Python进阶知识(1)—— 什么是爬虫?爬文档,爬图片,万物皆可爬,文末附模板
文章目录
- 01 | 🍒 什么是 P y t h o n 爬虫? \color{red}{什么是Python爬虫?} 什么是Python爬虫?🍒
- 02 | 🍊 怎么发起网络请求? \color{orange}{怎么发起网络请求?} 怎么发起网络请求?🍊
- 03 | 🍋 怎么解析 H T M L 页面 \color{yellow}{怎么解析HTML页面} 怎么解析HTML页面🍋
- 04 | 🥒 怎么提取数据? \color{green}{怎么提取数据?} 怎么提取数据?🥒
- 05 | 🧙♂️ 怎么进行数据存储 \color{blue}{怎么进行数据存储} 怎么进行数据存储🧙♂️
- 06 | 🎫 怎么进行数据预处理? \color{cyan}{怎么进行数据预处理?} 怎么进行数据预处理?🎫
- 07 | 🍇 怎么进行数据可视化? \color{purple}{怎么进行数据可视化?} 怎么进行数据可视化?🍇
- 08 | 🌸 爬虫模板 \color{pink}{爬虫模板} 爬虫模板🌸
A bold attempt is half success.
勇敢的尝试是成功的一半。

01 | 🍒 什么是 P y t h o n 爬虫? \color{red}{什么是Python爬虫?} 什么是Python爬虫?🍒

Python爬虫是一种利用编程语言Python从互联网上自动获取大量数据的技术。通常采用模拟网页浏览器行为,通过访问URL、解析HTML页面并提取数据等操作,实现对网络信息资源的信息抓取和处理,生成所需的数据集合。
调用Python库中的HTTP库或框架,如Requests或Scrapy,向目标网站发出请求,从而获得网站上的数据,并将它们解析成Python可处理的格式(Python对象)。待解析完毕后,程序可以对数据进行保存、分析、加工及可视化展示等相关处理。
Python爬虫主要包括以下步骤:
-
发起网络请求,下载网页内容 \color{red}{发起网络请求,下载网页内容} 发起网络请求,下载网页内容:使用 Python 库中的 HTTP 库或框架,如urllib或requests等,向目标网站发出符合HTTP协议规范的请求,获取需要爬取的网页内容。
-
解析 H T M L 页面 \color{orange}{解析 HTML 页面} 解析HTML页面:根据需要爬取的内容所在的 HTML 元素,使用 HTML 解析器,如BeautifulSoup或pyquery,来解析网页的结构和内容。
-
提取数据 \color{green}{提取数据} 提取数据:对解析后的 HTML 文档进行筛选、过滤并提取有价值的数据,并将其存储到本地文件或数据库中。
-
数据预处理 \color{blue}{数据预处理} 数据预处理:对爬取回来的数据进行格式转换、去除异常数据并归纳整理,方便后续的挖掘和应用。
-
数据可视化或数据挖掘 \color{cyan}{数据可视化或数据挖掘} 数据可视化或数据挖掘:根据需求,使用Python库中的可视化工具,如Matplotlib和Seaborn等库,或数据挖掘工具,如NumPy和pandas等库,对预处理后的数据进行分析处理并展示出来。
需要注意的是,爬虫在网络上获取信息时需要遵守相关法律法规,并尊重网站的版权及数据安全等相关问题。同时,在爬取过程中还需要注意防范反扒机制和反爬虫策略产生的限制。
当涉及到网络数据采集时,Python是一种非常有用的编程语言。该语言通过其各种库和框架支持爬虫脚本的编写。以下是关于Python爬虫的基本知识:
02 | 🍊 怎么发起网络请求? \color{orange}{怎么发起网络请求?} 怎么发起网络请求?🍊

Python爬虫可以利用内置的 urllib 库或第三方库 requests 发起网络请求,其中使用 requests 库更加方便,因此下文主要介绍该库的用法。
requests 是一个易于使用且功能强大的第三方 HTTP 库,它包含了各种各样的函数和参数,使得网页抓取变得更为简单。发起 HTTP 请求时,我们可以通过发送 GET、POST等不同方法的请求,同时还可以设置请求头、请求参数、代理设置、cookies管理等相关信息。
以下是一个发起GET请求的示例代码:
import requestsurl = 'https://www.baidu.com/'
response = requests.get(url)
print(response.status_code) # 打印响应状态码
if response.status_code == 200:print(response.text) # 打印网页HTML源代码
通过 requests.get()函数来实现对百度首页的请求,将返回的响应结果保存在response变量中。调用 status_code() 方法获取响应状态码,如果状态码为200则表示请求成功,并调用 text 属性获取网页HTML源代码,最后将网页代码输出到控制台上。
注意:requests 在访问时可能会出现超时、请求异常等情况,需要针对性进行异常处理,并添加报错信息以确保程序安全稳定地运行。
除了发送GET请求,我们还可以通过 requests.post() 实现POST请求,只需在传递URL参数后,再设置相关的参数,如请求头、请求数据等,即可完成POST请求。以下是一个示例代码:
import requestsurl = 'https://www.xxx.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
data = {'username': 'xxx', 'pw': '123456'}
response = requests.post(url, headers=headers, data=data)
print(response.json()) # 打印JSON格式响应数据
该示例代码利用 requests.post() 方法向一个URL发起POST请求,并通过设置请求头及请求数据,模拟用户登录行为。调用 json() 属性解析返回的JSON格式数据,最终输出结果到控制台。
需要注意的是,在实际使用中,我们可以将请求头、请求参数等内容进行封装,使程序更加简单易用同时减少重复操作,提高代码复用率。
03 | 🍋 怎么解析 H T M L 页面 \color{yellow}{怎么解析HTML页面} 怎么解析HTML页面🍋

在Python爬虫中,我们可以使用第三方库如Beautiful Soup、pyquery等来解析HTML页面,并提取网页所需的数据。下面以Beautiful Soup为例,介绍解析HTML页面的基本流程。
首先,需要安装Beautiful Soup库和相关依赖:
pip install BeautifulSoup4
然后,导入库文件并使用requests库发起请求获取目标网页的源码:
import requests
from bs4 import BeautifulSoupurl = 'http://www.example.com'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
其中response保存了请求的响应内容,soup是一个BeautifulSoup对象。当然,前提条件是要保证requests成功返回了网页源码。
接着,我们就可以遍历页面上的DOM节点并提取所需要的数据。常用的两种方法是find和find_all。如果我们想查找页面上的某个标签(如h1)并显示其内容,则可以将以下代码添加到上述示例中:
title = soup.find('h1').text
print(title)
这里的find()相当于在页面节点树上递归查找第一个符合条件的元素。
如果我们想要查找所有满足条件的HTML标签,在循环处理标签时,可以采用find_all()匹配多个标签,如:
all_links = soup.find_all('a')
for link in all_links:print(link.get('href'))
其中,link.get("href")获取a标签的href属性。
在解析完HTML页面之后,我们可以将提取到的内容存储到文件、数据库或者内存中进行后续处理。需要注意的是,在遍历DOM树时,要注意验证节点是否为空,以及是否符合预期,方可保证代码稳定性和可靠性。另外,如果想要提取特定的CSS选择器或XPath表达式中的信息,则可以使用其他Python库(如lxml)实现。
04 | 🥒 怎么提取数据? \color{green}{怎么提取数据?} 怎么提取数据?🥒

在Python爬虫中,数据提取是一个非常重要的过程。通常来说,我们从HTML页面中提取有用的信息,可以采用以下几种方式:
-
使用正则表达式匹配
-
使用XPath或CSS选择器解析
-
使用Python内置的字符串处理函数解析
其中,使用正则表达式的方法需要较高的技能和经验,并且容易出现错误,后面再进行正则表达式的学习。这里使用XPath或CSS选择器解析更加直观和简单,这里以Beautiful Soup为例来介绍如何利用XPath或CSS选择器提取数据。
在 Beautiful Soup 中,可以通过 find 和 find_all 方法查找匹配某个 CSS 选择器或者 XPath 表达式的元素。使用 CSS 选择器时,将选择器作为 find 或者 find_all 的参数即可:
soup.find_all('p a') # 查找所有 <p> 元素中包含 <a> 元素的数据
使用 XPath 表达式时,在执行 find、find_all 或 select 时传递参数 ‘xpath’ 即可:
soup.find_all(xpath='//p/a') # 查找所有 <p> 元素中的 <a> 元素
和直接使用 CSS 选择器相比,XPath 更加强大,但也更加复杂,需要对语法有一定的了解。
拿到匹配的元素后,可以通过 BeautifulSoup 对象的 text 属性获取该元素的文本值,也可以通过 attrs 属性获取其他属性值,例如:
for link in soup.find_all('a'):print(link['href'], link.text) # 输出 href 属性和 text 内容
另外,对于某些比较特殊的数据提取需求,我们可以进一步使用Python内置的字符串处理函数,如 split()、strip()等方法对文本进行分割和处理。
在爬虫过程中,提取到的数据可能需要进一步进行整理,清洗和转换等操作,在进行这些操作时,要注意数据的类型和格式,以避免错误出现。
05 | 🧙♂️ 怎么进行数据存储 \color{blue}{怎么进行数据存储} 怎么进行数据存储🧙♂️

Python脚本通常需要直接或间接地保存数据以供后续使用。常见的数据存储选项包括文件、数据库,以及云存储等等。例如,以下代码将使用Pandas库将搜索结果保存到CSV文件中:
from bs4 import BeautifulSoup
import requests
import pandas as pdresponse = requests.get('https://www.baidu.com/s?wd=python')
soup = BeautifulSoup(response.content, 'html.parser')results = []
for result in soup.find_all('h3', {'class': 't'}):results.append(result.text)df = pd.DataFrame({'results': results})
df.to_csv('search_results.csv', index=False)
该代码从百度搜索“Python”并将搜索结果解析为HTML。然后,它使用Pandas库将数据转换为数据框,并将其保存到名为search_results.csv的CSV文件中。
总之,在Python爬虫方面,请求库和解析器是很重要的工具,因为它们可以帮助Python脚本与Web应用程序交互,并从HTML页面中提取所需的数据。同时,不同的数据存储选项也可以提供更多的选择来备份或分享网络采集数据。
06 | 🎫 怎么进行数据预处理? \color{cyan}{怎么进行数据预处理?} 怎么进行数据预处理?🎫

在数据爬取过程中,我们获取到的数据可能存在多种不规范、重复和缺失等问题,因此需要对数据进行预处理,以提高后续分析和应用的准确性和可靠性。以下是一些常用的数据预处理方法:
-
数据清洗 \color{red}{数据清洗} 数据清洗:清除数据中的异常值和噪声,例如空值、重复值、特殊符号和无效字符等。可以使用Pandas库中的dropna()、drop_duplicates()等方法来实现。
-
数据结构转换 \color{orange}{数据结构转换} 数据结构转换:将数据格式化为适合在其他系统上使用的数据结构,例如将数据从CSV格式转换为JSON格式。
-
数据归一化 \color{yellow}{数据归一化} 数据归一化:将数据统一处理,消除数据之间的差异性,例如将统计指标按照某种方式进行标准化,以保证其具有可比性。
-
数据规范化 \color{green}{数据规范化} 数据规范化:规范化数据的单位、格式和描述等信息,使其符合特定的标准。
-
特征选择 \color{blue}{特征选择} 特征选择:根据具体应用场景选择合适的特征变量,并去掉冗余变量,以降低模型的复杂度。
-
特征提取 \color{cyan}{特征提取} 特征提取:利用数据挖掘和机器学习等技术,对数据进行降维或者抽象处理,以提取出最具代表性的特征变量。
-
数据分布统计 \color{purple}{ 数据分布统计} 数据分布统计:通过对数据进行统计学分析来了解数据的分布情况、结构特征等。可以使用Python内置的统计函数,如mean()、std()、median()等来实现。
在实际操作中,我们通常需要多种方法的组合才能达到最佳的预处理效果。在选择预处理方法时,要根据实际场景和数据类型进行灵活调整和优化,以提高数据质量和后续应用价值。
07 | 🍇 怎么进行数据可视化? \color{purple}{怎么进行数据可视化?} 怎么进行数据可视化?🍇

Python作为一种高级编程语言,可以方便地对爬取到的数据进行可视化和数据挖掘,以帮助我们更好地理解数据、分析数据和展示数据。以下是一些常用的数据可视化和数据挖掘方法:
-
数据可视化 \color{blue}{数据可视化} 数据可视化
在进行数据可视化时,Python中最常用的库是Matplotlib和Seaborn。这些库可以绘制各种类型的图表和图形,如线图、柱状图、饼图、散点图等。此外,还可以结合Pandas,使用它的DataFrame来处理和可视化数据。
-
数据挖掘 \color{cyan}{数据挖掘} 数据挖掘
Python中最常用的数据挖掘工具是Scikit-learn和NumPy。Scikit-learn基于科学计算库NumPy和SciPy,提供了大量的算法和技术,如聚类、分类、回归、特征选择、降维等。同时,Scikit-learn也支持可视化工具,如数据集的分布和预测情况的可视化。除了Scikit-learn,还有其他开源的Python工具,例如NLTK(自然语言处理),Gensim(主题建模)等。
-
W e b 应用程序 \color{PURPLE}{Web应用程序} Web应用程序
Python也是一个非常适合构建Web应用的语言。可以使用Flask或Django等框架,将数据挖掘和数据可视化功能结合起来,搭建出一款完整的数据分析平台。在这种平台上,可以将数据保存到数据库中,通过Web UI进行处理和展示。
总体来说,Python提供了丰富的工具和库,可以让我们轻松实现对爬虫数据的可视化和数据挖掘。但在实际应用中要注意,选择合适的工具和方法,以及合理处理和清洗数据非常重要,才能得到准确、有用且易于理解的结果。
08 | 🌸 爬虫模板 \color{pink}{爬虫模板} 爬虫模板🌸

-
使用Python爬取网站图片:
-
使用requests库获取网页内容
import requestsurl = "https://www.example.com" response = requests.get(url)可以通过以上代码获取URL对应的网页内容,存储在变量‘response’中。
-
使用BeautifulSoup解析HTML文档
from bs4 import BeautifulSoupsoup = BeautifulSoup(response.text, 'html.parser')使用BeautifulSoup库将获取到的HTML文档进行解析,并转化成内部的数据结构,方便后续的信息提取。
-
获取图片标签和链接
img_list = soup.find_all('img') # 查找所有<img>标签 for img in img_list:url = img['src'] # 获取图片链接地址filename = url.split('/')[-1] # 获取图片名称response_img = requests.get(url)with open(filename, 'wb') as f:f.write(response_img.content) # 把图片写入文件在第三步中,我们遍历了所有的‘img’标签,提取出了其中的图片链接地址,并根据链接地址中最后一个斜杠后的内容,提取了图片的本地文件名。然后,我们使用requests库再次向图片链接地址发送请求,获得二进制的图片内容,最后将其保存到本地文件中,以实现图片下载的功能。
需要注意的是,在爬取过程中,存在一些图片链接地址是相对路径的情况,此时需要将其转换为绝对路径。在某些场景下,还可能需要登录网站或者模拟登录才能够获取到网页的内容和相关的图片链接地址。除此之外,在使用爬虫进行图片下载时,还应该遵从网络道德规范和法律法规,不要违反任何网站的协议和规定。
-
-
爬取小说
Python可以使用requests和beautifulsoup4库来实现小说网站的爬取,并将获取到的内容保存到本地txt文件中。下面是一个简单的Python爬虫示例,用于从指定网站上获取小说内容:
import requests from bs4 import BeautifulSoupurl = 'https://www.example.com/novel/1234' response = requests.get(url) # 发送请求if response.status_code == 200: # 判断是否成功响应soup = BeautifulSoup(response.content, 'html.parser')title = soup.h1.text.strip() # 获取小说名称content = soup.find(id='content') # 查找小说内容content = content.text.replace('\r\n\r\n', '\n').strip() # 清理字符串的空白和换行符with open(title + '.txt', 'w', encoding='utf-8') as file:file.write(content)print('小说{}已经存储在本地文件{}中'.format(title, title+'.txt')) else:print('小说获取失败')在以上代码中,我们首先使用requests库向目标网站发送http请求,获得小说内容所对应的HTML文档。然后,使用BeautifulSoup库进行页面解析,查找小说的标题和内容,并清除多余空格和换行符。
最后,使用Python内置的打开文件操作函数,创建一个以小说名命名的TXT文件,并将小说内容写入文件中,实现了小说信息的本地存储。如果程序运行正常,则在终端中输出“小说已经存储在本地文件中”的提示,否则输出“小说获取失败”的错误信息。需要注意的是,在爬取小说等文本内容时,应该依法依规,遵循相关法规和道德规范,不要通过非法或不当手段进行文本采集和公开传播。同时,我们还应该尽可能考虑到对被爬取网站的服务器负载和安全的影响,以免造成恶劣影响和法律后果。
相关文章:
Python进阶知识(1)—— 什么是爬虫?爬文档,爬图片,万物皆可爬,文末附模板
文章目录 01 | 🍒 什么是 P y t h o n 爬虫? \color{red}{什么是Python爬虫?} 什么是Python爬虫?🍒02 | 🍊 怎么发起网络请求? \color{orange}{怎么发起网络请求?} 怎么发起网络请求…...

如何在andorid native layer中加log function.【转】
在开发Android一些应用或是链接库, 在程序代码中埋一些log是一定有需要的, 因为谁也无法保证自己所写出来的程序一定没有问题, 而log机制正是用来追踪bug途径的一种常用的方法. 在andorid中提供了logcat的机制来作log的目的, 在javalayer有logcat class可以用,哪在nativelayer呢…...
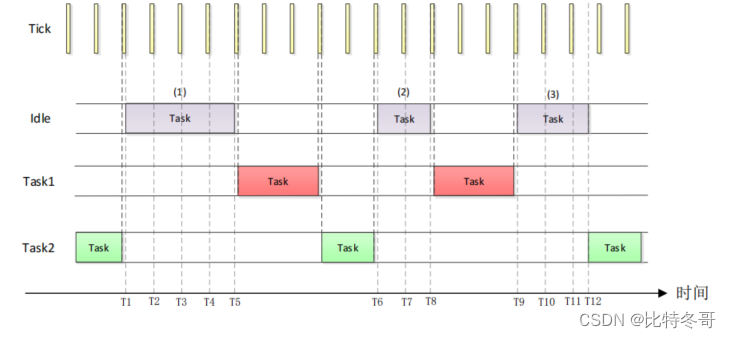
FreeRTOS 空闲任务
文章目录 一、空闲任务详解1. 空闲任务简介2. 空闲任务的创建3. 空闲任务函数 二、空闲任务钩子函数详解1. 钩子函数2. 空闲任务钩子函数 三、空闲任务钩子函数实验 一、空闲任务详解 1. 空闲任务简介 当 FreeRTOS 的调度器启动以后就会自动的创建一个空闲任务,这…...

快速生成HTML结构语法、快速生成CSS样式语法以及emmet
快速生成HTML结构语法 1、生成标签直接输入标签名按Tab键即可 比如 div 然后tab键 2、如果要生成多个相同标签,加上就可以了,比如 div3就可以快捷生成三个div 3、如果有父子级关系的标签,可以用 > 比如 ul>li 就可以了 4、如果有兄弟关…...

企业直播该如何做?硬件设备、网络环境、设备连接和观看权限等整个直播流程教程
这是一份面向直播新手的企业直播说明教程,字数较多,完整看完,可能会需要求10分钟,建议您可以【收藏】,如果本文章对您有帮助,就帮助【点个赞】吧~~~ 阿酷TONY / 2023-5-12 / 原创文章 / 长沙 / 文章…...
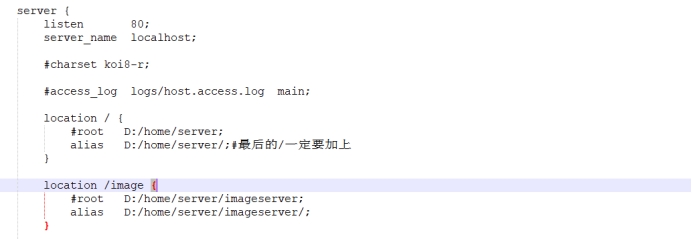
第4章 静态网站部署
第4章 静态网站部署 Nginx是一个HTTP的web服务器,可以将服务器上的静态文件(如HTML、图片等)通过HTTP协议返回给浏览器客户端 4.1 案例:将ace-master这个静态网站部署到Nginx服务器上 4.1.1 通过Xftp将ace-master到linux服务器…...
免费版的mp3格式转换器有哪些?这三款软件帮你实现!
在娱乐文化越来越丰富的今天,人们越来越追求音乐、视频等娱乐方式,其中音乐作为一种能够治愈心灵的艺术形式备受欢迎。但要欣赏一首美妙的音乐,就需要我们自己去制作、编辑并转换其格式,以适应各种软件如MP3、MP4等格式。 方法一…...
版本控制器git
目录 一、版本控制系统 二、工作流程和使用命令 (1)工作流程 (2)一次完整流程的相关命令 1.初始化1个空的本地仓库 2.克隆方式1个远程仓库到本地仓库 3.新文件添加到暂存区 4.查看仓库状态,显示有变更的文件 5…...

接口自动化测试 vs. UI自动化测试:为什么前者更快,更省力,更稳定?
从入门到精通!企业级接口自动化测试实战,详细教学!(自学必备视频) 目录 前言: 一、什么是接口自动化测试和 UI 自动化测试 二、为什么接口自动化测试效率比 UI 自动化测试高 1.执行速度 2.维护成本 3.…...

看Chat GPT解答《情报学基础教程》课后思考和习题
情报学基础教程课后思考题 情报学经验规律 (一)按照布拉德福定律,设布拉德福常数为5, 当核心期刊数量为20时,外围一区和外围二区期刊数量各是多少? 答: 核心期刊数和外围期刊比例关系:nc: n1: n2 = 1: a : a2 (a称为布拉德福常数) 外围一区期刊数量为20*5=100,…...
线程同步、生产者消费模型和POSIX信号量
gitee仓库: 1.阻塞队列代码:https://gitee.com/WangZihao64/linux/tree/master/BlockQueue 2.环形队列代码:https://gitee.com/WangZihao64/linux/tree/master/ringqueue 条件变量 概念 概念: 利用线程间共享的全局变量进行同…...
(六)实现好友管理:教你如何在即时通信系统中添加好友
文章目录 一、引言1.1 即时通信系统中用户增加好友功能的重要性和应用场景1.2 TCP连接传输用户增加好友请求的基本原理 二、实现用户增加好友功能2.1 实现用户好友列表的展示和管理2.1.1 使用QListWidgetItem控件展示好友列表客户端关键代码展示服务端关键代码展示 三、效果展示…...

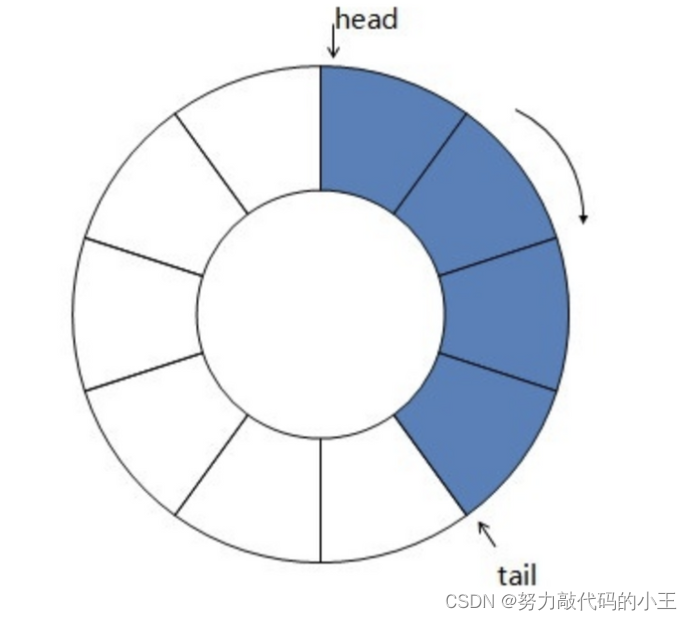
使用循环数组和环形链表实现双端队列
本文主要介绍了两种实现双端队列的数据结构 —— 基于环形链表和循环数组。两种实现方式的基本原理和特点,以及详细的Java代码实现和分析。 引言 双端队列(Deque, Double-ended queue)是一种具有队列和栈的性质的数据结构。它允许在两端插入和删除元素,…...
谁想和我一起做低代码平台!一个可以提升技术,让简历装x的项目
序言 正如文章标题所述,最近一段时间低代码这个概念非常的火,但其实在不了解这个东西的时候觉得它真的很炫酷,从那时就萌生了做一个低代码平台的想法。 但随着时间的变化,现在市面上低代码各个业务方向的平台都有了,可…...
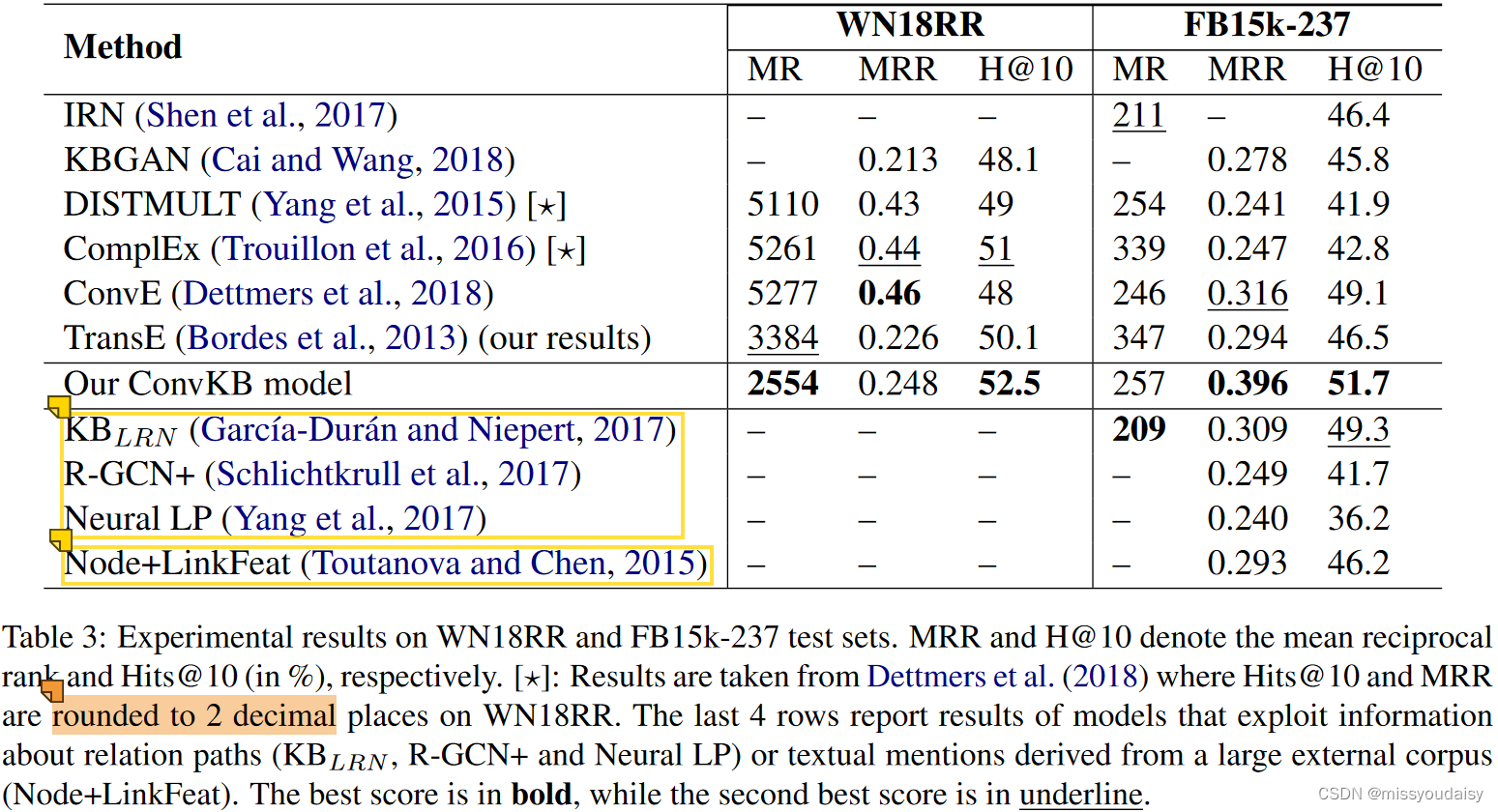
知识推理——CNN模型总结(一)
记录一下我看过的利用CNN实现知识推理的论文。 最后修改时间:2023.05.12 目录 1.ConvE 1.1.解决的问题 1.2.优势 1.3.贡献与创新点 1.4.方法 1.4.1 为什么用二维卷积,而不是一维卷积? 1.4.2.ConvE具体实现 1.4.3.1-N scoring 1.5.…...

OpengES中 GLSL优化要点
本文整理一些日常积累的可以优化的方向 一.延迟vector计算 在进行float与vector计算的时候,可以先确定float再计算,不要多个float一起计算 如: highp float f0,f1;highp vec4 v0,v1;v0 (v1 * f0) * f1;优化为 highp float f0,f1;highp vec…...

项目集角色定义
一、项目集经理的角色 项目集经理是由执行组织授权、领导团队实现项目集目标的人员。项目集经理对项目集的领导、 实施和绩效负责,并负责组建一支能够实现项目集目标和预期项目集效益的项目集团队。项目集经 理的角色与项目经理的角色不同。二者之间的差异是基于项…...

Unreal Engine11:触发器和计时器的使用
写在前面 主要是介绍一下触发器和计时器的使用; 一、在Actor中使用触发器 1. 新建一个C类 创建的C类也是放在Source文件夹中的Public和Private文件夹中;选择Actor作为继承的父类;头文件包括一个触发器和两个静态网格,它们共同…...

Qt之信号槽原理
Qt之信号槽原理 一.概述 所谓信号槽,实际就是观察者模式。当某个事件发生之后,比如,按钮检测到自己被点击了一下,它就会发出一个信号(signal)。这种发出是没有目的的,类似广播。如果有对象对这…...

【MySqL】 表的创建,查看,删除
目录 一.使用Cmd命令执行操作 1.使用( mysql -uroot -p)命令进入数据库 2.创建表之前先要使用数据库 3.创建表之前要先确定表的名称,列名,以及每一列的数据类型及属性 4.创建表 注意: 5.查看所有已创建的表 6.查看单表 …...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...

JS手写代码篇----使用Promise封装AJAX请求
15、使用Promise封装AJAX请求 promise就有reject和resolve了,就不必写成功和失败的回调函数了 const BASEURL ./手写ajax/test.jsonfunction promiseAjax() {return new Promise((resolve, reject) > {const xhr new XMLHttpRequest();xhr.open("get&quo…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...