Transformer论文阅读:ViT算法笔记
标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
会议:ICLR2021
论文地址:https://openreview.net/forum?id=YicbFdNTTy
文章目录
- Abstract
- 1 Introduction
- 2 Related Work
- 3 Method
- 3.1 Vision Transformer
- 3.2 Fine-Tuning and Higher Resolution
- 4 Experiments
- 4.1 Setup
- 4.2 Comparison to State of the Art
- 4.3 Pre-Training Data Requirements
- 4.4 Scaling Study
- 4.5 Inspecting Vision Transformer
- 4.6 Self-Supervision
- 5 Conclusion
Abstract
虽然Transformer结构已经成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。在视觉中,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件同时保持它们的整体结构。我们表明,这种对CNN的依赖不是必要的,直接用于图像块序列的纯Transformer可以在图像分类任务中表现得很好。当在大量数据上进行预训练,再迁移到多个中小型图像识别基准(ImageNet、CIFAR- 00、VTAB等)时,视觉变换器(Vision Transformer,ViT)与SOTA的卷积网络相比取得了优异的结果,并且需要的训练计算资源更少。
1 Introduction
基于自注意力机制的结构,尤其是Transformers,已经成为自然语言处理(NLP)的首选模型。主流的方法是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调。得益于Transformers的计算效率和可扩展性,训练参数超过100B的规模空前的模型已经成为可能。随着模型和数据集的增长,目前仍然没有性能饱和的迹象。
然而,在计算机视觉中,卷积结构仍然占据主导地位。受NLP成功的启发,许多工作尝试将CNN结构与自注意力相结合,其中有些完全取代了卷积。后者模型虽然在理论上是有效的,但由于使用了专门的注意力模式,在现代硬件加速器上还没能有效地推广。因此,在大规模图像识别中,经典的ResNet式结构仍然是SOTA的。
受NLP中Transformer大规模成功的启发,我们以尽可能少的改动,直接将标准的Transformer用在图片上进行实验。为此,我们将图像拆分为小块(patch),并提供这些patch的线性嵌入序列作为Transformer的输入。图片块像NLP程序里一样被当作tokens(words)。我们以监督的方式训练图像分类模型。
当在中等大小的数据集(如ImageNet)上进行训练时,如果没有强大的正则化,这些模型的精度会比同等大小的ResNets低几个百分点。这种看似令人沮丧的结果可能是意料之中的:Transformers缺少CNN固有的一些归纳偏差,如平移等变性和局部性,因此在训练数据量不足时不能很好地泛化。
然而,如果在更大的数据集(14M~300M张图像)上训练模型,情况会发生变化。我们发现大规模训练要比归纳偏差更重要。我们的视觉变换器(Vision Transformer,ViT)在足够大规模的预训练后,再迁移到数据点较少的任务时取得了优异的效果。当在公开的ImageNet-21k数据集或内部的JFT-300M数据集上预训练后,ViT在多个图像识别基准上接近或超过了当前的SOTA。
2 Related Work
Transformers由Vaswani等人提出用于机器翻译,此后成为许多NLP任务中SOTA的方法。基于大型Transformer的模型往往在大型语料库上进行预训练,然后针对手头的任务进行微调:BERT使用一个去噪自监督预训练任务,而GPT系列使用语言建模作为其预训练任务。
自注意力在图像上的简单应用需要每个像素关注所有其它像素。由于像素数平方级的代价,这并不能扩展到实际的输入尺寸。因此,为了将Transformers用于图像处理的环境,过去已经尝试了几种近似方法。Parmar等人对每个查询像素只在局部而不是全局邻域使用自注意力。这样的局部多头点积自注意力块可以完全替代卷积。在不同的工作方向中,Sparse Transformers采用可扩展的全局自注意力近似以便适用于图像。改变注意力的另一种方法是将其用于不同大小的块,在极端情况下只沿单个坐标轴。很多这些特殊的注意力结构在计算机视觉任务上展示出有前景的结果,但需要复杂的工程才能在硬件加速器上有效地实现。
与我们最相关的是Cordonnier等人的模型,该模型从输入图像中提取大小为2×2的patch,并在顶部使用完全自注意力。该模型与ViT非常相似,但我们的工作进一步证明了大规模预训练使得原始的Transformers与SOTA的CNN具有竞争力(甚至更好)。此外,Cordonnier等人使用2×2像素的小块尺寸,这使得模型只适用于小分辨率的图像,而我们也处理中等分辨率的图像。
卷积神经网络(CNNs)与自注意力的结合也引起了广泛的兴趣,例如通过增强特征图进行图像分类,或者通过自注意力进一步处理CNN的输出,如用于目标检测、视频处理、图像分类、无监督目标发现或统一的文本视觉任务。
最近另一个相关的模型是图像GPT(iGPT),它在减少图像分辨率和颜色空间后,将Transformers用于图像像素。该模型以无监督的方式作为生成模型进行训练,然后可以对生成的表示进行微调或线性搜索,以提高分类性能,在ImageNet上达到72%的最高精度。
我们的工作增加了在比标准ImageNet数据集更大规模上探索图像识别的论文集。使用额外的数据源可以在标准基准上取得SOTA的结果。此外,Sun等人研究了CNN性能如何随数据集大小变化;Kolesnikov等人和Djolonga等人在ImageNet-21k和JFT-300M等大规模数据集上进行CNN迁移学习的实证研究。我们也关注后两个数据集,但训练的是Transformers而不是之前工作中使用的基于ResNet的模型。
3 Method
在模型设计中,我们尽可能地遵循原始的Transformer。这种故意简单设置的一个优点是,可扩展的NLP Transformer结构——以及它们的高效实现——几乎可以开箱即用。
3.1 Vision Transformer

模型的概述如图1所示。标准的Transformer接收一个1维的token嵌入序列作为输入。为了处理2维图像,我们将图像x∈RH×W×C\mathrm x\in\mathbb R^{H×W×C}x∈RH×W×C重构为一系列展平的2维图像块xp∈RN×(P2⋅C)\mathrm x_p\in\mathbb R^{N×(P^2·C)}xp∈RN×(P2⋅C),其中,(H,W)(H,W)(H,W)是原始图像的分辨率,(P,P)(P,P)(P,P)是每个图像块的分辨率,N=HW/P2N=HW/P^2N=HW/P2是产生的图像块数,它也是Transformer的有效输入序列长度。Transformer在其所有层中使用恒定的隐藏向量大小DDD,因此我们将图像块展平,并使用可训练的线性投影来将其映射到DDD维(公式1)。我们将此投影的输出称为块嵌入(patch embeddings)。
与BERT的[class] token类似,我们在嵌入块(z00=xclass\mathrm z_0^0=\mathrm x_{\mathrm{class}}z00=xclass)的序列上预置一个可学习的嵌入,其在Transformer编码器输出处的状态(zL0\mathrm z_L^0zL0)作为图像表示y\mathrm yy(公式4)。在预训练和微调期间,一个分类头被附加到zL0\mathrm z_L^0zL0。分类头由一个MLP实现,在预训练时有一个隐藏层,在微调时有一个线性层。
位置嵌入(position embeddings)被添加到块嵌入(patch embeddings)以保留位置信息。我们使用标准的可学习的1维位置嵌入,因为我们没有观察到使用更先进的2维感知位置嵌入带来的显著性能增益(附录D.3)。得到的嵌入向量序列作为编码器的输入。
Transformer编码器由交替的多头自注意力(multiheaded self-attention,MSA,见附录A)和MLP块(公式2和3)层组成。Layernorm(LN)用于每个块之前,残差连接用于每个块之后。
MLP包含两个具有GELU非线性的层。
z0=[xclass;xp1E;xp2E;⋅⋅⋅;xpNE]+Epos,E∈R(P2⋅C)×D,Epos∈R(N+1)×Dz′ℓ=MSA(LN(zℓ−1))+zℓ−1,ℓ=1...Lzℓ=MLP(LN(z′ℓ))+z′ℓ,ℓ=1...Ly=LN(zL0)\begin{align} \mathrm z_0&=[\mathrm x_{\mathrm{class}};~\mathrm x_p^1\bold E;~\mathrm x_p^2\bold E;~···;~\mathrm x_p^N\bold E]+\bold E_{pos},&\bold E&\in\mathbb R^{(P^2·C)×D},\bold E_{pos}\in\mathbb R^{(N+1)×D}&\\ \mathrm {z^\prime}_\ell&=\mathrm{MSA}(\mathrm{LN}(\mathrm z_{\ell-1}))+\mathrm z_{\ell-1},&\ell&=1...L&\\ \mathrm z_\ell&=\mathrm{MLP}(\mathrm{LN}(\mathrm {z^\prime}_\ell))+\mathrm {z^\prime}_\ell,&\ell&=1...L&\\ \mathrm y&=\mathrm{LN}(\mathrm z_L^0) \end{align} z0z′ℓzℓy=[xclass; xp1E; xp2E; ⋅⋅⋅; xpNE]+Epos,=MSA(LN(zℓ−1))+zℓ−1,=MLP(LN(z′ℓ))+z′ℓ,=LN(zL0)Eℓℓ∈R(P2⋅C)×D,Epos∈R(N+1)×D=1...L=1...L归纳偏置。 我们注意到Vision Transformer比CNN具有的特定于图像的归纳偏置更少。在CNN中,局部性、2维邻域结构和平移不变性贯穿于整个模型的每一层。在ViT中,只有MLP层是局部和平移不变的,而自注意力层是全局的。2维邻域结构使用得非常少:仅在模型最开始裁剪图像块时和微调阶段针对不同分辨率图像调整位置嵌入(position embedding)有用到。除此之外,位置嵌入在初始化时没有任何关于块的2维位置信息,块之间的所有空间关系都必须从头开始学习。
混合结构。 作为原始图像块的替代,输入序列可以从CNN的特征图中形成。在这个混合模型中,块嵌入(patch embedding)投影E\mathrm EE(公式1)被用于从CNN特征图中提取的块。在极端情况下,块的空间尺寸可以是1×1,这意味着输入序列是通过简单地将特征图的空间维度展平并投影到Transformer维度得到的。分类输入嵌入和位置嵌入按照上述方式加入。
3.2 Fine-Tuning and Higher Resolution
通常,我们在大型数据集上预训练ViT,然后微调到(更小的)下游任务。为此,我们去掉预训练的预测头,增加一个零初始化的D×KD×KD×K的前馈层,其中KKK为下游任务预测的类别数量。通常使用比预训练更高分辨率的图像微调是有益的。当输入更高分辨率的图像时,我们保持块的尺寸不变,这将导致更大的有效序列长度。Vision Transformer可以处理任意的序列长度(直至内存限制),但是预训练的位置嵌入可能不再有意义。因此,我们对预训练的位置嵌入进行2维插值,根据它们在原始图像中的位置。值得注意的是,这种分辨率调整和块提取是关于图像2维结构的归纳偏置被手动添加到Vision Transformer的唯一一处。
4 Experiments
我们评估了ResNet、ViT和混合模型的表示学习能力。为了了解每个模型的数据需求,我们在不同大小的数据集上进行预训练,并在许多基准任务上进行了评估。当考虑预训练模型的计算成本时,ViT表现非常出色,以更低的预训练成本在大多数识别基准上达到了SOTA。最后,我们进行了一个使用自监督的小实验,并表明自监督的ViT在未来是有前景的。
4.1 Setup
数据集。 介绍了实验所用的数据集。
模型变体。 我们在BERT所使用的模型结构基础上确定ViT的配置,如表1所示。“Base”和“Large”模型是直接取自BERT,“Huge”是我们增加的更大的模型。下面我们使用简短的符号表示模型大小和输入块尺寸:例如,ViT-L/16表示输入块尺寸为16×16的“Large”模型变体。注意,Transformer的序列长度与块尺寸的平方成反比,因此块尺寸更小的模型在计算上更加高昂。

对于CNN基线,我们使用ResNet,但将Batch Normalization层替换为Group Normalization层,并使用标准化卷积。这些改动可以提升迁移的性能,我们用“ResNet(BiT)”表示修改后的模型。对于混合模型,我们将中间层的特征图送给ViT,块尺寸为1个像素。为了实验不同长度的序列,我们要么①使用常规ResNet50中stage4的输出,要么②移除stage4,在stage3中放置相同的层数(保持总层数不变),然后取这个扩展的stage3的输出。选项②会导致4倍长的序列长度,对应的ViT模型计算开销更大。
训练&微调。 介绍了训练和微调的实现细节。
评价指标。 我们报告了下游数据集少样本和微调的准确率结果。微调准确率体现的是每个模型在对应数据集上微调后的性能。小样本准确率是通过求解一个将训练图像子集的(冻结)表示映射到{−1,1}K\{-1,1\}^K{−1,1}K个目标向量的正则化最小二乘回归问题得到。这个公式使得我们能够以闭环的方式获取精确解。尽管我们主要关注微调性能,但当有时候微调成本太高时,我们会使用线性少样本准确率来进行快速的在线评估。
4.2 Comparison to State of the Art


和SOTA的对比实验,具体的实验结论可以参照原文。
4.3 Pre-Training Data Requirements
在大型的JFT-300M数据集上预训练时,Vision Transformer表现较好。相比ResNets,ViT使用的视觉归纳偏置更少,那么数据集大小是关键吗?对此我们进行了两组实验。
首先,我们在越来越大的数据集上预训练ViT模型:ImageNet、ImageNet-21k和JFT300M。为了提高在较小数据集上的性能,我们优化了三个基本的正则化参数——权重衰减、Dropout和标签平滑。图3显示了在ImageNet上微调后的结果(其它数据集上的结果如表5所示)(注意,ImageNet预训练模型也进行了微调,但仍在ImageNet上进行。这是因为微调过程中分辨率的提高改善了性能)。当在最小的ImageNet数据集上进行预训练时,尽管进行了(普通的)正则化,但ViT-Large模型性能仍不如ViT-Base。当在ImageNet-21k上预训练时,两个模型的性能接近。只有当使用JFT-300M数据集预训练时,我们才能看到更大模型的全部优势。图3还展现了不同大小的BiT模型的性能:BiT CNNs在ImageNet上的表现优于ViT,但在更大的数据集上,ViT超过了BiT。


然后,我们在9M、30M和90M的随机子集以及完整的JFT300M数据集上训练我们的模型。我们不对较小的子集执行额外的正则化,并在所有设置中使用相同的超参数。这样,我们评估的是内在的模型性质,而不是正则化的效果。然而,我们使用了早停,并报告了在训练过程中达到的最佳验证精度。为了节省计算量,我们报告了少样本线性精度,而不是完全微调精度。结果如图4所示。结果强化了一个直觉,即卷积归纳偏差对于较小的数据集是有用的,但对于较大的数据集,直接从数据中学习相关模式是足够的,甚至是有益的。具体的实验结论可以参照原文。
总体而言,ImageNet上的少样本结果(图4),以及VTAB上的低数据结果(表2)看起来有望实现非常低数据的迁移。进一步分析ViT的少样本特性是未来工作的一个令人激动的方向。

4.4 Scaling Study
我们通过评估JFT-300M的迁移性能,对不同模型进行了控制扩展研究。在这种设定下,数据集大小不是模型的性能瓶颈,我们评估每个模型性能和预训练开销的关系。具体的实验设置可以参照原文。


图5包含了迁移性能与总预训练计算,每个模型的详细结果见表6。可以观察到一些模式。首先,Vision Transformers在性能/计算权衡上与ResNets相比占绝对优势。ViT使用大约2-4倍更少的计算量来达到相同的性能(平均超过5个数据集)。其次,在较小的计算预算下,混合模型略优于ViT,但对于较大的模型,这种差异消失了。这个结果有点令人惊讶,因为我们可能期望通过局部卷积特征处理来辅助任意尺寸的ViT。第三,Vision Transformer在尝试范围内未出现性能饱和的现象,刺激未来的扩展努力。
4.5 Inspecting Vision Transformer
为了开始理解Vision Transformer如何处理图像数据,我们分析了它的内部表示。Vision Transformer的第一层将展平的块线性投影到一个较低纬度的空间(公式1)。图7左显示了学习得到的嵌入滤波器的顶端主要组成。这些组成类似于可靠的基函数,用于低维表示每个块内的精细结构。



在投影之后,一个学习到的位置嵌入被添加到块表示中。图7中表明模型将图像中的距离使用位置嵌入相似性进行编码,即距离更近的块倾向于具有更相似的位置嵌入。而且,出现了row-column结构,同一行/列的块有相似的位置嵌入。最后,在较大的网格中有时会出现明显的正弦结构。位置嵌入可以学习到表示2维图像的拓扑结构,这解释了为什么手工设计的2维感知嵌入变体没有带来改进。
自监督使得ViT即使是在最底层也能整合整张图像的信息。我们对网络自监督能力的使用程度进行了研究。具体来说,我们根据注意力权重计算图像空间中信息整合的平均距离(图7右)。这个“注意力距离”和CNN中的感受野大小相似。我们发现,有些头在网络最底层就已经注意到了图像的绝大部分区域,表明模型的确使用了全局信息整合的能力。其它的注意力头在低层具有一致的小注意力距离。这种高度局部化的注意力在Transformer之前使用ResNet的混合模型中不太明显(图7右),这表明它可能与CNN中的前几个卷积层具有类似的功能。而且,注意力距离随着网络深度的增加而增加。从全局来看,我们发现模型关注的是与分类语义相关的图像区域(图6)。

4.6 Self-Supervision
Transformer在NLP任务上表现出令人印象深刻的性能。然而,它们的成功很大程度上不仅源于其出色的可扩展性,还源于大规模的自监督预训练。我们还模仿BERT中使用的masked language modeling任务,对自监督的masked patch prediction做了初步探索。在自监督预训练的情况下,我们较小的ViT-B/16模型在ImageNet上达到了79.9%的准确率,相比从头训练提升了2%,但仍然落后于有监督预训练4%。
5 Conclusion
我们探索了Transformers在图像识别中的直接应用。与以前在计算机视觉中使用自注意力的工作不同,除了最初的块提取步骤外,我们没有将特定于图像的归纳偏置引入到结构中。取而代之的是,我们将一幅图像理解为一系列的图像块,并通过NLP中使用的标准Transformer编码器进行处理。这种简单但可扩展的策略在与大型数据集上的预训练相结合时效果出奇地好。因此,在许多图像分类数据集上,Vision Transformer匹配或超过了SOTA,同时相对便宜的预训练。
虽然这些初步成果令人鼓舞,但仍存在许多挑战。一种是将ViT应用于其它计算机视觉任务,如检测和分割。我们的结果,加上Carion等人的结果,表明了这种方法的前景。另一个挑战是继续探索自监督预训练方法。我们的初步实验表明自监督预训练有所改进,但自监督预训练与大规模监督预训练之间仍有较大差距。最后,ViT的进一步扩展可能会导致性能的提高。
相关文章:
Transformer论文阅读:ViT算法笔记
标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 会议:ICLR2021 论文地址:https://openreview.net/forum?idYicbFdNTTy 文章目录Abstract1 Introduction2 Related Work3 Method3.1 Vision Transformer3.2…...

Android基础练习解答【2】
文章目录一 填空题二 判断题三 选择题四 简答题一 填空题 1.除了开启开发者选项之外,还需打开手机上的 usb调试 开关,然后才能在手机上调试App。 2.App开发的两大技术路线包括 _原生开发_和混合开发。 3.App工程的编译…...

k8s 搭建
需求:搭建k8s 为后续自动部署做准备进程:安装至少两个ubuntu18.04系统(一个master 一到多个 node)每个系统上都要装上docker 和 kubernetes安装dockersudo su apt-get update#安装相关插件 apt-get install apt-transport-https c…...

安全运维之mysql基线检查
版本加固 选择稳定版本并及时更新、打补丁。 稳定版本:发行6-12个月以内的偶数版本。 检查方法: 使用sql语句:select version(); 检查结果: 存在问题:当前数据库版本较老需要更新 解决方案:前往http://www.mysql…...

跨境电商卖家敦煌、雅虎、乐天、亚马逊测评自养号的重要性!
作为亚马逊、敦煌、乐天、雅虎等跨境的卖家,这两年以来,面对流量越来越贵的现实,卖家需要更加珍惜每次访问listing页面的流量,把转化做好,把流量尽可能转化为更多的订单。 提升转化率的技巧 提升产品转化率࿰…...
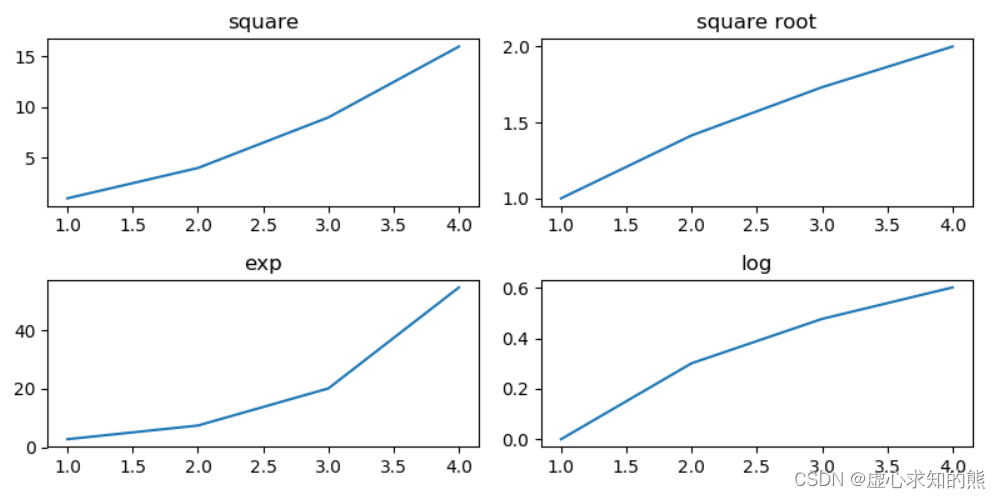
Python 之 Matplotlib xticks 的再次说明、图形样式和子图
文章目录一. 改变 x 轴显示内容 xticks 方法再次说明1. x 轴是数值型数据2. 将 x 轴更改为字符串3. 总结二. 其他元素可视性1. 显示网格:plt.grid()2. plt.gca( ) 对坐标轴的操作三. plt.rcParams 设置画图的分辨率,大小等信息四. 图表的样式参数设置1. …...
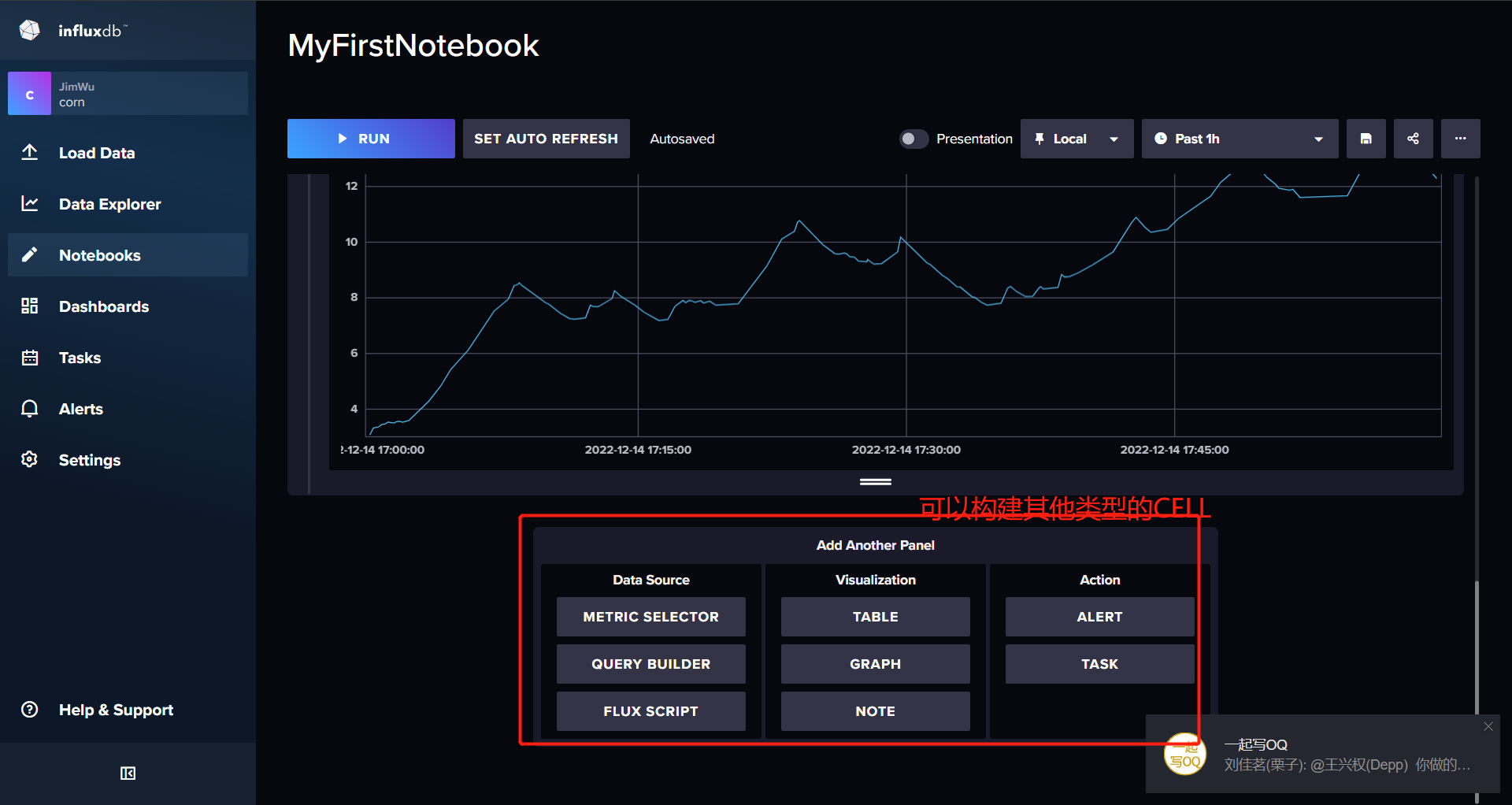
3.InfluxDB WEB使用
结合telegraf做指标数据收集 点击 Load Data -> Telegraf 配置界面 influxDB支持在WEB-UI中生成配置文件 然后利用telegraf通过远程URL请求的方式进行获取 点击CREATE CONFIGURATION 创建telegraf配置文件 选择Bucket InfluxDB提供了很多配置好的监控模板供用户选择 可以…...

git冲突合并
一、版本说明 dev:本地仓库中的dev分支 master:本地仓库中的master分支 remotes/origin/master和origin/master:都是远程仓库上的master分支 二、一个解决冲突的常规流程 1、前提条件:不能在master分支上修改任何文件。master分支…...

项目自动化构建工具make/Makefile
目录 make/Makefile概念和关系 make/Makefie的使用 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重…...

双目客流统计方案的应用原理
双目客流统计客流摄像头采用立体视觉技术实现高度统计功能。基于视差原理。利用双镜头摄取的两幅图像的视差,构建三维场景,在检测到运动目标后。通过计算图像对应点间的位置偏差。获取目标的三维信息,在深度图像中对目标的检测与追踪…...
)
python魔术方法(二)
__getattr__() class A:def __getattr__(self,name):print(f"getting {name}")raise AttributeErroro A() print(o.test)程序调用一个对象的属性,当这个属性不存的时候希望程序做些什么,这里我们打印希望的属性,并且抛出异常 __…...

cmd for命令笔记
语法 help for输出如下: 对一组文件中的每一个文件执行某个特定命令。 FOR %variable IN (set) DO command [command-parameters] %variable 指定一个单一字母可替换的参数。 (set) 指定一个或一组文件。可以使用通配符。 command 指定对每个文件执行的命令。 c…...

4.1 Filter-policy
1. 实验目的 熟悉Filter-policy的应用场景掌握Filter-policy的配置方法2. 实验拓扑 Filter-policy实验拓扑如图4-5所示: 图4-5:Filter-policy 3. 实验步骤 (1) 网络连通性 R1的配置 <Huawei>system-vi…...
day15_常用类
今日内容 上课同步视频:CuteN饕餮的个人空间_哔哩哔哩_bilibili 同步笔记沐沐霸的博客_CSDN博客-Java2301 零、 复习昨日 一、作业 二、代码块[了解] 三、API 四、Object 五、包装类 六、数学和随机 零、 复习昨日 抽象接口修饰符abstractinterface是不是类类接口属性正常属性没…...

【网络原理5】IP协议篇
目录 IP协议报头 4位版本号 4位首部长度 8位服务类型(TOS) 16位总长度 IP拆包 16位标识、3位标志、13位片偏移编辑 8位生存时间(TTL) 8位协议 16位首部校验和 网络地址管理 32位源ip&32位目的ip 方案一:动态分配ip地址 方案2:NAT网络地址转换(使用一个ip代…...

Unity导出WebGL工程,并部署本地web服务器
WebGL打包 设置修改 在Build Settings->PlayerSettings->Other Settings->Rendering 将Color Space 设置为Gamma 将Lightmap Encoding 设置为NormalQuality 在Build Settings->PlayerSettings->Publishing Settings 勾选Decompression Fallback 打包 完成配…...

蓝桥杯考试总结汇总
一进考场设置devc快捷键 设置注释和取消注释快捷键设置代码自动补全快捷键开启devc调试功能,详细可以看怎么开调试功能https://blog.csdn.net/hz18790581821/article/details/78418648比赛过程中,如果不相信自己是否做对,没有把握的…...
备战蓝桥杯【二维前缀和】
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...

阿里P6细谈Python简易接口自动化测试框架设计与实现,我直呼内行
1、开发环境 操作系统:Ubuntu18 开发工具:IDEAPyCharm插件 Python版本:3.6 2、用到的模块 requests:用于发送请求 xlrd:操作Excel,组织测试用例 smtplib,email:发送测试报告 l…...
数据库存储
RAID DSL : Domain Spesic Language 专用领域语言 单机存储 一切皆Key-Value 本地文件系统 一切皆文件 Ceph - 分布式存储 关系型数据库通用组件 Query Engine :解析query,生成查询计划Txn Manager :事务并发管理Lock Man…...
边缘端适配记录)
万象熔炉 | Anything XL部署教程:ARM架构(Jetson Orin)边缘端适配记录
万象熔炉 | Anything XL部署教程:ARM架构(Jetson Orin)边缘端适配记录 1. 项目简介与核心价值 最近在折腾边缘计算设备,手头的Jetson Orin Nano开发者套件性能不错,但一直想找个能稳定跑起来的图像生成模型。SDXL效果…...

位运算的技巧和演示
尝试理解并去总结...

【Nginx】前端项目开启 Gzip 压缩大幅提高页面加载速度
背景 Gzip 是一种文件压缩算法,减少文件大小,节省带宽从而提减少网络传输时间,网站会更快更丝滑。 // nginx roothcss-ecs-1d22:/etc/nginx# nginx -v nginx version: nginx/1.24.0// node ndde v18.20.1// dependencies "vue": &q…...

HagiCode Desktop 混合分发架构解析:如何用 PP 加速大文件下载耘
一、Actor 模型:不是并发技巧,而是领域单元 Actor 模型的本质是: Actor 是独立运行的实体 Actor 之间只通过消息交互 Actor 内部状态不可被外部直接访问 Actor 自行决定如何处理收到的消息 Actor 模型真正解决的是: 如何在不共享状…...
在并网系统中的应用与优化)
逆变器核心技术解析:锁相环(PLL)在并网系统中的应用与优化
1. 锁相环(PLL)在并网逆变器中的核心作用 想象一下你正在参加一场合唱比赛,如果每个人的节奏都不一致,整个表演就会变得杂乱无章。并网逆变器面临的也是类似的问题——它需要与电网保持完美的"节奏同步",而这个"指挥家"就…...

小白也能玩转AI配音!Fish Speech 1.5一键部署实战指南
小白也能玩转AI配音!Fish Speech 1.5一键部署实战指南 想让你的文字变成专业级语音吗?Fish Speech 1.5作为一款强大的AI语音合成工具,支持12种语言和声音克隆功能,现在通过CSDN星图镜像,只需简单几步就能快速体验。本…...
)
保姆级教程:用PyTorch 1.13+全卷积网络搞定MSTAR SAR图像分类(附完整代码)
从零构建PyTorch全卷积网络实现MSTAR SAR图像分类实战指南 当第一次接触MSTAR数据集时,很多开发者会被其特殊的灰度SAR图像特性所困扰。与常规RGB图像不同,SAR图像具有独特的散射特性和成像机制,这给传统计算机视觉方法带来了挑战。本文将带你…...

基于核密度估计的CNN-LSTM-Attention-KDE多输入单输出回归模型【MATLAB】
基于核密度估计的CNN-LSTM-Attention-KDE多输入单输出回归模型 在深度学习时间序列预测与回归分析中,传统的模型往往只能给出一个确定的“点预测”结果(例如:预测明天的温度是25度)。然而,在许多高风险的工程和金融场景…...

MyBatis拦截器黑科技:不修改业务代码实现动态数据权限控制
MyBatis拦截器黑科技:零侵入实现企业级数据权限管控 在当今企业级应用开发中,数据权限控制是一个无法回避的核心需求。传统方案往往需要在每个SQL语句中硬编码权限条件,或者通过AOP切面批量修改Mapper接口,这些方法要么维护成本高…...

千问3.5-9B提示工程:提升OpenClaw复杂任务分解能力
千问3.5-9B提示工程:提升OpenClaw复杂任务分解能力 1. 为什么需要优化任务拆解能力 上周我让OpenClaw执行"整理上季度销售数据并邮件发送给团队"时,AI直接把原始CSV文件作为附件群发——这显然不是人类想要的"整理"结果。这个尴尬…...