【图像分割】【深度学习】SAM官方Pytorch代码-Mask decoder模块MaskDeco网络解析
【图像分割】【深度学习】SAM官方Pytorch代码-Mask decoder模块MaskDeco网络解析
Segment Anything:建立了迄今为止最大的分割数据集,在1100万张图像上有超过1亿个掩码,模型的设计和训练是灵活的,其重要的特点是Zero-shot(零样本迁移性)转移到新的图像分布和任务,一个图像分割新的任务、模型和数据集。SAM由三个部分组成:一个强大的图像编码器(Image encoder)计算图像嵌入,一个提示编码器(Prompt encoder)嵌入提示,然后将两个信息源组合在一个轻量级掩码解码器(Mask decoder)中来预测分割掩码。本博客将讲解Mask decoder模块的深度学习网络代码。

文章目录
- 【图像分割】【深度学习】SAM官方Pytorch代码-Mask decoder模块MaskDeco网络解析
- 前言
- MaskDecoder网络简述
- SAM模型关于MaskDeco网络的配置
- MaskDeco网络结构与执行流程
- MaskDeco网络基本步骤代码详解
- transformer
- TwoWayAttention Block
- Attention
- transformer_MLP
- upscaled
- mask_MLP
- iou_MLP
- MaskDeco_MLP
- 总结
前言
在详细解析SAM代码之前,首要任务是成功运行SAM代码【win10下参考教程】,后续学习才有意义。本博客讲解Mask decoder模块的深度网络代码,不涉及其他功能模块代码。
MaskDecoder网络简述
SAM模型关于MaskDeco网络的配置
博主以sam_vit_b为例,详细讲解MaskDeco网络的结构。
代码位置:segment_anything/build_sam.py
def build_sam_vit_b(checkpoint=None):return _build_sam(# 图像编码channelencoder_embed_dim=768,# 主体编码器的个数encoder_depth=12,# attention中head的个数encoder_num_heads=12,# 需要将相对位置嵌入添加到注意力图的编码器( Encoder Block)encoder_global_attn_indexes=[2, 5, 8, 11],# 权重checkpoint=checkpoint,)sam模型中Mask_decoder模块初始化
mask_decoder=MaskDecoder(# 消除掩码歧义预测的掩码数num_multimask_outputs=3,# 用于预测mask的网咯transformertransformer=TwoWayTransformer(# 层数depth=2,# 输入channelembedding_dim=prompt_embed_dim,# MLP内部channelmlp_dim=2048,# attention的head数num_heads=8,),# transformer的channeltransformer_dim=prompt_embed_dim,# MLP的深度,MLP用于预测掩模质量的iou_head_depth=3,# MLP隐藏channeliou_head_hidden_dim=256,
),
MaskDeco网络结构与执行流程
Mask decoder源码位置:segment_anything/modeling/mask_decoder.py
MaskDeco网络(MaskDecoder类)结构参数配置。
def __init__(self,*,# transformer的channeltransformer_dim: int,# 用于预测mask的网咯transformertransformer: nn.Module,# 消除掩码歧义预测的掩码数num_multimask_outputs: int = 3,# 激活层activation: Type[nn.Module] = nn.GELU,# MLP深度,MLP用于预测掩模质量的iou_head_depth: int = 3,# MLP隐藏channeliou_head_hidden_dim: int = 256,
) -> None:super().__init__()self.transformer_dim = transformer_dim # transformer的channel#----- transformer -----self.transformer = transformer # 用于预测mask的网咯transformer# ----- transformer -----self.num_multimask_outputs = num_multimask_outputs # 消除掩码歧义预测的掩码数self.iou_token = nn.Embedding(1, transformer_dim) # iou的takenself.num_mask_tokens = num_multimask_outputs + 1 # mask数self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim) # mask的tokens数#----- upscaled -----# 4倍上采样self.output_upscaling = nn.Sequential(nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2), #转置卷积 上采样2倍LayerNorm2d(transformer_dim // 4),activation(),nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),activation(),)# ----- upscaled -----# ----- MLP -----# 对应mask数的MLPself.output_hypernetworks_mlps = nn.ModuleList([MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)for i in range(self.num_mask_tokens)])# ----- MLP -----# ----- MLP -----# 对应iou的MLPself.iou_prediction_head = MLP(transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth)# ----- MLP -----
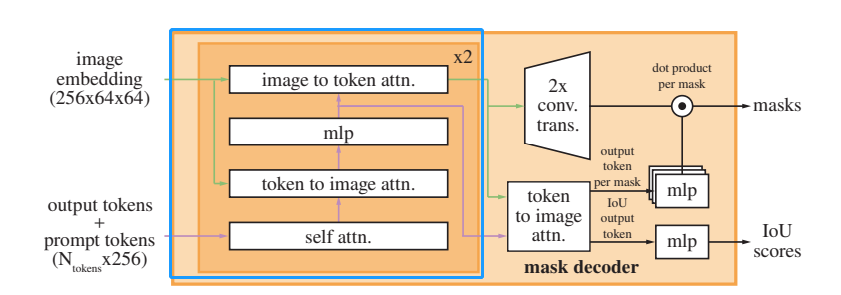
SAM模型中MaskDeco网络结构如下图所示:

原论文中Mask decoder模块各部分结构示意图:

MaskDeco网络(MaskDecoder类)在特征提取中的几个基本步骤:
- transformer:融合特征(提示信息特征与图像特征)获得粗略掩膜src
- upscaled:对粗略掩膜src上采样
- mask_MLP:全连接层组(计算加权权重,使粗掩膜src转变为掩膜mask)
- iou_MLP:全连接层组(计算掩膜mask的Score)
def forward(self,# image encoder 图像特征image_embeddings: torch.Tensor,# 位置编码image_pe: torch.Tensor,# 标记点和标记框的嵌入编码sparse_prompt_embeddings: torch.Tensor,# 输入mask的嵌入编码dense_prompt_embeddings: torch.Tensor,# 是否输出多个maskmultimask_output: bool,
) -> Tuple[torch.Tensor, torch.Tensor]:masks, iou_pred = self.predict_masks(image_embeddings=image_embeddings,image_pe=image_pe,sparse_prompt_embeddings=sparse_prompt_embeddings,dense_prompt_embeddings=dense_prompt_embeddings,)# Select the correct mask or masks for outputif multimask_output:mask_slice = slice(1, None)else:mask_slice = slice(0, 1)masks = masks[:, mask_slice, :, :]iou_pred = iou_pred[:, mask_slice]return masks, iou_pred
def predict_masks(self,image_embeddings: torch.Tensor,image_pe: torch.Tensor,sparse_prompt_embeddings: torch.Tensor,dense_prompt_embeddings: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:# Concatenate output tokens# 1,E and 4,E --> 5,Eoutput_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)# 5,E --> B,5,Eoutput_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)# B,5,E and B,N,E -->B,5+N,E N是点的个数(标记点和标记框的点)tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)# 扩展image_embeddings的B维度,因为boxes标记分割时,n个box时batchsize=batchsize*n# Expand per-image data in batch direction to be per-mask# B,C,H,Wsrc = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)# B,C,H,W + 1,C,H,W ---> B,C,H,Wsrc = src + dense_prompt_embeddings# 1,C,H,W---> B,C,H,Wpos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)b, c, h, w = src.shape# ----- transformer -----# Run the transformer# B,N,Chs, src = self.transformer(src, pos_src, tokens)# ----- transformer -----iou_token_out = hs[:, 0, :]mask_tokens_out = hs[:, 1: (1 + self.num_mask_tokens), :]# Upscale mask embeddings and predict masks using the mask tokens# B,N,C-->B,C,H,Wsrc = src.transpose(1, 2).view(b, c, h, w)# ----- upscaled -----# 4倍上采样upscaled_embedding = self.output_upscaling(src)# ----- upscaled -----hyper_in_list: List[torch.Tensor] = []# ----- mlp -----for i in range(self.num_mask_tokens):# mask_tokens_out[:, i, :]: B,1,C# output_hypernetworks_mlps: B,1,chyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))# B,n,chyper_in = torch.stack(hyper_in_list, dim=1)# ----- mlp -----b, c, h, w = upscaled_embedding.shape# B,n,c × B,c,N-->B,n,h,wmasks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)# ----- mlp -----# Generate mask quality predictions# iou_token_out: B,1,niou_pred = self.iou_prediction_head(iou_token_out)# ----- mlp -----# masks: B,n,h,w# iou_pred: B,1,nreturn masks, iou_pred
MaskDeco网络基本步骤代码详解
transformer
MaskDeco由多个重复堆叠TwoWayAttention Block和1个Multi-Head Attention组成。
class TwoWayTransformer(nn.Module):def __init__(self,# 层数depth: int,# 输入channelembedding_dim: int,# attention的head数num_heads: int,# MLP内部channelmlp_dim: int,activation: Type[nn.Module] = nn.ReLU,attention_downsample_rate: int = 2,) -> None:super().__init__()self.depth = depth # 层数self.embedding_dim = embedding_dim # 输入channelself.num_heads = num_heads # attention的head数self.mlp_dim = mlp_dim # MLP内部隐藏channelself.layers = nn.ModuleList()for i in range(depth):self.layers.append(TwoWayAttentionBlock(embedding_dim=embedding_dim, # 输入channelnum_heads=num_heads, # attention的head数mlp_dim=mlp_dim, # MLP中间channelactivation=activation, # 激活层attention_downsample_rate=attention_downsample_rate, # 下采样skip_first_layer_pe=(i == 0),))self.final_attn_token_to_image = Attention(embedding_dim, num_heads, downsample_rate=attention_downsample_rate)self.norm_final_attn = nn.LayerNorm(embedding_dim)def forward(self,image_embedding: Tensor,image_pe: Tensor,point_embedding: Tensor,) -> Tuple[Tensor, Tensor]:# BxCxHxW -> BxHWxC == B x N_image_tokens x Cbs, c, h, w = image_embedding.shape# 图像编码(image_encoder的输出)# BxHWxC=>B,N,Cimage_embedding = image_embedding.flatten(2).permute(0, 2, 1)# 图像位置编码# BxHWxC=>B,N,Cimage_pe = image_pe.flatten(2).permute(0, 2, 1)# 标记点编码# B,N,Cqueries = point_embeddingkeys = image_embedding# -----TwoWayAttention-----for layer in self.layers:queries, keys = layer(queries=queries,keys=keys,query_pe=point_embedding,key_pe=image_pe,)# -----TwoWayAttention-----q = queries + point_embeddingk = keys + image_pe# -----Attention-----attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys)# -----Attention-----queries = queries + attn_outqueries = self.norm_final_attn(queries)return queries, keys

TwoWayAttention Block
TwoWayAttention Block由LayerNorm 、Multi-Head Attention和MLP构成。
class TwoWayAttentionBlock(nn.Module):def __init__(self,embedding_dim: int, # 输入channelnum_heads: int, # attention的head数mlp_dim: int = 2048, # MLP中间channelactivation: Type[nn.Module] = nn.ReLU, # 激活层attention_downsample_rate: int = 2, # 下采样skip_first_layer_pe: bool = False,) -> None:super().__init__()self.self_attn = Attention(embedding_dim, num_heads)self.norm1 = nn.LayerNorm(embedding_dim)self.cross_attn_token_to_image = Attention(embedding_dim, num_heads, downsample_rate=attention_downsample_rate)self.norm2 = nn.LayerNorm(embedding_dim)self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)self.norm3 = nn.LayerNorm(embedding_dim)self.norm4 = nn.LayerNorm(embedding_dim)self.cross_attn_image_to_token = Attention(embedding_dim, num_heads, downsample_rate=attention_downsample_rate)self.skip_first_layer_pe = skip_first_layer_pedef forward(self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor) -> Tuple[Tensor, Tensor]:# queries:标记点编码相关(原始标记点编码经过一系列特征提取)# keys:原始图像编码相关(原始图像编码经过一系列特征提取)# query_pe:原始标记点编码# key_pe:原始图像位置编码# 第一轮本身queries==query_pe没比较再"残差"if self.skip_first_layer_pe:queries = self.self_attn(q=queries, k=queries, v=queries)else:q = queries + query_peattn_out = self.self_attn(q=q, k=q, v=queries)queries = queries + attn_outqueries = self.norm1(queries)# Cross attention block, tokens attending to image embeddingq = queries + query_pek = keys + key_peattn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)queries = queries + attn_outqueries = self.norm2(queries)# MLP blockmlp_out = self.mlp(queries)queries = queries + mlp_outqueries = self.norm3(queries)# Cross attention block, image embedding attending to tokensq = queries + query_pek = keys + key_peattn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)keys = keys + attn_outkeys = self.norm4(keys)return queries, keys
TwoWayAttentionBlock的结构对比示意图:
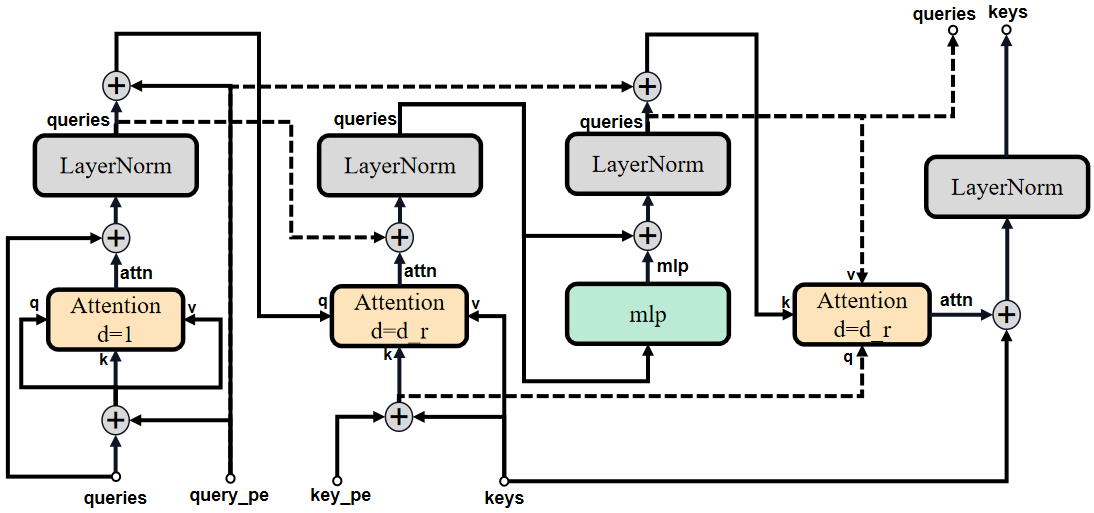
原论文中TwoWayAttention部分示意图:
个人理解:TwoWayAttentionBlock是Prompt encoder的提示信息特征与Image encoder的图像特征的融合过程,而Prompt encoder对提示信息没有过多处理,因此博主认为TwoWayAttentionBlock的目的是边对提示信息特征做进一步处理边与图像特征融合。
Attention
MaskDeco的Attention与ViT的Attention有些细微的不同:MaskDeco的Attention是3个FC层分别接受3个输入获得q、k和v,而ViT的Attention是1个FC层接受1个输入后将结果均拆分获得q、k和v。
class Attention(nn.Module):def __init__(self,embedding_dim: int, # 输入channelnum_heads: int, # attention的head数downsample_rate: int = 1, # 下采样) -> None:super().__init__()self.embedding_dim = embedding_dimself.internal_dim = embedding_dim // downsample_rateself.num_heads = num_headsassert self.internal_dim % num_heads == 0, "num_heads must divide embedding_dim."# qkv获取self.q_proj = nn.Linear(embedding_dim, self.internal_dim)self.k_proj = nn.Linear(embedding_dim, self.internal_dim)self.v_proj = nn.Linear(embedding_dim, self.internal_dim)self.out_proj = nn.Linear(self.internal_dim, embedding_dim)def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:b, n, c = x.shapex = x.reshape(b, n, num_heads, c // num_heads)return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_headdef _recombine_heads(self, x: Tensor) -> Tensor:b, n_heads, n_tokens, c_per_head = x.shapex = x.transpose(1, 2)return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x Cdef forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:# Input projectionsq = self.q_proj(q)k = self.k_proj(k)v = self.v_proj(v)# Separate into heads# B,N_heads,N_tokens,C_per_headq = self._separate_heads(q, self.num_heads)k = self._separate_heads(k, self.num_heads)v = self._separate_heads(v, self.num_heads)# Attention_, _, _, c_per_head = q.shapeattn = q @ k.permute(0, 1, 3, 2) # B,N_heads,N_tokens,C_per_head# Scaleattn = attn / math.sqrt(c_per_head)attn = torch.softmax(attn, dim=-1)# Get outputout = attn @ v# # B,N_tokens,Cout = self._recombine_heads(out)out = self.out_proj(out)return out
MaskDeco的Attention和ViT的Attention的结构对比示意图:
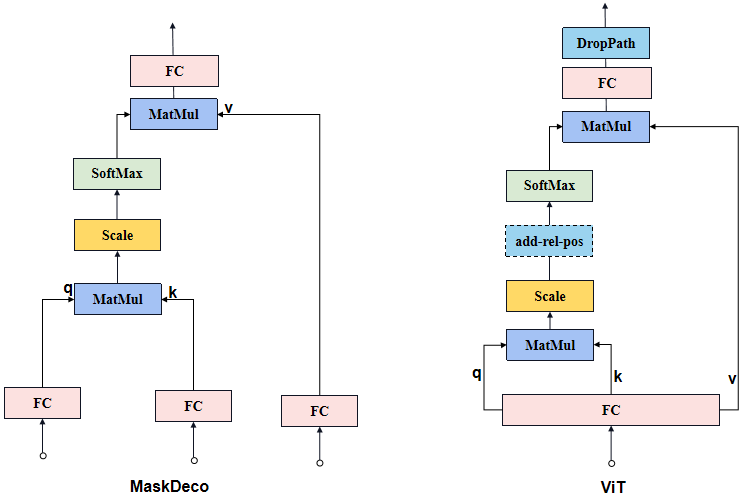
原论文中Attention部分示意图:

transformer_MLP
class MLPBlock(nn.Module):def __init__(self,embedding_dim: int,mlp_dim: int,act: Type[nn.Module] = nn.GELU,) -> None:super().__init__()self.lin1 = nn.Linear(embedding_dim, mlp_dim)self.lin2 = nn.Linear(mlp_dim, embedding_dim)self.act = act()def forward(self, x: torch.Tensor) -> torch.Tensor:return self.lin2(self.act(self.lin1(x)))
transformer中MLP的结构对比示意图:

upscaled
# 在MaskDecoder的__init__定义
self.output_upscaling = nn.Sequential(nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2), #转置卷积 上采样2倍LayerNorm2d(transformer_dim // 4),activation(),nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),activation(),
)
# 在MaskDecoder的predict_masks添加位置编码
upscaled_embedding = self.output_upscaling(src)
upscaled的结构对比示意图:

mask_MLP
此处的MLP基础模块不同于ViT的MLP(transformer_MLP)基础模块。
# 在MaskDecoder的__init__定义
self.output_hypernetworks_mlps = nn.ModuleList([MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)for i in range(self.num_mask_tokens)]
)
# 在MaskDecoder的predict_masks添加位置编码for i in range(self.num_mask_tokens):# mask_tokens_out[:, i, :]: B,1,C# output_hypernetworks_mlps: B,1,chyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))# B,n,chyper_in = torch.stack(hyper_in_list, dim=1)b, c, h, w = upscaled_embedding.shape# B,n,c × B,c,N-->B,n,h,wmasks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
iou_MLP
此处的MLP基础模块不同于ViT的MLP(transformer_MLP)基础模块。
# 在MaskDecoder的__init__定义
self.iou_prediction_head = MLP(transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
)
# 在MaskDecoder的predict_masks添加位置编码
iou_pred = self.iou_prediction_head(iou_token_out)
MaskDeco_MLP
class MLP(nn.Module):def __init__(self,input_dim: int, # 输入channelhidden_dim: int, # 中间channeloutput_dim: int, # 输出channelnum_layers: int, # fc的层数sigmoid_output: bool = False,) -> None:super().__init__()self.num_layers = num_layersh = [hidden_dim] * (num_layers - 1)self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))self.sigmoid_output = sigmoid_outputdef forward(self, x):for i, layer in enumerate(self.layers):x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)if self.sigmoid_output:x = F.sigmoid(x)return x
MaskDeco中MLP的结构对比示意图:

总结
尽可能简单、详细的介绍SAM中Mask decoder模块的MaskDeco网络的代码。
相关文章:
【图像分割】【深度学习】SAM官方Pytorch代码-Mask decoder模块MaskDeco网络解析
【图像分割】【深度学习】SAM官方Pytorch代码-Mask decoder模块MaskDeco网络解析 Segment Anything:建立了迄今为止最大的分割数据集,在1100万张图像上有超过1亿个掩码,模型的设计和训练是灵活的,其重要的特点是Zero-shot(零样本迁…...
A Restful API
SpringBoot 定义Restful API 定义POJOOrderBuyer 定义RestfulControllerGet API for queryPost API for addPut API for updateDelete API for delete 定义AjaxResponse Patavariable RequestParm RequestBodyRequestHeader 定义POJO Order import java.util.Date; import ja…...

从零开始学习JSP,让你全面掌握Web开发技能
JSP(Java Server Pages),是一种动态网页技术,它允许开发者使用Java代码和HTML标签来创建网页。在这篇文章中,我们将详细介绍JSP的基本概念、语法和应用。 一、JSP的基本概念 1.1 JSP的含义 JSP是一种网页技术&#…...

java基于知识库的中医药问询系统
本系统主要包含了等系统用户管理、中医药常识管理、科室信息管理、知识库管理多个功能模块。下面分别简单阐述一下这几个功能模块需求。 管理员的登录模块:管理员登录系统对本系统其他管理模块进行管理。 用户的登录模块:用户登录本系统,对个…...

【新星计划-2023】什么是ARP?详解它的“解析过程”与“ARP表”。
一、什么是ARP ARP(地址解析协议)英文全称“Address Resolution Protocol”,是根据IP地址获取物理地址的一个TCP/IP协议。主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确…...

自动驾驶行业观察之2023上海车展-----车企发展趋势(2)
自主品牌发展 比亚迪:展示3款新车,均于2023年年内上市 比亚迪在本次展会上推出了3款新车:宋L概念车(王朝系列)、驱逐舰07(海洋系列)、海鸥(海洋系列)。 • 宋L&#x…...

通知所有员工所需的时间
题目描述 公司里有 n 名员工,每个员工的 ID 都是独一无二的,编号从 0 到 n - 1。公司的总负责人通过 headID 进行标识。 在 manager 数组中,每个员工都有一个直属负责人,其中 manager[i] 是第 i 名员工的直属负责人。对于总负责…...

Docker:bash: vim: command not found
进入docker容器 docker exec -it [容器ID] /bin/bash docker exec -it e56e7bbe85ad /bin/bash 在使用 Docker 容器时,有时候里边没有安装vim,敲vim命令时提示说:vim: command not found,这个时候就需要安装vim,可是…...

排序算法之选择排序
选择排序(Selection Sort)是一种简单直观的排序算法,其基本思路是在未排序的数据序列中找到最小元素,将其放在已排序的数据序列的末尾。重复该过程,直到整个序列排序完成。 具体实现过程如下: 首先&#x…...

5_服务编排_docker-compose
服务编排之Docker Compose 微服务架构的应用系统中一般包含若干个微服务,每个微服务一般都会部署多个实例,如果每个微服务都要手动启停,维护的工作量会很大。 要从Dockerfile build image 或者去dockerhub拉取image 要创建多个container 要…...

Java基本数据类型以及包装类型的常量池技术
Java 中的基本数据类型 Java 中有 8 种基本数据类型,分别为: 6 种数字类型: 4 种整数型:byte、short、int、long2 种浮点型:float、double 1 种字符类型:char1 种布尔型:boolean。 这 8 种基本…...

P1054 [NOIP2005 提高组] 等价表达式
题目描述 明明进了中学之后,学到了代数表达式。有一天,他碰到一个很麻烦的选择题。这个题目的题干中首先给出了一个代数表达式,然后列出了若干选项,每个选项也是一个代数表达式,题目的要求是判断选项中哪些代数表达式…...

什么牌子蓝牙耳机好用不贵?国产性价比高的蓝牙耳机推荐
相较于有线耳机,无线蓝牙耳机更便携、功能更丰富,不用受到耳机孔与线的限制。那么,什么牌子的蓝牙耳机好用不贵?针对这个问题,我给大家推荐几款国产性价比高的蓝牙耳机,可以当个参考。 一、南卡小音舱Lite…...

明明花钱上了ERP,为什么还要我装个MES系统
目前, ERP系统依旧是很多制造企业的选择。据统计,ERP系统的应用已经达到70%以上,但是在车间的应用, MES系统的应用比例并不高。那么,为什么现在很多企业又都选择再上个MES呢? MES系统是一个面向…...

JAVA中的集合框架有哪些?
在Java中,集合(Collection)是一组对象的容器,而集合框架(Collection Framework)是一组接口、实现类和算法,用于存储和操作集合。Java集合框架提供了一组通用的、高性能的、可扩展的接口和类&…...
用Jmeter进行接口自动化测试的工作流程你知道吗?
目录 测试流程 接口测试相关文档管理规范 接口测试要点 测试流程 在测试负责人接受到测试任务后,应该按照以下流程规范完成测试工作。 2.1 测试需求分析 产品开发负责人在完成某产品功能的接口文档编写后,在核对无误后下发给对应的接口测试负责人…...
)
Java 中的设计模式有哪些?(十九)
Java设计模式是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。 设计模式可以帮助我们解决软件开发过程中面临的一般问题,提高代码的可读性、可复用性和可扩展性。 Java中一般认为有23种设计模式,总体来说设计模式分为三大类&…...

奇数单增序列
题目描述 给定一个长度为 N(不大于 500)的正整数序列,请将其中的所有奇数取出,并按升序输出。 输入格式 第 1 行为 N;第 2 行为 N 个正整数,其间用空格间隔。 输出格式 增序输出的奇数序列,…...
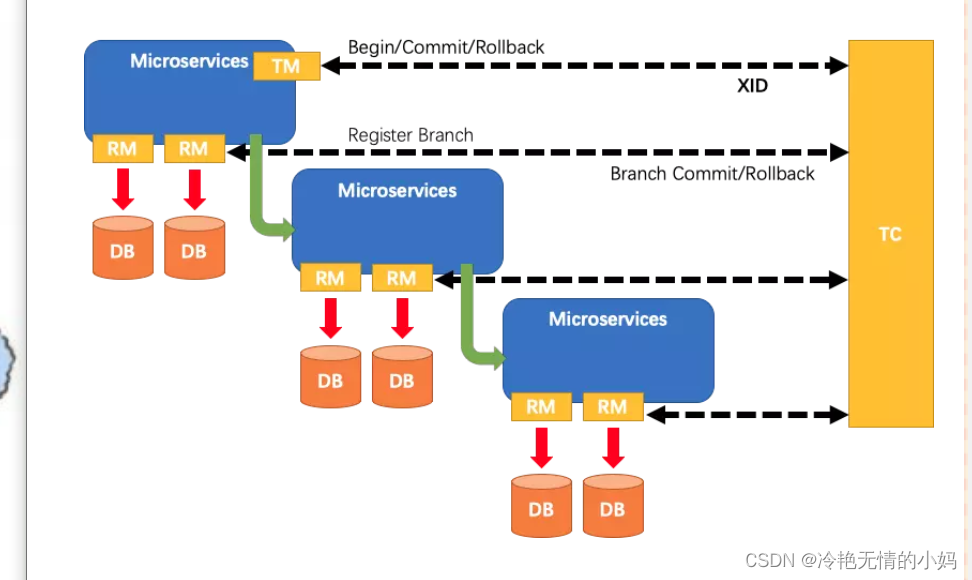
Seata介绍
介绍: Seata的设计目标是对这个业务无侵入,因此从业务无侵入的2PC方案开始的,在传统的2PC的基础上演进的。它把一个分布式事务拆分理解成一个包含了若干分支事务的全局事务。全局事务的职责是协调其下管辖的分支事务达成一致性,要…...
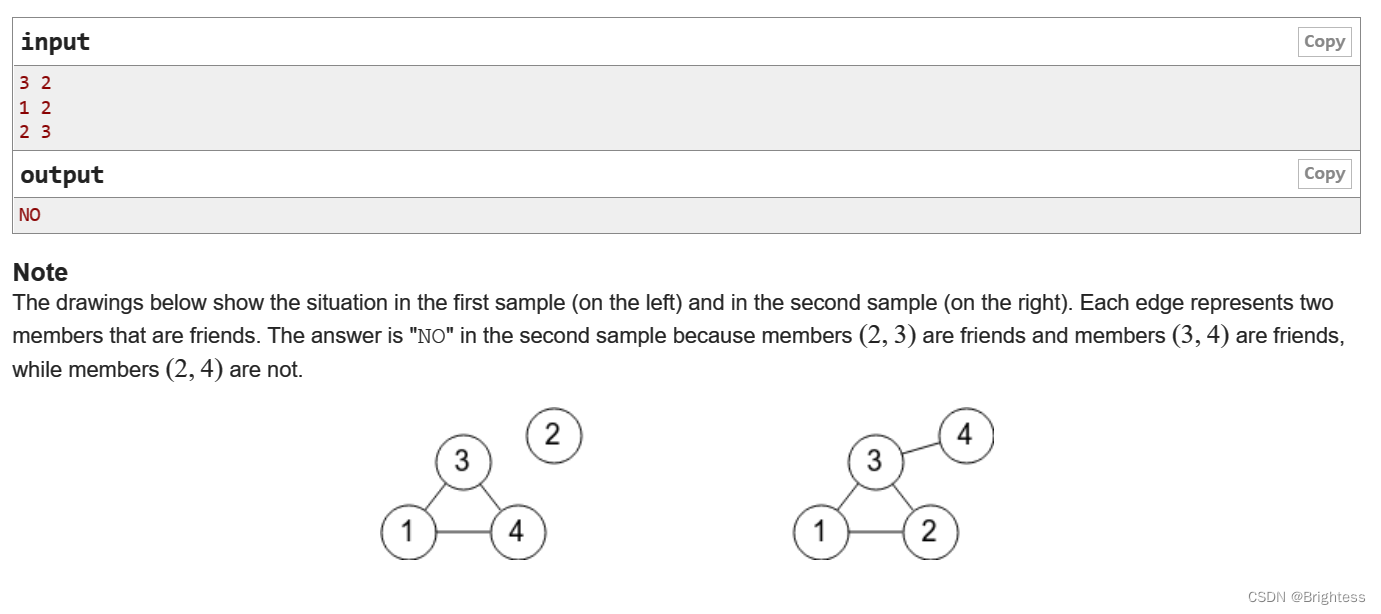
VK Cup 2017 - Round 1 A - Bear and Friendship Condition(并查集维护大小 + dfs 遍历图统计边数)
题目大意: 给你一些n个点m条边,如果三个点(a,b,c)是合法的,当且仅当 a-b,b-c,c-a都有一条边,问你这个图是否合法,如果有一个或两个点视为合法 思路 考虑什么图才是个合法图:除了点…...

干货来了:专科生必备的降AIGC软件 —— 千笔·降AI率助手
在AI技术快速发展的今天,越来越多的学生开始借助AI工具辅助论文写作,提升效率和质量。然而,随着学术审查标准的不断提高,AI生成内容的痕迹越来越容易被识别,导致论文AI率超标成为普遍难题。无论是知网、维普还是Turnit…...

新手必看!前端如何玩转Blob对象:从URL生成到文件下载全流程解析
前端开发者必备:Blob对象实战指南——从URL生成到文件下载全流程 在Web开发中,处理二进制数据是每个前端工程师迟早要面对的挑战。Blob(Binary Large Object)作为浏览器提供的原生对象,能够高效地处理文件流、图像数据…...
)
Dify异步节点稳定性攻坚实录(生产环境零宕机的5大硬核配置)
第一章:Dify异步节点稳定性攻坚实录(生产环境零宕机的5大硬核配置)在高并发、长生命周期任务密集的生产环境中,Dify 的异步节点(如 LLM 调用、RAG 检索、工作流编排)曾频繁出现超时中断、Celery worker 意外…...

Python基础语法:从零开始,掌握编程核心
目录 一、print输出函数(重点) 二、字面量和注释 三、变量(重点) 四、type函数查看数据类型 五、数据类型转换函数 六、标识符 七、运算符 八、字符串格式化【重点】 九、input输入函数(重点) 前言 学习Python,…...

实测对比后!更贴合论文写作全流程的降AI率网站,千笔·专业降AI率智能体 VS 云笔AI
在AI技术迅速发展的今天,越来越多的学生和研究人员开始借助AI工具辅助论文写作,以提高效率、优化结构甚至生成初稿。然而,随着知网、维普、万方等查重系统不断升级算法,以及Turnitin对AIGC内容的识别愈发严格,AI率超标…...

RTL8211E千兆PHY芯片PCB设计避坑指南:从电源分层到差分线等长
RTL8211E千兆PHY芯片PCB设计实战:规避高频信号陷阱的12个关键策略 在千兆以太网硬件设计中,RTL8211E作为主流PHY芯片方案,其PCB实现质量直接影响网络传输的稳定性和速率上限。许多工程师在完成原理图设计后,往往在PCB阶段遭遇信号…...

GPTK进阶指南:除了装游戏,这些Wine Prefix的维护技巧让你少走弯路
GPTK进阶指南:Wine Prefix管理与维护实战技巧 如果你已经成功用Game Porting Toolkit(GPTK)在Mac上运行了几款Windows游戏,可能会发现随着游戏数量的增加,环境变得越来越混乱——某个游戏的设置影响了其他游戏…...

告别手绘:用Matlab脚本批量生成自定义伯德图坐标纸
1. 为什么需要自动生成伯德图坐标纸 作为一名自动化专业的学生,我深刻理解绘制伯德图时的痛苦。每次作业都要在坐标纸上手绘各种曲线,不仅耗时耗力,还经常因为坐标轴刻度不准确导致整张图作废。更糟的是,不同题目要求的频率范围和…...

【MCP跨语言SDK开发终极指南】:20年架构师亲测的7大避坑法则与性能优化黄金组合
第一章:MCP跨语言SDK开发指南对比评测报告概述MCP(Model Control Protocol)作为新兴的模型交互协议标准,正推动AI服务接口的统一化演进。为支撑多语言生态快速集成,主流社区已发布Go、Python、TypeScript、Java及Rust五…...

Minio Client实战指南:从安装到高效管理对象存储
1. Minio Client入门:为什么你需要这个神器? 第一次接触Minio Client(简称mc)时,我正被海量文件同步问题折磨得焦头烂额。作为与S3协议兼容的命令行工具,mc就像给你的对象存储操作装上了涡轮增压器。想象一…...