数据库(三)
第三章 MySQL库表操作
3.1 SQL语句基础
3.1.1 SQL简介
SQL:结构化查询语言(Structured Query Language),在关系型数据库上执行数据操作、数据检索以及数据维护的标准语言。使用SQL语句,程序员和数据库管理员可以完成如下的任务。
-
改变数据库的结构
-
更改系统的安全设置
-
增加用户对数据库或表的许可权限
-
在数据库中检索需要的信息
-
对数据库的信息进行更新
3.1.2 SQL语句分类
MySQL致力于支持全套ANSI/ISO SQL标准。在MySQL数据库中,SQL语句主要可以划分为以下几类:
DDL(Data Definition Language):数据定义语言,定义对数据库对象(库、表、列、索引)的操作。CREATE、DROP、ALTER、RENAME、 TRUNCATE等。 DML(Data Manipulation Language): 数据操作语言,定义对数据库记录的操作。INSERT、DELETE、UPDATE等。
DQL(Data Query Language)数据查询语言:SELECT语句。
DCL(Data Control Language): 数据控制语言,定义对数据库、表、字段、用户的访问权限和安全级别。GRANT、REVOKE等。 TCL(Transaction Control):事务控制。COMMIT、ROLLBACK、SAVEPOINT等。
注:可以使用help查看这些语句的帮助信息。
3.1.3 SQL语句的书写规范
-
在数据库系统中,SQL语句不区分大小写(建议用大写) 。
-
但字符串常量区分大小写。
-
SQL语句可单行或多行书写,以“;”结尾。
-
关键词不能跨多行或简写。
-
用空格和缩进来提高语句的可读性。
-
子句通常位于独立行,便于编辑,提高可读性。
sql语句注释: (1)单行注释:“--” mysql> -- select user,host from mysql.user; mysql> select user from mysql.user -- where user='root';-> ; +------------------+ | user | +------------------+ | mysql.infoschema | | mysql.session | | mysql.sys | | root | +------------------+ (2)多行注释:/* text */ mysql> select user from mysql.user /*/*> where user='root'/*> */-> ; +------------------+ | user | +------------------+ | mysql.infoschema | | mysql.session | | mysql.sys | | root | +------------------+
3.2 数据库操作
1、查看
语法:SHOW DATABASES [LIKE wild];
wild可以使用"%"和"_"通配符。
%表示匹配任意零个或多个的任意字符。
_表示单个任意字符。
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ Information_schema:主要存储了系统中的一些数据库对象信息:如用户表信息、列信息、权限信息、字符集信息、分区信息等。(数据字典表) performance_schema:主要存储数据库服务器的性能参数 mysql:存储了系统的用户权限信息及帮助信息。 sys: 5.7新增,之前版本需要手工导入。这个库是通过视图的形式把information_schema和performance_schema结合起来,查询出更加令人容易理解的数据。 test:系统自动创建的测试数据库,任何用户都可以使用。 mysql> show databases like '__s%'; +-----------------+ | Database (__s%) | +-----------------+ | mysql | | sys | +-----------------+
2、创建
语法:CREATE DATABASE [IF NOT EXISTS] 数据库名;
用给定的名字创建一个数据库,如果数据库已经存在,则报错。
#查看创建数据库的语句:SHOW CREATE DATABASE <数据库名>; mysql> show create database mysql; +----------+---------------------------------------------------------------------------------------------------------------------------------+ | Database | Create Database | +----------+---------------------------------------------------------------------------------------------------------------------------------+ | mysql | CREATE DATABASE `mysql` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ | +----------+---------------------------------------------------------------------------------------------------------------------------------+ mysql> create database chap03; Query OK, 1 row affected (0.00 sec) mysql> show create database chap03; +----------+----------------------------------------------------------------------------------------------------------------------------------+ | Database | Create Database | +----------+----------------------------------------------------------------------------------------------------------------------------------+ | chap03 | CREATE DATABASE `chap03` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ | +----------+----------------------------------------------------------------------------------------------------------------------------------+
3、删除
语法:DROP DATABASE [IF EXISTS]数据库名;
删除数据库中得所有表和数据库(慎用)
mysql> drop database chap03;
4、切换
语法:USE 数据库名;
把指定数据库作为默认(当前)数据库使用,用于后续语句。
mysql> use mysql # 查看当前连接的数据库 mysql> select database(); +------------+ | database() | +------------+ | mysql | +------------+ #设置提示符显示当前数据库名称 [root@mysql8-0-30 mysql]# vim /etc/my.cnf.d/mysql-server.cnf [mysql] prompt=mysql8.0 [\\d]> [root@mysql8-0-30 mysql]# systemctl restart mysqld [root@mysql8-0-30 mysql]# mysql -uroot -pAdmin123! mysql mysql8.0 [mysql]>
5、执行系统命令
语法:system 命令
mysql> system date 2023年 02月 06日 星期一 15:57:52 CST mysql> system ls / afs boot etc lib media opt root sbin sys usr bin dev home lib64 mnt proc run srv tmp var
3.3 MySQL 字符集
MySQL字符集包括字符集(CHARACTER)和校对规则(COLLATION)两个概念:字符集(CHARACTER)是一套编码,校对规则(COLLATION)是在字符集内用于比较字符的一套规则。
mysql字符集:latin1支持西欧字符、希腊字符等gbk支持中文简体字符big5支持中文繁体字符utf8几乎支持世界所有国家的字符。utf8mb4是真正意义上的utf-8
#查看字符集 mysql> show variables like 'character%'; +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8mb4 | | character_set_connection | utf8mb4 | | character_set_database | utf8mb4 | | character_set_filesystem | binary | | character_set_results | utf8mb4 | | character_set_server | utf8mb4 | | character_set_system | utf8mb3 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+ #修改mysql默认字符集 1.在[mysqld]下添加character-set-server=utf8init_connect = 'SET NAMES utf8' 2.在[client]下添加default-character-set=utf8 3. 5.8开始,官方建议使用utf8mb4。
| character_set_client | utf8mb4 | mysql客户端字符集 | character_set_connection | utf8mb4 | 数据通信链路字符集,当mysql客户端向服务器发送请求时,客户端的请求数据以该字符集进行编码。 | character_set_database | utf8mb4 | 数据库字符集 | character_set_filesystem | binary | MySQL服务器文件系统字符集,该值是固定的binary | character_set_results | utf8mb4 | 结果集的字符集,MySQL服务器向mysql客户端返回执行结果时,执行结果以该字符集进行编码。 | character_set_server | utf8mb4 | mysql服务器实例字符集 | character_set_system | utf8mb3 | 元数据(字段名、表名、数据库名等)的字符集 | character_sets_dir | /usr/share/mysql/charsets/ | 字符集安装的目录
#查看当前mysql服务实例支持的校对规则 mysql> show collation; | Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute | | armscii8_bin | armscii8 | 64 | | Yes | 1 | PAD SPACE |
Collation 字符集校对规则名称。MySQL校对规则名称是:以对应的字符集名称开头,以国家名居中(或以general居中),以ci、cs或bin结尾。【ci表示大小写不敏感,cs表示大小写敏感,bin表示按二进制编码值比较。】 Charset 与字符集校对规则关联的字符集名称 Id 字符集校对规则编号 Default 是不是对应字符集默认的校对规则 Compiled 是否有将此字符集校对规则集成到服务器中 Sortlen 这个与字符串表示的字符集所需要的内存数量有关 Pad_attribute 控制字符串尾部空格处理方式。PAD SPACE:在排序和比较运算中,忽略字符串尾部空格;NO PAD:在排序和比较运算中,字符串尾部空格当成普通字符,不能忽略。
3.3.1 utf8和utf8mb4的区别
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。
既然utf8能够存下大部分中文汉字,那为什么还要使用utf8mb4呢? 原来mysql支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多文种平面(BMP)。也就是说,任何不在基本多文本平面的 Unicode字符,都无法使用 Mysql 的 utf8 字符集存储。包括 Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和很多不常用的汉字,以及任何新增的 Unicode 字符,如表情等等(utf8的缺点)。
因此在8.0之后,建议大家使用utf8mb4这种编码。
3.4 数据库对象
数据库对象的命名规则:
-
必须以字母开头
-
可包括数字和特殊字符(_和$)
-
不要使用MySQL的保留字
-
同一Schema下的对象不能同名
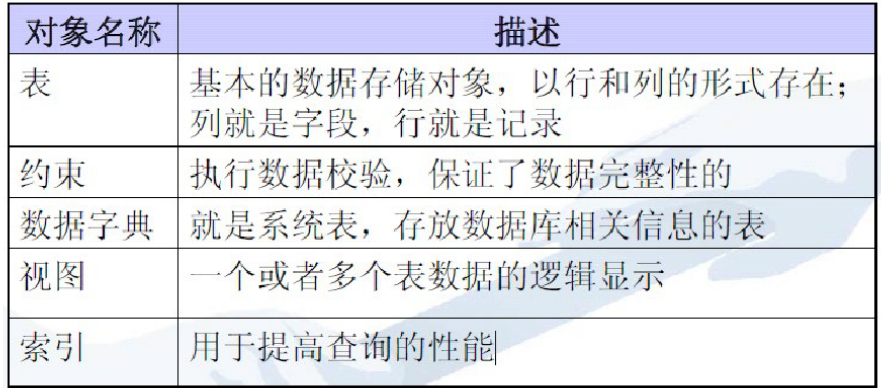
3.5 表的基本操作
3.5.1 创建表
数据表的每行称为一条记录(record);每一列称为一个字段(field)【列之间以英文逗号隔开】。
简单语法:在当前数据库中创建一张表CREATE TABLE 表名(列名 列数据类型,列名 列数据类型);
mysql8.0 [chap03]>create table t1(id int,name char(30));
3.5.2 数据类型
在 MySQL 中,有三种主要的类型:文本、数值和日期/时间类型。
文本类型:
| 数据类型 | 描述 |
|---|---|
| CHAR(size) | 保存固定长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的长度。最多 255 个字符。 |
| VARCHAR(size) | 保存可变长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的最大长度。最多 255 个字符。 注释:如果值的长度大于 255,则被转换为 TEXT 类型。 |
| TINYTEXT | 存放最大长度为 255 个字符的字符串。 |
| TEXT | 存放最大长度为 65,535 个字符的字符串。 |
| BLOB | 用于 BLOBs (Binary Large OBjects),二进制形式的长文本数据。存放最多 65,535 字节的数据。 |
| MEDIUMTEXT | 存放最大长度为 16,777,215 个字符的字符串。 |
| MEDIUMBLOB | 用于 BLOBs (Binary Large OBjects),二进制形式的中等长度文本数据。存放最多 16,777,215 字节的数据。 |
| LONGTEXT | 存放最大长度为 4,294,967,295 个字符的字符串。 |
| LONGBLOB | 用于 BLOBs (Binary Large OBjects),二进制形式的极大文本数据。存放最多 4,294,967,295 字节的数据。 |
| ENUM(x,y,z,etc.) | 允许你输入可能值的列表。可以在 ENUM 列表中列出最大 65535 个值。如果列表中不存在插入的值,则插入空值。 注释:这些值是按照你输入的顺序存储的。 可以按照此格式输入可能的值: ENUM('X','Y','Z') |
| SET | 与 ENUM 类似, SET 最多只能包含 64 个列表项,不过 SET 可存储一个以上的值。 |
数值类型:
| 类型 | 用途 | 存储需求 | 范围(有符号) | 范围(无符号) |
|---|---|---|---|---|
| TINYINT | 小整数值 | 1 Bytes | (-128,127) | (0,255) |
| SMALLINT | 大整数值 | 2 Bytes | (-32 768,32 767) | (0,65 535) |
| MEDIUMINT | 大整数值 | 3 Bytes | (-8 388 608,8 388 607) | (0,16 777 215) |
| INT或INTEGER | 大整数值 | 4 Bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) |
| BIGINT | 极大整数值 | 8 Bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) |
| 类型 | 用途 | 存储需求 | 范围(有符号) | 范围(无符号) |
|---|---|---|---|---|
| FLOAT(size,d) | 带有浮动小数点的小数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 | 4Byte | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) |
| DOUBLE(size,d) | 带有浮动小数点的大数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 | 8Byte | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) |
| DECIMAL(size,d) | 作为字符串存储的 DOUBLE 类型,允许固定的小数点。 | (size+2)Byte |
注意:这些数值类型拥有额外的选项 UNSIGNED。通常,整数可以是负数或正数。如果添加 UNSIGNED属性,那么范围将从 0 开始,而不是某个负数。
日期/时间类型:
| 数据类型 | 存储需求 | 描述 |
|---|---|---|
| DATE | 3Bytes | 日期。格式: YYYY-MM-DD 注释:支持的范围是从 '1000-01-01' 到 '9999-12-31' |
| DATETIME | 8Bytes | 日期和时间的组合。格式: YYYY-MM-DD HH:MM:SS 注释:支持的范围是'1000-01-01 00:00:00' 到 '9999-12- 31 23:59:59' |
| TIMESTAMP | 4Bytes | 时间戳。 TIMESTAMP 值使用 Unix 纪元('1970-01-01 00:00:00' UTC) 至今的描述来存储。格式: YYYY-MM-DD HH:MM:SS 注释:支持的范围是从 '1970-01-01 00:00:01' UTC 到 '2038-01-19 03:14:07' UTC |
| TIME | 3Bytes | 时间。格式: HH:MM:SS 注释:支持的范围是从 '-838:59:59' 到 '838:59:59' |
| YEAR | 1Bytes | 2 位或 4 位格式的年。 注释: 4 位格式所允许的值: 1901 到 2155。 2 位格式所允许的值: 70 到69,表示从 1970 到 2069 |
常用数据类型:
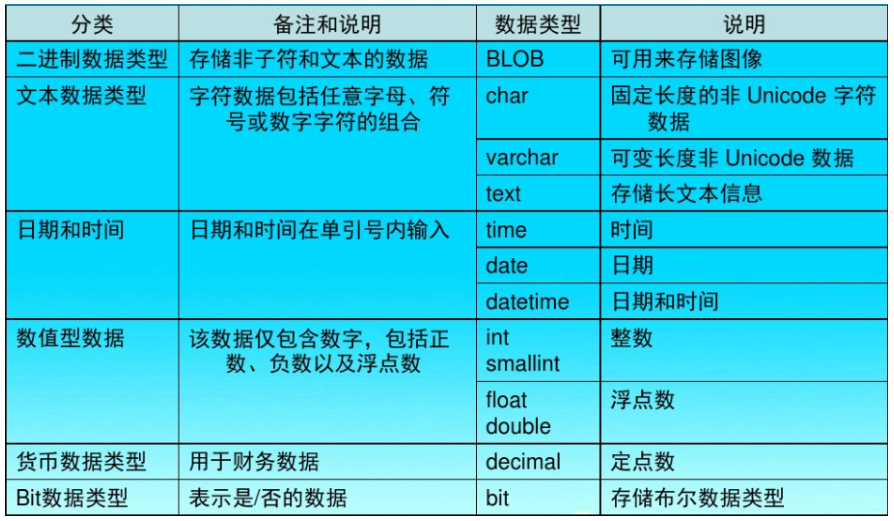
3.5.3 查看表
#查看某数据库中的所有表 语法:SHOW TABLES[FROM 数据库名][LIKE wild]; mysql8.0 [chap03]>show tables from mysql;
#显示当前数据库中已有的数据表的信息【结构和创建信息】
1、语法:{DESCRIBE|DESC} 表名[列名];
mysql8.0 [chap03]>describe mysql.user;
mysql8.0 [chap03]>desc mysql.user;
2、语法:show columns from 表名称;
mysql8.0 [chap03]>show columns from mysql.user;
#查看数据表中各列的信息 语法:SHOW CREATE TABLE 表名\G mysql8.0 [chap03]>show create table mysql.user\G 说明:\G表示向mysql服务器发送命令,垂直显示结果
3.5.4 删除表
#删除指定的表 语法:DROP TABLE [IF EXISTS] 表名; mysql8.0 [chap03]>drop table t1;
3.5.5 修改表的结构
mysql8.0 [chap03]>create table t1(id int,name char(30)); mysql8.0 [chap03]>desc t1; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int | YES | | NULL | | | name | char(30) | YES | | NULL | | +-------+----------+------+-----+---------+-------+ #修改列类型:ALTER TABLE 表名 MODIFY 列名 列类型; mysql8.0 [chap03]>alter table t1 modify name varchar(30); Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql8.0 [chap03]>desc t1; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int | YES | | NULL | | | name | varchar(30) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+#增加列:ALTER TABLE 表名 ADD 列名 列类型; mysql8.0 [chap03]>alter table t1 add bir date; #删除列:ALTER TABLE 表名 DROP 列名; mysql8.0 [chap03]>alter table t1 drop bir; #修改列名:ALTER TABLE 表名 CHANGE 旧列名 新列名 列类型; mysql8.0 [chap03]>alter table t1 change id user_id int; #更改表名: 方式1:ALTER TABLE 表名 RENAME 新表名; 方式2:RENAME TABLE 表名 TO 新表名; mysql8.0 [chap03]>alter table t1 rename t2; mysql8.0 [chap03]>rename table t2 to t3; mysql8.0 [chap03]>show tables; +------------------+ | Tables_in_chap03 | +------------------+ | t3 | +------------------+
3.5.6 复制表的结构
#复制一个表结构的实现方法有两种: 方法1:在create table语句的末尾添加like子句,可以将源表的表结构复制到新表中,语法:create table 新表名 like 源表 mysql8.0 [chap03]>create table t4 like t3; 方法2:在create table语句的末尾添加一个select语句,可以实现表结构的复制,甚至可以将源表的表记录拷贝到新表中。 语法:create table 新表名 select * from 源表 mysql8.0 [chap03]>create table t5 select * from t4; 方法3:如果已经存在一张结构一致的表,复制数据 语法:insert into 表名 select * from 原表;
3.5.7 表的约束
约束是在表上强制执行的数据校验规则。约束主要用于保证数据库的完整性。当表中数据有相互依赖性时,可以保护相关的数据不被删除。
可以在创建表时规定约束(通过 CREATE TABLE 语句),或者在表创建之后通过 ALTER TABLE 语句规定约束。
-
根据约束数据列的限制,约束可分为:
-
单列约束:每个约束只约束一列。
-
多列约束:每个约束可约束多列数据。
-
-
根据约束的作用范围,约束可分为:
-
列级约束:只能作用在一个列上,跟在列的定义后面,语法:列定义 约束类型
-
表级约束:可以作用在多个列上,不与列一起,而是单独定义
语法:[CONSTRAINT 约束名] 约束类型(列名) 约束名的取名规则,推荐采用:表名_列名_约束类型 例如:alter table 表名 add constraint 约束名 约束类型(要约束的列名) 表级约束类型有四种:主键、外键、唯一、检查
-
-
根据约束起的作用,约束可分为:
NOT NULL 非空约束,规定某个字段不能为空 UNIQUE 唯一约束,规定某个字段在整个表中是唯一的 PRIMARY KEY 主键(非空且唯一)约束 FOREIGN KEY 外键约束 CHECK 检查约束 DEFAULT 默认值约束
表的约束示例:
1、非空约束(NOT NULL)
列级约束,只能使用列级约束语法定义。确保字段值不允许为空。
mysql8.0 [chap03]>create table t6(-> id int,-> name char(30) not null-> ); 注意:所有数据类型的值都可以是NULL,空字符串不等于NULL,0也不等于NULL。 #删除NOT NULL约束,alter table 表名 modify 列名 类型; mysql8.0 [chap03]>alter table t6 modify name char(30);
2、唯一约束(UNIQUE)
-
唯一性约束条件确保所在的字段或者字段组合不出现重复值。
-
唯一性约束条件的字段允许出现多个NULL。
-
同一张表内可建多个唯一约束。
-
唯一约束可由多列组合而成。
-
建唯一约束时MySQL会为之建立对应的索引。
-
如果不给唯一约束起名,该唯一约束默认与列名相同。
mysql8.0 [chap03]>create table t7(-> id int unique,-> name char(30) not null-> ); mysql8.0 [chap03]>desc t7; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int | YES | UNI | NULL | | | name | char(30) | NO | | NULL | | +-------+----------+------+-----+---------+-------+ 2 rows in set (0.00 sec)t #删除UNIQUE约束,alter table 表名 drop index 唯一约束名; mysql8.0 [chap03]>alter table t7 drop index id;
3、主键约束(PRIMARY KEY)
主键从功能上看相当于非空且唯一,一个表中只允许一个主键,主键是表中唯一确定一行数据的字段,主键字段可以是单字段或者是多字段的组合。 当建立主键约束时,MySQL为主键创建对应的索引。
mysql8.0 [chap03]>mysql8.0 [chap03]>create table t8(-> id int primary key,-> name char(30) not null-> ); Query OK, 0 rows affected (0.06 sec) mysql8.0 [chap03]>desc t8; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int | NO | PRI | NULL | | | name | char(30) | NO | | NULL | | +-------+----------+------+-----+---------+-------+ #自动增长:auto_increment :自动增长,为新的行产生唯一的标识,一个表只能有一个auto_increment,且该属性必须为主键的一部分。auto_increment的属性可以是任何整数类型。 mysql8.0 [chap03]>create table t_auto(id int primary key auto_increment); #删除PRIMARY KEY约束,alter table 表名 drop primary key; mysql8.0 [chap03]>alter table t8 drop primary key;
4、外键约束(FOREIGN KEY)
外键是构建于一个表的两个字段或者两个表的两个字段之间的关系,外键确保了相关的两个字段的两个关系。 子(从)表外键列的值必须在主表参照列值的范围内,或者为空(也可以加非空约束,强制不允许为空)。 当主表的记录被子表参照时,主表记录不允许被删除。 外键参照的只能是主表主键或者唯一键,保证子表记录可以准确定位到被参照的记录。
语法:FOREIGN KEY (外键列名)REFERENCES 主表(参照列) mysql8.0 [chap03]>create table tb_dept(dept_id int primary key,name char(30)); mysql8.0 [chap03]>create table tb_employee(employee_id int primary key,name char(30),dept_id int,foreign key(dept_id) references tb_dept(dept_id)); #删除FOREIGN KEY约束,alter table 表名 drop foreign key 约束名; mysql8.0 [chap03]>show create table tb_employee\G *************************** 1. row ***************************Table: tb_employee Create Table: CREATE TABLE `tb_employee` (`employee_id` int NOT NULL,`name` char(30) DEFAULT NULL,`dept_id` int DEFAULT NULL,PRIMARY KEY (`employee_id`),KEY `dept_id` (`dept_id`),CONSTRAINT `tb_employee_ibfk_1` FOREIGN KEY (`dept_id`) REFERENCES `tb_dept` (`dept_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci mysql8.0 [chap03]>alter table tb_employee drop foreign key tb_employee_ibfk_1;
5、检查约束(CHECK )
# 注意检查约束在8.0之前,MySQL默认但不会强制的遵循check约束(写不报错,但是不生效,需要通过触发器完成),8之后就开始正式支持这个约束了。
mysql8.0 [chap03]>create table t9(-> id int,-> age int check(age > 18),-> gender char(1) check(gender in ('M','F'))-> );
#删除检查约束
mysql8.0 [chap03]>show create table t9;
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t9 | CREATE TABLE `t9` (`id` int DEFAULT NULL,`age` int DEFAULT NULL,`gender` char(1) DEFAULT NULL,CONSTRAINT `t9_chk_1` CHECK ((`age` > 18)),CONSTRAINT `t9_chk_2` CHECK ((`gender` in (_utf8mb4'M',_utf8mb4'F')))
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
mysql8.0 [chap03]>alter table t9 drop check t9_chk_2;
6、 默认值约束(DEFAULT)
可以使用default关键字设置每一个字段的默认值。
#设置默认值约束 mysql8.0 [chap03]>create table t10(-> id int unique,-> name char(30) not null,-> gender char(1) default 'M',-> primary key(id)-> ); #删除默认值约束 mysql8.0 [chap03]>alter table t10 modify gender char;
3.5.8 数据库字典
由information_schema数据库负责维护: tables-存放数据库里所有的数据表、以及每个表所在数据库。 schemata-存放数据库里所有的数据库信息 views-存放数据库里所有的视图信息。 columns-存放数据库里所有的列信息。 triggers-存放数据库里所有的触发器。 routines-存放数据库里所有存储过程和函数。 key_column_usage-存放数据库所有的主外键 table_constraints-存放各个表的约束。 statistics-存放了数据表的索引。
3.5.9 存储引擎
MySQL中的数据用各种不同的技术存储在文件(或者内存)中, 每种技术都使用不同的存储机制、 索引技巧、 锁定水平。这些不同的技术以及配套的相关功能在MySQL中被称作存储引擎(也称作表类型)。
数据库存储引擎是数据库底层软件组件,数据库管理系统使用数据引擎进行创建、查询、更新和删除数据操作。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎还可以获得特定的功能。
现在许多数据库管理系统都支持多种不同的存储引擎。MySQL 的核心就是存储引擎。
InnoDB 事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键。应用于对事务的完整性要求高,在并发条件下要求数据的一致性的情况。 MySQL 5.5.5 之后,InnoDB 作为默认存储引擎。
MyISAM 是基于 ISAM 的存储引擎,并对其进行扩展,是在 Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM 拥有较高的插入、查询速度,但不支持事务。应用于以读写操作为主, 很少更新 、 删除 , 并对事务的完整性、 并发性要求不高的情况。
MEMORY 存储引擎将表中的数据存储到内存中,为查询和引用其他数据提供快速访问。
MEMORY:表的数据存放在内存中,访问效率高 ,但一旦服务关闭,表中的数据全部丢失。
MERGE: 是一组MyISAM表的组合。 可以突破对单个MyISAM表大小的限制, 并提高访问效率。
默认情况下, 创建表不指定表的存储引擎, 则会使用配置文件my.cnf中 default-storage-engine=InnoDB指定的存储引擎。
#在创建表时, 可以指定表的存储引擎: CREATE TABLE (...) ENGINE=InnoDB;
#完整的创建表的命令语法 CREATE TABLE 表名 (列名 列类型 [primary key AUTO_INCREMENT] [DEFAULT 默认值][列约束]...[表约束] ) [ENGINE=存储引擎类型] [DEFAULT] CHARSET=字符集; 列类型: 该列的数据的存储类型 AUTO_INCREMENT: 自动增长,只能是数值类型的列 DEFAULT 默认值:设置该列的默认值 列约束:对列的一些限制 ENGINE: 表类型, 也叫表的存储引擎 CHARSET: 设置表的字符集
3.5.10 表物理存储结构
表的物理存储结构:
MyISAM(一种引擎)的表: mysql8.0 [chap03]>create table test(id int)engine=myisam; [root@node1 ~]# cd /var/lib/mysql/chap03/ [root@mysql8-0-30 chap03]# ll test* #表结构元数据 -rw-r-----. 1 mysql mysql 1630 2月 7 01:21 test_414.sdi # 数据信息文件,存储数据信息 -rw-r-----. 1 mysql mysql 0 2月 7 01:21 test.MYD # 索引信息文件,index -rw-r-----. 1 mysql mysql 1024 2月 7 01:21 test.MYI InnoDB(默认的存储引擎)的表: [root@node2 employess]# ls -l t4* #innodb引擎开启了独立表空间产生的存放该表的数据和索引的文件 -rw-r----- 1 mysql mysql 98304 7月 16 20:32 t4.ibd ttt
3.6 MySQL用户授权
3.6.1 密码策略
#mysql8.0会生成临时密码,查看临时密码
[root@mysql8-0-30 ~]# awk '/temporary password/ {print $NF}' /var/log/mysqld.log
[root@mysql8-0-30 ~]# grep 'password' /var/log/mysqld.log
#查看数据库当前密码策略: mysql8.0 [chap03]>show VARIABLES like "%password%";
3.6.2 用户授权和撤销授权
MySql8有新的安全要求,不能像之前的版本那样一次性创建用户并授权。需要先创建用户,再进行授权操作。
mysql8.0 [chap03]>grant all privileges on *.* to 'xiaoming'@'%'; ERROR 1410 (42000): You are not allowed to create a user with GRANT
1、创建用户
#创建新用户,语法:create user 'username'@'host' identified by 'password'; 说明:username为自定义的用户名,host为客户端的域名或者IP,如果host为'%'时表示为任意IP,password为密码。 mysql8.0 [mysql]>create user xiaoming@'%' identified by '123'; mysql8.0 [mysql]>select user,host,authentication_string from mysql.user; #删除用户 mysql8.0 [mysql]>drop user xiaoming@'%'; #注意,如果删除用户时显示如下提示,需要执行该语句【mysql8.0 [(none)]>grant system_user on *.* to root@'%';】 mysql8.0 [mysql]>drop user xiaoming; ERROR 1227 (42000): Access denied; you need (at least one of) the SYSTEM_USER privilege(s) for this operation
2、授权和回收权限
授予权限的原则: (1)只授予能满足需要的最小权限 ,防止用户干坏事。比如用户只是需要查询,那就只给 select 权限就可以了,不要给用户赋予update 、 insert 或者 delete 权限 (2)创建用户的时候限制用户的登录主机 ,一般是限制成指定 IP 或者内网 IP 段。 (3)为每个用户设置满足密码复杂度的密码 。 (4)定期清理不需要的用户 ,回收权限或者删除用户。
#查看授予用户的权限 mysql8.0 [mysql]>show grants; mysql8.0 [mysql]>show grants for root@'%'; mysql8.0 [mysql]>select * from mysql.user; #查看某个用户从哪个服务器ip地址连接对某个数据库的操作权限,这三个字段的组合构成了db表的主键。 mysql8.0 [mysql]>select * from mysql.db; #查看用户对单个表的权限 mysql8.0 [mysql]>select * from mysql.tables_priv;
授权语法:grant 权限列表 on 库名.表名 to 用户名@'主机' [with GRANT option];
| mysql用户常用权限列表 | 说明 |
|---|---|
| all 或者all privileges | 授予用户所有权限 |
| create | 授予用户创建新数据库和表的权限 |
| drop | 授予用户删除数据库和表的权限 |
| delete | 授予用户删除表中的行的权限 |
| alter | 授予用户修改表结构的权限 |
| insert | 授予用户在表中插入行(add)的权限 |
| select | 授予用户运行select命令以从表中读取数据的权限 |
| update | 授予用户更新表中的数据的权限 |
mysql8.0 [mysql]>grant all privileges on *.* to 'xiaoming'@'%' with grant option; mysql8.0 [mysql]>flush privileges; #说明:*.*中第一个*表示所有数据库,第二个*表示所有数据表;with grant option表示授予xiaoming用户grant命令(该命令可以给别的用户授权)的权限 mysql8.0 [mysql]>select user,grant_priv from mysql.user; +------------------+------------+ | user | grant_priv | +------------------+------------+ | root | Y | | xiaoming | Y | | mysql.infoschema | N | | mysql.session | N | | mysql.sys | N | +------------------+------------+ mysql8.0 [mysql]>create user xiaohong@'%' identified by '123'; Query OK, 0 rows affected (0.01 sec) mysql8.0 [mysql]>select select_priv,user from mysql.user; +-------------+------------------+ | select_priv | user | +-------------+------------------+ | Y | root | | N | xiaohong | | Y | xiaoming | | Y | mysql.infoschema | | N | mysql.session | | N | mysql.sys | +-------------+------------------+ 6 rows in set (0.00 sec) mysql8.0 [mysql]>grant select on mysql.user to xiaohong@'%'; mysql8.0 [mysql]>select * from tables_priv; +-----------+-------+---------------+------------+--------------------+---------------------+------------+-------------+ | Host | Db | User | Table_name | Grantor | Timestamp | Table_priv | Column_priv | +-----------+-------+---------------+------------+--------------------+---------------------+------------+-------------+ | % | mysql | xiaohong | user | xiaoming@localhost | 2023-02-08 00:56:32 | Select | | | localhost | mysql | mysql.session | user | boot@ | 2023-02-05 18:30:53 | Select | | | localhost | sys | mysql.sys | sys_config | root@localhost | 2023-02-05 18:30:53 | Select | | +-----------+-------+---------------+------------+--------------------+---------------------+------------+-------------+ mysql8.0 [mysql]>select * from db where user='xiaohong'; +------+--------+----------+-------------+-------------+-------------+-------------+-------------+-----------+------------+-----------------+------------+------------+-----------------------+------------------+------------------+----------------+---------------------+--------------------+--------------+------------+--------------+ | Host | Db | User | Select_priv | Insert_priv | Update_priv | Delete_priv | Create_priv | Drop_priv | Grant_priv | References_priv | Index_priv | Alter_priv | Create_tmp_table_priv | Lock_tables_priv | Create_view_priv | Show_view_priv | Create_routine_priv | Alter_routine_priv | Execute_priv | Event_priv | Trigger_priv | +------+--------+----------+-------------+-------------+-------------+-------------+-------------+-----------+------------+-----------------+------------+------------+-----------------------+------------------+------------------+----------------+---------------------+--------------------+--------------+------------+--------------+ | % | chap03 | xiaohong | Y | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | +------+--------+----------+-------------+-------------+-------------+-------------+-------------+-----------+------------+-----------------+------------+------------+-----------------------+------------------+------------------+----------------+---------------------+--------------------+--------------+------------+--------------+ mysql8.0 [mysql]>show grants for xiaohong@'%'; +--------------------------------------------------+ | Grants for xiaohong@% | +--------------------------------------------------+ | GRANT USAGE ON *.* TO `xiaohong`@`%` | | GRANT SELECT ON `chap03`.* TO `xiaohong`@`%` | | GRANT SELECT ON `mysql`.`user` TO `xiaohong`@`%` | +--------------------------------------------------+ #usage:连接(登录)权限,建立一个用户,就会自动授予usage权限(默认授予)。该usage权限并不能被revoke(回收)。 #收回权限(不包含赋权权限) REVOKE ALL PRIVILEGES ON *.* FROM username; #收回赋权权限 REVOKE GRANT OPTION ON *.* FROM username; mysql8.0 [(none)]>revoke grant option on *.* from xiaoming@'%'; Query OK, 0 rows affected (0.00 sec) mysql8.0 [(none)]>select grant_priv,user from mysql.user; +------------+------------------+ | grant_priv | user | +------------+------------------+ | Y | root | | N | xiaohong | | N | xiaoming | | N | mysql.infoschema | | N | mysql.session | | N | mysql.sys | +------------+------------------+ mysql8.0 [(none)]>revoke all on *.* from xiaoming; #操作完后重新刷新权限 mysql8.0 [(none)]>flush privileges; mysql8.0 [(none)]>revoke select on mysql.user from xiaohong;
第四章 MySQL之sql语句
有关数据表的DML操作
INSERT INTO
DELETE、TRUNCATE
UPDATE
SELECT
条件查询
查询排序
聚合函数
分组查询
4.1 INSERT语句
#在表里面插入数据:默认情况下,一次插入操作只插入一行 方式1: INSERT [INTO] 表名 [(column [, column...])] VALUES(value [, value...]); 方式2: insert [into] 表名 set 字段1=值1, 字段2=值2 #一次性插入多条记录: INSERT [INTO] table [(column [, column...])] VALUES(value [, value...]),(value [, value...]) 注: 1、如果为每列都指定值,则表名后不需列出插入的列名 2、可以使用如下方式一次插入多行:insert into 表名[(列名,…)] select 语句 3、如果需要插入其他特殊字符,应该采用\转义字符做前缀
示例: mysql8.0 [chap04]>create table t1(-> id int primary key,-> name char(30) not null,-> birthday date-> ); mysql8.0 [chap04]>insert t1 values (1,'xiaoming',20000101); mysql8.0 [chap04]>insert into t1 values (2,'xiaohong',20000102),(3,'xiaolan',20000103),(4,'xiaohei',20000104); mysql8.0 [chap04]>insert into t1(id,name) values (5,'xiaolv'),(6,'xiaobai'); mysql8.0 [chap04]>insert into t1 set id=6,name='xiaozi';
4.2 REPLACE语句
replace语句的语法格式有三种语法格式。 语法格式1:replace [into] 表名 [(字段列表)] values (值列表) 语法格式2:replace [into] 目标表名[(字段列表1) select (字段列表2) from 源表 where 条件表达式语法格式3:replace [into] 表名 set 字段1=值1, 字段2=值2
REPLACE与INSERT语句区别:
replace语句的功能与insert语句的功能基本相同,不同之处在于:使用replace语句向表插入新记录时,如果新记录的主键值或者唯一性约束的字段值与已有记录相同,则已有记录先被删除(注意:已有记录删除时也不能违背外键约束条件),然后再插入新记录。
使用replace的最大好处就是可以将delete和insert合二为一(效果相当于更新),形成一个原子操作,这样就无需将delete操作与insert操作置于事务中了
mysql8.0 [chap04]>replace t1 (id,name,birthday) values (8,'xiaoqing',20010101); mysql8.0 [chap04]>replace t1 values(5,'xiaolv',20000105); mysql8.0 [chap04]>select * from t1; +----+----------+------------+ | id | name | birthday | +----+----------+------------+ | 1 | xiaoming | 2000-01-01 | | 2 | xiaohong | 2000-01-02 | | 3 | xiaolan | 2000-01-03 | | 4 | xiaohei | 2000-01-04 | | 5 | xiaolv | 2000-01-05 | | 6 | xiaobai | NULL | | 7 | xiaozi | NULL | | 8 | xiaoqing | 2001-01-01 | +----+----------+------------+ mysql8.0 [chap04]>replace t1(id,name,birthday) values (9,'zhouyi',20010102),(10,'zhouer',20010102);
4.3 UPDATE语句
UPDATE 表名 SET column = value [, column = value] [WHERE condition];
修改可以一次修改多行数据,修改的数据可用where子句限定,where子句里是一个条件表达式,只有符合该条件的行才会被修改。没有where子句意味着where字句的表达式值为true。也可以同时修改多列,多列的修改中间采用逗号(,)隔开。
mysql8.0 [chap04]>select * from t1; +----+----------+------------+ | id | name | birthday | +----+----------+------------+ | 1 | xiaoming | 2000-01-01 | | 2 | xiaohong | 2000-01-02 | | 3 | xiaolan | 2000-01-03 | | 4 | xiaohei | 2000-01-04 | | 5 | xiaolv | 2000-01-05 | | 6 | xiaobai | NULL | | 7 | xiaozi | NULL | | 8 | xiaoqing | 2001-01-01 | | 9 | zhouyi | 2001-01-02 | | 10 | zhouer | 2001-01-02 | +----+----------+------------+ 10 rows in set (0.00 sec) mysql8.0 [chap04]>update t1 set birthday=20010101 where id=6; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0
4.4 delete和TRUNCATE语句
DELETE FROM table_name [where 条件]; TRUNCATE TABLE table_name
DROP、TRUNCATE、DELETE的区别:
delete:删除数据,保留表结构,可以回滚,如果数据量大,很慢。
truncate: 删除所有数据,保留表结构,不可以回滚,一次全部删除所有数据,速度相对很快。
drop: 删除数据和表结构,删除速度最快。
mysql8.0 [chap04]>delete from t1 where id=7; Query OK, 1 row affected (0.00 sec) mysql8.0 [chap04]>create table t2 select * from t1; mysql8.0 [chap04]>truncate table t2;
4.5 SELECT语句
1、简单的SELECT语句:
#简单的SELECT语句:
SELECT {*, column [alias],...}
FROM table;
说明:
select *表示所有列。
FROM 提供数据源(表名/视图名)
mysql8.0 [chap04]>select * from t1; mysql8.0 [chap04]>select id,name from t1;
2、SELECT语句中的算术表达式:
对数值型数据列、变量、常量可以使用算数操作符创建表达式(+ - * /) 对日期型数据列、变量、常量可以使用部分算数操作符创建表达式(+ -) 运算符不仅可以在列和常量之间进行运算,也可以在多列之间进行运算。
运算符的优先级: 乘法和除法的优先级高于加法和减法; 同级运算的顺序是从左到右; 表达式中使用括号可强行改变优先级的运算顺序;
mysql8.0 [chap04]>create table t3(-> id int primary key,-> name char(30) not null,-> salary int,-> performance decimal(3,2)-> ); mysql8.0 [chap04]>insert into t3 values(2,'xiaohong',8000,1.594),(2,'xiaohong',8000,1.594),(3,'xiaobai',9000,1.789); mysql8.0 [chap04]>select * from t3; +----+----------+--------+-------------+ | id | name | salary | performance | +----+----------+--------+-------------+ | 1 | xiaoming | 10000 | 1.34 | | 2 | xiaohong | 8000 | 1.59 | | 3 | xiaobai | 9000 | 1.79 | +----+----------+--------+-------------+ 3 rows in set (0.00 sec) mysql8.0 [chap04]>select id,name,salary*12,salary*performance from t3; +----+----------+-----------+--------------------+ | id | name | salary*12 | salary*performance | +----+----------+-----------+--------------------+ | 1 | xiaoming | 120000 | 13400.00 | | 2 | xiaohong | 96000 | 12720.00 | | 3 | xiaobai | 108000 | 16110.00 | +----+----------+-----------+--------------------+
补充说明:MySQL的+默认只有一个功能:运算符 SELECT 100+80; # 结果为180 SELECT '123'+80; # 只要其中一个为数值,则试图将字符型转换成数值,转换成功做预算,结果为203 SELECT 'abc'+80; # 转换不成功,则字符型数值为0,结果为80 SELECT 'This'+'is'; # 转换不成功,结果为0 SELECT NULL+80; # 只要其中一个为NULL,则结果为NULL
NULL值的使用:
空值是指不可用、未分配的值 空值不等于零或空格 任意类型都可以支持空值 包括空值的任何算术表达式都等于空 字符串和null进行连接运算,得到也是null
补充说明:
安全等于运算符<=> (1)可作为普通运算符的=,两个值进行比较时,2<=>2结果是1,2<=>3是0; mysql8.0 [chap04]>select 2=2; +-----+ | 2=2 | +-----+ | 1 | +-----+ 1 row in set (0.00 sec) mysql8.0 [chap04]>select 2<=>2; +-------+ | 2<=>2 | +-------+ | 1 | +-------+ (2)也可以用于判断是否是NULL;where salary is NULL等价于where salary <=>NULL;where salary is not NULL等价于where not salary <=>null; mysql8.0 [chap04]>insert t1(id,name) values(11,'zhousan'); mysql8.0 [chap04]>select * from t1 where birthday<=>null; mysql8.0 [chap04]>select * from t1 where birthday is null; +----+---------+----------+ | id | name | birthday | +----+---------+----------+ | 11 | zhousan | NULL | +----+---------+----------+ mysql8.0 [chap04]>select * from t1 where birthday is not null; mysql8.0 [chap04]>select * from t1 where not birthday<=>null;
3、定义字段的别名:
改变列的标题头 用于表示计算结果的含义 作为列的别名 如果别名中使用特殊字符,或者是强制大小写敏感,或有空格时,都可以通过为别名添加加双引号实现。
mysql8.0 [chap04]>select name as "姓名",id,birthday "生日" from t1; +----------+----+------------+ | 姓名 | id | 生日 | +----------+----+------------+ | xiaoming | 1 | 2000-01-01 | | xiaohong | 2 | 2000-01-02 | | xiaolan | 3 | 2000-01-03 | | xiaohei | 4 | 2000-01-04 | | xiaolv | 5 | 2000-01-05 | | xiaobai | 6 | 2001-01-01 | | xiaoqing | 8 | 2001-01-01 | | zhouyi | 9 | 2001-01-02 | | zhouer | 10 | 2001-01-02 | | zhousan | 11 | NULL | +----------+----+------------+ mysql8.0 [chap04]>select id,name,salary*12 "年薪",salary*performance from t3; +----+----------+--------+--------------------+ | id | name | 年薪 | salary*performance | +----+----------+--------+--------------------+ | 1 | xiaoming | 120000 | 13400.00 | | 2 | xiaohong | 96000 | 12720.00 | | 3 | xiaobai | 108000 | 16110.00 | +----+----------+--------+--------------------+
4、重复记录处理
#缺省情况下查询显示所有行,包括重复行 mysql8.0 [chap04]>select birthday from t1; #使用DISTINCT关键字可从查询结果中清除重复行 mysql8.0 [chap04]>select distinct birthday from t1; #DISTINCT的作用范围是后面所有字段的组合 mysql8.0 [chap04]>select distinct name,birthday from t1;
5、使用where子句限制所选择的记录:
#使用WHERE子句限定返回的记录,WHERE子句在FROM 子句后。
语法:SELECT [DISTINCT] {*, column [alias], ...} FROM table [WHERE condition(s)] [order by column [alias], ...];
WHERE中的字符串和日期值:字符串和日期要用单引号扩起来;日期值是格式敏感的。
#WHERE中比较运算符【>,>=,<,<=,=,!=】。
mysql8.0 [chap04]>select * from t1 where birthday<='2000-01-01';
+----+----------+------------+
| id | name | birthday |
+----+----------+------------+
| 1 | xiaoming | 2000-01-01 |
+----+----------+------------+
1 row in set (0.00 sec)
mysql8.0 [chap04]>select * from t1 where id<='3';
#使用IS NULL运算符,查询包含空值的记录
mysql8.0 [chap04]>select * from t1 where birthday is null;
#where中between比较运算符,使用BETWEEN运算符显示某一值域范围的记录。SELECTlast_name, salaryFROM employeesWHERE salary BETWEEN 1000 AND 1500;
mysql8.0 [chap04]>select * from t1 where birthday between'2000-01-01' and '2000=01-04';
#where中使用IN运算符,使用IN运算符获得匹配列表值的记录。
mysql8.0 [chap04]>select * from t1 where birthday in ('20000101','20000102','20010101')
#where中使用LIKE运算符,使用LIKE运算符执行模糊查询,查询条件可包含文字字符或数字,‘%’可表示零或多个字符,‘_’表示任意单字符。
mysql8.0 [chap04]>select * from t1 where name like 'xiao%';
#where中使用逻辑运算符
(1)使用and运算符,所有条件都是满足mysql8.0 [chap04]>select * from t1 where id>=2 and birthday='20010101';
(2)使用OR运算符,只要两个条件满足一个就可以mysql8.0 [chap04]>select * from t1 where id>=2 or birthday='20010101';
(3)使用NOT运算符,取反的意思
mysql8.0 [chap04]>select * from t1 where id not in (1,3,5,7,9);
#联合查询,对两个结果求并集,使用union(去掉重复的)或者union all(不去掉重复的行)
mysql8.0 [chap04]>select * from employee where dept_id in (1,4) union select * from employee where dept_name in ('sale','tech') ;
mysql8.0 [chap04]>select * from employee where dept_id in (1,4) union all select * from employee where dept_name in ('sale','tech') ;
mysql8.0 [chap04]>select * from employee where dept_id in (1,4) or dept_name in ('sale','tech') ;
#排序显示,查询语句执行的查询结果默认是按数据插入顺序排列,实际上可能需要按某列的值大小排列,按某列排序采用order by 列名[desc],列名…;设定排序列的时候可采用列名、列别名。
mysql8.0 [chap04]>select * from t1 order by birthday desc;
#where中使用正则表达式,<列名> regexp '正则表达式'
mysql8.0 [chap04]>select * from t1 where name regexp '^xiao';
基本正则:^,$,\,.,*,[0-9],[a-z],[A-Z],[a-Z],[^],\(\),\<,\>
扩展正则:+,?,(|)
4.6 SQL函数
聚合函数
聚合函数对一组值进行运算,并返回单个值。也叫分组函数。
COUNT(*|列名) 统计行数,*表示所有记录都不忽略,指定列名时会忽略null AVG(数值类型列名) 平均值,忽略null SUM (数值类型列名) 求和,忽略null MAX(列名) 最大值,忽略null MIN(列名) 最小值,忽略null
mysql8.0 [chap04]>create table employee(-> employ_id int,-> dept_id int,-> dept_name char(10),-> salary int-> ); mysql8.0 [chap04]>insert into employee set employ_id=100,dept_id=1,dept_name='boss'; mysql8.0 [chap04]>insert into employee values (101,2,'sale',10000),(102,2,'sale',9000),(103,4,'tech',12000),(104,2,'sale',5000),(105,3,'hr',8000),(106,4,'tech',10000); mysql8.0 [chap04]>select count(*) from employee; mysql8.0 [chap04]>select count(salary) from employee; mysql8.0 [chap04]>select avg(salary) from employee; mysql8.0 [chap04]>select sum(salary) from employee; mysql8.0 [chap04]>select max(salary) from employee;
数据分组——GROUP BY
GROUP BY子句的真正作用在于与各种聚合函数配合使用。它用来对查询出来的数据进行分组。
分组的含义是:把该列具有相同值的多条记录当成一组记录处理,最后只输出一条记录。
#数据分组--GROUP BY 语法:SELECT column,group_function FROM table [WHERE condition] [GROUP BY group_by_expression] #每个部门的平均工资 mysql8.0 [chap04]>select dept_name,avg(salary) from employee group by dept_name; #如果select语句中的列未使用聚合函数,那么它必须出现在GROUP BY子句中 mysql8.0 [chap04]>select dept_id,dept_name,avg(salary) from employee group by dept_id,dept_name; #出现在group by子句的字段可以不出现在select的列表当中 mysql8.0 [chap04]>select dept_name,avg(salary) from employee group by dept_id,dept_name; #查每个部门的整体工资情况 mysql8.0 [chap04]>select dept_id,dept_name,avg(salary),max(salary),min(salary),sum(salary),count(*) from employee group by dept_id,dept_name; #限定组的结果:HAVING子句,HAVING子句用来对分组后的结果再进行条件过滤。 语法:SELECT column, group_function FROM table [WHERE condition] [GROUP BY group_by_expression] [HAVING group_condition] [ORDER BYcolumn]; #查询部门平均工资大于10000的 mysql8.0 [chap04]>select dept_name,avg(salary) from employee group by dept_name having avg(salary)>10000; #HAVING与WHERE的区别:WHERE是在分组前进行条件过滤, HAVING子句是在分组后进行条件过滤,WHERE子句中不能使用聚合函数,HAVING子句可以使用聚合函数。 mysql8.0 [chap04]>select dept_name,dept_id,avg(salary) from employee where dept_id > 1 group by dept_name,dept_id; #对结果集排序:查询语句执行的查询结果默认是按数据插入顺序排列,实际上可能需要按某列的值大小排列,按某列排序采用order by 列名[desc],列名…;设定排序列的时候可采用列名、列别名。 mysql8.0 [chap04]>select dept_name,dept_id,avg(salary) from employee group by dept_name,dept_id order by dept_id,avg(salary); #MySQL多行数据合并:GROUP_CONCAT mysql8.0 [chap04]>select dept_id,dept_name,group_concat(employ_id) from employee group by dept_id,dept_name; 注意:使用 GROUP_CONCAT()函数必须对源数据进行分组,否则所有数据会被合并成一行 mysql8.0 [chap04]>select group_concat(employ_id) from employee; +-----------------------------+ | group_concat(employ_id) | +-----------------------------+ | 100,101,102,103,104,105,106 | +-----------------------------+ #查询结果限定,在SELECT语句最后可以用LIMLT来限定查询结果返回的起始记录和总数量。MySQL特有。 语法:SELECT … LIMIT offset_start,row_count; offset_start:第一个返回记录行的偏移量。默认为0。 row_count:要返回记录行的最大数目。 #显示三行数据 mysql8.0 [chap04]>select * from employee limit 3; #显示3-7行数据,共5行数据 mysql8.0 [chap04]>select * from employee limit 2,5;
数值型函数
| 函数名称 | 作用 |
|---|---|
| ABS | 求绝对值 |
| SQRT | 求平方根 |
| POW 和 POWER | 两个函数的功能相同,返回参数的幂次方 |
| MOD | 求余数 |
| CEIL 和 CEILING | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 |
| FLOOR | 向下取整,返回值转化为一个BIGINT |
| RAND | 生成一个0~1之间的随机数,传入整数参数时,用来产生重复序列 |
| ROUND | 对所传参数进行四舍五入 |
| SIGN | 返回参数的符号 |
字符串函数
| 函数名称 | 作用 |
|---|---|
| LENGTH | 计算字符串长度函数,返回字符串的字节长度 |
| CHAR_LENGTH | 计算字符串长度函数,返回字符串的字符长度,注意两者的区别 |
| CONCAT | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以是一个或多个 |
| INSERT(str,pos,len,newstr) | 替换字符串函数 |
| LOWER | 将字符串中的字母转换为小写 |
| UPPER | 将字符串中的字母转换为大写 |
| LEFT(str,len) | 从左侧字截取符串,返回字符串左边的若干个字符 |
| RIGHT | 从右侧字截取符串,返回字符串右边的若干个字符 |
| TRIM | 删除字符串左右两侧的空格 |
| REPLACE(s,s1,s2) | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING(s,n,len) | 截取字符串,返回从指定位置开始的指定长度的字符换 |
| REVERSE | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
| STRCMP(expr1,expr2) | 比较两个表达式的顺序。若expr1 小于 expr2 ,则返回 -1,0相等,1则相反 |
| LOCATE(substr,str [,pos]) | 返回第一次出现子串的位置 |
| INSTR(str,substr) | 返回第一次出现子串的位置 |
日期和时间函数
| 函数名称 | 作用 |
|---|---|
| CURDATE() CURRENT_DATE() CURRENT_DATE | 两个函数作用相同,返回当前系统的日期值 |
| CURTIME CURRENT_TIME() CURRENT_TIME | 两个函数作用相同,返回当前系统的时间值 |
| NOW() | 返回当前系统的日期和时间值 |
| SYSDATE | 返回当前系统的日期和时间值 |
| DATE | 获取指定日期时间的日期部分 |
| TIME | 获取指定日期时间的时间部分 |
| MONTH | 获取指定日期中的月份 |
| MONTHNAME | 获取指定曰期对应的月份的英文名称 |
| DAYNAME | 获取指定曰期对应的星期几的英文名称 |
| YEAR | 获取年份,返回值范围是 1970〜2069 |
| DAYOFWEEK | 获取指定日期对应的一周的索引位置值,也就是星期数,注意周日是开始日,为1 |
| WEEK | 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1 〜53 |
| DAYOFYEAR | 获取指定曰期是一年中的第几天,返回值范围是1~366 |
| DAYOFMONTH 和 DAY | 两个函数作用相同,获取指定日期是一个月中是第几天,返回值范围是1~31 |
| DATEDIFF(expr1,expr2) | 返回两个日期之间的相差天数,如 SELECT DATEDIFF('2007-12-31 23:59:59','2007-12-30'); |
| SEC_TO_TIME | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 |
| TIME_TO_SEC | 将时间参数转换为秒数,是指将传入的时间转换成距离当天00:00:00的秒数,00:00:00为基数,等于 0 秒 |
流程控制函数
| 函数名称 | 作用 |
|---|---|
| IF(expr,v1,v2) | 判断,流程控制,当expr = true时,或者为1时返回 v1,当expr = false、null 、0时返回v2 |
| IFNULL(v1,v2) | 判断是否为空,如果 v1 不为 NULL,则 IFNULL 函数返回 v1,否则返回 v2 |
| CASE | 搜索语句 |
流程控制函数示例:
(1)使用IF()函数进行条件判断
mysql>SELECT IF(12,2,3),-> IF(1<2,'yes ','no'),-> IF(STRCMP('test','test1'),'no','yes');
+------------+---------------------+---------------------------------------+
| IF(12,2,3) | IF(1<2,'yes ','no') | IF(STRCMP('test','test1'),'no','yes') |
+------------+---------------------+---------------------------------------+
| 2 | yes | no |
+------------+---------------------+---------------------------------------+
1 row in set (0.00 sec)
(2)分别显示emp表有奖金和没奖金的员工信息。
mysql> select ename,comm,if(comm is null,'没奖金,呵呵','有奖金,嘻嘻') 备注 from emp;
+-----------+-------+------------------+
| ename | comm | 备注 |
+-----------+-------+------------------+
| 甘宁 | NULL | 没奖金,呵呵 |
| 黛绮丝 | 3000 | 有奖金,嘻嘻 |
| 殷天正 | 5000 | 有奖金,嘻嘻 |
| 刘备 | NULL | 没奖金,呵呵 |
| 谢逊 | 14000 | 有奖金,嘻嘻 |
| 关羽 | NULL | 没奖金,呵呵 |
| 张飞 | NULL | 没奖金,呵呵 |
| 诸葛亮 | NULL | 没奖金,呵呵 |
| 曾阿牛 | NULL | 没奖金,呵呵 |
| 韦一笑 | 0 | 有奖金,嘻嘻 |
| 周泰 | NULL | 没奖金,呵呵 |
| 程普 | NULL | 没奖金,呵呵 |
| 庞统 | NULL | 没奖金,呵呵 |
| 黄盖 | NULL | 没奖金,呵呵 |
| 张三 | 50000 | 有奖金,嘻嘻 |
+-----------+-------+------------------+
15 rows in set (0.00 sec)
(3)使用IFNULL()函数进行条件判断
IFNULL() 函数语法格式为:IFNULL(expression, alt_value)
mysql> SELECT IFNULL(1,2), IFNULL(NULL,10), IFNULL(1/0, 'wrong');
+-------------+-----------------+----------------------+
| IFNULL(1,2) | IFNULL(NULL,10) | IFNULL(1/0, 'wrong') |
+-------------+-----------------+----------------------+
| 1 | 10 | wrong |
+-------------+-----------------+----------------------+
1 row in set, 1 warning (0.00 sec)
#IFNULL() 函数用于判断第一个表达式是否为 NULL,如果为 NULL 则返回第二个参数的值,如果不为NULL 则返回第一个参数的值。
(4)使用CASE value WHEN语句执行分支操作
语法:CASE <表达式>WHEN <值1> THEN <操作>WHEN <值2> THEN <操作>...ELSE <操作>
END
将 <表达式> 的值逐一和每个 when 的 <值> 进行比较,如果跟某个<值>相等,则执行它后面的 <操作> ,如果所有 when 的值都不匹配,则执行 else 的操作,如果 when 的值都不匹配,且没写 else,则会报错。
mysql> SELECT CASE 2 WHEN 1 THEN 'one' WHEN 2 THEN 'two' ELSE 'more' END;
+------------------------------------------------------------+
| CASE 2 WHEN 1 THEN 'one' WHEN 2 THEN 'two' ELSE 'more' END |
+------------------------------------------------------------+
| two |
+------------------------------------------------------------+
1 row in set (0.00 sec)
mysql8.0 [chap04]>select dept_name,dept_id,case dept_id when 1 then 'boss' when 2 then 'sale' else 'other'
end as 'bumen' from employee;
+-----------+---------+-------+
| dept_name | dept_id | bumen |
+-----------+---------+-------+
| boss | 1 | boss |
| sale | 2 | sale |
| sale | 2 | sale |
| tech | 4 | other |
| sale | 2 | sale |
| hr | 3 | other |
| tech | 4 | other |
+-----------+---------+-------+
mysql8.0 [chap04]>select employ_id,dept_id,dept_name,salary,case dept_name when 'sale' then salary*1.3 when
'tech' then salary*1.1 else salary end as last_salary from employee;
(5)使用CASE WHEN语句执行分支操作
mysql> SELECT CASE WHEN 1<0 THEN 'true' ELSE 'false' END;
+--------------------------------------------+
| CASE WHEN 1<0 THEN 'true' ELSE 'false' END |
+--------------------------------------------+
| false |
+--------------------------------------------+
1 row in set (0.00 sec)
mysql8.0.30 [chap04]>select name,salary,case when salary<=300 then '[0,300]' when salary<=500 then '(300,500]' when salary<=1000 then '(500,1000]' when salary is null then 'dont know' else '(1000,*)' end'salary level' from employee;
4.7 多表关联查询
1. inner join:内连接,只取得键值一致的部分,代表选择的是两个表键值交叉的部分。
语法如下:
SELECT 列名1,列名2... FROM 表1 INNER JOIN 表2 ON 表1.列=表2.列 [and 条件表达式 ][ WhERE 条件语句 ] [ order by 列 [desc] ];
mysql8.0 [chap04]>create table dept( dept_id int, dept_name char(10) );
mysql8.0 [chap04]>insert into dept values (1,'boss'),(2,'sale'),(3,'hr'),(4,'tech'),(5,'finance');
mysql8.0 [chap04]>alter table employee add foreign key(dept_id) references dept(dept_id);
mysql8.0 [chap04]>insert into employee set employ_id=107;
mysql8.0 [chap04]>select * from employee inner join dept on employee.dept_id=dept.dept_id where
dept.dept_name='sale';
mysql8.0 [chap04]>select * from employee inner join dept on employee.dept_id=dept.dept_id and salary>8000;
mysql8.0 [chap04]>select * from employee inner join dept on employee.dept_id=dept.dept_id and salary>8000 order by salary;
2. left join:左连接,代表选择的是前面一个表的全部。左连接是以左表为标准,只查询在左边表中存在的数据。语法如下:
SELECT 列名1 FROM 表1 LEFT OUTER JOIN 表2 ON 表1.列=表2.列 WhERE 条件语句;
mysql8.0 [chap04]>select e.employ_id,e.dept_id,e.salary,d.dept_name from employee e left outer join dept d on e.dept_name=d.dept_name;
3. right join:右连接,代表选择的是后面一个表的全部。右连接将会以右边作为基准,进行检索。语法如下:
SELECT 列名1 FROM 表1 RIGHT OUTER JOIN 表2 ON 表1.列=表2.列 WhERE 条件语句;
#列出所有部门的员工,包括没有员工的部门
mysql8.0 [chap04]>select d.dept_id,d.dept_name,e.employ_id,e.salary from employee e right join
dept d on e.dept_id=d.dept_id;
4.自连接,自连接顾名思义就是自己跟自己连接,参与连接的表都是同一张表。(通过给表取别名虚拟出)
#查找比自己mgr岁数大的员工和mgr的姓名和年龄
mysql8.0 [chap04]>create table t4(-> name char(20),-> age int,-> mgr char(20)-> );
mysql8.0 [chap04]>insert into t4 values ('xiaoming',29,'xiao'),('xiaohong',26,'xiao'),('zhouyi',19,'zhou'),('xiao',28,'boss'),('zhou',30,'boss');
mysql8.0 [chap04]>select e.name,e.age,m.name,m.age from t4 e join t4 m on e.mgr=m.name and e.age > m.age;
mysql8.0 [chap04]>select e.name,e.age,m.name,m.age from t4 e,t4 m where e.mgr=m.name and e.age >m.age;
5.交叉连接:不适用任何匹配条件。生成笛卡尔积
mysql8.0 [chap04]>select * from dept,t4;
子查询,子查询是将一个查询语句嵌套在另一个查询语句中。内部嵌套其他select语句的查询,称为外查询或主查询。 注意: 1、子查询要包含在括号内。 2、将子查询放在比较条件的右侧。 3、单行操作符对应单行子查询,多行操作符对应多行子查询 #查询工资最低的员工的信息 mysql8.0 [chap04]>select * from employee e where e.salary=(select min(salary) from employee); #查询出高于hr部门平均工资的员工 mysql8.0 [chap04]>select * from employee e where e.salary>(select avg(salary) from employee where dept_name='hr');#查询出比sale部门所有员工工资高的员工信息 mysql8.0 [chap04]>select * from employee where salary >(select max(salary) from employee where dept_name='sale') and dept_name!='sale'; mysql8.0 [chap04]>select * from employee where salary>all(select salary from employee where dept_name='sale') and dept_name!='sale'; #查询出比sale部门任意一个员工工资高的员工信息,只要比其中随便一个工资高都可以 mysql8.0 [chap04]>select * from employee where salary>any(select salary from employee where dept_name='sale') and dept_name!='sale'; # 获取员工的名字和部门的名字 select后面接子查询 mysql8.0 [chap04]>alter table employee drop dept_name; mysql8.0 [chap04]>select employ_id,(select dept_name from dept d where d.dept_id=e.dept_id) dept_name from employee e; mysql8.0 [chap04]>select employ_id,d.dept_name from employee e left join dept d on e.dept_id=d.dept_id; # 查询所有管理层的信息 mysql8.0 [chap04]>select * from t4 e,(select distinct mgr from t4) m where e.name=m.mgr;
第三次作业
一、单表查询 素材: 表名:worker-- 表中字段均为中文,比如 部门号 工资 职工号 参加工作 等 CREATE TABLE `worker` (`部门号` int(11) NOT NULL,`职工号` int(11) NOT NULL,`工作时间` date NOT NULL,`工资` float(8,2) NOT NULL,`政治面貌` varchar(10) NOT NULL DEFAULT '群众',`姓名` varchar(20) NOT NULL,`出生日期` date NOT NULL,PRIMARY KEY (`职工号`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC; INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (101, 1001, '2015-5-4', 3500.00, '群众', '张三', '1990-7-1'); INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (101, 1002, '2017-2-6', 3200.00, '团员', '李四', '1997-2-8'); INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1003, '2011-1-4', 8500.00, '党员', '王亮', '1983-6-8'); INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1004, '2016-10-10', 5500.00, '群众', '赵六', '1994-9-5'); INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1005, '2014-4-1', 4800.00, '党员', '钱七', '1992-12-30'); INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1006, '2017-5-5', 4500.00, '党员', '孙八', '1996-9-2'); 1、显示所有职工的基本信息。 2、查询所有职工所属部门的部门号,不显示重复的部门号。 3、求出所有职工的人数。 4、列出最高工资和最低工资。 5、列出职工的平均工资和总工资。 6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。 7、显示所有女职工的年龄。 8、列出所有姓刘的职工的职工号、姓名和出生日期。 9、列出1960年以前出生的职工的姓名、参加工作日期。 10、列出工资在1000-2000之间的所有职工姓名。 11、列出所有陈姓和李姓的职工姓名。 12、列出所有部门号为2和3的职工号、姓名、党员否。 13、将职工表worker中的职工按出生的先后顺序排序。 14、显示工资最高的前3名职工的职工号和姓名。 15、求出各部门党员的人数。 16、统计各部门的工资和平均工资 17、列出总人数大于4的部门号和总人数。 1、显示所有职工的基本信息。 select * from worker;2、查询所有职工所属部门的部门号,不显示重复的部门号。 select distinct 部门号 from worker ;3、求出所有职工的人数。 select count(*) 员工人数 from worker;4、列出最高工和最低工资。select max(工资),min(工资) from worker;5、列出职工的平均工资和总工资。select avg(工资) 平均工资,SUM(工资) 总工资 FROM worker;6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。 CREATE TABLE `工作日期` (`职工号` INT(11) NOT NULL,`姓名` VARCHAR(20) NOT NULL, `工作时间` DATE NOT NULL, PRIMARY KEY (`职工号`) ) ENGINE=INNODB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;7、显示所有职工的年龄。 SELECT 姓名,DATE_FORMAT(FROM_DAYS(TO_DAYS(NOW())-TO_DAYS(出生日期)), '%Y')+0 AS age FROM worker;8、列出所有姓刘的职工的职工号、姓名和出生日期。SELECT 职工号,姓名,出生日期 FROM worker WHERE 姓名 LIKE '刘%';9、列出1960年以后出生的职工的姓名、参加工作日期。SELECT 姓名,工作时间 FROM worker WHERE 出生日期>1960-01-01;10、列出工资在4000-5000之间的所有职工姓名。 SELECT 姓名 FROM worker WHERE 工资 BETWEEN 4000 AND 5000;11、列出所有部门号为101和102的职工号、姓名、党员否。 SELECT 职工号,姓名,政治面貌 FROM worker WHERE 部门号=101 or 部门号=102;12、将职工表worker中的职工按出生的先后顺序排序。SELECT * FROM worker ORDER BY 出生日期;13、显示工资最高的前3名职工的职工号和姓名。 SELECT 职工号,姓名 FROM worker ORDER BY 工资 DESC LIMIT 3;14、求出各部门党员的人数。 SELECT 部门号,COUNT(*) 党员人数 FROM worker WHERE 政治面貌='党员' GROUP BY 部门号;15、统计各部门的工资和平均工资SELECT 工资,AVG(工资) 平均工资 FROM worker GROUP BY 部门号;16、列出总人数大于3的部门号和总人数。SELECT 部门号,COUNT(*) 总人数 FROM worker GROUP BY 部门号 HAVING 总人数>3;二、多表查询 1.创建student和score表 CREATE TABLE student ( id INT(10) NOT NULL UNIQUE PRIMARY KEY , name VARCHAR(20) NOT NULL , sex VARCHAR(4) , birth YEAR, department VARCHAR(20) , address VARCHAR(50) ); 创建score表。SQL代码如下: CREATE TABLE score ( id INT(10) NOT NULL UNIQUE PRIMARY KEY AUTO_INCREMENT , stu_id INT(10) NOT NULL , c_name VARCHAR(20) , grade INT(10) ); 2.为student表和score表增加记录 向student表插入记录的INSERT语句如下: INSERT INTO student VALUES( 901,'张老大', '男',1985,'计算机系', '北京市海淀区'); INSERT INTO student VALUES( 902,'张老二', '男',1986,'中文系', '北京市昌平区'); INSERT INTO student VALUES( 903,'张三', '女',1990,'中文系', '湖南省永州市'); INSERT INTO student VALUES( 904,'李四', '男',1990,'英语系', '辽宁省阜新市'); INSERT INTO student VALUES( 905,'王五', '女',1991,'英语系', '福建省厦门市'); INSERT INTO student VALUES( 906,'王六', '男',1988,'计算机系', '湖南省衡阳市'); 向score表插入记录的INSERT语句如下: INSERT INTO score VALUES(NULL,901, '计算机',98); INSERT INTO score VALUES(NULL,901, '英语', 80); INSERT INTO score VALUES(NULL,902, '计算机',65); INSERT INTO score VALUES(NULL,902, '中文',88); INSERT INTO score VALUES(NULL,903, '中文',95); INSERT INTO score VALUES(NULL,904, '计算机',70); INSERT INTO score VALUES(NULL,904, '英语',92); INSERT INTO score VALUES(NULL,905, '英语',94); INSERT INTO score VALUES(NULL,906, '计算机',90); INSERT INTO score VALUES(NULL,906, '英语',85); 1.查询student表的所有记录 2.查询student表的第2条到4条记录 3.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息 4.从student表中查询计算机系和英语系的学生的信息 5.从student表中查询年龄18~22岁的学生信息 6.从student表中查询每个院系有多少人 7.从score表中查询每个科目的最高分 8.查询李四的考试科目(c_name)和考试成绩(grade) 9.用连接的方式查询所有学生的信息和考试信息 10.计算每个学生的总成绩 11.计算每个考试科目的平均成绩 12.查询计算机成绩低于95的学生信息 13.查询同时参加计算机和英语考试的学生的信息 14.将计算机考试成绩按从高到低进行排序 15.从student表和score表中查询出学生的学号,然后合并查询结果 16.查询姓张或者姓王的同学的姓名、院系和考试科目及成绩 17.查询都是湖南的学生的姓名、年龄、院系和考试科目及成绩
1.查询student表的所有记录
SELECT * FROM student;
2.查询student表的第2条到4条记录
SELECT * FROM student LIMIT 1,3;
3.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息
SELECT id 学号,name 姓名,department 院系 FROM student;
4.从student表中查询计算机系和英语系的学生的信息
SELECT * FROM student WHERE department='计算机系' or department='英语系';
5.从student表中查询年龄18~22岁的学生信息
SELECT * FROM student where birth>2000 and birth<2002;
6.从student表中查询每个院系有多少人
SELECT department,count(*) 人数 from student group by department;
7从score表中查询每个科目的最高分
SELECT c_name,max(grade) from score group by c_name;
8.查询李四的考试科目(c_name)和考试成绩(grade)
select c.c_name,c.grade from student s inner join score c on s.id=c.stu_id where s.name='李四';
9.用连接的方式查询所有学生的信息和考试信息
select * from student inner join score on student.id=score.stu_id;
10.计算每个学生的总成绩
select stu_id,sum(grade) 总成绩 from score group by stu_id;
11.计算每个考试科目的平均成绩
select c_name,avg(grade) 平均成绩 from score group by c_name;
12.查询计算机成绩低于95的学生信息
select s.* from student s inner join score c on s.id=c.stu_id WHERE grade<95 and c_name='计算机';
13.查询同时参加计算机和英语考试的学生的信息
select s.* from student s inner join score c on s.id=c.stu_id where c_name='计算机' and c_name='英语';
14.将计算机考试成绩按从高到低进行排序
select grade from score where c_name='计算机' order by grade desc;
15.从student表和score表中查询出学生的学号,然后合并查询结果
select s.name,c.stu_id from student s inner join score c on s.id=c.stu_id;
16.查询姓张或者姓王的同学的姓名、院系和考试科目及成绩
select name,department,c_name,grade from student s inner join score c on s.id=c.stu_id where s.name like '张%' or name like '王%';
17.查询都是湖南的学生的姓名、年龄、院系和考试科目及成绩
select name,department,c_name,grade from student s inner join score c on s.id=c.stu_id where address like '湖南%';
相关文章:
数据库(三)
第三章 MySQL库表操作 3.1 SQL语句基础 3.1.1 SQL简介 SQL:结构化查询语言(Structured Query Language),在关系型数据库上执行数据操作、数据检索以及数据维护的标准语言。使用SQL语句,程序员和数据库管理员可以完成如下的任务。 改变数据…...

2023软考纸质证书领取通知来了!
不少同学都在关注2022下半年软考证书领取时间,截止至目前,上海、湖北、江苏、南京、安徽、山东、浙江、宁波、江西、贵州、云南、辽宁、大连、吉林、广西地区的纸质证书可以领取了。将持续更新2022下半年软考纸质证书领取时间,请同学们在证书…...

Python requests模块
一、requests模块简介 requests模块是一个第三方模块,需要在python环境中安装: pip install requests 该模块主要用来发送 HTTP 请求,requests 模块比 urllib 模块更简洁。 requests模块支持: 自动处理url编码自动处理post请求…...

工业智能网关解决方案:物联网仓储环境监测系统
仓储是连接生产、供应和销售的中转系统,对于促进生产、提高效率有着重要的辅助作用。对于很多大型工厂或食品厂来说,需要对仓储环境进行严控的控制,以确保产品或食品的质量,避免不必要的产品损耗,提高产品存管的水平。…...
Linux进程线程管理
目录 存储管理 linux内存管理基本框架 系统空间管理和用户空间管理 进程与进程调度 进程四要素 用户堆栈的扩展 进程三部曲:创建,执行,消亡 系统调用exit(),wait() 内核中的互斥操作 存储管理 linux内存管理基本框架 系统空间管理…...

分享111个HTML电子商务模板,总有一款适合您
分享111个HTML电子商务模板,总有一款适合您 111个HTML电子商务模板下载链接:https://pan.baidu.com/s/1e8Wp1Rl9RaFrcW0bilIatg?pwdc97h 提取码:c97h Python采集代码下载链接:采集代码.zip - 蓝奏云 HTML5家居家具电子商务网…...

百度前端必会手写面试题整理
请实现一个 add 函数,满足以下功能 add(1); // 1 add(1)(2); // 3 add(1)(2)(3);// 6 add(1)(2, 3); // 6 add(1, 2)(3); // 6 add(1, 2, 3); // 6function add(...args) {// 在内部声明一个函数,利用闭包的特性保存并收集…...
ubuntu 安装支持GPU的Docker详细步骤
安装依赖项 sudo apt-get update sudo apt-get install -y apt-transport-https ca-certificates curl gnupg-agent software-properties-common 添加 Docker GPG 密钥 curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo apt-key fingerpr…...
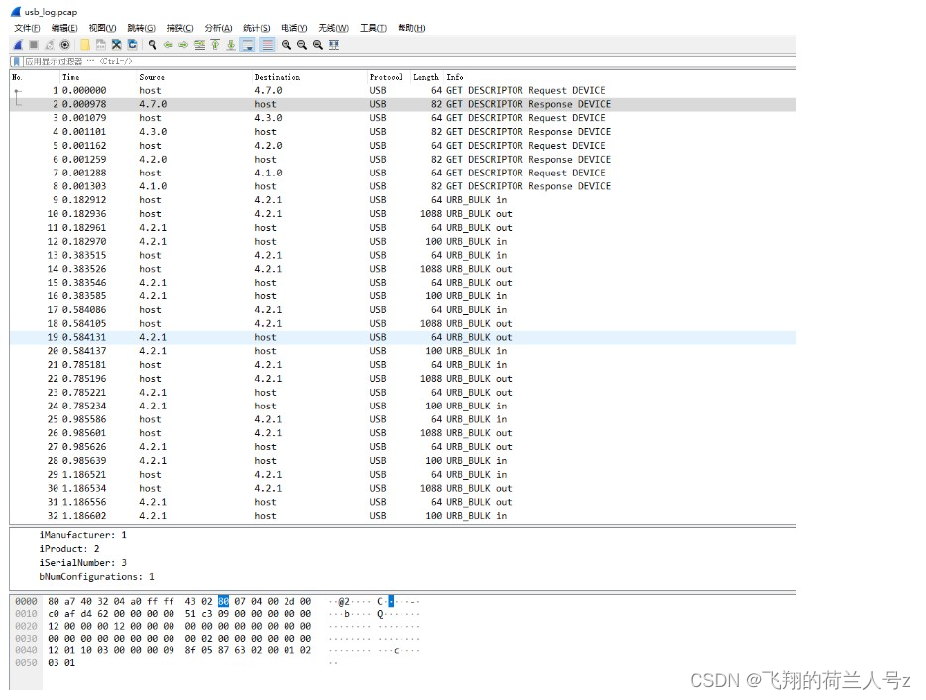
usbmon+tcpdump+wireshark USB抓包
文章目录usbmon抓包及配合wireshark解析usbmon抓包及配合wireshark解析 usbmon首先编译为内核模块,然后通过modprobe usbmon加载到linux sys文件系统中 rootroot-PC:~# modprobe usbmon 而后 linux系统下安装 tcpdump rootroot-PC:~# apt-get install tcpdump…...
【LeetCode】剑指 Offer 04. 二维数组中的查找 p44 -- Java Version
题目链接: https://leetcode.cn/problems/er-wei-shu-zu-zhong-de-cha-zhao-lcof/ 1. 题目介绍(04. 二维数组中的查找) 在一个 n * m 的二维数组中,每一行都按照从左到右 非递减 的顺序排序,每一列都按照从上到下 非递…...
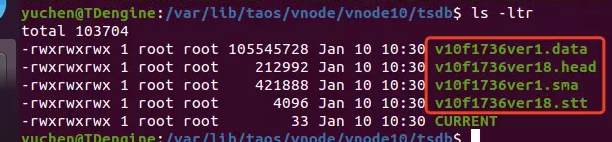
TDengine 3.0.2.5 查询再优化!揭秘索引文件的工作原理
TDengine 3.0 虽然对底层做了大规模的优化重构,但是相对于数据文件的工作逻辑和 2.0 相比是整体保持不变的。本系列文章的主旨在于帮助用户深入理解产品,并且拥有基本的性能调试思路,从而获得更好的产品体验。本期文章会在讲解 TDengine 时序…...

蓝牙耳机哪个品牌性价比高?性价比高的无线蓝牙耳机
现如今耳机已经十分普及,大多数人会随身佩戴蓝牙耳机,相较于传统耳机,无线耳机不仅携带方便,舒适度上也更加出色。不过市面上的无线耳机种类繁多,很多朋友不知道该如何挑选,所以小编特意整理了一期性价比高…...

python的disutils创建分发包
python中的distutils包主要用创建共享包,安装包,在平时安装python模块的时候,使用的命令如下: python setup.py install 其实以上代码就是distuitls包提供的功能,直接使用setup.py来进行安装一个包,在用这种…...
【洛谷】P1195 口袋的天空
明显看出为最小生成树,那么:难点在哪里呢?if(cntn-k)//******{flag1;break;}为什么是cntn-k呢而不是k呢?!!!解释:(如果每个已经连在一起了就不能分开,不管多少…...

JavaScript高级程序设计读书分享之3章——3.5操作符
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 目录 操作符 一元操作符 递增/递减操作符 一元加和减 布尔操作符 逻辑非 逻辑与 逻辑或 乘性操作符 乘法操作符 除法操作符 取模操作符 加性操作符 加法操作符 减法操作符 关系操作符 相等操…...

moveToCoordinateF3DconcatenateRotations
moveToCoordinate 演示视频: 注意:前提是3~6轴机器人机构且不是PickAndPlace 该方法_3D。Poses.moveToCoordinate 移动由 指定的对象,该对象 对应于支持的机器人配置之一,只要标识的机器人配置支持,其第一个动画指向指定坐标和指定旋转。这无需您定义姿势即可工作。 工…...
)
多线程面试题开胃菜6(5道)
一、Fork/Join 框架是干什么的?大任务自动分散小任务,并发执行,合并小任务结果。二、线程数过多会造成什么异常?线程过多会造成栈溢出,也有可能会造成堆异常。三、说说线程安全的和不安全的集合。Java 中平时用的最多的…...
植物大战 List——C++
这里写目录标题vector和stirng的细节对于stringlist的使用list的迭代器反向迭代器构造函数关于list::sort的排序uniquelist的底层模拟实现结点类的实现迭代器模拟实现list实现插入的实现迭代器失效inserterase析构函数拷贝构造赋值构造函数vector和stirng的细节 复习vector的深…...

安灯(andon)系统是车间现场管理的必备工具
安灯(andon)系统应用越来越广泛,不单单局限于汽车行业,更多生产型企业意识到了提高工作效率的重要性,提高工作效率根本的能提高生产水平,提高产量,而且安灯(andon)系统不…...
Hazel游戏引擎(004)
本人菜鸟,文中若有代码、术语等错误,欢迎指正 我写的项目地址:https://github.com/liujianjie/GameEngineLightWeight(中文的注释适合中国人的你) 文章目录前言操作步骤讲解GitHubHazel项目此项目定位项目属性修改Sand…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...