pytorch基础入门教程
pytorch基础入门教程
Pytorch一小时入门教程
前言
机器学习的门槛并没有想象中那么高,我会陆续把我在学习过程中看过的一些文章和写过的代码以博客的形式分享给大家,和大家一起交流,这个是本系列的第一篇,pytoch入门教程,翻译自pytoch官方文档:Pytorch一小时入门教程。
pytorch是什么
它是一个基于python的科学计算库,致力于为两类用户提供服务:
- 一些想要找到Numpy搭建神经网络替代品的用户;
- 寻找一个可提供极强的可拓展性和运行速度的深度学习研究平台;
让我们开始干活吧!
1. 张量的概念和生成
张量和Numpy中ndarrays的概念很相似,有了这个作为基础,张量也可以被运行在GPU上来加速计算,下面介绍如何创建张量。
from __future__ import print_function
import torch
# 这个是用来生成一个为未初始化的5*3的张量,切记不是全零
x = torch.empty(5, 3)
print(x)
"""
tensor([[2.7712e+35, 4.5886e-41, 7.2927e-04],[3.0780e-41, 3.8725e+35, 4.5886e-41],[4.4446e-17, 4.5886e-41, 3.9665e+35],[4.5886e-41, 3.9648e+35, 4.5886e-41],[3.8722e+35, 4.5886e-41, 4.4446e-17]])
"""# 这个是生成一个均匀分布的初始化的,每个元素从0~1的张量,与第一个要区别开,另外,还有其它的随机张量生成函数,如torch.randn()、torch.normal()、torch.linespace(),分别是标准正态分布,离散正态分布,线性间距向量
x = torch.rand(5, 3)
print(x)
"""
tensor([[0.9600, 0.0110, 0.9917],[0.9549, 0.1732, 0.7781],[0.8098, 0.5300, 0.5747],[0.5976, 0.1412, 0.9444],[0.6023, 0.7750, 0.5772]])
"""# 这个是初始化一个全零张量,可以指定每个元素的类型。
x = torch.zeros(5, 3, dtype=torch.long)
print(x)
"""tensor([[0, 0, 0],[0, 0, 0],[0, 0, 0],[0, 0, 0],[0, 0, 0]])"""#从已有矩阵转化为张量
x = torch.tensor([5.5, 3])
print(x)
"""
tensor([5.5000, 3.0000])
"""# 从已有张量中创造一个张量,新的张量将会重用已有张量的属性。如:若不提供新的值,那么每个值的类型将会被重用。
x = x.new_ones(5, 3, dtype=torch.double) # new_* methods take in sizes
print(x)x = torch.randn_like(x, dtype=torch.float) # override dtype!
print(x) # result has the same size
"""
tensor([[1., 1., 1.],[1., 1., 1.],[1., 1., 1.],[1., 1., 1.],[1., 1., 1.]], dtype=torch.float64)
tensor([[ 0.3327, -0.2405, -1.3764],[-0.1040, -0.9072, 0.0069],[-0.2622, 1.8072, 0.0175],[ 0.0572, -0.6766, 1.6201],[-0.7197, -1.1166, 1.7308]])"""# 最后我们学习如何获取张量的形状,一个小Tip,torch.Size是一个元组,所以支持元组的操作。
print(x.size())
"""torch.Size([5, 3])"""2. 张量的操作
实际上有很多语法来操作张量,现在我们来看一看加法。
y = torch.rand(5, 3)
# 加法方式1
print(x + y)
"""
tensor([[ 1.2461, 0.6067, -0.9796],[ 0.0663, -0.9046, 0.8010],[ 0.4199, 1.8893, 0.7887],[ 0.6264, -0.2058, 1.8550],[ 0.0445, -0.8441, 2.2513]])
"""
# 加法方式2
print(torch.add(x, y))
"""
tensor([[ 1.2461, 0.6067, -0.9796],[ 0.0663, -0.9046, 0.8010],[ 0.4199, 1.8893, 0.7887],[ 0.6264, -0.2058, 1.8550],[ 0.0445, -0.8441, 2.2513]])
"""
# 还可以加参数
result = torch.empty(5, 3)
torch.add(x, y, out=result)
print(result)
"""
tensor([[ 1.2461, 0.6067, -0.9796],[ 0.0663, -0.9046, 0.8010],[ 0.4199, 1.8893, 0.7887],[ 0.6264, -0.2058, 1.8550],[ 0.0445, -0.8441, 2.2513]])
"""
# 方法二的一种变式,注意有一个‘_’,这个符号在所有替换自身操作符的末尾都有,另外,输出的方式还可以象python一样。
y.add_(x)
print(y)
"""
tensor([[ 1.2461, 0.6067, -0.9796],[ 0.0663, -0.9046, 0.8010],[ 0.4199, 1.8893, 0.7887],[ 0.6264, -0.2058, 1.8550],[ 0.0445, -0.8441, 2.2513]])
"""
print(x[:, 1])
"""
tensor([-0.2405, -0.9072, 1.8072, -0.6766, -1.1166])
"""
我们现在看一看如何调整张量的形状。
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) # the size -1 is inferred from other dimensions
print(x.size(), y.size(), z.size())
"""
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
"""
我们现在看一看如何查看张量的大小。
x = torch.randn(1)
print(x)
print(x.item())
"""
tensor([-1.4743])
-1.4742881059646606
"""
到这里,基本的操作知识就已经讲完了,如果了解更详细的部分,请点击这个链接.
3. 张量和Numpy的相互转换
张量和Numpy数组之间的转换十分容易。
- Tensor到Nump,在使用Cpu的情况下,张量和array将共享他们的物理位置,改变其中一个的值,另一个也会随之变化。
a = torch.ones(5)
print(a)
"""
tensor([1., 1., 1., 1., 1.])
"""
b = a.numpy()
print(b)
"""
[1. 1. 1. 1. 1.]
"""
a.add_(1)
print(a)
print(b)
"""
tensor([2., 2., 2., 2., 2.])
[2. 2. 2. 2. 2.]
"""
- Numpy到Tensor ,在使用Cpu的情况下,张量和array将共享他们的物理位置,改变其中一个的值,另一个也会随之变化。
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a)
print(b)
"""
[2. 2. 2. 2. 2.]
tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
"""
- Gpu下的转换。
# let us run this cell only if CUDA is available
# We will use ``torch.device`` objects to move tensors in and out of GPU
if torch.cuda.is_available():device = torch.device("cuda") # a CUDA device objecty = torch.ones_like(x, device=device) # directly create a tensor on GPUx = x.to(device) # or just use strings ``.to("cuda")``z = x + yprint(z)print(z.to("cpu", torch.double)) # ``.to`` can also change dtype together!
"""
tensor([-0.4743], device='cuda:0')
tensor([-0.4743], dtype=torch.float64)
"""
自动微分
在pytorch中,神经网络的核心是自动微分,在本节中我们会初探这个部分,也会训练一个小型的神经网络。自动微分包会提供自动微分的操作,它是一个取决于每一轮的运行的库,你的下一次的结果会和你上一轮运行的代码有关,因此,每一轮的结果,有可能都不一样。接下来,让我们来看一些例子。
1. 张量
torch.Tensor是这个包的核心类,如果你设置了它的参数 ‘.requires_grad=true’ 的话,它将会开始去追踪所有的在这个张量上面的运算。当你完成你得计算的时候,你可以调用’backwward()来计算所有的微分。这个向量的梯度将会自动被保存在’grad’这个属性里面。
如果想要阻止张量跟踪历史数据,你可以调用’detach()'来将它从计算历史中分离出来,当然未来所有计算的数据也将不会被保存。或者你可以使用’with torch.no_grad()‘来调用代码块,不光会阻止梯度计算,还会避免使用储存空间,这个在计算模型的时候将会有很大的用处,因为模型梯度计算的这个属性默认是开启的,而我们可能并不需要。
第二个非常重要的类是Function,Tensor和Function,他们两个是相互联系的并且可以搭建一个非循环的运算图。每一个张量都有一个’grad_fn’的属性,它可以调用Function来创建Tensor,当然,如果用户自己创建了Tensor的话,那这个属性自动设置为None。
如果你想要计算引出量的话,你可以调用’.backward()'在Tensor上面,如果Tensor是一个纯数的话,那么你将不必要指明任何参数;如果它不是纯数的话,你需要指明一个和张量形状匹配的梯度的参数。下面来看一些例程。
import torch
x = torch.ones(2, 2, requires_grad=True)
print(x)
"""
tensor([[1., 1.],[1., 1.]], requires_grad=True)
"""
y = x + 2
print(y)
"""
tensor([[3., 3.],[3., 3.]], grad_fn=<AddBackward0>)
"""
print(y.grad_fn)
"""
<AddBackward0 object at 0x7fc6bd199ac8>
"""
z = y * y * 3
out = z.mean()
print(z, out)
"""
tensor([[27., 27.],[27., 27.]], grad_fn=<MulBackward0>) tensor(27., grad_fn=<MeanBackward0>)
"""
a = torch.randn(2, 2)
a = ((a * 3) / (a - 1))
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b.grad_fn)
"""
False
True
<SumBackward0 object at 0x7fc6bd1b02e8>
"""
2. 梯度
现在我们将进行反向梯度传播。因为输出包含一个纯数,那么out.backward()等于out.backward(torch.tensor(1.));梯度的计算如下(分为数量和向量)
- 数量的梯度,即各个方向的导数的集合
print(x.grad)
"""
tensor([[4.5000, 4.5000],[4.5000, 4.5000]])
"""
-
向量的全微分,即雅可比行列式。
J = ( ∂ y 1 ∂ x 1 ⋯ ∂ y 1 ∂ x n ⋮ ⋱ ⋮ ∂ y m ∂ x 1 ⋯ ∂ y m ∂ x n )J=(∂y1∂x1⋯∂y1∂xn⋮⋱⋮∂ym∂x1⋯∂ym∂xn)\begin{aligned}J=\left(\begin{array}{ccc} \frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}}\\ \vdots & \ddots & \vdots\\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}} \end{array}\right)\end{aligned} J=∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym
J=⎝⎜⎛∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym⎠⎟⎞
-
最后的例子。
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(v)print(x.grad)
"""
tensor([1.0240e+02, 1.0240e+03, 1.0240e-01])
"""
#停止计算微分
print(x.requires_grad)
print((x ** 2).requires_grad)with torch.no_grad():print((x ** 2).requires_grad)
"""
True
True
False
"""
神经网络
神经网络可以用torch.nn构建。现在我们可以来看一看autograd这个部分了,torch.nn依赖于它它来定义模型并做微分,nn.Module包含神经层,forward(input)可以用来返回output.例如,看接下来这个可以给数字图像分层的网络。
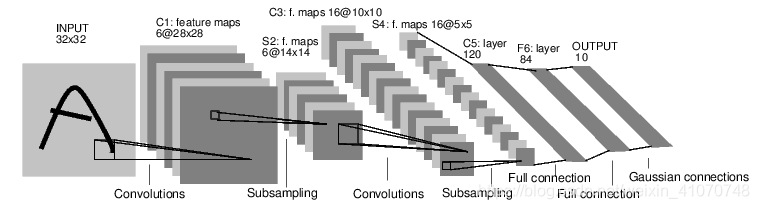
这个是一个简单前馈网络,它将输入经过一层层的传递,最后给出了结果。一个经典的神经网络的学习过程如下所示:
- 定义神经网络及其参数;
- 在数据集上多次迭代循环;
- 通过神经网络处理数据集;
- 计算损失(输出和正确的结果之间相差的距离);
- 用梯度对参数反向影响;
- 更新神经网络的权重,weight = weight - rate * gradient;
让我们来一步步详解这个过程。
1.定义网络
import torch
import torch.nn as nn
import torch.nn.functional as F# 汉字均为我个人理解,英文为原文标注。
class Net(nn.Module):def __init__(self):# 继承原有模型super(Net, self).__init__()# 1 input image channel, 6 output channels, 5x5 square convolution# kernel# 定义了两个卷积层# 第一层是输入1维的(说明是单通道,灰色的图片)图片,输出6维的的卷积层(说明用到了6个卷积核,而每个卷积核是5*5的)。self.conv1 = nn.Conv2d(1, 6, 5)# 第一层是输入1维的(说明是单通道,灰色的图片)图片,输出6维的的卷积层(说明用到了6个卷积核,而每个卷积核是5*5的)。self.conv2 = nn.Conv2d(6, 16, 5)# an affine operation: y = Wx + b# 定义了三个全连接层,即fc1与conv2相连,将16张5*5的卷积网络一维化,并输出120个节点。self.fc1 = nn.Linear(16 * 5 * 5, 120)# 将120个节点转化为84个。self.fc2 = nn.Linear(120, 84)# 将84个节点输出为10个,即有10个分类结果。self.fc3 = nn.Linear(84, 10)def forward(self, x):# Max pooling over a (2, 2) window# 用relu激活函数作为一个池化层,池化的窗口大小是2*2,这个也与上文的16*5*5的计算结果相符(一开始我没弄懂为什么fc1的输入点数是16*5*5,后来发现,这个例子是建立在lenet5上的)。# 这句整体的意思是,先用conv1卷积,然后激活,激活的窗口是2*2。x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))# If the size is a square you can only specify a single number# 作用同上,然后有个需要注意的地方是在窗口是正方形的时候,2的写法等同于(2,2)。# 这句整体的意思是,先用conv2卷积,然后激活,激活的窗口是2*2。x = F.max_pool2d(F.relu(self.conv2(x)), 2)# 这句整体的意思是,调用下面的定义好的查看特征数量的函数,将我们高维的向量转化为一维。x = x.view(-1, self.num_flat_features(x))# 用一下全连接层fc1,然后做一个激活。x = F.relu(self.fc1(x))# 用一下全连接层fc2,然后做一个激活。x = F.relu(self.fc2(x))# 用一下全连接层fc3。x = self.fc3(x)return xdef num_flat_features(self, x):# 承接上文的引用,这里需要注意的是,由于pytorch只接受图片集的输入方式(原文的单词是batch),所以第一个代表个数的维度被忽略。size = x.size()[1:] # all dimensions except the batch dimensionnum_features = 1for s in size:num_features *= sreturn num_featuresnet = Net()
print(net)"""
Net((conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear(in_features=400, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=84, bias=True)(fc3): Linear(in_features=84, out_features=10, bias=True)
)
"""# 现在我们已经构建好模型了,但是还没有开始用bp呢,如果你对前面的内容有一些印象的话,你就会想起来不需要我们自己去搭建,我们只需要用某一个属性就可以了,autograd。# 现在我们需要来看一看我们的模型,下列语句可以帮助你看一下这个模型的一些具体情况。params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weight"""
10
torch.Size([6, 1, 5, 5])
"""input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)"""
tensor([[ 0.0114, 0.0476, -0.0647, 0.0381, 0.0088, -0.1024, -0.0354, 0.0220,-0.0471, 0.0586]], grad_fn=<AddmmBackward>)
"""#最后让我们清空缓存,准备下一阶段的任务。
net.zero_grad()
out.backward(torch.randn(1, 10))2. 损失函数
先介绍一下损失函数是干什么的:它可以用来度量输出和目标之间的差距,那度量出来有什么意义呢?还记得我们的反向传播吗?他可以将误差作为一个反馈来影响我们之前的参数,更新参数将会在下一节中讲到。当然度量的方法有很多,我们这里选用nn.MSELoss来计算误差,下面接着完善上面的例程。
# 这个框架是来弄明白我们现在做了什么,这个网络张什么样子。
"""
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d-> view -> linear -> relu -> linear -> relu -> linear-> MSELoss-> loss
"""
# 到目前为止我们学习了Tensor(张量),autograd.Function(自动微分),Parameter(参数),Module(如何定义,各个层的结构,传播过程)
# 现在我们还要学习损失函数和更新权值。# 这一部分是来搞定损失函数
output = net(input)
target = torch.randn(10) # a dummy target, for example
target = target.view(1, -1) # make it the same shape as output
criterion = nn.MSELoss()loss = criterion(output, target)
print(loss)# 看一看我们的各个点的结果。
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU"""
<MseLossBackward object at 0x7efbcad51a58>
<AddmmBackward object at 0x7efbcad51b38>
<AccumulateGrad object at 0x7efbcad51b38>
"""# 重点来了,反向传播计算梯度。
net.zero_grad() # zeroes the gradient buffers of all parametersprint('conv1.bias.grad before backward')
print(net.conv1.bias.grad)loss.backward()print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)"""
conv1.bias.grad before backward
tensor([0., 0., 0., 0., 0., 0.])
conv1.bias.grad after backward
tensor([ 0.0087, -0.0073, 0.0013, 0.0006, -0.0107, -0.0042])
"""另外官方文档给了一个各个模型和损失函数的地址,有兴趣的可以看一看,或者收藏一下,做个备份。
3. 损失函数
激动人心的时刻终于来了,如何更新权值?如果你对上面我们翻译的文章了解的话,你就知道,我们现在搞定了模型的搭建,也得到了预测值与真实值的差距是多少,在哪里可能造成了这个差距,但是还是短些什么,短什么呢(先自己想一下)?
还剩如何修正这个差距。也就是我们所说的权值更新,我们这个所采用的方法是SGD,学名称为随机梯度下降法 Stochastic Gradient Descent 。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0LsRGcHw-1676447350887)(./5.png)]
# 相应的python代码
learning_rate = 0.01
for f in net.parameters():f.data.sub_(f.grad.data * learning_rate)
如果你想用更多的其它方法的话,你可以查看 t o r c h . o p t i m torch.optim torch.optim。
import torch.optim as optim# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update
至此,我们的基本知识就差不多结束了,接下来我们会动手在CPU和GPU上训练我们的图像分类器。
训练分类器
1. 首先进行数据处理
我们知道,要想有一个好的模型你必须有一些好的数据,并将他们转化为模型可以理解的语言,这个工作非常重要。对于前者我将来会写一个博客介绍我所知道的几种方法,现在我们来看后者。
我们知道,要想有一个好的模型你必须有一些好的数据,并将他们转化为模型可以理解的语言,这个工作非常重要。对于前者我将来会写一个博客介绍我所知道的几种方法,现在我们来看后者如何解决。
众所周知,当我们需要处理图像,文本,音频或者视频数据的时候,你可以使用标准的python库来将这些书v就转化为numpy array,然后你可以其再转化为Tensor。下面列出一些相应的python库:
- For images, packages such as Pillow, OpenCV are useful
- For audio, packages such as scipy and librosa
- For text, either raw Python or Cython based loading, or NLTK and SpaCy are useful
特别是对于视觉领域,我们写了一个叫做torchvision的包,他可以将很多知名数据的数据即涵盖在内。并且,通过torchvision.datasets 和 torch.utils.data.DataLoader 进行数据的转化。在本里中我们将会使用 CIFAR10 数据集,它有以下各类: ‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。在这个数据集中的图像尺寸都是3_32_32的。
2. 开始训练模型
- 先说一下训练步骤.
- 首先装载数据,并将其统一化;
- 定义CNN;
- 定义损失函数;
- 训练神经网络;
- 测试网络;
- 接下来开始干活(cpu版本的):
import torch
import torch.optim as optim
import torchvision
import torchvision.transforms as transformstransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=2)testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=2)classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')import matplotlib.pyplot as plt
import numpy as np# functions to show an imagedef imshow(img):img = img / 2 + 0.5 # unnormalizenpimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xnet = Net()for epoch in range(2): # loop over the dataset multiple timesrunning_loss = 0.0for i, data in enumerate(trainloader, 0):# get the inputsinputs, labels = data# zero the parameter gradientscriterion = nn.CrossEntropyLoss()optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)optimizer.zero_grad()# forward + backward + optimizeoutputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()if i % 2000 == 1999: # print every 2000 mini-batchesprint('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 2000))running_loss = 0.0print('Finished Training')dataiter = iter(testloader)
images, labels = dataiter.next()# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))outputs = net(images)_, predicted = torch.max(outputs, 1)print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]for j in range(4)))correct = 0
total = 0
with torch.no_grad():for data in testloader:images, labels = dataoutputs = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():for data in testloader:images, labels = dataoutputs = net(images)_, predicted = torch.max(outputs, 1)c = (predicted == labels).squeeze()for i in range(4):label = labels[i]class_correct[label] += c[i].item()class_total[label] += 1for i in range(10):print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))
- 还没完,还有活干(gpu版本的):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# Assuming that we are on a CUDA machine, this should print a CUDA device:print(device)net.to(device)inputs, labels = inputs.to(device), labels.to(device)
- 还没完,还有活干(gpu版本的最终代码成品):
import torch.optim as optim
import torch
import torchvision
import torchvision.transforms as transformstransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=2)testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=2)classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')import matplotlib.pyplot as plt
import numpy as np# functions to show an imagedef imshow(img):img = img / 2 + 0.5 # unnormalizenpimg = img.cpu().numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xnet = Net()device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# Assuming that we are on a CUDA machine, this should print a CUDA device:print(device)net.to(device)for epoch in range(2): # loop over the dataset multiple timesrunning_loss = 0.0for i, data in enumerate(trainloader, 0):# get the inputsinputs, labels = datainputs, labels = inputs.to(device), labels.to(device)# zero the parameter gradientscriterion = nn.CrossEntropyLoss()optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)optimizer.zero_grad()# forward + backward + optimizeoutputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()if i % 2000 == 1999: # print every 2000 mini-batchesprint('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 2000))running_loss = 0.0print('Finished Training')dataiter = iter(testloader)
images, labels = dataiter.next()
images, labels = inputs.to(device), labels.to(device)# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))outputs = net(images)_, predicted = torch.max(outputs, 1)print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]for j in range(4)))correct = 0
total = 0
with torch.no_grad():for data in testloader:images, labels = dataimages, labels = inputs.to(device), labels.to(device)outputs = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():for data in testloader:images, labels = dataimages, labels = inputs.to(device), labels.to(device)outputs = net(images)_, predicted = torch.max(outputs, 1)c = (predicted == labels).squeeze()for i in range(4):label = labels[i]class_correct[label] += c[i].item()class_total[label] += 1for i in range(10):print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))相关文章:
pytorch基础入门教程
pytorch基础入门教程 Pytorch一小时入门教程 前言 机器学习的门槛并没有想象中那么高,我会陆续把我在学习过程中看过的一些文章和写过的代码以博客的形式分享给大家,和大家一起交流,这个是本系列的第一篇,pytoch入门教程&#x…...
RTSP协议交互时TCP/UDP的区别 以及视频和音频的区别 以及H264/H265的区别
经过这几天的调试 一个功能简单的 RTSP服务端已经实现了 支持TCP/UDP 支持H264 H265 支持同时传输 AAC音频 记录下 交互时需要注意的地方 1.OPTIONS 都一样 如下:左箭头内是客户端发给服务端 箭头内是服务端回给客户端 2.DESCRIBE 目前的流是包含视频和AAC音频…...

调用大智慧L2接口是什么原理?作用是什么?
有些开发人员想要设计一个微信公众号或者微信小程序,由于自己搭建数据库工作量太大,或者技术受限,也会选择调用大智慧L2接口减少工作量。调用大智慧L2接口是什么原理?作用是什么? 大智慧L2接口即应用程序编程接口&…...
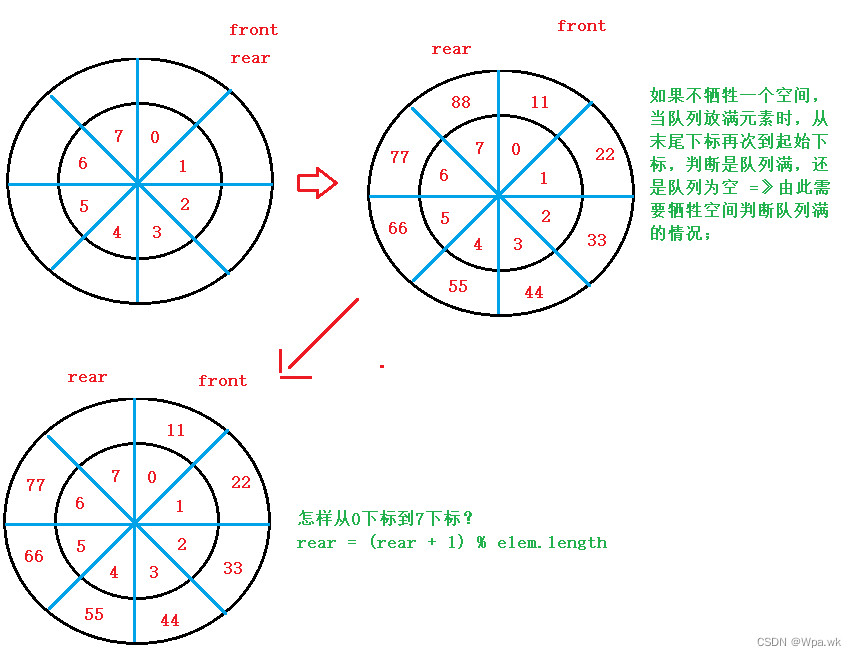
数据结构 - 栈 与 队列 - (java)
前言 本篇介绍栈和队列,了解栈有顺序栈和链式栈,队列底层是双链表实现的,单链表也可以实现队列,栈和队列的相互实现和循环队列;如有错误,请在评论区指正,让我们一起交流,共同进步&a…...

CellularAutomata元胞向量机-8-渗流集群MATLAB代码分享
%% Percolation Clusterclf clc, clearthreshold .63; % ax axes(units,pixels,position,[1 1 650 700],color,k); text(units, pixels, position, [150,255,0],... string,美赛,color,w,fontname,helvetica,fontsize,100) text(units, pixels, position, [40,120,0],... str…...

iOS UI自动化测试详解
前言: 小目标 关于UI自动化的定义,我想要的是自动地按照流程去点击页面、输入数据,不需要人去参与,节省人工时间。比如登录,能够自己去填写用户名&密码,然后点击按钮跳转到下一个页面等。在能够保证业…...
Mybatis源码分析(九)Mybatis的PreparedStatement
文章目录一 JDBC的PreparedStatement二 prepareStatement的准备阶段2.1 获取Connection2.1.1 **UnpooledDataSource**2.1.2 PooledDataSource2.2 Sql的预编译PreparedStatementHandler2.3 为Statement设置参数2.4 执行具体的语句过程官网:mybatis – MyBatis 3 | 简…...

winfrom ui
http://www.iqidi.com/download/warehouse/Device_DotNetBar.rar http://qiosdevsuite.com/Download https://sourceforge.net/projects/qiosdevsuite/ https://www.cnblogs.com/hcyblogs/p/6758381.html https://www.cnblogs.com/jordonin/p/6484366.html MBTiles地图瓦片管…...
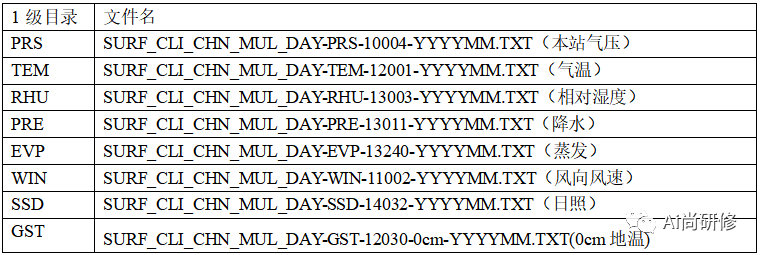
中国国家级地面气象站基本气象要素日值数据集(V3.0)
数据集摘要 数据集包含了中国基本气象站、基准气候站、一般气象站在内的主要2474个站点1951年1月以来本站气压、气温、降水量、蒸发量、相对湿度、风向风速、日照时数和0cm地温要素的日值数据。数据量为21.3GB。 (1)SURF_CLI_CHN_MUL_DAY-TEM-12001-201501.TXT 气温数据TEM, 包…...

【Python语言基础】——Python NumPy 数组副本 vs 视图
Python语言基础——Python NumPy 数组副本 vs 视图 文章目录 Python语言基础——Python NumPy 数组副本 vs 视图一、Python NumPy 数组副本 vs 视图一、Python NumPy 数组副本 vs 视图 副本和视图之间的区别 副本和数组视图之间的主要区别在于副本是一个新数组,而这个视图只是…...
Spring Cloud_OpenFeign服务接口调用
目录一、概述1.OpenFeign是什么2.能干嘛二、OpenFeign使用步骤1.接口注解2.新建Module3.POM4.YML5.主启动类6.业务类7.测试8.小总结三、OpenFeign超时控制1.超时设置,故意设置超时演示出错情况2.是什么3.YML中需要开启OpenFeign客户端超时控制四、OpenFeign日志打印…...

十三、GIO GTask
GTask表示管理一个可取消的“任务task” GCancellable GCancellable是一个线程安全的操作取消栈,用于整个GIO,以允许取消同步和异步操作。 它继承于GObject对象,不是一个单纯的结构体 相关函数 g_task_new GTask* g_task_new (GObject*…...
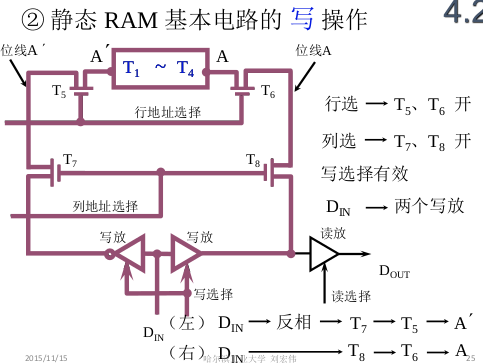
ch4_1存储器
1. 存储器的类型 1.1 按照存储介质来分类 半导体存储器: TTL, MOS 易失性 磁表面存储器: 磁头, 载磁体; 磁芯存储器: 硬磁材料, 环状元件 光盘存储器: 激光, 磁光材料; 1.2 按…...

Doris通过Flink CDC接入MySQL实战
1. 创建MySQL库表,写入demo数据 登录测试MySQL mysql -u root -pnew_password创建MySQL库表,写入demo数据 CREATE DATABASE emp_1;USE emp_1; CREATE TABLE employees_1 (emp_no INT NOT NULL,birth_date DATE NOT NULL,…...
搭建zookeeper高可用集群详细步骤
目录 一、虚拟机设置 1.新建一台虚拟机并克隆三台,配置自定义 2.修改四台虚拟机的主机名并立即生效 3.修改四台虚拟机的网络信息 4.重启四台虚拟机的网络服务并测试网络连接 5.重启四台虚拟机,启动后关闭四台虚拟机的防火墙 6.在第一台虚拟机的/e…...
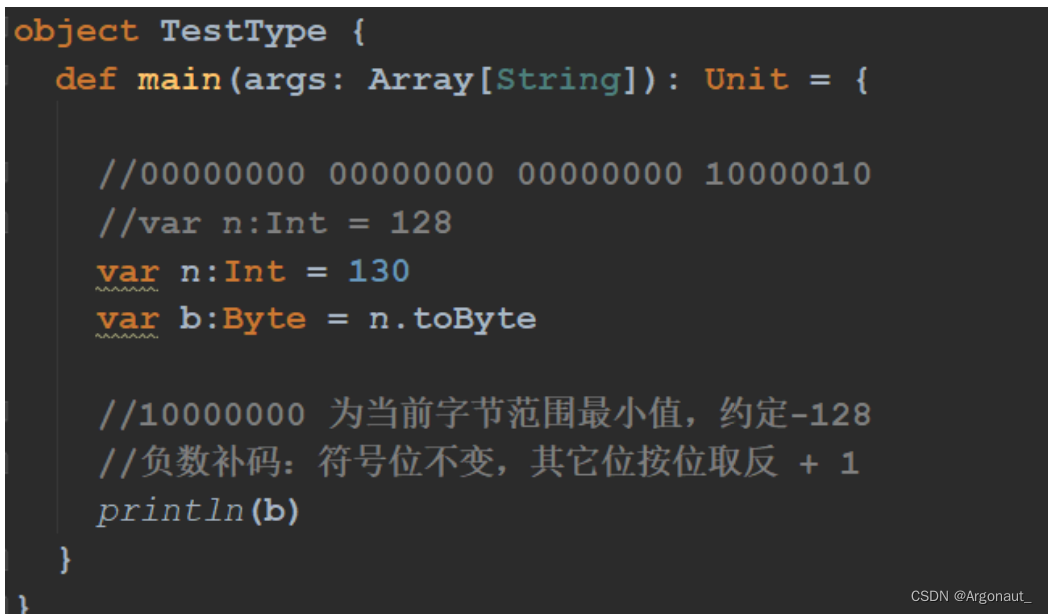
Scala 变量和数据类型(第二章)
第二章、变量和数据类型2.1 注释2.2 变量和常量(重点)2.3 标识符的命名规范2.4 字符串输出2.5 键盘输入2.6 数据类型(重点)回顾:Java数据类型Scala数据类型2.7 整数类型(Byte、Short、Int、Long)…...
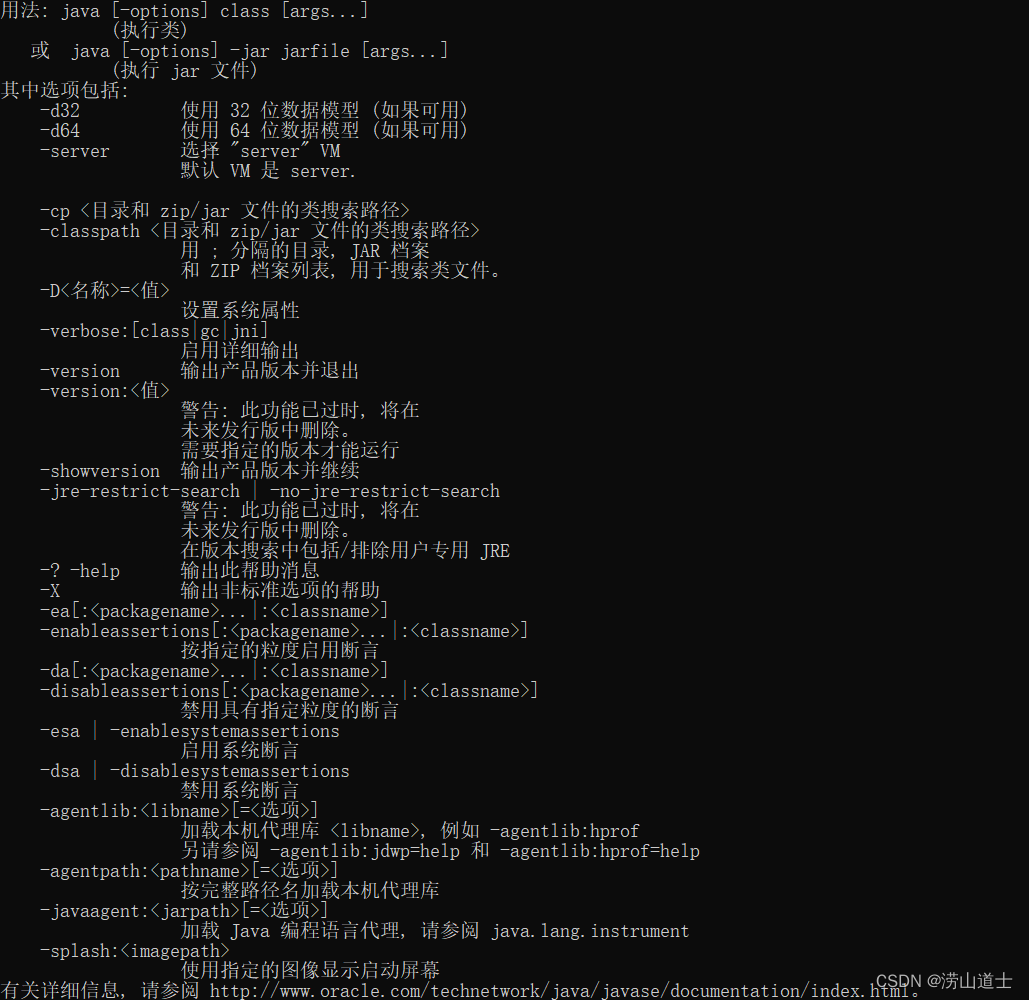
【JVM基础内容速查表】JVM基础知识 默认参数 GC命令 工具使用 JVM参数设置、说明、使用方法、注意事项等(持续更新)
目录一、JVM前置知识1. -X、-XX含义2. JVM参数值的类型和设置方式3. 查看GC时用到的命令和JVM参数4. 查看JVM默认参数二、垃圾收集器选择-XX:UseSerialGC-XX:UseParallelGC-XX:UseParallelOldGC-XX:UseParNewGC-XX:UseConcMarkSweepGC-XX:UseG1GC三、垃圾收集器特有参数1. ParN…...
)
C语言经典编程题100例(61~80)
目录61、练习7-7 矩阵运算62、练习7-8 方阵循环右移63、习题6-1 分类统计字符个数64、习题6-2 使用函数求特殊a串数列和65、习题6-4 使用函数输出指定范围内的Fibonacci数66、习题6-5 使用函数验证哥德巴赫猜想67、习题6-6 使用函数输出一个整数的逆序数68、练习8-2 计算两数的…...

toxssin:一款功能强大的XSS漏洞扫描利用和Payload生成工具
关于toxssin toxssin是一款功能强大的XSS漏洞扫描利用和Payload生成工具,这款渗透测试工具能够帮助广大研究人员自动扫描、检测和利用跨站脚本XSS漏洞。该工具由一台HTTPS服务器组成,这台服务器将充当一个解释器,用于处理恶意JavaScript Pay…...
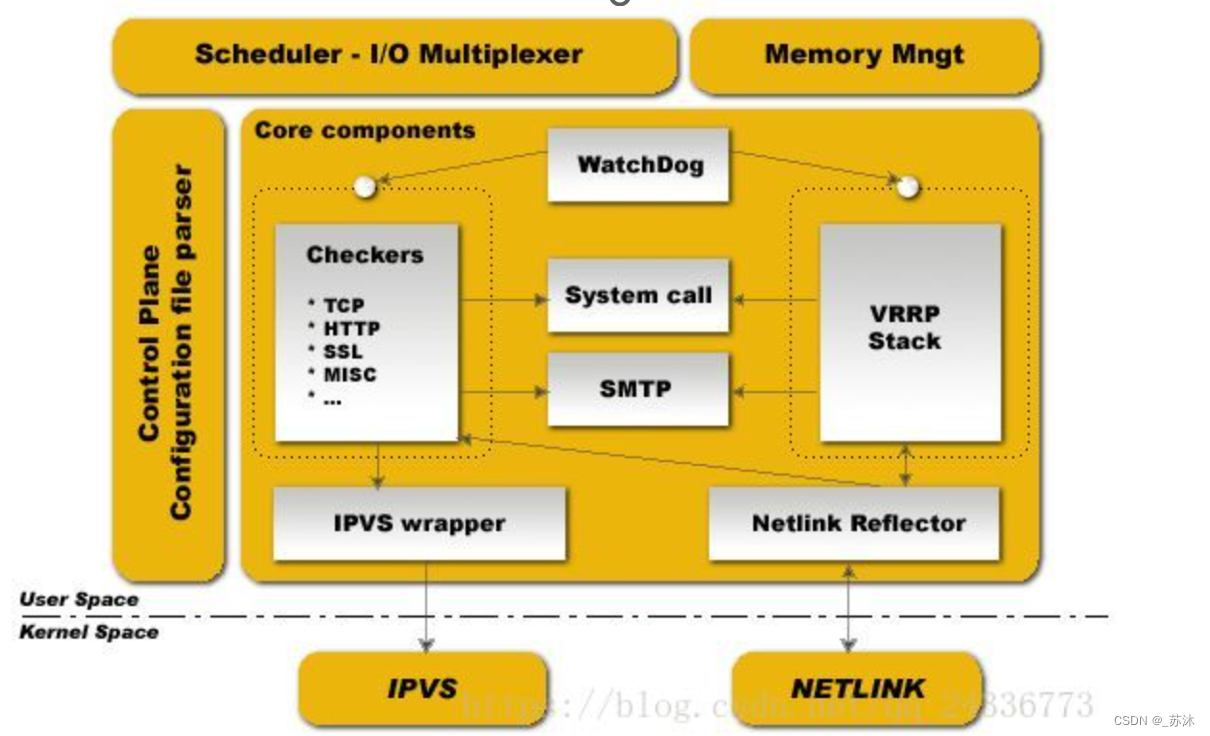
Keepalived与HaProxy的协调合作原理分析
Keepalived与HaProxy的协调合作原理分析keepalived与haproxy合作场景更好的理解方式协调合作中考虑的问题一、Keepalived以TCP/IP模型角度来分析:二、HaProxy总结:协调合作中考虑的问题的答案虚拟ip:虚拟IP技术,就是一个未分配给客…...

Stable Yogi Leather-Dress-Collection开源模型实践:SD 1.5生态LoRA工程最佳范例
Stable Yogi Leather-Dress-Collection开源模型实践:SD 1.5生态LoRA工程最佳范例 你是不是也遇到过这样的问题:想用Stable Diffusion生成特定风格的动漫角色,比如穿着酷炫皮衣的2.5D人物,但要么生成的服装不对味,要么…...

SOONet在体育赛事分析中的效果:自动定位精彩进球与犯规瞬间
SOONet在体育赛事分析中的效果:自动定位精彩进球与犯规瞬间 如果你看过体育比赛,尤其是足球、篮球这类快节奏的项目,一定有过这样的体验:一场90分钟的比赛,真正决定胜负的精彩瞬间可能就那么几分钟。赛后想重温梅西的…...

ollama-QwQ-32B模型微调实践:提升OpenClaw任务执行准确率
ollama-QwQ-32B模型微调实践:提升OpenClaw任务执行准确率 1. 为什么需要微调OpenClaw背后的模型? 去年冬天,当我第一次用OpenClaw自动整理电脑上的照片时,发现它总是把"2023年春节"和"2023春节"识别成两个不…...

QQ空间历史数据备份终极指南:使用GetQzonehistory完整保存你的青春记忆
QQ空间历史数据备份终极指南:使用GetQzonehistory完整保存你的青春记忆 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾担心QQ空间里的珍贵说说会随着时间流逝而消失…...

智能体开发必看!LLM、RAG、MCP、Skills核心解析,手把手教你搭建AI大脑!
0. 前言 最近一年我一直在做智能体相关的项目落地,从对接企业Agent需求、搭建技术架构到开发实现、给团队做基础培训等,一直和LLM、RAG、MCP、Skills这些概念打交道。 所以我结合实际经验,用最易懂的技术语言,梳理一下这些核心概念…...

HUNYUAN-MT 7B翻译效果深度评测:多领域文本翻译对比展示
HUNYUAN-MT 7B翻译效果深度评测:多领域文本翻译对比展示 最近试用了不少翻译模型,发现了一个挺有意思的现象:很多模型处理日常对话还行,但一遇到专业点的内容,翻译出来的东西就有点“词不达意”,要么术语翻…...
在GiveWin软件中的实操指南)
马尔科夫区制转移向量自回归模型(MS - VAR)在GiveWin软件中的实操指南
马尔科夫区制转移向量自回归模型,MSVAR模型,MS-VAR模型的GiveWin软件安装和操作过程MS-VAR各种图形制作(区制转换图、脉冲图、模型预测图和模型预测结果等等)最优区制数和模型形式判断(MSI-VAR、MSM-VAR模型形式的最优…...

IDEA插件Maven Helper保姆级教程:一键解决SpringBoot3项目依赖冲突与版本管理
IDEA插件Maven Helper实战指南:SpringBoot3依赖冲突排查与版本管理精要 当你正在开发一个SpringBoot3项目时,突然遇到NoSuchMethodError或ClassNotFoundException这类运行时错误,而编译阶段一切正常——这往往意味着你正面临Maven依赖冲突的经…...

glm5降智,春的没边,拼写都错
...

Pensieve代码覆盖率分析:提高项目稳定性的终极指南
Pensieve代码覆盖率分析:提高项目稳定性的终极指南 【免费下载链接】pensieve A passive recording project allows you to have complete control over your data. Automatically take screenshots of all your screens, index them, and save them locally. 项目…...