Spark 3.1.1 shuffle fetch 导致shuffle错位的问题
背景
最近从数据仓库小组那边反馈了一个问题,一个SQL任务出来的结果不正确,重新运行一次之后就没问题了,具体的SQL如下:
select col1,count(1) as cnt
from table1
where dt = '20230202'
group by col1
having count(1) > 1
这个问题是偶发的,在其运行的日志中会发现如下三类日志:
FetchFailed
TaskKilled (another attempt succeeded)
ERROR (org.apache.spark.network.shuffle.RetryingBlockFetcher:231) - Failed to fetch block shuffle_4865_2481
283_286, and will not retry (3 retries)
最终在各种同事的努力下,找到了一个Jira:SPARK-34534
分析
直接切入主题,找到对应的类OneForOneBlockFetcher,该类会被NettyBlockTransferService(没开启ESS)和ExternalBlockStoreClient(开启ESS)调用,其中start方法:
public void start() {client.sendRpc(message.toByteBuffer(), new RpcResponseCallback() {@Overridepublic void onSuccess(ByteBuffer response) {try {streamHandle = (StreamHandle) BlockTransferMessage.Decoder.fromByteBuffer(response);logger.trace("Successfully opened blocks {}, preparing to fetch chunks.", streamHandle);// Immediately request all chunks -- we expect that the total size of the request is// reasonable due to higher level chunking in [[ShuffleBlockFetcherIterator]].for (int i = 0; i < streamHandle.numChunks; i++) {if (downloadFileManager != null) {client.stream(OneForOneStreamManager.genStreamChunkId(streamHandle.streamId, i),new DownloadCallback(i));} else {client.fetchChunk(streamHandle.streamId, i, chunkCallback);}}} catch (Exception e) {logger.error("Failed while starting block fetches after success", e);failRemainingBlocks(blockIds, e);}}@Overridepublic void onFailure(Throwable e) {logger.error("Failed while starting block fetches", e);failRemainingBlocks(blockIds, e);}});}
其中的message的初始化在构造方法中:
if (!transportConf.useOldFetchProtocol() && isShuffleBlocks(blockIds)) {this.message = createFetchShuffleBlocksMsg(appId, execId, blockIds);} else {this.message = new OpenBlocks(appId, execId, blockIds);}其中transportConf.useOldFetchProtocol 也就是 spark.shuffle.useOldFetchProtocol配置(默认是false),如果是shuffle block的话,就会运行到:createFetchShuffleBlocksMsg方法,对于为什么存在这么一个判断,具体参考SPARK-27665
关键的就是 createFetchShuffleBlocksMsg 方法:
这个方法的作用就是: 构建一个FetchShuffleBlocks(appId, execId, shuffleId, mapIds, reduceIdArr, batchFetchEnabled) 对象,其中里面的值
如图:

其中这里有一点需要注意:
long[] mapIds = Longs.toArray(mapIdToReduceIds.keySet());reduceIdArr[i] = Ints.toArray(mapIdToReduceIds.get(mapIds[i]));
这里面对MapId和ReduceId 进行了重组(在获得streamHandle的时候内部会根据reduceIdArr构建blocks索引,下文中会说到)会导致和成员变量blockIds的顺序不一致,为什么两者不一致会导致问题呢?
原因在于任务的fetch失败会导致重新进行fetch,如下:
client.fetchChunk(streamHandle.streamId, i, chunkCallback);
chunkCallback的代码如下:
private class ChunkCallback implements ChunkReceivedCallback {@Overridepublic void onSuccess(int chunkIndex, ManagedBuffer buffer) {// On receipt of a chunk, pass it upwards as a block.listener.onBlockFetchSuccess(blockIds[chunkIndex], buffer);}@Overridepublic void onFailure(int chunkIndex, Throwable e) {// On receipt of a failure, fail every block from chunkIndex onwards.String[] remainingBlockIds = Arrays.copyOfRange(blockIds, chunkIndex, blockIds.length);failRemainingBlocks(remainingBlockIds, e);}}
String[] remainingBlockIds = Arrays.copyOfRange(blockIds, chunkIndex, blockIds.length),此处的chunckIndex就是shuffle blocks的索引下标,也就是下文中numBlockIds组成的数组下标,
但是这个和createFetchShuffleBlocksMsg输出的顺序是不一致的,所以如果发生问题重新fetch的时候,数据有错位,具体可以看:
ShuffleBlockFetcherIterator中的
if (req.size > maxReqSizeShuffleToMem) {shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray,blockFetchingListener, this)} else {shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray,blockFetchingListener, null)}
其中blockFetchingListener回调方法onBlockFetchSuccess会把fetch的block数据和shuffleBlockId一一对应上
ESS端构建blocks的信息
在start方法中,client.sendRpc向对应的ESS发送对应的请求shuffle数据信息,ESS会重新构建blocks的信息,组成StreamHandle(streamId, numBlockIds)返回给请求端:
具体为ExternalBlockHandler的handleMessage方法:
if (msgObj instanceof FetchShuffleBlocks) {FetchShuffleBlocks msg = (FetchShuffleBlocks) msgObj;checkAuth(client, msg.appId);numBlockIds = 0;if (msg.batchFetchEnabled) {numBlockIds = msg.mapIds.length;} else {for (int[] ids: msg.reduceIds) {numBlockIds += ids.length;}}streamId = streamManager.registerStream(client.getClientId(),new ShuffleManagedBufferIterator(msg), client.getChannel());
。。。
callback.onSuccess(new StreamHandle(streamId, numBlockIds).toByteBuffer());这里的numBlockIds就是OneForOneBlockFetcher中的streamHandle.numChunks
如图:
没有开启ESS端的构建blocks的信息
这里和上面的一样,只不过对应的方法为NettyBlockRpcServer的receive:
case fetchShuffleBlocks: FetchShuffleBlocks =>val blocks = fetchShuffleBlocks.mapIds.zipWithIndex.flatMap { case (mapId, index) =>if (!fetchShuffleBlocks.batchFetchEnabled) {fetchShuffleBlocks.reduceIds(index).map { reduceId =>blockManager.getLocalBlockData(ShuffleBlockId(fetchShuffleBlocks.shuffleId, mapId, reduceId))}} else {val startAndEndId = fetchShuffleBlocks.reduceIds(index)if (startAndEndId.length != 2) {throw new IllegalStateException(s"Invalid shuffle fetch request when batch mode " +s"is enabled: $fetchShuffleBlocks")}Array(blockManager.getLocalBlockData(ShuffleBlockBatchId(fetchShuffleBlocks.shuffleId, mapId, startAndEndId(0), startAndEndId(1))))}}val numBlockIds = if (fetchShuffleBlocks.batchFetchEnabled) {fetchShuffleBlocks.mapIds.length} else {fetchShuffleBlocks.reduceIds.map(_.length).sum}val streamId = streamManager.registerStream(appId, blocks.iterator.asJava,client.getChannel)logTrace(s"Registered streamId $streamId with $numBlockIds buffers")responseContext.onSuccess(new StreamHandle(streamId, numBlockIds).toByteBuffer)这里的numBlockIds就是OneForOneBlockFetcher中的streamHandle.numChunks
如图:

所以在以上两种情况下,只要有重新fetch数据的操作,就会存在数据的错位,导致数据的不准确
解决
直接git cherry-pick对应的commit就行:
git cherry-pick 4e438196114eff2e1fc4dd726fdc1bda1af267da
相关文章:
Spark 3.1.1 shuffle fetch 导致shuffle错位的问题
背景 最近从数据仓库小组那边反馈了一个问题,一个SQL任务出来的结果不正确,重新运行一次之后就没问题了,具体的SQL如下: select col1,count(1) as cnt from table1 where dt 20230202 group by col1 having count(1) > 1这个问题是偶发…...
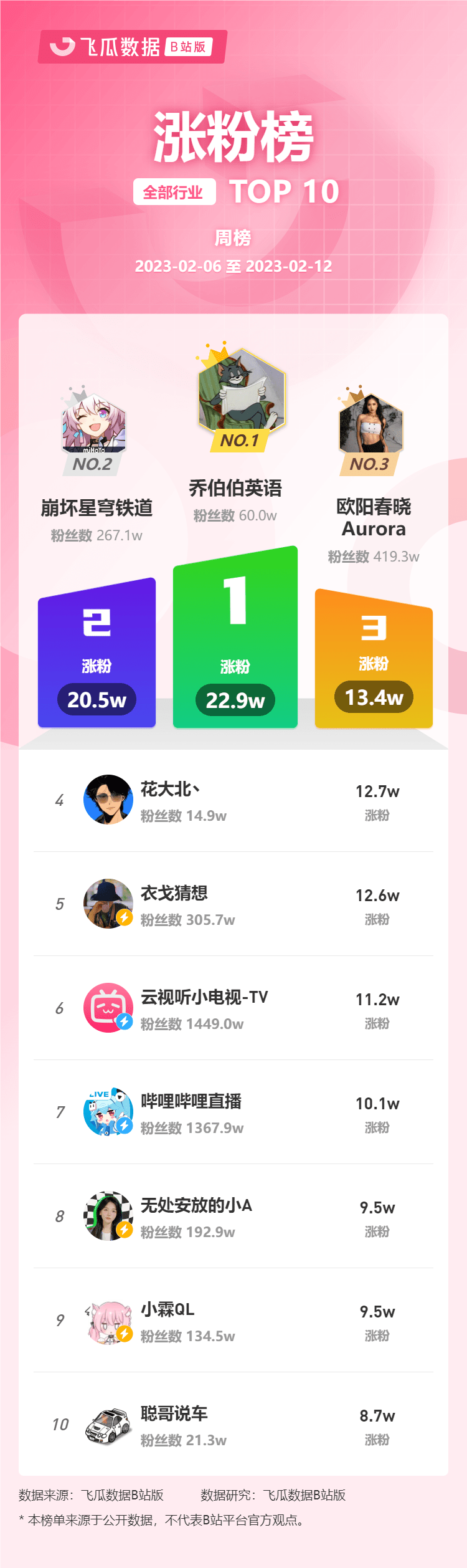
2月第2周榜单丨飞瓜数据B站UP主排行榜(哔哩哔哩平台)发布!
飞瓜轻数发布2023年2月6日-2月12日飞瓜数据UP主排行榜(B站平台),通过充电数、涨粉数、成长指数三个维度来体现UP主账号成长的情况,为用户提供B站号综合价值的数据参考,根据UP主成长情况用户能够快速找到运营能力强的B站…...
Jdk19 动态编译 Java源码为 Class 文件
动态编译 Java 源码为 Class一.背景1.Jdk 版本2.需求二.Java 源码动态编译实现1.Maven 依赖2.源码包装类3.Java 文件对象封装类4.文件管理器封装类5.类加载器6.类编译器三.动态编译测试1.普通测试类2.接口实现类3.测试四.用动态编译 Class 替换 SpringBoot 的 Bean(…...
安装 GPU 版本的 tensorflow 完整版本
前言: 之前安装的 CPU 版本的 tensorflow 一直出问题,索性就直接安装 GPU 版本的 tensorflow 了(有了GPU 就不能浪费)。 安装过程: 1)看自己有无 GPU,找到对应 GPU 的版本:任务管理…...

BOM编程-设置地址栏上的URL
<!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>设置地址栏上的URL</title> </head> <body> <script> function go(){ // 获…...
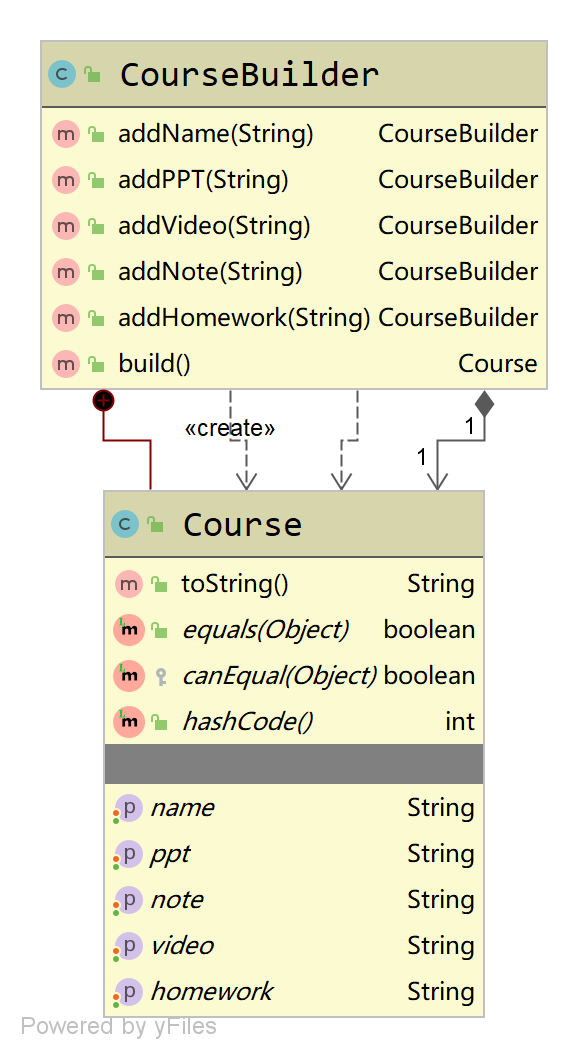
设计模式之原型模式与建造者模式详解和应用
目录1 原型模式1.1 原型模式定义1.2 原型模式的应用场景1.3 原型模式的通用写法(浅拷贝)1.4 使用序列化实现深度克隆1.5 克隆破坏单例模式1.6 原型模式在源码中的应用1.7 原型模式的优缺点1.8 总结2 建造者模式2.1 建造者模式定义2.2 建造者模式的应用场…...

C语言(函数和递归)
函数是完成特定任务的独立程序代码单元。 目录 一.函数 1.创建一个简单的函数 2.定义带形式参数的函数 3.使用return从函数中返回值 二.递归 一.函数 1.创建一个简单的函数 #include <stdio.h> void print(void); //函数原型 int main(){ print(); //函…...

快乐的shell命令行
快乐的shell命令行 PART1——基础 1.权限 #超级用户权限$普通用户 2.复制粘贴 复制:鼠标左键沿着文本拖动高亮的文本被复制到X管理的缓冲区(或者双击一个单词)粘贴:鼠标中键 3.简单命令 时间和日期date当前月份的日历cal磁…...

大数据面试题flume篇
1.Flume 的Source,Sink,Channel 的作用?你们Source 是什么类型? 1. 作用 (1)Source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jm…...
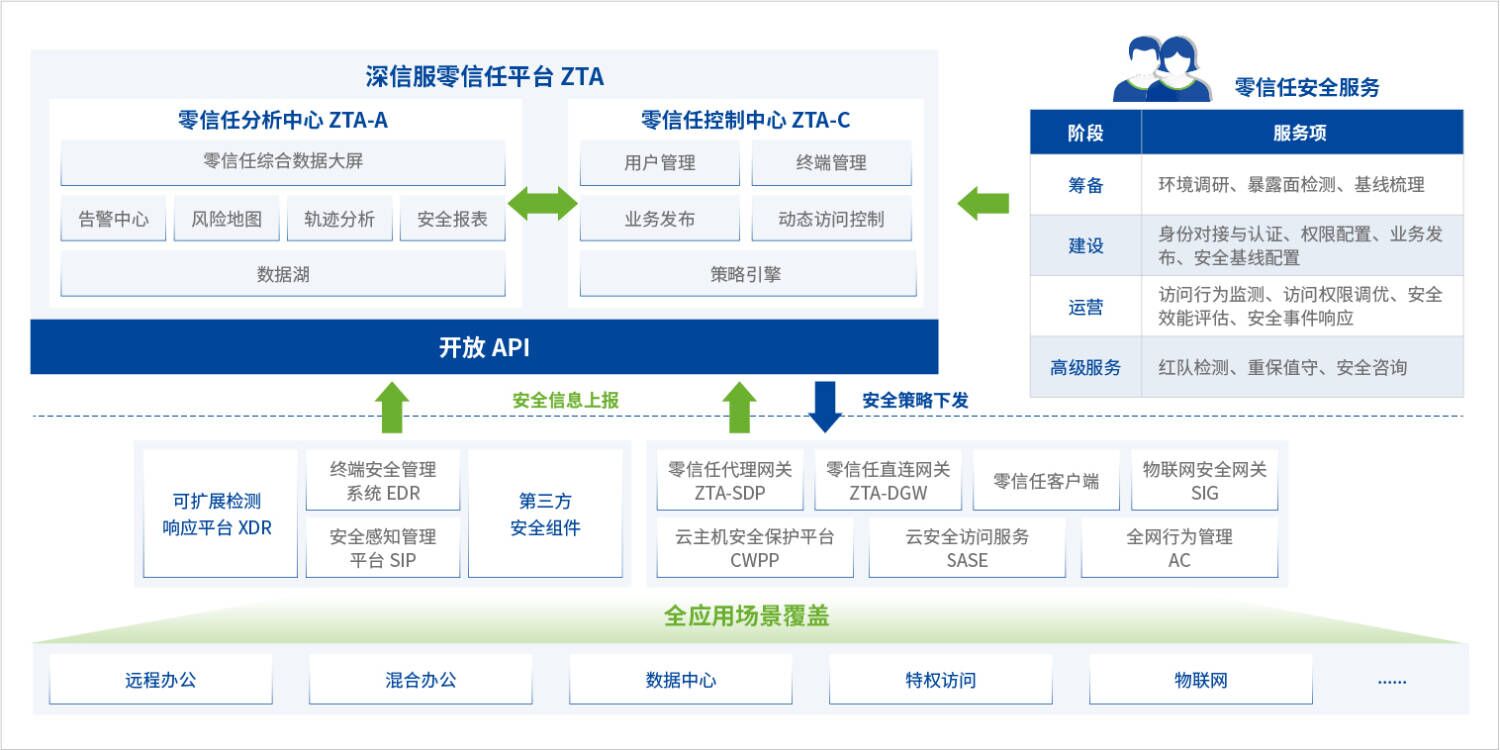
零信任-深信服零信任aTrust介绍(5)
深信服零信任aTrust介绍 深信服是国内领先的互联网信任服务提供商,也是国内首家通过认证的全球信任服务商。深信服零信任是其中一项核心的信任技术,主要针对身份认证、数字签名、数字证书等方面的信任问题。 深信服零信任提供了一种新的安全保护模式…...
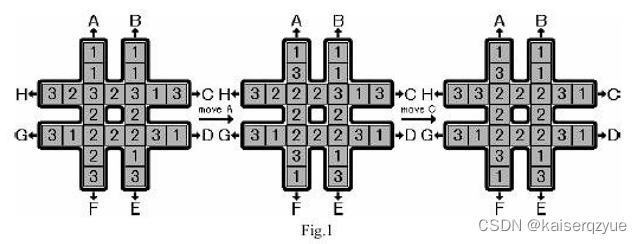
UVa 1343 The Rotation Game 旋转游戏 IDA* BFS 路径还原
题目链接:The Rotation Game 题目描述: 给定二十四个整数,这二十四个整数由八个一,八个二,八个三组成,从左到右,从上到下依次描述下图方格中的数字: 例如上图左边对应的输入就是[1,…...
硬件学习 软件Cadence day02 画原理图的基本操作 (键盘快捷键 , 原理图设计流程 , 从开始到导出网表流程)
1. ORCAD Capture cls 界面的快捷键 键盘 按键对应的操作I放大 (可以滚轮操作)O缩小 (可以滚轮操作)W画线Esc退出现在的状态 (画图界面 右键 End xxx)N放置网络标号J放置节点 (控制…...
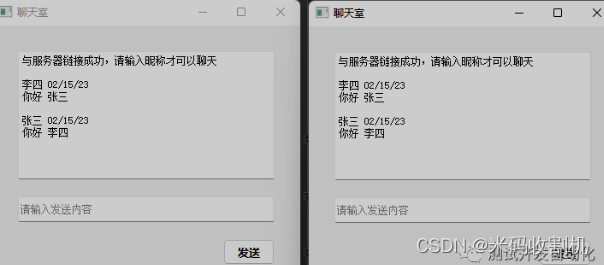
【python】基于Socket的聊天室Python开发
基于Socket的聊天室Python开发一、Socket简述二、创建服务端Server2.1 创建服务端初始化2.2 监听客户端连接2.3 处理客户端消息三、创建客户端Client3.1 创建服务端初始化3.2 发送消息3.3 接收消息3.3 线程工作3.4 线程工作是不是挺好玩的呢?也可以作为课程设计哦&a…...

2023想转行软件测试的看过来,你想要了解的薪资、前景、岗位方向、学习路线都讲明白了
在过去的一年中,软件测试行业发展迅速,随着数字化技术应用的广泛普及,业界对于软件测试的要求也在持续迭代与增加。 同样的,有市场就有需求,软件测试逐渐成为企业中不可或缺的岗位,作为一个高薪又需求广的…...
TortoiseSVN的使用
基本概念 版本库 SVN保持数据的地方,所有的文件都保存在这个库中,Tortoise访问的就是远程服务器上的Subversion版本库。 工作拷贝 就是工作副本,可将版本库的文件拷贝到本地中,可以任意修改, 不会影响版本库。在你…...
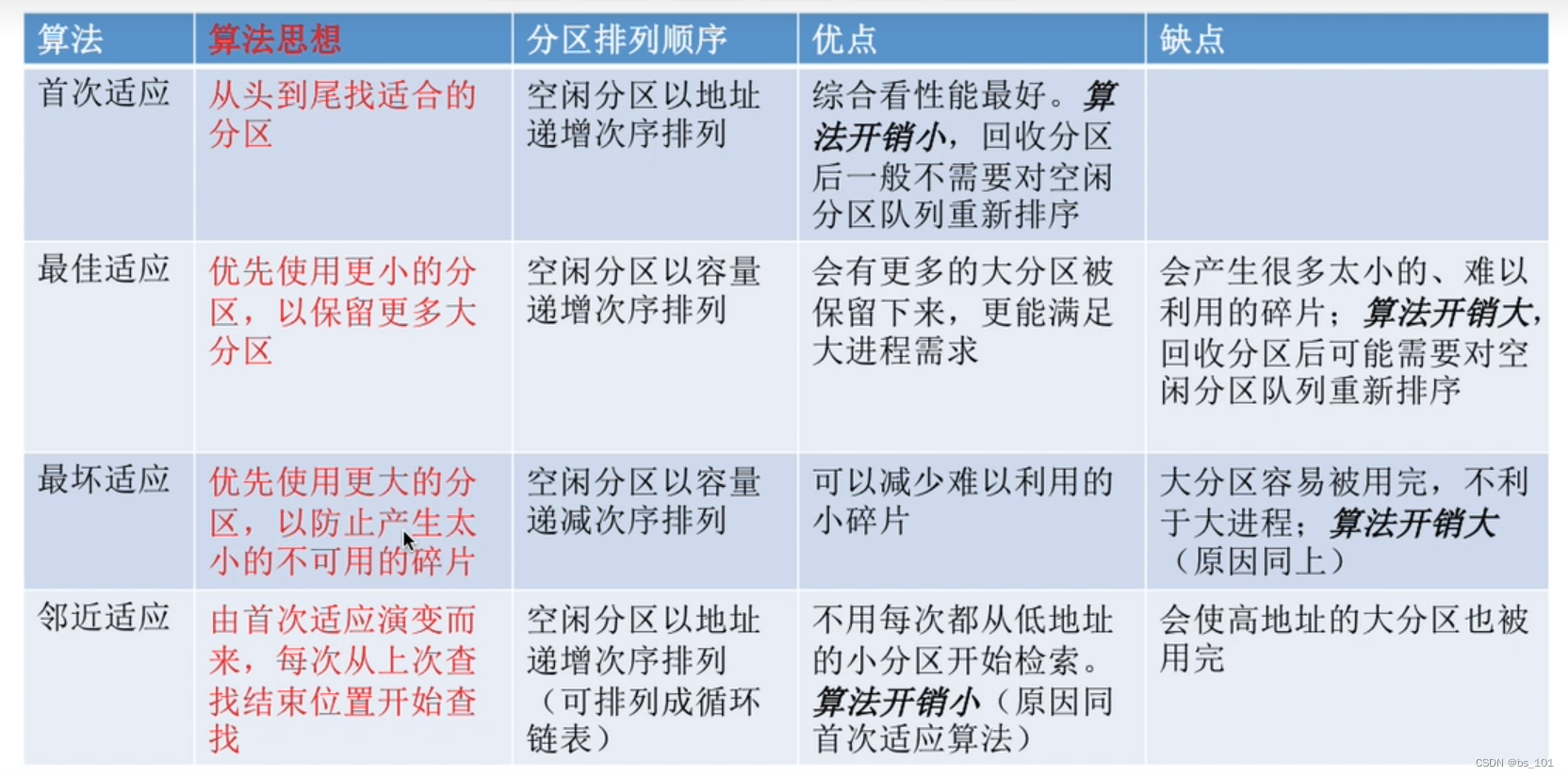
操作系统(day09) -- 连续分配管理方式
连续分配管理方式 单元连续分配 动态分区分配 1.系统要用什么样的数据结构记录内存的使用情况? 两种常用的数据结构 空闲分区表 每个空闲分区对应一个表项。表项中包含分区号、分区大小、分区起始地址等信息空闲分区链 每个分区的起始部分和末尾部分分别设置前向…...

APISpace 带你一起走进西湖美景
俗话说:“上有天堂,下有苏杭”。 “欲把西湖比西子,浓妆艳抹总相宜” 今天我就带大家走进杭州的西湖美景。自古以来,文人歌者面对西湖美景留下千古绝句,还以西湖为背景书写了一段段动人的爱情传说。 天生自带浪漫色…...
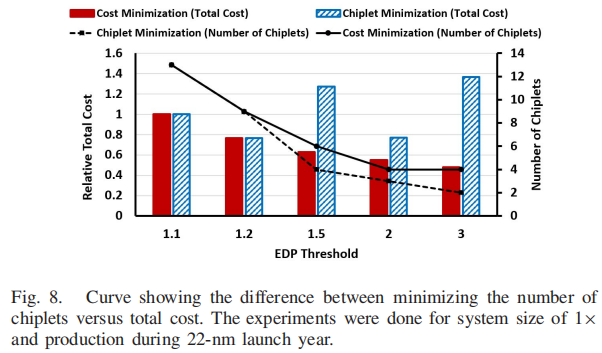
傻白探索Chiplet,Design Space Exploration for Chiplet-Assembly-Based Processors(十三)
阅读了Design Space Exploration for Chiplet-Assembly-Based Processors这篇论文,是关于chiplet设计空间探索的,个人感觉核心贡献有两个:1.提出使用整数线性规划算法进行Chiplet的选择;2.基于RE和NRE提出了一个cost模型ÿ…...

系统分析师真题2020试卷相关概念一
对象系统测试的基本概念: 面向对象系统的单元测试包括方法层次的测试、类层次的测试和类树层次的测试。方法层次的测试类似于传统软件测试中对单个函数的测试; 测试技术: 方法层次的测试,单个函数的测试;常用的技术:等价类划分测试、组合功能测试、递归函数的测试和多态…...

20230215_数据库过程_渠道业务计算过程
—20221209 渠道产能 —自有人员工号表 shzc.xc_qdcn_pgtx_opertype —select * from shzc.xc_qdcn_pgtx_opertype for update ; —渠道基础目录 shzc.xc_qdcn_pgtx_qdtype —select * from shzc.xc_qdcn_pgtx_qdtype for update ; SQL_STRING:‘update shzc.xc_qdcn_pgtx_q…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...