【Linux】项目自动化构建工具make/makefile
🏖️作者:@malloc不出对象
⛺专栏:Linux的学习之路
👦个人简介:一名双非本科院校大二在读的科班编程菜鸟,努力编程只为赶上各位大佬的步伐🙈🙈

目录
- 前言
- 一、make/makefile的背景
- 二、makefile的基本结构
- 三、项目清理
- 四、makefile的依赖
- 五、如何快速编写大型项目中的Makefile文件
前言
本篇文章我们将要讲解的是项目自动化构建工具make与makefile。
一、make/makefile的背景
会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力,一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。makefile带来的好处就是——“自动化编译”,一旦写好只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
在Linux下,make命令主要用于自动化构建(build)软件项目,它能够根据程序员编写的Makefile文件中的指令,自动编译、链接、打包和安装软件。
具体而言,make完成以下工作:
1.根据Makefile文件中的规则,检查每个源文件的修改时间和依赖关系,确定哪些文件需要重新编译。
2.编译源文件,生成目标文件。
3.链接目标文件,生成可执行文件或库文件。
4.打包可执行文件或库文件,以便于分发和安装。
5.安装可执行文件或库文件到指定的目录中。
通过使用make命令,程序员可以更加方便和高效地管理项目中的代码编译、构建和部署等任务。
Makefile是一个文本文件,其中包含了一系列规则和指令,用于告诉make命令如何构建(build)软件项目。
具体而言,Makefile完成以下工作:
1.定义变量:可以定义一些变量,用于存储常量或者目录路径等信息。
2.定义规则:规则指定了如何生成一个或多个目标文件。每个规则包含了目标文件、依赖文件和生成命令。如果目标文件需要更新,make会根据规则自动执行生成命令。
3.定义伪目标:伪目标是没有实际文件对应的目标,只是一个执行动作的标签。伪目标可以用来执行清理操作、运行测试脚本等操作。
4.定义命令:命令是指make需要执行的操作。可以是编译源代码、链接目标文件、打包可执行文件等操作。
5.定义依赖关系:依赖关系指明哪些文件是构建目标文件所必需的。当依赖文件被修改时,make会根据依赖关系重新构建目标文件。
通过编写Makefile文件,程序员可以实现对项目的自动化构建,提高项目构建的效率和可靠性。
注:make是一个指令,makefile是一个文件!!
二、makefile的基本结构
makefile是一个围绕依赖关系和依赖方法构建的一个自动化编译的工具,我们想完成一件事,必须有正确的依赖关系和正确的依赖方法。
我们先来看看它的基本结构:

注意:依赖方法必须以tab(tab长度不定,我们一般tab以4字符为一个间隔)开头,这是语法规定!!
如果我们使用空格的话会出现下面的情况:


我们可以看到不符合Makefile规则是不能完成构建的。另外细心的读者也可以发现如果使用tab符合Makefile规则的话是会颜色高亮的!!
下面我们来简单使用make演示一下:
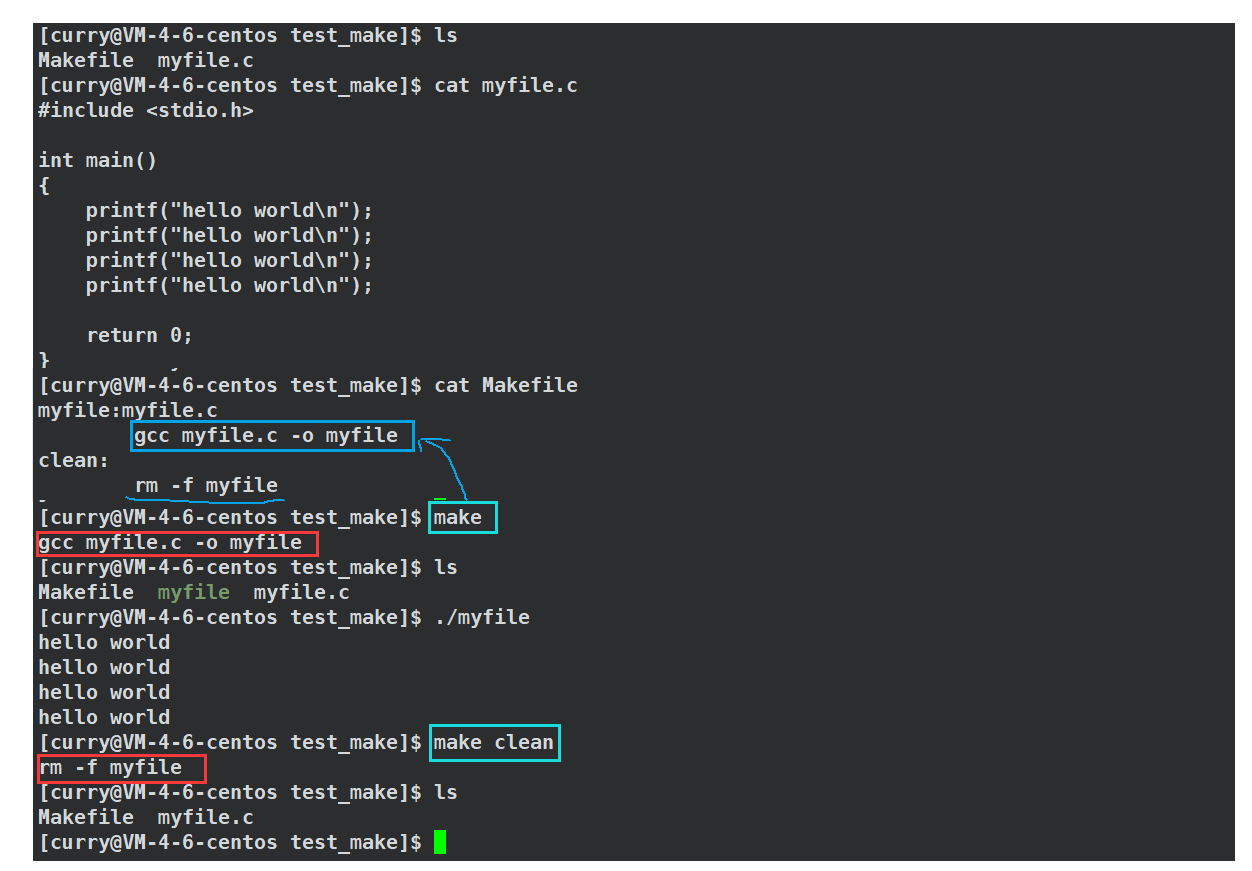
看了上图那么我有一个问题,为什么直接使用make就执行了第一个目标文件的依赖方法??而第二个目标文件clean却要显式的使用make clean?
这是因为编译器会默认从上往下扫描,找到文件中的第一个目标文件,在上面的例子中,他会找到“myfile”这个目标文件,然后根据依赖方法得到可执行程序!!而其他的目标文件则需要指令文件名才能进行编译了。
下面我们来验证一下,这次我将clean目标文件放在最前面:
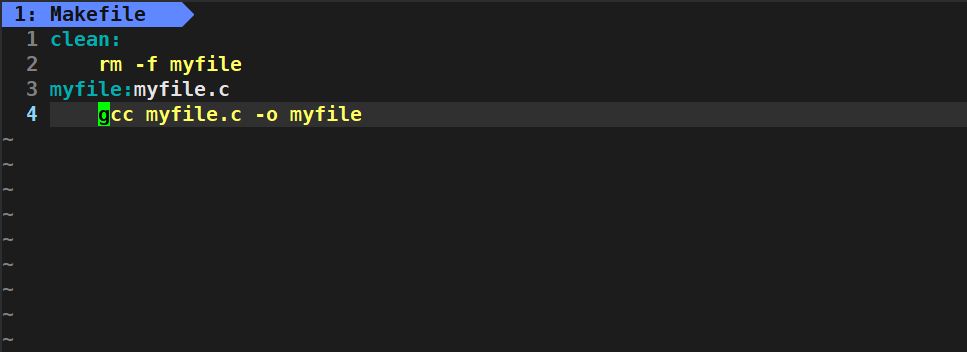
我们发现此时make执行的就是第一个目标文件的依赖方法了,而myfile需要make指明构建:
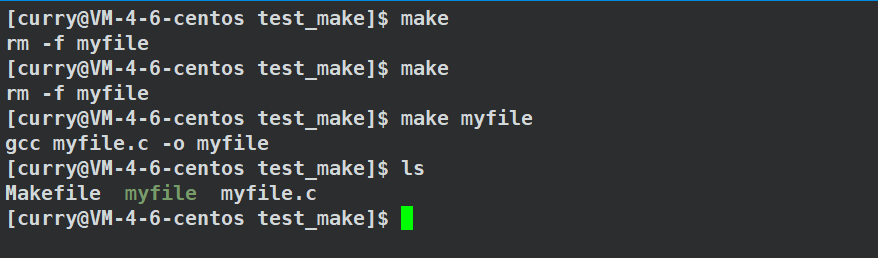
回到之前的例子,我们来看看下面出现的现象:
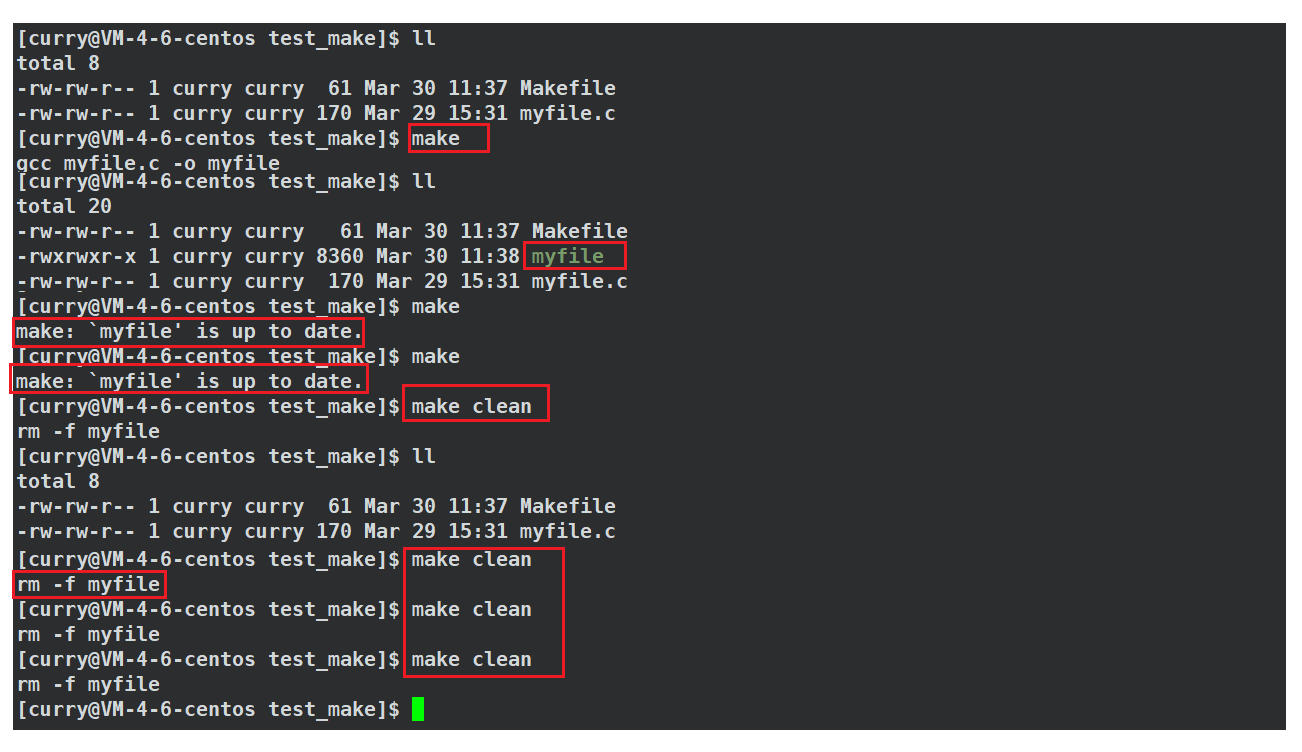
为什么make只能进行一次,然后就提示myfile这个可执行程序已经是最新的了,不需要重新编译了,而make clean却能执行多次??
这是因为clean的依赖文件列表为空,则意味着该目标文件不依赖于任何文件。这意味着在执行该目标时,不需要检查其依赖项是否已经更新,因为没有依赖项需要检查;而myfile可执行程序它其实是需要根据依赖文件来判断是否需要重新编译的!!
Q:那么请问gcc是如何根据依赖文件来判断是否需要重新编译?
实际上gcc是根据依赖文件修改的时间来判断是否需要重新编译的,我们的源文件(依赖文件)对应一个时间戳,我们的目标文件也有一个时间戳,我们知道源文件(依赖文件)的创建时间一定比目标文件要早,这样才能形成目标文件对吧;而在源文件(依赖文件)进行修改之后它的时间戳就进行了更新,此时
源文件(依赖文件)的时间戳比目标文件新,那么Make工具就会重新构建这个目标文件。
如下图我简单的展示一下:

下面我们来进行实验一下:
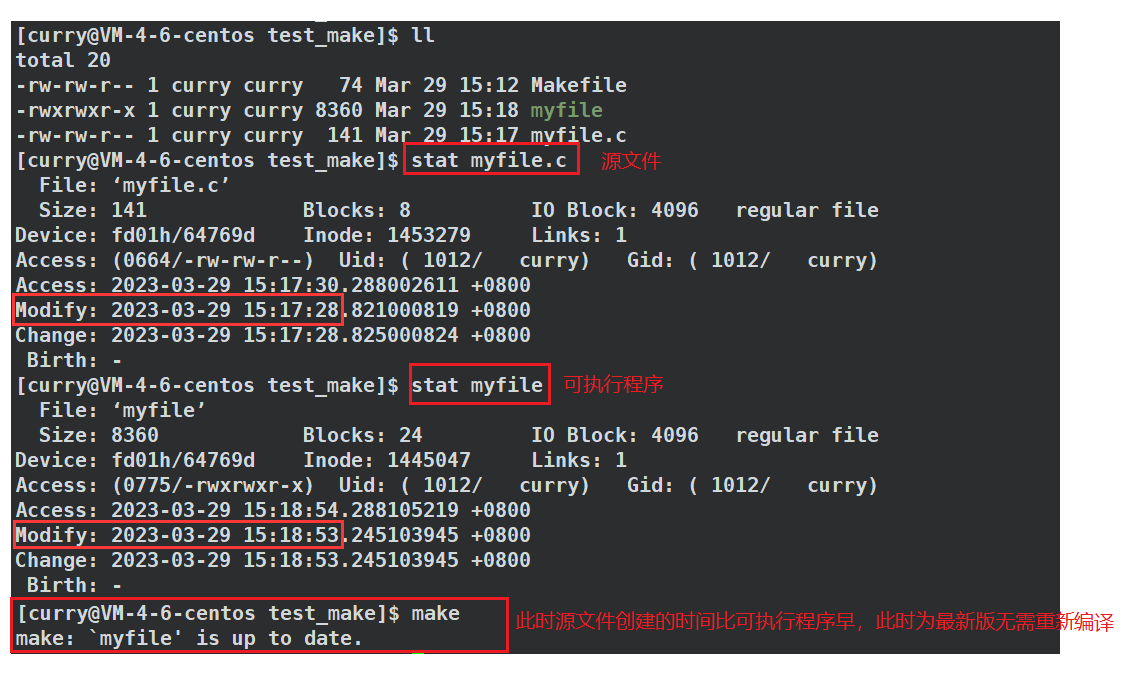
修改依赖文件(源文件)之后:

Q:那么有没有办法不修改源文件也可以使目标文件能够重新构建呢?
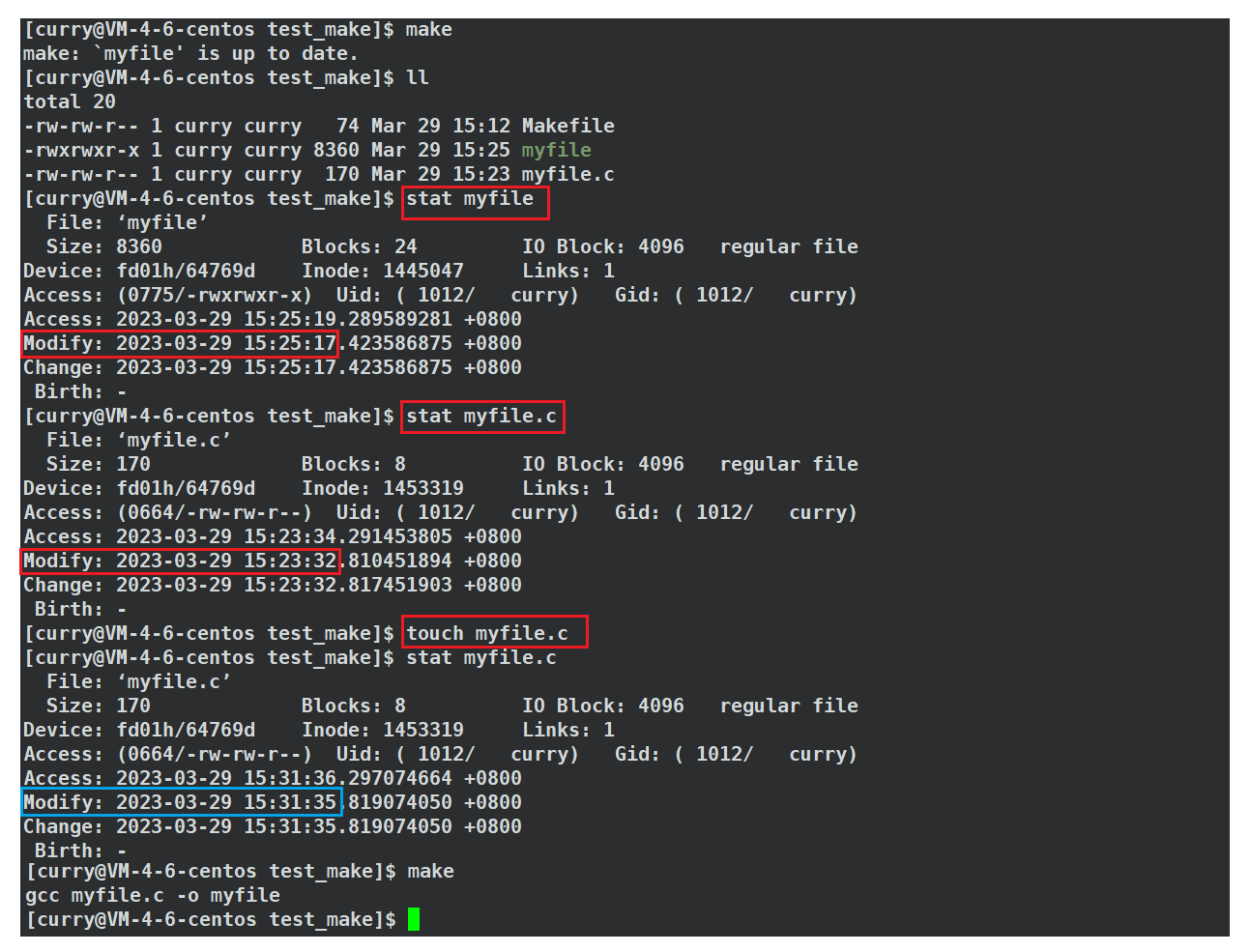
我们可以使用touch指令将依赖文件(源文件)更新到最新的时间戳,那么此时我们的依赖文件(源文件)比目标文件的时间戳更新,所以我们就能重新进行编译了!!!
总结:如果这个目标文件不存在或者它的时间戳比依赖文件的时间戳更旧,那么 Make 工具会重新构建这个目标文件;否则,它会认为这个目标文件已经是最新的,不需要重新构建。
三、项目清理
工程是需要被清理的,像clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过我们可以显式要make执行。即命令——“make clean”,以此来清除所有的目标文件,以便重新编译。但是一般我们这种clean的目标文件,我们将它设置为伪目标,用 .PHONY 修饰,伪目标表示一个“虚拟目标”,它并不对应于任何实际的文件,而是表示一些需要执行的命令。当执行伪目标时,Make 不会检查它是否存在于文件系统中,而是仅仅执行对应的命令。我们记住它最重要的特性——总是执行的。
我们来看看它的使用方式:
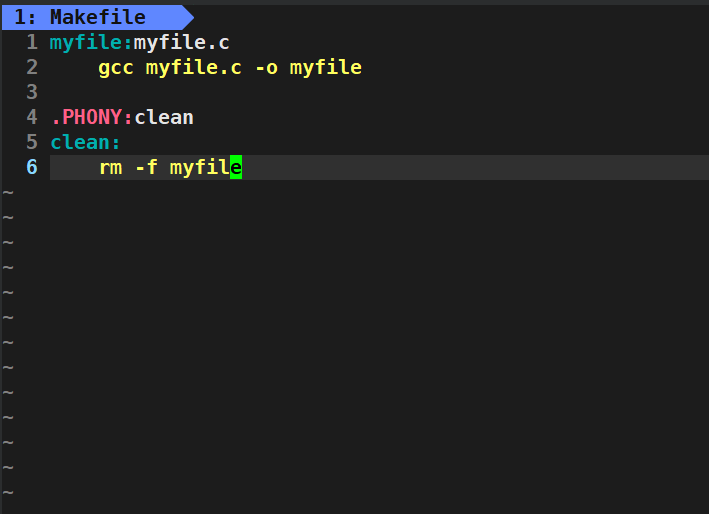
我们来看看现象:
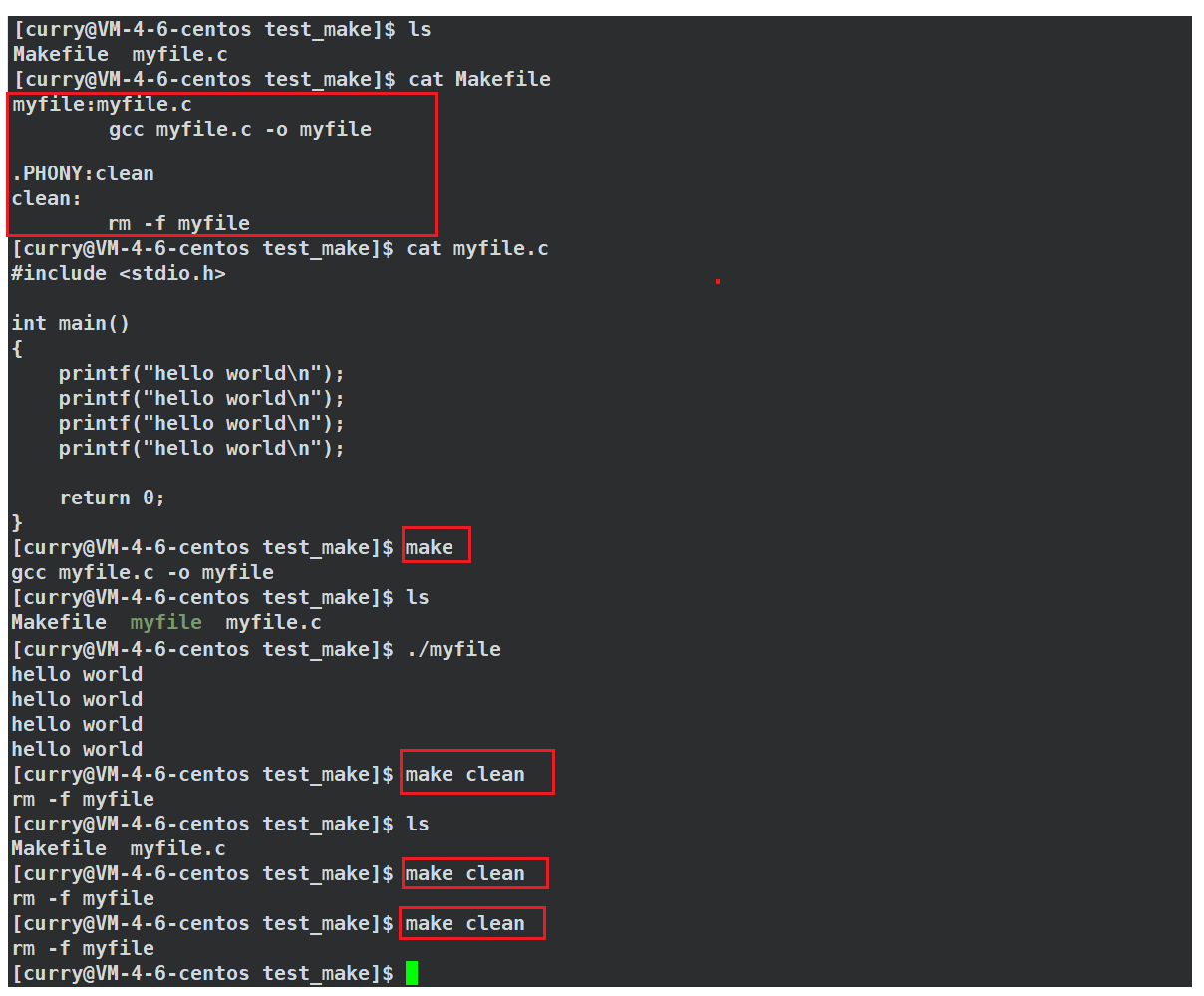
我们发现在clean被.PHONY修饰之后能执行多次,那之前我们写的clean依赖的文件列表为空不是也能完成这个任务吗?它们之间一样吗?
首先目标文件依赖的文件为空和.PHONY修饰的伪目标是两个不同的概念。
目标文件依赖的文件为空:
- 当一个目标文件依赖的文件为空时,make 不会检查这个依赖项是否存在或是否被更新。这通常用于创建某个目标文件,但其依赖项是通过其他方式处理或生成的情况。
.PHONY修饰的伪目标:.PHONY是一个特殊的目标,用于声明一些伪目标。伪目标不是实际的文件名,而是 makefile 中定义的一组操作。.PHONY目标声明的目标通常不需要实际的文件作为依赖项。当你运行 make 时,它将忽略这些目标是否存在或是否被更新,而是直接执行定义的操作。
总的来说,目标文件依赖的文件为空适用于依赖项是通过其他方式生成的情况,而.PHONY适用于声明一组操作而不需要实际文件作为依赖项的情况。
Q:"依赖项通过其他方式生成"是什么意思呢?
“依赖项通过其他方式生成” 的意思是在构建某个目标时,它的某个依赖项并不是一个实际的文件,而是通过其他方式生成的,比如:
1.通过命令行运行一些程序生成的结果。
2.通过其他的 Makefile 规则生成的结果。
3.通过复制或者下载远程文件得到的结果。
在这些情况下,依赖项并不是一个实际的文件,因此无法使用文件的时间戳来判断它是否需要重新构建。相反,你需要手动定义生成依赖项的规则,以确保它们能够在构建目标之前正确地生成。
我们来看看具体的例子:
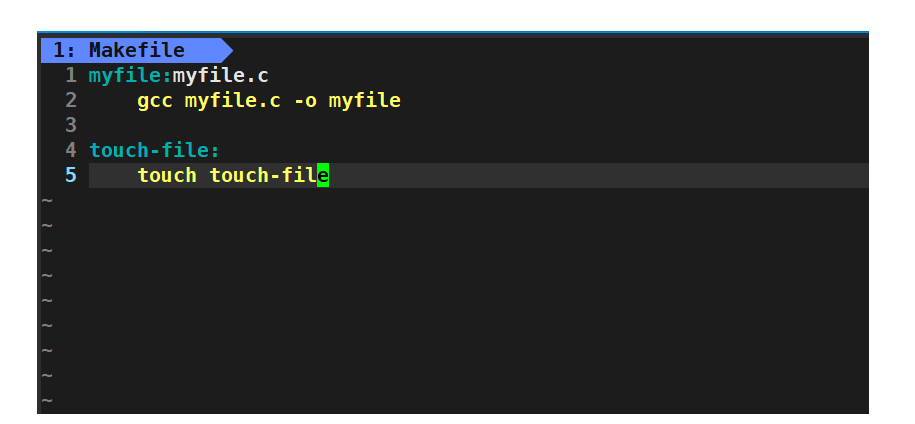
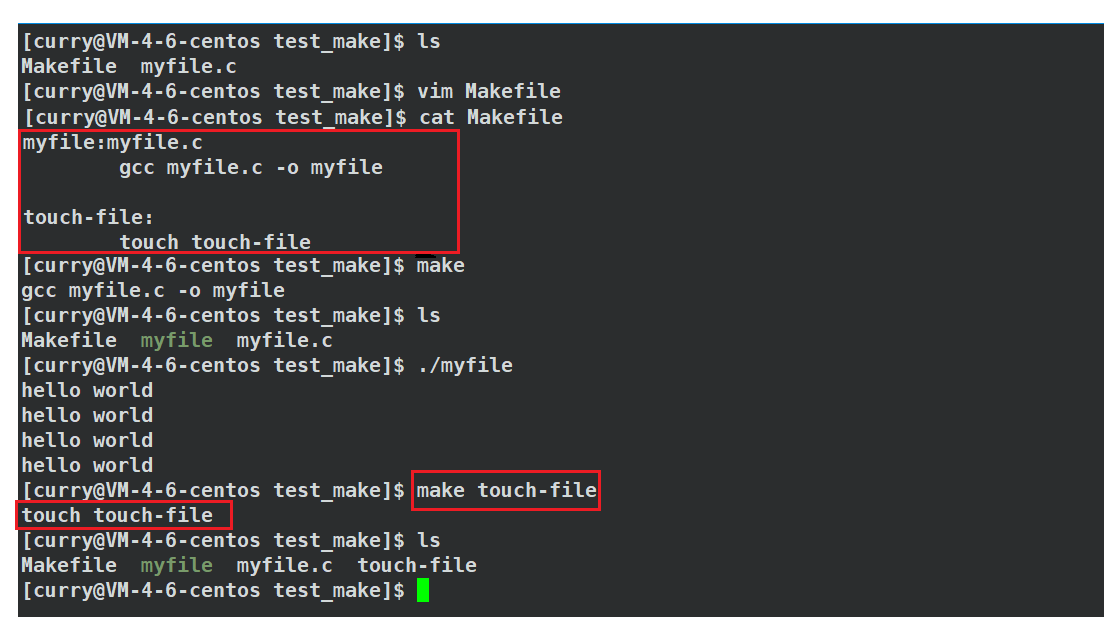
上述例子我们通过clean目标文件创建了一个新的文件touch-file,我们还可以进行一些命令行的其他指令等,依赖项通过其他方式生成还有其他的情况,这里我就不一一进行讲解了,感兴趣的读者下来可以试试。
利用.PHONY修饰目标文件,我们也可以重新编译之前的目标文件了,我们一起来看看:

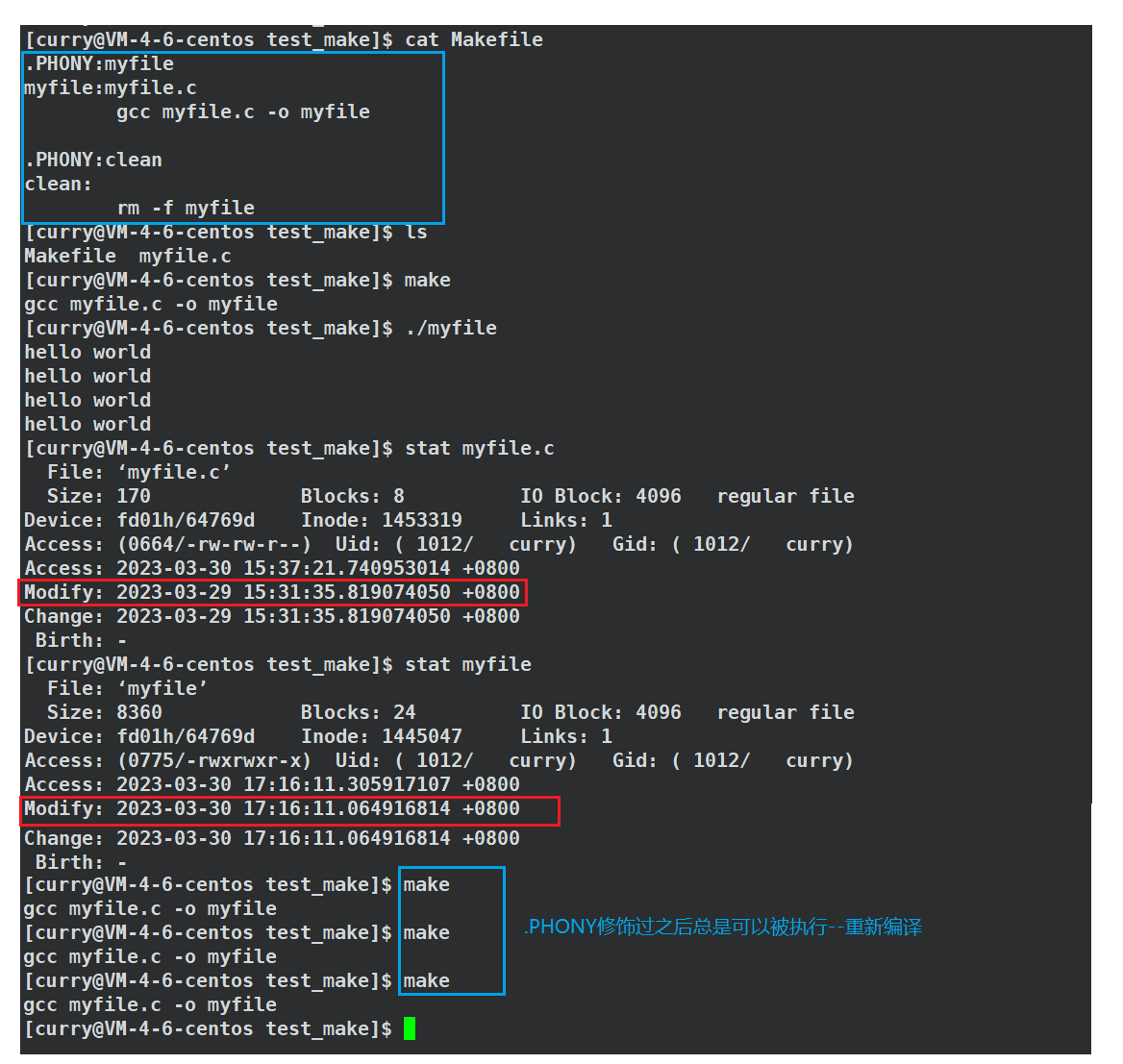
.PHONY修饰目标文件后忽略目标是否存在或是否被更新,直接执行定义的操作,只会更新目标文件的时间戳!!

虽然我们达到了重新编译的目的,但其实我们是非常不推荐这种行为的,因为重新编译需要消耗大量的时间(大型工程中),而且我们的文件内容并没有进行修改,重新编译也没什么必要!!
四、makefile的依赖
我们来看看下面这个例子,它很好的体现了makefile的依赖关系:
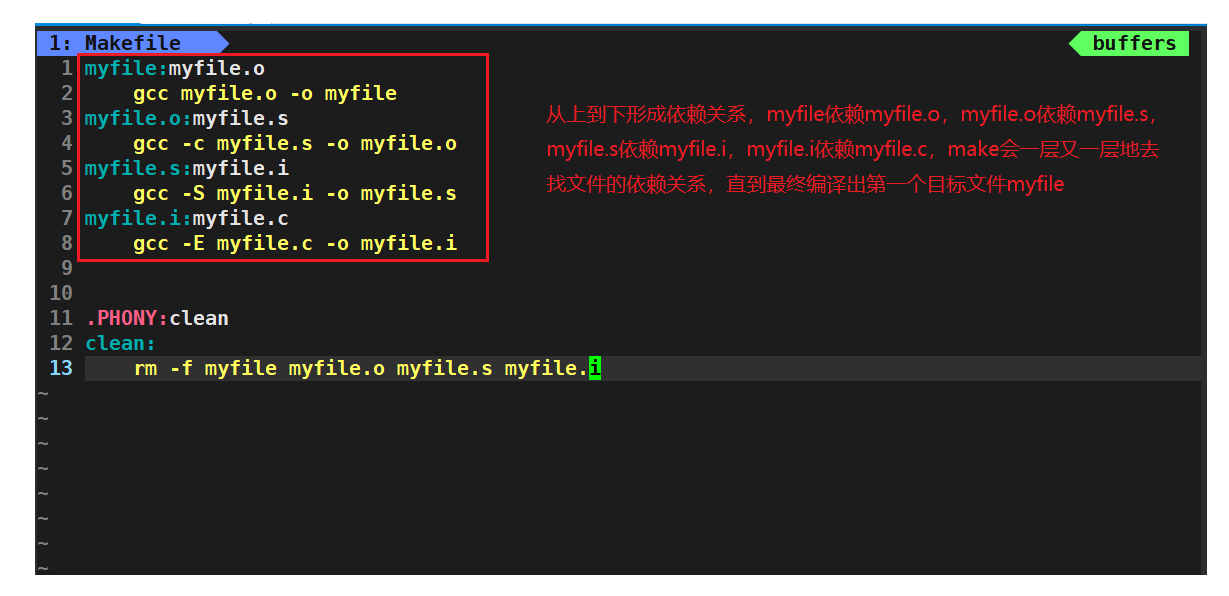
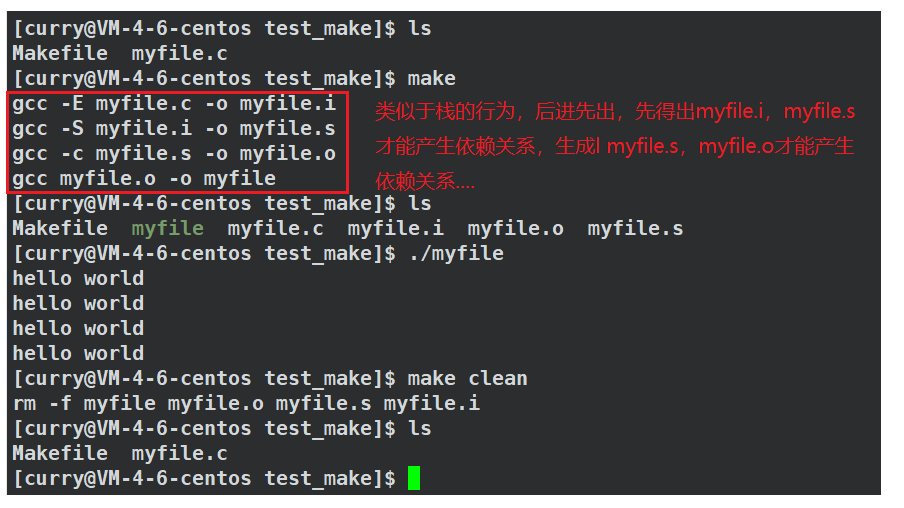
我们平时还是不建议这些写哈,因为没什么必要我们只要得到目标文件就可以了。
五、如何快速编写大型项目中的Makefile文件
我们在前面编写的Makefile文件都只涉及一个源文件的编译链接,但是如果在一个大型项目中我们有很多的源文件需要被合并链接,难道我们一个个的手动去添加吗??
既然有这种问题的出现,那么必然会有对应的解决办法。对于大型工程,我们一般采用模块化的方式组织代码,每个模块对应一个或多个源文件。为了避免将全部源文件写出来进行链接,可以使用通配符或变量来自动化处理源文件!!!
以下是一个示例 Makefile,演示如何使用通配符和变量来构建一个大型工程:
# 编译器
CC = gcc # 列出Makefile所在目录中所有的.c文件
SOURCES := $(wildcard *.c) # 列出SOURCES中所有.c文件对应的.o文件
OBJECTS := $(patsubst %.c,%.o,$(SOURCES)) # 最后生成的目标文件
TARGET = myfile # 目标文件依赖OBJECTS中的所有.o文件,变量使用时需要在变量名前加上"$"符号,并且最好用小括号或者大括号把变量括起来
$(TARGET): $(OBJECTS) $(CC) $^ -o $@ # 所有依赖目标集$^利用CC编译器,一个一个编译成目标文件集$@
%.o: %.c # 所有的.o目标文件依赖于对应的.c文件$(CC) -c $< -o $@ # 所有的.c文件一个一个的取出来,利用CC编译器形成同名对应的.o文件# 清理所有的.o文件以及目标文件
.PHONY:clean
clean:rm -rf $(OBJECTS) $(TARGET)
我们的源文件如下图:

Makefile中的内容:
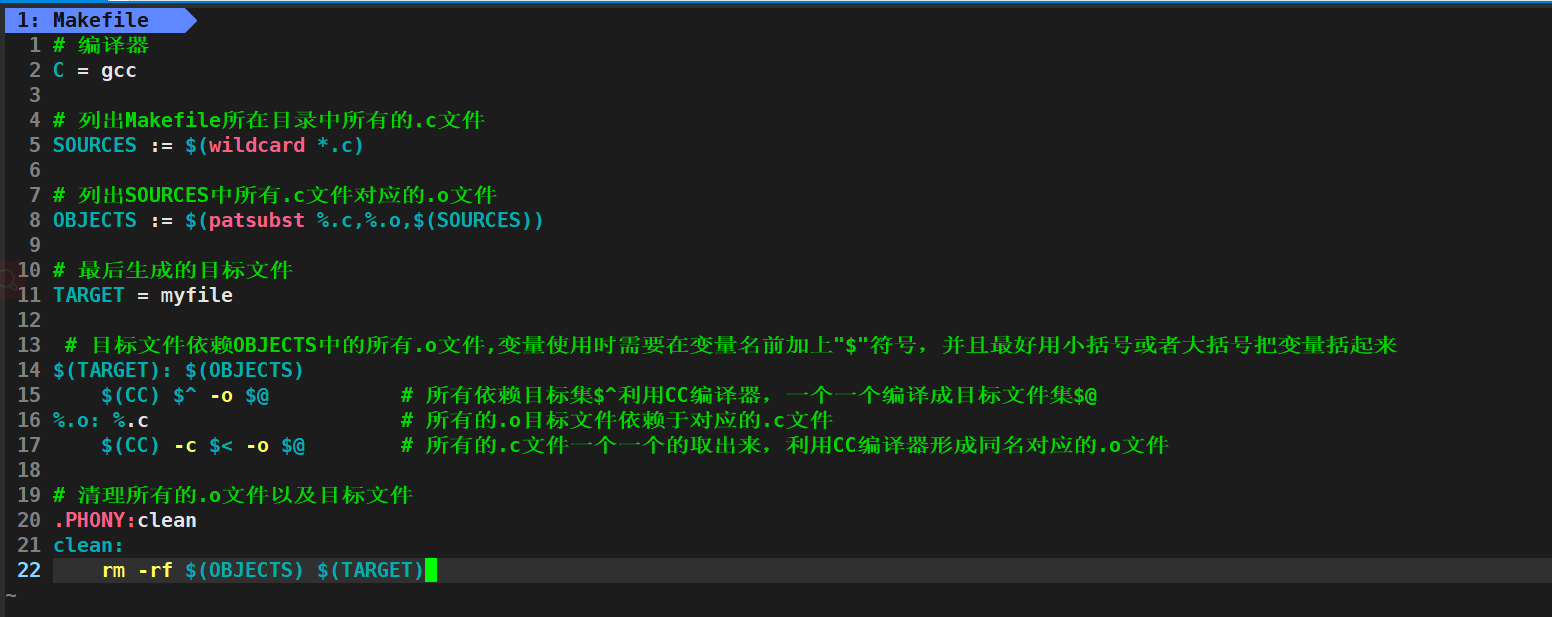
上述图中的CC、SOURCES、OBJECTS以及TARGET都是变量,在Makefile中变量其实也就是C/C++中的宏!!!
在OBJECTS变量中我们使用了一个patsubst模式字符串替换函数。
使用格式:
$(patsubst \<pattern>,\<replacement>,\<text>)。
返回:函数返回被替换过后的字符串。
功能:查找<text> 中的单词(单词以“空格”、“Tab”或“回车”“换行”分隔)是否符合模式 <pattern> ,如果匹配的话,则以 替换。这里, <pattern> 可以包括通配符 % ,表示任意长度的字串。如果<replacement> 中也包含 % ,那么,<replacement> 中的这个 % 将是 <pattern> 中的那个 % 所代表的字串。(可以用 \ 来转义,以 % 来表示真实含义的 % 字符)
注: \$(objects:.o=.c) 和 $(patsubst \%.o,\%.c,\$(objects)) 是一样的,大家下来可以试试。
另外我们上述看到的\$^、$@、\$< 都被叫做自动化变量!!
所谓自动化变量,就是这种变量会把模式中所定义的一系列的文件自动地挨个取出,直至所有的符合模式的文件都取完了。这种自动化变量只应出现在规则的命令中。
下面是所有的自动化变量及其说明:
$@ : 表示规则中的目标文件集。在模式规则中,如果有多个目标,那么, $@ 就是匹配于目标中模式定义的集合。
$% : 仅当目标是函数库文件中,表示规则中的目标成员名。例如,如果一个目标是 foo.a(bar.o) ,那么, $% 就是 bar.o , $@ 就是 foo.a 。如果目标不是函数库文件(Unix下是 .a ,Windows下是 .lib ),那么,其值为空。
$< : 依赖目标中的第一个目标名字。如果依赖目标是以模式(即 % )定义的,那么 $< 将是符合模式的一系列的文件集。注意,其是一个一个取出来的。
$? : 所有比目标新的依赖目标的集合。以空格分隔。
$^ : 所有的依赖目标的集合。以空格分隔。如果在依赖目标中有多个重复的,那么这个变量会去除重复的依赖目标,只保留一份。
$+ : 这个变量很像 $^ ,也是所有依赖目标的集合。只是它不去除重复的依赖目标。
$* :这个变量表示目标模式中 % 及其之前的部分。如果目标是 dir/a.foo.b ,并且目标的模式是 a.%.b ,那么, $* 的值就是 dir/foo 。这个变量对于构造有关联的文件名是比较有效。如果目标中没有模式的定义,那么 $* 也就不能被推导出,但是,如果目标文件的后缀是make所识别的,那么 $* 就是除了后缀的那一部分。例如:如果目标是 foo.c ,因为 .c 是make所能识别的后缀名,所以, $* 的值就是 foo 。这个特性是GNU make的,很有可能不兼容于其它版本的make,所以,你应该尽量避免使用 $* ,除非是在隐含规则或是静态模式中。如果目标中的后缀是make所不能识别的,那么 $* 就是空值。
通过上述使用变量以及通配符我们已经配置好了一个简单的自动化构建的Makefile文件,下面我们来检测一下:
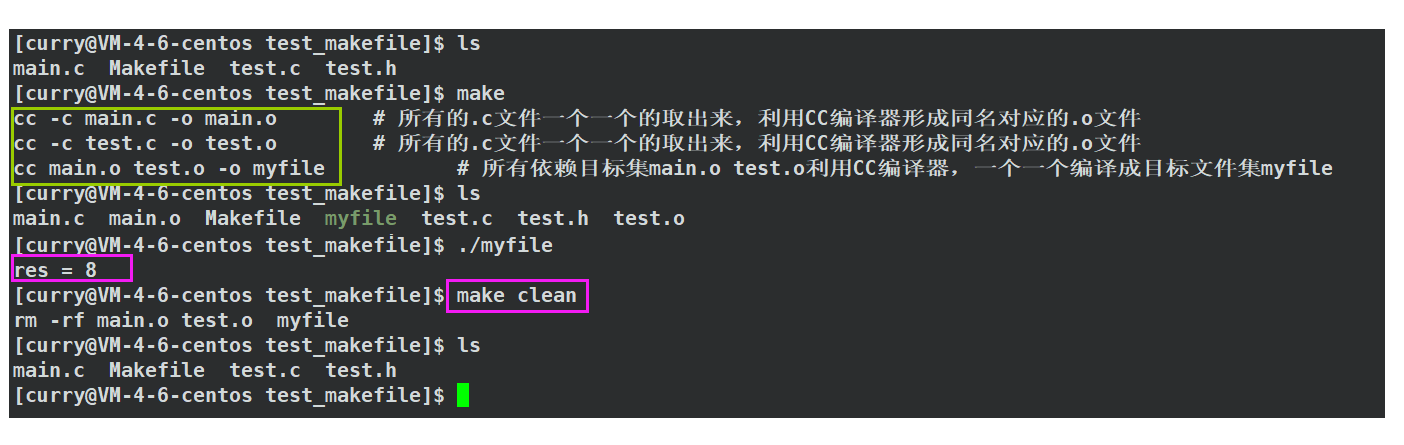
通过这种方式,我们就实现了自动化处理大量的源文件,避免了手动编译的繁琐。
本篇文章的Makefile就讲到这里了,它是我们开发项目中非常重要的一个工具,它非常的灵活。一个Makefile写的好不好决定了你的工作效率;另外,其实Makefile其实还有很多功能在这篇文章中并未进行展示,因为博主的精力和水平还不够就讲了大致的一部分的,如果有读者感兴趣的话可以拜读一下这位巨佬的博客分享哦orz~🙈🙈
相关文章:
【Linux】项目自动化构建工具make/makefile
🏖️作者:malloc不出对象 ⛺专栏:Linux的学习之路 👦个人简介:一名双非本科院校大二在读的科班编程菜鸟,努力编程只为赶上各位大佬的步伐🙈🙈 目录 前言一、make/makefile的背景二、…...

【系分范文】论软件需求获取技术以及应用
目录 论题论题介绍论文要点理论素材准备范文摘要正文论题 论软件需求获取技术以及应用 论题介绍 软件需求是指用户对新系统在功能、行为、性能、设计约束等方面的期望。软件需求获取是一个确定和理解不同的项目干系人的需求和约束的过程。需求获取是否科学、准备充分,对获取…...

vue2.0中post请求
vue2.0中post请求 三种格式:在vue中axois的用法:1、 multipart/form-data类型2、 x-www-form-urlencoded类型3、 application/json类型 三种格式: ○ Content-Type:x-www-form-urlencoded ○ Content-Type:multipart/form-data ○ Content…...

MySQL双写缓冲区(Doublewrite Buffer)
本文已收录至Github,推荐阅读 👉 Java随想录 文章目录 摘要为什么需要Doublewrite BufferDoublewrite Buffer原理Doublewrite Buffer相关参数总结 摘要 InnoDB是MySQL中一种常用的事务性存储引擎,它具有很多优秀的特性。其中,Dou…...
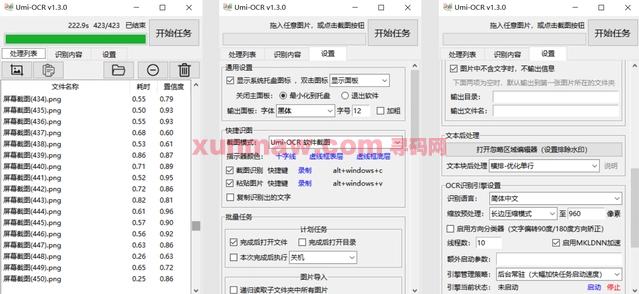
免费开源的Umi-OCR 文字识别工具
大家好,我是小寻,欢迎关注公众号:工具优选,免费领取优质项目源码和常用工具,还可以加入我的交流群! 如今,在日常生活和工作中,我们经常需要捕捉屏幕截图并识别其中的文本信息。比如别人给你发资料时直接发…...

如何让微信小程序弹窗滚动条设置在最上面
最近发现一个事情搞得很烦,微信小程序的弹窗内容可以滚动的时候,要保证每一次打开都在最上面,研究了一下终于发现了怎么解决 第一步 首先得把你的弹窗里面的内容用scroll-view标签包起来,像这样 <scroll-view style"hei…...
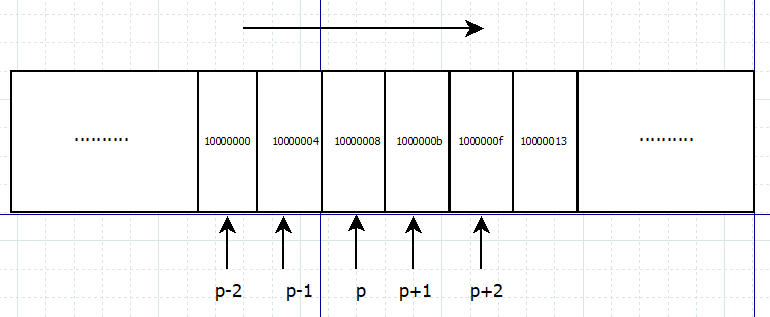
c语言-指针
指针详解 这段时间在看 Linux内核,深觉C语言功底不扎实,很多代码都看不太懂,深入学习巩固C语言的知识很有必要。先从指针开始。 什么是指针 C语言里,变量存放在内存中,而内存其实就是一组有序字节组成的数组&…...
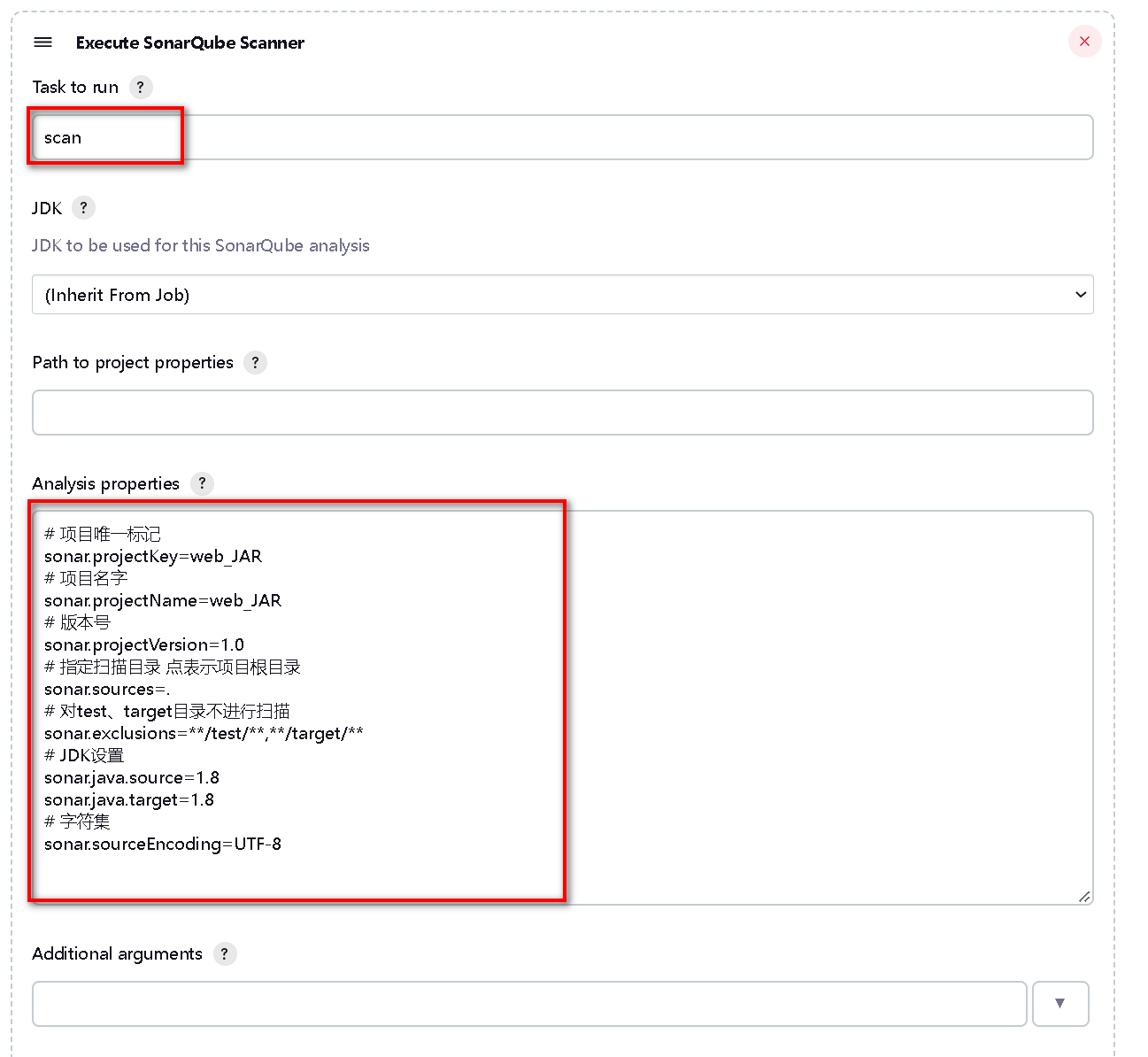
Jenkins集成SonarQube实现代码质量检查
文章目录 一、前提配置1.1 安装及配置SonarQube Scanner插件1.2 配置SonarQube servers 二、非流水线集成SonarQube1.1 配置非流水线任务 三、流水线集成SonarQube 一、前提配置 1.1 安装及配置SonarQube Scanner插件 (1) 点击【系统管理】>【插件管理】>【可选插件】搜…...

2023 谷歌I/O发布会新AI,PALM 2模型要反超GPT-4,一雪前耻!
文章目录 1 前言2 Google I/O 发布者大会3 PaLM 2模型3 Bard项目4 其他AI工具4.1 AI 图片编辑 Magic Editor4.2 Duet AI 办公4.3 Universal Translator 翻译工具4.4 Google 沉浸式导航4.5 Google 搜索引擎 5 讨论 1 前言 每年必看两大会,苹果发布会和谷歌发布会&am…...
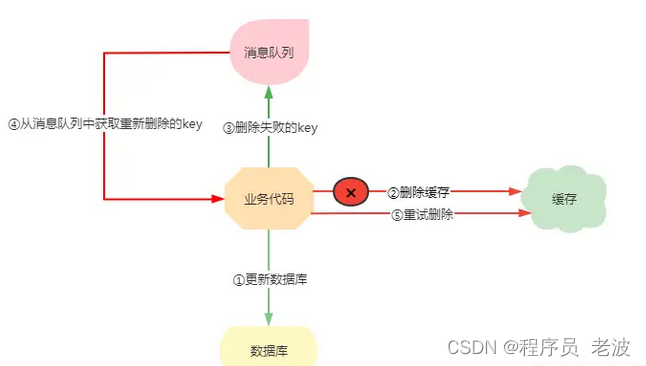
MySQL和Redis如何保证数据一致性?
前言 由于缓存的高并发和高性能已经在各种项目中被广泛使用,在读取缓存这方面基本都是一致的,大概都是按照下图的流程进行操作: 但是在更新缓存方面,是更新完数据库再更新缓存还是直接删除缓存呢?又或者是先删除缓存再…...
)
Markdown使用(超详细)
(HBuilderX) 掌握md及HBuilderX对md的强大支持。如果没有点右键设置自动换行,可按Alt滚轮横向滚动查看。 很多人只把markdown用于网络文章发表,这糟蹋了markdown。 markdown不止是HTML的简化版,更重要的是txt的升级版…...

yolov5实现扑克牌识别的产品化过程
文章目录 介绍项目下载硬件准备软件环境素材获取自行获取素材网盘获取图片标注模型训练窗口截图窗口截图(HWND)桌面截图wgc方法最终采用的方式WGC使用方法如何保存灰度图片python 如何加载dll库图片推理扑克牌逻辑ui编写模型加密软件授权软件加密软件打包安装包制作...

第07讲:Java High Level Client,读写 ES 利器
SkyWalking OAP 后端可以使用多种存储对数据进行持久化,例如 MySQL、TiDB 等,默认使用 ElasticSearch 作为持久化存储,在后面的源码分析过程中也将以 ElasticSearch 作为主要存储进行分析。 ElasticSearch 基本概念 本课时将快速介绍一下 E…...

dockerfile暴力处理配置文件外提
前言: 一般来说,springboot打成的jar运行时,同目录/config目录下放application.yml文件会被进行加载,然后通过设置docker映射出宿主机即可做到配置文件外配的效果,但很多时候别的配置文件做不到这种效果,说…...
如何快速给出解释——正交矩阵子矩阵的特征值的模必然不大于1
Memory 首先快速回忆一下正交矩阵的定义: A为n阶实矩阵,且满足A‘AE或是说AA’E,那么A为正交矩阵。 (啊,多么简洁的定义) 其次快速想到它的性质: ① 实特征值必然 或 其他复数…...

c语言-位运算
位运算小结 位运算不管是在C语言中,或者其他语言,都是经常会用到的,所以本文也就不固定以某种语言来举例子了,原始点就从0、1开始。位运算主要包括按位与(&)、按位或(|)、按位异或(^)、取反(~)、左移(<<)、右移(>…...

【Android学习专题】安卓样式学习(学习内容记录)
学习记录内容来自《Android编程权威指南(第三版)》 样式调整和添加 调整颜色资源(res/values/colors.xml) 格式: 添加样式(res/values/styles.xml),(创建BeatBox项目时…...

普罗米修斯统计信息上报结构设计
为了实现高效的监控和警报,普罗米修斯提供了一个强大的统计信息上报机制。通过这个机制,可以将应用程序的各种统计信息发送到普罗米修斯,普罗米修斯会对这些信息进行处理,然后提供丰富的监控和警报功能。下面是基本的统计信息上报…...

两个系统之间的传值
在两个系统之间传值可以采用以下几种方式: 使用 URL 参数:可以将数据作为 URL 参数传递给另一个系统,另一个系统可以解析 URL 参数并获取数据。例如:Example Domain 使用 Cookie:可以在一个系统中设置 Cookie…...
PostgreSQL(五)JDBC连接串常用参数
目录 1.单机 PostgreSQL 连接串2.集群PostgreSQL 连接串 PostgreSQL JDBC 官方驱动下载地址: https://jdbc.postgresql.org/download/ PostgreSQL JDBC 官方参数说明文档: https://jdbc.postgresql.org/documentation/use/ 驱动类: driver-…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...