高速缓存(cache)的原理: 了解计算机架构与性能优化
计基之存储器层次结构
Author: Once Day Date: 2023年5月9日
长路漫漫,而今才刚刚启程!
本内容收集整理于《深入理解计算机系统》一书。
参看文档:
- 捋一捋Cache - 知乎 (zhihu.com)
- iCache和dCache一致性 - 知乎 (zhihu.com)
- Cache设计总结 - 知乎 (zhihu.com)
文章目录
- 计基之存储器层次结构
- 1. 概述
- 1.1 随机访问存储器(Random-Access Memory, RAM)
- 1.2 局部性原理(principle of locality)
- 1.3 缓存(caching)
- 2. 高速缓存存储器
- 2.1 通用高速缓存存储器的组织结构
- 2.2 直接映射高速缓存(direct-mapped cache)
- 2.3 直接映射高速缓存实例分析
- 2.4 组相联高速缓存(set associative cache)
- 2.5 全相联高速缓存
- 3. 高速缓存性能分析
- 3.1 写回问题
- 3.2 真实缓存结构的剖析
- 3.3 高速缓存参数的性能影响
- 3.4 编写对高速缓存友好的代码
- 3.5 分块(blocking)技术
1. 概述
在理想的环境下,存储器系统是一个线性的字节数组,而CPU能够在一个常数时间内访问每个存储器的位置。

但实际上,存储器系统(memory system)是一个具有不同容量、成本和访问时间的存储设备的层次结构:
- CPU寄存器保存着最常用的数据。
- 接着是小的、快速的高速缓存存储器(cache memory).
- 然后是慢速,但容量较大的主存储器(main memory),里面存着指令和数据。
- 再往下就是容量更大的磁盘、硬盘、云盘、磁带、网络等等实际或虚拟存储器。

程序一般偏向局部性原理,因此在大多时候,访问的都是某一段位置的内容,这意味这种层次的结构,可以在成本和效率之间取得良好的平衡。
一般而言,存储在寄存器上的数据,0个周期就可以直接访问,存在高速缓存的数据需要4~75个周期,主存的数据需要上百个周期,而在磁盘上的数据,可能需要上百万个周期才能访问。
1.1 随机访问存储器(Random-Access Memory, RAM)
随机访问存储器分为两类:静态SRAM和动态DRAM。SRAM一般更贵,因此其容量较小,一般为几兆字节。
静态SRAM将每个位存储在一个双稳态的存储器单元里,每个单元是利用一个晶体管电路实现的,该电路有一个属性,可以无限期地保存在两个不同的电压配置或者状态下,其他任何状态都是不稳定的。即使遭遇电子噪声,也可以恢复到稳定状态。
动态DRAM将每个位使用电容存储,其更加敏感,有很多原因导致其电容电压改变,因此需要周期性刷新每一个位的值(数十毫秒)。
1.2 局部性原理(principle of locality)
一个编程良好的计算机程序常常具有良好的局部性(locality),倾向于引用邻近于其他最近引用过的数据项,或者最近引用过的数据项本身。通常有如下两种形式:
- 时间局部性(temporal locality),被引用过一次的内存位置在不远的将来再被多次引用。
- 空间局部性(spatial locality),一个内存位置被引用了一次,那么程序可能将不远的将来引用附近的位置。
局部性原理是一种通用的性能优化技巧,有良好局部性的程序比局部性差的程序运行得快。例如硬件高速缓存,操作系统用DRAM来缓存磁盘内容。
下面是一个数据引用局部性的例子,二维数组求和:
# 步长为1
for (int i = 0; i < M; i++){for (int j = 0; j < N; j++) {sum += g_data[i][j];}
}
# 步长为N=1000=M
for (int i = 0; i < M; i++){for (int j = 0; j < N; j++) {sum += g_data[j][i];}
}
在测试设备上,步长1的耗费时间仅为步长N的三分之一。
像第一个循环这样的顺序访问一个向量的每个元素,认为其具有步长为1的引用模式(stride-1 reference pattern),步长为1的引用模式也称为顺序引用模式(sequential reference pattern)。随着步长增加,空间局部性下降。
一般局部性的基本思想如下:
- 重复引用相同的变量具有良好的时间局部性。
- 对于具有步长为k的引用模式程序,步长越小,空间局部性越好。
- 对于取指令来说,循环有好的时间和空间局部性。
1.3 缓存(caching)
一般而言,高速缓存(cache)是一个小而快速的存储设备,作为存储在更大,也更慢的设备中的数据对象的缓冲区域。使用高速缓存的过程称为缓存(caching)。
缓存命中:当程序需要K+1层的某个数据对象d时,如果d刚好缓存在第k层中。
缓存不命中:如果第K+1层中没有缓存数据对象d,那么就是缓存不命中(cache miss)。
当发现缓存不命中时,第K层的缓存会去第K-1层中取出包含d的那个块,如果第k层的缓存已经满了,可能就会覆盖现存的一个块。
覆盖现存块的过程称为替换(replacing)或驱逐(evicting)这个块。被驱逐的块也有时被称为牺牲块(victim block)。
决定替换哪个块是由缓存的替换策略决定的,如随机替换和最少使用替换。
缓存不命中有如下种类:
- 空缓存一般称为冷缓存(cold cache),此类不命中称为强制性不命中(compulsory miss)或冷不命中(cold miss)。
- 限制性的放置策略同样会引起不命中,称为冲突不命中(conflict miss),因此这些数据对象会映射到同一个块中。
- 程序每个阶段访问的缓存块集合是不一样的,即工作集。当工作集大小超过缓存大小时,缓存会经历容量不命中(capacity miss)。
一般L1/L2/L3高速缓存都是按照64字节的内存块来缓存。
2. 高速缓存存储器
2.1 通用高速缓存存储器的组织结构
假设一个计算机系统,其每个存储器地址有m位,形成 M = 2 m M=2^m M=2m个不同的地址。

然后机器的高速缓存被组织成一个有 S = 2 s S=2^s S=2s个高速缓存组(cache set)的数组,每个组包含E个高速缓存行(cache line)。每一个行都是由一个 B = 2 b B=2^b B=2b字节的数据块(block)组成,一个有效位(valid bit)指明这个行是否包含有意义的信息,还有 t = m − ( b + s ) t=m-(b+s) t=m−(b+s)个标记位(tag bit),是当前块的内存地址的位的一个子集,唯一标识存储在这个高速缓存行中的块。
高速缓存的结构一般可以用元组(S, E, B, m)来描述,高速缓存的容量指的是所有块的大小的和,标记位和有效位不包括在内,因此 C = S ∗ E ∗ B C=S*E*B C=S∗E∗B。
高速缓存将m位的地址划分成以下的结构:
|-(高位)--------------m位------------(低位)-|
|--标记(t位)--|--组索引(s位)--|--块偏移(b位)--|
一般有以下的符号参数:
| 参数 | 描述 | 衍生量 |
|---|---|---|
| S = 2 s S=2^s S=2s | 组数 | s = l o g 2 ( S ) s=log_2(S) s=log2(S),组索引位数量 |
| E | 每个组的行数 | |
| B = 2 b B=2^b B=2b | 块大小(字节) | b = l o g 2 ( B ) b=log_2(B) b=log2(B),块偏移位数量 |
| m = l o g 2 ( M ) m=log_2(M) m=log2(M) | (主存)物理地址位数 | t = m − ( s + b ) t=m-(s+b) t=m−(s+b), 标记位数量 |
2.2 直接映射高速缓存(direct-mapped cache)
根据每个组的高速缓存行数E,高速缓存被分为不同的类。每个组只有一行(E=1)的高速缓存称为直接映射高速缓存。

对于一个简单的系统,如cpu+寄存器+L1缓存+DRAM。当CPU执行一个读取内存字w的指令时,它向L1高速缓存请求这个字,如果L1高速缓存有w的一个缓存的副本,那么就得到L1高速缓存命中。
如果高速缓存不命中,此时L1高速缓存会向主存DRAM请求包含w块的一个副本时,CPU必须等待。
最终L1高速缓存里面会包含w块的一个副本,然后从该缓存块中抽出字w,并返回给CPU。
缓存确定一个请求是否命中,然后抽出来被请求字的过程,分为三步:
- (1) 组选择
- (2) 行匹配
- (3) 字抽取
如下所示,直接从w的地址中间抽取出s个组索引位,这些位被解释成一个对应于一个组号的无符号整数。

利用s个组索引位组成的索引,即可找到对应的缓存块。对于直接映射高速缓存,因为每组只有一行,因此直接判断有效位和标记是否匹配。如果有效位被设置,且标记匹配,那么这一行中包含w的一个副本。

如上所示,如果(1)(2)两步判断不成立,那么就是缓存不命中。地址的最低几位是块偏移位,其大小受块大小限制,一般的cache line大小是64字节,因此偏移位一般为6位。
直接映射高速缓存不命中时的行替换策略很简单,直接用新取出来的行替换当前行即可。
2.3 直接映射高速缓存实例分析
加深对高速缓存运行过程的理解,最好的方式是实际模拟一下具体的情况。
假设一个实例如下:
( S , E , B , m ) = ( 4 , 1 , 2 , 4 ) (S,E,B,m) = (4,1,2,4) (S,E,B,m)=(4,1,2,4)
即高速缓存有4个组,每个组一行,每一行的缓存块有2个字节,地址位有4位,字长(word)为1个字节。下面列出全部情况:
| 地址m | 标记位(t=1) | 索引位(s=2)(二进制) | 偏移位(b=1) | 块号 |
|---|---|---|---|---|
| 0 | 0 | 00 | 0 | 0 |
| 1 | 0 | 00 | 1 | 0 |
| 2 | 0 | 01 | 0 | 1 |
| 3 | 0 | 01 | 1 | 1 |
| 4 | 0 | 10 | 0 | 2 |
| 5 | 0 | 10 | 1 | 2 |
| 6 | 0 | 11 | 0 | 3 |
| 7 | 0 | 11 | 1 | 3 |
| 8 | 1 | 00 | 0 | 4 |
| 9 | 1 | 00 | 1 | 4 |
| 10 | 1 | 01 | 0 | 5 |
| 11 | 1 | 01 | 1 | 5 |
| 12 | 1 | 10 | 0 | 6 |
| 13 | 1 | 10 | 1 | 6 |
| 14 | 1 | 11 | 0 | 7 |
| 15 | 1 | 11 | 1 | 7 |
从上图可以看出:
- 标记位和索引位唯一标识了内存中的每个块。
- 一共有8个块,但只有4个高速缓存组,因此多个块会映射到同一个高速缓存组中,这些块具有相同的组索引。
- 映射到同一个高速缓存组的块由标记位唯一标识。
下面执行一次模拟运行:
-
初始时,高速缓存是空的,因此四个缓存组情况如下:
|---组---|---有效位----|----标记位----|----块[0]----|----块[1]----|0 01 02 03 0 -
读取地址0的字,此时发生缓存不命中,属于
cold cache,此时高速缓存从内存中取出块0,并把这个块存储在组0中,即地址m[0]和m[1]的内容,然后返回m[0]的内容。|---组---|---有效位----|----标记位----|----块[0]----|----块[1]----|0 1 0 m[0] m[1]1 02 03 0 -
读取地址1的字,此时命令高速缓存,因此直接从高速缓存组[0]的块[1]中拿取m[1]的值。
-
读取地址13的字,由于组[2]中高速缓存行不是有效的,所以有缓存不命中,高速缓存行把块[6]加载到组[2]中,然后从新的高速缓存行组[2]的块[1]中返回m[13]。
|---组---|---有效位----|----标记位----|----块[0]----|----块[1]----|0 1 0 m[0] m[1]1 02 1 1 m[12] m[13] 3 0 -
读取地址8的字,这会发生缓存不命中,组0中的高速缓存行虽然有效,但标记不匹配,高速缓存将块4加载到组0中,替换原来的数据,然后从新的块[0]中返回m[8]。
|---组---|---有效位----|----标记位----|----块[0]----|----块[1]----|0 1 1 m[8] m[9]1 02 1 1 m[12] m[13] 3 0 -
读取地址0的字,这又会发生缓存不命中,前面替换过块0。这是典型的容量足够,但由于缓存冲突造成的不命中。
这种高速缓存反复地加载和驱逐相同的高速缓存块的组的现象,一般称为抖动。如下所示:
float dotprod(float x[8], float y[8])
{float sum =0.0;int i;for (i = 0; i < 8; i++) {sum += x[i] * y[i];}return sum;
}
虽然上面这个函数具有良好的空间局部性,但是如果x地址和y地址之差刚好等于高速缓存大小的整数倍,那么就会映射到同一个缓存组上,容易产生缓存冲突。
2.4 组相联高速缓存(set associative cache)
直接映射高速缓存中冲突不命中造成的问题源于每个组只有一行,组相联高速缓存放松了该限制,每个组都保存有多于一个的高速缓存行,即 1 < E < C / B 1<E<C/B 1<E<C/B,称为E路组相连高速缓存。
组相连高速缓存的组选择和直接映射高速缓存没有区别,都是使用组索引位标识组。
不同的是组相连高速缓存中每个组有多个行,可以将每个组看成一个相连存储器,即(key, value)的数组,返回对应的value值,key即由标记位和有效位组成。
组相连高速缓存的每个组中任何一行,都可以包含任何映射到这个组的内存块,因此高速缓存必须搜索组中的每一个行,寻找一个有效的行,其标记与地址中的标记相匹配。
如果CPU请求的字不在组的任何一行中,那么就是缓存不命中,高速缓存必须从内核中取出包含这个字的块。如果该组中存在空行,那么直接替换空行是个不错的选择。
如果该组中没有空行,必须从中选择一个非空的行,策略一般如下(一般代码编程是无需关心此点):
- 随机替换策略
- 最不常使用策略(Least-Frequently)
- 最近最少使用策略(Least-Recently-Used, LRU)
2.5 全相联高速缓存
全相联高速缓存(fully associative cache),是由一个包含所有高速缓存行的组( E = C / B E=C/B E=C/B)组成的。
全相联高速缓存中的组选择非常简单,因为只有一个组,地址中没有组索引位,地址只被划分为一个标记和一个块偏移。
全相联高速缓存的行匹配和字选择与组相联高速缓存是一致的,但是构建一个又大又快的全相联高速缓存很困难,一般来说容量较小。典型的例子是虚拟内存系统中的翻译备用缓冲器(TLB)。
3. 高速缓存性能分析
3.1 写回问题
相比较于读取高速缓存,写回的问题会更加复杂一些。
假设写一个已经缓存的字w(写命中,write hit),在高速缓存更新了它的w副本以后,如何更新更低层次的副本呢?如下:
- 直写(write-through),最简单的方法,就是立即将w的高速缓存块写回到紧接着的低一层中。缺点是每次都会引起总线流量。
- 写回(write-back),尽可能推迟更新,只有当替换算法要驱逐这个更新过的块时,才把它写到紧接着的低一层中。缺点是会增加处理逻辑的复杂性。
当面临写不命中时,有以下的处理方法:
- 写分配(write-allocate),加载相应的低一层块到高速缓存中,然后更新这个高速缓存块。该方法试图利用写的空间局部性,但是缺点是每次不命中都会导致一个块从低一层传送到高速缓存。
- 非写分配(not-write-allocate),避开高速缓存,直接把这个字写到低一层中。
直接高速缓存通常是非写分配的,写回高速缓存通常是写分配的。
现代CPU的高速缓存一般使用写回策略。写回策略是指在修改高速缓存中的数据时,不立即写回主存,而是将修改后的数据标记为“脏数据”,并等待下一次需要替换该缓存行时再将脏数据写回主存。这种策略可以减少对主存的写入次数,提高系统性能。
相比之下,直写策略则是在修改高速缓存中的数据时立即将其写回主存,这会导致频繁的主存写入,降低系统性能。
因此,写回策略通常比直写策略更为常见,也更为优秀。但是,写回策略也可能会导致数据不一致的问题,需要进行合理的缓存一致性协议设计来解决。
一般可以假设现代系统使用写回和写分配的方式,这与读取的方式对称(但具体细节仍和处理器细节有关)。
其次,可以在高层次开发我们的程序,展示良好的空间和时间局部性,而不是试图为某个存储器进行优化。
3.2 真实缓存结构的剖析
只保存指令的高速缓存称为i-cache,只保存程序数据的高速缓存称为d-cache,既保存数据也保存命令的高速缓存称为统一的高速缓存(unified cache)。
i-cache 的优点:
- 加速指令的获取:i-cache 可以缓存 CPU 需要执行的指令,减少了从主存中获取指令的时间,从而提高了程序的执行速度。
- 减少指令访问冲突:由于指令通常是按照程序的执行顺序依次执行的,因此 i-cache 的访问模式比较规律,不容易出现访问冲突。
i-cache 的缺点:
- 浪费一部分缓存容量:由于指令通常是按照程序的执行顺序依次执行的,因此 i-cache 中存储的指令可能会比较连续,这导致了一些缓存行可能存储的是不必要的指令,从而浪费了一部分缓存容量。
- 缓存失效对程序的影响较大:如果 i-cache 中的缓存行失效,CPU 就需要从主存中重新获取指令,这会导致较大的性能损失。
d-cache 的优点:
- 加速数据的读写:d-cache 可以缓存 CPU 需要读写的数据,减少了从主存中获取数据的时间,从而提高了程序的执行速度。
- 支持多种访问模式:与 i-cache 不同,d-cache 中存储的数据可能会被多个线程或者进程同时访问,因此 d-cache 支持多种访问模式,包括读、写、读写等模式,能够更好地适应多线程程序的需求。
d-cache 的缺点:
- 容易出现访问冲突:由于数据的访问模式比较随机,因此 d-cache 的访问模式比较不规律,容易出现访问冲突,从而影响程序的执行效率。
- 可能会出现一致性问题:由于 d-cache 中存储的是 CPU 需要修改的数据,如果多个线程或进程同时访问同一块数据,就可能出现一致性问题。为了解决这个问题,需要采用一些同步机制,例如锁或原子操作等,这会增加程序的复杂度和开销。
下面是Intel Core i7处理器的高速缓存层次结构,用于参考(来自《深入理解计算机》第六章)。

相关数据总结如下:
| 高速缓存类型 | 访问时间(周期) | 高速缓存大小© | 相联度(E) | 块大小(B) | 组数(S) |
|---|---|---|---|---|---|
L1 i-cache | 4 | 32KB | 8 | 64B | 64 |
L1 d-cache | 4 | 32KB | 8 | 64B | 64 |
| L2统一的高速缓存 | 10 | 256KB | 8 | 64B | 512 |
| L3统一的高速缓存 | 40~75 | 8MB | 16 | 64B | 8192 |
3.3 高速缓存参数的性能影响
下面是常见的衡量高速缓存性能的指标:
- 不命中率(miss rate),指在访问高速缓存时,所需数据在缓存中找到的次数(hits)相比于没有找到的次数(不命中数量/引用数量)。
- 命中率(hit rate),命中内存引用比率,它等于
1 - 不命中率。 - 命中时间(hit time),从高速缓存传送一个字到CPU所需的时间,包括组选择、行确认和字选择的时间。对于L1高速缓存来说, 命中时间的数量级是几个时钟周期。
- 不命中处罚(miss penalty),由于不命中所需要的额外时间,L1不命中需要从L2得到服务的处罚,通常是数10个周期,从L3得到服务的处罚,50个周期,从主存得到服务的处罚,200个周期。
高速缓存的大小、块大小、相联度和写策略等指标都会对高速缓存的性能产生影响,具体如下:
- 高速缓存大小:高速缓存大小是指缓存可以存储的数据量。缓存大小越大,可以缓存的数据就越多,命中率也有可能更高。但是,缓存大小也受到制造成本和功耗等因素的限制。
- 块大小:块大小是指高速缓存中每个缓存块可以存储的数据量。块大小的选择会影响缓存的命中率和访问延迟。较小的块大小可以提高命中率,因为可以更精细地缓存数据,但会增加访问延迟和标签存储器的开销。较大的块大小可以减少访问延迟,但会降低命中率,因为每次缓存块的替换会导致更多的数据失效,从而降低命中率。
- 相联度:相联度是指高速缓存中每个缓存块可以映射到多少个缓存行中。相联度的选择会影响缓存的命中率和访问延迟。较低的相联度可以减少访问延迟,因为每个缓存块只需要查找一个缓存行就可以了,但会降低命中率,因为如果多个缓存块映射到同一个缓存行中,就会发生冲突。较高的相联度可以提高命中率,因为每个缓存块可以映射到多个缓存行中,从而减少了冲突,但会增加访问延迟和标签存储器的开销。
- 写策略:写策略是指当 CPU 对缓存进行写操作时,缓存如何处理数据的更新。常见的写策略有写回和写直两种。写回策略是指当 CPU 对缓存进行写操作时,数据先被写入到缓存中,而不是立即写入主存。这样可以减少对主存的访问,提高性能。但也会增加缓存的复杂度和一致性问题。写直策略是指当 CPU 对缓存进行写操作时,数据会直接被写入到主存中。这样可以保证数据的一致性,但会增加对主存的访问,降低性能。
3.4 编写对高速缓存友好的代码
高速缓存友好(cache friendly)的代码,首先要具备良好的局部性,核心原则有两个:
- 让最常见的情况运行得快,忽略一些细枝末节的路径,专注于最核心的路径。
- 尽量减少每个循环内部的缓存不命中数量。
编写缓存友好的代码是一种优化技术,旨在最大化高速缓存的使用效率,从而提高程序的性能。以下是一些编写缓存友好的代码的实践方法:
- 空间局部性:高速缓存通常是以缓存块为单位进行管理的,因此,如果程序中的数据访问模式比较局部,即对相邻的数据进行访问,就可以提高缓存的命中率。
- 时间局部性:高速缓存中存储的数据通常是最近访问过的数据。因此,如果程序中的数据访问模式比较重复,即对同一块数据进行多次访问,就可以提高缓存的命中率。
- 数据对齐:高速缓存通常是按照缓存块的大小进行管理的,因此,如果程序中的数据没有对齐到缓存块的边界,就会导致跨越缓存块边界的访问,从而降低缓存的命中率和性能。
- 循环展开:循环展开是一种优化技术,可以将循环中的代码复制多次,以减少循环的迭代次数,从而提高程序的性能。循环展开可以提高空间局部性和时间局部性,从而提高缓存的命中率和性能。
- 编写缓存友好的算法:一些算法具有良好的缓存局部性,例如矩阵乘法和卷积等算法。
- 避免缓存污染:缓存污染是指缓存中存储了不必要的数据,从而降低了缓存的命中率和性能。可以使用局部变量和静态变量等技术,以减少对全局变量和动态分配内存的访问,从而提高缓存的命中率和性能。
- 避免缓存冲突:缓存冲突是指多个数据映射到同一个缓存块中,从而导致数据的互相替换,降低缓存的命中率和性能。可以使用不同的数据结构和算法等技术,以减少数据的冲突,从而提高缓存的命中率和性能。
3.5 分块(blocking)技术
分块技术(Blocking)是一种用于提高时间局部性(temporal locality)的优化技术。时间局部性描述了程序在一段时间内多次访问相同数据的趋势。利用时间局部性可以减少缓存未命中(cache miss)的数量,从而提高程序的执行速度。
分块技术的核心思想是将大的数据结构划分为较小的块(block),以便它们可以适应缓存的大小。访问这些较小的块时,程序会在较短的时间内多次访问相同的数据,从而提高缓存利用率。分块技术在许多领域都有应用,例如矩阵乘法、图像处理和数据库查询优化等。
下面以矩阵乘法为例,介绍如何使用分块技术提高时间局部性。
假设我们有两个矩阵 A 和 B,它们的大小分别为 N x N。我们要计算这两个矩阵的乘积 C = A x B。传统的矩阵乘法算法如下:
for i in range(N):for j in range(N):for k in range(N):C[i][j] += A[i][k] * B[k][j]
这种实现方式存在缓存未命中的问题,因为数据访问的局部性较差。为了提高时间局部性,我们可以使用分块技术,将矩阵 A、B 和 C 划分为较小的子矩阵。假设我们使用 blockSize x blockSize 的块大小,分块后的矩阵乘法算法如下:
for i in range(0, N, blockSize):for j in range(0, N, blockSize):for k in range(0, N, blockSize):for ii in range(i, min(i + blockSize, N)):for jj in range(j, min(j + blockSize, N)):for kk in range(k, min(k + blockSize, N)):C[ii][jj] += A[ii][kk] * B[kk][jj]
通过这种方式,我们将大矩阵划分为较小的子矩阵,并在子矩阵间进行计算。这样可以提高缓存利用率,因为在较短时间内会多次访问相同的数据。同时,分块技术可以根据硬件特性调整 blockSize 的大小,以适应不同的缓存结构。
需要注意的是,分块技术并不总是能提高性能,它需要根据特定的程序和硬件环境进行优化。在实际应用中,程序员需要对所处理的问题有深入了解,并根据具体情况选择适当的优化方法。
相关文章:
高速缓存(cache)的原理: 了解计算机架构与性能优化
计基之存储器层次结构 Author: Once Day Date: 2023年5月9日 长路漫漫,而今才刚刚启程! 本内容收集整理于《深入理解计算机系统》一书。 参看文档: 捋一捋Cache - 知乎 (zhihu.com)iCache和dCache一致性 - 知乎 (zhihu.com)C…...

【Vue3+TS项目】硅谷甄选day04--顶部组件搭建+面包屑+路由鉴权
顶部组件搭建 顶部左侧折叠和面包屑实现 左侧菜单刷新折叠的问题解决---属性default-active 折叠之后图标不见:icon放在插槽外面----element的menu属性:collapse project\src\layout\index.vue // 获取路由对象 import { useRoute } from vue-route…...
某oa 11.10 未授权任意文件上传
漏洞简介 之前也对通达 oa 做过比较具体的分析和漏洞挖掘,前几天看到通达 oa 11.10 存在未授权任意文件上传漏洞,于是也打算对此进行复现和分析。 环境搭建 https://www.tongda2000.com/download/p2019.php 下载地址 :https://cdndown.tongda…...

Grounded Language-Image Pre-training(论文翻译)
文章目录 Grounded Language-Image Pre-training摘要1.介绍2.相关工作3.方法3.1统一构建3.2.语言感知深度融合3.3.使用可扩展的语义丰富数据进行预训练 4.迁移到既定的基准4.1.COCO上的zero-shot和监督迁移学习4.2.LVIS上的zero-shot 迁移学习4.3.Flickr30K实体上的 phrase gro…...
)
设计模式-行为型模式(模板方法、策略、观察者、迭代器、责任链、命令、状态、备忘录、访问者、中介者、解释器)
行为型模式:专注于对象之间的 协作 及如何通过彼此之间的交互来完成任务。行为型模式通常集中在描述对象之间的 责任 分配和 通信 机制,并提供了一些优雅解决特定问题的方案。 模板方法模式(Template Method Pattern)策略模式(Strategy Pattern)观察者模…...

全面探讨 Spring Boot 的自动装配机制
Spring Boot 是一个基于 Spring 框架的快速开发脚手架,它通过自动配置机制帮助我们快速搭建应用程序,从而减少了我们的配置量和开发成本。自动装配是 Spring Boot 的核心特点之一,它可以减少项目的依赖,简化配置文件,提…...

河道水位监测:河道水位监测用什么设备
中国地形复杂,气候多样,导致水资源分布不均,洪涝和干旱等问题时有发生。同时,人类活动也对水资源造成了很大压力,工业和农业用水增加,河道水位下降,生态环境受到威胁。因此,对河道水…...

嵌入式系统中u-boot和bootloader到底有什么区别
嵌入式软件工程师都听说过 u-boot 和 bootloader,但很多工程师依然不知道他们到底是啥。 今天就来简单讲讲 u-boot 和 bootloader 的内容以及区别。 Bootloader Bootloader从字面上来看就是启动加载的意思。用过电脑的都知道,windows开机时会首先加载…...
)
实验14:20211030 1+X 中级实操考试(id:2498)
实验14:20211030 1X 中级实操考试(id:2498) 一、项目背景说明二、表结构三、步骤【5 分】步骤 1:项目准备【5 分】步骤 2:完成实体类 Member【10 分】步骤 3:完成实体类 Goods【10 分】步骤 4&a…...
(字符串 ) 剑指 Offer 58 - II. 左旋转字符串 ——【Leetcode每日一题】
❓剑指 Offer 58 - II. 左旋转字符串 难度:简单 字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的…...

EPICS编程
提纲 1) 为什么在EPICS上编程 2)构建系统特性:假设基本理解Unix Make 3)在libCom中可用的工具 1) 为什么在EPICS上编程 1、社区标准:EPICS合作者知道和明白EPICS结构 2、在很多操作系统之间代码移值性…...

17:00面试,还没10分钟就出来了,问的实在是太...
从外包出来,没想到死在另一家厂子 自从加入这家公司,每天都在加班,钱倒是给的不少,所以也就忍了。没想到8月一纸通知,所有人不许加班,薪资直降30%,顿时有吃不起饭的赶脚。 好在有个兄弟内推我去…...

docker都有那些工具,及工具面试题
docker介绍 Docker 是一种开源的容器化平台,可以帮助开发者将应用程序和依赖项打包到轻量级的容器中,然后部署到任何基于 Linux 的操作系统中。使用 Docker 可以大大简化开发、部署和管理应用程序的过程,使其更加快速、灵活和可靠。 Docker…...

LAMP网站应用架构
LAMP 一、LAMP概述1、各组件的主要作用2、构建LAMP各组件的安装顺序 二、编译安装Apache httpd服务1、关闭防火墙,将安装Apache所需软件包传到/opt目录下2.安装环境依赖包3.配置软件模块4.编译及安装5.优化配置文件路径,并把httpd服务的可执行程序文件放…...
(纯虚函数))
C++虚函数virtual(动态多态)(纯虚函数)
怎么判断函数是虚函数还是普通函数? 用VS,在调用对象的方法的地方。。按altg ,如果他跳转到正确的函数,那也就意味着他是编译时可以确定的。。。 但是如果他跳到了这个调用对象的基类的函数,那么也就意味着他是一个运行…...

【Java 接口】接口(Interface)的定义,implements关键字,接口实现方法案例
博主:_LJaXi Or 東方幻想郷 专栏: Java | 从入门到入坟 专属:六月一日 | 儿童节 Java 接口 接口简介 🎃接口的定义 🧧接口实现类名定义 🎁接口实现类小案例 🎈后话 🎰 接口简介 &…...
解决Vmware上的kali找不到virtualbox上的靶机的问题
解决kali找不到靶场ip问题的完整方法 1.配置靶机2.配置kali的虚拟网络3.配置kali中的eth0网络 1.配置靶机 靶机部署在Virtualbox上对其进行网络配置,选择连接方式为仅主机(Host-Only)网络。 2.配置kali的虚拟网络 在编辑中选择虚拟网络配…...

查看MySQL服务器是否启用了SSL连接,并且查看ssl证书是否存在
文章目录 一、查看MySQL服务器是否启用了SSL连接 1.登录MySQL服务器 2.查看SSL配置 二、查看证书是否存在 前言 查看MySQL服务器是否启用了SSL连接,并且查看ssl证书是否存在 一、查看MySQL服务器是否启用了SSL连接 1.登录MySQL服务器 在Linux终端中…...

华为OD机试真题 Java 实现【表示数字】【牛客练习题】
一、题目描述 将一个字符串中所有的整数前后加上符号“*”,其他字符保持不变。连续的数字视为一个整数。 数据范围:字符串长度满足1≤n≤100 。 二、输入描述 输入一个字符串。 三、输出描述 字符中所有出现的数字前后加上符号“*”,其他字符保持不变。 四、解题思路…...

使用Python进行接口性能测试:从入门到高级
前言: 在今天的网络世界中,接口性能测试越来越重要。良好的接口性能可以确保我们的应用程序可以在各种网络条件下,保持流畅、稳定和高效。Python,作为一种广泛使用的编程语言,为进行接口性能测试提供了强大而灵活的工…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...
实现跳一跳小游戏)
鸿蒙(HarmonyOS5)实现跳一跳小游戏
下面我将介绍如何使用鸿蒙的ArkUI框架,实现一个简单的跳一跳小游戏。 1. 项目结构 src/main/ets/ ├── MainAbility │ ├── pages │ │ ├── Index.ets // 主页面 │ │ └── GamePage.ets // 游戏页面 │ └── model │ …...
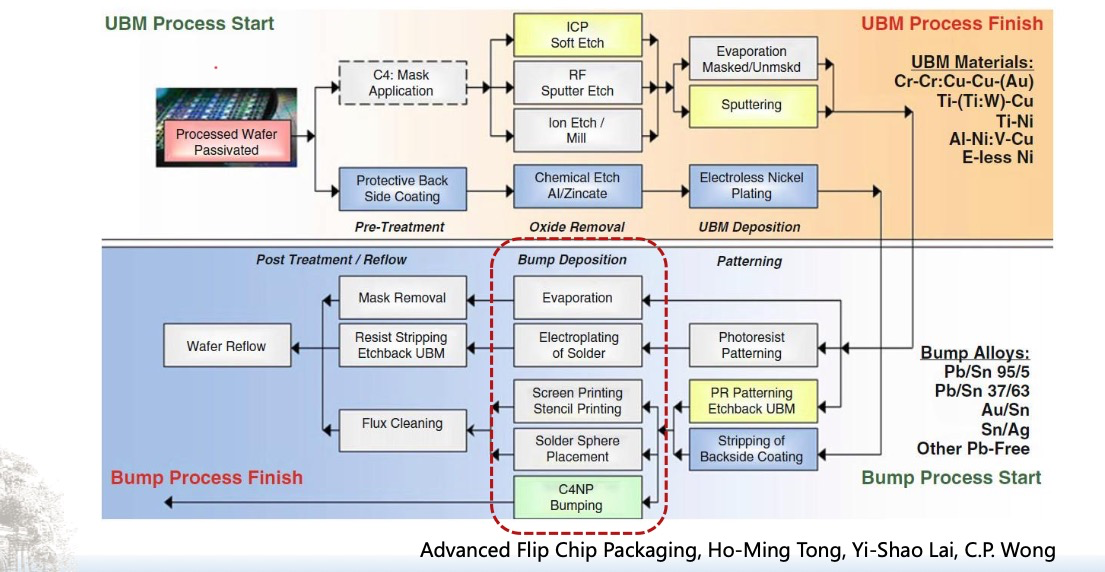
倒装芯片凸点成型工艺
UBM(Under Bump Metallization)与Bump(焊球)形成工艺流程。我们可以将整张流程图分为三大阶段来理解: 🔧 一、UBM(Under Bump Metallization)工艺流程(黄色区域ÿ…...