读书笔记-《ON JAVA 中文版》-摘要16[第十六章 代码校验]
文章目录
- 第十六章 代码校验
- 1. 测试
- 1.1 单元测试
- 1.2 JUnit
- 1.3 测试覆盖率的幻觉
- 2. 前置条件
- 2.1 断言(Assertions)
- 2.2 Java 断言语法
- 2.3 Guava 断言
- 2.4 使用断言进行契约式设计
- 2.4.1 检查指令
- 2.4.2 前置条件
- 2.4.3 后置条件
- 2.4.4 不变性
- 2.4.5 放松 DbC 检查或非严格的 DbC
- 2.4.6 使用 Guava 前置条件
- 3. 测试驱动开发
- 4. 日志
- 4.1 日志会给出正在运行的程序的各种信息。
- 4.2 日志等级
- 5. 调试
- 5.1 使用 JDB 调试
- 5.2 图形化调试器
- 6. 基准测试
- 6.1 微基准测试
- 6.2 JMH 的引入
- 7. 剖析和优化
- 7.1 优化准则
- 8. 风格检测
- 9. 静态错误分析
- 10. 代码重审
- 11. 结对编程
- 12. 重构
- 12.1 重构基石
- 13. 持续集成
- 14. 本章小结
第十六章 代码校验
你永远不能保证你的代码是正确的,你只能证明它是错的。
1. 测试
如果没有测试过,它就是不能工作的。
Java是一个静态类型的语言,但静态类型检查是一种非常局限性的测试,只是说明编译器接受你代码中的语法和基本类型规则,并不意味着你的代码达到程序的目标。
1.1 单元测试
==“单元”是指测试一小部分代码 。通常,每个类都有测试来检查它所有方法的行为。“系统”==测试则是不同的,它检查的是整个程序是否满足要求。
1.2 JUnit
在 JUnit 最简单的使用中,使用 @Test 注解标记表示测试的每个方法。JUnit 将这些方法标识为单独的测试,并一次设置和运行一个测试,采取措施避免测试之间的副作用。
package validating;import java.util.ArrayList;public class CountedList extends ArrayList<String> {private static int counter = 0;private int id=counter++;public CountedList() {System.out.println("CountedList #" + id);}public int getId() {return id;}
}
package validating;import org.junit.jupiter.api.*;import java.util.Arrays;
import java.util.List;import static org.junit.jupiter.api.Assertions.assertArrayEquals;
import static org.junit.jupiter.api.Assertions.assertEquals;public class CountedListTest {private CountedList list;@BeforeAllstatic void beforeAllMsg() {System.out.println(">>> Starting CountedListTest");}@AfterAllstatic void afterAllMsg() {System.out.println(">>> Finished CountedListTest");}@BeforeEachpublic void initialize() {list = new CountedList();System.out.println("Set up for " + list.getId());for (int i = 0; i < 3; i++) {list.add(Integer.toString(i));}}@AfterEachpublic void cleanup() {System.out.println("Cleaning up " + list.getId());}@Testpublic void insert() {System.out.println("Running testInsert()");assertEquals(list.size(), 3);list.add(1, "Insert");assertEquals(list.size(), 4);assertEquals(list.get(1), "Insert");}@Testpublic void replace() {System.out.println("Running testReplace()");assertEquals(list.size(), 3);list.set(1, "Replace");assertEquals(list.size(), 3);assertEquals(list.get(1), "Replace");}private void compare(List<String> lst, String[] strs) {assertArrayEquals(lst.toArray(new String[0]), strs);}@Testpublic void order() {System.out.println("Running testOrder()");compare(list, new String[]{"0", "1", "2"});}@Testpublic void remove() {System.out.println("Running testRemove()");assertEquals(list.size(), 3);list.remove(1);assertEquals(list.size(), 2);compare(list, new String[]{"0", "2"});}@Testpublic void addAll() {System.out.println("Running testAddAll()");list.addAll(Arrays.asList(new String[]{"An", "African", "Swallow"}));assertEquals(list.size(), 6);compare(list, new String[]{"0", "1", "2", "An", "African", "Swallow"});}
}
输出:
>>> Starting CountedListTest
CountedList #0
Set up for 0
Running testAddAll()
Cleaning up 0
CountedList #1
Set up for 1
Running testInsert()
Cleaning up 1
CountedList #2
Set up for 2
Running testRemove()
Cleaning up 2
CountedList #3
Set up for 3
Running testOrder()
Cleaning up 3
CountedList #4
Set up for 4
Running testReplace()
Cleaning up 4
>>> Finished CountedListTest
@BeforeAll 注解是在任何其他测试操作之前运行一次的方法。 @AfterAll 是所有其他测试操作之后只
运行一次的方法。两个方法都必须是静态的。
@BeforeEach注解是通常用于创建和初始化公共对象的方法,并在每次测试前运行。可以将所有这样
的初始化放在测试类的构造函数中。
—PS:@BeforeAll 是只运行一次,@BeforeEach 是每次都运行,例子中有5个 @Test 注释的方法,@BeforeEach 就运行了5次
JUnit 使用 @Test 注解发现这些方法,并将每个方法作为测试运行。在方法内部,你可以执行任何所需的操作并使用 JUnit 断言方法(以"assert"开头)验证测试的正确性(更全面的"assert"说明可以在 Junit 文档里找到)。如果断言失败,将显示导致失败的表达式和值。
1.3 测试覆盖率的幻觉
测试覆盖率,同样也称为代码覆盖率,度量代码的测试百分比。百分比越高,测试的覆盖率越大。
对于没有知识但处于控制地位的人来说,很容易在没有任何了解的情况下也有概念认为 100% 的测试覆盖是唯一可接受的值。这有一个问题,因为 100% 并不意味着是对测试有效性的良好测量。你可以测试所有需要它的东西,但是只需要 65% 的覆盖率。如果需要 100% 的覆盖,你将浪费大量时间来生成剩余的代码,并且在向项目添加代码时浪费的时间更多。
当分析一个未知的代码库时,测试覆盖率作为一个粗略的度量是有用的。如果覆盖率工具报告的值特别低(比如,少于百分之40),则说明覆盖不够充分。然而,一个非常高的值也同样值得怀疑,这表明对编程领域了解不足的人迫使团队做出了武断的决定。覆盖工具的最佳用途是发现代码库中未测试的部分。但是,不要依赖覆盖率来得到测试质量的任何信息。
—PS:我有理由怀疑在内涵什么
2. 前置条件
前置条件的概念来自于契约式设计(Design By Contract, DbC), 利用断言机制实现。
2.1 断言(Assertions)
断言通过验证在程序执行期间满足某些条件,从而增加了程序的健壮性。举例,假设在一个对象中有一个数值字段表示日历上的月份。这个数字总是介于 1-12 之间。断言可以检查这个数字,如果超出了该范围,则报告错误。如果在方法的内部,则可以使用断言检查参数的有效性。这些是确保程序正确的重要测试,但是它们不能在编译时被检查,并且它们不属于单元测试的范围。
2.2 Java 断言语法
断言语句有两种形式 :
-
assert boolean-expression;
-
assert boolean-expression: information-expression;
2.3 Guava 断言
因为启用 Java 本地断言很麻烦,Guava 团队添加一个始终启用的用来替换断言的 Verify 类。
2.4 使用断言进行契约式设计
契约式设计*(DbC)*是 Eiffel 语言的发明者 Bertrand Meyer 提出的一个概念,通过确保对象遵循某些规则来帮助创建健壮的程序。
Meyer 认为:
1.应该明确指定行为,就好像它是一个契约一样。
2.通过实现某些运行时检查来保证这种行为,他将这些检查称为前置条件、后置条件和不变项。
2.4.1 检查指令
详细研究 DbC 之前,思考最简单使用断言的办法,Meyer 称它为检查指令。检查指令说明你确信代码中的某个特定属性此时已经得到满足。
在化学领域,你也许会用一种纯液体去滴定测量另一种液体,当达到一个特定的点时,液体变蓝了。 从两个液体的颜色上并不能明显看出;这是复杂反应的一部分。滴定完成后一个有用的检查指令是能够断定液体变蓝了。
检查指令是对你的代码进行补充,当你可以测试并阐明对象或程序的状态时,应该使用它。
2.4.2 前置条件
前置条件确保客户端(调用此方法的代码)履行其部分契约。这意味着在方法调用开始时几乎总是会检查参数(在你用那个方法做任何操作之前)以此保证它们的调用在方法中是合适的。因为你永远无法知道客户端会传递给你什么,前置条件是确保检查的一个好做法。
—PS:checkdata
2.4.3 后置条件
后置条件测试你在方法中所做的操作的结果。这段代码放在方法调用的末尾,在 return 语句之前(如果有的话)。对于长时间、复杂的方法,在返回计算结果之前需要对计算结果进行验证(也就是说,在某些情况下,由于某种原因,你不能总是相信结果),后置条件很重要,但是任何时候你可以描述方法结果上的约束时,最好将这些约束在代码中表示为后置条件。
—PS:review
2.4.4 不变性
不变性保证了必须在方法调用之间维护的对象的状态。但是,它并不会阻止方法在执行过程中暂时偏离这些保证,它只是在说对象的状态信息应该总是遵守状态规则:
-
1. 在进入该方法时。
-
2. 在离开方法之前。
此外,不变性是构造后对于对象状态的保证。
根据这个描述,一个有效的不变性被定义为一个方法,可能被命名为 invariant() ,它在构造之后以及每个方法的开始和结束时调用。方法以如下方式调用:
assert invariant();
2.4.5 放松 DbC 检查或非严格的 DbC
尽管 Meyer 强调了前置条件、后置条件和不变性的价值以及在开发过程中使用它们的重要性,他承认在一个产品中包含所有 DbC 代码并不总是实际的。你可以基于对特定位置的代码的信任程度放松 DbC 检查。
2.4.6 使用 Guava 前置条件
谷歌的 Guava 库包含了一组很好的前置条件测试,这些测试不仅易于使用,而且命名也足够好。
首先引入依赖
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>21.0</version></dependency>
import java.util.function.Consumer;import static com.google.common.base.Preconditions.*;public class GuavaPreconditions {static void test(Consumer<String> c, String s) {try {System.out.println(s);c.accept(s);System.out.println("Success");} catch (Exception e) {String type = e.getClass().getSimpleName();String msg = e.getMessage();System.out.println(type + (msg == null ? "" : ": " + msg));}}public static void main(String[] args) {test(s -> s = checkNotNull(s), "X");test(s -> s = checkNotNull(s), null);test(s -> s = checkNotNull(s, "s was null"), null);test(s -> s = checkNotNull(s, "s was null, %s %s", "arg2", "arg3"), null);test(s -> checkArgument(s == "Fozzie"), "Fozzie");test(s -> checkArgument(s == "Fozzie"), "X");test(s -> checkArgument(s == "Fozzie"), null);test(s -> checkArgument(s == "Fozzie", "Bear Left!"), null);test(s -> checkArgument(s == "Fozzie", "Bear Left! %s Right!", "Frog"), null);test(s -> checkState(s.length() > 6), "Mortimer");test(s -> checkState(s.length() > 6), "Mort");test(s -> checkState(s.length() > 6), null);test(s -> checkElementIndex(6, s.length()), "Robert");test(s -> checkElementIndex(6, s.length()), "Bob");test(s -> checkElementIndex(6, s.length()), null);test(s -> checkPositionIndex(6, s.length()), "Robert");test(s -> checkPositionIndex(6, s.length()), "Bob");test(s -> checkPositionIndex(6, s.length()), null);test(s -> checkPositionIndexes(0, 6, s.length()), "Hieronymus");test(s -> checkPositionIndexes(0, 10, s.length()), "Hieronymus");test(s -> checkPositionIndexes(0, 11, s.length()), "Hieronymus");test(s -> checkPositionIndexes(-1, 6, s.length()), "Hieronymus");test(s -> checkPositionIndexes(7, 6, s.length()), "Hieronymus");test(s -> checkPositionIndexes(0, 6, s.length()), null);}
}
输出:
X
Success
null
NullPointerException
null
NullPointerException: s was null
null
NullPointerException: s was null, arg2 arg3
Fozzie
Success
X
IllegalArgumentException
null
IllegalArgumentException
null
IllegalArgumentException: Bear Left!
null
IllegalArgumentException: Bear Left! Frog Right!
Mortimer
Success
Mort
IllegalStateException
null
NullPointerException
Robert
IndexOutOfBoundsException: index (6) must be less than size (6)
Bob
IndexOutOfBoundsException: index (6) must be less than size (3)
null
NullPointerException
Robert
Success
Bob
IndexOutOfBoundsException: index (6) must not be greater than size (3)
null
NullPointerException
Hieronymus
Success
Hieronymus
Success
Hieronymus
IndexOutOfBoundsException: end index (11) must not be greater than size (10)
Hieronymus
IndexOutOfBoundsException: start index (-1) must not be negative
Hieronymus
IndexOutOfBoundsException: end index (6) must not be less than start index (7)
null
NullPointerException
每个前置条件都有三种不同的重载形式:一个什么都没有,一个带有简单字符串消息,以及带有一个字符串和替换值。
在上面的例子中,演示了 checkNotNull() 和 checkArgument() 这两种形式。但是它们对于所有前置条件方法都是相同的。注意 checkNotNull() 的返回参数, 所以你可以在表达式中内联使用它。下面是如何在构造函数中使用它来防止包含 Null 值的对象构造:
import static com.google.common.base.Preconditions.checkNotNull;public class NonNullConstruction {private Integer n;private String s;public NonNullConstruction(Integer n, String s) {this.n = checkNotNull(n);this.s = checkNotNull(s);}public static void main(String[] args) {NonNullConstruction nnc = new NonNullConstruction(3, "Trousers");}
}
-
checkArgument() 接受布尔表达式来对参数进行更具体的测试, 失败时抛出 IllegalArgumentException
-
checkState() 用于测试对象的状态(例如,不变性检查),而不是检查参
数,并在失败时抛出 IllegalStateException 。
最后三个方法在失败时抛出 IndexOutOfBoundsException:
-
checkElementIndex() 确保其第一个参数是列表、字符串或数组的有效元素索引,其大小由第二个参数指定
-
checkPositionIndex() 确保它的第一个参数在 0 到第二个参数(包括第二个参数)的范围内。
-
checkPositionIndexes() 检查 [first_arg, second_arg] 是一个列表的有效子列表,由第三个参数指定大小的字符串或数组。
3. 测试驱动开发
之所以可以有测试驱动开发(TDD)这种开发方式,是因为如果你在设计和编写代码时考虑到了测试,那么你不仅可以写出可测试性更好的代码,而且还可以得到更好的代码设计。
纯粹的 TDD 主义者会在实现新功能之前就为其编写测试,这称为测试优先的开发。
测试驱动 vs. 测试优先
虽然我自己还没有达到测试优先的意识水平,但我最感兴趣的是来自测试优先中的==“测试失败的书签”==这一概念。 当你离开你的工作一段时间后,重新回到工作进展中,甚至找到你离开时工作到的地方有时会很有挑战性。 然而,以失败的测试为书签能让你找到之前停止的地方。 这似乎让你能更轻松地暂时离开你的工作,因为不用担心找不到工作进展的位置。
纯粹的测试优先编程的主要问题是它假设你事先了解了你正在解决的问题。 根据我自己的经验,我通常是从实验开始,而只有当我处理问题一段时间后,我对它的理解才会达到能给它编写测试的程度。
—PS:这个要求有点高
当然,偶尔会有一些问题在你开始之前就已经完全定义,但我个人并不常遇到这些问题。 实际上,可能用==“面向测试的开发 ( Test-Oriented Development )”==这个短语来描述编写测试良好的代码或许更好。
4. 日志
4.1 日志会给出正在运行的程序的各种信息。
在调试程序中,日志可以是普通状态数据,用于显示程序运行过程(例如,安装程序可能会记录安装过程中采取的步骤,存储文件的目录,程序的启动值等)。
业内普遍认为标准 Java 发行版本中的日志包 (java.util.logging) 的设计相当糟糕。 大多数人会选择其他的替代日志包。如 Simple Logging Facade for Java(SLF4J) ,它为多个日志框架提供了一个封装好的调用方式,这些日志框架包括 java.util.logging , logback 和 log4j 。 SLF4J 允许用户在部署时插入所需的日志框架。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class SLF4JLogging {private static Logger log= LoggerFactory.getLogger(SLF4JLogging.class);public static void main(String[] args) {log.info("hello logging");}
}
输出:
14:07:59.401 [main] INFO validating.SLF4JLogging - hello logging
4.2 日志等级
SLF4J 提供了多个等级的日志消息。下面这个例子以“严重性”的递增顺序对它们作出演示:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class SLF4JLevels {private static Logger log = LoggerFactory.getLogger(SLF4JLevels.class);public static void main(String[] args) {log.trace("Hello");log.debug("Logging");log.info("Using");log.warn("the SLF4J");log.error("Facade");}
}
输出:
15:07:50.873 [main] DEBUG validating.SLF4JLevels - Logging
15:07:50.875 [main] INFO validating.SLF4JLevels - Using
15:07:50.875 [main] WARN validating.SLF4JLevels - the SLF4J
15:07:50.875 [main] ERROR validating.SLF4JLevels - Facade
5. 调试
使用 System.out 或日志信息能给我们带来对程序行为的有效见解,但对于困难问题来说,这种方式就显得笨拙且耗时了。
此时你需要调试器。除了比打印语句更快更轻易地展示信息以外,调试器还可以设置断点,并在程序运行到这些断点处暂停程序。
使用调试器,可以展示任何时刻的程序状态,查看变量的值,一步一步运行程序,连接远程运行的程序等等。
5.1 使用 JDB 调试
Java 调试器(JDB)是 JDK 内置的命令行工具。从调试的指令和命令行接口两方面看的话,JDB 至少从概念上是 GNU 调试器(GDB,受 Unix DB 的影响)的继承者。
public class SimpleDebugging {private static void foo1() {System.out.println("In foo1");foo2();}private static void foo2() {System.out.println("In foo2");foo3();}private static void foo3() {System.out.println("In foo3");int j = 1;j--;int i = 5 / j;}public static void main(String[] args) {foo1();}
}
输出:
In foo1
In foo2
In foo3
Exception in thread "main" java.lang.ArithmeticException: / by zeroat validating.SimpleDebugging.foo3(SimpleDebugging.java:23)at validating.SimpleDebugging.foo2(SimpleDebugging.java:16)at validating.SimpleDebugging.foo1(SimpleDebugging.java:11)at validating.SimpleDebugging.main(SimpleDebugging.java:27)
为了运行 JDB,你需要在编译 SimpleDebugging.java 时加上 -g 标记,从而告诉编译器生成编译信息。然后使用如下命令开始调试程序:
另开一篇:开发技术-使用 JDB 调试
5.2 图形化调试器
使用类似 JDB 的命令行调试器是不方便的。使用图形化调试器能更加高效、更快速地追踪 bug。IBM 的 Eclipse,Oracle 的 NetBeans 和 JetBrains 的 IntelliJ 这些集成开发环境都含有面向 Java 语言的好用的图形化调试器。
6. 基准测试
我们应该忘掉微小的效率提升,说的就是这些 97% 的时间做的事:过早的优化是万恶之源。
—— Donald Knuth
通常,一个简单直接的编码方法就足够好了。如果你进行了不必要的优化,就会使你的代码变得无谓的复杂和难以理解。
基准测试意味着对代码或算法片段进行计时看哪个跑得更快。
6.1 微基准测试
写一个计时工具类从而比较不同代码块的执行速度是具有吸引力的。看上去这会产生一些有用的数据。比如,这里有一个简单的 Timer 类,可以用以下两种方式使用它:
import static java.util.concurrent.TimeUnit.NANOSECONDS;public class Timer {// PS:获取时间戳,纳秒级private long start = System.nanoTime();// PS:产生以毫秒为单位的运行时间public long duration() {return NANOSECONDS.toMillis(System.nanoTime() - start);}public static long duration(Runnable test) {Timer timer = new Timer();test.run();return timer.duration();}
}
import java.util.Arrays;public class BadMicroBenchmark {static final int SIZE = 250_000_000;public static void main(String[] args) {try {long[] la = new long[SIZE];System.out.println("setAll: " + Timer.duration(() -> Arrays.setAll(la, n -> n)));System.out.println("parallelSetAll: " + Timer.duration(() -> Arrays.parallelSetAll(la, n -> n)));} catch (OutOfMemoryError e) {System.out.println("Insufficient memory");System.exit(0);}}
}
输出:
setAll: 188
parallelSetAll: 165
6.2 JMH 的引入
截止目前为止,唯一能产生像样结果的 Java 微基准测试系统就是 Java Microbenchmarking Harness,简称 JMH。
7. 剖析和优化
剖析器可以找到这些导致程序慢的地方,剖析器收集的信息能显示程序哪一部分消耗内存,哪个方法最耗时。一些剖析器甚至能关闭垃圾回收,从而帮助限定内存分配的模式,剖析器还可以帮助检测程序中的线程死锁。
安装 Java 开发工具包(JDK)时会顺带安装一个虚拟的剖析器,叫做 VisualVM。
7.1 优化准则
-
避免为了性能牺牲代码的可读性。
-
不要独立地看待性能。衡量与带来的收益相比所需投入的工作量。
-
程序的大小很重要。性能优化通常只对运行了长时间的大型项目有价值。性能通常不是小项目的关注点。
-
运行起来程序比一心钻研它的性能具有更高的优先级。一旦你已经有了可工作的程序,如有必要的话,你可以使用剖析器提高它的效率。只有当性能是关键因素时,才需要在设计/开发阶段考虑性能。
-
不要猜测瓶颈发生在哪。运行剖析器,让剖析器告诉你。
-
无论何时有可能的话,显式地设置实例为 null 表明你不再用它。这对垃圾收集器来说是个有用的暗示。
-
static final 修饰的变量会被 JVM 优化从而提高程序的运行速度。因而程序中的常量应该声明 static final。
—PS:程序能跑起来再说其他
8. 风格检测
当你在一个团队中工作时(包括尤其是开源项目),让每个人遵循相同的代码风格是非常有帮助的。这样阅读项目的代码时,不会因为风格的不同产生思维上的中断。幸运的是,存在可以指出你代码中不符合风格准则的工具。
一个流行的风格检测器是 Checkstyle。
—PS:制定准则不难,难的是怎么让人遵守
9. 静态错误分析
尽管 Java 的静态类型检测可以发现基本的语法错误,其他的分析工具可以发现躲避 javac 检测的更加
复杂的bug。一个这样的工具叫做 Findbugs。
10. 代码重审
代码重审是一个或一群人的一段代码被另一个或一群人阅读和评估的众多方式之一。它的目标是找到程序中的错误,代码重审是最成功的能做到这点的途径之一。可惜的是,它们也经常被认为是“过于昂贵的”(有时这会成为程序员避免代码被重审时感到尴尬的借口)。
11. 结对编程
结对编程是指两个程序员一起编程的实践活动。通常来说,一个人“驱动”(敲击键盘,输入代码),另一人(观察者或指引者)重审和分析代码,同时也要思考策略。这产生了一种实时的代码重审。通常程序员会定期地互换角色。
结对编程有很多好处,但最显著的是分享知识和防止阻塞。
有时很难向管理人员们推行结对编程,因为他们可能觉得两个程序员解决同一个问题的效率比他们分开解决不同问题的效率低。尽管短期内是这样,但是结对编程能带来更高的代码质量,产生更高的生产力。
12. 重构
技术负债是指迭代发展的软件中为了应急而生的丑陋解决方案从而导致设计难以理解,代码难以阅读的部分。特别是当你必须修改和增加新特性的时候,这会造成麻烦。
—PS:shit山
重构可以矫正技术负债。重构的关键是它能改善代码设计,结构和可读性(因而减少代码负债),但是它不能改变代码的行为。
很难向管理人员推行重构:“我们将投入很多工作不是增加新的特性,当我们完成时,外界无感知变化。”。不幸的是,管理人员意识到重构的价值时都为时已晚了: 当他们提出增加新的特性时,你不得不告诉他们做不到,因为代码基底已经埋藏了太多的问题,试图增加新特性可能会使软件崩溃,即使你能想出怎么做。
12.1 重构基石
在开始重构代码之前,你需要有以下三个系统的支撑:
-
测试(通常,JUnit 测试作为最小的根基),因此你能确保重构不会改变代码的行为。
-
自动构建,因而你能轻松地构建代码,运行所有的测试。
-
版本控制,以便你能回退到可工作的代码版本,能够一直记录重构的每一步。
13. 持续集成
在软件开发的早期,人们只能一次处理一步,每个开发阶段无缝进入下一个。这种错觉经常被称为软件开发中的“瀑布流模型”。
产品本身经常也不是对客户有价值的事物。有时一大堆的特性完全是浪费时间,因为创造出这些特性需求的人不是客户而是其他人。
上游团队的延期传递到下游团队,当到了需要进行测试和集成的时候,这些团队被指望赶上预期时间,当他们必然做不到时,就认为他们是“差劲的团队成员”。
另外,商学院培养出的管理人员仍然被训练成只在已有的流程上做一些改动。
终于一些编程领域的人们再也忍受不了这种情况并开始进行实验。最初一些实验叫做“极限编程”,因为它们与工业时代的思想完全不同。这些实验逐渐形成了如今显而易见的观点——尽管非常小——即把生产可运作的产品交到客户手中,询问他们 (A) 是否想要它 (B) 是否喜欢它工作的方式 © 还希望有什么其他有用的功能特性。然后这些信息反馈给开发,从而继续产出一个新版本。版本不断迭代,项目最终演变成为客户带来真正价值的事物。
这完全颠倒了瀑布流开发的方式。每件事从开始到结束必须都在进行——即使一开始产品几乎没有任何特性。这么做对于在 开发周期的早期发现更多问题有巨大的益处。此外,不是做大量宏大超前的计划和花费时间金钱在许多无用的特性上,而是一直都能从顾客那得到反馈。当客户不再需要其他特性时,你就完成了。这节省了大量的时间和金钱,并提高了顾客的满意度。
有许多不同的想法导向这种方式,但是目前首要的术语叫持续集成(CI)。
—PS:瀑布流开发,只能一步接着一步,一个环节的延期后延续到后面的环节,在前期可能会花费巨大的成本去做计划和调研,结果做出来的产品包含了许多对客户无用的特性。CI 就是为了解决以上的问题,每次快速交付小功能为客户,再根据客户的反馈及需求进行下一步开发。
当前 CI 技术的高峰是持续集成服务器。正如重构一样,持续集成需要分布式版本管理,自动构建和自动测试系统作为基础。通常来说,CI 服务器会绑定到你的版本控制仓库上。当 CI 服务器发现仓库中有改变时,就会拉取最新版本的代码,并按照 CI 脚本中的过程处理。接着它会执行脚本中定义的构建和测试操作;通常脚本中使用的命令与人们在安装和测试中使用的命令完全相同。如果执行成功或失败,CI 服务器会有许多种方式汇报给你,包括在你的代码仓库上显示一个简单的标记。
—PS:一般使用的工具有 Git Gitlab Maven Jenkins ,即常说的流水线发布那一套
14. 本章小结
代码校验不是单一的过程或技术。每种方法只能发现特定类型的 bug,作为程序员的你在开发过程中会明白每个额外的技术都能增加代码的可靠性和鲁棒性。校验不仅能在开发过程中,还能在为应用添加 新功能的整个项目期间帮你发现更多的错误。现代化开发意味着比仅仅编写代码更多的内容,每种你在开发过程中融入的测试技术—— 包括而且尤其是你创建的能适应特定应用的自定义工具——都会带来更好、更快和更加愉悦的开发过程,同时也能为客户提供更高的价值和满意度体验。
自我学习总结:
- 单元测试简单理解为测试每一个方法
- 常用的 Java 单元测试框架为 JUnit,它包含的注解有 @Test @BeforeAll @AfterAll @BeforeEach @AfterEach
- 测试覆盖率并不是需要达到 100%,因为性价比不高
- 契约式设计*(DbC)*包含前置条件、后置条件、不变项等检查
- 谷歌的 Guava 库包含了一组很好的前置条件测试,这些测试不仅易于使用,而且命名也足够好
- 大佬都是测试优先
- 日志相关推荐一篇大佬的文章:Java日志框架&日志门面介绍
- SLF4J 日志等级从低到高为:trace debug info warn error
- 代码优化要遵循准则
- 一个好的开发应该做好单元测试、遵循良好的开发规范,一个好的项目组还需要做好代码重审
- 好听的叫技术负债,不好听就是代码屎山,重构就是还债,费时费力,不重构的话,系统越来越沉重。
- CI ,每次快速交付小功能为客户,再根据客户的反馈及需求进行下一步开发
(图网,侵删)
相关文章:
读书笔记-《ON JAVA 中文版》-摘要16[第十六章 代码校验]
文章目录 第十六章 代码校验1. 测试1.1 单元测试1.2 JUnit1.3 测试覆盖率的幻觉 2. 前置条件2.1 断言(Assertions)2.2 Java 断言语法2.3 Guava 断言2.4 使用断言进行契约式设计2.4.1 检查指令2.4.2 前置条件2.4.3 后置条件2.4.4 不变性2.4.5 放松 DbC 检…...

SQL Server:打造高效数据管理系统的利器
使用SQL Server进行数据管理 简介 SQL Server是由Microsoft开发的一款关系型数据库管理系统,它可以用于存储和管理大量结构化数据。本篇博客将介绍如何使用SQL Server进行数据管理。 数据库连接 在开始使用SQL Server之前,需要先建立与数据库的连接。…...

代码随想录二刷day20 | 二叉树之 654.最大二叉树 617.合并二叉树 700.二叉搜索树中的搜索 98.验证二叉搜索树
day20 654.最大二叉树617.合并二叉树700.二叉搜索树中的搜索98.验证二叉搜索树 654.最大二叉树 题目链接 解题思路: 本题属于构造二叉树,需要使用前序遍历,因为先构造中间节点,然后递归构造左子树和右子树。 确定递归函数的参数…...

python基础知识(十三):numpy库的基本用法
目录 1. numpy的介绍2. numpy库产生矩阵2.1 numpy将列表转换成矩阵2.2 numpy创建矩阵 3. numpy的基础运算4. numpy的基础运算25. 索引 1. numpy的介绍 numpy库是numpy是python中基于数组对象的科学计算库。 2. numpy库产生矩阵 2.1 numpy将列表转换成矩阵 import numpy as …...
线程函数 tp_recv_thread() 源码分析)
【SA8295P 源码分析】16 - TouchScreen Panel (TP)线程函数 tp_recv_thread() 源码分析
【【SA8295P 源码分析】16 - TouchScreen Panel (TP)线程函数 tp_recv_thread 源码分析 一、TP 线程函数:tp_recv_thread()二、处理&上报 坐标数据 cypress_read_touch_data()系列文章汇总见:《【SA8295P 源码分析】00 - 系列文章链接汇总》 本文链接:《【SA8295P 源码…...
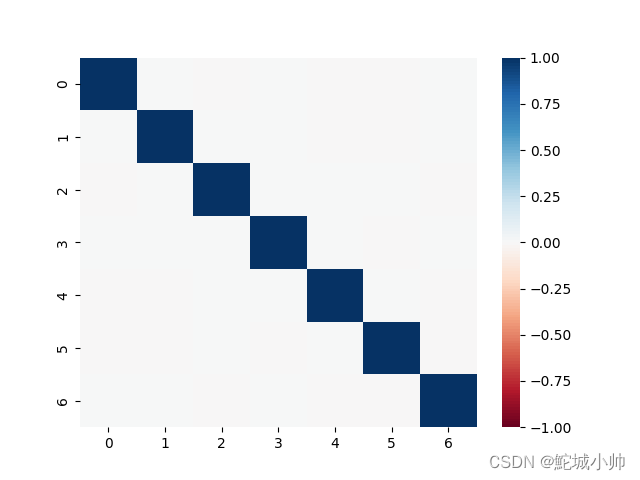
Python3数据分析与挖掘建模(13)复合分析-因子关分析与小结
1.因子分析 1.1 探索性因子分析 探索性因子分析(Exploratory Factor Analysis,EFA)是一种统计方法,用于分析观测变量之间的潜在结构和关联性。它旨在确定多个观测变量是否可以归结为较少数量的潜在因子,从而帮助简化…...
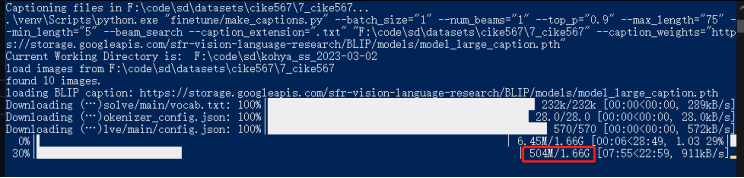
【stable diffusion】图片批量自动打标签、标签批量修改(BLIP、wd14)用于训练SD或者LORA模型
参考: B站教学视频【:AI绘画】新手向!Lora训练!训练集准备、tag心得、批量编辑、正则化准备】官方教程:https://github.com/darkstorm2150/sd-scripts/blob/main/docs/train_README-en.md#automatic-captioning 一、…...

TCP可靠数据传输
TCP的可靠数据传输 1.TCP保证可靠数据传输的方法 TCP主要提供了检验和、序号/确认号、超时重传、最大报文段长度、流量控制等方法实现了可靠数据传输。 检验和 通过检验和的方式,接收端可以检测出来数据是否有差错和异常,假如有差错就会直接丢失该TC…...

Python 私有变量和私有方法介绍
Python 私有变量和私有方法介绍 关于 Python 私有变量和私有方法,通常情况下,开发者可以在方法或属性名称前加上单下划线(_),以表示该方法或属性仅供内部使用,但这只是一种约定,并没有强制执行禁…...
Kotlin Lambda表达式和匿名函数的组合简直太强了
Kotlin Lambda表达式和匿名函数的组合简直太强了 简介 首先,在 Kotlin 中,函数是“第一公民”(First Class Citizen)。因此,它们可以被分配为变量的值,作为其他函数的参数传递或者函数的返回值。同样&…...

uniapp 小程序 获取手机号---通过前段获取
<template><!-- 获取手机号,登录内容 --><view><!-- 首先需要先登录获取code码,然后才可以获取用户唯一标识openid以及会话密钥及用于解密获取手机的加密信息 --><view click"login">登录</view><view…...

面板安全能力持续增强,新增日志审计功能,1Panel开源面板v1.3.0发布
2023年6月12日,现代化、开源的Linux服务器运维管理面板1Panel正式发布v1.3.0版本。 在这一版本中,1Panel进一步增强了安全方面的能力,包括新增SSH配置管理、域名绑定和IP授权支持,以及启用网站防盗链功能。此外,该版本…...
k8s学习-CKS考试必过宝典
目录 CKS考纲集群安装:10%集群强化:15%系统强化:15%微服务漏洞最小化:20%供应链安全:20%监控、日志记录和运行时安全:20% 报名模拟考试考试注意事项考前考中考后 参考 CKS考纲 集群安装:10% 使…...

jmeter如何将上一个请求的结果作为下一个请求的参数
目录 1、简介 2、用途 3、下载、简单应用 4、如何将上一个请求的结果作为下一个请求的参数 1、简介 在JMeter中,可以通过使用变量来将上一个请求的结果作为下一个请求的参数传递。 ApacheJMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测…...

JAVA如何学习爬虫呢?
学习Java爬虫需要掌握以下几个方面: Java基础知识:包括Java语法、面向对象编程、集合框架等。 网络编程:了解HTTP协议、Socket编程等。 HTML、CSS、JavaScript基础:了解网页的基本结构和样式,以及JavaScript的基本语…...

距离保护原理
距离保护是反映故障点至保护安装处的距离,并根据距离的远近确定动作时间的一种保护。故障点距保护安装处越近,保护的动作时间就越短,反之就越长,从而保证动作的选择性。测量故障点至保护安装处的距离,实际上就是用阻抗…...
从微观世界的RST包文视角助力企业网络应用故障排查和优化
1. 前言 随着互联网的普及和发展,各行业的业务和应用越来越依赖于网络。然而,网络环境的不稳定性和复杂性使得出现各种异常现象的概率变得更高了。这些异常现象会导致业务无法正常运行,给用户带来困扰,甚至影响企业的形象和利益。…...

企业微信开发,简单测试。
企业微信开发,参考文档: https://github.com/wechat-group/WxJava/wiki...

element日期选择设置默认时间el-date-picker
<el-date-pickerv-model"rangeDate"style"width:350px"type"daterange"value-format"yyyy-MM-dd"change"dataChange"start-placeholder"开始日期"end-placeholder"结束日期"></el-date-picker…...
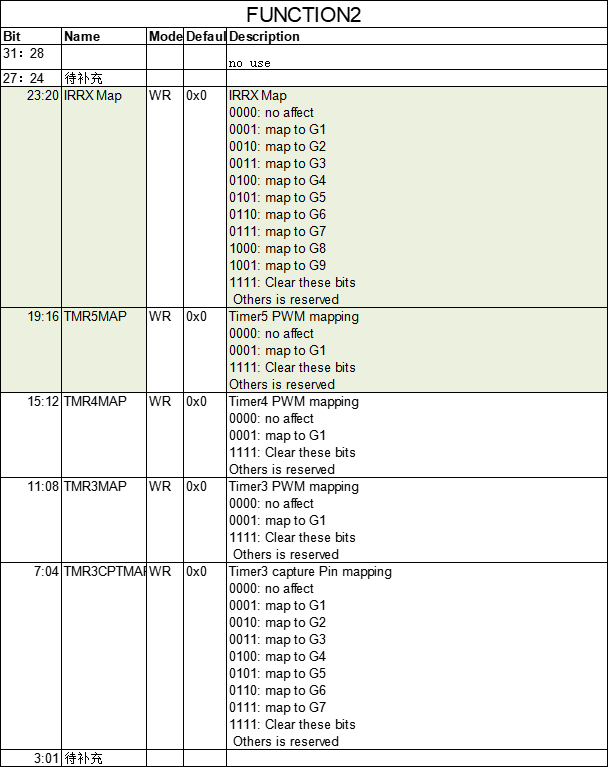
AB32VG:SDK_AB53XX_V061(3)IO口复用功能的补充资料
文章目录 1.IO口功能复用表格2.功能映射寄存器 FUNCTION03.功能映射寄存器 FUNCTION14.功能映射寄存器 FUNCTION2 AB5301A的官方数据手册很不完善,没有开放出来。我通过阅读源码补充了一些关于IO口功能复用寄存器的资料。 官方寄存器文档:《 AB32VG1_Re…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

(一)单例模式
一、前言 单例模式属于六大创建型模式,即在软件设计过程中,主要关注创建对象的结果,并不关心创建对象的过程及细节。创建型设计模式将类对象的实例化过程进行抽象化接口设计,从而隐藏了类对象的实例是如何被创建的,封装了软件系统使用的具体对象类型。 六大创建型模式包括…...