One2Multi Graph Autoencoder for Multi-view Graph Clustering
One2Multi Graph Autoencoder for Multi-view Graph Clustering | Proceedings of The Web Conference 2020 (acm.org)
目录
Abstract
1 Introduction
2 Model
2.1 Overview
2.2 One2Multi Graph Convolutional Autoencoder
Informative graph convolutional encoder
Multi-view graph decoder
Reconstruction loss
2.3 Self-training Clustering
2.4 Optimization
3 代码注释
Abstract
多视图图聚类受到关注,它寻求用,可以提供更全面但更复杂信息的多个视图,对图进行划分。虽然一些方法在多视图聚类方面取得了不错的成功,但大多采用shallow model处理多视图图内部的复杂关系,会限制多视图图信息建模能力。
作者首次尝试将深度学习技术应用于属性多视图图聚类,提出了一种新的任务导向的One2Multi图自编码器聚类框架。One2Multi图自编码器能够通过使用一个信息图视图和内容数据来重建多个图视图学习节点嵌入。因此,可以很好地捕获多个图的共享特征表示。在此基础上,提出了自训练聚类目标,迭代改进聚类结果。通过将自训练和自编码器重构整合到一个统一的框架中,模型可以共同优化适合图聚类的聚类标签分配和嵌入。
1 Introduction
大多数图聚类方法只关注处理一个图,但现实中图形数据很复杂。因此要使用多视图图而不是单视图图,来更好表示实的图数据,其中每个图视图代表节点之间的一种关系。以学术网络为例,一个图视图可以表示共同作者关系,另一个图视图可以表示共同会议关系,作者还可以与代表性关键字相关联,作为其属性。这种复杂图通常被称为属性多视图图,它以互补和综合的方式对交互系统进行建模,具有更准确的图聚类潜力。
属性多视图图聚类可以被分为两类:(1)基于图分析的方法。其目的是最大化不同视图之间的相互一致性,从而将图划分为组。(2)图嵌入。利用图嵌入技术从多视图图数据中学习节点的表示,随后使用k-means等传统聚类方法。
但这些方法都被认为是浅层模型,对揭示复杂图数据中的深层关系的能力有限。此外,上述方法对节点属性信息关注较少。
近年来,GNN作为一种深度非线性表示学习框架,在节点分类和聚类等图分析任务上显示出了强大的性能。然而,大多数gnn是针对单视图图开发的。此外,也有一些作品将GNN扩展到多视图设置,但它们是在半监督场景下设计的,用于分类任务。将CNN用于属性多视图图聚类会遇到挑战:(1)简单的融合方法建立多个模型,开发多个编码器和解码器,每个编码器和解码器对应于每个视图。然而,由于引入了不同视图中包含的噪声,这种简单的方法并不有效。更重要的是,multi2multi模型只能单独提取每个视图表示,而共享表示可能对任务更重要。从所有观点中学习也很耗时。(2)如何使GNN学习到的嵌入更适合聚类任务?节点嵌入和聚类通常是两个独立的任务。节点嵌入的目的是重建原始图,因此学习到的节点嵌入不一定适用于节点聚类。因此,需要以统一的方式优化节点嵌入和聚类。
观察真实的多视图图数据,可以发现:(1)虽然多视图信息从不同方面反映了节点关系,但它们应该具有一些共同的节点特征。(2)在许多场景中,通常存在一个最具信息量的视图比其他视图产生更好的聚类效果。
本文提出了一种新的One2Multi图自编码器框架,用于属性多视图图聚类。该模型的基本思想是从信息量最大的图视图和内容数据中提取共享表示,然后利用共享表示重构所有视图。根据这一思路,我们设计了一种新型的One2Multi图形自编码器,它由一个编码器和多个解码器组成。具体来说,它利用多视图图结构和节点内容来学习节点表示,通过一个多层图卷积网络(GCN)编码器从最具信息量的视图中学习节点表示,多个图解码器重构所有视图。进一步,设计了自训练聚类目标,使当前聚类分布趋近于更适合聚类任务的目标分布。通过联合优化重构损失和聚类损失,该模型可以同时优化节点嵌入和聚类,并在统一的框架内相互改进。
贡献总结如下:
(1)第一次将图深度学习用到多视图图聚类;
(2)提出了一种新的One2Multi自编码器框架,用于属性多视图图聚类,One2Multi 图自编码器提供了一个有效的深度框架来集成多视图图结构和内容信息。此外,该框架还对多视图图嵌入学习和图聚类进行了相互促进的优化。
2 Model
2.1 Overview
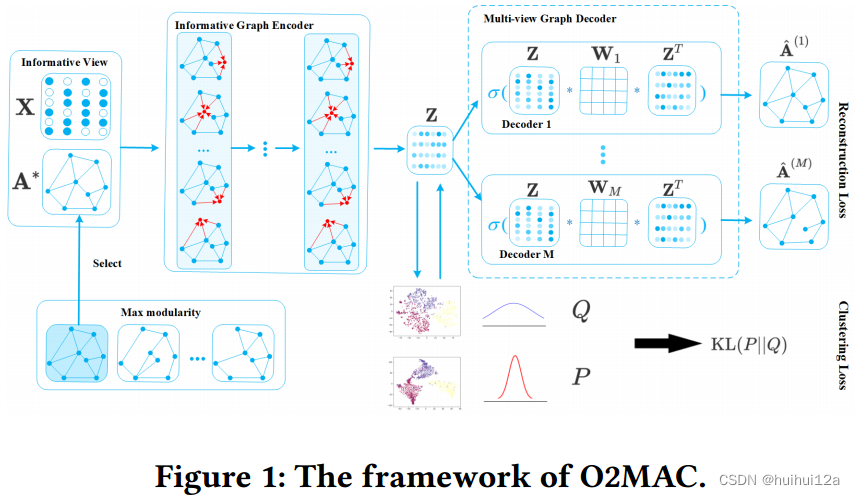
该模型主要由两部分组成:One2Multi图自编码器和自训练图聚类。One2Multi图自编码器由一个信息图编码器和多视图图解码器组成。采用启发式度量模块化方法,选择信息量最大的视图作为图编码器的输入,将图结构和节点内容编码为节点表示。
然后设计了一个多视图图解码器来解码表示,以重建所有视图。由于One2Multi图自编码器的精致设计,它不仅学习了共享表示,而且吸收了不同视图的结构特征。使用由学习嵌入本身生成的软标签来监督编码器参数和聚类中心的学习。对多视图图的嵌入和聚类在统一的框架中进行优化,从而得到一个信息丰富的编码器,使其表示更适合聚类任务。
2.2 One2Multi Graph Convolutional Autoencoder
为了在统一框架中表示多视图图结构A(1)、···、A(M)和节点内容X,作者开发了一种新的One2Multi图自编码器(O2MA)架构,其中所有视图共享一个图卷积编码器,从一个信息图视图和内容数据中提取共享表示,并设计了一个多解码器,从共享表示中重构多视图图数据。
Informative graph convolutional encoder
由于不同的图视图是在同一组节点之间通过不同方面表示关系,并且所有图视图共享内容信息,因此视图之间存在共享信息。此外,在许多场景中,通常存在一个最具信息量的视图来有最好聚类性能。因此,信息视图和其他视图之间的共享信息可以从信息量最大的图视图和内容数据中提取出来,然后用于重构所有的图视图。
基于上述假设,以信息量最大的图视图A∗∈{A(1),···,A(M)}和节点内容信息X作为输入,重构所有图视图。使用启发式度量——模块化,来选择信息量最大的视图。首先将每个单视图图邻接矩阵和内容信息分别馈送到GCN层中学习节点嵌入,然后对学习到的嵌入执行k-means来获得它们的聚类指标。基于聚类指标和邻接矩阵,计算每个图视图的模块化得分,并选择得分最高的图视图作为信息量最大的图视图。因为模块化提供了评估聚类结构的客观度量。
信息图编码器是两层的GCN,初始的节点嵌入是节点的属性:

Multi-view graph decoder
为了监督编码器提取所有视图的共享表示,提出了一种多视图图解码器,从表征Z,重构出多视图数据,解码器由M个特定于视图的解码器组成
,预测视图m中两个节点之间是否存在连接,Wm是视图m的特定于视图的权重。也就是基于图嵌入训练了一个多视图链接预测层。
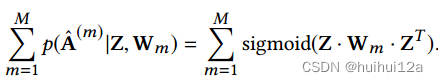
Reconstruction loss
对于多视图图自编码器,将每个图视图数据的重构误差之和最小化:
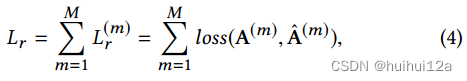
由于解码器的多视图结构,在反向传播过程中,多解码器的梯度会通过信息图编码器传播(会更新信息图编码器的参数,使它能产生更利于重构出更好的多视图嵌入)。因此,在处理前向传播时,图编码器将提取所有视图的共享表示。这个模型也可以看作是多任务学习。多视图图解码器为信息图编码器提取共享表示提供了多任务监督信号,使共享表示更加全面和一般化。
2.3 Self-training Clustering
前面提到的One2Multi图卷积自编码器可以将属性多视图图编码成紧凑的表示形式。然而,嵌入空间中的节点接近性是为了保留原始多视图图数据的局部结构,这可能不能保证适合聚类。对于聚类来说,良好的数据分布是同一聚类内的节点密集聚集,不同聚类之间的边界明显。因此,有必要引入其他目标来指导嵌入学习过程。采用自训练聚类目标,利用”high confident“节点作为软标签来监督图聚类过程。
除了重构损失外,将隐藏的嵌入输入到一个自我训练聚类目标中,该目标最小化以下目标:
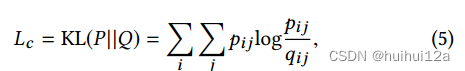
其中Q是软标签的分布,qij采用Student 's t-分布来度量,表示节点i的嵌入zi与聚类中心µj之间的相似度:
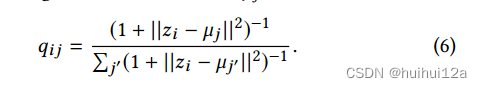
qij可以看作是每个节点的软聚类分配分布。pij是目标分布:
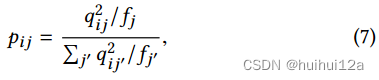
其中,是对每个质心的损失贡献进行归一化的软聚类频率,以防止大型聚类扭曲隐藏特征空间。目标分布P将Q提高到二次幂以得到更密集的分布。通过最小化Q和P之间的KL散度,可以使Q的分布更加密集。观察到“high confident”的节点在KL散度最小化开始时对梯度的贡献更大。“high confident”的节点表示节点有很高的概率属于某个由Eq. 6计算的集群。这种现象可以解释为半监督训练。
Overall objective function
共同优化了One2Multi图自编码器嵌入和聚类学习,总目标函数定义为:
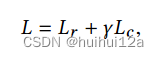
2.4 Optimization
首先预训练没有自训练聚类部分的One2Multi图自编码器,以获得一个训练良好的嵌入Z。然后进行自训练聚类目标来改进这种嵌入。为了初始化聚类中心,对嵌入节点Z执行标准k-means聚类,以获得k个初始质心{µj}。具体来说,需要更新的参数有三种:One2Multi图自编码器的权值W (l)和W1、···、WM、聚类中心µ和目标分布P.
(1)聚类中心的更新

(2)解码器参数的更新
可以看到,Wm的更新只与视图m的重构损失有关,因此,视图特定解码器的权重可以捕获视图特定的局部结构信息
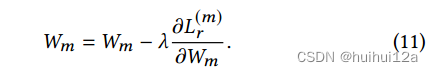
(3)编码器参数的更新
W (l)的更新与所有视图的重构损失相关,使得编码器的权重可以提取所有视图的共享表示。
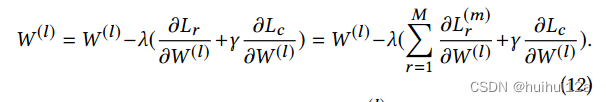
(4)更新目标分布
目标分布P依赖于预测的软标签。为了避免自训练过程中的不稳定性,每T次迭代应使用所有嵌入节点更新P。根据Eq. 6和Eq. 7更新P,在更新目标发行版时,分配给vi的标签由:
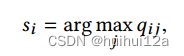
qij由式6计算。如果目标分布的两次连续更新之间的标签分配变化(以百分比表示)小于阈值δ,则训练过程将停止。我们可以从最后一个优化后的Q得到聚类结果。
3 代码注释

因为自编码器的Decoder的参数更新只和重构损失有关,自编码器的Encoder的参数更新和KL散度损失和重构损失有关(见2.4)
因此(1)首先预训练没有自训练聚类部分的One2Multi图自编码器,以获得一个训练良好的嵌入Z
(2)进行自训练聚类目标来改进这种嵌入。为了初始化聚类中心,对嵌入节点Z执行标准k-means聚类获得聚类中心,计算出KL散度,再更新Encoder参数,此时嵌入向量Z可以进一步更新,聚类中心也可以更新,并更新P与Q
(3)交替Q与P
O2MAC.py
from __future__ import division
from __future__ import print_function
from sklearn.cluster import KMeans
import settings
import warnings
import tensorflow as tf
warnings.filterwarnings('ignore')
import os
import numpy as np
#os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
#os.environ['CUDA_VISIBLE_DEVICES'] = 1
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1,2"
import tensorflow as tf
from metrics import clustering_metrics
from constructor import get_placeholder, get_model, compute_q, format_data, get_optimizer, warm_update, warm_update_test, update, update_test, update_kl
#from sklearn.metrics import calinski_harabasz_score, silhouette_score
from sklearn import preprocessing
import scipy.io as scio
# Settings
flags = tf.app.flags
FLAGS = flags.FLAGS
def label_mask(labels):num = labels.shape[1]label_mask = np.dot(labels, np.array(range(num)).reshape((num, 1))).reshape((labels.shape[0]))return label_maskdef target_distribution(q):weight = q**2 / q.sum(0)return (weight.T / weight.sum(1)).Tdef count_num(labels):label_num = {}for label in labels:if label not in label_num:label_num[label] = 1else:label_num[label] += 1return label_numdef save_embed(emb, filename):fw = open(filename, 'w')for line in emb:fw.write(' '.join([str(s) for s in line]))fw.write('\n')fw.close()loss = []
NMIs = []
class Clustering_Runner():def __init__(self, settings):print("Clustering on dataset: %s, model: %s, number of iteration: %3d" % (settings['data_name'], settings['model'], settings['iterations']))self.data_name = settings['data_name']self.iterations = 50self.kl_iterations = 0self.model = settings['model']self.n_clusters = settings['clustering_num']self.tol = 0.001self.time = 5def erun(self):tf.reset_default_graph()model_str = self.model# formatted datafeas = format_data(self.data_name)placeholders = get_placeholder(feas['adjs'], feas['numView'])# construct modelae_model = get_model(model_str, placeholders, feas['numView'], feas['num_features'], feas['num_nodes'], self.n_clusters)# Optimizeropt = get_optimizer(model_str, ae_model, feas['numView'], placeholders, feas['num_nodes'])# Initialize sessionconfig = tf.ConfigProto()config.gpu_options.allow_growth=True #设置tf模式为按需赠长模式sess = tf.Session(config=config)sess.run(tf.global_variables_initializer())# Train modelpos_weights = feas['pos_weights']fea_pos_weights = feas['fea_pos_weights']# 1 首先预训练没有自训练聚类部分的One2Multi图自编码器,以获得一个训练良好的嵌入Z# 重构损失# 解码器的参数更新和编码器的部分参数更新只和重构损失相关,和KL散度损失无关for epoch in range(self.iterations):reconstruct_loss = update(ae_model, opt, sess, feas['adjs'], feas['adjs_label'], feas['features'], placeholders, pos_weights, fea_pos_weights, feas['norms'], attn_drop=0., ffd_drop=0.)print('reconstruct_loss', reconstruct_loss)if (epoch+1) % 10 == 0:# 更新嵌入向量,利用嵌入向量产生聚类中心,看产生的嵌入向量的聚类效果如何emb_ind = update_test(ae_model, opt, sess, feas['adjs'], feas['adjs_label'], feas['features'], placeholders, pos_weights = pos_weights, fea_pos_weights = fea_pos_weights, norm = feas['norms'], attn_drop=0, ffd_drop=0)kmeans = KMeans(n_clusters=self.n_clusters).fit(emb_ind)print("PAP Epoch:", '%04d' % (epoch + 1))predict_labels = kmeans.predict(emb_ind)#print('emb1', emb_ind[1])label_num = count_num(predict_labels)print('view1 label_num:', label_num)cm = clustering_metrics(label_mask(feas['true_labels']), predict_labels)acc, f1_macro, precision_macro, nmi, adjscore,_ = cm.evaluationClusterModelFromLabel()NMIs.append(nmi)loss.append(reconstruct_loss)# 2 进行自训练聚类目标来改进这种嵌入。使用训练后的自编码器产生的嵌入向量Z,使用KMeans初始化集群,得到聚类中心kmeans = KMeans(n_clusters=self.n_clusters).fit(emb_ind)y_pred_last = kmeans.labels_cm = clustering_metrics(label_mask(feas['true_labels']), y_pred_last)acc, f1_macro, precision_macro, nmi, adjscore, idx= cm.evaluationClusterModelFromLabel()init_cluster = tf.constant(kmeans.cluster_centers_)sess.run(tf.assign(ae_model.cluster_layer.vars['clusters'], init_cluster))q = compute_q(ae_model, opt, sess, feas['adjs'], feas['adjs_label'], feas['features'], placeholders, pos_weights, fea_pos_weights, feas['norms'], attn_drop=0., ffd_drop=0.)p = target_distribution(q)# P和Q的KL散度损失for epoch in range(self.kl_iterations):# 因为图自编码器中Encoder的参数更新也和KL散度损失有关,因此可以通过KL散度更新Encoder的参数,从而可以更进一步更新嵌入向量Zemb, kl_loss = update_kl(ae_model, opt, sess, feas['adjs'], feas['adjs_label'], feas['features'], p, placeholders, pos_weights, fea_pos_weights, feas['norms'], attn_drop=0., ffd_drop=0., idx=idx, label = label_mask(feas['true_labels']))if epoch%10 == 0:# 使用嵌入向量进一步计算聚类中心,再计算KL散度损失kmeans = KMeans(n_clusters=self.n_clusters).fit(emb)predict_labels = kmeans.predict(emb)cm = clustering_metrics(label_mask(feas['true_labels']), predict_labels)acc, f1_macro, precision_macro, nmi, adjscore, _ = cm.evaluationClusterModelFromLabel()NMIs.append(nmi)loss.append(kl_loss)if epoch%5 == 0:# 更新目标分布P# 训练停止条件# 如果T步前后节点类别标签的比例改变delta_label小于self.tol则停止更新q = compute_q(ae_model, opt, sess, feas['adjs'], feas['adjs_label'], feas['features'], placeholders, pos_weights, fea_pos_weights, feas['norms'], attn_drop=0., ffd_drop=0.)p = target_distribution(q)y_pred = q.argmax(1)delta_label = np.sum(y_pred != y_pred_last).astype(np.float32) / y_pred.shape[0]y_pred_last = y_predprint('delta_label', delta_label)print("Epoch:", '%04d' % (epoch + 1))kmeans = KMeans(n_clusters=self.n_clusters).fit(emb)predict_labels = kmeans.predict(emb)cm = clustering_metrics(label_mask(feas['true_labels']), predict_labels)acc, f1_macro, precision_macro, nmi, adjscore, _ = cm.evaluationClusterModelFromLabel()if epoch > 0 and delta_label < self.tol:print("early_stop")break print('NMI', NMIs)print('loss', loss)return acc, f1_macro, precision_macro, nmi, adjscoreif __name__ == '__main__':dataname = 'ACM' # "ACM" or "DBLP" #dataname = './data/DBLP4057_GAT_with_idx.mat'model = 'arga_ae' # 'arga_ae' or 'arga_vae'task = 'clustering' # 'clustering' or 'link_prediction'times = 10accs = []f1_macros = []precision_macros = []nmis = []adjscores = []settings = settings.get_settings(dataname, model, task)for t in range(times):# 进行使用重构损失和KL散度的交替更新print('times:%d'%t)if task == 'clustering':runner = Clustering_Runner(settings)acc, f1_macro, precision_macro, nmi, adjscore = runner.erun()accs.append(acc)f1_macros.append(f1_macro)precision_macros.append(precision_macro)nmis.append(nmi)adjscores.append(adjscore)acc_mean = np.mean(np.array(accs)) acc_std = np.std(np.array(accs), ddof=1)f1_mean = np.mean(np.array(f1_macros)) f1_std = np.std(np.array(f1_macros), ddof=1)precision_mean = np.mean(np.array(precision_macros)) precision_std = np.std(np.array(precision_macros), ddof=1) nmi_mean = np.mean(np.array(nmis)) nmi_std = np.std(np.array(nmis), ddof=1)ari_mean = np.mean(np.array(adjscores)) ari_std = np.std(np.array(adjscores), ddof=1)print('ACC_mean=%f, ACC_std=%f, f1_mean=%f, f1_std=%f, precision_mean=%f, precision_std=%f, nmi_mean=%f, nmi_std=%f, ari_mean=%f, ari_std=%f' % (acc_mean, acc_std, f1_mean, f1_std, precision_mean, precision_std, nmi_mean, nmi_std, ari_mean, ari_std))model.py中ARGA部分
class ARGA(Model):def __init__(self, placeholders, numView, num_features, num_clusters, **kwargs):super(ARGA, self).__init__(**kwargs)self.inputs = placeholders['features']self.num_features = num_features#self.features_nonzero = features_nonzeroself.adjs = placeholders['adjs']self.dropout = placeholders['dropout']self.attn_drop = placeholders['attn_drop']self.ffd_drop = placeholders['ffd_drop']self.num_clusters = num_clustersself.numView = numViewself.build()def _build(self):with tf.variable_scope('Encoder', reuse=None):# 两层GCN产生嵌入向量self.hidden1 = GraphConvolution(input_dim=self.num_features,output_dim=FLAGS.hidden1,adj=self.adjs[FLAGS.input_view],act=tf.nn.relu,dropout=self.dropout,logging=self.logging,name='e_dense_1_'+str(FLAGS.input_view))(self.inputs)self.noise = gaussian_noise_layer(self.hidden1, 0.1)self.embeddings = GraphConvolution(input_dim=FLAGS.hidden1,output_dim=FLAGS.hidden2,adj=self.adjs[FLAGS.input_view],act=lambda x: x,dropout=self.dropout,logging=self.logging,name='e_dense_2_'+str(FLAGS.input_view))(self.noise)# 利用嵌入向量和聚类中心生成分布qself.cluster_layer = ClusteringLayer(input_dim=FLAGS.hidden2, n_clusters=self.num_clusters, name='clustering')self.cluster_layer_q = self.cluster_layer(self.embeddings)'''self.reconstructions = []for v in range(self.numView):view_reconstruction = MP(input_dim=FLAGS.hidden2, v = v,act=lambda x: x,logging=self.logging)(embeddings)self.reconstructions_fuze.append(view_reconstruction)'''# 重构所有视图self.reconstructions_fuze = []for v in range(self.numView):view_reconstruction = InnerProductDecoder(input_dim=FLAGS.hidden2, name = 'e_weight_multi_', v = v,act=lambda x: x,logging=self.logging)(self.embeddings)self.reconstructions_fuze.append(view_reconstruction)相关文章:
One2Multi Graph Autoencoder for Multi-view Graph Clustering
One2Multi Graph Autoencoder for Multi-view Graph Clustering | Proceedings of The Web Conference 2020 (acm.org) 目录 Abstract 1 Introduction 2 Model 2.1 Overview 2.2 One2Multi Graph Convolutional Autoencoder Informative graph convolutional encoder M…...
:读入一个小于 10 的整数 n,输出它的阶乘 n。(for循环))
Java编程实现输入数的阶乘(for循环):读入一个小于 10 的整数 n,输出它的阶乘 n。(for循环)
public class Main { public static void main(String[] args) { Scanner input new Scanner(System.in); //输入提示语句 System.out.print(“请输入一个小于10的数:”); //从键盘获取值 int num input.nextInt(); //定义一个总和 int sum 1; //开始判断输入数是…...

算法提高-搜索-FloodFill和最短路
FloodFill和最短路 FloodFillAcwing 1097. 池塘计数AcWing 1098. 城堡问题AcWing 1106. 山峰和山谷 最短路AcWing 1076. 迷宫问题AcWing 188. 武士风度的牛AcWing 1100. 抓住那头牛 FloodFill Acwing 1097. 池塘计数 //acwing 1097. 池塘计数 #include <iostream> #inc…...

【蓝桥杯单片机第八届国赛真题】
【蓝桥杯单片机第八届国赛真题】 文章目录 【蓝桥杯单片机第八届国赛真题】前言一、真题二、源码 前言 有幸进入国赛,为自己大学最后一个比赛画上完满的句号^^ 下面为蓝桥杯单片机第八届国赛程序部分,功能差不多都实现了,可能存在小bug&#…...

一种简单的Android骨架屏实现方案----0侵入0成本
对骨架屏的理解 什么是骨架屏 所谓骨架屏,就是在页面进行耗时加载时,先展示的等待 UI, 以告知用户程序目前正在运行,稍等即可。 等待的UI大部分是 loading 转圈的弹窗,有的是自己风格的小动画。其实大同小异。而骨架屏无非也是一…...

【Kubernetes 架构】了解 Kubernetes 网络模型
Kubernetes 网络使您能够在 k8s 网络内配置通信。它基于扁平网络结构,无需在主机和容器之间映射端口。 Kubernetes 网络支持容器化组件之间的通信。这种网络模型的主要优点是不需要在主机和容器之间映射端口。然而,配置 Kubernetes 网络模型并不是一件容…...

shell
一、判断当前磁盘剩余空间是否有20G,如果小于20G,则将报警邮件发送给管理员,每天检查一次磁盘剩余空间。 二、判断web服务是否运行 三、使用curl命令访问第二题的web服务,看能否正常访问,如果能正常访问,…...
springboot+ssm+java校园二手物品交易系统vxkyj
样需要经过市场调研,需求分析,概要设计,详细设计,编码,测试这些步骤,基于Java语言、Jsp技术设计并实现了校园二手物品交易系统。系统主要包括个人中心、商家管理、用户管理、商品分类管理、商品信息管理、商…...

Android系统内置应用
Android系统内置应用 背景 客户提供APK,需要集成进系统,并且不可卸载 Android原生是怎么做的? 已Launcher3为例,apk是位于/system/priv-app/Launcher3目录下 AOSP系统内置app步骤 1.在package/apps/目录下创建相应的文件夹如&…...

CMMI实施需要准备什么:
1. 人力资源 实施中会涉及到EPG过程改进小组、QA、试点项目团队等人力资源: 1) 专职人员:1-2名 即在CMMI实施推广期内,基本上100%的时间投入。 2) 质量人员:1-更多名 组建质量管理部门,实施体系执行的监控&#x…...

【ARM AMBA AXI 入门 1 - AXI 握手协议】
文章目录 1.1 AXI 双向握手机制简介1.1.1 信号列表1.1.2 双向握手目的1.1.3 握手过程 1.2 数据通路的握手要求1.2.1 读数据通路1.2.2 读地址通路1.2.3 写数据通路1.2.4 写地址通路1.2.5 写回复通路1.2.6 全信号 1.3 不同数据通路间的约束关系1.3.1 读操作约束关系1.3.2 写操作约…...
详解uni-app应用生命周期函数
详解uni-app应用生命周期函数 详解uni-app应用生命周期函数 文章目录 详解uni-app应用生命周期函数前言一、应用生命周期函数二、页面生命周期函数总结 前言 UNI-APP学习系列之详解uni-app应用生命周期函数 一、应用生命周期函数 函数名说明onLaunch当uni-app 初始化完成时触…...

【WebFlux】List指定bean引用对象更新后同步到List
Java 8的流式API实现 如果你想在WebFlux中更新List中指定bean的引用对象并将其同步到List中,你可以使用Java 8的流式API来完成这个任务。 以下是一个例子: List<MyBean> myBeanList new ArrayList<>(); MyBean myBean1 new MyBean(); My…...

【JavaSE】Java基础语法(二十六):Collection集合
文章目录 1. 数组和集合的区别2. 集合类体系结构3. Collection 集合概述和使用【应用】4. Collection集合的遍历【应用】5. 增强for循环【应用】 1. 数组和集合的区别 相同点 都是容器,可以存储多个数据不同点 数组的长度是不可变的,集合的长度是可变的 数组可以存基本数据类型…...
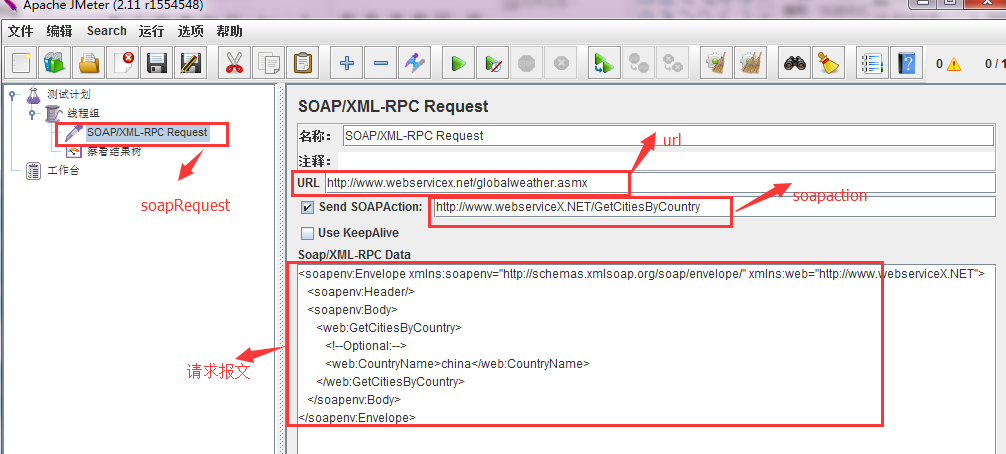
jmeter做接口压力测试_jmeter接口性能测试
jmeter是apache公司基于java开发的一款开源压力测试工具,体积小,功能全,使用方便,是一个比较轻量级的测试工具,使用起来非常简单。因为jmeter是java开发的,所以运行的时候必须先要安装jdk才可以。jmeter是免…...
网络编程 lesson5 IO多路复用
select 当需要在一个或多个文件描述符上等待事件发生时,可以使用select函数。 select函数是一个阻塞调用,它会一直等待,直到指定的文件描述符上有事件发生或超时。 select函数详解 int select(int nfds, fd_set *readfds, fd_set *writefd…...

码出高效_第一章 | 有意思的二进制表示及运算
目录 0与1的世界1.如何理解32位机器能够同时处理处理32位电路信号?2.如何理解负数的加减法运算3.溢出在运算中如何理解4.计算机种常用的存储单位及转换5.位移运算规则6.有趣的 && 和 & 浮点数1.定点小数(为什么会出现浮点数表示?…...
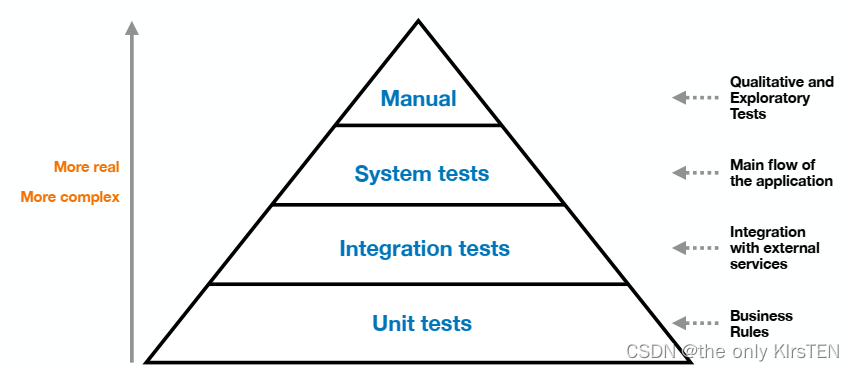
测试类型(单元、集成、系统或手动测试)
测试类型(单元、集成、系统或手动测试) 单元测试 单元是系统的单个组件,例如类或单个方法。孤立地测试单元称为单元测试。 优点:速度快/易控/易写 缺点:缺乏现实性/无法捕获所有错误(例如与其他组件或服务的交互) 单元…...

【笔试强训编程题】Day3.(字符串中找出连续最长的数字串 69385)和(数组中出现次数超过一半的数字 23271)
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:笔试强训编程题 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!! 文章目录…...
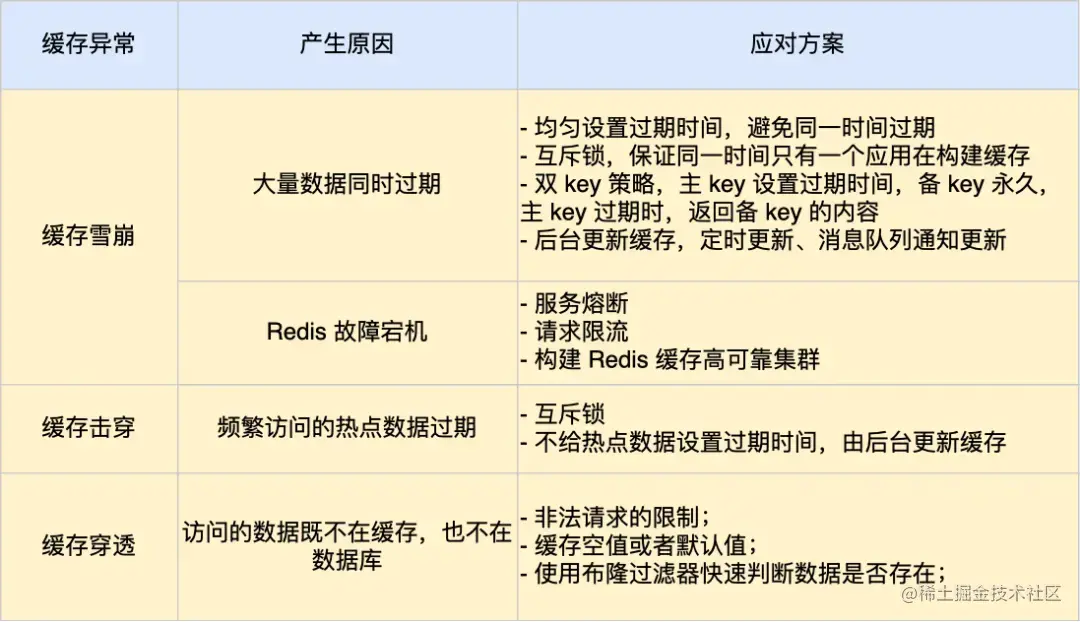
学懂缓存雪崩,缓存击穿,缓存穿透仅需一篇,基于Redis讲解
在了解缓存雪崩、击穿、穿透这三个问题前,我们需要知道为什么我们需要缓存。在了解这三个问题后,我们也必须知道使用Redis时,如何解决这些问题。 所以我将按照"为什么我们需要缓存"、"什么是缓存雪崩、击穿、穿透"、&qu…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...
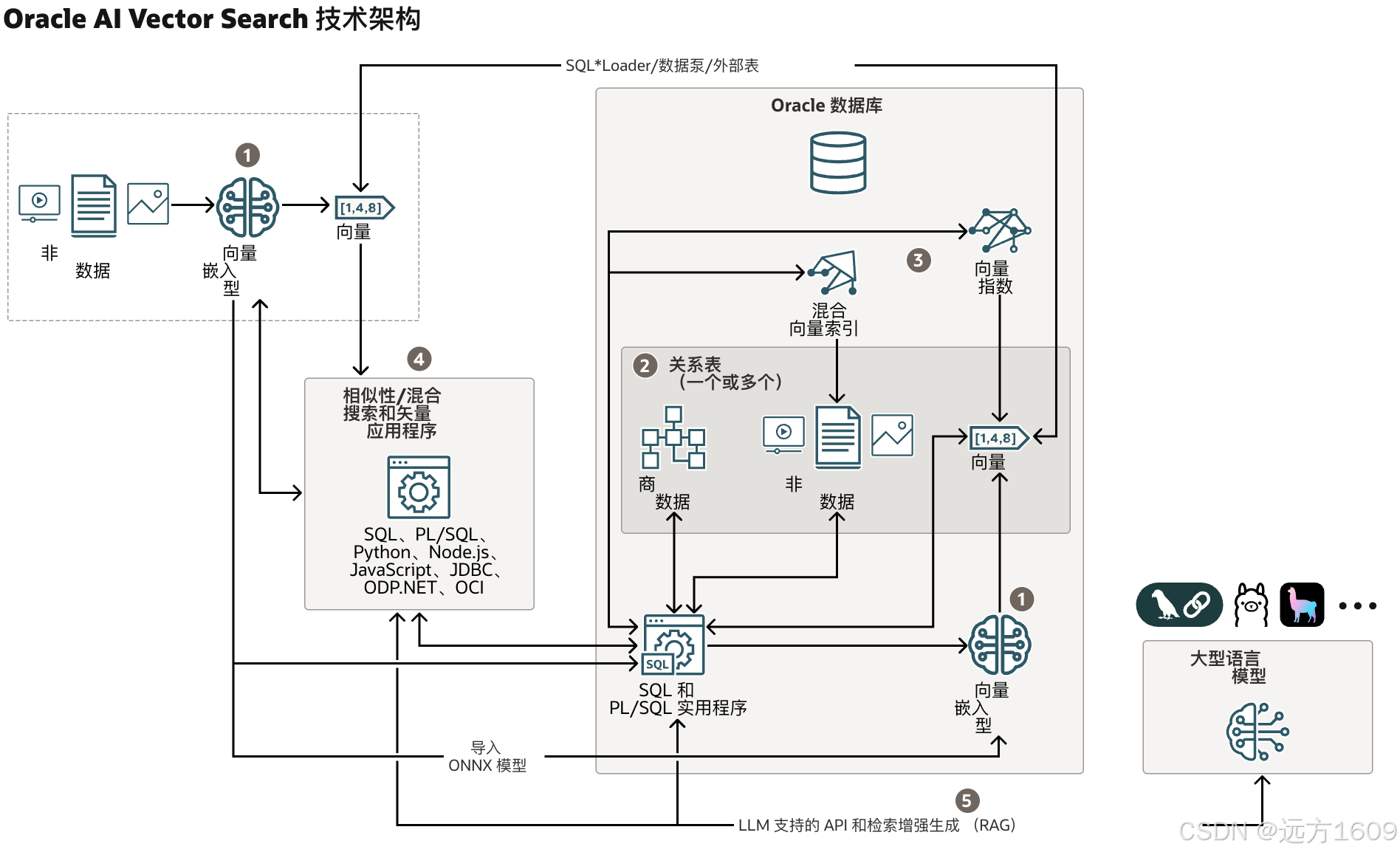
9-Oracle 23 ai Vector Search 特性 知识准备
很多小伙伴是不是参加了 免费认证课程(限时至2025/5/15) Oracle AI Vector Search 1Z0-184-25考试,都顺利拿到certified了没。 各行各业的AI 大模型的到来,传统的数据库中的SQL还能不能打,结构化和非结构的话数据如何和…...

Xela矩阵三轴触觉传感器的工作原理解析与应用场景
Xela矩阵三轴触觉传感器通过先进技术模拟人类触觉感知,帮助设备实现精确的力测量与位移监测。其核心功能基于磁性三维力测量与空间位移测量,能够捕捉多维触觉信息。该传感器的设计不仅提升了触觉感知的精度,还为机器人、医疗设备和制造业的智…...

算法250609 高精度
加法 #include<stdio.h> #include<iostream> #include<string.h> #include<math.h> #include<algorithm> using namespace std; char input1[205]; char input2[205]; int main(){while(scanf("%s%s",input1,input2)!EOF){int a[205]…...

Python第七周作业
Python第七周作业 文章目录 Python第七周作业 1.使用open以只读模式打开文件data.txt,并逐行打印内容 2.使用pathlib模块获取当前脚本的绝对路径,并创建logs目录(若不存在) 3.递归遍历目录data,输出所有.csv文件的路径…...