机器学习:分类、回归、决策树
分类:具有明确的类别
如:去银行借钱,会有借或者不借的两种类别
回归:不具有明确的类别和数值
如:去银行借钱,预测银行会借给我多少钱,如:1~100000之间的一个数值
不纯度:
为了要将表格转化为一棵树,决策树需要找出最佳节点和最佳的分枝方法,对分类树来说,衡量这个 “ 最佳 ” 的指标 叫做“ 不纯度 ” 。通常来说,不纯度越低,决策树对训练集的拟合越好。
·不纯度基于节点来计算,树中的每个节点都会有一个不纯度,并且子节点的不纯度一定是低于父节点的,也就是 说,在同一棵决策树上,叶子节点的不纯度一定是最低的。
不存度的概念
决策树的每个叶子节点中都会包含一组数据,在这组数据中,如果有某一类标签占有较大的比例,我们就说叶子 节点“ 纯 ” ,分枝分得好。某一类标签占的比例越大,叶子就越纯,不纯度就越低,分枝就越好。
如果没有哪一类标签的比例很大,各类标签都相对平均,则说叶子节点 ” 不纯 “ ,分枝不好,不纯度高。
过拟合 | 模型在训练集上表现很好,在测试集上表现很糟糕,学习能力很强但是学得太过精细了 |
欠拟合 | 模型在训练集和测试集上都表现糟糕,学习能力不足 |
机器学习的例子:
y=kx+b
先通过已知:x和y,求出:k和b
再通过y=kx+b(k已知,b已知)和x的测试集
求出y预测=k已知*x测试+b已知
y的预测值和y的测试值相比较,需要使y的预测与y的测试尽量的接近
from sklearn import tree #从sklearn 包里面导入tree类
clf = tree.DecisionTreeClassifier() #实例化一个决策树分类器
clf =clf.fit(X_train,y_train) #用训练集数据训练模型
result=clf.score(X_test,y_test)#导入测试集,从接口中调用需要的信息建立一棵树
#导入需要的算法库和模块
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split#搜索数据红酒数据集
#红酒数据集
#导入需要的算法库和模块
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
wine = load_wine() #加载并返回葡萄酒数据集(分类)。
wine.data.shape #看一下这个表格是怎么样的
#输出(178, 13),代表存在178行,13列
wine.target #查看表格中有几个标签
# array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
# 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
# 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
# 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
# 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
# 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
# 2, 2])
#即数据集中的标签有三种,0,1和2,也就是这些红酒被分成了三类。#如果wine是一张表,应该长这样
# import pandas as pd
# pd.concat([pd.DataFrame(wine.data),pd.DataFrame(
# .wine.target)],axis=1)
#这里是将红酒属性数据集和标签列进行了横向链接(也叫合并,学过数据库的都知道)# wine.feature_names
#查看红酒的属性名字
# wine.target_names
#查看标签名字,也就是分类的名字Xtrain,Xtest,Ytrain,Ytest=train_test_split(wine.data,wine.target,test_size=0.3)
#将数据集分为训练集和测试集,其中70%为训练集,30%为测试集。
Xtrain.shape
#训练集有124个样本,13个属性
Xtest.shape
#训练集有54个样本,13个属性
Ytrain
#查看训练集的目标属性;有三种,为0,1,2#建立模型
clf = tree.DecisionTreeClassifier(criterion="entropy") #建立决策分类树,判断不纯度的方法是信息熵
clf = clf.fit(Xtrain,Ytrain) #用训练集数据训练模型
score = clf.score(Xtest,Ytest) #返回预测的准确accuracy(分数)
score#查看预测的模型分数#画出这棵树
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜 色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
import graphviz
dot_data = tree.export_graphviz(clf,out_file = None,feature_names= feature_name,class_names=["琴酒","雪莉","贝尔摩德"],filled=True,rounded=True)
#以 DOT 格式导出决策树。# decision_tree:决策树分类器;要导出到 GraphViz 的决策树。# out_file:对象或字符串,默认=无;输出文件的句柄或名称。如果 None ,则结果以字符串形式返回。# feature_names:str列表,默认=无;每个函数的名称。如果 None 将使用通用名称(“feature_0”、“feature_1”、...)。# class_names:str 或 bool 的列表,默认 = 无
# 每个目标类别的名称按数字升序排列。仅与分类相关,不支持multi-output。如果 True ,则显示类名的符号表示。# filled:布尔,默认=假
# 当设置为 True 时,绘制节点以指示分类的多数类、回归值的极值或 multi-output 的节点纯度。#rounded:布尔,默认=假;当设置为 True 时,绘制圆角节点框。
graph = graphviz.Source(dot_data) #获取生成的决策树
graph #打印生成的决策树#特征重要性
clf.feature_importances_
#打印每个属性的重要性的数值,只有数值,不知道数值对应的属性是什么
[*zip(feature_name,clf.feature_importances_)]
#打印每个属性及其对应的重要性的数值# 建更多的不同的树,然后从中取最好的。
# 在每次分枝时,不从使用全部特征,而是随 机选取一部分特征,从中选取不纯度相关指标最优的作为分枝用的节点。
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30)
# random_state 用来设置分枝中的随机模式的参数,默认 None
#random_state是一个随机种子,是在任意带有随机性的类或函数里作为参数来控制随机模式。
#当random_state取某一个值时,也就确定了一种规则。
# 在高维度时随机性会表现更明显,低维度的数据 (比如鸢尾花数据集),随机性几乎不会显现。
#固定random_state后,每次构建的模型是相同的、生成的数据集是相同的、每次的拆分结果也是相同的。clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest) #返回预测的准确度
score
#这里的score会固定在0.925,不论你运行多少遍,它都不会变,因为每次都是选择的最优的树。#使用splitter来降低过拟合的可能性
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30 ,splitter="random")
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
score #输出结果为0.944444
# splitter 也是用来控制决策树中的随机选项的,有两种输入值
# 输入 "best" :决策树在分枝时虽然随机,但是还是会 优先选择更重要的特征进行分枝(重要性可以通过属性feature_importances_ 查看)
# 输入 "random" :决策树在 分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。
# 这也是防止过拟合的一种方式。当你预测到你的模型会过拟合,用这两个参数来帮助你降低树建成之后过拟合的可能性。#画出图像
import graphviz
dot_data = tree.export_graphviz(clf,feature_names= feature_name,class_names=["琴酒","雪莉","贝尔摩德"],filled=True,rounded=True )
graph = graphviz.Source(dot_data)
graph#我们的树对训练集的拟合程度如何?
score_train = clf.score(Xtrain, Ytrain) #返回预测的准确分数
score_train #查看预测的准确分数,此时结果为1.0 过拟合了#剪枝方法降低过拟合的可能性:
#(1)max_depth 限制树的最大深度
#(2)min_samples_split 限定,一个节点必须要包含至少 min_samples_split 个训练样本,这个节点才允许被分枝,否则分枝就不会发生。
#(3)min_samples_leaf 限定,一个节点在分枝后的每个子节点都必须包含至少 min_samples_leaf 个训练样本,否则分枝就不会发生
# 或者,分枝会朝着满足每个子节点都包含min_samples_leaf 个样本的方向去发生#通过限制条件进行剪枝,得到的决策树会更简洁,预测的准确分数也不错
clf=tree.DecisionTreeClassifier(criterion="entropy",random_state=30,splitter="random",max_depth=3,min_samples_leaf=5,min_samples_split=5)
clf = clf.fit(Xtrain, Ytrain)
dot_data = tree.export_graphviz(clf,feature_names= feature_name,class_names=["琴酒","雪莉","贝尔摩德"],filled=True,rounded=True)
graph = graphviz.Source(dot_data)
graph
score = clf.score(Xtest, Ytest)
score #0.9629629629629629# 超参数的学习曲线,是一条以超参数的取值为横坐标,模型的度量指标为纵坐标的曲线,它是用来衡量不同超参数取值下模型的表现的线。
# 在我们建好的决策树里,我们的模型度量指标就是score 。
import matplotlib.pyplot as plt #导入画图库
test = [] #创建一个列表
for i in range(10): #循环10次clf = tree.DecisionTreeClassifier(max_depth=i+1,criterion="entropy",random_state=30,splitter="random")clf = clf.fit(Xtrain, Ytrain) #训练模型score = clf.score(Xtest, Ytest) #预测的准确分数test.append(score) #往列表里面添加预测的分数值
plt.plot(range(1,11),test,color="red",label="max_depth") #画图
#横坐标为max_depth取值,纵坐标为score,图线颜色为red,label为图例的名称
#从图中我们可以看到,当max_depth取3的时候,模型得分最高
plt.legend() #给图像加图例
plt.show() #显示所打开的图形相关文章:

机器学习:分类、回归、决策树
分类:具有明确的类别 如:去银行借钱,会有借或者不借的两种类别 回归:不具有明确的类别和数值 如:去银行借钱,预测银行会借给我多少钱,如:1~100000之间的一个数值 不纯度࿱…...

java常见的异常,下一篇写如何正确处理异常
当我们编写Java程序时,经常会遇到各种异常情况。异常是指在程序执行过程中发生的一些错误或意外情况,它会打断程序的正常执行流程,并且需要被适当地处理。在Java中,异常被分为两种类型:可检查异常(Checked …...

C#开发的OpenRA游戏之网络协议打包和解包
C#开发的OpenRA游戏之网络协议打包和解包 OpenRA游戏里,由于这是一个网络游戏,那么与服务器通讯就缺少不了, 既然要通讯,那么就需要协议,有协议就需要对数据进行打包和解包, 这个过程其实就是序列化与反序列化的过程。 游戏里很多命令都需要发送给服务器,以便服务器同…...

K8S通过Ansible安装集群
K8S通过Ansible安装集群 K8S集群安装可参考https://gitee.com/open-hand/kubeadm-ha.git、https://github.com/easzlab/kubeasz.git 安装高可用集群 git clone https://gitee.com/open-hand/kubeadm-ha.git && cd kubeadm-ha升级内核,非必需,默认不升级&…...

ChatGPT辩证观点:“人才不是一个企业的核心竞争力,对人才的管理能力才是一个企业的核心竞争力”
一、问: “人才不是一个企业的核心竞争力,对人才的管理能力才是一个企业的核心竞争力”这句话的理解和误解,这句话有哪个中心论点转移和变化 二、ChatGPT答: 这句话的理解和误解: 理解:这句话的意思是说…...

windows11 永久关闭windows defender的方法
1、按键盘上的windows按键,再点【设置】选项。 2、点击左侧菜单的【隐私和安全性】,再点击列表的【Windows安全中心】选项。 3、点击界面的【病毒和威胁保护】设置项。 4、病毒保护的全部关闭 5、别人的图(正常是都开着的) 6、终极…...

继承的基本知识
概念 假设基于A类,创建了B类,那么称A为B的父类,B为A的子类 子类会继承父类的成员变量及成员函数,但是不能继承构造、析构、运算符重载 假设又基于B创建了C,那么称B为C的直接基类,A为C的间接基类 继承按…...
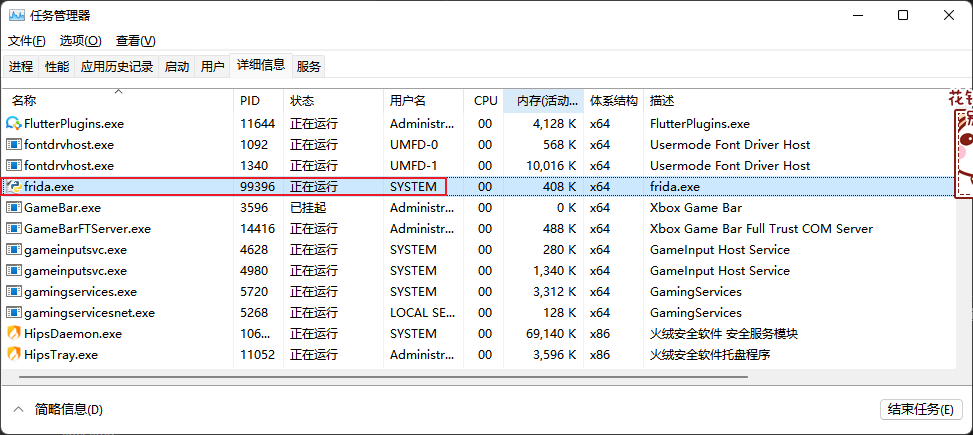
【Frida-实战】EA游戏平台的文件监控(PsExec.exe提权)
▒ 目录 ▒ 🛫 问题描述环境 1️⃣ 代码编写开源代码搜索自己撸代码procexp确定句柄对应的文件名并过滤 2️⃣ PsExec.exe提权定位找不到EABackgroundService.exe的问题 PsExec.exe提权PsExec.exe原理 🛬 结论📖 参考资料 🛫 问题…...

可视化和回归分析星巴克咖啡在中国的定价建议
可视化和回归分析星巴克咖啡在中国的定价建议。星巴克的拿铁大杯Tall 在各国的价格。 Claude AI | 代码自动生成的数据可视化代码 选择Claude AI 而非 ChatGPT的理由是前者更懂中文!具体可以参见我前面的两篇文章对比两者的中英文翻译的表现及使用安装等难易程度…...

热门影片怎么买票比较便宜,低价买电影票的方法,纯攻略!
有时候真的有被自己蠢到!看电影看了这么多年,竟然不知道电影票价格才9.9元、19.9元就能买到。之前我看电影动不动就是几十上百块,感觉好亏啊。 其实,我也不敢相信的,通过这些平台,同时在节假日甚至春节档期…...

Python通过SWIG调用C++时出现的ImportError问题解析
摘要 win10系统,编译器为mingw,按照教程封装C的一个类并用python调用,一步步进行直到最后一步运行python代码时,在python代码中import example时报错ImportError: DLL load failed while importing _example: The specified modul…...

3ds Max云渲染有多快,3ds Max云渲染怎么用?
本地渲染效果图和动画3D项目是一个非常耗时的过程,当在场景中使用未优化的几何体或在最终渲染中使用大量多边形模型时,诸如此类的变量最终会增加渲染项目所需的时间和处理器能力。随着提供的渲染服务的云渲染平台出现,越来越多动画师、艺术家…...

Java之线程安全
目录 一.上节回顾 1.Thread类常见的属性 2.Thread类中的方法 二.多线程带来的风险 1.观察线程不安全的现象 三.造成线程不安全现象的原因 1.多个线程修改了同一个共享变量 2.线程是抢占式执行的 3.原子性 4.内存可见性 5.有序性 四.解决线程不安全问题 ---synchroni…...

我有一个方法判断你有没有编程天赋
我有一个方法判断你有没有编程天赋 一 前言 基于知识的诅咒的原理 做一个敲击者很难。问题在于敲击者已拥有的知识(歌曲题目)让 他们想象不到缺乏这种知识会是什么情形。当他们敲击的时候,他 们不能想象听众听到的是那些独立的敲击声而不是…...

python 生成chart 并以附件形式发送邮件
import requests import json import pandas as pd import numpy as np import matplotlib.pyplot as plt data np.random.randn(5, 3)#生成chart def generate_line_chart(data):df pd.DataFrame(np.abs(data),index[Mon, Tue, Wen, Thir, Fri],columns[A, B, C])df.plot()…...

leetcode-035-搜索插入位置
题目及测试 package pid035; /*35. 搜索插入位置 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。请必须使用时间复杂度为 O(log n) 的算法。示例 1:输入: nums …...
读书笔记--数据治理之法
继续延续上一篇文章,对数据治理之法进行学习。数据治理之法是战术层面的方法,是一套涵盖8项举措的数据治理实施方法论,包括梳理现状与确定目标、能力成熟度评估、治理路线图规划、保障体系建设、技术体系建设、治理策略执行与监控、绩效考核与…...

送了老弟一台 Linux 服务器,它又懵了!
大家好,我是鱼皮。 前两天我学编程的老弟小阿巴过生日,我问他想要什么礼物。 本来以为他会要什么游戏机、Q 币卡、鼠标键盘啥的,结果小阿巴说:我想要一台服务器。 鱼皮听了,不禁称赞道:真是个学编程的好苗…...

CentOS 7(2009) 升级 GCC 版本
1. 前言 CentOS 7 默认安装的 gcc 版本为 4.8,但是很多时候都会需要用到更高版本的 gcc 来编译源码,那么本文将会介绍如何在线升级 CentOS 的 gcc 版本。 2. 升级 GCC (1). 安装 centos-release-scl; [imaginemiraclecentos7 ~]$ sudo yum…...
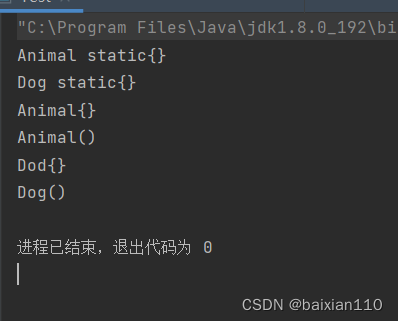
java非静态代码块和静态代码块介绍
代码块 SE.10.0…02.28 非静态普通代码块:定义在方法内部的代码块,不用任何关键字修饰,又名构造代码块、实例代码块 静态代码块:用static修饰的代码块 非静态代码块 public class Test {public static void main(String[] args…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

DBLP数据库是什么?
DBLP(Digital Bibliography & Library Project)Computer Science Bibliography是全球著名的计算机科学出版物的开放书目数据库。DBLP所收录的期刊和会议论文质量较高,数据库文献更新速度很快,很好地反映了国际计算机科学学术研…...