echonet-dynamic代码解读
1 综述
一共是这些代码,我们主要看echo.py,segmentation.py,video.py,config.py。

2 配置文件config.py
基于配置文件设置路径。
"""Sets paths based on configuration files."""import configparser
import os
import types_FILENAME = None
_PARAM = {}
# 如果存在下面这些自定义的配置文件,则读取配置文件中的定义
for filename in ["echonet.cfg",".echonet.cfg",os.path.expanduser("~/echonet.cfg"),os.path.expanduser("~/.echonet.cfg"),]:if os.path.isfile(filename):_FILENAME = filenameconfig = configparser.ConfigParser()with open(filename, "r") as f:config.read_string("[config]\n" + f.read())_PARAM = config["config"]breakCONFIG = types.SimpleNamespace(FILENAME=_FILENAME,DATA_DIR=_PARAM.get("data_dir", "a4c-video-dir/")) # 默认的数据存放路径3 数据集加载echo.py
4 左心室分割segmentation.py
Trains/tests segmentation model.
参数介绍:
data_dir(str,可选):包含数据集的目录。默认值为`echonet.config.DATA_DIR`。
output(str,可选):放置输出的目录。默认值为输出/分段/<模型名称>_<预训练/随机>/。
model_name(str,可选):分段模型的名称。“deeplabv3_resnet50”、``deeplabv3_resnet101“”、“fcn_resnet50”或“fcn_res net101”之一,(选项为torchvision.models.segmentation.<model_name>)默认值为“`deeplabv3_resnet50'”。
pretrained(bool,可选):是否对模型使用预训练权重,默认为False。
weights(str,可选):包含权重的检查点路径初始化模型。默认为“无”。
run_test(bool,可选):是否在测试中运行。默认为False。
save_video(bool,可选):是否保存带有分段的视频。默认为False。
num_epochs(int,可选):训练期间的纪元数。默认值为50。
lr(float,可选):SGD的学习率。默认值为1e-5。
weight_decay(浮动,可选):SGD的权重衰减。默认值为0。
lr_step_period(int或None,可选):学习率衰减的时间段。(学习率衰减0.1倍)。默认为math.inf(从不衰减学习率)。
num_train_patients(int或None,可选):培训患者的数量。用于消融。默认为所有患者。
num_workers(int,可选):用于数据的子进程数加载。如果为0,则数据将加载到主进程中。默认值为4。
device(str或None,可选):要运行的设备的名称。选项来自https://pytorch.org/docs/stable/tensor_attributes.html#torch.torch.device。如果可用,则默认为“cuda”,否则默认为“cpu”。
batch_size(int,可选):每个批次要加载的样本数。默认值为20。
seed(int,可选):随机数生成器的种子。默认值为0。
"""Functions for training and running segmentation."""import math
import os
import timeimport click
import matplotlib.pyplot as plt
import numpy as np
import scipy.signal
import skimage.draw
import torch
import torchvision
import tqdmimport echonet
@click.command("segmentation")
@click.option("--data_dir", type=click.Path(exists=True, file_okay=False), default=None)
@click.option("--output", type=click.Path(file_okay=False), default=None)
@click.option("--model_name", type=click.Choice(sorted(name for name in torchvision.models.segmentation.__dict__if name.islower() and not name.startswith("__") and callable(torchvision.models.segmentation.__dict__[name]))),default="deeplabv3_resnet50")
@click.option("--pretrained/--random", default=False)
@click.option("--weights", type=click.Path(exists=True, dir_okay=False), default=None)
@click.option("--run_test/--skip_test", default=False)
@click.option("--save_video/--skip_video", default=False)
@click.option("--num_epochs", type=int, default=50)
@click.option("--lr", type=float, default=1e-5)
@click.option("--weight_decay", type=float, default=0)
@click.option("--lr_step_period", type=int, default=None)
@click.option("--num_train_patients", type=int, default=None)
@click.option("--num_workers", type=int, default=4)
@click.option("--batch_size", type=int, default=20)
@click.option("--device", type=str, default=None)
@click.option("--seed", type=int, default=0)
def run(data_dir=None,output=None,model_name="deeplabv3_resnet50",pretrained=False,weights=None,run_test=False,save_video=False,num_epochs=50,lr=1e-5,weight_decay=1e-5,lr_step_period=None,num_train_patients=None,num_workers=4,batch_size=20,device=None,seed=0,
):# Seed RNGsnp.random.seed(seed) # 如果使用相同的seed()值,则每次生成的随机数都相同torch.manual_seed(seed) #设置 CPU 生成随机数的 种子 ,方便下次复现实验结果。# Set default output directoryif output is None:output = os.path.join("output", "segmentation", "{}_{}".format(model_name, "pretrained" if pretrained else "random"))os.makedirs(output, exist_ok=True)# Set device for computationsif device is None:device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# Set up model# torchvision.models.segmentation.deeplabv3_resnet50model = torchvision.models.segmentation.__dict__[model_name](pretrained=pretrained, aux_loss=False)#__dict__,会输出该由类中所有类属性组成的字典# 设置分类器, 输出为1(即是心房是非心房,是01问题)# model.classifier 为卷积核设置,修改卷积层,【-1】最后一层model.classifier[-1] = torch.nn.Conv2d(model.classifier[-1].in_channels, 1, kernel_size=model.classifier[-1].kernel_size) # change number of outputs to 1if device.type == "cuda":model = torch.nn.DataParallel(model)# 用多个GPU来加速训练model.to(device)if weights is not None:checkpoint = torch.load(weights)# ,map_location='cpu'model.load_state_dict(checkpoint['state_dict'])# Set up optimizeroptim = torch.optim.SGD(model.parameters(), lr=lr, momentum=0.9, weight_decay=weight_decay)if lr_step_period is None:lr_step_period = math.infscheduler = torch.optim.lr_scheduler.StepLR(optim, lr_step_period)# Compute mean and std 由于医学数据集比较特殊, 需要计算一下自己的均值和标准差mean, std = echonet.utils.get_mean_and_std(echonet.datasets.Echo(root=data_dir, split="train"))tasks = ["LargeFrame", "SmallFrame", "LargeTrace", "SmallTrace"]kwargs = {"target_type": tasks,"mean": mean,"std": std}
# 获取训练集和验证集# Set up datasets and dataloadersdataset = {}dataset["train"] = echonet.datasets.Echo(root=data_dir, split="train", **kwargs)if num_train_patients is not None and len(dataset["train"]) > num_train_patients:# Subsample patients (used for ablation experiment)indices = np.random.choice(len(dataset["train"]), num_train_patients, replace=False)dataset["train"] = torch.utils.data.Subset(dataset["train"], indices)dataset["val"] = echonet.datasets.Echo(root=data_dir, split="val", **kwargs)# Run training and testing loops 打开日志文件, 记录训练过程with open(os.path.join(output, "log.csv"), "a") as f:epoch_resume = 0 # 训练开始的周期位置bestLoss = float("inf")# Attempt to load checkpoint尝试加载检查点try:checkpoint = torch.load(os.path.join(output, "checkpoint.pt"))model.load_state_dict(checkpoint['state_dict'])optim.load_state_dict(checkpoint['opt_dict'])scheduler.load_state_dict(checkpoint['scheduler_dict'])epoch_resume = checkpoint["epoch"] + 1bestLoss = checkpoint["best_loss"]f.write("Resuming from epoch {}\n".format(epoch_resume))except FileNotFoundError:f.write("Starting run from scratch\n") # 如果检查点文件不存在,则从头开始运行# 开始训练for epoch in range(epoch_resume, num_epochs):print("Epoch #{}".format(epoch), flush=True)for phase in ['train', 'val']:start_time = time.time()for i in range(torch.cuda.device_count()):torch.cuda.reset_peak_memory_stats(i)ds = dataset[phase]dataloader = torch.utils.data.DataLoader(ds, batch_size=batch_size, num_workers=num_workers, shuffle=True, pin_memory=(device.type == "cuda"), drop_last=(phase == "train"))#在循环中调用 run_epoch() 方法loss, large_inter, large_union, small_inter, small_union = echonet.utils.segmentation.run_epoch(model, dataloader, phase == "train", optim, device)overall_dice = 2 * (large_inter.sum() + small_inter.sum()) / (large_union.sum() + large_inter.sum() + small_union.sum() + small_inter.sum())large_dice = 2 * large_inter.sum() / (large_union.sum() + large_inter.sum())small_dice = 2 * small_inter.sum() / (small_union.sum() + small_inter.sum())f.write("{},{},{},{},{},{},{},{},{},{},{}\n".format(epoch,phase,loss,overall_dice,large_dice,small_dice,time.time() - start_time,large_inter.size,sum(torch.cuda.max_memory_allocated() for i in range(torch.cuda.device_count())),sum(torch.cuda.max_memory_reserved() for i in range(torch.cuda.device_count())),batch_size))f.flush()scheduler.step()# Save checkpointsave = {'epoch': epoch,'state_dict': model.state_dict(),'best_loss': bestLoss,'loss': loss,'opt_dict': optim.state_dict(),'scheduler_dict': scheduler.state_dict(),}torch.save(save, os.path.join(output, "checkpoint.pt"))if loss < bestLoss:torch.save(save, os.path.join(output, "best.pt"))bestLoss = loss# Load best weightsif num_epochs != 0:checkpoint = torch.load(os.path.join(output, "best.pt"))model.load_state_dict(checkpoint['state_dict'])f.write("Best validation loss {} from epoch {}\n".format(checkpoint["loss"], checkpoint["epoch"]))if run_test:# Run on validation and testfor split in ["val", "test"]:dataset = echonet.datasets.Echo(root=data_dir, split=split, **kwargs)dataloader = torch.utils.data.DataLoader(dataset,batch_size=batch_size, num_workers=num_workers, shuffle=False, pin_memory=(device.type == "cuda"))loss, large_inter, large_union, small_inter, small_union = echonet.utils.segmentation.run_epoch(model, dataloader, False, None, device)overall_dice = 2 * (large_inter + small_inter) / (large_union + large_inter + small_union + small_inter)large_dice = 2 * large_inter / (large_union + large_inter)small_dice = 2 * small_inter / (small_union + small_inter)with open(os.path.join(output, "{}_dice.csv".format(split)), "w") as g:g.write("Filename, Overall, Large, Small\n")for (filename, overall, large, small) in zip(dataset.fnames, overall_dice, large_dice, small_dice):g.write("{},{},{},{}\n".format(filename, overall, large, small))f.write("{} dice (overall): {:.4f} ({:.4f} - {:.4f})\n".format(split, *echonet.utils.bootstrap(np.concatenate((large_inter, small_inter)), np.concatenate((large_union, small_union)), echonet.utils.dice_similarity_coefficient)))f.write("{} dice (large): {:.4f} ({:.4f} - {:.4f})\n".format(split, *echonet.utils.bootstrap(large_inter, large_union, echonet.utils.dice_similarity_coefficient)))f.write("{} dice (small): {:.4f} ({:.4f} - {:.4f})\n".format(split, *echonet.utils.bootstrap(small_inter, small_union, echonet.utils.dice_similarity_coefficient)))f.flush()# 以下应该是加载测试集,分割,以及保存数据# Saving videos with segmentationsdataset = echonet.datasets.Echo(root=data_dir, split="test",target_type=["Filename", "LargeIndex", "SmallIndex"], # Need filename for saving, and human-selected frames to annotate需要用于保存的文件名和要注释的人工选定帧mean=mean, std=std, # Normalizationlength=None, max_length=None, period=1 # Take all frames)dataloader = torch.utils.data.DataLoader(dataset, batch_size=10, num_workers=num_workers, shuffle=False, pin_memory=False, collate_fn=_video_collate_fn)# Save videos with segmentationif save_video and not all(os.path.isfile(os.path.join(output, "videos", f)) for f in dataloader.dataset.fnames):# Only run if missing videosmodel.eval()os.makedirs(os.path.join(output, "videos"), exist_ok=True)os.makedirs(os.path.join(output, "size"), exist_ok=True)echonet.utils.latexify()with torch.no_grad():with open(os.path.join(output, "size.csv"), "w") as g:g.write("Filename,Frame,Size,HumanLarge,HumanSmall,ComputerSmall\n")for (x, (filenames, large_index, small_index), length) in tqdm.tqdm(dataloader):# Run segmentation model on blocks of frames one-by-one #逐个在帧块上运行分割模型# The whole concatenated video may be too long to run together #整个串联视频可能太长,无法一起运行y = np.concatenate([model(x[i:(i + batch_size), :, :, :].to(device))["out"].detach().cpu().numpy() for i in range(0, x.shape[0], batch_size)])start = 0x = x.numpy()for (i, (filename, offset)) in enumerate(zip(filenames, length)):# Extract one video and segmentation predictionsvideo = x[start:(start + offset), ...]logit = y[start:(start + offset), 0, :, :]# Un-normalize videovideo *= std.reshape(1, 3, 1, 1)video += mean.reshape(1, 3, 1, 1)# Get frames, channels, height, and widthf, c, h, w = video.shape # pylint: disable=W0612assert c == 3# Put two copies of the video side by side # 并排存放两份视频video = np.concatenate((video, video), 3)# If a pixel is in the segmentation, saturate blue channel# Leave alone otherwisevideo[:, 0, :, w:] = np.maximum(255. * (logit > 0), video[:, 0, :, w:]) # pylint: disable=E1111# Add blank canvas under pair of videos # 在视频对下添加空白画布video = np.concatenate((video, np.zeros_like(video)), 2)# Compute size of segmentation per frame # 计算每帧分割的大小size = (logit > 0).sum((1, 2))# Identify systole frames with peak detectiontrim_min = sorted(size)[round(len(size) ** 0.05)]trim_max = sorted(size)[round(len(size) ** 0.95)]trim_range = trim_max - trim_minsystole = set(scipy.signal.find_peaks(-size, distance=20, prominence=(0.50 * trim_range))[0])# Write sizes and frames to filefor (frame, s) in enumerate(size):g.write("{},{},{},{},{},{}\n".format(filename, frame, s, 1 if frame == large_index[i] else 0, 1 if frame == small_index[i] else 0, 1 if frame in systole else 0))# Plot sizesfig = plt.figure(figsize=(size.shape[0] / 50 * 1.5, 3))plt.scatter(np.arange(size.shape[0]) / 50, size, s=1)ylim = plt.ylim()for s in systole:plt.plot(np.array([s, s]) / 50, ylim, linewidth=1)plt.ylim(ylim)plt.title(os.path.splitext(filename)[0])plt.xlabel("Seconds")plt.ylabel("Size (pixels)")plt.tight_layout()plt.savefig(os.path.join(output, "size", os.path.splitext(filename)[0] + ".pdf"))plt.close(fig)# Normalize size to [0, 1]size -= size.min()size = size / size.max()size = 1 - size# Iterate the frames in this videofor (f, s) in enumerate(size):# On all frames, mark a pixel for the size of the framevideo[:, :, int(round(115 + 100 * s)), int(round(f / len(size) * 200 + 10))] = 255.if f in systole:# If frame is computer-selected systole, mark with a linevideo[:, :, 115:224, int(round(f / len(size) * 200 + 10))] = 255.def dash(start, stop, on=10, off=10):buf = []x = startwhile x < stop:buf.extend(range(x, x + on))x += onx += offbuf = np.array(buf)buf = buf[buf < stop]return bufd = dash(115, 224)if f == large_index[i]:# If frame is human-selected diastole, mark with green dashed line on all frames# 如果帧是人类选择的舒张期,则在所有帧上用绿色虚线标记video[:, :, d, int(round(f / len(size) * 200 + 10))] = np.array([0, 225, 0]).reshape((1, 3, 1))if f == small_index[i]:# If frame is human-selected systole, mark with red dashed line on all frames# 如果帧是人为选择的收缩期,则在所有帧上用红色虚线标记video[:, :, d, int(round(f / len(size) * 200 + 10))] = np.array([0, 0, 225]).reshape((1, 3, 1))# Get pixels for a circle centered on the pixel# 获取以像素为中心的圆的像素r, c = skimage.draw.disk((int(round(115 + 100 * s)), int(round(f / len(size) * 200 + 10))), 4.1)# On the frame that's being shown, put a circle over the pixel# 在显示的帧上,在像素上画一个圆圈video[f, :, r, c] = 255.# Rearrange dimensions and savevideo = video.transpose(1, 0, 2, 3)video = video.astype(np.uint8)echonet.utils.savevideo(os.path.join(output, "videos", filename), video, 50)# Move to next videostart += offsetdef run_epoch(model, dataloader, train, optim, device):"""Run one epoch of training/evaluation for segmentation.Args:model (torch.nn.Module): Model to train/evaulate.dataloder (torch.utils.data.DataLoader): Dataloader for dataset.train (bool): Whether or not to train model.optim (torch.optim.Optimizer): Optimizerdevice (torch.device): Device to run on"""total = 0.n = 0pos = 0neg = 0pos_pix = 0neg_pix = 0model.train(train)large_inter = 0large_union = 0small_inter = 0small_union = 0large_inter_list = []large_union_list = []small_inter_list = []small_union_list = []with torch.set_grad_enabled(train):with tqdm.tqdm(total=len(dataloader)) as pbar:# 遍历dataloaderfor (_, (large_frame, small_frame, large_trace, small_trace)) in dataloader:# 医学中的统计指标 Count number of pixels in/out of human segmentationpos += (large_trace == 1).sum().item()pos += (small_trace == 1).sum().item()neg += (large_trace == 0).sum().item()neg += (small_trace == 0).sum().item()# Count number of pixels in/out of computer segmentationpos_pix += (large_trace == 1).sum(0).to("cpu").detach().numpy()pos_pix += (small_trace == 1).sum(0).to("cpu").detach().numpy()neg_pix += (large_trace == 0).sum(0).to("cpu").detach().numpy()neg_pix += (small_trace == 0).sum(0).to("cpu").detach().numpy()# Run prediction for diastolic frames and compute losslarge_frame = large_frame.to(device)large_trace = large_trace.to(device)y_large = model(large_frame)["out"]loss_large = torch.nn.functional.binary_cross_entropy_with_logits(y_large[:, 0, :, :], large_trace, reduction="sum")# Compute pixel intersection and union between human and computer segmentationslarge_inter += np.logical_and(y_large[:, 0, :, :].detach().cpu().numpy() > 0., large_trace[:, :, :].detach().cpu().numpy() > 0.).sum()large_union += np.logical_or(y_large[:, 0, :, :].detach().cpu().numpy() > 0., large_trace[:, :, :].detach().cpu().numpy() > 0.).sum()large_inter_list.extend(np.logical_and(y_large[:, 0, :, :].detach().cpu().numpy() > 0., large_trace[:, :, :].detach().cpu().numpy() > 0.).sum((1, 2)))large_union_list.extend(np.logical_or(y_large[:, 0, :, :].detach().cpu().numpy() > 0., large_trace[:, :, :].detach().cpu().numpy() > 0.).sum((1, 2)))# Run prediction for systolic frames and compute losssmall_frame = small_frame.to(device)small_trace = small_trace.to(device)y_small = model(small_frame)["out"]loss_small = torch.nn.functional.binary_cross_entropy_with_logits(y_small[:, 0, :, :], small_trace, reduction="sum")# Compute pixel intersection and union between human and computer segmentationssmall_inter += np.logical_and(y_small[:, 0, :, :].detach().cpu().numpy() > 0., small_trace[:, :, :].detach().cpu().numpy() > 0.).sum()small_union += np.logical_or(y_small[:, 0, :, :].detach().cpu().numpy() > 0., small_trace[:, :, :].detach().cpu().numpy() > 0.).sum()small_inter_list.extend(np.logical_and(y_small[:, 0, :, :].detach().cpu().numpy() > 0., small_trace[:, :, :].detach().cpu().numpy() > 0.).sum((1, 2)))small_union_list.extend(np.logical_or(y_small[:, 0, :, :].detach().cpu().numpy() > 0., small_trace[:, :, :].detach().cpu().numpy() > 0.).sum((1, 2)))# 计算loss然后反向传播,Take gradient step if trainingloss = (loss_large + loss_small) / 2if train:optim.zero_grad()loss.backward()optim.step()# Accumulate losses and compute baselinestotal += loss.item()n += large_trace.size(0)p = pos / (pos + neg)p_pix = (pos_pix + 1) / (pos_pix + neg_pix + 2)# Show info on process barpbar.set_postfix_str("{:.4f} ({:.4f}) / {:.4f} {:.4f}, {:.4f}, {:.4f}".format(total / n / 112 / 112, loss.item() / large_trace.size(0) / 112 / 112, -p * math.log(p) - (1 - p) * math.log(1 - p), (-p_pix * np.log(p_pix) - (1 - p_pix) * np.log(1 - p_pix)).mean(), 2 * large_inter / (large_union + large_inter), 2 * small_inter / (small_union + small_inter)))pbar.update()large_inter_list = np.array(large_inter_list)large_union_list = np.array(large_union_list)small_inter_list = np.array(small_inter_list)small_union_list = np.array(small_union_list)return (total / n / 112 / 112,large_inter_list,large_union_list,small_inter_list,small_union_list,)def _video_collate_fn(x):
……训练和测试写到了一起,那我们如何测试自己的数据集呢?
重写代码?
由于检查点的存在,那么我们再次运行segmentation.py文件的时候,直接跳过训练进行预测。
生成文件介绍
log.csv
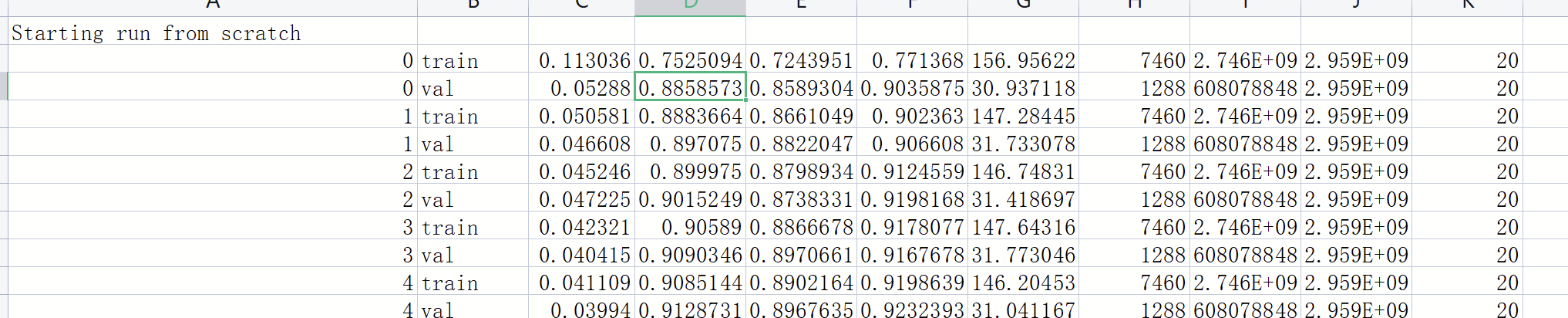 epoch, phase,loss,overall_dice, large_dice,small_dice,time.time() - start_time, large_inter.size,sum(torch.cuda.max_memory_allocated() for i in range(torch.cuda.device_count())), sum(torch.cuda.max_memory_cached() for i in range(torch.cuda.device_count())), batch_size
epoch, phase,loss,overall_dice, large_dice,small_dice,time.time() - start_time, large_inter.size,sum(torch.cuda.max_memory_allocated() for i in range(torch.cuda.device_count())), sum(torch.cuda.max_memory_cached() for i in range(torch.cuda.device_count())), batch_size
5 射血分数预测vedio.py
“”“Functions for training and running EF prediction.”“”
相关文章:
echonet-dynamic代码解读
1 综述 一共是这些代码,我们主要看echo.py,segmentation.py,video.py,config.py。 2 配置文件config.py 基于配置文件设置路径。 """Sets paths based on configuration files."""import conf…...
大气温室气体浓度不断增加,导致气候变暖加剧,随之会引发一系列气象、生态和环境灾害怎样解决?
大气温室气体浓度不断增加,导致气候变暖加剧,随之会引发一系列气象、生态和环境灾害。如何降低温室气体浓度和应对气候变化已成为全球关注的焦点。海洋是地球上最大的“碳库”,“蓝碳”即海洋活动以及海洋生物(特别是红树林、盐沼和海草&…...
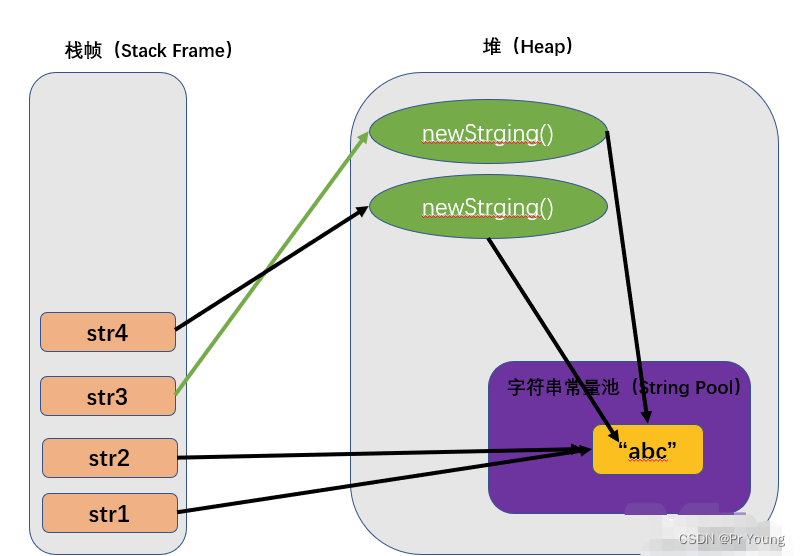
字符串内存分配
涉及三块区域:栈,堆,字符串常量池(jdk1.7之前在方法区,jdk1.7之后在堆中) 关于字符串常量池到底在不在堆中: jdk1.6及以前,方法区独立存在(不在堆里面)&…...

CHI协议通道概念
通道定义为一组结点之间的通信信号。CHI协议定义了四种通道,请求REQ、响应RSP、侦听SNP和数据DAT。 RN结点上CHI协议通道信号组包括: 请求发送端信号,RN结点发送读/写等请求,从不接收请求响应接收端信号,RN结点接收来…...
XQuery 简介
XQuery 简介 解释 XQuery 最佳方式是这样讲:XQuery 相对于 XML 的关系,等同于 SQL 相对于数据库表的关系。 XQuery 被设计用来查询 XML 数据 - 不仅仅限于 XML 文件,还包括任何可以 XML 形态呈现的数据,包括数据库。 您应该具备的…...

Spring的Bean的生命周期与自动注入细节
1. Bean的生命周期 通过一个LifeCycleBean和一个MyBeanPostProcessor来观察Bean的生命周期: 构造(实例化)->依赖注入(前后处理)->初始化(前后处理)->销毁 LifeCycleBean Component public class LifeCycleBean {private static final Logger log LoggerFactory.g…...
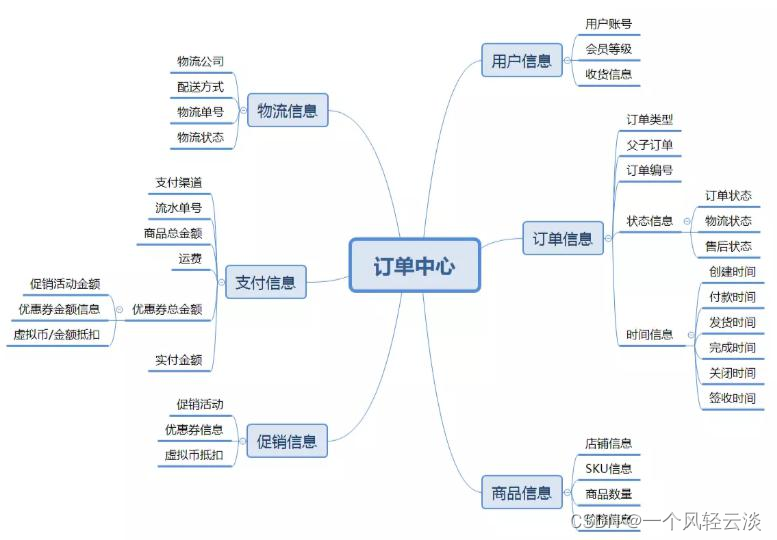
谷粒商城:订单中心概念解析
1、订单中心 电商系统涉及到 3 流,分别时信息流,资金流,物流,而订单系统作为中枢将三者有机的集 合起来。 订单模块是电商系统的枢纽,在订单这个环节上需求获取多个模块的数据和信息,同时对这 些信息进行加…...

快递员配送手机卡,要求当面激活有“猫腻”吗?
咨询:快递员配送手机卡,要求当面激活有“猫腻”吗?有些朋友可能在网上看到了一些关于快递小哥激活会采集信息的文章,所以觉得让快递小哥激活流量卡并不安全,其实,哪有这么多的套路,只要你自己在…...

Sage X3 ERP的称重插件帮助食品和化工企业实现精细化管理
目录 需要称重插件管理的行业客户 Sage X3 ERP称重插件管理的两个关键单位 Sage X3 ERP称重插件的特色 Sage X3 ERP称重插件管理的重要性 需要称重插件管理的行业客户 术语“实际重量”表示在销售和运输时捕获的物品重量。生产销售家禽、肥料、钢材或任何其他需要跟踪实…...
【笔试强训】Day_01
目录 一、选择题 1、 2、 3、 4、 5、 6、 7、 8、 9、 10、 二、编程题 1、组队竞赛 2、删除公共字符 一、选择题 1、 以下for循环的执行次数是() for(int x 0, y 0; (y 123) && (x < 4); x); A 、是无限循环 B 、循环次…...
字节跳动青训营--前端day9
文章目录前言PC web端一、 前端Debug的特点二、 前端Debug的方式1. 浏览器动态修改元素和样式2. Console3. Sorce Tab4. NetWork5. Application6. Performancee7. Lighthouse移动端调试IOSAndroid通过代理工具调试前言 仅以此文章记录学习。 PC web端 一、 前端Debug的特点 …...

如何把模糊的照片还原?
在我们工作和学习中,经常需要各种各样的照片,方便我们需要时可以使用。比如写文档就需要添加图片、或者上传文章、视频等都需要使用图片。由于网络上的图片质量都不一样,难免会遇到不能满足自己的需求。如果是遇到了模糊的照片,如…...

29-Golang中的切片
Golang中的切片基本介绍切片在内存中的形式切片使用的三种方式方式一:方式二:方式三:切片使用的区别切片的遍历切片注意事项和细节说明append函数切片的拷贝操作string和slice基本介绍 1.切片是数组的一个引用,因此切片是引用类型…...

闲聊一下开源
今天看了下中国开源开发者报告,感觉收货不少,针对里面的内容,我也加入一些自己的理解,写下来和大家一起闲聊一下。 AI 时至今日,我说一句AI已经在我国几乎各个行业都能找到应用,应该没人反对吧࿱…...

用这4招优雅的实现Spring Boot 异步线程间数据传递
Spring Boot 自定义线程池实现异步开发相信大家都了解,但是在实际开发中需要在父子线程之间传递一些数据,比如用户信息,链路信息等等 比如用户登录信息使用ThreadLocal存放保证线程隔离,代码如下: /*** author 公众号…...

RocketMQ源码分析之NameServer
1、RocketMQ组件概述 NameServer NameServer相当于配置中心,维护Broker集群、Broker信息、Broker存活信息、主题与队列信息等。NameServer彼此之间不通信,每个Broker与集群内所有的Nameserver保持长连接。 2、源码分析NameServer 本文不对 NameServer 与…...

如何优化认知配比
战略可以归结为三种要素的合理配比。我们对战略的一个定义是:在终局处的判断。这其实来自于一个宗教的命题——面死而生。死是终局,生是过程,当你想做一个思想实验,或者是你真的有缘能够直面死亡,你所有关于生的认知就…...

WuThreat身份安全云-TVD每日漏洞情报-2023-02-15
漏洞名称:TOTOLINK A7100RU 安全漏洞 漏洞级别:严重 漏洞编号:CVE-2023-24276,CNNVD-202302-367 相关涉及:TOTOlink A7100RU(V7.4cu.2313_B20191024)路由器 漏洞状态:POC 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2023-02977 漏洞名称:Windows NTLM 特权提…...
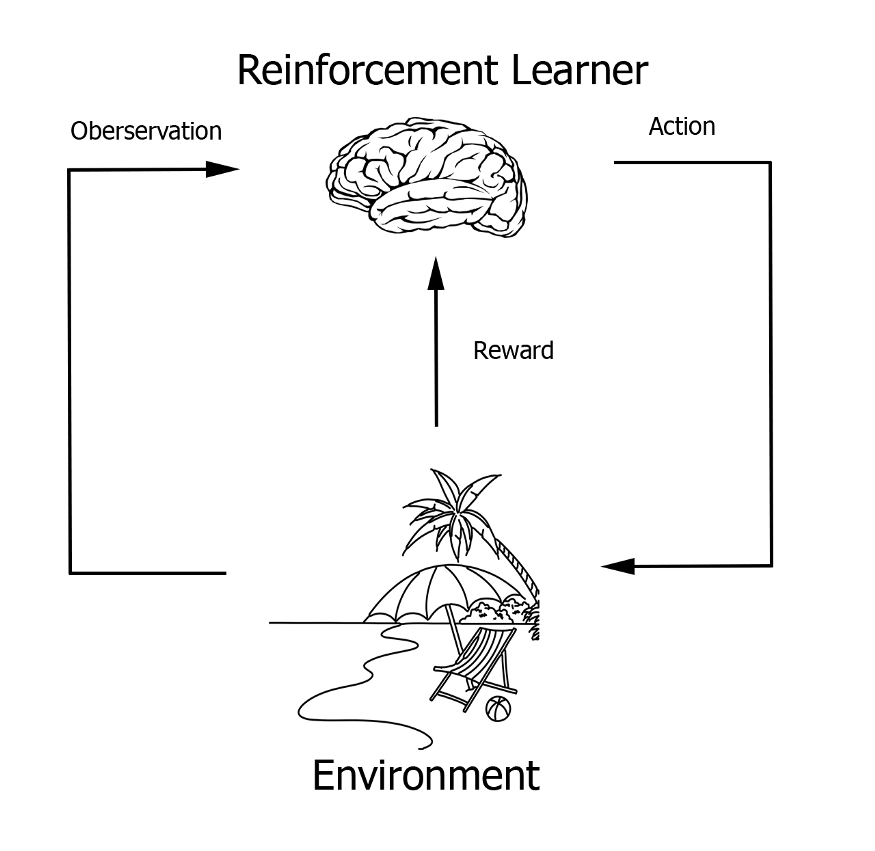
Unreal Engine角色涌现行为开发教程
在本文中,我将讨论如何使用虚幻引擎、强化学习和免费的机器学习插件 MindMaker 在 AI 角色中生成涌现行为。 目的是感兴趣的读者可以使用它作为在他们自己的游戏项目或具体的 AI 角色中创建涌现行为的指南。 推荐:使用 NSDT场景设计器 快速搭建 3D场景。…...
vue处理一千张图片进行分页加载
vue处理一千张图片进行分页加载 开发过程中,如果后端一次性返回你1000多条图片或数据,那我们前端应该怎么用什么思路去更好的渲染呢? 第一种:我们可以使用分页加载 第二种:我们可以进行懒加载那我们用第一种方法使用…...
)
Spring Boot项目实战:手把手教你配置Google Play订阅与Pub/Sub回调(含完整代码)
Spring Boot实战:构建高可靠Google Play订阅与Pub/Sub回调系统 在移动应用商业化路径中,应用内订阅已成为数字服务持续变现的核心模式。根据Statista数据,2023年全球应用订阅收入达到380亿美元,其中Google Play贡献了超过34%的份额…...

别再手动切换收发!用SP3485芯片实现RS485自动收发电路的保姆级教程
用SP3485芯片实现RS485自动收发电路的完整设计指南 在工业控制、楼宇自动化等长距离通信场景中,RS485接口因其抗干扰能力强、传输距离远等优势成为首选。然而传统RS485设计需要手动控制收发使能信号,不仅增加软件复杂度,还容易因时序错误导致…...

Qwen3交互界面开发:利用JavaScript实现网页端字幕编辑器
Qwen3交互界面开发:利用JavaScript实现网页端字幕编辑器 1. 引言 做视频的朋友们,不知道你们有没有过这样的经历:用AI工具生成了视频字幕,时间轴对得总差那么一点,要么是话还没说完字幕就跳了,要么是沉默…...

WAF工程师实战笔记:如何用Suricata规则精准识别哥斯拉、冰蝎、蚁剑的Webshell流量
WAF工程师实战笔记:Suricata规则精准识别主流Webshell流量 在安全运维的日常工作中,Webshell流量的检测始终是一场攻防对抗的持久战。面对哥斯拉、冰蝎、蚁剑等主流Webshell管理工具不断升级的流量混淆技术,传统的特征匹配方法往往力不从心。…...
)
WRF风场后处理实战:用Python+Cartopy绘制500hPa风场矢量图(附完整代码)
WRF风场后处理实战:用PythonCartopy绘制500hPa风场矢量图(附完整代码) 气象数据分析中,风场可视化是理解大气环流特征的关键环节。WRF(Weather Research and Forecasting)模式输出的数据包含丰富的三维风场…...

MinerU 2.5-1.2B新手教程:无需深度学习基础,快速上手PDF提取
MinerU 2.5-1.2B新手教程:无需深度学习基础,快速上手PDF提取 1. 引言:为什么选择MinerU? PDF文档是我们日常工作和学习中常见的文件格式,但要从PDF中提取内容却常常让人头疼。特别是遇到学术论文、技术报告这类包含复…...

OpenClaw人人养虾:密钥管理
Gateway 提供安全的密钥管理(Secrets Management)功能,用于加密存储 API Key、Token 等敏感凭证,避免在配置文件中暴露明文。为什么需要密钥管理明文风险将 API Key 直接写在配置文件中存在严重安全风险:配置文件可能被…...

Scarab:重新定义空洞骑士模组管理体验
Scarab:重新定义空洞骑士模组管理体验 【免费下载链接】Scarab An installer for Hollow Knight mods written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 在独立游戏模组管理领域,手动复制文件、解决版本冲突和跟踪更新的…...
)
告别散斑噪声困扰:用PyTorch手把手实现DenoDet的频域去噪模块(附完整代码)
频域魔法:用PyTorch实现SAR图像去噪的工程实践 当你在处理SAR图像时,是否曾被那些恼人的散斑噪声困扰?这些像胡椒粒一样随机分布的噪声点不仅影响视觉效果,更会严重干扰目标检测的准确性。传统方法试图在空间域直接对抗噪声&#…...

构建语音驱动的智能Agent:集成SenseVoice-Small与AI决策框架
构建语音驱动的智能Agent:集成SenseVoice-Small与AI决策框架 你有没有想过,对着电脑说句话,它就能帮你写代码、查资料、甚至控制智能家居?这听起来像是科幻电影里的场景,但现在,通过将强大的语音识别模型与…...