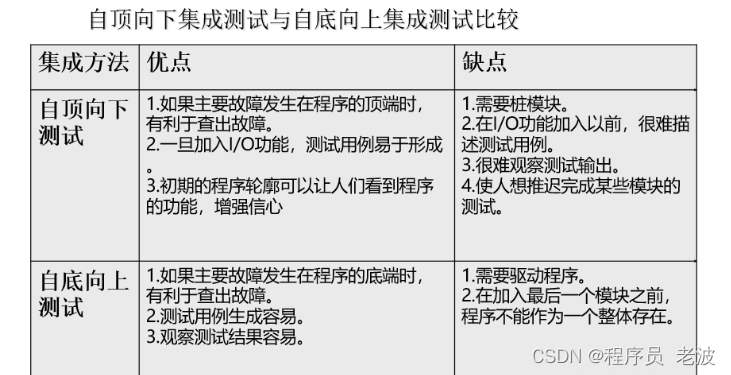
软件测试技术(五)软件测试流程
软件测试流程 软件测试流程如下: 测试计划测试设计测试执行 单元测试集成测试确认测试系统测试验收测试回归测试验证活动 测试计划 测试计划由测试负责人来编写,用于确定各个测试阶段的目标和策略。这个过程将输出测试计划,明确要完成的测…...

Redis缓存穿透和雪崩
Redis缓存穿透和雪崩 Redis缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面。但同时,它也带来了一些问题。其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...
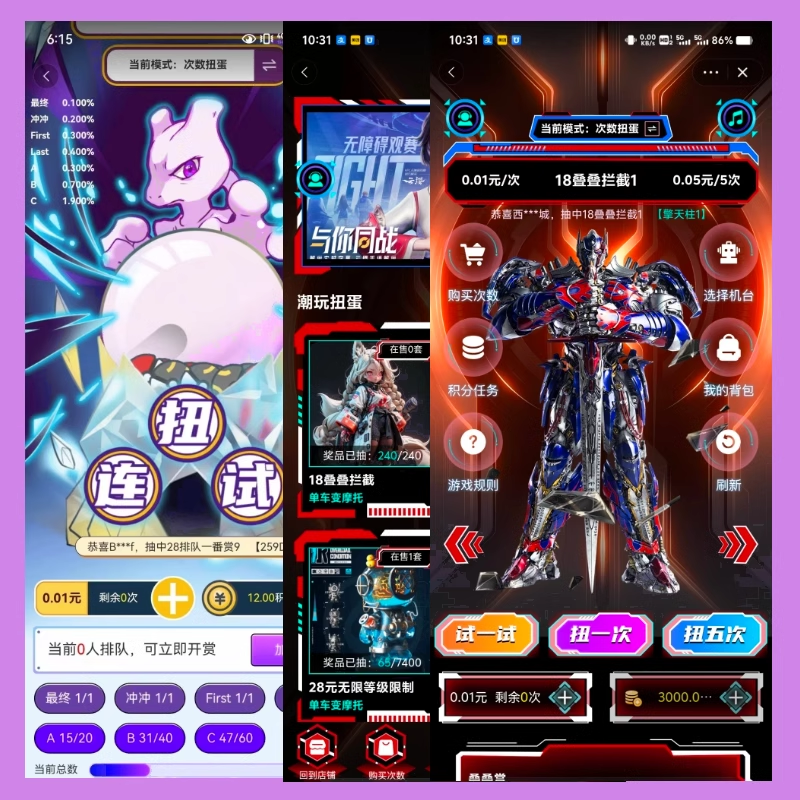
淘宝扭蛋机小程序系统开发:打造互动性强的购物平台
淘宝扭蛋机小程序系统的开发,旨在打造一个互动性强的购物平台,让用户在购物的同时,能够享受到更多的乐趣和惊喜。 淘宝扭蛋机小程序系统拥有丰富的互动功能。用户可以通过虚拟摇杆操作扭蛋机,实现旋转、抽拉等动作,增…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...