基于trace_id实现ForkJoinPool的链路追踪
一、引言
之前写过一篇博客:基于trace_id的链路追踪(含Feign、Hystrix、线程池等场景),主要介绍在微服务体系架构中,如何实现分布式系统的链路追踪的博客,其中主要实现了以下几种场景:
- Filter实现trace_id拦截
- RestTemplate的链路追踪
- Feign的链路追踪
- Hystrix的链路追踪
- Dubbo的链路追踪
- Spring异步线程池的链路追踪
其中,还缺失了一种较为常见的场景,那就是Java中常用的线程池实现:ForkJoinPool。
尤其Java 8提供的 Stream并行流 采用了 ForkJoinPool 作为默认实现,当我们基于并行流做一些业务操作时,日志的链路追踪往往很容易在这里出现断层的情况。
本文将探讨如何基于trace_id实现ForkJoinPool的链路追踪,以提升系统的可追溯性。
二、ForkJoinPool简介
ForkJoinPool是Java提供的一种线程池实现,特别适用于处理递归分解的任务。它采用了工作窃取(Work-Stealing)算法,通过将任务分解为更小的子任务并将其分配给空闲线程执行,从而实现了任务的并行执行。
三、基于trace_id的链路追踪设计
为了实现基于trace_id的链路追踪,我们可以通过以下步骤进行设计:
- 为每个请求生成唯一的trace_id,并将其传递给ForkJoinPool中的任务。
- 在任务开始和结束时,记录相关的trace_id信息。
- 在任务执行过程中,将trace_id传递给子任务。
- 使用日志或专门的链路追踪工具,收集和分析trace_id信息,构建请求的链路图。
四、代码实现
1、自定义线程池:MdcForkJoinPool
MdcForkJoinPool
package com.github.jesse.l2cache.util.pool;import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.Future;/*** 自定义 {@link ForkJoinPool},扩展MDC内容,以便链路追踪** @author chenck* @date 2021/5/11 14:48*/
public class MdcForkJoinPool extends ForkJoinPool {/*** max #workers - 1*/public static final int MAX_CAP = 0x7fff;/*** the default parallelism level*/public static final int DEFAULT_PARALLELISM = Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors());/*** the default thread name prefix*/public static final String DEFAULT_THREAD_NAME_PREFIX = "MdcForkJoinPool";/*** Sequence number for creating workerNamePrefix.*/private static int poolNumberSequence;/*** Returns the next sequence number. We don't expect this to* ever contend, so use simple builtin sync.*/private static final synchronized int nextPoolId() {return ++poolNumberSequence;}/*** Common (static) pool.*/static final MdcForkJoinPool mdcCommon = new MdcForkJoinPool();public static MdcForkJoinPool mdcCommonPool() {return mdcCommon;}// constructorpublic MdcForkJoinPool() {this(DEFAULT_PARALLELISM, DEFAULT_THREAD_NAME_PREFIX);}public MdcForkJoinPool(int parallelism) {this(parallelism, DEFAULT_THREAD_NAME_PREFIX);}public MdcForkJoinPool(String threadNamePrefix) {this(DEFAULT_PARALLELISM, threadNamePrefix);}public MdcForkJoinPool(int parallelism, String threadNamePrefix) {this(parallelism, new LimitedThreadForkJoinWorkerThreadFactory(parallelism, threadNamePrefix + "-" + nextPoolId()), null, false);}/*** Creates a new MdcForkJoinPool.** @param parallelism the parallelism level. For default value, use {@link java.lang.Runtime#availableProcessors}.* @param factory the factory for creating new threads. For default value, use* {@link #defaultForkJoinWorkerThreadFactory}.* @param handler the handler for internal worker threads that terminate due to unrecoverable errors encountered* while executing tasks. For default value, use {@code null}.* @param asyncMode if true, establishes local first-in-first-out scheduling mode for forked tasks that are never* joined. This mode may be more appropriate than default locally stack-based mode in applications* in which worker threads only process event-style asynchronous tasks. For default value, use* {@code false}.*/public MdcForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, Thread.UncaughtExceptionHandler handler, boolean asyncMode) {super(parallelism, factory, handler, asyncMode);}// Execution methods@Overridepublic <T> T invoke(ForkJoinTask<T> task) {if (task == null) {throw new NullPointerException();}return super.invoke(new ForkJoinTaskMdcWrapper<T>(task));}@Overridepublic void execute(ForkJoinTask<?> task) {if (task == null) {throw new NullPointerException();}super.execute(new ForkJoinTaskMdcWrapper<>(task));}// AbstractExecutorService methods@Overridepublic void execute(Runnable task) {if (task == null) {throw new NullPointerException();}super.execute(new RunnableMdcWarpper(task));}@Overridepublic <T> ForkJoinTask<T> submit(ForkJoinTask<T> task) {if (task == null) {throw new NullPointerException();}return super.submit(new ForkJoinTaskMdcWrapper<T>(task));}@Overridepublic <T> ForkJoinTask<T> submit(Callable<T> task) {if (task == null) {throw new NullPointerException();}return super.submit(new CallableMdcWrapper(task));}@Overridepublic <T> ForkJoinTask<T> submit(Runnable task, T result) {if (task == null) {throw new NullPointerException();}return super.submit(new RunnableMdcWarpper(task), result);}@Overridepublic ForkJoinTask<?> submit(Runnable task) {if (task == null) {throw new NullPointerException();}return super.submit(new RunnableMdcWarpper(task));}@Overridepublic <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) {if (tasks == null) {throw new NullPointerException();}Collection<Callable<T>> wrapperTasks = new ArrayList<>();for (Callable<T> task : tasks) {wrapperTasks.add(new CallableMdcWrapper(task));}return super.invokeAll(wrapperTasks);}}
2、自定义包装类:透传trace_id
CallableMdcWrapper
package com.github.jesse.l2cache.util.pool;import org.slf4j.MDC;
import java.util.Map;
import java.util.concurrent.Callable;/*** @author chenck* @date 2021/5/11 17:09*/
public class CallableMdcWrapper<T> implements Callable<T> {private static final long serialVersionUID = 1L;Callable<T> callable;Map<String, String> contextMap;public CallableMdcWrapper(Callable<T> callable) {this.callable = callable;this.contextMap = MDC.getCopyOfContextMap();}@Overridepublic T call() throws Exception {Map<String, String> oldContext = MdcUtil.beforeExecution(contextMap);try {return callable.call();} finally {MdcUtil.afterExecution(oldContext);}}
}
RunnableMdcWarpper
package com.github.jesse.l2cache.util.pool;import org.slf4j.MDC;
import java.util.Map;/*** Runnable 包装 MDC** @author chenck* @date 2020/9/23 19:37*/
public class RunnableMdcWarpper implements Runnable {private static final long serialVersionUID = 1L;Runnable runnable;Map<String, String> contextMap;Object param;public RunnableMdcWarpper(Runnable runnable) {this.runnable = runnable;this.contextMap = MDC.getCopyOfContextMap();}public RunnableMdcWarpper(Runnable runnable, Object param) {this.runnable = runnable;this.contextMap = MDC.getCopyOfContextMap();this.param = param;}@Overridepublic void run() {Map<String, String> oldContext = MdcUtil.beforeExecution(contextMap);try {runnable.run();} finally {MdcUtil.afterExecution(oldContext);}}public Object getParam() {return param;}
}
ForkJoinTaskMdcWrapper
package com.github.jesse.l2cache.util.pool;import org.slf4j.MDC;
import java.util.Map;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.atomic.AtomicReference;/*** @author chenck* @date 2021/5/11 16:56* @see https://stackoverflow.com/questions/36026402/how-to-use-mdc-with-forkjoinpool*/
public class ForkJoinTaskMdcWrapper<T> extends ForkJoinTask<T> {private static final long serialVersionUID = 1L;/*** If non-null, overrides the value returned by the underlying task.*/private final AtomicReference<T> override = new AtomicReference<>();private ForkJoinTask<T> task;private Map<String, String> newContext;public ForkJoinTaskMdcWrapper(ForkJoinTask<T> task) {this.task = task;this.newContext = MDC.getCopyOfContextMap();}@Overridepublic T getRawResult() {T result = override.get();if (result != null) {return result;}return task.getRawResult();}@Overrideprotected void setRawResult(T value) {override.set(value);}@Overrideprotected boolean exec() {Map<String, String> oldContext = MdcUtil.beforeExecution(newContext);try {task.invoke();return true;} finally {MdcUtil.afterExecution(oldContext);}}
}
3、自定义线程工厂:自定义线程名称前缀+管理阻塞时限制最大线程数
LimitedThreadForkJoinWorkerThread
package com.github.jesse.l2cache.util.pool;import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinWorkerThread;/*** 自定义ForkJoinWorkerThread,用于限制ForkJoinPool中创建的最大线程数** @author chenck* @date 2023/5/6 13:49*/
public class LimitedThreadForkJoinWorkerThread extends ForkJoinWorkerThread {protected LimitedThreadForkJoinWorkerThread(ForkJoinPool pool) {super(pool);setPriority(Thread.NORM_PRIORITY); // 设置线程优先级setDaemon(false); // 设置是否为守护线程}protected LimitedThreadForkJoinWorkerThread(ForkJoinPool pool, String threadName) {super(pool);setPriority(Thread.NORM_PRIORITY); // 设置线程优先级setDaemon(false); // 设置是否为守护线程setName(threadName);}
}
LimitedThreadForkJoinWorkerThreadFactory
package com.github.jesse.l2cache.util.pool;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinWorkerThread;
import java.util.concurrent.atomic.AtomicInteger;/*** 自定义ForkJoinWorkerThreadFactory,用于限制ForkJoinPool中创建的最大线程数,并复用当前的ForkJoinPool的线程** @author chenck* @date 2023/5/6 13:48*/
public class LimitedThreadForkJoinWorkerThreadFactory implements ForkJoinPool.ForkJoinWorkerThreadFactory {protected static Logger logger = LoggerFactory.getLogger(LimitedThreadForkJoinWorkerThreadFactory.class);/*** 最大线程数*/private final int maxThreads;/*** 线程名称前缀*/private String threadNamePrefix;/*** 当前线程数*/private final AtomicInteger threadCount = new AtomicInteger(0);public LimitedThreadForkJoinWorkerThreadFactory(int maxThreads) {this.maxThreads = maxThreads;}public LimitedThreadForkJoinWorkerThreadFactory(int maxThreads, String threadNamePrefix) {this.maxThreads = maxThreads;this.threadNamePrefix = threadNamePrefix;}/*** 限制了线程数量并复用当前的ForkJoinPool的线程*/@Overridepublic ForkJoinWorkerThread newThread(ForkJoinPool pool) {int count = threadCount.incrementAndGet();// 如果当前线程数量小于等于最大线程数,则创建新线程,并将threadCount+1if (count <= maxThreads) {if (null == threadNamePrefix || "".equals(threadNamePrefix.trim())) {return new LimitedThreadForkJoinWorkerThread(pool);} else {// 使用自定义线程名称return new LimitedThreadForkJoinWorkerThread(pool, threadNamePrefix + "-worker-" + count);}}// 如果当前线程数量超过最大线程数,则不创建新线程,并将threadCount-1threadCount.decrementAndGet();if (logger.isDebugEnabled()) {logger.debug("Exceeded maximum number of threads");}return null;// 不创建新线程}}
4、工具类
MyManagedBlocker
package com.github.jesse.l2cache.util.pool;import java.util.concurrent.ForkJoinPool;
import java.util.function.Function;/*** Java 8中的默认并行流使用公共ForkJoinPool,如果提交任务时公共池线程耗尽,会导致任务延迟执行。* <p>* CPU密集型:如果在ForkJoinPool中填充的任务,执行时间足够短,且CPU的可用能力足够,那么将不会出现上述延迟的问题。(ForkJoinPool的大多数使用场景)* I/O密集型:如果在ForkJoinPool中填充的任务,执行时间足够长,且是不受CPU限制的I/O任务,那么任务将延迟执行,并出现瓶颈。* 小结:ForkJoinPool 最适合的是CPU密集型的任务,如果存在 I/O,线程间同步,sleep() 等会造成线程长时间阻塞的情况时,最好配合使用 ManagedBlocker。* <p>* 对I/O阻塞型任务提供一个ManagedBlocker,让ForkJoinPool知道当前任务即将阻塞,因此需要创建新的`备用线程`来执行新提交的任务.* <p>* 【问题】通过ManagedBlocker来管理阻塞时,最大正在运行的线程数限制为32767,如果不限制新创建的线程数量,可能导致oom。如何控制ForkJoinPool中新创建的最大备用线程数?* 【分析】* 1、ForkJoinPool.common.commonMaxSpares 表示 tryCompensate 中`备用线程`创建的限制,默认为256* 2、上面这个参数,只能针对commonPool进行限制,并且tryCompensate方法不一定能会命中该限制,若未命中该限制,则可能无限制的创建`备用线程`来避免阻塞,最终还是可能出现oom* 3、ManagedBlocker将最大正在运行的线程数限制为32767.尝试创建大于最大数目的池导致IllegalArgumentException,只有当池被关闭或内部资源耗尽时,此实现才会拒绝提交的任务(即通过抛出RejectedExecutionException )。* 【方案】* 在管理阻塞时,通过自定义 {@LimitedThreadForkJoinWorkerThreadFactory} 来限制ForkJoinPool最大可创建的线程数,并复用当前的ForkJoinPool的线程,以此来避免无限制的创建`备用线程`** @author chenck* @date 2023/5/5 18:30*/
public class MyManagedBlocker implements ForkJoinPool.ManagedBlocker {private Function function;private Object key;private Object result;private boolean done = false;public MyManagedBlocker(Object key, Function function) {this.key = key;this.function = function;}@Overridepublic boolean block() throws InterruptedException {result = function.apply(key);done = true;return false;}@Overridepublic boolean isReleasable() {return done;}public Object getResult() {return result;}}
MdcUtil
package com.github.jesse.l2cache.util.pool;import org.slf4j.MDC;
import java.util.Map;/*** @author chenck* @date 2021/5/11 17:00*/
public class MdcUtil {/*** Invoked before running a task.** @param newMdcContext the new MDC context* @return the old MDC context*/public static Map<String, String> beforeExecution(Map<String, String> newMdcContext) {Map<String, String> oldMdcContext = MDC.getCopyOfContextMap();if (newMdcContext == null) {MDC.clear();} else {MDC.setContextMap(newMdcContext);}return oldMdcContext;}/*** Invoked after running a task.** @param oldMdcContext the old MDC context*/public static void afterExecution(Map<String, String> oldMdcContext) {if (oldMdcContext == null) {MDC.clear();} else {MDC.setContextMap(oldMdcContext);}}
}
五、小结
基于trace_id的链路追踪是提升分布式系统可追溯性的关键技术之一。
通过在任务中传递和记录trace_id信息,并结合日志和监控系统,开发人员可以更好地了解请求的流转路径和系统性能状况,从而快速定位和解决问题。
在实际应用中,需要根据具体的业务场景和性能要求,灵活选择追踪策略和工具,以实现最佳的性能和可追溯性的平衡。
参考文献:
- Oracle官方文档:https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ForkJoinPool.html
- OpenTracing官方文档:https://opentracing.io/
相关文章:

基于trace_id实现ForkJoinPool的链路追踪
一、引言 之前写过一篇博客:基于trace_id的链路追踪(含Feign、Hystrix、线程池等场景),主要介绍在微服务体系架构中,如何实现分布式系统的链路追踪的博客,其中主要实现了以下几种场景: Filter…...

Qt推流程序(视频文件/视频流/摄像头/桌面转成流媒体rtmp+hls+webrtc)可在网页和播放器远程观看
一、前言说明 推流直播就是把采集阶段封包好的内容传输到服务器的过程。其实就是将现场的视频信号从手机端,电脑端,摄影机端打包传到服务器的过程。“推流”对网络要求比较高,如果网络不稳定,直播效果就会很差,观众观…...

ChatGPT入门到高级【第一章】
第一章:Chatgpt的起源和发展 1.1 人工智能和Chatbot的概念 1.2 Chatbot的历史发展 1.3 机器学习技术在Chatbot中的应用 1.4 Chatgpt的诞生和发展 第二章:Chatgpt的技术原理 2.1 自然语言处理技术 2.2 深度学习技术 2.3 Transformer模型 2.4 GPT模型 第…...
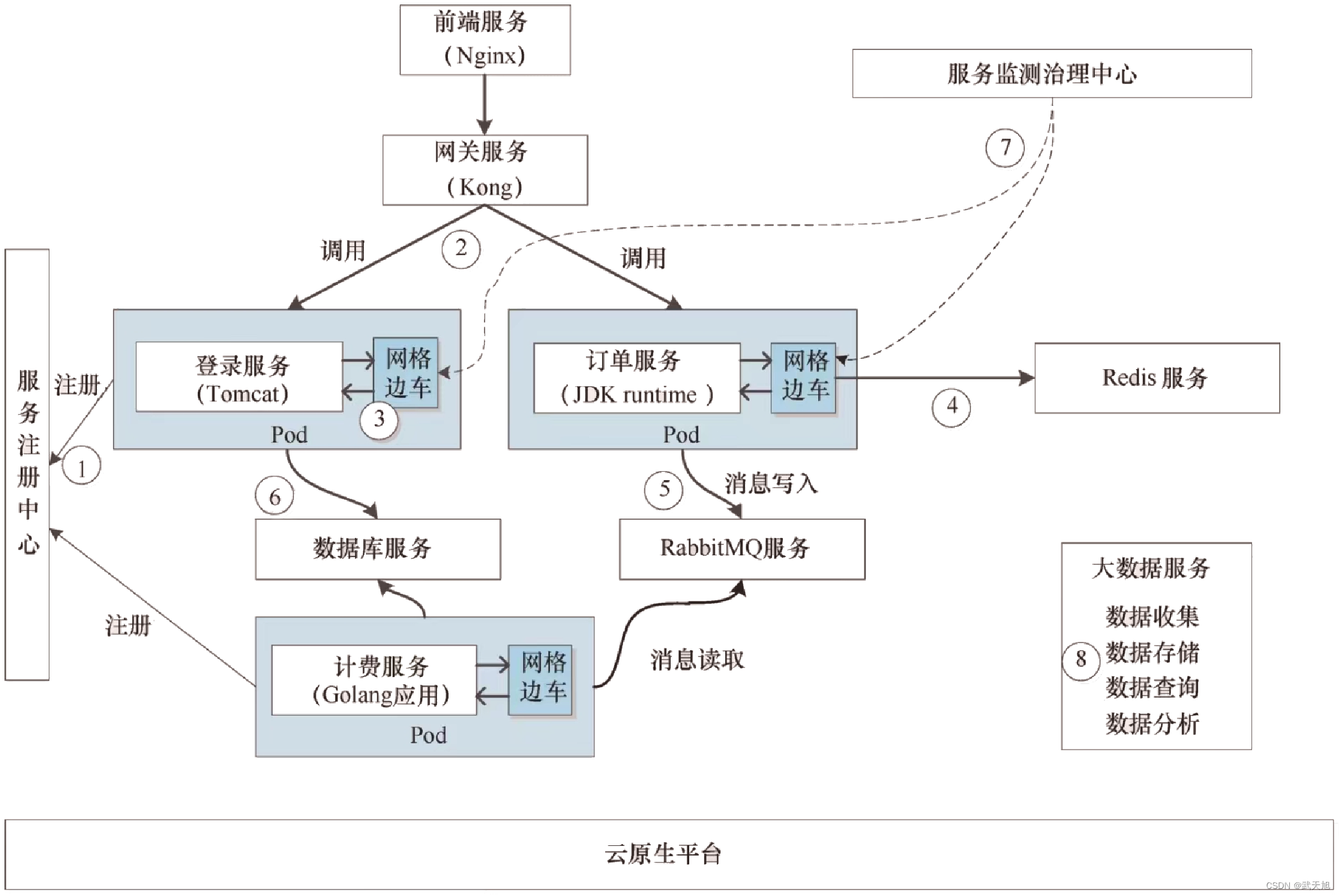
云原生应用架构
本博客地址:https://security.blog.csdn.net/article/details/130566883 一、什么是云原生应用架构 成为云原生应用至少需要满足下面几个特点: ● 使用微服务架构对业务进行拆分。单个微服务是个自治的服务领域,对这个领域内的业务实体能够…...
rem、px、em的区别 -前端
文章目录 三者的区别特点与换算举例emrem 总结一总结二 三者的区别 在css中单位长度用的最多的是px、em、rem,这三个的区别是: 一、px是固定的像素,一旦设置了就无法因为适应页面大小而改变。 二、em和rem相对于px更具有灵活性,…...
分享几款小白从零开始学习的会用到的工具/网站
大二狗接触编程也有两年了,差生文具多这大众都认可的一句话,在这里蹭一下这个活动分享一下从0开始学习编程有啥好用的工具 目录 伴侣一、Snipaste截图工具 伴侣二、Postman软件(可用ApiPost平替) 伴侣三、字体图标网站 伴侣四…...

第八章 文件处理命令
第八章 文件处理命令 一、 文本编辑器 vi • vi 是 Unix 类操作系统中最为流行的文本编辑器。尽管目前 已有 gedit 等一些工作在图形界面下使用起来也更为方便 的文本编辑器,但在很多情况下,vi 这种专为字符界面操 作而设计的编辑器恐怕还是要充当首…...

LVS 负载均衡群集的 NAT 模式和 DR 模式
1. 对比 LVS 负载均衡群集的 NAT 模式和 DR 模式,比较其各自的优势 DR 模式 * 负载各节点服务器通过本地网络连接,不需要建立专用的IP隧道 原理:首先负载均衡器接收到客户的请求数据包时,根据调度算法决定将请求发送给哪个后端的…...
自学自动化测试,第一份工作就18K,因为掌握了这些技术
我个人的情况是有1年自动化测试工作经验半年的实习经验,2020年毕业,专业通信工程,大一的时候学过C语言,所以一直对于编程感兴趣,之所以毕业后没做通信的工作,通信行业的朋友应该都明白,通信的天…...

C++ 类的继承与派生
目录 1、继承的概念 2、继承(Inherit) 3、继承方式 4、父子同名成员并存 5、虚函数(virtual) 6、纯虚函数 1、继承的概念 以李白为例 类1是类2的基类(父类),类2是类3的基类(父类…...

分布式系统基础理论
CAP是分布式系统方向中的一个非常重要的理论,可以粗略的将它看成是分布式系统的起点,CAP分别代表的是分布式系统中的三种性质,分别是Consistency(可用性)、Availability(一致性)、Partition tol…...

HttpServletRequestWrapper的使用与原理
介绍 HttpServletRequestWrapper 实现了 HttpServletRequest 接口,可以让开发人员很方便的改造发送给 Servlet 的请求.HttpServletRequest 对参数值的获取实际调的是org.apache.catalina.connector.Request没有提供对应的set方法修改属性所以不能对前端传来的参…...
)
PBDB Data Service:List of fossil occurrences(化石产出记录列表)
List of fossil occurrences(化石产出记录列表) 描述用法参数选择PBDB所有记录(all_records)以下参数可用于按各种条件查询化石产出记录以下参数可用于筛选所选内容以下参数还可用于根据分类筛选结果列表以下参数可用于生成数据存…...

初识C语言
1. 初识C语言 C语言是一门通用计算机编程语言,广泛应用于底层开发。 C语言是一门面向过程的计算机编程语言,它与C,Java等面向对象的编程语言有所不同。 第一个C语言程序: #include<stdio.h>int main(void) {printf("hello worl…...
)
Leetcode 322. 零钱兑换(完全背包)
Leetcode 322. 零钱兑换(完全背包)题目 给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额&…...
怎么恢复回收站?分享4个宝藏方法!
案例:怎么恢复回收站 【请问大家怎么恢复误删的文件呀?如果回收站被清空了,又应该怎么恢复呢?】 电脑回收站是我们存储被删除文件的地方。但是有时候,我们会不小心把一些重要的文件或者照片误删了。这时候࿰…...

大模型混战,最先实现“智慧涌现”的会是谁?
作者 | 曾响铃 文 | 响铃说 几秒钟写出了一篇欢迎词; 小说人物乱入现实,快速创作不重样的故事; 鼠标一点,一封英文工作沟通邮件撰写完成; 准确解出数学应用题,还给出解题步骤; 甚至还能理…...
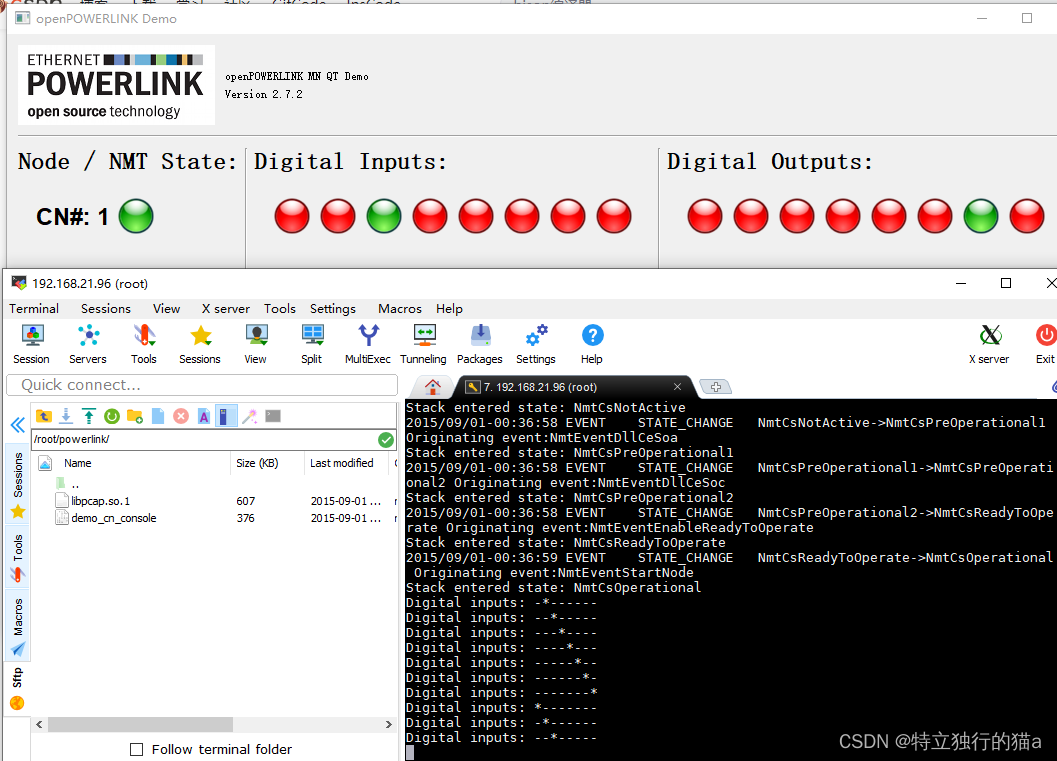
Powerlink协议在嵌入式linux上的移植和主从站通信(电脑和linux板通信实验)
使用最新的openPOWERLINK 2.7.2源码,业余时间搞定了Powerlink协议在嵌入式linux上的移植和测试,并进行了下电脑和linux开发板之间的通信实验。添加了一个节点配置,跑通了源码中提供的主站和从站的两个demo。这里总结下移植过程分享给有需要的…...
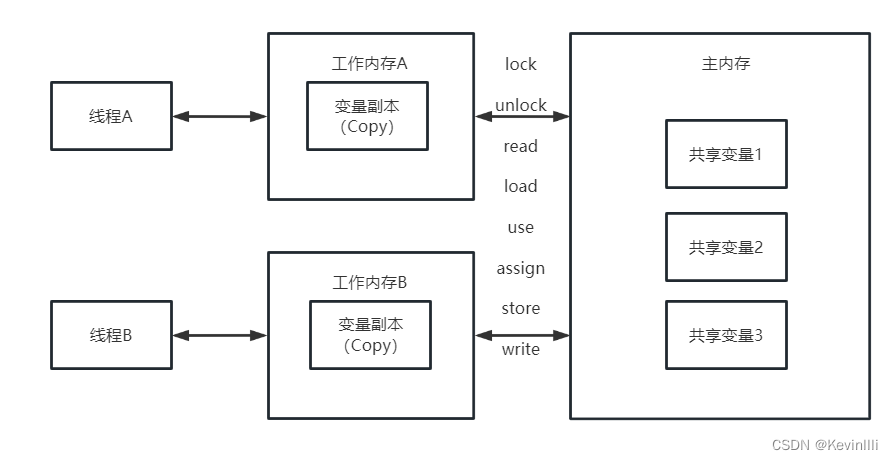
快速理解基本的cookie、session 和 redis
一、Cookie 1、什么是Cookie 1、Cookie实际上是一小段的文本信息,是一种keyvalue形式的字符串。客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端会把Cookie保存起来。 2、当浏览器再请求…...
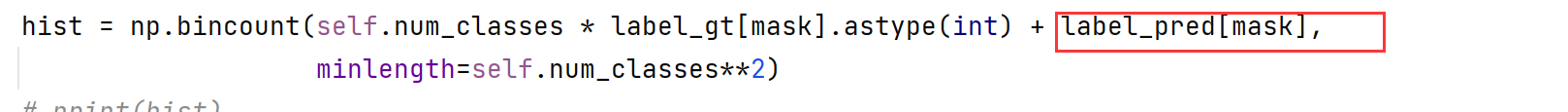
STANet代码复现出现的问题
1 IndexError: boolean index did not match indexed array along dimension 0; dimension is 4194304 but corresponding boolean dimension is 65536定位到导致错误的代码,是metric.py,Collect values for Confusion Matrix 收集混淆矩阵的值时出错 …...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...