数仓实战 - 滴滴出行
项目大致流程:
1、项目业务背景
1.1 目的
本案例将某出行打车的日志数据来进行数据分析,例如:我们需要统计某一天订单量是多少、预约订单与非预约订单的占比是多少、不同时段订单占比等
数据海量 – 大数据
hive比MySQL慢很多
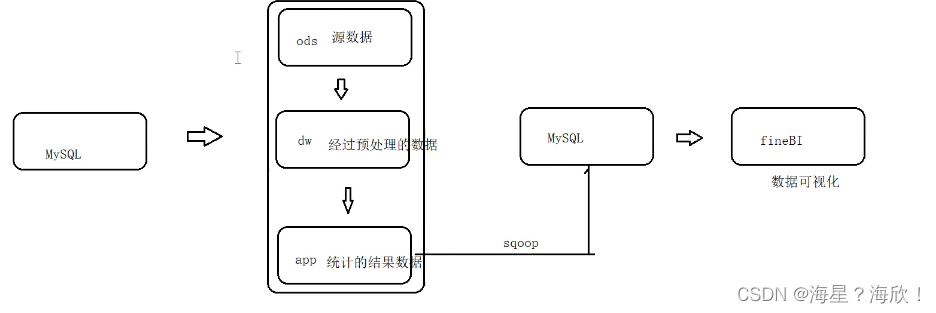
1.2 项目架构
- 用户打车的订单数据非常庞大。所以我们需要选择一个大规模数据的分布式文件系统来存储这些日志文件,此处,我们基于Hadoop的HDFS文件系统来存储数据。
- 为了方便进行数据分析,我们要将这些日志文件的数据映射为一张一张的表,所以,我们基于Hive来构建数据仓库。所有的数据,都会在Hive下来几种进行管理。为了提高数据处理的性能。
- 我们将基于MR引擎来进行数据开发。
- 我们将使用Zeppelin来快速将数据进行SQL指令交互。
- 我们使用Sqoop导出分析后的数据到传统型数据库,便于后期应用
- 我们使用fineBI来实现数据可视化展示
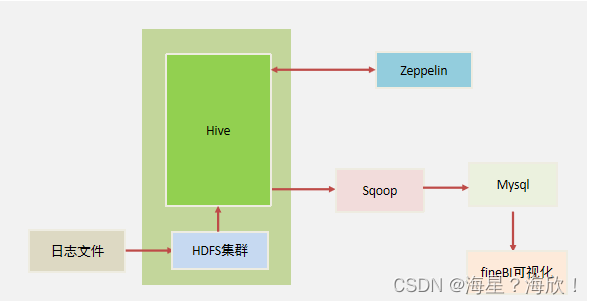
2、日志数据集介绍
四张表:打车表,取消订单表,支付表,评价表
1,日志数据文件
处理的数据都是一些文本日志,例如:以下就是一部门用户打车的日志文件。

一行就是一条打车订单数据,而且,一条数据是以逗号来进行分隔的,逗号分隔出来一个个的字段。
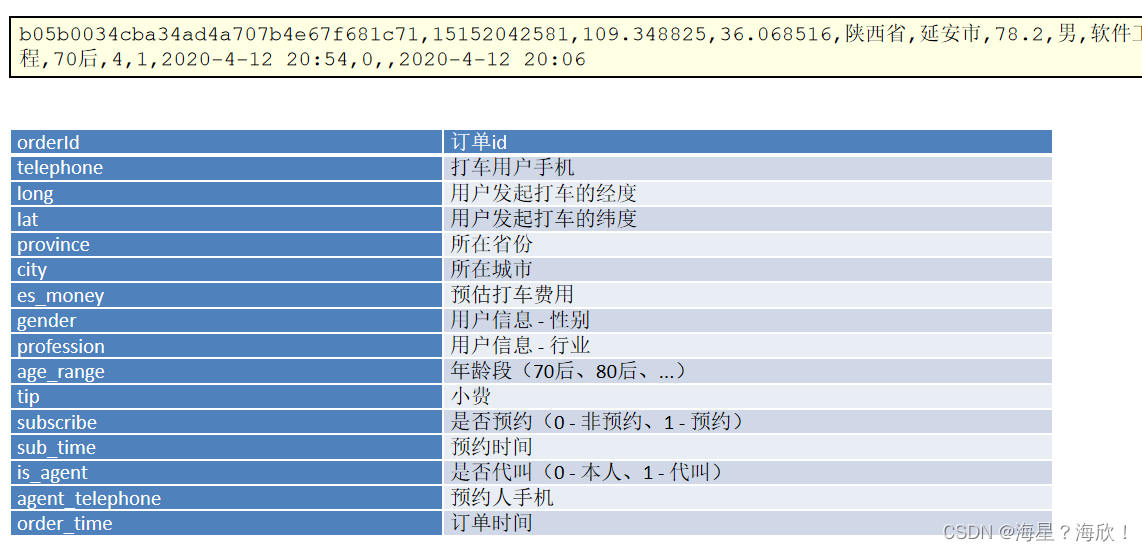
2,用户取消订单日志
当用户取消订单时,也会在系统后台产生一条日志。用户需求选择取消订单的原因。
3,用户支付日志
用户点击确认支付后,系统后台会将用户的支持信息保存为一条日志。

4,用户评价日志
我们点击提交评价后,系统后台也会产生一条日志。

3、数据仓库构建
面试问题:数仓如何从0到1?
我们的目标是分析用户打车的订单,进行各类的指标计算(指标,例如:订单的总数、订单的总支付金额等等)。
思想:可以将日志数据上传到HDFS保存下来,每天都可以进行上传,HDFS可以保存海量的数据。同时,可以将HDFS中的数据文件,对应到Hive的表中。但需要考虑一个问题,就是业务系统的日志数据不一定是能够直接进行分析的,
例如:我们需要分析不同时段的订单占比,凌晨有多少订单、早上有多少订单、上午有多少订单等。但是,我们发现,原始的日志文件中,并没有区分该订单的是哪个时间段的字段。所以,我们需要对日志文件的原始数据进行预处理,才能进行分析。
我们会有这么几类数据要考虑:
- 原始日志数据(业务系统中保存的日志文件数据) ods
- 预处理后的数据 dw
- 分析结果数据 app
这些数据我们都通过Hive来进行处理,因为Hive可以将数据映射为一张张的表,然后就可以通过编写HQL来处理数据了,简单、快捷、高效。为了区分以上这些数据,我们将这些数据对应的表分别保存在不同的数据库中。
为了方便组织、管理上述的三类数据,我们将数仓分成不同的层,简单来说,就是分别将三类不同的数据保存在Hive的不同数据库中。
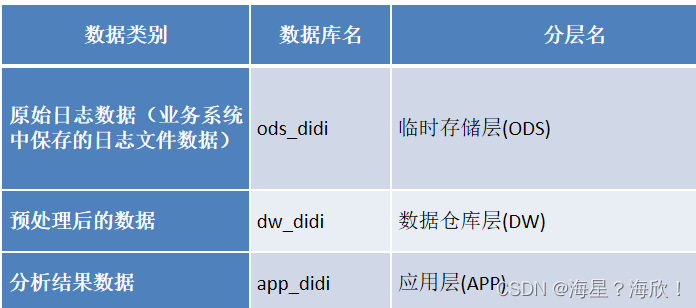
1)在hive构建三层数据仓库:ods、dw、app:
--1:创建数据库 -- 1.1 创建ods库create database if not exists ods_didi;-- 1.2 创建dw库create database if not exists dw_didi;-- 1.3 创建app库create database if not exists app_didi;
2)在ods层创建四张表
--2:创建表
-- 2.1 创建订单表结构create table if not exists ods_didi.t_user_order(orderId string comment '订单id',telephone string comment '打车用户手机',lng string comment '用户发起打车的经度',lat string comment '用户发起打车的纬度',province string comment '所在省份',city string comment '所在城市',es_money double comment '预估打车费用',gender string comment '用户信息 - 性别',profession string comment '用户信息 - 行业',age_range string comment '年龄段(70后、80后、...)',tip double comment '小费',subscribe int comment '是否预约(0 - 非预约、1 - 预约)',sub_time string comment '预约时间',is_agent int comment '是否代叫(0 - 本人、1 - 代叫)',agent_telephone string comment '预约人手机',order_time string comment '预约时间')partitioned by (dt string comment '时间分区') ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
--2.2 创建取消订单表
create table if not exists ods_didi.t_user_cancel_order(orderId string comment '订单ID',cstm_telephone string comment '客户联系电话',lng string comment '取消订单的经度',lat string comment '取消订单的纬度',province string comment '所在省份',city string comment '所在城市',es_distance double comment '预估距离',gender string comment '性别',profession string comment '行业',age_range string comment '年龄段',reason int comment '取消订单原因(1 - 选择了其他交通方式、2 - 与司机达成一致,取消订单、3 - 投诉司机没来接我、4 - 已不需要用车、5 - 无理由取消订单)',cancel_time string comment '取消时间'
)
partitioned by (dt string comment '时间分区')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
--2.3 创建订单支付表
create table if not exists ods_didi.t_user_pay_order(id string comment '支付订单ID',orderId string comment '订单ID',lng string comment '目的地的经度(支付地址)',lat string comment '目的地的纬度(支付地址)',province string comment '省份',city string comment '城市',total_money double comment '车费总价',real_pay_money double comment '实际支付总额',passenger_additional_money double comment '乘客额外加价',base_money double comment '车费合计',has_coupon int comment '是否使用优惠券(0 - 不使用、1 - 使用)',coupon_total double comment '优惠券合计',pay_way int comment '支付方式(0 - 微信支付、1 - 支付宝支付、3 - QQ钱包支付、4 - 一网通银行卡支付)',mileage double comment '里程(单位公里)',pay_time string comment '支付时间'
)
partitioned by (dt string comment '时间分区')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ; --2.4创建用户评价表
create table if not exists ods_didi.t_user_evaluate(id string comment '评价日志唯一ID',orderId string comment '订单ID',passenger_telephone string comment '用户电话',passenger_province string comment '用户所在省份',passenger_city string comment '用户所在城市',eva_level int comment '评价等级(1 - 一颗星、... 5 - 五星)',eva_time string comment '评价时间'
)
partitioned by (dt string comment '时间分区')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ; comment—注释
show tables --查看一下
4、数据分区表构建
3)表数据加载
大规模数据的处理,必须要构建分区。我们此处的需求每天都会进行数据分析,采用的是T+1的模式。
就是假设今天是2021-01-01,那么1月1日的分析结果在第二天才能看到,也就是2021-01-02查看到上一天的数据分析结果。此处,我们采用最常用的分区方式,使用日期来进行分区。
-3:给表加载数据
--3.1、创建本地路径,上传源日志文件
mkdir -p /export/data/didi--3.2、通过load命令给表加载数据,并指定分区
load data local inpath '/export/data/didi/order.csv' into table t_user_order partition (dt='2020-04-12');
load data local inpath '/export/data/didi/cancel_order.csv' into table t_user_cancel_order partition (dt='2020-04-12');
load data local inpath '/export/data/didi/pay.csv' into table t_user_pay_order partition (dt='2020-04-12');
load data local inpath '/export/data/didi/evaluate.csv' into table t_user_evaluate partition (dt='2020-04-12');加载完数据后也是查看一下,数据是否成功进入;
select * from t_user_order limit 1;
select * from t_user_cancel_order limit 1;
select * from t_user_pay_order limit 1;
select * from t_user_evaluate limit 1;
5、数据预处理
现在数据已经准备好了,接下来需要对ods层中的数据进行预处理。
数据预处理是数据仓库开发中的一个重要环节。目的主要是让预处理后的数据更容易进行数据分析,并且能够将一些非法的数据处理掉,避免影响实际的统计结果。
需要在预处理之前考虑以下需求:
- 过滤掉order_time长度小于8的数据,如果小于8,表示这条数据不合法,不应该参加统计。—length(order_time)>=8
- 将一些0、1表示的字段,处理为更容易理解的字段。例如:subscribe字段,0表示非预约、1表示预约。我们需要添加一个额外的字段,用来展示非预约和预约,这样将来我们分析的时候,跟容易看懂数据。—case when
- order_time字段为2020-4-12 1:15,为了将来更方便处理,我们统一使用类似 2020-04-12 01:15:00来表示,这样所有的order_time字段长度是一样的。并且将日期获取出来 为了方便将来按照年、月、日、小时统计,我们需要新增这几个字段。后续要分析一天内,不同时段的订单量,我们需要在预处理过程中将订单对应的时间段提前计算出来。例如:1:00-5:00为凌晨。

多增加了7个字段—形成宽表,包含以下字段:
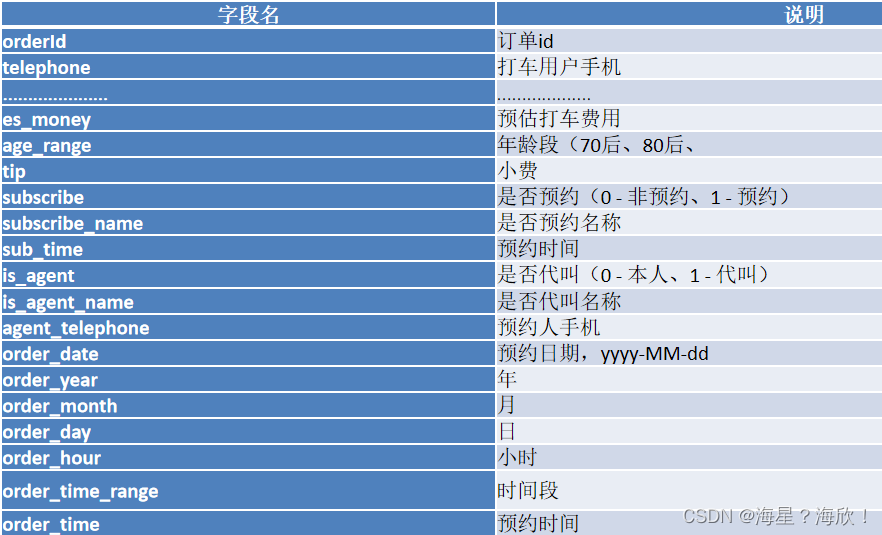
--4:数据预处理
--建表
create table if not exists dw_didi.t_user_order_wide(orderId string comment '订单id',telephone string comment '打车用户手机',lng string comment '用户发起打车的经度',lat string comment '用户发起打车的纬度',province string comment '所在省份',city string comment '所在城市',es_money double comment '预估打车费用',gender string comment '用户信息 - 性别',profession string comment '用户信息 - 行业',age_range string comment '年龄段(70后、80后、...)',tip double comment '小费',subscribe int comment '是否预约(0 - 非预约、1 - 预约)',subscribe_name string comment '是否预约名称',sub_time string comment '预约时间',is_agent int comment '是否代叫(0 - 本人、1 - 代叫)',is_agent_name string comment '是否代叫名称',agent_telephone string comment '预约人手机',order_date string comment '预约时间,yyyy-MM-dd',order_year string comment '年',order_month string comment '月',order_day string comment '日',order_hour string comment '小时',order_time_range string comment '时间段',order_time string comment '预约时间'
)
partitioned by (dt string comment '时间分区')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ; --转宽表HQL语句
--------------------------------------
--date_format将字符串转为日期
select date_format('2020-1-1', 'yyyy-MM-dd'); -- 2020-01-01
select date_format('2020-1-1 12:23', 'yyyy-MM-dd'); -- 2020-01-01
select date_format('2020-1-1 12:23:35', 'yyyy-MM-dd'); -- 2020-01-01select date_format('2020-1-1 1:1:1', 'yyyy-MM-dd HH:mm:ss'); -- 2020-01-01 01:01:01select hour(date_format('2020-1-1 1:1:00', 'yyyy-MM-dd HH:mm:ss')); -- 2020-01-01 01:01:01--concat字符串的拼接
select concat('aaa','bbb','ccc');-- aaabbbccc
--length 获取字符串长度
select length('aaabbb'); -- 6
一天新增4500TB,一个服务器的磁盘存储容量10T
生成宽表后,往宽表中插入数据
如何将一个表的查询结果保存到另外一张表:
insert overwrite table 表名1 select 字段 from 表名2
insert overwrite table dw_didi.t_user_order_wide partition(dt='2020-04-12')
select orderId,telephone,lng,lat,province,city,es_money,gender,profession,age_range,tip,subscribe,case when subscribe = 0 then '非预约'when subscribe = 1 then'预约'end as subscribe_name,date_format(concat(sub_time,':00'), 'yyyy-MM-dd HH:mm:ss') as sub_time,is_agent,case when is_agent = 0 then '本人'when is_agent = 1 then '代叫'end as is_agent_name,agent_telephone,date_format(order_time, 'yyyy-MM-dd') as order_date, -- 2020-1-1 --->2020-01-01year(date_format(order_time, 'yyyy-MM-dd')) as order_year, --2020month(date_format(order_time, 'yyyy-MM-dd')) as order_month, --12day(date_format(order_time, 'yyyy-MM-dd')) as order_day, --23hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) as order_hour,case when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 1 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 5 then '凌晨'when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 5 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 8 then '早上'when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 8 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 11 then '上午'when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 11 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 13 then '中午'when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 13 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 17 then '下午'when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 17 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 19 then '晚上'when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 19 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 20 then '半夜'when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 20 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 24 then '深夜'when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) >= 0 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 1 then '深夜'else 'N/A'end as order_time_range,date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss') as order_time
from ods_didi.t_user_order where dt = '2020-04-12' and length(order_time) >= 8;
6、订单指标分析
1 总订单笔数
select count(orderid) as total_cnt
fromdw_didi.t_user_order_wide
wheredt = '2020-04-12'
;
-- 创建保存日期对应订单笔数的app表
create table if not exists app_didi.t_order_total(date_val string comment '日期(年月日)',count int comment '订单笔数'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;--加载数据到app表
insert overwrite table app_didi.t_order_total partition(month='2020-04')
select '2020-04-12',count(orderid) as total_cnt
fromdw_didi.t_user_order_wide
wheredt = '2020-04-12'
;
- 预约和非预约用户占比
需求:
求出预约用户订单所占的百分比:
select 预约订单总数 / 总订单数 from 预约统计订单数表,总订单数表
union all
select 非预约订单总数 / 总订单数 from 非预约统计订单数表,总订单数表
select '2020-04-12','预约',concat(round(t1.total_cnt /t2.total_cnt *100,2),'%') as subscribe
from (select count(orderid) as total_cntfromdw_didi.t_user_order_widewheresubscribe = 1 and dt = '2020-04-12' )t1,(select count(orderid) as total_cntfromdw_didi.t_user_order_widewheredt = '2020-04-12')t2union all --将上边的查询结果和下边的查询结果进行合并select '2020-04-12','非预约',concat(round(t1.total_cnt /t2.total_cnt *100,2),'%') as nosubscribe
from (select count(orderid) as total_cntfromdw_didi.t_user_order_widewheresubscribe = 0 and dt = '2020-04-12' )t1,(select count(orderid) as total_cntfromdw_didi.t_user_order_widewheredt = '2020-04-12')t2-- 创建保存日期对应订单笔数的app表
create table if not exists app_didi.t_order_subscribe_percent(date_val string comment '日期',subscribe_name string comment '是否预约',percent_val string comment '百分比'
)partitioned by (month string comment '年月yyyy-MM')
row format delimited fields terminated by ','--加载数据到app表
insert overwrite table app_didi.t_order_subscribe_percent partition(month='2020-04')
select '2020-04-12','预约',concat(round(t1.total_cnt /t2.total_cnt *100,2),'%') as subscribe
from (select count(orderid) as total_cntfromdw_didi.t_user_order_widewheresubscribe = 1 and dt = '2020-04-12' )t1,(select count(orderid) as total_cntfromdw_didi.t_user_order_widewheredt = '2020-04-12')t2union all
select '2020-04-12','非预约',concat(round(t1.total_cnt /t2.total_cnt *100,2),'%') as nosubscribe
from (select count(orderid) as total_cntfromdw_didi.t_user_order_widewheresubscribe = 0 and dt = '2020-04-12' )t1,(select count(orderid) as total_cntfromdw_didi.t_user_order_widewheredt = '2020-04-12')t23 不同时段的占比分析
--编写HQL语句
selectorder_time_range,count(*) as order_cnt
fromdw_didi.t_user_order_wide
wheredt = '2020-04-12'
group byorder_time_range
--创建APP层表
create table if not exists app_didi.t_order_timerange_total(date_val string comment '日期',timerange string comment '时间段',count int comment '订单数量'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;--加载数据到APP表
insert overwrite table app_didi.t_order_timerange_total partition(month = '2020-04')
select'2020-04-12',order_time_range,count(*) as order_cnt
fromdw_didi.t_user_order_wide
wheredt = '2020-04-12'
group byorder_time_range
;4 不同地域订单占比
--编写HQL ---方式1
selectprovince,count(*) as order_cnt
fromdw_didi.t_user_order_wide
wheredt = '2020-04-12'
group byprovince
;--编写HQL ---方式2
select * from
(select *,dense_rank() over(partition by province order by t.total_cnt desc) as rkfrom(select '2020-04-12',province,city,count(orderid) as total_cntfrom dw_didi.t_user_order_widegroup by province,city)t
)tt
where tt.rk <=3;--创建APP表
create table if not exists app_didi.t_order_province_total(date_val string comment '日期',province string comment '省份',count int comment '订单数量'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;--数据加载到APP表
insert overwrite table app_didi.t_order_province_total partition(month = '2020-04')
select'2020-04-12',province,count(*) as order_cnt
fromdw_didi.t_user_order_wide
wheredt = '2020-04-12'
group byprovince
order by order_cnt desc
;5 不同年龄段,不同时段订单占比
--不同年龄段的订单统计
select
'2020-04-12',age_range,count(*)
from dw_didi.t_user_order_wide
where dt='2020-04-12'
group by age_range--不同时段的订单统计
select
'2020-04-12',order_time_range,count(*)
from dw_didi.t_user_order_wide
where dt='2020-04-12'
group by order_time_range--不同年龄段,不同时段的订单统计
select'2020-04-12',age_range,order_time_range,count(*) as order_cnt
fromdw_didi.t_user_order_wide
wheredt = '2020-04-12'
group byage_range,order_time_range
;--创建APP表
create table if not exists app_didi.t_order_age_and_time_range_total(date_val string comment '日期',age_range string comment '年龄段',order_time_range string comment '时段',count int comment '订单数量'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;--加载数据到APP表
insert overwrite table app_didi.t_order_age_and_time_range_total partition(month = '2020-04')
select'2020-04-12',age_range,order_time_range,count(*) as order_cnt
fromdw_didi.t_user_order_wide
wheredt = '2020-04-12'
group byage_range,order_time_range
;
7、Sqoop数据导出
Sqoop安装
-- 准备工作#验证sqoop是否工作
/export/server/sqoop-1.4.7/bin/sqoop list-databases \
--connect jdbc:mysql://192.168.88.100:3306/ \
--username root \
--password 123456 --1:mysql创建目标数据库和目标表#创建目标数据库create database if not exists app_didi;#创建订单总笔数目标表create table if not exists app_didi.t_order_total(order_date date,count int);--2:导出订单总笔数表数据/export/server/sqoop-1.4.7/bin/sqoop export \--connect jdbc:mysql://192.168.88.100:3306/app_didi \--username root \--password 123456 \--table t_order_total \--export-dir /user/hive/warehouse/app_didi.db/t_order_total/month=2020-048、finebi数据可视化
--Superset可视化superset run -h 192.168.88.100 -p 8099 --with-threads --reload --debuggermysql+pymysql://root:123456@192.168.88.100/app_didi?charset=utf8相关文章:
数仓实战 - 滴滴出行
项目大致流程: 1、项目业务背景 1.1 目的 本案例将某出行打车的日志数据来进行数据分析,例如:我们需要统计某一天订单量是多少、预约订单与非预约订单的占比是多少、不同时段订单占比等 数据海量 – 大数据 hive比MySQL慢很多 1.2 项目架…...
python虚拟环境与环境变量
一、环境变量 1.环境变量 在命令行下,使用可执行文件,需要来到可执行文件的路径下执行 如果在任意路径下执行可执行文件,能够有响应,就需要在环境变量配置 2.设置环境变量 用户变量:当前用户登录到系统,…...

BeautifulSoup文档4-详细方法 | 用什么方法对文档树进行搜索?
4-详细方法 | 用什么方法对文档树进行搜索?1 过滤器1.1 字符串1.2 正则表达式1.3 列表1.4 True1.5 可以自定义方法2 find_all()2.1 参数原型2.2 name参数2.3 keyword 参数2.4 string 参数2.5 limit 参数2.6 recursive 参数3 find()4 find_parents()和find_parent()5…...

初识Tkinter界面设计
目录 前言 一、初识Tkinter 二、Label控件 三、Button控件 四、Entry控件 前言 本文简单介绍如何使用Python创建一个界面。 一、初识Tk...

软件测试面试题中的sql题目你会做吗?
目录 1.学生表 2.一道SQL语句面试题,关于group by表内容: 3.表中有A B C三列,用SQL语句实现:当A列大于B列时选择A列否则选择B列,当B列大于C列时选择B列否则选择C列 4. 5.姓名:name 课程:subject 分数&…...

VS实用调试技巧
一.什么是BUG🐛Bug一词的原意是虫子,而在电脑系统或程序中隐藏着的一些未被发现的缺陷或问题,人们也叫它"bug"。这是为什么呢?这就要追溯到一个程序员与飞蛾的故事了。Bug的创始人格蕾丝赫柏(Grace Murray H…...
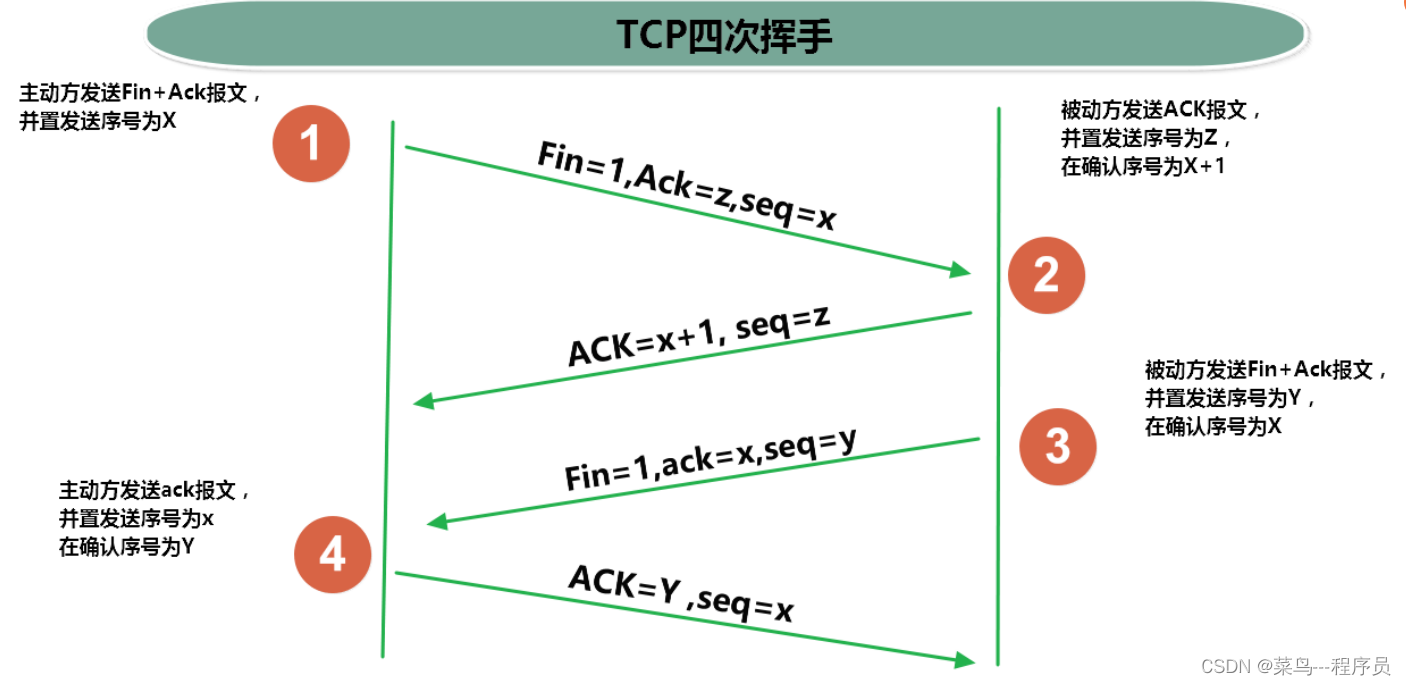
通俗易懂理解三次握手、四次挥手(TCP)
文章目录1、通俗语言理解1.1 三次握手1.2 四次挥手2、进一步理解三次握手和四次挥手2.1 三次握手2.2 四次挥手1、通俗语言理解 1.1 三次握手 C:客户端 S:服务器端 第一次握手: C:在吗?我要和你建立连接。 第二次握手ÿ…...
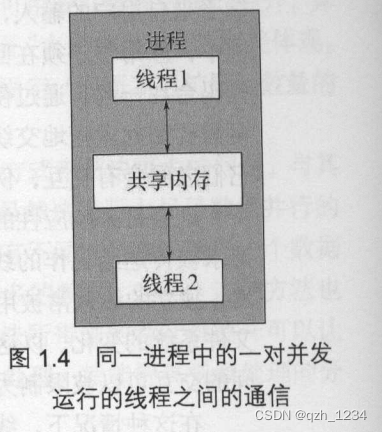
1.1 什么是并发
1.1 什么是并发 并发:指两个或更多独立的活动同时发生。并发在生活中随处可见。我们可以一边走路一边说话,也可以两只手同时做不同的动作。 1.1.1 计算机系统中的并发 当我们提到计算机术语的“并发”,指的是在单个系统里同时执行多个独立…...

万字讲解你写的代码是如何跑起来的?
今天我们来思考一个简单的问题,一个程序是如何在 Linux 上执行起来的? 我们就拿全宇宙最简单的 Hello World 程序来举例。 #include <stdio.h> int main() {printf("Hello, World!\n");return 0; } 我们在写完代码后,进行…...

034.Solidity入门——21不可变量
Solidity 中的不可变量是在编译时就被确定的常量,也称为常量变量(constant variable)或只读变量(read-only variable)。这些变量在定义时必须立即初始化,并且在整个合约中都无法被修改,可以在函…...
Vulnhub 渗透练习(四)—— Acid
环境搭建 环境下载 kail 和 靶机网络适配调成 Nat 模式,实在不行直接把网络适配还原默认值,再重试。 信息收集 主机扫描 没扫到,那可能端口很靠后,把所有端口全扫一遍。 发现 33447 端口。 扫描目录,没什么有用的…...

C++ 在线工具
online编译器https://godbolt.org/Online C Compiler - online editor (onlinegdb.com) https://www.onlinegdb.com/online_c_compilerC Shell (cpp.sh) https://cpp.sh/在线文档Open Standards (open-std.org)Index of /afs/cs.cmu.edu/academic/class/15211/spring.96/wwwC P…...

使用MMDetection进行目标检测、实例和全景分割
MMDetection 是一个基于 PyTorch 的目标检测开源工具箱,它是 OpenMMLab 项目的一部分。包含以下主要特性: 支持三个任务 目标检测(Object Detection)是指分类并定位图片中物体的任务实例分割(Instance Segmentation&a…...
使用ThreadLocal实现当前登录信息的存取
有志者,事竟成 文章持续更新,可以关注【小奇JAVA面试】第一时间阅读,回复【资料】获取福利,回复【项目】获取项目源码,回复【简历模板】获取简历模板,回复【学习路线图】获取学习路线图。 文章目录一、使用…...

高通平台开发系列讲解(Android篇)AudioTrack音频流数据传输
文章目录 一、音频流数据传输通道创建1.1、流程描述1.2、流程图解二、音频数据传输2.1、流程描述2.2、流程图解沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇章主要图解AudioTrack音频流数据传输 。 一、音频流数据传输通道创建 1.1、流程描述 AudioTrack在set函…...

BUUCTF-firmware1
题目下载:下载 新题型,记录一下 题目给出了flag形式,md5{网址:端口},下载发现是一个.bin文件 二进制文件,其用途依系统或应用而定。一种文件格式binary的缩写。一个后缀名为".bin"的文件&#x…...

【C++之容器篇】二叉搜索树的理论与使用
目录前言一、二叉搜索树的概念二、二叉搜素树的模拟实现(增删查非递归实现)1. 二叉搜素树的结点2. 二叉搜索树的实现(1). 二叉搜索树的基本结构(2)构造函数(3)查找函数(4…...

爬虫神级解析工具之XPath:用法详解及实战
一、XPATH是什么 Xpath最初被设计用来搜寻XML文档,但它同样适用于HTML文档的搜索。通过简洁明了的路径选择表达式,它提供了强大的选择功能;同时得益于其内置的丰富的函数,它可以匹配和处理字符串、数值、时间等数据格式,几乎所有节点我们都可以通过Xpath来定位。 在Pyth…...
Markdown编辑器
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注…...
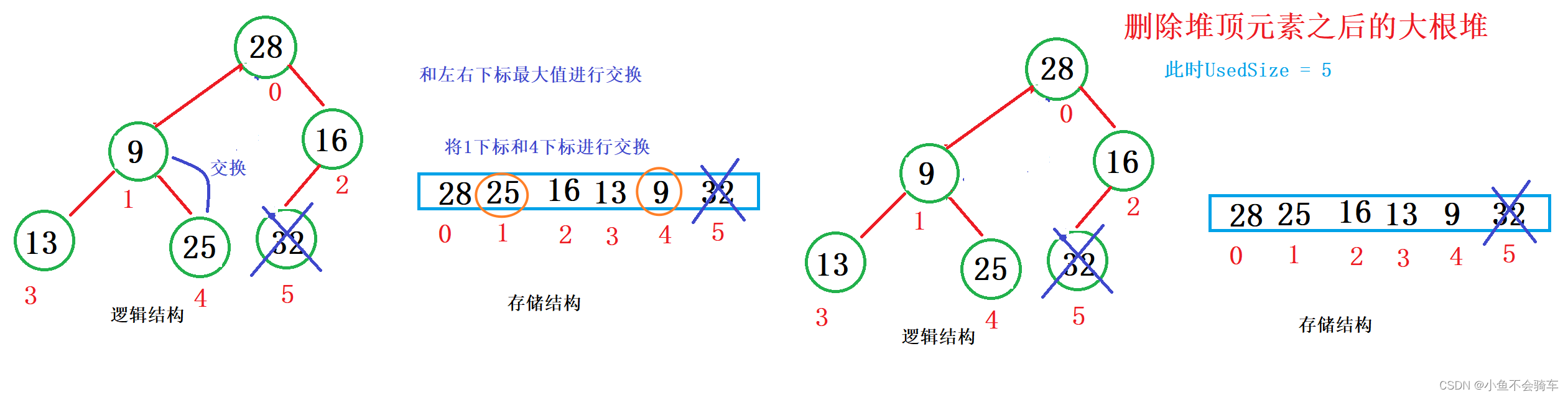
数据结构<堆>
🎇🎇🎇作者: 小鱼不会骑车 🎆🎆🎆专栏: 《数据结构》 🎓🎓🎓个人简介: 一名专科大一在读的小比特,努力学习编程是我唯一…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...