基于DBACAN的道路轨迹点聚类
目录
- 前言
- 道路栅格化
- 轨迹聚类
- 参考资料
前言
很多针对道路轨迹的挖掘项目前期都需要对道路进行一段一段的分割成路段,然后对每一个路段来单独进行考察,如设定路段限速标识,超速概率等,如何对道路进行划分,其实是一个很有技巧性的活,最直白的有以下2种策略
-
道路栅格化
-
轨迹点聚类
下面分别对两种策略进行简单讲解。
道路栅格化

道路栅格化,简言之就是用一张纵横交错的网去尽可能覆盖道路所在的范围,这样,整个区域就被划分成一块一块的小矩形,形成栅格化,可以给每一个栅格编号,形成编号序列,而且可以判断出哪些栅格有轨迹点落入,哪些是没有轨迹点落入的,有轨迹点的栅格相对稀疏一些,此方法关键要考虑道路的经纬度最大范围和网眼大小,下面是道路栅格化处理主函数。
def roadRaster(road_data, unit_gap): #轨迹栅格化min_lng, max_lng = np.min(road_data['lng']), np.max(road_data['lng']) #经度范围min_lat, max_lat = np.min(road_data['lat']), np.max(road_data['lat']) #纬度范围lng_gap = max_lng - min_lng lat_gap = max_lat - min_latm = int(lng_gap/unit_gap)n = int(lat_gap/unit_gap)print(fleet_id, min_lng, max_lng, min_lat, max_lat, m, n, (m-1)*(n-1))slice_lng = np.linspace(min_lng, max_lng, m) #对经度等间距划分slice_lat = np.linspace(min_lat, max_lat, n) #对纬度等间距划分idx = 0for i in range(len(slice_lng)-1):for j in range(len(slice_lat)-1):raster_a_lng = slice_lng[i]raster_a_lat = slice_lat[j]raster_b_lng = slice_lng[i+1]raster_b_lat = slice_lat[j+1]idx +=1
代码解读,首先,找出道路轨迹点经纬度最大最小值,然后对经纬度跨度进行等间距划分,然后对经纬度循环,不断生成栅格左下角点的经纬度对和右上角的经纬度对,由这样对顶角的点对就可以刻画出栅格,其中,unit_gap很关键,直接决定网眼大小,按下面经纬度小数点对应精度来粗略估计
| 小数点后位数 | 精度 |
| 第1位 | 10000米 |
| 第2位 | 1000米 |
| 第3位 | 100米 |
| 第4位 | 10米 |
| 第5位 | 1米 |
| 第6位 | 0.1米 |
| 第7位 | 0.01米 |
| 第8位 | 0.001米 |
轨迹聚类
轨迹聚类,就是根据历史行驶轨迹点的稠密程度来进行聚合成一簇一簇的轨迹点集合,其中同一簇的轨迹点尽可能靠在一起,不同一簇的轨迹点尽可能分散开来,然后把一簇的轨迹点范围提炼出来,如提取其四至,这样便把整个道路进行的切分。具体可以利用DBSCAN算法实现,DBACAN是一种基于密度的聚类算法,可以用于对道路轨迹点进行聚类。具体步骤如下:
-
初始化:将所有轨迹点标记为未访问状态,并设置一个固定的邻域半径r和最小聚类数量minPts。
-
随机选择一个未访问的点p,以p为中心,搜索其邻域内所有未访问点,并将这些点标记为已访问状态。
-
如果邻域内访问点的数量小于minPts,则将p标记为噪声点,否则创建一个新的聚类,并将p加入该聚类中。
-
遍历邻域内所有访问点的邻域,将其未访问的邻域点添加到聚类中,并将其标记为已访问状态。
-
重复2-4步,直到所有点都被访问过。
-
最后,将所有噪声点从聚类中去除。
需要注意的是,选择合适的邻域半径r和最小聚类数量minPts非常重要,这会影响到聚类结果的质量。可以通过试验不同的参数来获得最佳结果,下面是利用DBSCAN算法实现轨迹点聚类的主函数。
def roadCluster(trajectory): # 使用DBSCAN聚类算法进行路段划分sample_num = int(0.6*len(trajectory))print(sample_num)trajectory_sample = trajectory.sample(sample_num) #随机抽样60%样本点 locations = np.array(trajectory_sample[['lat','lng']]) #位置数据param_grid = {"eps":[0.0005, 0.001, 0.003, 0.005, 0.006, 0.01],"min_samples":[6, 9, 15, 20, 30, 50, 70]} # epsilon控制聚类的距离阈值,min_samples控制形成簇的最小样本数dbscan = DBSCAN()grid_search = GridSearchCV(estimator= dbscan, param_grid=param_grid, scoring=myScore)grid_search.fit(locations)print("best parameters:{}".format(grid_search.best_params_))print("label:{}".format(grid_search.best_estimator_.labels_))labels = grid_search.best_estimator_.labels_ #-1表示离群点score = silhouette_score(locations, labels, metric='euclidean') #轮廓系数total_cluster = labels.max() - labels.min()print("一共聚了{}类, 轮廓系数为{}".format(total_cluster, score))road_label = pd.DataFrame({"road_label": labels})trajectory_sample.reset_index(drop=True, inplace=True)road_label.reset_index(drop=True, inplace=True)cluster_data = pd.concat([trajectory_sample, road_label], axis = 1, ignore_index=True) #带标签的行驶记录cluster_data.columns= ['lng', 'lat', 'speed', 'road_label']cluster_data['road_label'] = [str(i) for i in cluster_data['road_label']]print(cluster_data)return cluster_data
代码解读,聚类的对象locations由经纬度组成的2维数组,通过grid_search 来寻找最佳的超参数epsilon和min_samples,最后把标签类和原先的轨迹拼接起来,相当于给原先的每一个轨迹点打一个类别标签,聚类后,可以只提炼出每一类的经纬度中位数进行可视化,即用一个点来代表这一簇,效果会显得更加稀疏明显
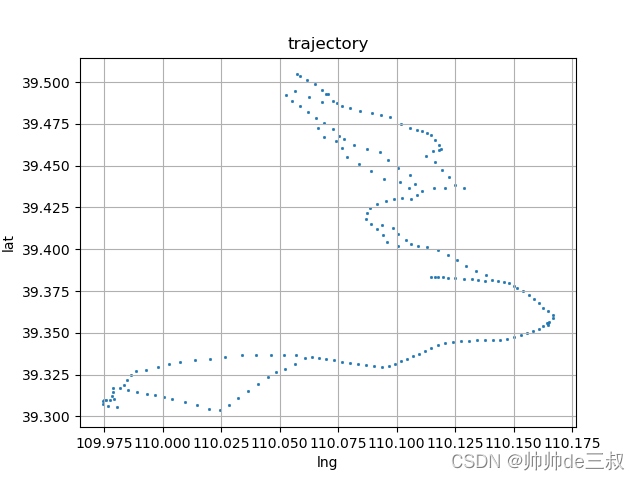
参考资料
1,经纬度坐标小数位与精度的对应关系
https://blog.csdn.net/lang_niu/article/details/123550453
2,基于DBSCAN算法的营运车辆超速点聚类分析
https://max.book118.com/html/2018/0407/160435287.shtm
相关文章:
基于DBACAN的道路轨迹点聚类
目录 前言道路栅格化轨迹聚类参考资料 前言 很多针对道路轨迹的挖掘项目前期都需要对道路进行一段一段的分割成路段,然后对每一个路段来单独进行考察,如设定路段限速标识,超速概率等,如何对道路进行划分,其实是一个很…...
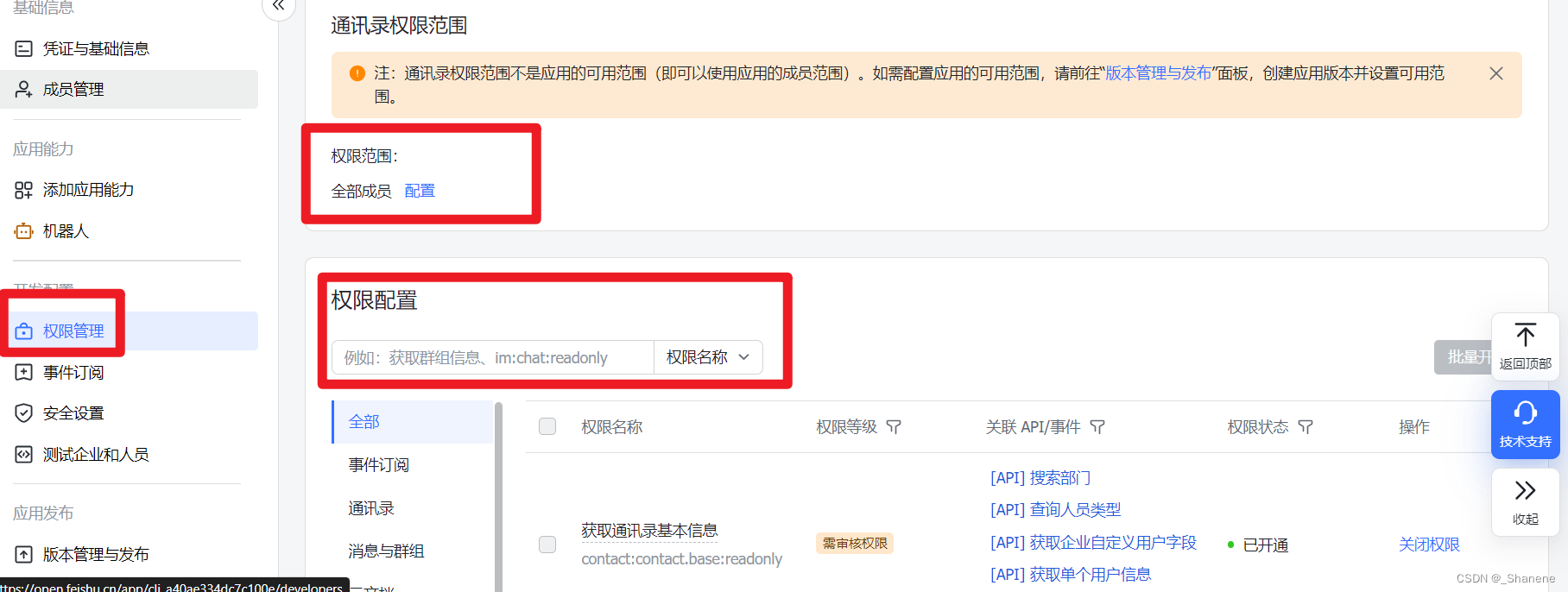
【项目】接入飞书平台
前言 项目有和飞书打通的需求,因为是第一次打通,摸索过程还是花了些时间的,现在相关笔记分享给大家。 步骤 1、熟悉开发文档 熟悉飞书的开发文档:开发文档 ,找到你需要的接口,拿我为例,我需…...
c++11 标准模板(STL)(std::ios_base)(三)
定义于头文件 <ios> class ios_base; 类 ios_base 是作为所有 I/O 流类的基类工作的多用途类。它维护数种数据: 1) 状态信息:流状态标志; 2) 控制信息:控制输入和输出序列格式化和感染的本地环境的标志; 3)…...
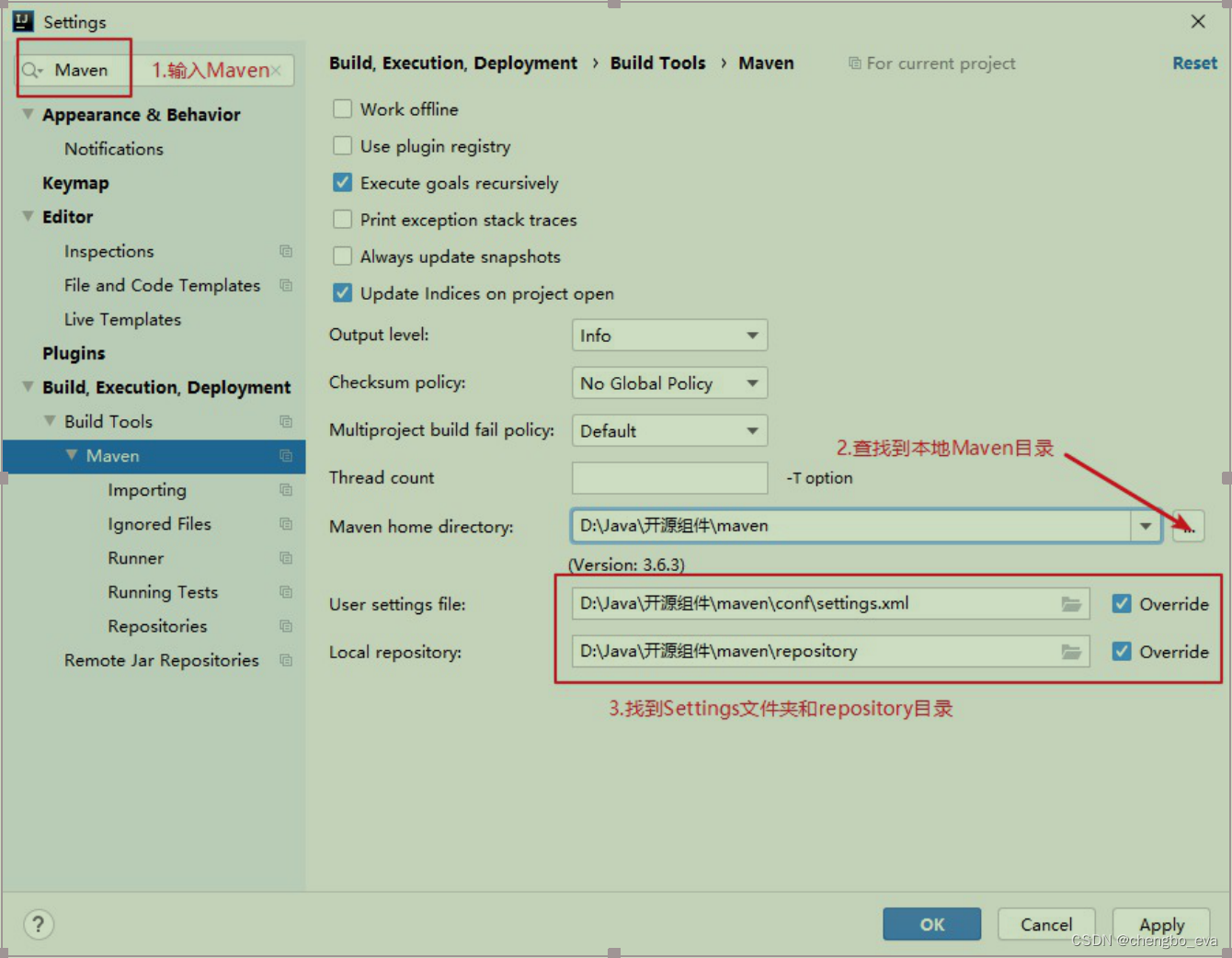
在线协同办公小程序开发搭建开发环境
目录 介绍 开发环境说明 虚拟机 原因 VirtualBox虚拟机 VMware虚拟机v15 安装MySQL数据库 安装步骤 导入EMOS系统数据库 安装MongoDB数据库 启动Navicat,选择创建MongoDB连接 创建用户 搭建Redis数据库 配置Maven 安装IDEA插件 Lombok插件 …...
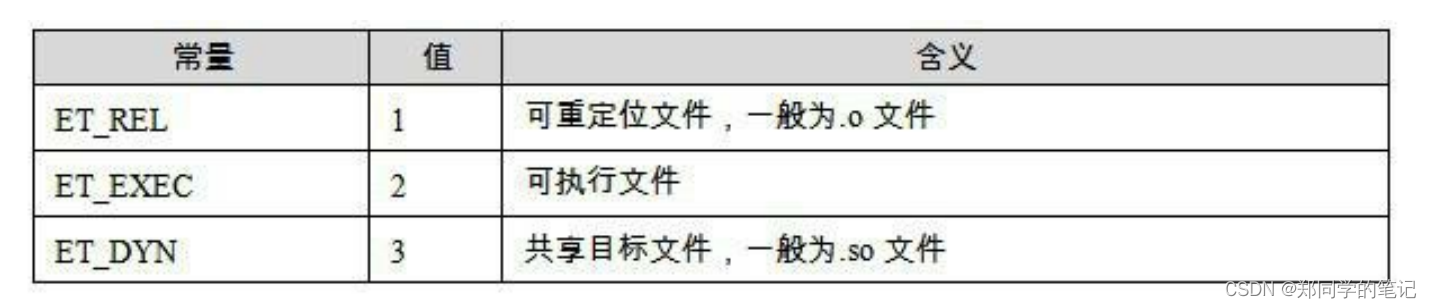
【编译、链接、装载六】汇编——目标文件
【编译和链接六】汇编——目标文件 一、目标文件_存储格式1、生成目标文件2、目标文件存储格式3、file查看文件格式 二、查看目标文件的内部结构——objdump三、代码段四、 数据段和只读数据段五、 ELF文件结构描述1、头文件2、段表2.1、重定位表2.2、字符串表2.3、查看重定位表…...
)
王道计算机考研408计算机组成原理汇总(下)
提示:真正的英雄是明白世界的残酷,也遭受了社会带给他的苦难,他依然能用心的说“我热爱这个世界,我愿竭尽所能去为我的世界而好好战斗 文章目录 前言4.1.1 指令格式4.1.2 扩展操作码指令格式4.2.1 指令寻址4.2.2 数据寻址4.2.3 偏移寻址4.2.4 堆栈寻址汇总前言4.3.1 高级语…...
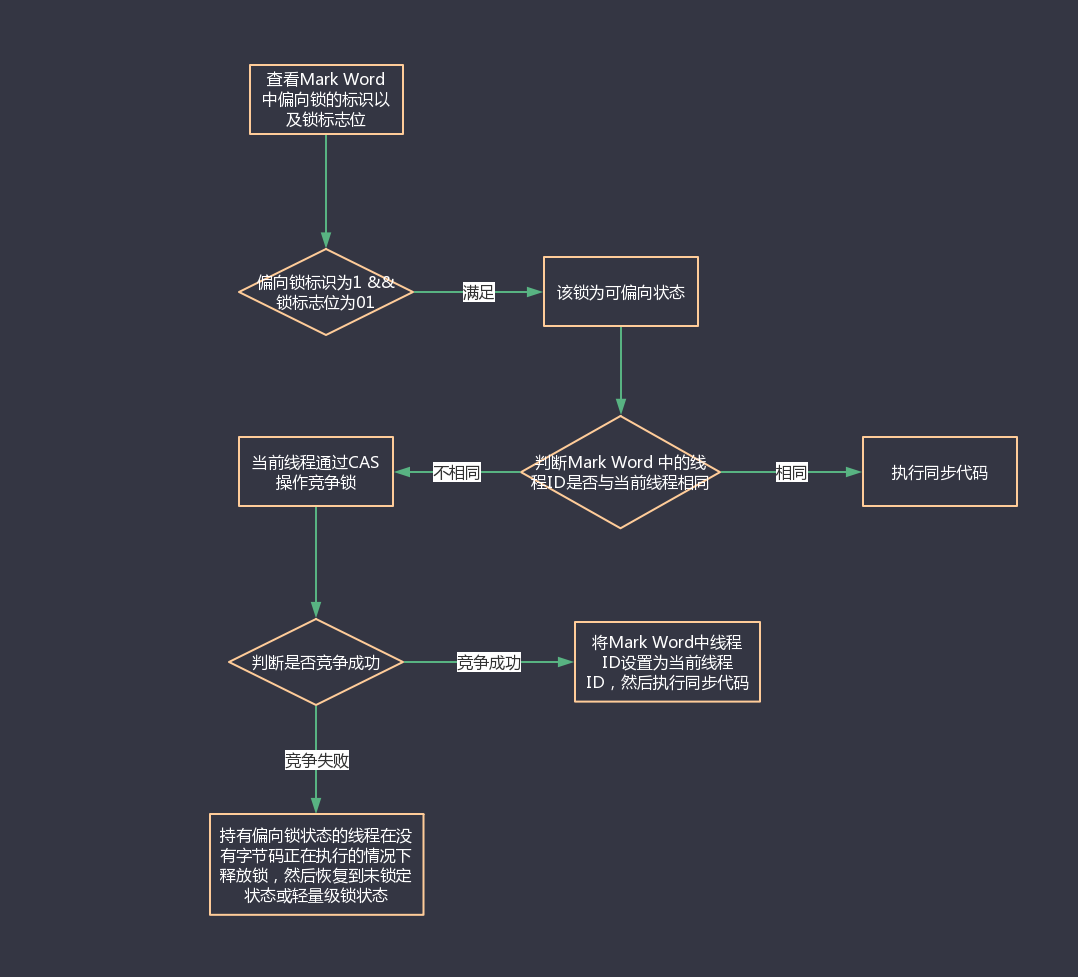
偏向锁、轻量级锁、重量级锁、自旋锁、自适应自旋锁
1. 偏向锁 偏向锁就是在运行过程中,对象的锁偏向某个线程。即在开启偏向锁机制的情况下,某个线程获得锁,当该线程下次再想要获得锁时,不需要重新申请获得锁(即忽略synchronized关键词),直接就可…...
Delta 一个新的 git diff 对比显示工具
目录 介绍git diff 介绍delta介绍 一、安装1.下载 Git2.下载 delta3.解压4.修改配置文件5. 修改主题6.其他配置和说明 二、对比命令1.在项目中 git diff 常用命令2.对比电脑上两个文件3.对比电脑上的两个文件夹 三、在Git 命令行中使用效果四、在idea 的Terminal命令行中使用效…...

C# 二进制序列化和反序列化示例
.NET框架提供了两种种串行化的方式: 1、是使用BinaryFormatter进行串行化; 2、使用XmlSerializer进行串行化。 第一种方式提供了一个简单的二进制数据流以及某些附加的类型信息,而第二种将数据流格式化为XML存储。可以使用[Serializable]属…...

【CSS】文字扫光 | 渐变光
码来 可调整角度与颜色值来改变效果 <p class"gf-gx-color">我是帅哥</p> <style>.gf-gx-color {background: -webkit-linear-gradient(135deg,red,red 25%,red 50%,#fff 55%,red 60%,red 80%,red 95%,red);-webkit-text-fill-color: transparen…...

Overhaul Distillation(ICCV 2019)原理与代码解析
paper:A Comprehensive Overhaul of Feature Distillation official implementation:GitHub - clovaai/overhaul-distillation: Official PyTorch implementation of "A Comprehensive Overhaul of Feature Distillation" (ICCV 2019) 本文的…...
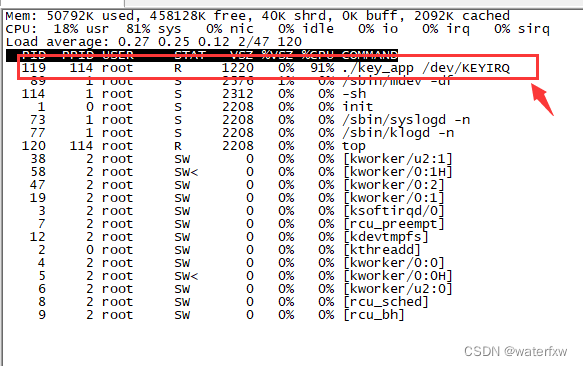
<Linux开发>驱动开发 -之-内核定时器与中断
<Linux开发>驱动开发 -之-内核定时器与中断 交叉编译环境搭建: <Linux开发> linux开发工具-之-交叉编译环境搭建 uboot移植可参考以下: <Linux开发> -之-系统移植 uboot移植过程详…...

希尔贝壳邀您参加2023深圳国际人工智能展览会
2023深圳国际人工智能展览会“AIE”将于2023年5月16-18日在深圳国际会展中心 (宝安)举办,希尔贝壳受邀参加,展位号:A331。 伴随着智能行业的快速发展,展会已被越来越多的企业列入每年必选展会,也成为各采购商选购的理…...
设计优质微信小程序的实用指南!
微信小程序是一种快速发展的应用形式,设计良好的小程序能够提升用户体验并吸引更多的用户。在设计微信小程序时,有一些关键的指南可以帮助我们做出出色的设计。以下是即时设计总结的一些设计指南,希望能对准备设计微信小程序的人有所帮助。 …...

大数据期末总结
文章目录 一、这学期分别学习了Scala、spark、spring、SpringMvc、SpringBoot1、scala2、spark3、spring4、SpringMvc5、SpringBoot 二、总结 一、这学期分别学习了Scala、spark、spring、SpringMvc、SpringBoot 1、scala Scala是一门基于JVM的编程语言,具有强大的…...
selenium面试题总结
今天有同学问到seleinum面试的时候会问到的问题,随便想了想,暂时纪录一下。欢迎大家在评论中提供更多问题。 1.selenium中如何判断元素是否存在? selenium中没有提供原生的方法判断元素是否存在,一般我们可以通过定位元素异常捕获…...

⑧电子产品拆解分析-1拖4USB拓展坞
⑧电子产品拆解分析-1拖4USB拓展坞 一、功能介绍二、电路分析以及器件作用1、内部电路拆解三、参考资料学习一、功能介绍 ①USB2.0一拖四通讯;②具备OTG功能,可适配大部分USB接口设备;二、电路分析以及器件作用 1、内部电路拆解 分析:❤️ ❤️ ❤️ 主控是MA8601 USB 2.0…...

月度精华汇总 | 最新XR行业资讯、场景案例、活动都在这一篇里啦!
在过去的一个月中,平行云为您带来了关于XR领域的一系列精彩文章,涵盖了行业资讯、应用案例,市场互动,帮助您掌握XR领域最新动态,了解实时云渲染、Cloud XR技术的价值,以及平行云实时云渲染解决方案LarkX…...
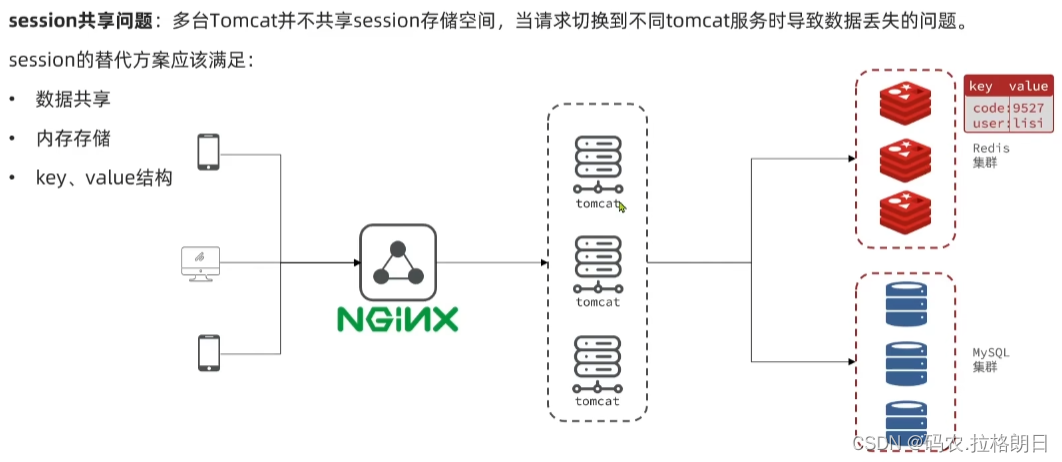
Redis实战案例1-短信登录
Redis的共享session应用 1. 项目的相关工作 导入sql文件 找到对应的sql文件即可 基本表的信息 基本架构 导入对应的项目文件,启动相关的service服务; 在nginx-1.18.0目录下启动命令行start nginx.exe; 2. 基于session实现登录的流程 这里利用到Javaweb中…...

华为OD机试真题 JavaScript 实现【找终点】【2023 B卷 100分】,附详细解题思路
一、题目描述 给定一个正整数数组,设为nums,最大为100个成员,求从第一个成员开始,正好走到数组最后一个成员,所使用的最少步骤数。 要求: 第一步必须从第一元素开始,且1 < 第一步的步长 &…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

(一)单例模式
一、前言 单例模式属于六大创建型模式,即在软件设计过程中,主要关注创建对象的结果,并不关心创建对象的过程及细节。创建型设计模式将类对象的实例化过程进行抽象化接口设计,从而隐藏了类对象的实例是如何被创建的,封装了软件系统使用的具体对象类型。 六大创建型模式包括…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...
6.9-QT模拟计算器
源码: 头文件: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QMouseEvent>QT_BEGIN_NAMESPACE namespace Ui { class Widget; } QT_END_NAMESPACEclass Widget : public QWidget {Q_OBJECTpublic:Widget(QWidget *parent nullptr);…...

node.js的初步学习
那什么是node.js呢? 和JavaScript又是什么关系呢? node.js 提供了 JavaScript的运行环境。当JavaScript作为后端开发语言来说, 需要在node.js的环境上进行当JavaScript作为前端开发语言来说,需要在浏览器的环境上进行 Node.js 可…...
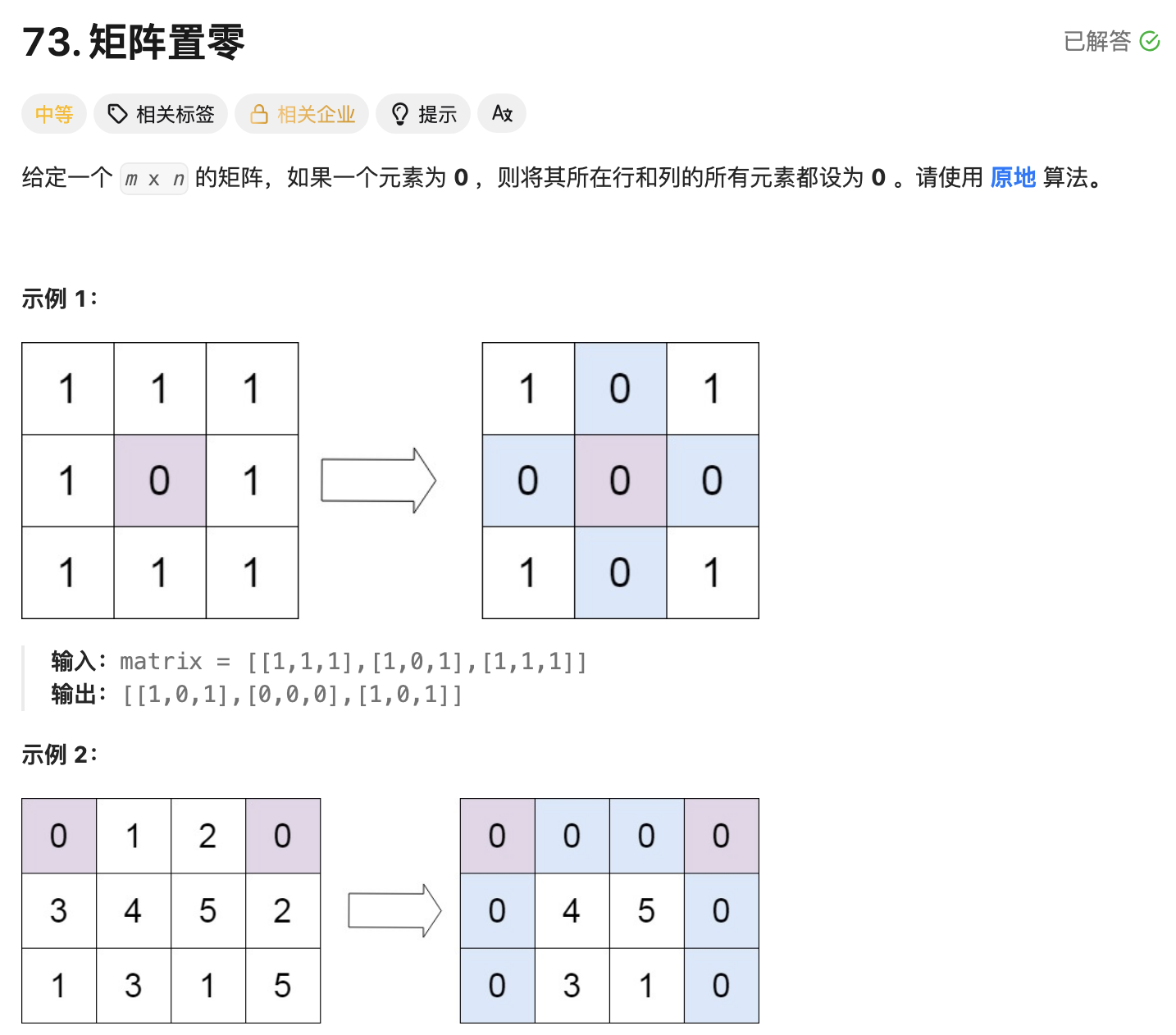
leetcode73-矩阵置零
leetcode 73 思路 记录 0 元素的位置:遍历整个矩阵,找出所有值为 0 的元素,并将它们的坐标记录在数组zeroPosition中置零操作:遍历记录的所有 0 元素位置,将每个位置对应的行和列的所有元素置为 0 具体步骤 初始化…...
【51单片机】4. 模块化编程与LCD1602Debug
1. 什么是模块化编程 传统编程会将所有函数放在main.c中,如果使用的模块多,一个文件内会有很多代码,不利于组织和管理 模块化编程则是将各个模块的代码放在不同的.c文件里,在.h文件里提供外部可调用函数声明,其他.c文…...