【C++】unordered_set 和 unordered_map 使用 | 封装
文章目录
- 1. 使用
- 1. unordered_set的使用
- 2. unordered_map的使用
- 2. 封装
- 修改结构定义
- 针对insert参数 data的两种情况
- 复用 哈希桶的insert
- KeyOfT模板参数的作用
- 迭代器
- operator++()
- begin
- end
- unordered_set对于 begin和end的复用
- unordered_map对于 begin和end的复用
- unordered_map中operator[]的实现
- unordered_set修改迭代器数据 问题
- 完整代码
- HashTable.h
- unordered_set.h
- unordered_map.h
1. 使用
unordered_map官方文档
unordered_set 官方文档
set / map与unordered_set / unordered_map 使用功能基本相同,但是两者的底层结构不同
set/map底层是红黑树
unordered_map/unordered_set 底层是 哈希表
红黑树是一种搜索二叉树,搜索二叉树又称为排序二叉树,所以迭代器遍历是有序的
而哈希表对应的迭代器遍历是无序的

在map中存在rbegin以及rend的反向迭代器

在unordered_map中不存在rbegin以及rend的反向迭代器
1. unordered_set的使用
大部分功能与set基本相同,要注意的是使用unordered_set是无序的

插入数据,并使用迭代器打印,会按照插入的顺序输出,但若插入的数据已经存在,则会插入失败
2. unordered_map的使用
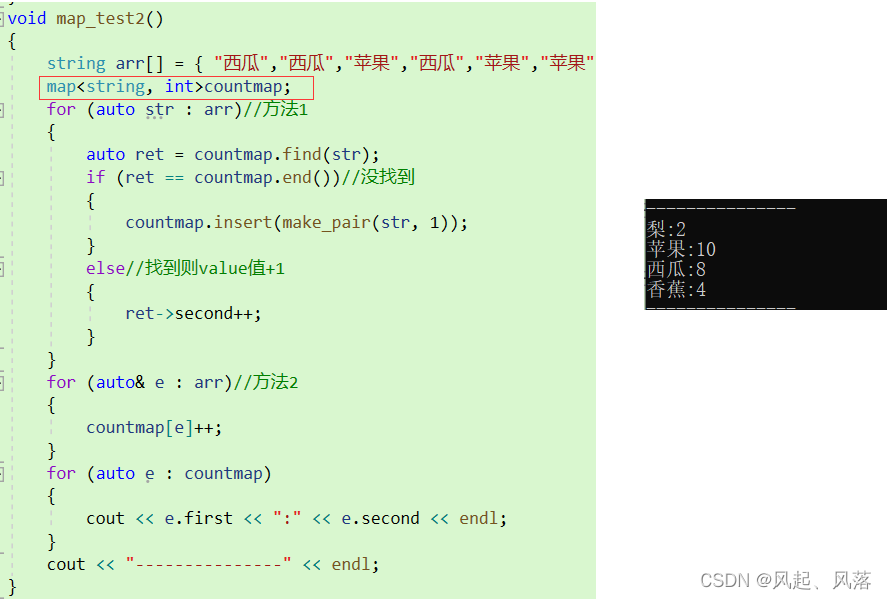
map统计时,会按照ASCII值排序

而unordered_map 中 元素是无序的
2. 封装
对于 unordered_set 和 unordered_map 的封装 是针对于 哈希桶HashBucket进行的,
即 在哈希开散列 的基础上修改
点击查看:哈希 开散列具体实现
修改结构定义
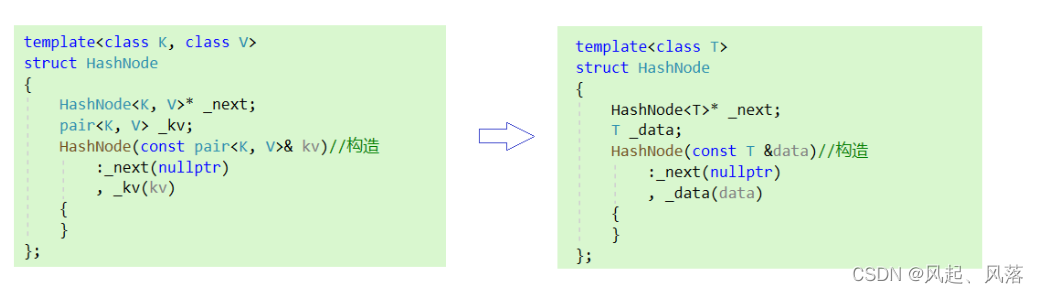
哈希桶HashBucket中
需要将其内部的HashNode 的参数进行修改
将原来的模板参数 K,V 改为 T
同样由于不知道传入数据的是K还是K V类型的 ,所以 使用 T 类型的data代替

之前实现的模板参数 K ,V分别代表 key 与value
修改后 , 第一个参数 拿到单独的K类型,是为了 使用 Find erase接口函数的参数为K
第二个参数 T 决定了 拿到的是K类型 还是 K V 类型
针对insert参数 data的两种情况

创建 unordered_set.h头文件,在其中创建命名空间unordered_set
在unordered_set中实现一个仿函数,
unordered_set 的第二个参数 为 K
unordered_set作为 K 模型 ,所以 T应传入K

创建 unordered_map.h头文件,在其中创建命名空间unordered_map
unordered_map 的第二个参数 为 pair<cosnt K,V> 类型
K加入const ,是为了防止修改key
unordered_map 作为 KV 模型 ,所以 T应传入 pair<K,V>
复用 哈希桶的insert

在unordered_set中insert 是 复用HashTable中的insert
但实际上直接运行就会出现一大堆错误,哈希桶的insert 原本参数从kv变为 data,
由于data的类型为T,也就不知道 到底是unoreder_set 的K还是 unoreder_map 的KV类型的K
所以 insert中的 hashi的 key 不能够直接求出
KeyOfT模板参数的作用

假设为unordered_set,则使用kot对象调用operator(),返回的是key

假设为unordered_map,则使用kot对象调用operator(),返回的是KV模型中的key
迭代器
在迭代器内存存储 节点的指针 以及 哈希表
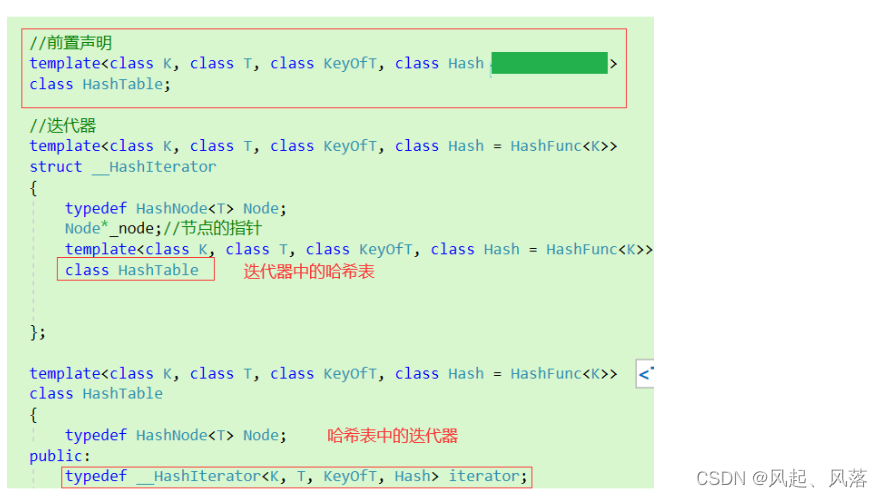
在迭代器中使用哈希表,在哈希表中使用迭代器 ,存在互相引用,需要使用前置声明

对于 operator * / operator-> / operator!= 跟 list 模拟实现基本类似
详细点击查看:list模拟实现
在自己实现的迭代器__HashIterator中,添加参数 Ref 和 Ptr

当为普通迭代器时,Ref作为T& ,Ptr作为T*
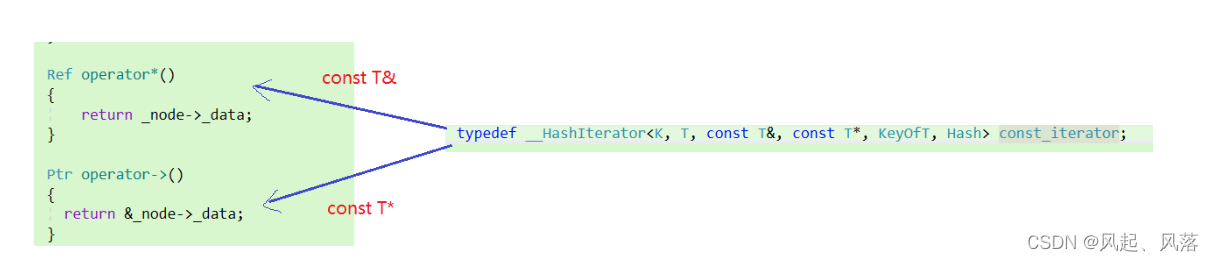
当为const 迭代器时,Ref作为const T& ,Ptr作为const T*
operator++()

调用 hash调用对应的仿函数HashFunc,若为普通类型(int)则输出对应key
若为 string类型,则调用特化,输出对应的各个字符累加的ASCII值
调用 KeyOfT ,主要区分unordered_map 与unordered_set ,
若为unordered_set ,则输出 K类型的K
若为unordered_map ,则输出 KV类型的K
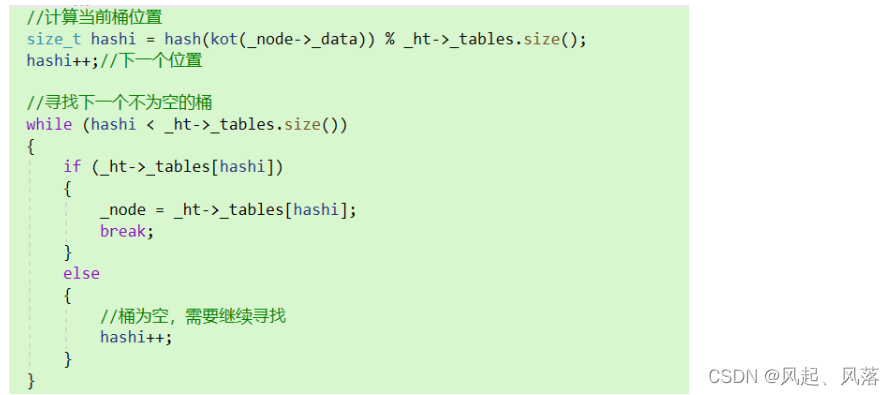
hashi++,计算下一个桶的位置,判断是否为空,若不为空则将其作为_node
若为空,需要继续寻找不为空的桶

begin

在HashTable内部实现 begin,使用自己实现的_hashiterator 作为迭代器
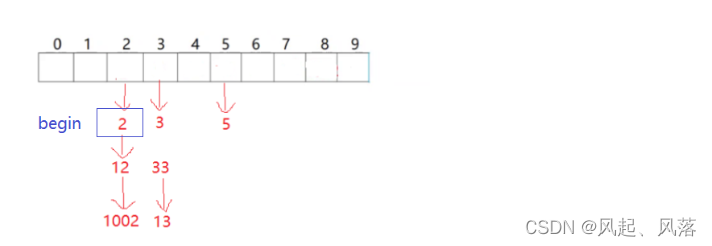
返回第一个不为空的桶的第一个数据
c
end
在HashTable内部实现 end
返回最后一个桶的下一个位置 即nullptr

unordered_set对于 begin和end的复用
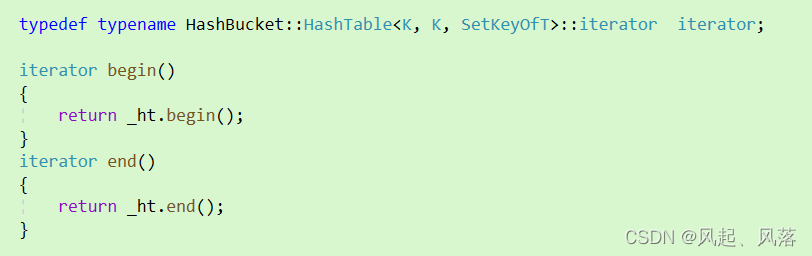
在unordered_set中,使用哈希桶中的HashTable的迭代器 来实现unordered_set的迭代器
加入typename 是因为编译器无法识别HashBucket::HashTable<K, K, SetKeyOfT>是静态变量还是类型
_ht作为哈希表,使其调用哈希表中的begin和end 来实现 unordered_set的begin 和end
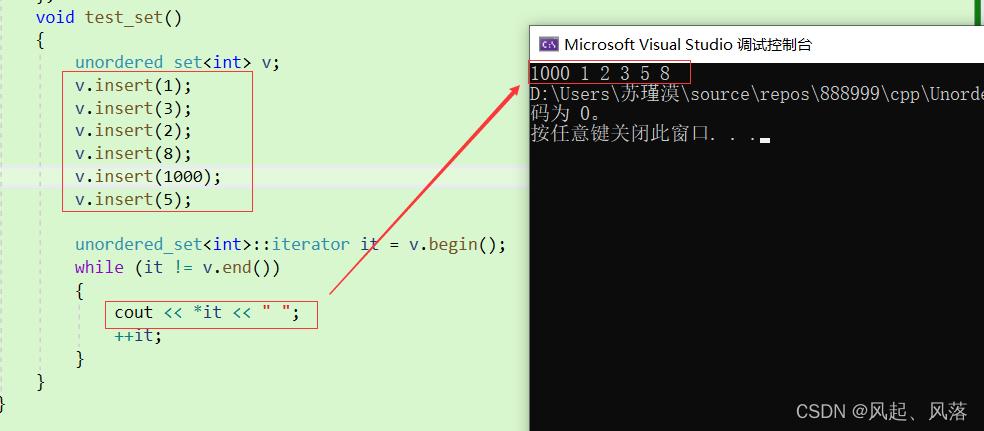
unordered_map对于 begin和end的复用
在 unordered_map中使用哈希桶中的HashTable的迭代器 来实现unordered_map的迭代器

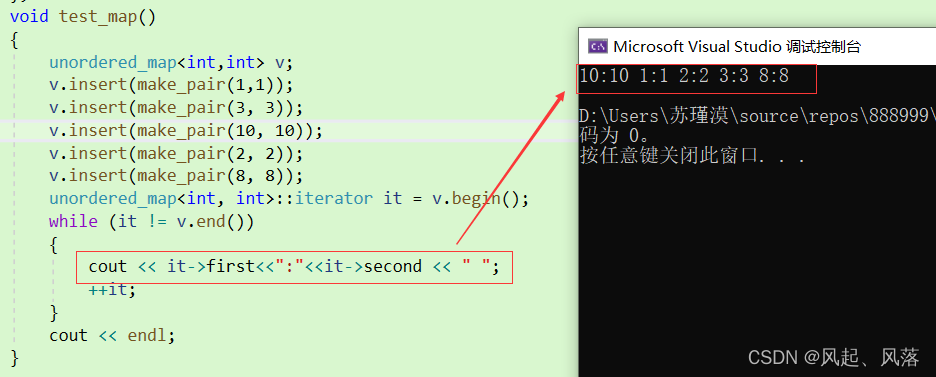
unordered_map中operator[]的实现

将insert的返回值 变为pair类型,第一个参数为迭代器 ,第二个参数为布尔值
若返回成功,则调用新插入位置的迭代器

通过寻找哈希桶中是否有相同的数据,若有则返回该迭代器以及false
在unordered_map中实现operator[]

详细查看:operaor[]本质理解
unordered_set修改迭代器数据 问题

在unordered_set中,借助 哈希桶中的普通迭代器 实现 unordered_set的普通迭代器
在unordered_set中,借助 哈希桶中的const迭代器 实现 unordered_set的const迭代器
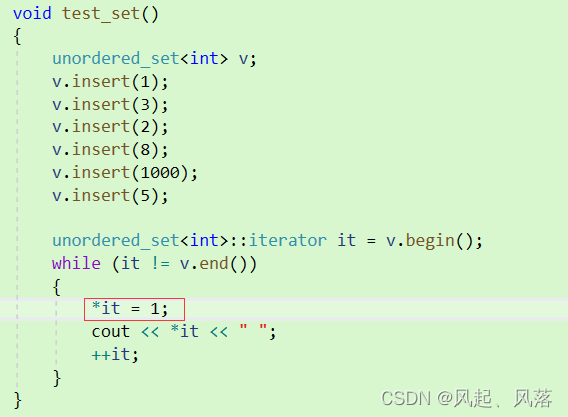
在STL中,是不允许 unordered_set去 *it 修改数据的 ,但是在自己实现的迭代器中却可以通过

在STL中将 unordered_set的普通迭代器也为哈希桶的const 迭代器

调用begin时,虽然看似返回普通迭代器,但是当前普通迭代器是作为哈希桶的const迭代器存在的
而返回值依旧是 哈希桶的普通迭代器
在哈希桶自己实现的迭代器__HashIterator中

创建一个普通迭代器 ,当传入普通迭代器时,为拷贝构造
当传入 const 迭代器时,就 发生隐式类型转换,讲普通迭代器转换为const 迭代器

此时在unordered_set中 的普通迭代器无法被修改
完整代码
HashTable.h
#include<iostream>
#include<vector>
using namespace std;template<class K>
struct HashFunc //仿函数
{size_t operator()(const K& key){return key;}
};//特化
template<>
struct HashFunc<string> //仿函数
{//将字符串转化为整形size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash += ch;hash *= 31;//用上次的结果乘以31}return hash;}
};namespace HashBucket //哈希桶
{template<class T>struct HashNode{HashNode<T>* _next;T _data;HashNode(const T& data):_next(nullptr), _data(data){}};//前置声明template<class K, class T, class KeyOfT, class Hash>class HashTable;//迭代器template<class K, class T, class Ref,class Ptr,class KeyOfT, class Hash >struct __HashIterator{typedef HashNode<T> Node;Node* _node;//节点的指针typedef HashTable<K, T, KeyOfT, Hash> HT; //哈希表 typedef HTHT* _ht; //哈希表typedef __HashIterator<K, T, Ref,Ptr,KeyOfT, Hash> Self; //定义一个普通迭代器typedef __HashIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;__HashIterator(Node* node, HT* ht):_node(node),_ht(ht){}__HashIterator(const Iterator &it):_node(it._node),_ht(it._ht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const Self &s){//使用节点的指针进行比较return _node != s._node;}//前置++Self& operator++(){//若不处于当前桶的尾位置,则寻找桶的下一个位置if (_node->_next != nullptr){_node = _node->_next;}else{//若为空,则说明处于当前桶的尾位置,则需寻找下一个不为空的桶KeyOfT kot;Hash hash;//计算当前桶位置size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size();hashi++;//下一个位置//寻找下一个不为空的桶while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi]){_node = _ht->_tables[hashi];break;}else{//桶为空,需要继续寻找hashi++;}}//没有找到不为空的桶if (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;}};template<class K, class T, class KeyOfT, class Hash>class HashTable{template<class K, class T,class Ref,class Ptr, class KeyOfT, class Hash >friend struct __HashIterator;//友元 使 __HashIterator中可以调用HashTable的私有typedef HashNode<T> Node;public:typedef __HashIterator<K, T,T&,T*, KeyOfT, Hash> iterator;typedef __HashIterator<K, T, const T&, const T*, KeyOfT, Hash> const_iterator;iterator begin(){Node* cur = nullptr;size_t i = 0;//找到第一个不为空的桶for (i = 0; i < _tables.size(); i++){cur = _tables[i];if (cur){break;}}//迭代器返回 第一个桶 和哈希表//this 作为哈希表本身return iterator(cur,this);}iterator end(){return iterator(nullptr, this);}const_iterator begin()const{Node* cur = nullptr;size_t i = 0;//找到第一个不为空的桶for (i = 0; i < _tables.size(); i++){cur = _tables[i];if (cur){break;}}//迭代器返回 第一个桶 和哈希表//this 作为哈希表本身return const_iterator(cur, this);} const_iterator end() const{return const_iterator(nullptr, this);}~HashTable()//析构{for (auto& cur : _tables){while (cur){Node* next = cur->_next;delete cur;cur = next;}cur = nullptr;}}iterator Find(const K& key)//查找{Hash hash;KeyOfT kot;//若表刚开始为空if (_tables.size() == 0){return end();}size_t hashi = hash(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){return iterator(cur,this);}cur = cur->_next;}return end();}bool Erase(const K& key)//删除{Hash hash;KeyOfT kot;size_t hashi = hash(key) % _tables.size();Node* prev = nullptr;//用于记录前一个节点Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){if (prev == nullptr)//要删除节点为头节点时{_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}else{prev = cur;cur = cur->_next;}}return false;}pair<iterator,bool> insert(const T& data )//插入{KeyOfT kot;//若对应的数据已经存在,则插入失败iterator it = Find(kot(data));if (it != end()){return make_pair(it, false);}Hash hash;//负载因子==1时扩容if (_n == _tables.size()){size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;vector<Node*>newtables(newsize, nullptr);//创建 newsize个数据,每个数据都为空for (auto& cur : _tables){while (cur){Node* next = cur->_next;//保存下一个旧表节点size_t hashi = hash(kot(cur->_data)) % newtables.size();//将旧表节点头插到新表节点中cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}}_tables.swap(newtables);}size_t hashi = hash(kot(data)) % _tables.size();//头插Node* newnode = new Node(data);//新建节点newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return make_pair(iterator(newnode,this), true);}private:vector<Node*> _tables; //指针数组size_t _n=0;//存储数据有效个数};
}unordered_set.h
#include"HashTable.h"
namespace yzq
{template<class K,class Hash=HashFunc<K>>class unordered_set{public:struct SetKeyOfT//仿函数{const K& operator()(const K&key){return key;}};public:typedef typename HashBucket::HashTable<K, K, SetKeyOfT, Hash>::const_iterator iterator;typedef typename HashBucket::HashTable<K, K, SetKeyOfT, Hash>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}const_iterator begin()const {return _ht.begin();}const_iterator end()const {return _ht.end();}pair<iterator,bool> insert(const K&key){return _ht.insert(key);}iterator find(const K&key){return _ht.Find();}bool erase(const K& key){return _ht.Erase(key);}private:HashBucket::HashTable<K,K, SetKeyOfT, Hash> _ht;};void test_set(){unordered_set<int> v;v.insert(1);v.insert(3);v.insert(2);v.insert(8);v.insert(1000);v.insert(5);unordered_set<int>::iterator it = v.begin();while (it != v.end()){//*it = 1;cout << *it << " ";++it;}}
}
unordered_map.h
#include"HashTable.h"
namespace yzq
{template<class K,class V,class Hash=HashFunc<K>>class unordered_map{public:struct MapKeyOfT//仿函数{const K& operator()(const pair<K,V>& kv){return kv.first;}};public:typedef typename HashBucket::HashTable<K,pair<const K, V>, MapKeyOfT,Hash>::iterator iterator;typedef typename HashBucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::constiterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}V& operator[](const K& key){pair<iterator, bool> ret = insert(make_pair(key,V()));return ret->first->second;}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.insert(kv);}iterator find(const K& key){return _ht.Find();}bool erase(const K& key){return _ht.Erase(key);}private:HashBucket::HashTable<K, pair<const K ,V>, MapKeyOfT,Hash> _ht;};void test_map(){unordered_map<int,int> v;v.insert(make_pair(1,1));v.insert(make_pair(3, 3));v.insert(make_pair(10, 10));v.insert(make_pair(2, 2));v.insert(make_pair(8, 8));unordered_map<int, int>::iterator it = v.begin();while (it != v.end()){cout << it->first<<":"<<it->second << " ";++it;}cout << endl;}
}
相关文章:
【C++】unordered_set 和 unordered_map 使用 | 封装
文章目录 1. 使用1. unordered_set的使用2. unordered_map的使用 2. 封装修改结构定义针对insert参数 data的两种情况复用 哈希桶的insertKeyOfT模板参数的作用 迭代器operator()beginendunordered_set对于 begin和end的复用unordered_map对于 begin和end的复用unordered_map中…...

C++环形缓冲区设计与实现:从原理到应用的全方位解析
C环形缓冲区设计与实现:从原理到应用的全方位解析 一、环形缓冲区基础理论解析(Basic Theory of Circular Buffer)1.1 环形缓冲区的定义与作用(Definition and Function of Circular Buffer)1.2 环形缓冲区的基本原理&…...

阿里云服务器部署flask简单方法
记录如何在阿里云服务器上部署flask接口并实现公网访问。 文章目录 1. 简介2. 部署python3环境3. 生成requirement.txt4. 将项目打包上传5. 安装依赖库6. 查看防火墙7. 测试能否公网访问 1. 简介 因落地通话callback服务测试,需要我写一个测试demo,用于…...

【JavaSE】Java基础语法(二十三):递归与数组的高级操作
文章目录 1. 递归1.1 递归1.2 递归求阶乘 2. 数组的高级操作2.1 二分查找2.2 冒泡排序2.3 快速排序2.4 Arrays (应用) 1. 递归 1.1 递归 递归的介绍 以编程的角度来看,递归指的是方法定义中调用方法本身的现象把一个复杂的问题层层转化为一个与原问题相似的规模较…...
HUSTOJ使用指南
如何快速上手(了解系统的功能)? admin管理员用户登录,点击右上角管理,仔细阅读管理首页的说明。 切记:题目导入后一次只能删一题,不要导入过多你暂时用不上的题目,正确的方式是每次…...

java基础学习
一、注释 1)当行注释 // 2)多行注释 /* ... */ 3)文档注释 (java特有) /** author 张三 version v1.0 这是文档注释,需要将class用public修饰 */ 二、关键字 (1)48个关键…...
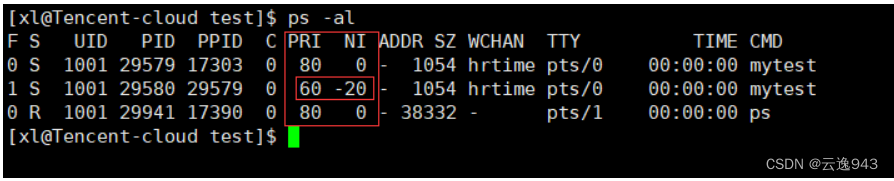
Linux——进程优先级
1.什么是优先级? 优先级和权限息息相关。权限的含义为能还是不能做这件事。而优先级则表示:你有权限去做,只不过是先去做还是后去做这件事罢了。 2.为什么会存在优先级? 优先级表明了狼多肉少的理念,举个例子ÿ…...

音频设备初始化与输出:QT与SDL策略模式的实现
音频设备初始化与输出:QT与SDL策略模式的实现 一、引言(Introduction)1.1 音频设备初始化与输出的重要性1.2 QT与SDL的音频设备处理1.3 策略模式在音频设备处理中的应用 二、深入理解音频设备初始化与输出2.1 音频设备的基本概念2.2 音频设备…...

Linux 手动部署 SpringBoot 项目
Linux 手动部署 SpringBoot 项目 1. 将项目打包成 jar 包 (1)引入插件 <build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></pl…...

华为OD机试真题B卷 Java 实现【内存资源分配】
一、题目描述 有一个简易内存池,内存按照大小粒度分类,每个粒度有若干个可用内存资源,用户会进行一系列内存申请,需要按需分配内存池中的资源,返回申请结果成功失败列表。 分配规则如下: 分配的内存要大于等于内存的申请量,存在满足需求的内存就必须分配,优先分配粒度…...

深入理解ChatGPT插件:competitorppcads、seoanalysis和kraftful
1. 引言 插件,作为一种扩展功能的工具,为我们的应用程序提供了无限的可能性。在ChatGPT中,我们有许多强大的插件,如competitorppcads、seoanalysis和kraftful。这篇博客将详细介绍这三个插件的功能和使用方法。 2. competitorpp…...

通过源码编译安装LAMP平台的搭建
目录 1. 编译安装Apache httpd服务2 编写mysqld服务3 编译安装PHP 解析环境安装论坛 LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整套系统和相关软件,能够提供动态Web站点服务及其应用开发环境。 LAMP是一个缩写词,具体包…...
mac os 安装rz/sz
说明:使用rz sz实现终端的文件传输,该命令主要使用场景为 macos中通过堡垒机登陆后无法使用ftp工具传输文件。 工具:iTerm2、lrzsz、homebrew 以及两个脚本文件(iterm2-recv-zmodem.sh、iterm2-send-zmodem.sh) …...
 建立监听服务和开启事件循环)
Redis源码(1) 建立监听服务和开启事件循环
Redis 是cs架构(服务端-客户端),典型的一对多的服务器应用程序。多个客户通过网络与Redis服务器进行通信。那么在linux环境中是使用epoll(我们也 只讨论linux环境的,便于学习)。 通过使用I/O多路复用技术, redis 服务器使用单线程单进程的…...

c++基础概念,const与指针、引用的关系,auto,decltype关键字能干啥总得了解吧。总得按照需求自定义创建实体类,自己编写头文件吧
const限定符 有时我们希望定义这样一种变量,它的值不能被改变。例如,用一个变量来表示缓冲区的大小。使用变量的好处是当我们觉得缓冲区大小不再合适时,很容易对其进行调整。另一方面,也应随时警惕防止程序一不小心改变了这个值。…...

【数据结构】---几分钟简单几步学会手撕链式二叉树(下)
文章目录 前言🌟一、二叉树链式结构的实现🌏1.1 二叉树叶子节点个数💫代码:💫流程图: 🌏1.2 二叉树的高度💫第一种写法(不支持):📒代码:…...
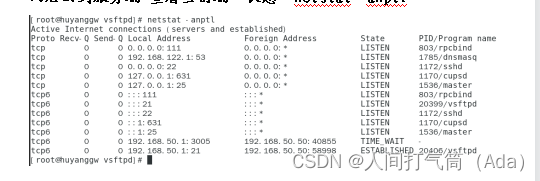
用户验证FTP实验
用户FTP实验 目录 匿名用户验证: 本地用户验证: 本地用户访问控制: 匿名用户验证: 例:(前提配置,防火墙关闭,yum安装,同模式vmware11) 现有一台计算机huy…...

App 软件开发《单选4》试卷答案及解析
App 软件开发《单选4》试卷答案及解析 注:本文章所有答案的解析来自 ChatGPT 的回答(给出正确答案让其解释原因),正确性请自行甄辨。 文章目录 App 软件开发《单选4》试卷答案及解析单选题(共计0分)1&#…...

代码随想录算法训练营第三十七天 | 力扣 738.单调递增的数字, 968.监控二叉树
738.单调递增的数字 题目 738. 单调递增的数字 当且仅当每个相邻位数上的数字 x 和 y 满足 x < y 时,我们称这个整数是单调递增的。 给定一个整数 n ,返回 小于或等于 n 的最大数字,且数字呈 单调递增 。 解析 从后向前遍历…...
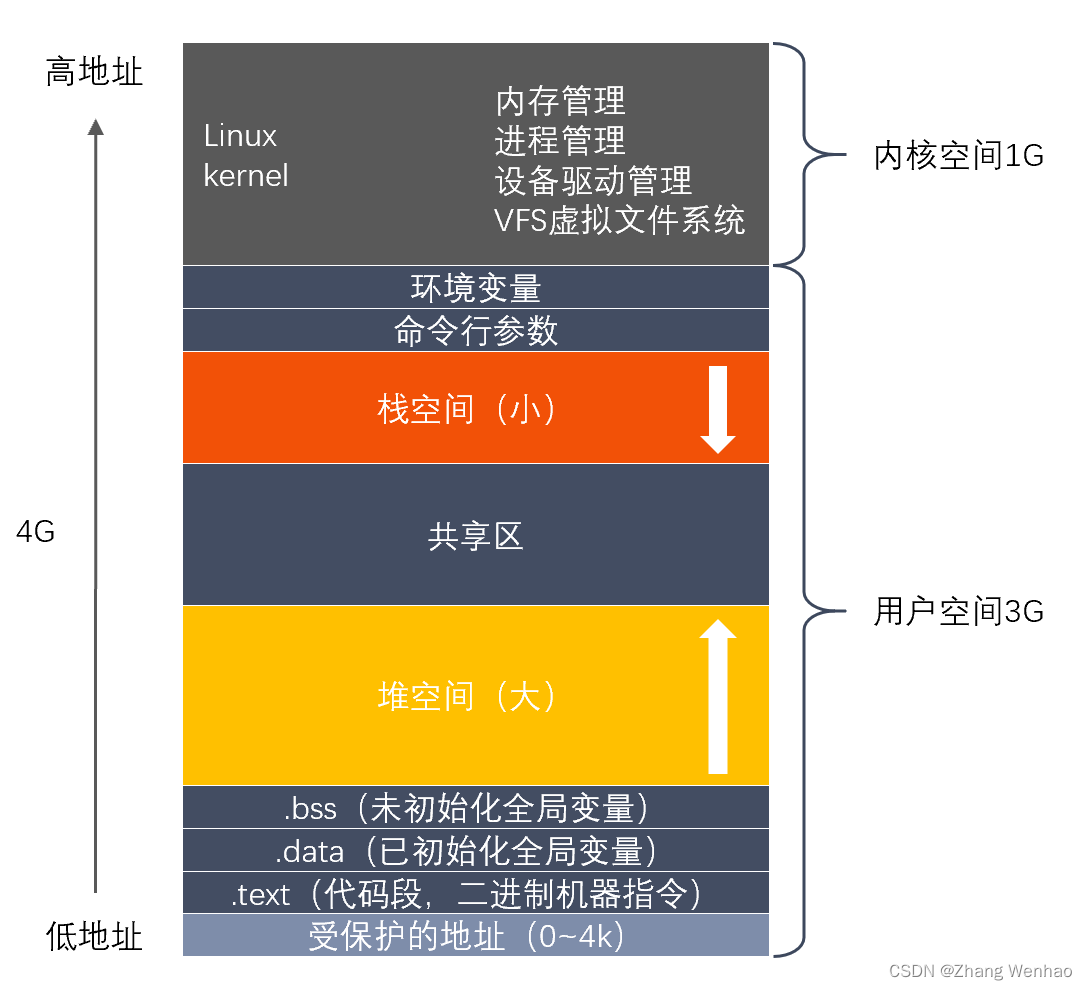
C++内存总结
1.2 C内存 参考 https://www.nowcoder.com/issue/tutorial?tutorialId93&uuid8f38bec08f974de192275e5366d8ae24 1.2.1 简述一下堆和栈的区别 参考回答 区别: 堆栈空间分配不同。栈由操作系统自动分配释放 ,存放函数的参数值,局部变…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...