Bert+FGSM中文文本分类
我上一篇博客已经分别用Bert+FGSM和Bert+PGD实现了中文文本分类,这篇文章与我上一篇文章Bert+FGSM/PGD实现中文文本分类(Loss=0.5L1+0.5L2)_Dr.sky_的博客-CSDN博客的不同之处在于主要在对抗训练函数和embedding添加扰动部分、模型定义部分、Loss函数传到部分不一样,这篇博客的思想借鉴了我之前看的一篇文章关于对抗训练在文本分类中的实验中的实现思路,下面开始记录下来具体实验代码。
目录
一、数据集下载
二、导入所需库和模块
三、加载数据集
四、定义模型参数和优化器
五、定义模型函数
六、定义对抗训练函数
七、定义训练函数
八、定义测试函数
一、数据集下载
这个网盘中包含实验所使用数据集和配套py文件
链接: https://pan.baidu.com/s/1Vz1jt3OHOoXOdZDAyeJKrQ?pwd=x7mv 提取码: x7mv
二、导入所需库和模块
# 导入 PyTorch 库
import torch
# 导入 PyTorch 中的神经网络模块
import torch.nn as nn
# 导入 PyTorch 中的优化器模块
import torch.optim as optim
# 导入 PyTorch 中的数据集和数据加载器模块
from torch.utils.data import DataLoader, Dataset
# 导入 transformers 库中的 BertTokenizerFast 和 BertForSequenceClassification 类
from transformers import BertTokenizerFast, BertForSequenceClassification
import numpy as np三、加载数据集
这部分代码主要是将自己的数据处理为Bert的输入。
# 导入 tqdm 库
from tqdm import tqdm
# 定义一个 THUCNewsDataset 类,继承自 PyTorch 中的 Dataset 类
class THUCNewsDataset(Dataset):# 定义构造函数,接收一个文件路径作为参数def __init__(self, file_path):# 初始化 BERT tokenizerself.tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')# 定义一个列表,用于存储数据集中的每一条数据self.data = []# 打开数据集文件,逐行读取数据并处理with open(file_path, 'r', encoding='utf-8') as f:# 使用 tqdm 库显示读取进度for line in tqdm(f):# 从每一行数据中提取文本和标签,并将其存储到列表中text, label = line.strip().split('\t')self.data.append((text, int(label)))# 定义 __len__ 方法,返回数据集的大小def __len__(self):return len(self.data)# 定义 __getitem__ 方法,根据索引返回数据集中的一条数据def __getitem__(self, idx):# 从列表中获取文本和标签text, label = self.data[idx]# 使用 BERT tokenizer 对文本进行处理,将其转换为 BERT 模型的输入格式inputs = self.tokenizer(text, padding='max_length', truncation=True, max_length=32, return_tensors='pt')# 将标签转换为 PyTorch 的张量格式,并将其添加到输入中inputs['labels'] = torch.tensor(label)# 返回处理后的输入return inputs# 加载训练集、测试集和验证集
train_dataset = THUCNewsDataset('train.txt')
test_dataset = THUCNewsDataset('test.txt')
dev_dataset = THUCNewsDataset('dev.txt')# 导入 PyTorch 库中的 pad_sequence 函数,用于填充序列
from torch.nn.utils.rnn import pad_sequence# 定义一个 collate_fn 函数,用于对数据进行批处理
def collate_fn(batch):# 从批次数据中提取 input_ids、attention_mask 和 labelsinput_ids = [item['input_ids'] for item in batch]attention_mask = [item['attention_mask'] for item in batch]labels = [item['labels'] for item in batch]# 对 input_ids 和 attention_mask 进行填充操作,使它们的长度相同input_ids = pad_sequence(input_ids, batch_first=True, padding_value=0)attention_mask = pad_sequence(attention_mask, batch_first=True, padding_value=0)# 将 labels 转换为 tensor 类型labels = torch.tensor(labels)# 返回一个字典,包含处理后的 input_ids、attention_mask 和 labelsreturn {'input_ids': input_ids, 'attention_mask': attention_mask, 'labels': labels}# 创建数据加载器,用于批量加载数据
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)
dev_loader = DataLoader(dev_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)四、定义模型参数和优化器
这部分代码主要是定义相关参数。
# 创建一个交叉熵损失函数,用于计算模型的损失
criterion = nn.CrossEntropyLoss()
# 创建一个 Adam 优化器,用于更新模型参数
optimizer = optim.Adam(model.parameters(), lr=2e-5)
# 创建一个交叉熵损失函数,用于计算模型的损失
criterion = nn.CrossEntropyLoss()
from lr_scheduler import ReduceLROnPlateau
parameters = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.Adam(parameters, lr=cfg.lr)
scheduler = ReduceLROnPlateau(optimizer, mode='max', factor=0.5, patience=3, verbose=1, epsilon=1e-4, cooldown=0, min_lr=0, eps=1e-8)# 将模型移动到计算设备上(GPU 或 CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')class Config:def __init__(self):self.num_classes = 10 # 分类类别数self.hidden_size = 768self.batch_size = 32 # 批大小self.max_seq_length = 32 # 最大序列长度self.lr = 2e-5 # 学习率self.epsilon = 1e-1 # FGSM扰动的最大范围self.alpha = 1e-2 # FGSM扰动的步长cfg = Config()这行代码的含义:
scheduler = ReduceLROnPlateau(optimizer, mode='max', factor=0.5, patience=3, verbose=1, epsilon=1e-4, cooldown=0, min_lr=0, eps=1e-8)这段代码创建了一个学习率调度器,即ReduceLROnPlateau调度器。该调度器可以在训练过程中自动降低学习率,以提高模型的性能。
具体来说,该调度器接受几个参数:
- optimizer:优化器对象,即要进行学习率调整的优化器。
- mode:用于确定评估指标的最大化或最小化模式。可以是“min”、“max”或“auto”。在本例中,mode被设置为“max”,表示评估指标应该最大化。
- factor:学习率降低的因子。新的学习率将是旧学习率的factor倍。在本例中,factor被设置为0.5,表示每次调整学习率时将其减半。
- patience:如果评估指标在patience个epoch中没有提高,则降低学习率。在本例中,patience被设置为3,表示如果3个epoch内评估指标没有提高,则降低学习率。
- verbose:控制日志输出的详细程度。如果为1,则在每次学习率调整时输出一条日志。在本例中,verbose被设置为1。
- epsilon:评估指标的最小变化量。如果评估指标的变化量小于epsilon,则不会触发学习率调整。在本例中,epsilon被设置为1e-4。
- cooldown:在降低学习率后,暂停更新学习率的epoch数。在本例中,cooldown被设置为0,表示在降低学习率后立即开始新一轮调整。
- min_lr:学习率的下限。学习率将不会低于此下限。在本例中,min_lr被设置为0。
- eps:数值稳定性的精度。在本例中,eps被设置为1e-8。
当评估指标在patience个epoch中没有提高时,ReduceLROnPlateau调度器将调用optimizer.param_groups中所有参数的optimizer.step()方法,以降低学习率。
五、定义模型函数
这部分与上一篇博客不一样的地方是需要定义模型函数,因为上一篇博客用到的是Bert文本分类模型,BertForSequenceClassification是一个基于BERT模型的文本分类模型,通常用于处理文本分类任务,例如情感分析、垃圾邮件过滤等。
该模型包含了BERT模型的基本结构,同时还增加了一个分类层,用于将BERT模型的输出映射到类别标签上。在具体实现中,BertForSequenceClassification继承自BertPreTrainedModel,它重载了其中的__init__方法和forward方法。
在__init__方法中,BertForSequenceClassification首先调用父类的__init__方法来初始化BERT模型的各个组件,然后添加了一个用于分类的线性层。该线性层的输入是BERT模型的输出,输出是类别标签的概率分布。具体来说,该线性层的输入维度为hidden_size,输出维度为num_labels,其中hidden_size是BERT模型的隐藏层大小,num_labels是类别标签的数量。
在forward方法中,BertForSequenceClassification首先调用父类的forward方法来获取BERT模型的输出,然后将其输入到分类层中,得到类别标签的概率分布。在具体实现中,BertForSequenceClassification还支持在模型训练时进行dropout和权重衰减等操作,以提高模型的泛化能力和鲁棒性。
from transformers import BertTokenizerFast, BertForSequenceClassification, BertModelclass BertModelWithAdversarialTraining(nn.Module):def __init__(self, cfg):super(BertModelWithAdversarialTraining, self).__init__()self.bert = BertModel.from_pretrained('bert-base-chinese')self.dropout = nn.Dropout(0.5)for param in self.bert.parameters():param.requires_grad = Trueself.fc = nn.Linear(cfg.hidden_size, cfg.num_classes)def forward(self, inputs_ids, attack=None, is_training=True):outputs = self.bert(inputs_ids)embs = outputs[0]if attack is not None:embs = embs + attack #加入干扰信息embs = embs[:, 0, :] #取第一个位置的输出作为句子的向量表示if is_training:embs = self.dropout(embs)out = self.fc(embs)return outmodel = BertModelWithAdversarialTraining(cfg)
model.to(device)
六、定义对抗训练函数
from transformers import BertTokenizerFast, BertForSequenceClassification, BertModelclass BertModelWithAdversarialTraining(nn.Module):def __init__(self, cfg):super(BertModelWithAdversarialTraining, self).__init__()self.bert = BertModel.from_pretrained('bert-base-chinese')self.dropout = nn.Dropout(0.5)for param in self.bert.parameters():param.requires_grad = Trueself.fc = nn.Linear(cfg.hidden_size, cfg.num_classes)def forward(self, inputs_ids, attack=None, is_training=True):outputs = self.bert(inputs_ids)embs = outputs[0]if attack is not None:embs = embs + attack #加入干扰信息embs = embs[:, 0, :] #取第一个位置的输出作为句子的向量表示if is_training:embs = self.dropout(embs)out = self.fc(embs)return outmodel = BertModelWithAdversarialTraining(cfg)
model.to(device)六、定义张量截断函数
这段代码实现了一个张量的截断操作,即将张量X中的元素限制在一个上下限范围内,返回截断后的张量。
具体来说,该函数接受三个参数:张量X、下限lower_limit和上限upper_limit。它首先使用X.clone().detach()复制构造一个新的张量,这样可以确保该函数不会修改原始张量X。然后,它使用torch.tensor()将下限和上限转换为张量,并使用X.device将它们分配给与X相同的设备。接下来,它使用torch.max()和torch.min()函数将张量X中的元素限制在下限和上限之间,并返回截断后的张量。
需要注意的是,该函数中使用了clone().detach()方法来复制构造一个新的张量,这是为了避免在函数中修改原始张量X。同时,该函数中使用了X.device来将下限和上限张量分配给与X相同的设备,这是为了保证在不同设备上运行时代码的兼容性。
def clamp(X, lower_limit, upper_limit):X = X.clone().detach() # 复制构造一个新的张量lower_limit = torch.tensor(lower_limit, device=X.device).clone().detach() # 复制构造一个新的张量,并将其分配给与X相同的设备upper_limit = torch.tensor(upper_limit, device=X.device).clone().detach() # 复制构造一个新的张量,并将其分配给与X相同的设备return torch.max(torch.min(X, upper_limit), lower_limit)七、定义训练函数
import time
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=cfg.lr)best_acc = 0
start_train_time = time.time()
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
delta = nn.Parameter(torch.zeros(cfg.batch_size, cfg.max_seq_length, cfg.hidden_size).to(device), requires_grad=True)
delta.requires_grad = True
def train(model, optimizer, criterion, train_loader, device, epsilon, alpha):model.train() # 将模型设置为训练模式train_loss = 0 # 初始化训练损失为0train_acc = 0 # 初始化训练准确率为0for batch in train_loader: # 遍历训练数据集input_ids = batch['input_ids'].squeeze(1).to(device) # 将输入数据移动到计算设备上attention_mask = batch['attention_mask'].squeeze(1).to(device) # 将输入数据移动到计算设备上labels = batch['labels'].to(device) # 将标签移动到计算设备上delta.data.uniform_(-epsilon, epsilon)delta.data = clamp(delta, -epsilon, epsilon)outputs = model(input_ids, attack=delta, is_training=True)loss = criterion(outputs, labels)loss.backward()optimizer.step()grad = delta.grad.detach()delta.data = delta + alpha * torch.sign(grad)delta.data = clamp(delta, -epsilon, epsilon)delta.grad.zero_()outputs = model(input_ids, attack=delta, is_training=True)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()preds = torch.argmax(outputs, dim=1) # 计算预测结果train_loss += loss.item() # 累加损失train_acc += torch.sum(preds == labels).item() # 计算准确率train_loss /= len(train_loader) # 计算平均损失train_acc /= len(train_loader.dataset) # 计算平均准确率return train_loss, train_acc # 返回训练损失和准确率def evaluate(model, criterion, test_loader, device):"""测试函数,仅进行前向传播,不生成对抗样本:param model: 模型:param criterion: 损失函数:param test_loader: 测试数据集的数据加载器:param device: 计算设备:return: 测试损失和准确率"""model.eval() # 设置模型为评估模式test_loss = 0test_acc = 0with torch.no_grad(): # 关闭梯度计算for batch in test_loader:input_ids = batch['input_ids'].squeeze(1).to(device) # 将输入数据移动到计算设备上attention_mask = batch['attention_mask'].squeeze(1).to(device)labels = batch['labels'].to(device)outputs = model(input_ids) # 模型前向传播loss = criterion(outputs, labels) # 计算损失test_loss += loss.item() # 加损失preds = torch.argmax(outputs, dim=1) # 计算预测结果test_acc += torch.sum(preds == labels).item() #计算准确率test_loss /= len(test_loader) # 计算平均损失test_acc /= len(test_loader.dataset) # 计算平均准确率return test_loss, test_acc八、定义测试函数
# 将模型移动到计算设备上(GPU 或 CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
best_acc = 0 # 初始化最佳准确率为0
for epoch in range(10): # 进行10轮训练train_loss, train_acc = train(model, optimizer, criterion, train_loader, device, epsilon=0.1, alpha=0.04) # 训练模型,并获取训练损失和准确率test_loss, test_acc = evaluate(model, criterion, test_loader, device) # 对测试集进行测试,并获取测试损失和准确率dev_loss, dev_acc = evaluate(model, criterion, dev_loader, device) # 对验证集进行测试,并获取验证损失和准确率print(f'Epoch {epoch+1}, Train Loss {train_loss:.4f}, Train Acc {train_acc:.4f}, Test Loss {test_loss:.4f}, Test Acc {test_acc:.4f}, Dev Loss {dev_loss:.4f}, Dev Acc {dev_acc:.4f}')# 打印训练轮数、训练损失和准确率、测试损失和准确率、验证损失和准确率if dev_acc > best_acc: # 如果当前验证准确率大于最佳准确率best_acc = dev_acc # 更新最佳准确率torch.save(model.state_dict(), 'adv_best_model.pt') # 保存模型参数到文件'best_model.pt'
通过本次实验,参照关于对抗训练在文本分类中的实验得到以下几点结论与想法:(1)对抗训练技术方法确实有助于提高文本分类任务的效果;(2)FGSM 方法虽然提高训练效率,但并不影响推理速度,而且 NLP 领域 任务都不用很大的轮数,所以 PGD 方法更合适些;(3)三种方法涉及 delta、alpha 超参数 的初始化设定,面临不同的任务,会有变动,变相增加设定合适超参数的难度;(4)在文本分类中,觉得用 bert 方式初始化向量来进行干扰样本生成,应会比随机初始化 embedding 方式更合适,而且可根据高频率词的分布来初始化 delta、alpha 参数会显 得更合理;(5)若在本论文提出的改进版 FGSM 基础上,考虑如何更稳定或自动化的方式初始化 delta 等参数,也是一个值得优化的方向。
相关文章:
Bert+FGSM中文文本分类
我上一篇博客已经分别用BertFGSM和BertPGD实现了中文文本分类,这篇文章与我上一篇文章BertFGSM/PGD实现中文文本分类(Loss0.5L10.5L2)_Dr.sky_的博客-CSDN博客的不同之处在于主要在对抗训练函数和embedding添加扰动部分、模型定义部分、Loss函数传到部分…...
)
爬楼梯问题-从暴力递归到动态规划(java)
爬楼梯,每次只能爬一阶或者两阶,计算有多少种爬楼的情况 爬楼梯--题目描述暴力递归递归缓存动态规划暴力递归到动态规划专题 爬楼梯–题目描述 一个总共N 阶的楼梯(N > 0) 每次只能上一阶或者两阶。问总共有多少种爬楼方式。 示…...

浏览器如何验证SSL证书?
浏览器如何验证SSL证书?当前SSL证书应用越来越广泛,我们看见的HTTPS网站也越来越多。点击HTTPS链接签名的绿色小锁,我们可以看见SSL证书的详细信息。那么浏览器是如何验证SSL证书的呢? 浏览器如何验证SSL证书? 在浏览器的菜单中…...
】:: ll 指令 :: 查看指定目录下的文件详细信息)
Linux :: 【基础指令篇 :: 文件及目录操作:(10)】:: ll 指令 :: 查看指定目录下的文件详细信息
前言:本篇是 Linux 基本操作篇章的内容! 笔者使用的环境是基于腾讯云服务器:CentOS 7.6 64bit。 学习集: C 入门到入土!!!学习合集Linux 从命令到网络再到内核!学习合集 目录索引&am…...

Java字符集/编码集
1 字符集/编码集 基础知识 计算机中储存的信息都是用二进制数表示的;我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果 按照某种规则, 将字符存储到计算机中,称为编码。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码。这里强调一下: 按照…...
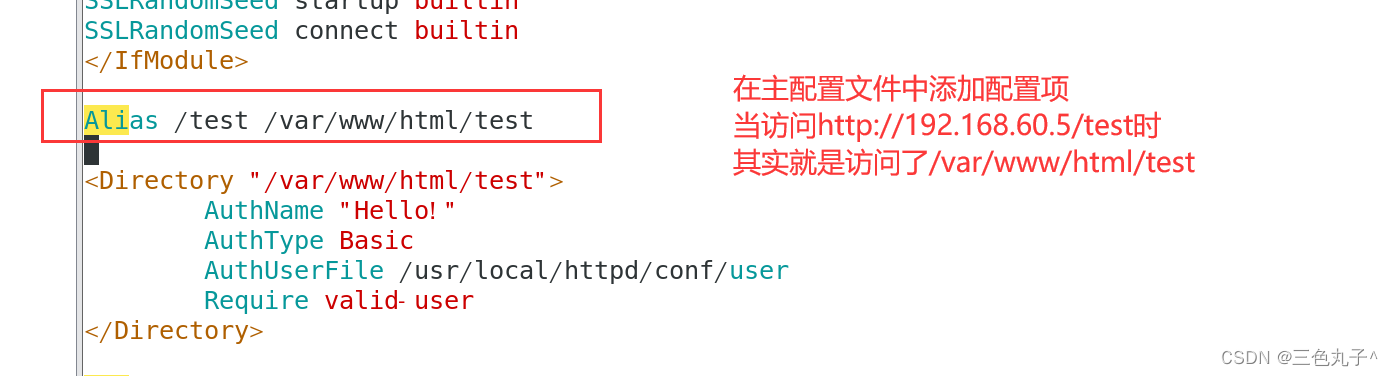
Apache配置与应用
目录 虚拟web主机httpd服务支持的虚拟主机类型基于域名配置方法基于IP配置方法基于端口配置方法 apache连接保持构建Web虚拟目录与用户授权限制Apache日志分割 虚拟web主机 虚拟Web主机指的是在同一台服务器中运行多个Web站点,其中每一个站点实际上并不独立占用整个…...
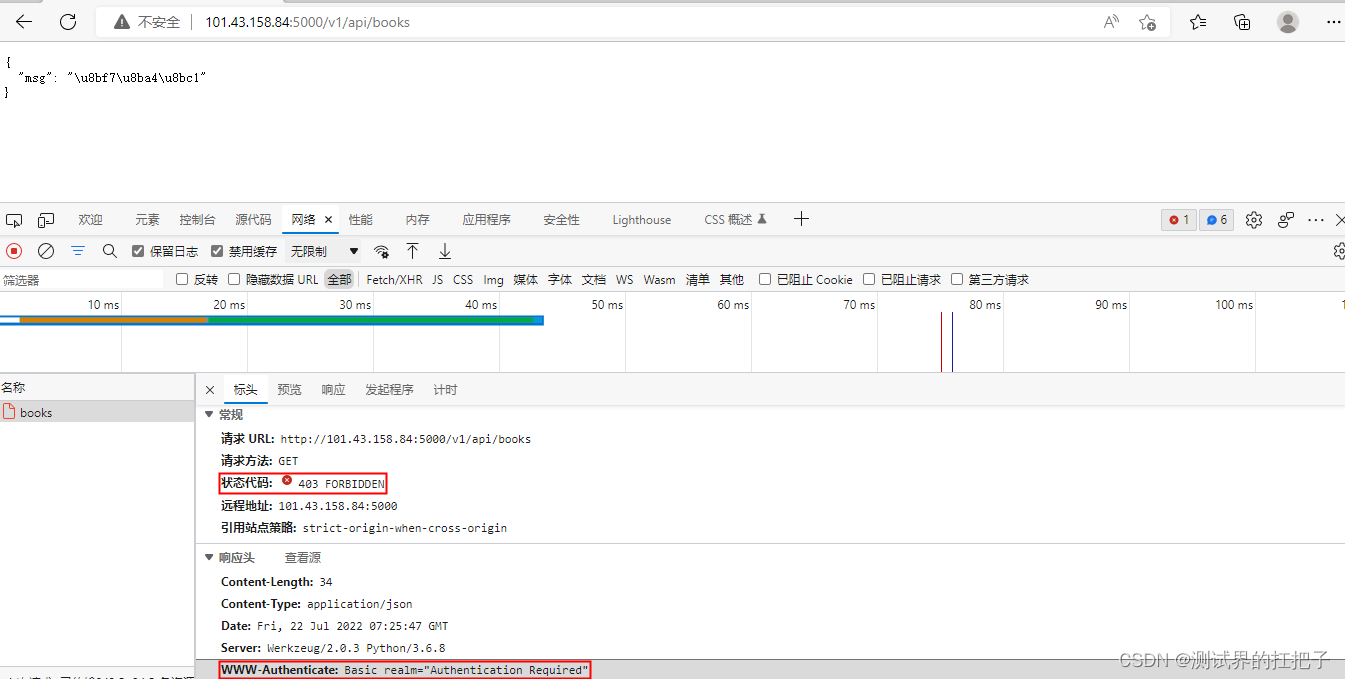
API自动化测试【postman生成报告】
PostMan生成测试报告有两种: 1、控制台的模式 2、HTML的测试报告 使用到一个工具newman Node.js是前端的一个组件,主要可以使用它来开发异步的程序。 一、控制台的模式 1、安装node.js 双击node.js进行安装,安装成功后在控制台输入node …...

探索OpenAI插件:ChatWithGit,memecreator,boolio
引言 在当今的技术世界中,插件扮演着至关重要的角色,它们提供了一种简单有效的方式来扩展和增强现有的软件功能。在本文中,我们将探索三个OpenAI的插件:ChatWithGit,memecreator,和boolio,它们…...

linux irq
中断上下部 软中断、tasklet、工作对列 软中断优点:运行在软中断上下文,优先级比普通进程高,调度速度快。 缺点:由于处于中断上下文,所以不能睡眠。 相对于软中断/tasklet,工作对列运行在进程上下文 h…...
使用详解)
串口流控(CTS/RTS)使用详解
1.流控概念 在两个设备正常通信时,由于处理速度不同,就存在这样一个问题,有的快,有的慢,在某些情况下,就可能导致丢失数据的情况。 如台式机与单片机之间的通讯,接收端数据缓冲区已满࿰…...

kube-proxy模式详解
1 kube-proxy概述 kubernetes里kube-proxy支持三种模式,在v1.8之前我们使用的是iptables 以及 userspace两种模式,在kubernetes 1.8之后引入了ipvs模式,并且在v1.11中正式使用,其中iptables和ipvs都是内核态也就是基于netfilter&…...
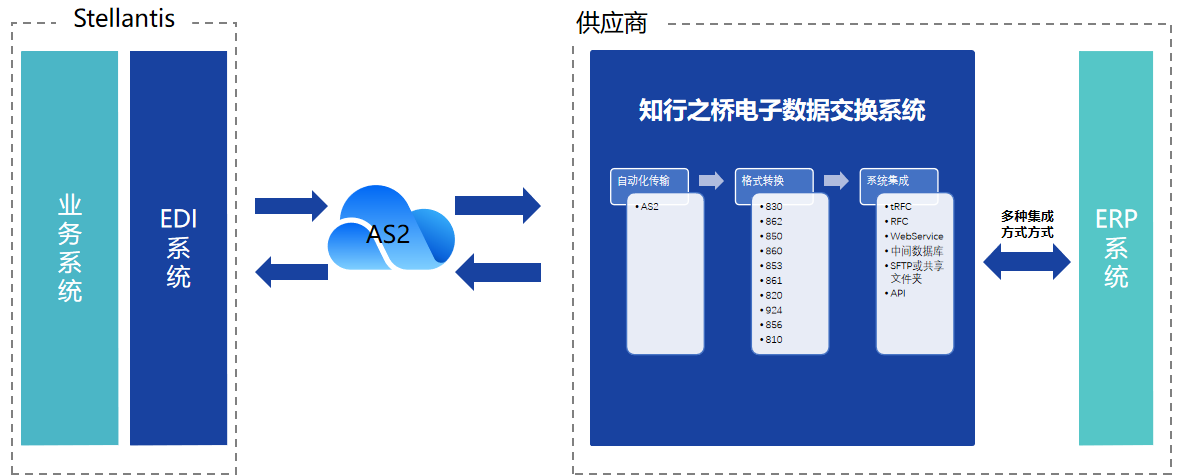
汽车EDI:如何与Stellantis建立EDI连接?
Stellantis 是一家实力雄厚的汽车制造公司,由法国标致雪铁龙集团(PSA集团)和意大利菲亚特克莱斯勒汽车集团(FCA集团)合并而成,是世界上第四大汽车制造商,拥有包括标致、雪铁龙、菲亚特、克莱斯勒…...

【SCI征稿】1区计算机科学类SCI, 自引率低,对国人友好~
一、【期刊简介】 JCR1区计算机科学类SCI&EI 【期刊概况】IF: 7.0-8.0,JCR1区,中科院2区; 【终审周期】走期刊系统,3-5个月左右录用; 【检索情况】SCI&EI双检; 【自引率】1.30% 【征稿领域】发表人工智能…...

Vue.js优化策略与性能调优指南
导语:Vue.js是一款出色的前端框架,但在处理大规模应用或复杂场景时,性能问题可能会出现。本文将介绍一些Vue.js优化策略和性能调优指南,帮助您提升应用的性能和用户体验。 延迟加载:将应用的代码进行按需加载ÿ…...
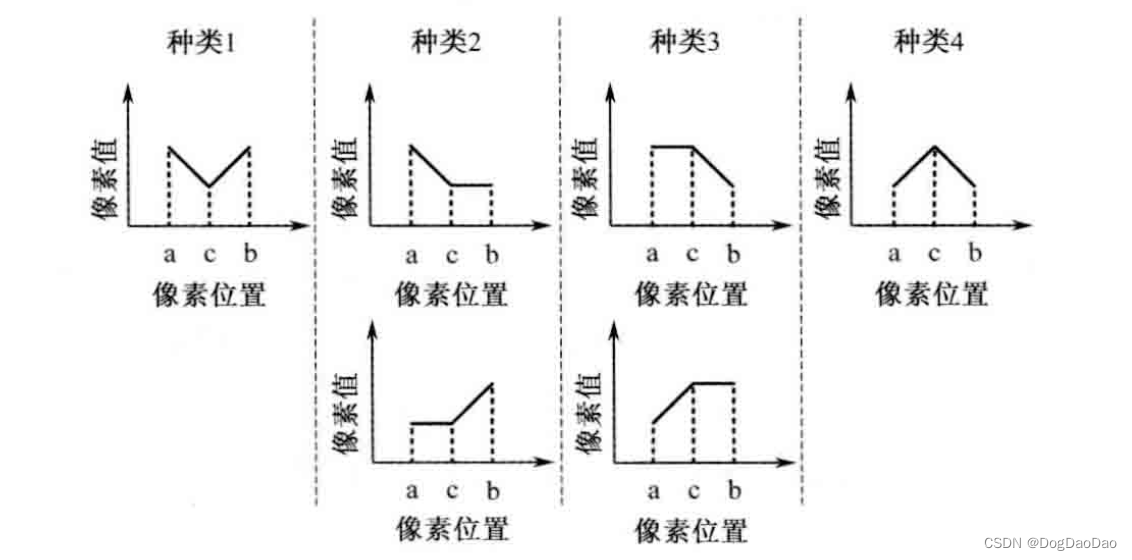
HEVC环路后处理核心介绍
介绍 为什么需要环路后处理技术 hevc采用基于快的混合编码框架,方块效应、振铃效应、颜色偏差、图像模糊等失真效应依旧存在,为了降低此类失真影响,需要进行环路滤波技术; 采用的技术 去方块滤波DF,为了降低块效应…...
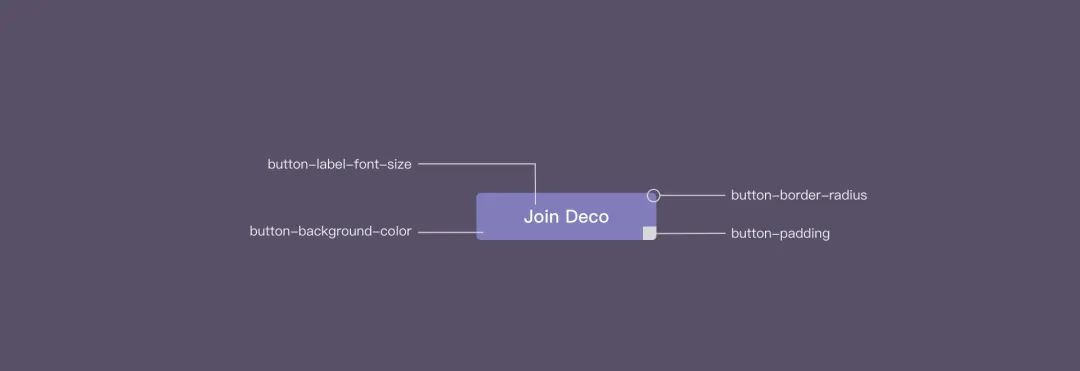
从组件化角度聊聊设计工程化
目录 设计系统 设计系统的定义 设计系统的优势 设计系统存在的问题 设计工程化 设计系统探索 设计系统落地实践 Design Token Design Token 实践 设计工程化理想方案构想 展望 参考文献 近几年围绕业务中台化的场景,涌现出了许多低代码平台。面对多组件…...

apache的配置和应用
文章目录 一、httpd服务支持的虚拟主机类型包括以下三种:二、构建Web虚拟目录与用户授权限制三、日志分割 虚拟Web主机指的是在同一台服务器中运行多个Web站点,其中每一个站点实际上并不独立占用整个服务器,因此被称为“虚拟”Web 主机。通过虚拟 Web 主…...
Buf 教程 - 使用 Protobuf 生成 Golang 代码和 Typescript 类型定义
简介 Buf 是一款更高效、开发者友好的 Protobuf API 管理工具,不仅支持代码生成,还支持插件和 Protobuf 格式化。 我们可以使用 Buf 替代原本基于 Protoc 的代码生成流程,一方面可以统一管理团队 Protoc 插件的版本、代码生成配置ÿ…...
)
Java 锁 面试题(ReentrantLock、synchronized)
Java 锁 面试题(ReentrantLock、synchronized) 1. 锁2. ReentrantLock2.1 ReentrantLock 的实现原理2.2 AQS 是什么?2.3 CAS 是什么? 3. synchronized3.1 synchronized 的实现原理3.2 synchronized 的锁升级过程3.2.1 无锁3.2.2 偏…...

Python中的缩进是什么意思?
在Python中,缩进是指在代码中使用空格或制表符来表示代码块的层次结构。Python使用缩进作为语法的一部分,以定义代码的逻辑结构和代码块的范围。缩进在Python中具有以下几个重要的方面和含义。 代码块的开始和结束: 缩进在Python中用于标识代…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...

【堆垛策略】设计方法
堆垛策略的设计是积木堆叠系统的核心,直接影响堆叠的稳定性、效率和容错能力。以下是分层次的堆垛策略设计方法,涵盖基础规则、优化算法和容错机制: 1. 基础堆垛规则 (1) 物理稳定性优先 重心原则: 大尺寸/重量积木在下…...