mybatis-plus用法(一)
MyBatis-plus 是一款 Mybatis 增强工具,用于简化开发,提高效率。下文使用缩写 mp来简化表示 MyBatis-plus,本文主要介绍 mp 整合 Spring Boot 的使用。
(5条消息) mybatis-plus用法(二)_渣娃工程师的博客-CSDN博客
1.创建一个Spring Boot项目。
2.导入依赖
<!-- pom.xml --> <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.4.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>mybatis-plus</artifactId> <version>0.0.1-SNAPSHOT</version> <name>mybatis-plus</name> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>3.配置数据库
# application.yml spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/yogurt?serverTimezone=Asia/Shanghai username: root password: root mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #开启SQL语句打印4.创建一个实体类
package com.example.mp.po; import lombok.Data; import java.time.LocalDateTime; @Data public class User { private Long id; private String name; private Integer age; private String email; private Long managerId; private LocalDateTime createTime; }5.创建一个mapper接口
package com.example.mp.mappers; import com.baomidou.mybatisplus.core.mapper.BaseMapper; import com.example.mp.po.User; public interface UserMapper extends BaseMapper<User> { }6.在SpringBoot启动类上配置mapper接口的扫描路径
package com.example.mp; import org.mybatis.spring.annotation.MapperScan; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconp.SpringBootApplication; @SpringBootApplication @MapperScan("com.example.mp.mappers") public class MybatisPlusApplication { public static void main(String[] args) { SpringApplication.run(MybatisPlusApplication.class, args); } }7.在数据库中创建表
DROP TABLE IF EXISTS user; CREATE TABLE user ( id BIGINT(20) PRIMARY KEY NOT NULL COMMENT '主键', name VARCHAR(30) DEFAULT NULL COMMENT '姓名', age INT(11) DEFAULT NULL COMMENT '年龄', email VARCHAR(50) DEFAULT NULL COMMENT '邮箱', manager_id BIGINT(20) DEFAULT NULL COMMENT '直属上级id', create_time DATETIME DEFAULT NULL COMMENT '创建时间', CONSTRAINT manager_fk FOREIGN KEY(manager_id) REFERENCES user (id) ) ENGINE=INNODB CHARSET=UTF8; INSERT INTO user (id, name, age ,email, manager_id, create_time) VALUES (1, '大BOSS', 40, 'boss@baomidou.com', NULL, '2021-03-22 09:48:00'), (2, '李经理', 40, 'boss@baomidou.com', 1, '2021-01-22 09:48:00'), (3, '黄主管', 40, 'boss@baomidou.com', 2, '2021-01-22 09:48:00'), (4, '吴组长', 40, 'boss@baomidou.com', 2, '2021-02-22 09:48:00'), (5, '小菜', 40, 'boss@baomidou.com', 2, '2021-02-22 09:48:00')8.编写一个SpringBoot测试类
package com.example.mp; import com.example.mp.mappers.UserMapper; import com.example.mp.po.User; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import java.util.List; import static org.junit.Assert.*; @RunWith(SpringRunner.class) @SpringBootTest public class SampleTest { @Autowired private UserMapper mapper; @Test public void testSelect() { List<User> list = mapper.selectList(null); assertEquals(5, list.size()); list.forEach(System.out::println); } }准备工作完成,数据库情况如下:
项目目录如下:
运行测试类

可以看到,针对单表的基本CRUD操作,只需要创建好实体类,并创建一个继承自BaseMapper的接口即可,可谓非常简洁。并且,我们注意到,User类中的managerId,createTime属性,自动和数据库表中的manager_id,create_time对应了起来,这是因为mp自动做了数据库下划线命名,到Java类的驼峰命名之间的转化。
注解
mp一共提供了8个注解,这些注解是用在Java的实体类上面的。
@TableName
注解在类上,指定类和数据库表的映射关系。实体类的类名(转成小写后)和数据库表名相同时,可以不指定该注解。
@TableId
注解在实体类的某一字段上,表示这个字段对应数据库表的主键。当主键名为id时(表中列名为id,实体类中字段名为id),无需使用该注解显式指定主键,mp会自动关联。若类的字段名和表的列名不一致,可用value属性指定表的列名。另,这个注解有个重要的属性type,用于指定主键策略。
@TableField
注解在某一字段上,指定Java实体类的字段和数据库表的列的映射关系。这个注解有如下几个应用场景。
-
排除非表字段
若Java实体类中某个字段,不对应表中的任何列,它只是用于保存一些额外的,或组装后的数据,则可以设置
exist属性为false,这样在对实体对象进行插入时,会忽略这个字段。排除非表字段也可以通过其他方式完成,如使用static或transient关键字,但个人觉得不是很合理,不做赘述 -
字段验证策略
通过
insertStrategy,updateStrategy,whereStrategy属性进行配置,可以控制在实体对象进行插入,更新,或作为WHERE条件时,对象中的字段要如何组装到SQL语句中。 -
字段填充策略
通过
fill属性指定,字段为空时会进行自动填充
@Version
乐观锁注解
@EnumValue
注解在枚举字段上
@TableLogic
逻辑删除
KeySequence
序列主键策略(oracle)
InterceptorIgnore
插件过滤规则
CRUD接口
mp封装了一些最基础的CRUD方法,只需要直接继承mp提供的接口,无需编写任何SQL,即可食用。mp提供了两套接口,分别是Mapper CRUD接口和Service CRUD接口。并且mp还提供了条件构造器Wrapper,可以方便地组装SQL语句中的WHERE条件。
Mapper CRUD接口
只需定义好实体类,然后创建一个接口,继承mp提供的BaseMapper,即可食用。mp会在mybatis启动时,自动解析实体类和表的映射关系,并注入带有通用CRUD方法的mapper。BaseMapper里提供的方法,部分列举如下:
-
insert(T entity)插入一条记录 -
deleteById(Serializable id)根据主键id删除一条记录 -
delete(Wrapper<T> wrapper)根据条件构造器wrapper进行删除 -
selectById(Serializable id)根据主键id进行查找 -
selectBatchIds(Collection idList)根据主键id进行批量查找 -
selectByMap(Map<String,Object> map)根据map中指定的列名和列值进行等值匹配查找 -
selectMaps(Wrapper<T> wrapper)根据 wrapper 条件,查询记录,将查询结果封装为一个Map,Map的key为结果的列,value为值 -
selectList(Wrapper<T> wrapper)根据条件构造器wrapper进行查询 -
update(T entity, Wrapper<T> wrapper)根据条件构造器wrapper进行更新 -
updateById(T entity) -
...
下面讲解几个比较特别的方法
selectMaps
BaseMapper接口还提供了一个selectMaps方法,这个方法会将查询结果封装为一个Map,Map的key为结果的列,value为值
该方法的使用场景如下:
-
只查部分列
当某个表的列特别多,而SELECT的时候只需要选取个别列,查询出的结果也没必要封装成Java实体类对象时(只查部分列时,封装成实体后,实体对象中的很多属性会是null),则可以用selectMaps,获取到指定的列后,再自行进行处理即可
比如
@Test public void test3() { QueryWrapper<User> wrapper = new QueryWrapper<>(); wrapper.select("id","name","email").likeRight("name","黄"); List<Map<String, Object>> maps = userMapper.selectMaps(wrapper); maps.forEach(System.out::println); }进行数据统计
比如
// 按照直属上级进行分组,查询每组的平均年龄,最大年龄,最小年龄 /** select avg(age) avg_age ,min(age) min_age, max(age) max_age from user group by manager_id having sum(age) < 500; **/ @Test public void test3() { QueryWrapper<User> wrapper = new QueryWrapper<>(); wrapper.select("manager_id", "avg(age) avg_age", "min(age) min_age", "max(age) max_age") .groupBy("manager_id").having("sum(age) < {0}", 500); List<Map<String, Object>> maps = userMapper.selectMaps(wrapper); maps.forEach(System.out::println); }
selectObjs
只会返回第一个字段(第一列)的值,其他字段会被舍弃
比如
@Test public void test3() { QueryWrapper<User> wrapper = new QueryWrapper<>(); wrapper.select("id", "name").like("name", "黄"); List<Object> objects = userMapper.selectObjs(wrapper); objects.forEach(System.out::println); }得到的结果,只封装了第一列的id
selectCount
查询满足条件的总数,注意,使用这个方法,不能调用QueryWrapper的select方法设置要查询的列了。这个方法会自动添加select count(1)
比如
@Test public void test3() { QueryWrapper<User> wrapper = new QueryWrapper<>(); wrapper.like("name", "黄"); Integer count = userMapper.selectCount(wrapper); System.out.println(count); }
Service CRUD 接口
另外一套CRUD是Service层的,只需要编写一个接口,继承IService,并创建一个接口实现类,即可食用。(这个接口提供的CRUD方法,和Mapper接口提供的功能大同小异,比较明显的区别在于IService支持了更多的批量化操作,如saveBatch,saveOrUpdateBatch等方法。
食用示例如下
1.首先,新建一个接口,继承IService
package com.example.mp.service; import com.baomidou.mybatisplus.extension.service.IService; import com.example.mp.po.User; public interface UserService extends IService<User> { } 2.创建这个接口的实现类,并继承ServiceImpl,最后打上@Service注解,注册到Spring容器中,即可食用
package com.example.mp.service.impl; import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl; import com.example.mp.mappers.UserMapper; import com.example.mp.po.User; import com.example.mp.service.UserService; import org.springframework.stereotype.Service; @Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService { }3.测试代码
package com.example.mp; import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper; import com.baomidou.mybatisplus.core.toolkit.Wrappers; import com.example.mp.po.User; import com.example.mp.service.UserService; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; @RunWith(SpringRunner.class) @SpringBootTest public class ServiceTest { @Autowired private UserService userService; @Test public void testGetOne() { LambdaQueryWrapper<User> wrapper = Wrappers.<User>lambdaQuery(); wrapper.gt(User::getAge, 28); User one = userService.getOne(wrapper, false); // 第二参数指定为false,使得在查到了多行记录时,不抛出异常,而返回第一条记录 System.out.println(one); } }4.结果

另,IService也支持链式调用,代码写起来非常简洁,查询示例如下
@Test public void testChain() { List<User> list = userService.lambdaQuery() .gt(User::getAge, 39) .likeRight(User::getName, "王") .list(); list.forEach(System.out::println); }更新示例如下
@Test public void testChain() { userService.lambdaUpdate() .gt(User::getAge, 39) .likeRight(User::getName, "王") .set(User::getEmail, "w39@baomidou.com") .update(); }
删除示例如下
@Test public void testChain() { userService.lambdaUpdate() .like(User::getName, "青蛙") .remove(); }
条件构造器
mp让我觉得极其方便的一点在于其提供了强大的条件构造器Wrapper,可以非常方便的构造WHERE条件。条件构造器主要涉及到3个类,AbstractWrapper。QueryWrapper,UpdateWrapper,它们的类关系如下
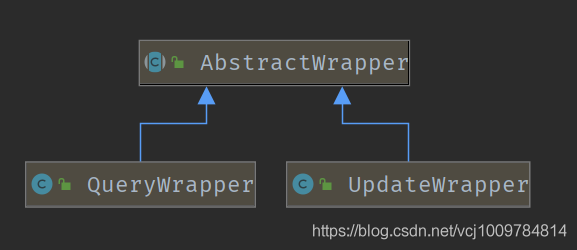
在AbstractWrapper中提供了非常多的方法用于构建WHERE条件,而QueryWrapper针对SELECT语句,提供了select()方法,可自定义需要查询的列,而UpdateWrapper针对UPDATE语句,提供了set()方法,用于构造set语句。条件构造器也支持lambda表达式,写起来非常舒爽。
下面对AbstractWrapper中用于构建SQL语句中的WHERE条件的方法进行部分列举
-
eq:equals,等于 -
allEq:all equals,全等于 -
ne:not equals,不等于 -
gt:greater than ,大于> -
ge:greater than or equals,大于等于≥ -
lt:less than,小于< -
le:less than or equals,小于等于≤ -
between:相当于SQL中的BETWEEN -
notBetween -
like:模糊匹配。like("name","黄"),相当于SQL的name like '%黄%' -
likeRight:模糊匹配右半边。likeRight("name","黄"),相当于SQL的name like '黄%' -
likeLeft:模糊匹配左半边。likeLeft("name","黄"),相当于SQL的name like '%黄' -
notLike:notLike("name","黄"),相当于SQL的name not like '%黄%' -
isNull -
isNotNull -
in -
and:SQL连接符AND -
or:SQL连接符OR -
apply:用于拼接SQL,该方法可用于数据库函数,并可以动态传参 -
.......
使用示例
下面通过一些具体的案例来练习条件构造器的使用。(使用前文创建的user表)
// 案例先展示需要完成的SQL语句,后展示Wrapper的写法 // 1. 名字中包含佳,且年龄小于25
// SELECT * FROM user WHERE name like '%佳%' AND age < 25
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.like("name", "佳").lt("age", 25);
List<User> users = userMapper.selectList(wrapper);
// 下面展示SQL时,仅展示WHERE条件;展示代码时, 仅展示Wrapper构建部分 // 2. 姓名为黄姓,且年龄大于等于20,小于等于40,且email字段不为空
// name like '黄%' AND age BETWEEN 20 AND 40 AND email is not null
wrapper.likeRight("name","黄").between("age", 20, 40).isNotNull("email"); // 3. 姓名为黄姓,或者年龄大于等于40,按照年龄降序排列,年龄相同则按照id升序排列
// name like '黄%' OR age >= 40 order by age desc, id asc
wrapper.likeRight("name","黄").or().ge("age",40).orderByDesc("age").orderByAsc("id"); // 4.创建日期为2021年3月22日,并且直属上级的名字为李姓
// date_format(create_time,'%Y-%m-%d') = '2021-03-22' AND manager_id IN (SELECT id FROM user WHERE name like '李%')
wrapper.apply("date_format(create_time, '%Y-%m-%d') = {0}", "2021-03-22") // 建议采用{index}这种方式动态传参, 可防止SQL注入 .inSql("manager_id", "SELECT id FROM user WHERE name like '李%'");
// 上面的apply, 也可以直接使用下面这种方式做字符串拼接,但当这个日期是一个外部参数时,这种方式有SQL注入的风险
wrapper.apply("date_format(create_time, '%Y-%m-%d') = '2021-03-22'"); // 5. 名字为王姓,并且(年龄小于40,或者邮箱不为空)
// name like '王%' AND (age < 40 OR email is not null)
wrapper.likeRight("name", "王").and(q -> q.lt("age", 40).or().isNotNull("email")); // 6. 名字为王姓,或者(年龄小于40并且年龄大于20并且邮箱不为空)
// name like '王%' OR (age < 40 AND age > 20 AND email is not null)
wrapper.likeRight("name", "王").or( q -> q.lt("age",40) .gt("age",20) .isNotNull("email") ); // 7. (年龄小于40或者邮箱不为空) 并且名字为王姓
// (age < 40 OR email is not null) AND name like '王%'
wrapper.nested(q -> q.lt("age", 40).or().isNotNull("email")) .likeRight("name", "王"); // 8. 年龄为30,31,34,35
// age IN (30,31,34,35)
wrapper.in("age", Arrays.asList(30,31,34,35));
// 或
wrapper.inSql("age","30,31,34,35"); // 9. 年龄为30,31,34,35, 返回满足条件的第一条记录
// age IN (30,31,34,35) LIMIT 1
wrapper.in("age", Arrays.asList(30,31,34,35)).last("LIMIT 1"); // 10. 只选出id, name 列 (QueryWrapper 特有)
// SELECT id, name FROM user;
wrapper.select("id", "name"); // 11. 选出id, name, age, email, 等同于排除 manager_id 和 create_time
// 当列特别多, 而只需要排除个别列时, 采用上面的方式可能需要写很多个列, 可以采用重载的select方法,指定需要排除的列
wrapper.select(User.class, info -> { String columnName = info.getColumn(); return !"create_time".equals(columnName) && !"manager_id".equals(columnName); });Condition
条件构造器的诸多方法中,均可以指定一个boolean类型的参数condition,用来决定该条件是否加入最后生成的WHERE语句中,比如
String name = "黄"; // 假设name变量是一个外部传入的参数
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.like(StringUtils.hasText(name), "name", name);
// 仅当 StringUtils.hasText(name) 为 true 时, 会拼接这个like语句到WHERE中
// 其实就是对下面代码的简化
if (StringUtils.hasText(name)) { wrapper.like("name", name);
}实体对象作为条件
调用构造函数创建一个Wrapper对象时,可以传入一个实体对象。后续使用这个Wrapper时,会以实体对象中的非空属性,构建WHERE条件(默认构建等值匹配的WHERE条件,这个行为可以通过实体类里各个字段上的@TableField注解中的condition属性进行改变)
示例如下
@Test public void test3() { User user = new User(); user.setName("黄主管"); user.setAge(28); QueryWrapper<User> wrapper = new QueryWrapper<>(user); List<User> users = userMapper.selectList(wrapper); users.forEach(System.out::println); }执行结果如下。可以看到,是根据实体对象中的非空属性,进行了等值匹配查询。
若希望针对某些属性,改变等值匹配的行为,则可以在实体类中用@TableField注解进行配置,示例如下
package com.example.mp.po;
import com.baomidou.mybatisplus.annotation.SqlCondition;
import com.baomidou.mybatisplus.annotation.TableField;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User { private Long id; @TableField(condition = SqlCondition.LIKE) // 配置该字段使用like进行拼接 private String name; private Integer age; private String email; private Long managerId; private LocalDateTime createTime;
}运行下面的测试代码
@Test public void test3() { User user = new User(); user.setName("黄"); QueryWrapper<User> wrapper = new QueryWrapper<>(user); List<User> users = userMapper.selectList(wrapper); users.forEach(System.out::println); } 从下图得到的结果来看,对于实体对象中的name字段,采用了like进行拼接

@TableField中配置的condition属性实则是一个字符串,SqlCondition类中预定义了一些字符串以供选择
package com.baomidou.mybatisplus.annotation; public class SqlCondition { //下面的字符串中, %s 是占位符, 第一个 %s 是列名, 第二个 %s 是列的值 public static final String EQUAL = "%s=#{%s}"; public static final String NOT_EQUAL = "%s<>#{%s}"; public static final String LIKE = "%s LIKE CONCAT('%%',#{%s},'%%')"; public static final String LIKE_LEFT = "%s LIKE CONCAT('%%',#{%s})"; public static final String LIKE_RIGHT = "%s LIKE CONCAT(#{%s},'%%')";
} SqlCondition中提供的配置比较有限,当我们需要<或>等拼接方式,则需要自己定义。比如
package com.example.mp.po;
import com.baomidou.mybatisplus.annotation.SqlCondition;
import com.baomidou.mybatisplus.annotation.TableField;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User { private Long id; @TableField(condition = SqlCondition.LIKE) private String name; @TableField(condition = "%s > #{%s}") // 这里相当于大于, 其中 > 是字符实体 private Integer age; private String email; private Long managerId; private LocalDateTime createTime;
}测试如下
@Test public void test3() { User user = new User(); user.setName("黄"); user.setAge(30); QueryWrapper<User> wrapper = new QueryWrapper<>(user); List<User> users = userMapper.selectList(wrapper); users.forEach(System.out::println); }从下图得到的结果,可以看出,name属性是用like拼接的,而age属性是用>拼接的

allEq方法
allEq方法传入一个map,用来做等值匹配
@Test public void test3() { QueryWrapper<User> wrapper = new QueryWrapper<>(); Map<String, Object> param = new HashMap<>(); param.put("age", 40); param.put("name", "黄飞飞"); wrapper.allEq(param); List<User> users = userMapper.selectList(wrapper); users.forEach(System.out::println); }
当allEq方法传入的Map中有value为null的元素时,默认会设置为is null
@Test public void test3() { QueryWrapper<User> wrapper = new QueryWrapper<>(); Map<String, Object> param = new HashMap<>(); param.put("age", 40); param.put("name", null); wrapper.allEq(param); List<User> users = userMapper.selectList(wrapper); users.forEach(System.out::println); } 若想忽略map中value为null的元素,可以在调用allEq时,设置参数boolean null2IsNull为false
@Test public void test3() { QueryWrapper<User> wrapper = new QueryWrapper<>(); Map<String, Object> param = new HashMap<>(); param.put("age", 40); param.put("name", null); wrapper.allEq(param, false); List<User> users = userMapper.selectList(wrapper); users.forEach(System.out::println); }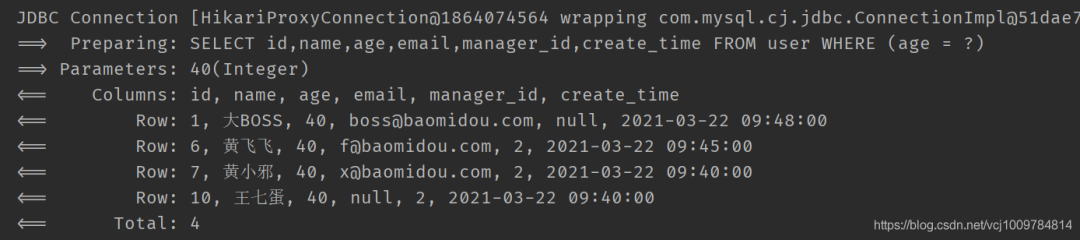
若想要在执行allEq时,过滤掉Map中的某些元素,可以调用allEq的重载方法allEq(BiPredicate<R, V> filter, Map<R, V> params)
@Test public void test3() { QueryWrapper<User> wrapper = new QueryWrapper<>(); Map<String, Object> param = new HashMap<>(); param.put("age", 40); param.put("name", "黄飞飞"); wrapper.allEq((k,v) -> !"name".equals(k), param); // 过滤掉map中key为name的元素 List<User> users = userMapper.selectList(wrapper); users.forEach(System.out::println); }
lambda条件构造器
lambda条件构造器,支持lambda表达式,可以不必像普通条件构造器一样,以字符串形式指定列名,它可以直接以实体类的方法引用来指定列。示例如下
@Test public void testLambda() { LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.like(User::getName, "黄").lt(User::getAge, 30); List<User> users = userMapper.selectList(wrapper); users.forEach(System.out::println); }像普通的条件构造器,列名是用字符串的形式指定,无法在编译期进行列名合法性的检查,这就不如lambda条件构造器来的优雅。
另外,还有个链式lambda条件构造器,使用示例如下
@Test public void testLambda() { LambdaQueryChainWrapper<User> chainWrapper = new LambdaQueryChainWrapper<>(userMapper); List<User> users = chainWrapper.like(User::getName, "黄").gt(User::getAge, 30).list(); users.forEach(System.out::println); }更新操作
上面介绍的都是查询操作,现在来讲更新和删除操作。
BaseMapper中提供了2个更新方法
-
updateById(T entity)
根据入参entity的id(主键)进行更新,对于entity中非空的属性,会出现在UPDATE语句的SET后面,即entity中非空的属性,会被更新到数据库,示例如下
@RunWith(SpringRunner.class) @SpringBootTest public class UpdateTest { @Autowired private UserMapper userMapper; @Test public void testUpdate() { User user = new User(); user.setId(2L); user.setAge(18); userMapper.updateById(user); } }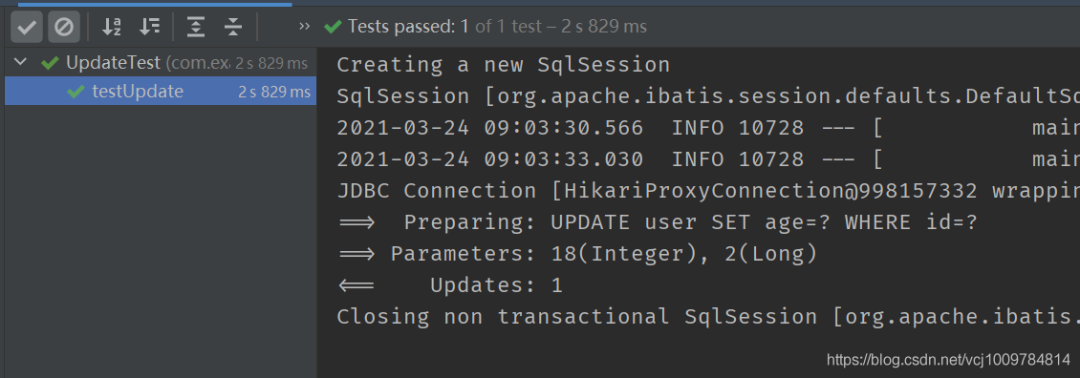
-
update(T entity, Wrapper<T> wrapper)
根据实体entity和条件构造器wrapper进行更新,示例如下
@Test public void testUpdate2() { User user = new User(); user.setName("王三蛋"); LambdaUpdateWrapper<User> wrapper = new LambdaUpdateWrapper<>(); wrapper.between(User::getAge, 26,31).likeRight(User::getName,"吴"); userMapper.update(user, wrapper); } 额外演示一下,把实体对象传入Wrapper,即用实体对象构造WHERE条件的案例
@Test public void testUpdate3() { User whereUser = new User(); whereUser.setAge(40); whereUser.setName("王"); LambdaUpdateWrapper<User> wrapper = new LambdaUpdateWrapper<>(whereUser); User user = new User(); user.setEmail("share@baomidou.com"); user.setManagerId(10L); userMapper.update(user, wrapper); }注意到我们的User类中,对name属性和age属性进行了如下的设置
@Data
public class User { private Long id; @TableField(condition = SqlCondition.LIKE) private String name; @TableField(condition = "%s > #{%s}") private Integer age; private String email; private Long managerId; private LocalDateTime createTime;
}执行结果

再额外演示一下,链式lambda条件构造器的使用
@Test public void testUpdate5() { LambdaUpdateChainWrapper<User> wrapper = new LambdaUpdateChainWrapper<>(userMapper); wrapper.likeRight(User::getEmail, "share") .like(User::getName, "飞飞") .set(User::getEmail, "ff@baomidou.com") .update(); }
反思
由于BaseMapper提供的2个更新方法都是传入一个实体对象去执行更新,这在需要更新的列比较多时还好,若想要更新的只有那么一列,或者两列,则创建一个实体对象就显得有点麻烦。针对这种情况,UpdateWrapper提供有set方法,可以手动拼接SQL中的SET语句,此时可以不必传入实体对象,示例如下
@Test public void testUpdate4() { LambdaUpdateWrapper<User> wrapper = new LambdaUpdateWrapper<>(); wrapper.likeRight(User::getEmail, "share").set(User::getManagerId, 9L); userMapper.update(null, wrapper); }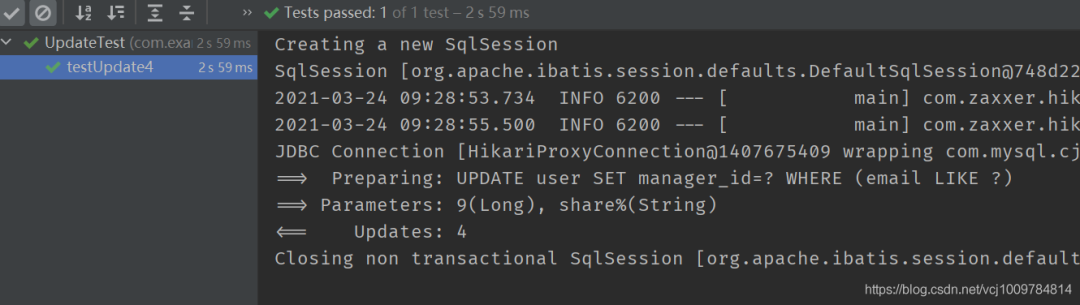
删除操作
BaseMapper一共提供了如下几个用于删除的方法
-
deleteById根据主键id进行删除 -
deleteBatchIds根据主键id进行批量删除 -
deleteByMap根据Map进行删除(Map中的key为列名,value为值,根据列和值进行等值匹配) -
delete(Wrapper<T> wrapper)根据条件构造器Wrapper进行删除
与前面查询和更新的操作大同小异,不做赘述
自定义SQL
当mp提供的方法还不能满足需求时,则可以自定义SQL。
原生mybatis
示例如下
-
注解方式
package com.example.mp.mappers; import com.baomidou.mybatisplus.core.mapper.BaseMapper; import com.example.mp.po.User; import org.apache.ibatis.annotations.Select; import java.util.List; /** * @Author yogurtzzz * @Date 2021/3/18 11:21 **/ public interface UserMapper extends BaseMapper<User> { @Select("select * from user") List<User> selectRaw(); } -
xml方式
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.example.mp.mappers.UserMapper"> <select id="selectRaw" resultType="com.example.mp.po.User"> SELECT * FROM user </select> </mapper>package com.example.mp.mappers; import com.baomidou.mybatisplus.core.mapper.BaseMapper; import com.example.mp.po.User; import org.apache.ibatis.annotations.Select; import java.util.List; public interface UserMapper extends BaseMapper<User> { List<User> selectRaw(); }使用xml时,若xml文件与mapper接口文件不在同一目录下,则需要在
application.yml中配置mapper.xml的存放路径mybatis-plus: mapper-locations: /mappers/*若有多个地方存放mapper,则用数组形式进行配置
mybatis-plus: mapper-locations: - /mappers/* - /com/example/mp/*测试代码如下
@Test public void testCustomRawSql() { List<User> users = userMapper.selectRaw(); users.forEach(System.out::println); }结果

mybatis-plus
也可以使用mp提供的Wrapper条件构造器,来自定义SQL
示例如下
-
注解方式
package com.example.mp.mappers; import com.baomidou.mybatisplus.core.conditions.Wrapper; import com.baomidou.mybatisplus.core.mapper.BaseMapper; import com.baomidou.mybatisplus.core.toolkit.Constants; import com.example.mp.po.User; import org.apache.ibatis.annotations.Param; import org.apache.ibatis.annotations.Select; import java.util.List; public interface UserMapper extends BaseMapper<User> { // SQL中不写WHERE关键字,且固定使用${ew.customSqlSegment} @Select("select * from user ${ew.customSqlSegment}") List<User> findAll(@Param(Constants.WRAPPER)Wrapper<User> wrapper); } -
xml方式
package com.example.mp.mappers; import com.baomidou.mybatisplus.core.conditions.Wrapper; import com.baomidou.mybatisplus.core.mapper.BaseMapper; import com.example.mp.po.User; import java.util.List; public interface UserMapper extends BaseMapper<User> { List<User> findAll(Wrapper<User> wrapper); }<!-- UserMapper.xml --> <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.example.mp.mappers.UserMapper"> <select id="findAll" resultType="com.example.mp.po.User"> SELECT * FROM user ${ew.customSqlSegment} </select> </mapper>分页查询
BaseMapper中提供了2个方法进行分页查询,分别是selectPage和selectMapsPage,前者会将查询的结果封装成Java实体对象,后者会封装成Map<String,Object>。分页查询的食用示例如下1. 创建mp的分页拦截器,注册到Spring容器中
package com.example.mp.config; import com.baomidou.mybatisplus.annotation.DbType; import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor; import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class MybatisPlusConfig { /** 新版mp **/ @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); return interceptor; } /** 旧版mp 用 PaginationInterceptor **/ }2. 执行分页查询
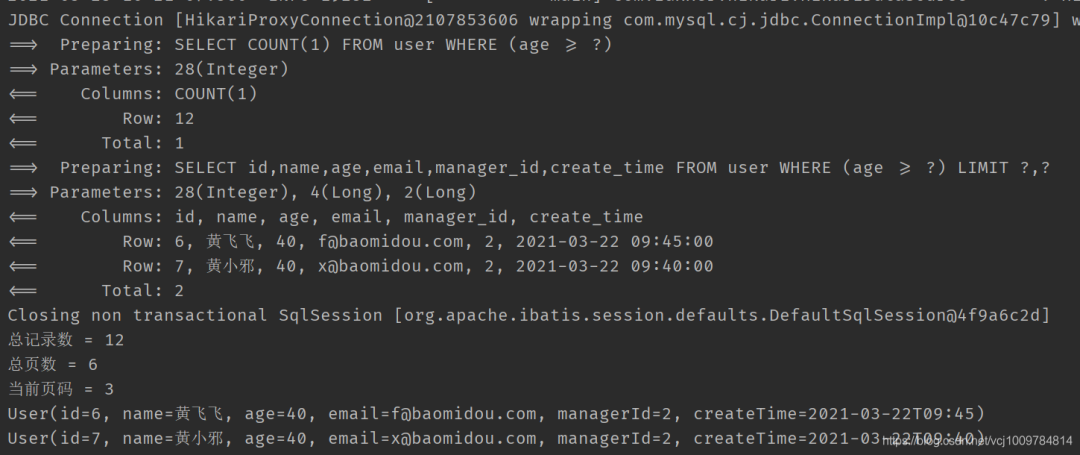
@Test public void testPage() { LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.ge(User::getAge, 28); // 设置分页信息, 查第3页, 每页2条数据 Page<User> page = new Page<>(3, 2); // 执行分页查询 Page<User> userPage = userMapper.selectPage(page, wrapper); System.out.println("总记录数 = " + userPage.getTotal()); System.out.println("总页数 = " + userPage.getPages()); System.out.println("当前页码 = " + userPage.getCurrent()); // 获取分页查询结果 List<User> records = userPage.getRecords(); records.forEach(System.out::println); }3. 结果
-
4. 其他
注意到,分页查询总共发出了2次SQL,一次查总记录数,一次查具体数据。若希望不查总记录数,仅查分页结果。可以通过
Page的重载构造函数,指定isSearchCount为false即可public Page(long current, long size, boolean isSearchCount)在实际开发中,可能遇到多表联查的场景,此时
BaseMapper中提供的单表分页查询的方法无法满足需求,需要自定义SQL,示例如下(使用单表查询的SQL进行演示,实际进行多表联查时,修改SQL语句即可)1. 在mapper接口中定义一个函数,接收一个Page对象为参数,并编写自定义SQL
// 这里采用纯注解方式。当然,若SQL比较复杂,建议还是采用XML的方式 @Select("SELECT * FROM user ${ew.customSqlSegment}") Page<User> selectUserPage(Page<User> page, @Param(Constants.WRAPPER) Wrapper<User> wrapper);2. 执行查询
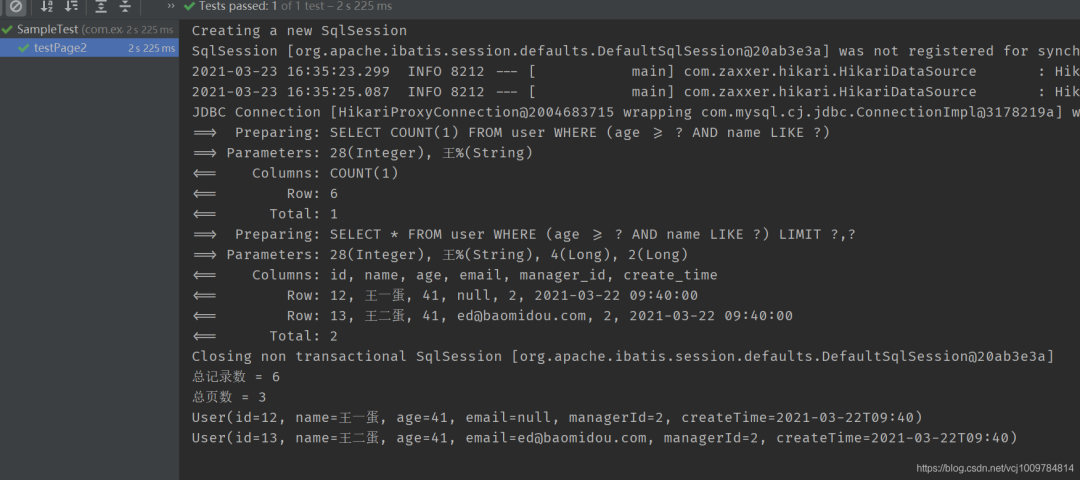
@Test public void testPage2() { LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.ge(User::getAge, 28).likeRight(User::getName, "王"); Page<User> page = new Page<>(3,2); Page<User> userPage = userMapper.selectUserPage(page, wrapper); System.out.println("总记录数 = " + userPage.getTotal()); System.out.println("总页数 = " + userPage.getPages()); userPage.getRecords().forEach(System.out::println); }3. 结果
相关文章:
mybatis-plus用法(一)
MyBatis-plus 是一款 Mybatis 增强工具,用于简化开发,提高效率。下文使用缩写 mp来简化表示 MyBatis-plus,本文主要介绍 mp 整合 Spring Boot 的使用。 (5条消息) mybatis-plus用法(二)_渣娃工程师的博客-CSDN博客 1…...

源码安装包管理
1. 源码包基本概述 在linux环境下面安装源码包是比较常见的, 早期运维管理工作中,大部分软件都是通过源码安装的。那么安装一个源码包,是需要我们自己把源代码编译成二进制的可执行文件。 源码包的编译用到了linux系统里的编译器,通常源码包…...

Vue|获取表单数据
在Vue中获取表单数据有多种方式,具体取决于你使用的是哪种表单元素和你的需求。 1. 单个表单元素: 如果你只需要获取单个表单元素的值,可以使用v-model指令将表单元素的值绑定到Vue实例的一个属性上。例如: <input type&quo…...
微信小程序入门学习02-TDesign中的自定义组件
目录 1 显示文本2 自定义组件3 变量定义4 值绑定总结 我们上一篇讲解了TDesign模板的基本用法,如何开始阅读模板。本篇我们讲解一下自定义组件的用法。 1 显示文本 官方模板在顶部除了显示图片外,还显示了一段文字介绍。文字是嵌套在容器组件里…...

【linux kernel】linux media子系统分析之media控制器设备
文章目录 一、抽象媒体设备模型二、媒体设备三、Entity四、Interfaces五、Pad六、Link七、Media图遍历八、使用计数和电源处理九、link设置十、Pipeline和Media流十一、链接验证十二、媒体控制器设备的分配器API 本文基于linux内核 4.19.4,抽象媒体设备模型框架的相…...
Scala--03
第6章 面向对象 Scala 的面向对象思想和Java 的面向对象思想和概念是一致的。 Scala 中语法和 Java 不同,补充了更多的功能。 6.1类和对象详解 6.1.1组成结构 构造函数: 在创建对象的时候给属性赋值 成员变量: 成员方法(函数) 局部变量 代码块 6.1.2构造器…...

【MongoDB】--MongoDB高级功能
目录 一、前言二、聚合管道aggregate1、示例说明2、具体代码实现一、前言 这里主要记录mongodb一些高级功能使用,如聚合。 二、聚合管道aggregate 聚合操作将来自多个文档的值组合在一起,并且可以对分组数据执行各种操作以返回单个结果,主要用于处理数据(诸如统计平均值,…...

C# new与malloc
目录 C# new与malloc C# new与malloc的区别 C# new关键字底层做的操作 C# new与malloc new关键字: new关键字在C#中用于实例化对象,并为其分配内存。它是面向对象编程的基本操作之一。使用new关键字可以在托管堆上分配内存,同时调用对象的构…...

微软MFC技术简明介绍
我是荔园微风,作为一名在IT界整整25年的老兵,今天来看一下微软MFC技术简明介绍 Visual C 与 MFC 微软公司于1992年上半年推出了C/C 7.0 产品时初次向世人介绍了MFC 1.0,这个产品包含了20,000行C原始代码,60个以上的Windows相关类…...
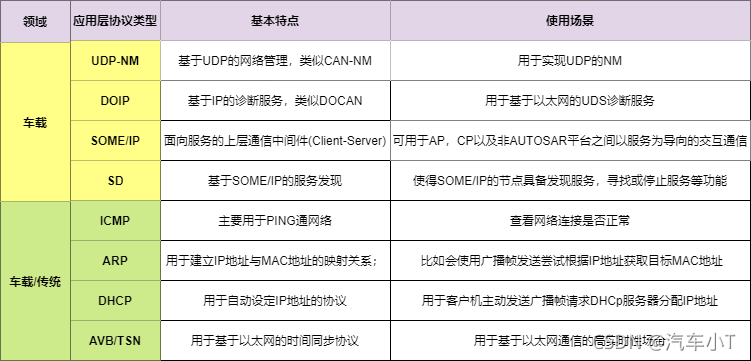
汽车电子Autosar之车载以太网
前言 近些年来,随着为了让汽车更加安全、智能、环保等,一系列的高级辅助驾驶功能喷涌而出。未来满足这些需求,就对传统的电子电器架构带来了严峻的考验,需要越来越多的电子部件参与信息交互,导致对网络传输速率&#x…...

MSP430_C语言例程注释详
本章选择了一些简单的C语言程序例题,这些程序的结构简单,编程技巧不多,题目虽然 简单,但是非常适合入门单片机的学习者学习MSP430单片机的C 语言编程。 如下列出了C语言例题运行的MSP430F149实验板硬件资源环境,熟悉…...
)
Vb+access库存管理系统(论文+开题报告+源代码+目录)
库存信息管理系统的基本问题1.1 库存信息管理系统的简介 本系统是为了提高腾达公司自动化办公的水平、经过详细的调查分析初步制定了腾达公司库存信息管理系统。基于WINDOWS 98 平台,使用Microsoft Access97, 在Visual Basic 6.0编程环境下开发的库存信息管理系统。该系统采用…...

Java 数组
在 Java 语言中,数组是一种基本的数据结构,可以存储一组相同类型的数据。本篇技术博客将详细介绍 Java 语言中的数组,包括一维数组和多维数组,以及数组的使用方法和注意事项。 一维数组 一维数组是指只有一行的数组,…...

CSDN 编程竞赛五十八期题解
竞赛总览 CSDN 编程竞赛五十八期:比赛详情 (csdn.net) 竞赛题解 题目1、打家劫舍 有一个小偷计划偷窃沿街的房屋,每间房内都藏有一定的现金,影响偷窃行为的唯一制约因素就是相邻的房屋装有相互连通的防盗系统。如果两间相邻的房屋在同一晚…...
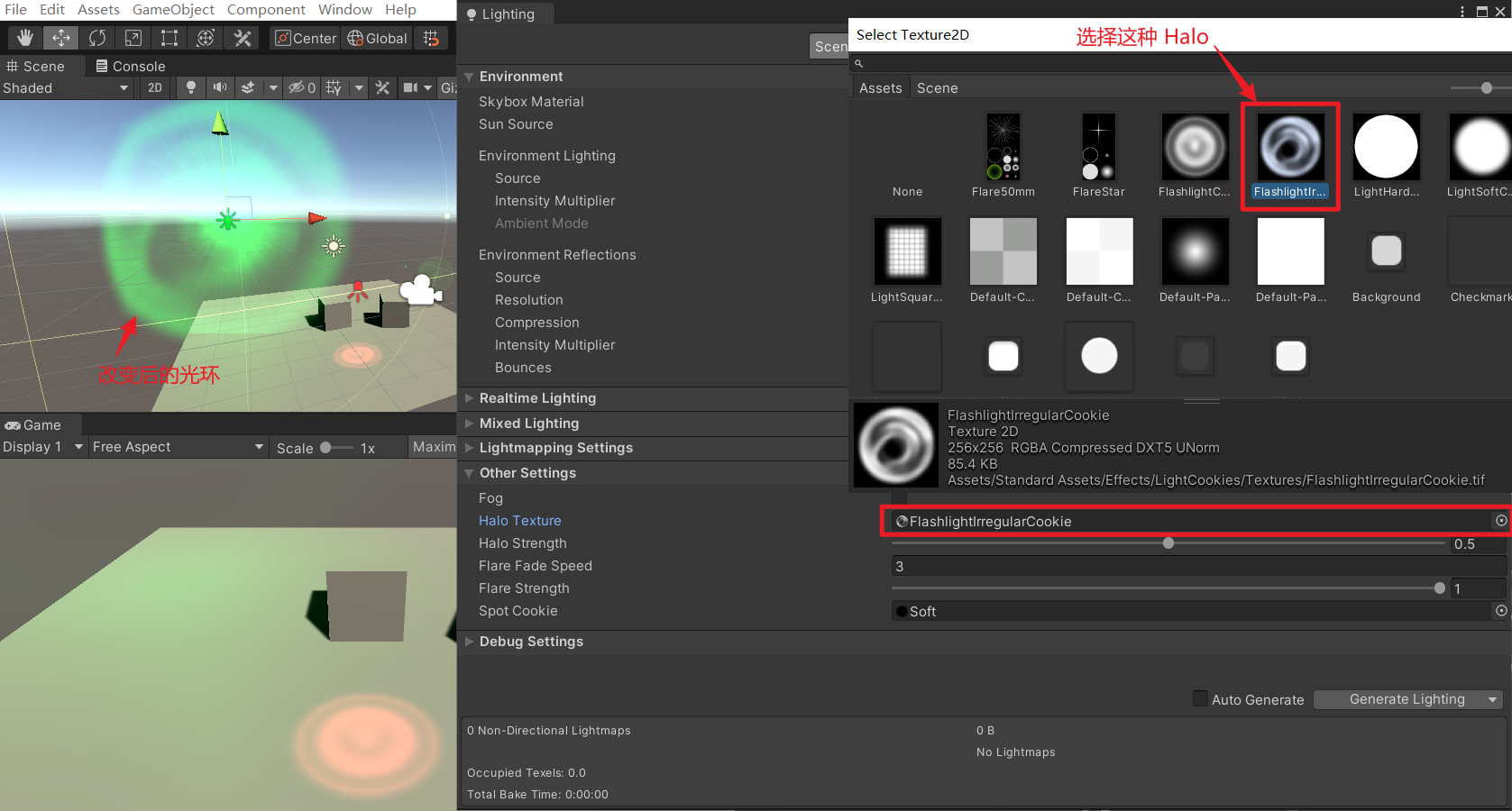
Unity入门6——光源组件
一、参数面板 二、参数介绍 Type:光源类型 Spot:聚光灯 Range:发光距离Spot Angle:光锥角度Directional:方向光Point:点光源Area(Baked Only):面光源 仅烘焙。预先算好&…...

C语言之动态内存分配(1)
目录 本章重点 为什么存在动态内存分配 动态内存函数的介绍 malloc free calloc realloc 常见的动态内存错误 几个经典的笔试题 柔性数组 动态内存管理—自己维护自己的内存空间的大小 首先我们申请一个变量,再申请一个数组 这是我们目前知道的向内存申请…...

AIGC新时代,注意政策走向,产业方向,拥抱可信AI。需要了解基本理论,基础模型,前沿进展,产品应用,以及小小的项目复现
AIGC(AI-Generated Content,AI生成内容)是指基于生成对抗网络(GAN)、大型预训练模型等人工智能技术的方法,通过对已有数据进行学习和模式识别,以适当的泛化能力生成相关内容的技术。类似的概念还…...

如何白嫖一年CSDN会员?618活动!亲测有效!!!
活动详情 CSDN会员免费送一年,仅剩3天! 下载权益延长一年! 一年一次的机会,错过了就要再等明年! 博主已经领取到了! 会员权益 1、修改专属域名,别人都是https://blog.csdn.net/qq_xxxxxxxx&a…...
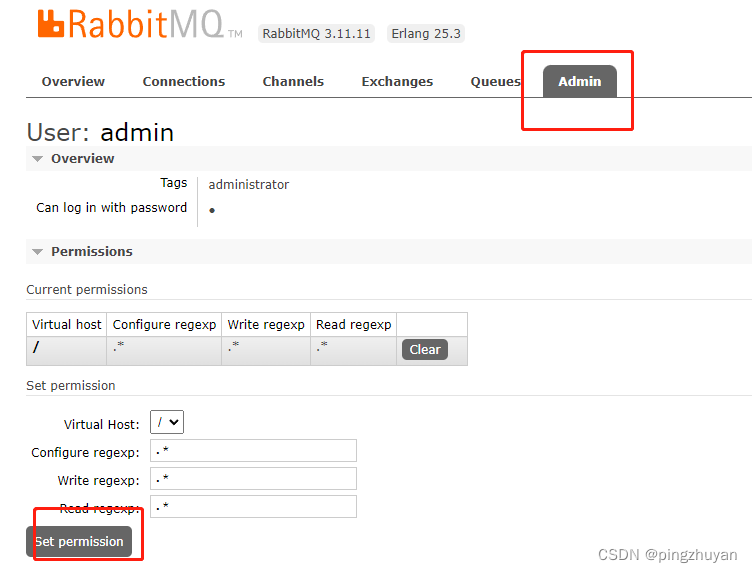
微服务: 00-rabbitmq出现的异常以及解决方案
目录 前言: 问题概述: 1. rabbitmq初始安装配置异常 -> 1.1 rabbitmq报您与此网站连接不是私密连接 --->1.1.1 上述问题解决方案 ---> 1.1.2 依次执行下面代码 -> 1.2 解决用户的No access情况 -> 1.2.1 使用设置的账号密码进行登录 -> 1.2.2 点击 Ad…...

Vue3与Vue2比较
Vue.js 3相对于Vue.js 2带来了一些重大变化,其中包括一些语法变化。 下面是Vue.js 2和Vue.js 3的一些语法差异比较: 一、语法差异比较 1.组件的注册方式不同 在Vue.js 2中,我们使用Vue.component()或者Vue.extend()方式创建一个组件。但是…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...