结巴分词原理分析
结巴分词器工作原理
结巴分词是一款python写成的开源中文分词器,分词过程大致如下:
首先,结巴使用正则表达式将输入文本切割成若干中文块,接着对每个中文块B做处理,将B转成有向无环图(DAG)。DAG是以{key:list[i,j...], ...}的字典结构存储,其中key是词在block中的起始位置,list存放的是block中以位置key开始的可能词语的结束位置。这里所谓的可能词语指的是词典里有的词,基本上所有的中文分词器都离不开词典。比如“特性开通”生成的DAG如下:
{0: [0, 1], 1: [1], 2: [2, 3], 3: [3]}
亦即:特、性、开、通、特性、开通这6个词在词典里都存在。
接下来,结巴会区分两种模式:全模式和精准模式。
全模式只是简单的遍历DAG(所以全模式速度是最快的),它找出所有可能的分词,比如“清华大学”,结巴会找出:
清华/ 清华大学/ 华大/ 大学
这是一个全集,因为这些词都是词典里已经存在的。
注意:全模式分词逻辑上并不一定是正确的,它依赖于词典的完备性,比如“话统计算”理应分词为:
话统/ 计算
但由于结巴自带的词典里没有收录“话统”这个词,全模式会把它分成:
话/ 统计/ 计算
这时我们需要手动把“话统”这个词加进词典,全模式才会分词为:
话统/ 统计/ 计算
精准模式则不是简单的遍历DAG,它采用动态规划查找最大概率路径, 找出基于词频的最大切分组合,基本思路就是对句子从右往左反向计算最大概率,最后得到最大概率路径,所以“清华大学”在精准模式下会分成:
清华/大学
下面是用动态规划计算最大概率路径的核心算法:
#动态规划,计算最大概率的切分组合def calc(self, sentence, DAG, route):N = len(sentence)route[N] = (0, 0)# 对概率值取对数之后的结果(可以让概率相除的计算变成对数相减,防止相除造成下溢)logtotal = log(self.total)# 从后往前遍历句子 反向计算最大概率for idx in xrange(N - 1, -1, -1):# 列表推导求最大概率对数路径# route[idx] = max([ (概率对数,词语末字位置) for x in DAG[idx] ])# 以idx:(概率对数最大值,词语末字位置)键值对形式保存在route中# route[x+1][0] 表示 词路径[x+1,N-1]的最大概率对数,# [x+1][0]即表示取句子x+1位置对应元组(概率对数,词语末字位置)的概率对数route[idx] = max((log(self.FREQ.get(sentence[idx:x + 1]) or 1) -logtotal + route[x + 1][0], x) for x in DAG[idx])
从代码中可以看出calc是一个自底向上的动态规划,它从block的最后一个字(N-1)开始倒序遍历block的每个字(位置为idx),计算子句block[idx~N-1]概率对数得分(这里利用DAG及历史计算结果实现,同时作者使用了概率对数,这样有效防止浮点数下溢问题)。然后将概率对数得分最高的情况以(概率对数,词语最后一个字的位置)这样的tuple保存在route中。这样,route已经把概率最大路径给标出来了(tuple[1]就是这条路径的中间节点)。
由上可知,由于精准模式额外使用了动态规划算法,效率肯定不及全模式高。
未登录词的处理
所谓未登录词,就是词典里没有收录的词,前面说过中文分词器离不开词典,那词典没这个词我又如何能把它识别出来呢?结巴使用的是基于隐马尔可夫模型(HMM)的Viterbi 算法。
HMM 模型有个五元组表示:
{ states,//状态空间 observations,//观察空间 start_probability,//状态的初始分布 transition_probability,//状态的转移概率emission_probability//状态产生观察的概率}其中,states(状态空间) 用B E M S四个状态来标记汉字在一个词中可能出现的位置,分别代表 Begin End Middle 和 Single, B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词。
observations(观察空间)就是所有汉字甚至包括标点符号所组成的集合。
由状态空间的元素组成的序列称为状态序列,类似的,观察空间的元素组成了观察序列。
在HMM模型中文分词中,观察序列是输入,就是待分词的句子,状态序列是输出,是这个句子中每个字的状态值。 如:
观察序列:我在北京 状态序列:SSBE
对于上面的状态序列,按简单的规则(例如:B后面只可能接M or E,不可能接B or S,而M后面也只可能接M or E,不可能接B or S)做划分即可得到分词方案,这里,状态序列要划分成 S/S/BE/ ,则最终的分词结果是:
我/ 在/ 北京/
现在,只剩下一个问题了:如何从观察序列中得到状态序列,这就要用到Viterbi 算法和那三个概率(初始、转移、发射概率),具体的实现算法可参看相关文章。
至于转移、发射概率的值是可以从语料库中训练得到的,对语料库中各种情况的出现次数做统计即可。
本质上,未登录词的识别是一个序列标注问题。
从词频到概率的转换
结巴词典里存的是词频,但分词的时候要计算多条分词路径的最大概率,所以这里有个“词频->概率”的转换过程,结巴会在生成前缀词典的时候用self.FREQ存储每个词的词频,用self.total记录总词频。相关代码为:
def gen_pfdict(self, f):lfreq = {}ltotal = 0f_name = resolve_filename(f)for lineno, line in enumerate(f, 1):try:line = line.strip().decode('utf-8')word, freq = line.split(' ')[:2]freq = int(freq)lfreq[word] = freqltotal += freqfor ch in xrange(len(word)):wfrag = word[:ch + 1]if wfrag not in lfreq:lfreq[wfrag] = 0except ValueError:raise ValueError('invalid dictionary entry in %s at Line %s: %s' % (f_name, lineno, line))f.close()return lfreq, ltotaldef initialize(self, dictionary=None):...self.FREQ, self.total = self.gen_pfdict(self.get_dict_file()) ...
概率的计算方法则是:
某个词的词频/总词频
见calc函数:
def calc(self, sentence, DAG, route):N = len(sentence)route[N] = (0, 0)logtotal = log(self.total)for idx in xrange(N - 1, -1, -1):route[idx] = max((log(self.FREQ.get(sentence[idx:x + 1]) or 1) -logtotal + route[x + 1][0], x) for x in DAG[idx])
注意这个部分:
(log(self.FREQ.get(sentence[idx:x + 1]) or 1) - logtotal
这里计算[idx,x]所组词的概率,实际是词频/总词频,因取了对数,所以变成了减法。
如何消除分词错误
jieba下,可通过添加新词、加大词频等方式解决分词错误。默认词频数一般是4,如果分不出来,可以加到10,甚至更大。
jieba的优点在于我们可以通过调整词频数这么一个很简单的方式就获得我们希望的分词效果,但这也是它的缺点,因为汉语分词的最大问题在于“切分歧义”,在不同的语境下,可以有不同的切分方法。例如:
这个标志牌是指示前进的方向该物品是指示例中的图片吗?
两句话里都有“是指示”,但前者应切分为“是/指示”,后者则应切分为“是指/示例”。
由于jieba核心词典没有收录“是指”这个词,所以我们加一条:
是指 100000 v
则第二句话划分没问题了:
该/ 物品/ 是指/ 示例/ 中/ 的/ 图片/ 吗
注意这里为了超过“指示”成词的概率,我们将“是指”的词频调的很高(也许过高了,实测调成10000即可,这里为了说明问题改成了10w),确保最大概率路径往“是指”倾斜。但这样写死概率的做法很不灵活,一旦有下面的情况:
这个标志牌是指明前进的方向
就会分词为:
这个/ 标志牌/ 是指/ 明/ 前进/ 的/ 方向
也就是说,写死的概率在保证语境A下分词成功的同时,有可能造成语境B分词错误!
究其原因,在于相邻词的概率不同,“指示”的词频大于“指明”,所以“是指示”划分没问题,“是指明”则划分的有问题了。
综上,只依靠设置单个词的词频是解决不了“切分歧义”问题的,因为它没考虑句子的上下文情境。所以,这是jieba分词的问题。
相关文章:

结巴分词原理分析
结巴分词器工作原理 结巴分词是一款python写成的开源中文分词器,分词过程大致如下: 首先,结巴使用正则表达式将输入文本切割成若干中文块,接着对每个中文块B做处理,将B转成有向无环图(DAG)。DAG是以{key:list[i,j...…...

JavaEE 第三-四周
计算机Z20-第3-4周作业 总分:100分 得分:74.2分 1 . 填空题 简单 5分 在web.xml文件中,<url-pattern>/xxxxServlet</url-pattern>中的第一个‘/’表示__________。 学生答案 当前web应用程序的根目录 2 . 填空题 简…...
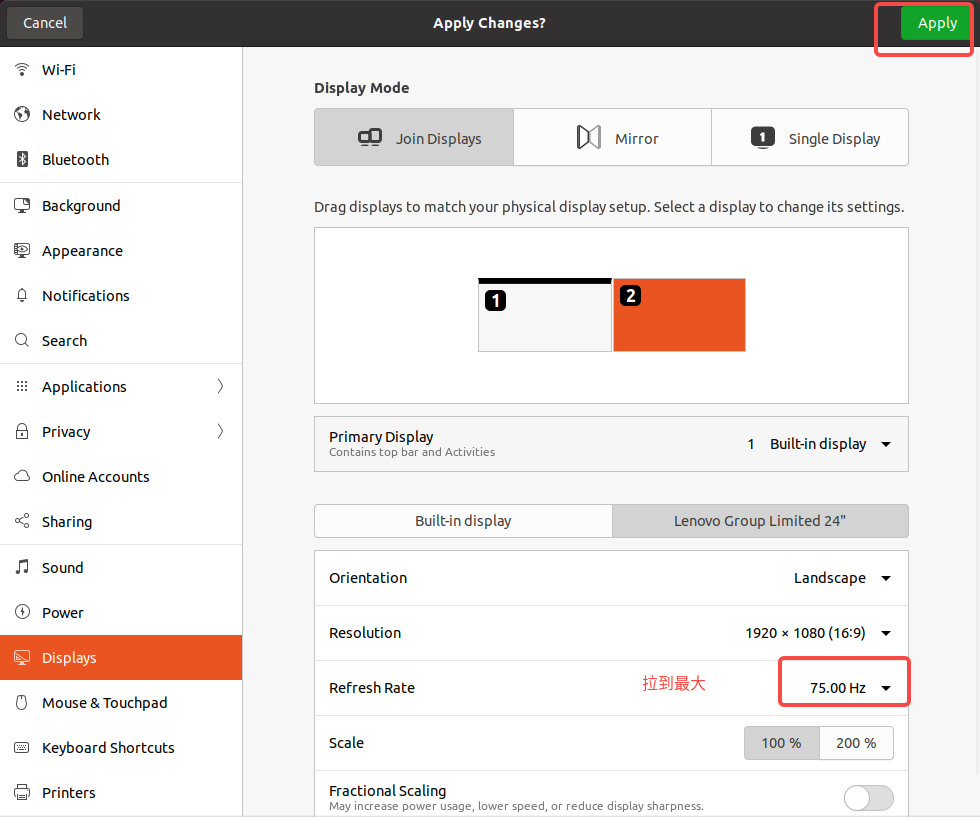
Ububtu20.04 无法连接外屏(显卡驱动问题导致)
Ububtu20.04 无法显示第二个屏幕(显卡驱动问题) Ububtu20.04 无法显示第二个屏幕(显卡驱动问题) Ububtu20.04 无法显示第二个屏幕(显卡驱动问题) 1. 问题描述2. 解决方案 1. 问题描述 一开始我的ububt…...
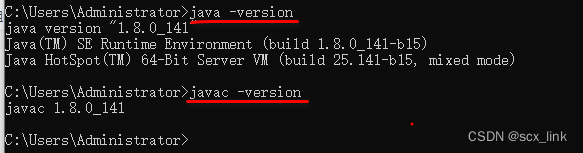
配置JDK环境变量
文章目录 查看电脑系统下载及安装JavaSE配置系统环境变量测试环境变量配置是否成功。 查看电脑系统 运行输入框中输入:control 下载及安装JavaSE 这个从网上下载就行,jdk-8u141-windows-x64.exe,不提供下载方式了。 主要讲解安装过程&a…...

保护移动设备免受恶意软件侵害优秀方法
几天前,移动恶意软件攻击增加了500%显然,我们大多数人都不知道不能很好地保护我们的手机下面小编揭秘有效保护移动设备免受恶意软件侵害的最佳方法。 1、使用移动反恶意软件 恶意软件很容易感染智能手机和平板电脑,因此在设备上安装可靠的…...
一个人在家怎么赚钱?普通人如何通过网络实现在家就能赚钱
近年来,随着互联网的飞速发展,嗅觉敏锐的人只要使用互联网就可以快乐地赚钱。一般来说,网上赚钱的投资较少,有时有一台能上网的电脑或手机就够了,所以大家有时称其为“无成本或低成本网赚”。今天就分享一个人在家如何…...
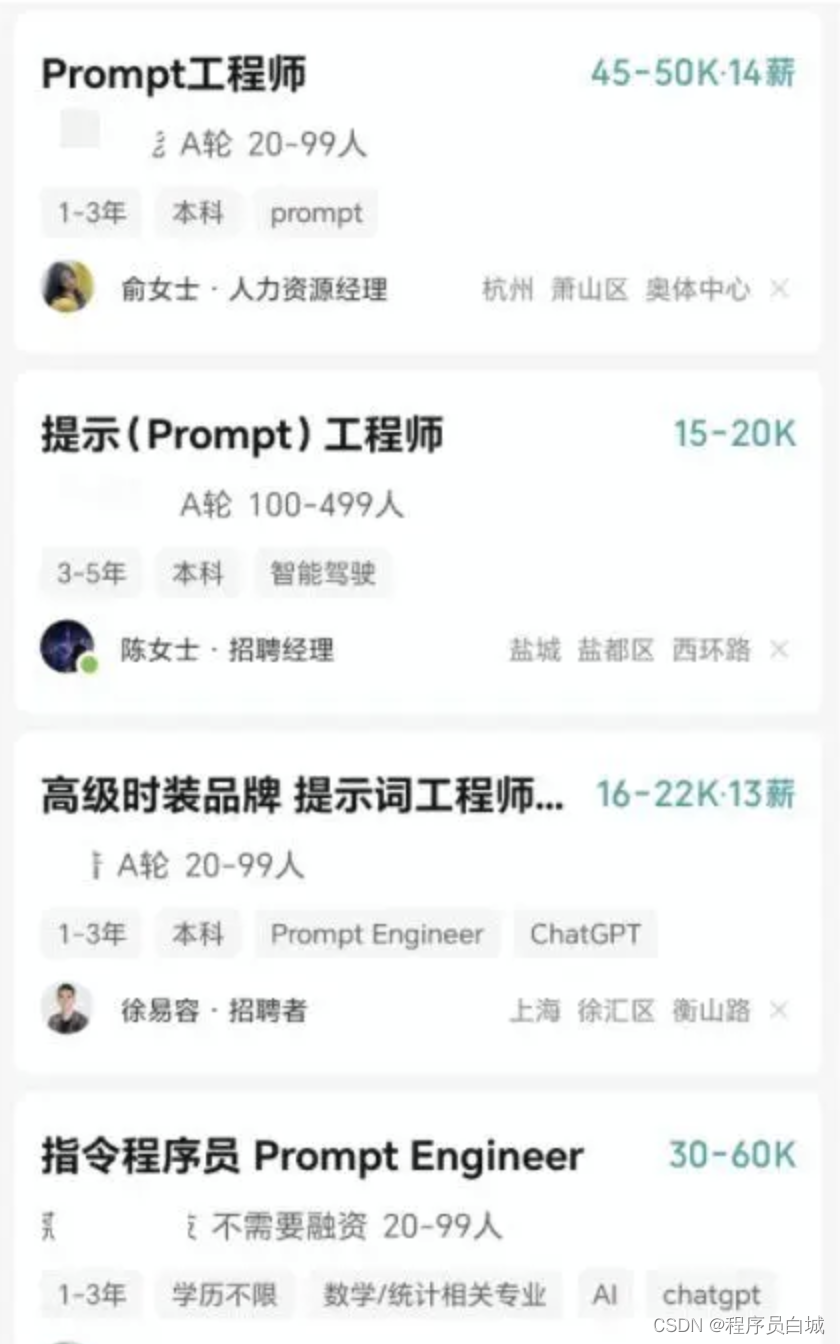
ChatGPT诞生的新岗位:提示工程师(Prompt Engineer)
ChatGPT诞生的新岗位:提示工程师(Prompt Engineer) Prompt 工程师是什么? 是识别人工智能的错误和隐藏功能,以便开发者可以对这些发现进行处理。 如果你正在寻找科技领域最热门的工作,你可以尝试了解如何与AI聊天机…...

机器学习笔记 使用PPOCRLabel标注自己的OCR数据集
一、PPOCRLabel的安装 最简单的方式就是直接pip安装,如下命令。 pip install PPOCRLabel -i https://pypi.douban.com/simple/ 运行的时候,直接激活安装了PPOCRLabel的环境后,输入PPOCRLabel回车即可运行,不过PPOCRLabel依赖PyQt5,所以会要求安装PyQt5,按要求安装或者提前…...

【C++初阶】类和对象(二)
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:C初阶 🎯长路漫漫浩浩,万事皆有期待 上一篇博客:【C初阶】…...

深入探讨Java、Spring和Dubbo的SPI机制
在Java开发领域中,SPI(Service Provider Interface)是一种用于实现框架扩展的机制。Java本身提供了SPI机制,Spring和Dubbo也都有自己的SPI机制。本文将介绍Java、Spring、Dubbo三者SPI机制的原理和区别。 一、Java SPI机制 Java…...
使用机器人为无线传感器网络提供服务(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 无线传感器网络是一种无线网络,包括大量循环的、自定向的、微小的、低功耗的设备,称为传感器节点&…...

QT自制软键盘 最完美、最简单、跟自带虚拟键盘一样
QT自制软键盘 最完美、最简单、跟自带虚拟键盘一样 [1] QT自制软键盘 最完美、最简单、跟自带虚拟键盘一样一、本自制虚拟键盘特点二、windows打开系统自带软键盘三、让键盘界面保持在最上方、不改变底层界面焦点四、长按按键重复输入键盘内容五、模拟键盘点击事件完成虚拟键盘…...

优思学院|8D和DMAIC两种方法应如何选择?
在现代的商业环境中,客户投诉是一个非常常见的问题。当客户不满意产品或服务时,他们往往会向企业发出投诉。质量管理部门是一个负责处理这些投诉的重要部门,因为它们需要确保产品和服务的质量满足客户的期望。改善方法是质量管理部门用来解决…...

回归预测 | MATLAB实现MLR多元线性回归预测(多指标评价)
回归预测 | MATLAB实现MLR多元线性回归预测(多指标评价) 目录 回归预测 | MATLAB实现MLR多元线性回归预测(多指标评价)预测效果基本介绍模型描述程序设计参考资料预测效果 基本介绍 回归预测 | MATLAB实现MLR多元线性回归预测(多指标评价) 模型描述 多元线性回归(Multip…...

PHP 二维数组相关函数:二维数组指定key排序,二维数组转一维数组,两个二维数组取差集,对象转数组,判断元素是否在多维数组中
目录 一、二维数组转一维数组 二、对二维数组进行指定key排序 三、二维数组转一维数组 四、两个二维数组取差集 五、对象转数组 六、判断元素是否在多维数组中 PHP 二维数组相关函数:二维数组转一维数组,二维数组指定key排序,两个二维数…...
演出剧院门票售票预约小程序开发制作功能介绍
基于微信小程序的票务预约小程序,广泛适用于演出主办方、剧院、艺术中心、活动中心售票、景区门票售票、儿童游乐园售票、会务签到、展会售票签到、教育培训报名预约、健身预约功能。 多场景售票支持: 售票软件支持多种场景的售票,支持选座、…...

JUC之Java内置锁的核心原理
文章目录 JUC之Java内置锁的核心原理Java对象结构对象头对象体对齐字节 Mark Word的结构信息64位Mark Word的构成 偏向锁偏向锁的设置偏向锁的重偏向偏向锁的撤销偏向锁的膨胀 轻量级锁执行过程轻量级锁的分类普通自旋锁自适应自旋锁 重量级锁偏向锁、轻量级锁与重量级锁的对比…...

【项目经理】论项目经理的自我修养
项目经理的非职权领导力 文章目录 项目经理的非职权领导力一、权利的类型二、构成权利的三要素三、沟通是实施影响力的重要手段3.1 沟通的主要类型3.2 沟通的内容和形式3.3 沟通的主要困难 四、综合沟通协调的技巧4.1 常见的负面反馈4.2 沟通技巧 五、论项目经理的自我修养5.1 …...

知识图谱学习笔记03-知识图谱的作用
语义搜索 知识图谱在语义搜索方面扮演着非常重要的角色。传统的文本搜索引擎基本上是基于关键词匹配的方式进行搜索,这种方式容易受到搜索词语的表述方式和不同语言之间的差异的影响,而无法深入理解用户的意图和查询目的。而知识图谱则提供了一种更加精…...

刚进公司就负责项目,把老弟整蒙了!
刚进公司就负责项目,把老弟整蒙了! 大家好,我是鱼皮,先把封面图送给大家: 又快到周末了,今天分享一些轻松的编程经验~ 还记得我学编程的老弟小阿巴么?他目前大二,听说最近刚刚找到…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...