VMware搭建Hadoop集群 for Windows(完整详细,实测可用)
目录
一、VMware 虚拟机安装
(1)虚拟机创建及配置
(2)创建工作文件夹
二、克隆虚拟机
三、配置虚拟机的网络
(1)虚拟网络配置
(2)配置虚拟机 主机名
(3)配置虚拟机hosts
(4)配置DNS、网关等
(5)reboot 重启虚拟机
四、配置SSH服务
(1)确认ssh进程
(2)生成秘钥
(3)秘钥拷贝
五、JDK安装
(1)把JDK安装包传输到虚拟机
(2)把JDK安装包解压到/export/software/
(3)配置JDK环境变量
六、Hadoop安装
(1)安装包上传及解压
(2)Hadoop系统环境配置
(3)Hadoop集群境配置
3.1 修改hadoop-env.sh文件
3.2 修改core-site.xml文件
3.3 修改hdfs-site.xml文件
3.4 修改mapred-site.xml文件
3.5 修改yarn-site.xml文件
3.6 修改workers文件
(4)将集群主节点的配置文件分发到其他子节点
(5)格式化文件系统
(6)集群启动
七、浏览器查看Hadoop集群
(1)修改windows下ip映射
(2)防火墙关闭
(3)浏览器查看
一、VMware 虚拟机安装
(1)虚拟机创建及配置
VMware下载地址
VMware的安装过程比较简单,正常安装就行,打开后是以下页面:

点击文件==》新建虚拟机








这里选择提前下载好的CentOS镜像:

点击开启此虚拟机
Enter回车,开始安装CentOS镜像:
选择语言:
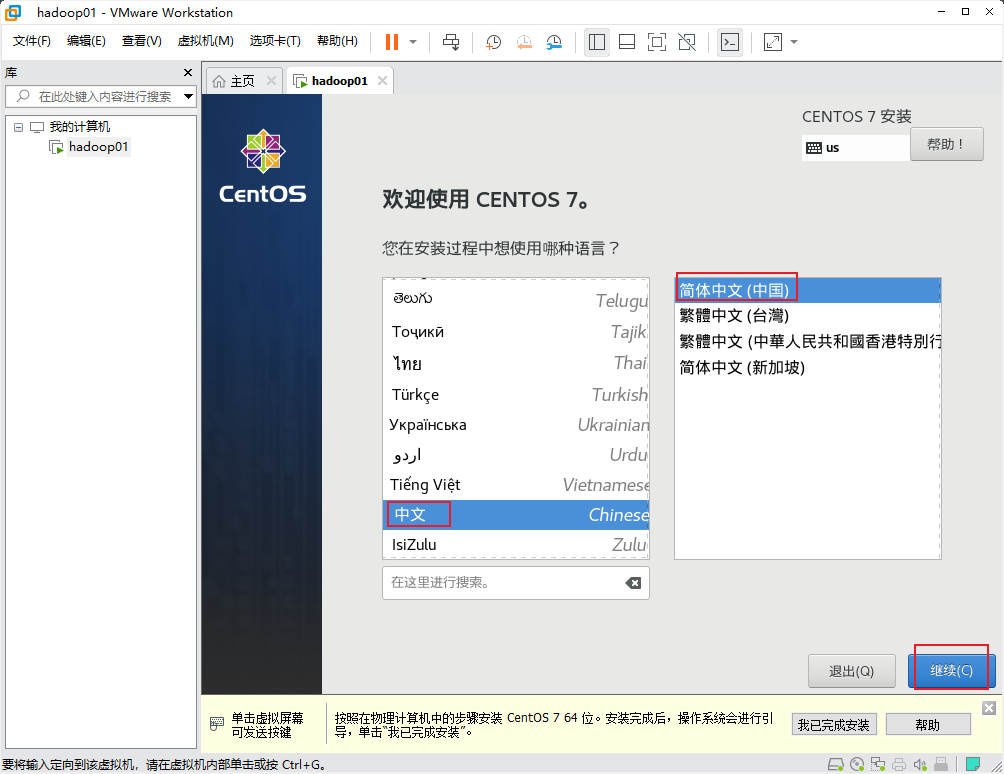
设置日期:

安装位置点进去,点击完成:

KDUMP禁用:

网络和主机名:
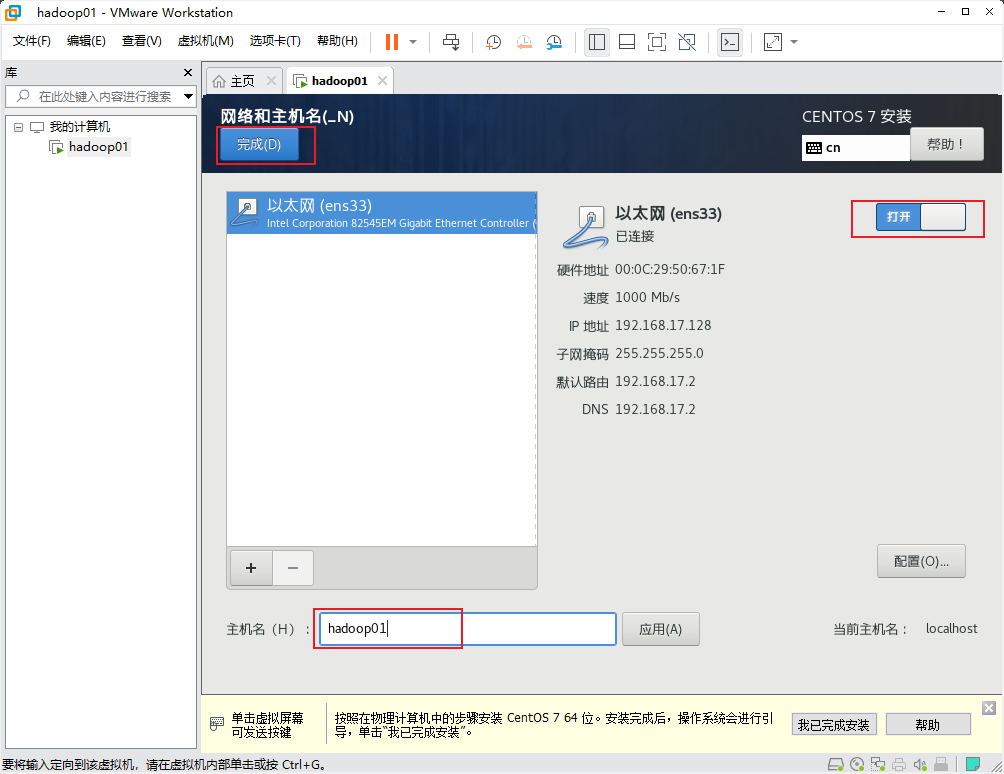
点击开始安装:

设置密码

这里要是密码设置过于简单,点击两次完成即可,后面就会继续执行安装了,等待执行完成,店点击重启按钮,重启后进入一下界面:

输入root和密码之后进入虚拟机:

(2)创建工作文件夹
在hadoop01上执行:
mkdir -p /export/data
mkdir -p /export/servers
mkdir -p /export/software二、克隆虚拟机
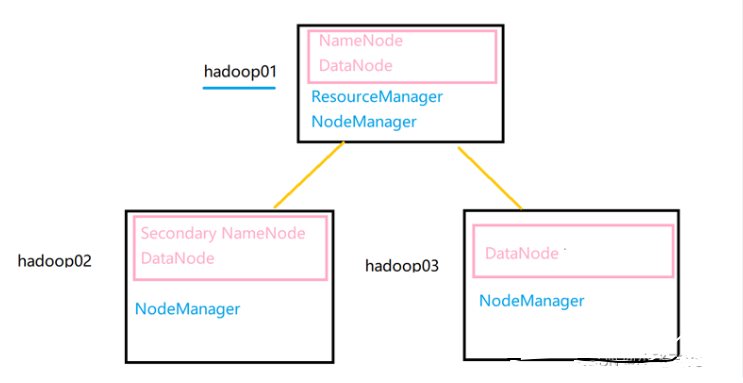
搭建集群需要3个虚拟机,hadoop01,hadoop02,hadoop03,已经安装了hadoop01,剩下两个需要用到虚拟机克隆。
先关闭hadoop01虚拟机:

点击克隆

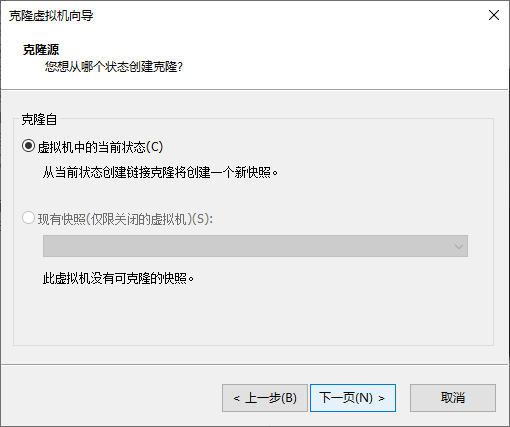


同理,克隆出hadoop03即可,到这虚拟机创建及配置完毕。
三、配置虚拟机的网络
三台虚拟机的ip和域名映射关系如下:
192.168.121.221 hadoop01
192.168.121.222 hadoop02
192.168.121.223 hadoop03
(1)虚拟网络配置
打开虚拟网络编辑器:

选择VMnet8




之后点击确定即可。


(2)配置虚拟机 主机名
在hadoop01虚拟机下执行:
vi /etc/hostnamevi的insert、save等基本操作参考:https://blog.csdn.net/weixin_41231928
修改后如下:
![]()
同理修改hadoop02和hadoop03的hostname为 hadoop02 和 hadoop03,原因是hadoop02和hadoop03是由hadoop01克隆来的,不修改的话,hostname都是hadoop01,修改后如下:
![]()
![]()
(3)配置虚拟机hosts
其实就是配置ip和域名的映射关系。
vi /etc/hosts上面的命令编辑hosts,在3个虚拟机都里面添加:
192.168.121.221 hadoop01
192.168.121.222 hadoop02
192.168.121.223 hadoop03

(4)配置DNS、网关等
在3个虚拟机下新增以下ip设置
IPADDR="192.168.121.221"
NETMASK="255.255.255.0"
GATEWAY="192.168.121.2"
DNS1="114.114.114.114"
执行以下命令:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
(5)reboot 重启虚拟机
以上所有配置完成后,执行:
reboot然后可以验证下网络是否通,出现一下说明配置正常:

四、配置SSH服务
SSH服务的作用一般是有两方面:一是便于虚拟机节点之间免密访问,二是传输数据时会有加解密的过程安全性更高。为了这三个节点间免密登录,比如后面在启动hadoop服务时,主节点启动其它从节点,就需要免密去执行。所以3台机器都执行以下流程,这样三台机器就可以使用ssh连接而无需输入密码了。
(1)确认ssh进程
输入以下命令,查看ssh进程是否存在(默认是开启的):
ps -e | grep sshd如下便是开启状态:
![]()
(2)生成秘钥
ssh-keygen -t rsa执行以上命令,不用输入,按3次回车:

(3)秘钥拷贝
三台机器的秘钥分别生成之后,需要将各自的秘钥拷贝到其他2台机器,3台机器都执行以下命令:
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03每条命令中间会有询问,输入“yes”回车,然后输入密码即可:

验证下ssh配置:
在hadoop01下执行ssh hadoop02 和ssh hadoop03,能成功登录:

五、JDK安装
下载一个linux版本的JDK,这里是 jdk-8u161-linux-x64.tar.gz,3台机器均要执行以下。
(1)把JDK安装包传输到虚拟机
这里我们需要借助ftcp文件传输软件,这里使用的是MobaxTerm,也可以使用别的文件传输软件,WinSCP\PuTTY\Xshell都可以。
MobaxTerm新建SFTP类型的session:

可以新建一个root用户,把3个虚拟机的密码输入:

点击ok后:

选择jdk文件,拖入之前建好的/export/software文件夹:


(2)把JDK安装包解压到/export/software/
执行以下命令:
cd /export/software/
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/
cd /export/servers/
mv jdk1.8.0_161/ jdk
(3)配置JDK环境变量
执行:
vim /etc/profile在文末添加:
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

注意:
修改 /etc/profile 文件最后都要执行下
source /etc/profile才能是修改生效。最后执行java -version看下是否配置成功。
六、Hadoop安装
Hadoop下载地址
这里使用的是 hadoop-3.1.3.tar.gz
(1)安装包上传及解压
跟前面JDK一样,先用 mobaxterm 将 hadoop-3.1.3.tar.gz 上传到3台机器的 /export/software:

执行下面解压命令:
tar -zxvf hadoop-3.1.3.tar.gz -C /export/servers/
(2)Hadoop系统环境配置
执行:
vim /etc/profile添加一下内容:
export HADOOP_HOME=/export/servers/hadoop-3.1.3
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

一样,修改 /etc/profile 文件最后都要执行下 “vim /etc/profile”。
执行验证下:
hadoop version
(3)Hadoop集群境配置
3.1 修改hadoop-env.sh文件
执行:
cd /export/servers/hadoop-3.1.3/etc/hadoop
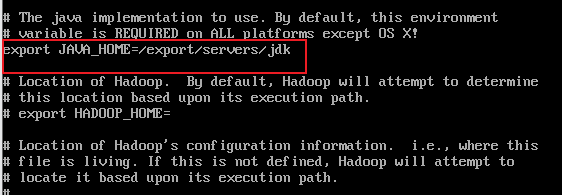
vim hadoop-env.sh找到export JAVA_HOME的位置修改:
export JAVA_HOME=/export/servers/jdk
3.2 修改core-site.xml文件
vim core-site.xml添加以下配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-3.1.3/tmp</value>
</property>
</configuration>

hadoop02、hadoop03修改时,把对于域名修改成hadoop02、hadoop03即可。
3.3 修改hdfs-site.xml文件
vim hdfs-site.xml添加以下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
</configuration>

dfs.namenode.secondary.http-address这配置在hadoop02、hadoop03不用配置。
3.4 修改mapred-site.xml文件
vim mapred-site.xml添加以下配置:
<configuration>
<!-- 指定MapReduce运行时框架,这里指定在Yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
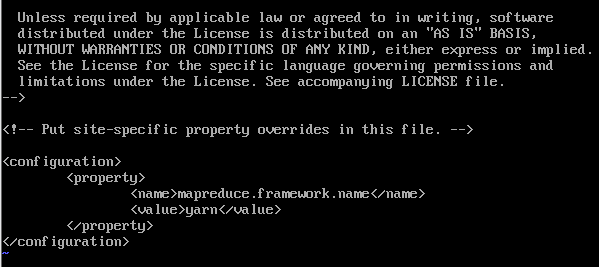
3.5 修改yarn-site.xml文件
vi yarn-site.xml添加以下配置:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3.6 修改workers文件
vim workers删除默认的localhost,添加以下内容:
hadoop01
hadoop02
hadoop03
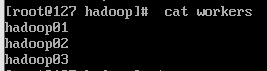
(4)将集群主节点的配置文件分发到其他子节点
执行:
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/ hadoop02:/
scp -r /export/ hadoop03:/
传完之后要在hadoop02和hadoop03上分别执行 source /etc/profile 命令。
(5)格式化文件系统
hdfs namenode -format
这个执行成功以后,不要二次执行。
(6)集群启动
执行:
start-dfs.sh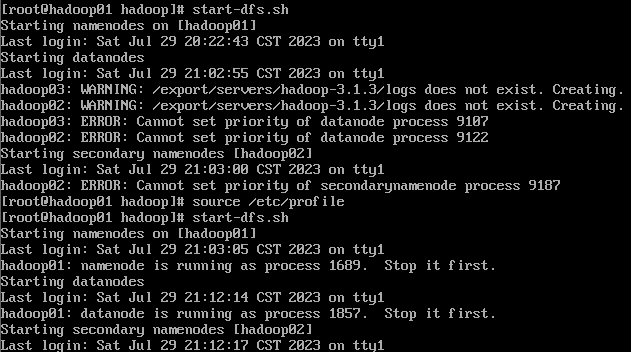
然后3个机器分别 jps 查看进程情况:

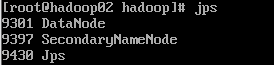
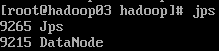
在主节点hadoop01上执行
start-yarn.sh启动resourcemanager和nodemanager:

jps:
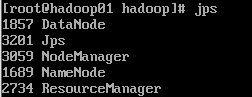
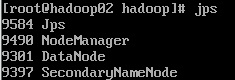
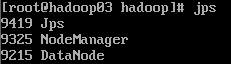
如果想要关闭,输入:
stop-dfs.sh以上hadoop安装配置就完成了。
七、浏览器查看Hadoop集群
(1)修改windows下ip映射
修改 C:\Windows\System32\drivers\etc下的hosts文件,添加以下内容:
192.168.121.221 hadoop01
192.168.121.222 hadoop02
192.168.121.223 hadoop03
这样就可以通过hadoop01、hadoop02、hadoop03这样的域名来访问了。
(2)防火墙关闭
在3台虚拟机上均执行以下命令(一个是临时关闭,一个是开机就关闭即永久关闭,两个命令执行其中一个即可):
systemctl stop firewalld.service
systemctl disable firewalld.service(3)浏览器查看
在浏览器输入:
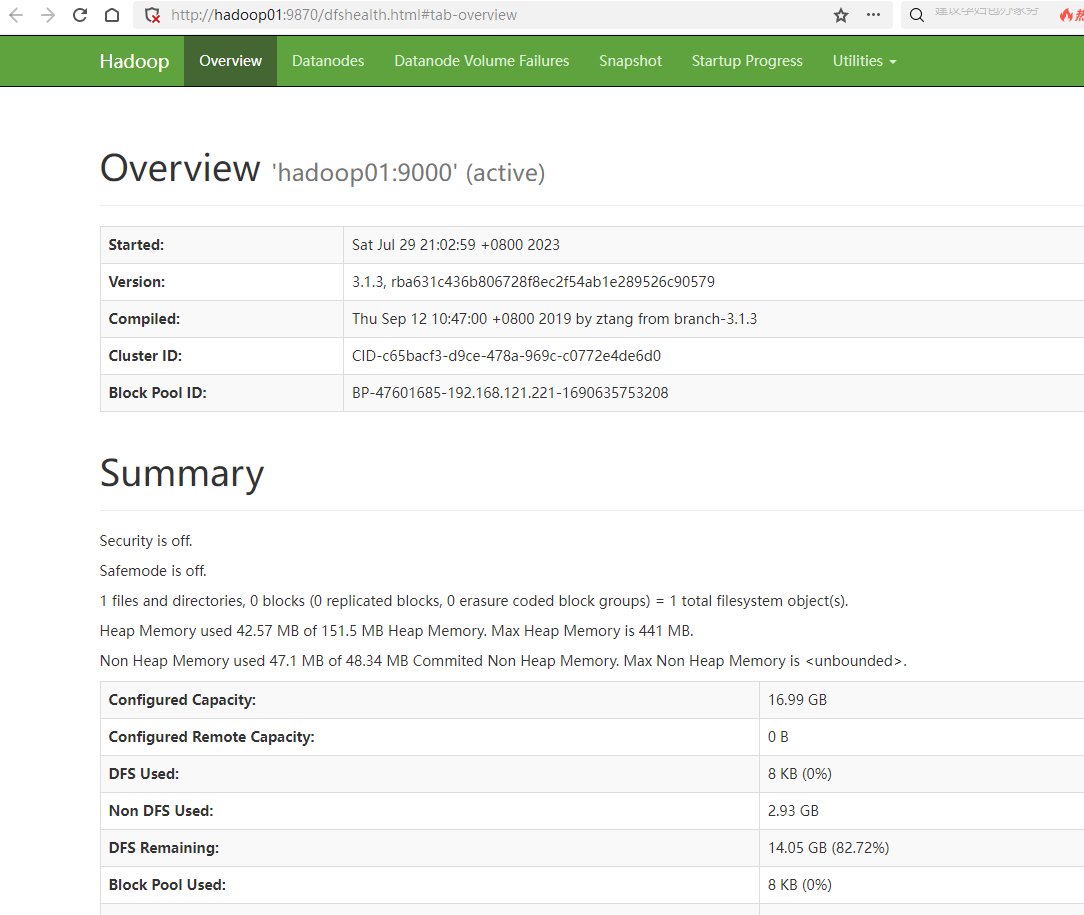
http://hadoop01:9870
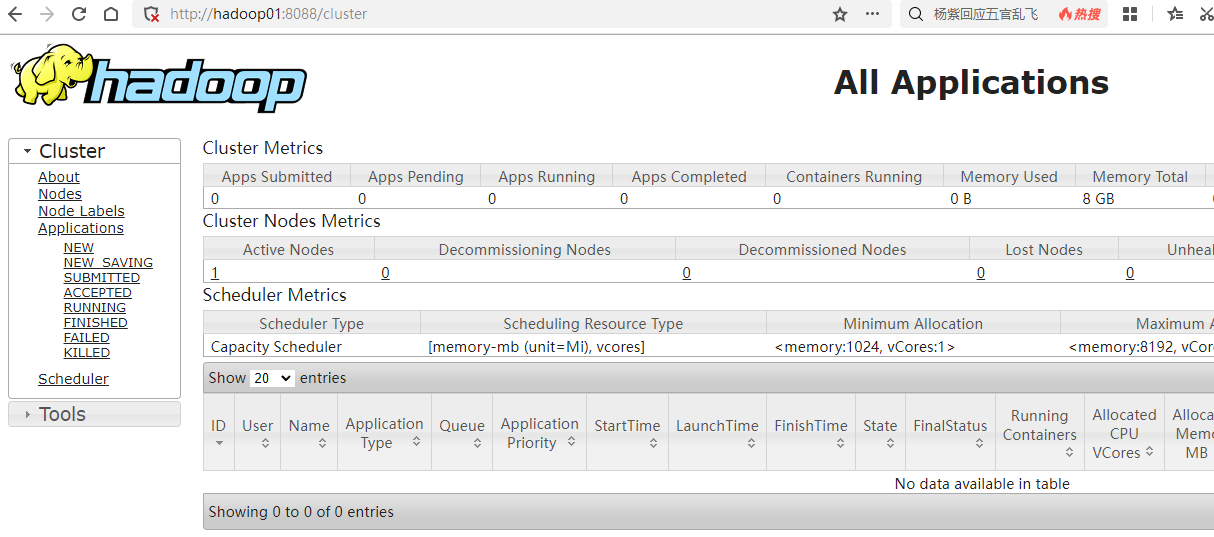
http://hadoop01:8088
即可访问 HDFS 和 Yarn
以上已经将Hadoop集群搭建完毕!
相关文章:
VMware搭建Hadoop集群 for Windows(完整详细,实测可用)
目录 一、VMware 虚拟机安装 (1)虚拟机创建及配置 (2)创建工作文件夹 二、克隆虚拟机 三、配置虚拟机的网络 (1)虚拟网络配置 (2)配置虚拟机 主机名 (3…...

【Rust 基础篇】Rust关联类型:灵活的泛型抽象
导言 Rust是一种以安全性和高效性著称的系统级编程语言,其设计哲学是在不损失性能的前提下,保障代码的内存安全和线程安全。为了实现这一目标,Rust引入了"所有权系统"、"借用检查器"等特性,有效地避免了常见…...

学习笔记21 list
一、概述 有两种不同的方法来实现List接口。ArrayList类使用基于连续内存分配的实现,而LinkedList实现基于linked allocation。 list接口提供了一些方法: 二、The ArrayList and LinkedList Classes 1.构造方法 这两个类有相似的构造方法:…...

微信小程序弱网监控
前言 在真实的项目中,我们为了良好的用户体验,会根据用户当前的网络状态提供最优的资源,例如图片或视频等比较大的资源,当网络较差时,可以提供分辨率更低的资源,能够让用户尽可能快的看到有效信息…...
【Linux】进程通信 — 共享内存
文章目录 📖 前言1. 共享内存2. 创建共享内存2.1 ftok()创建key值:2.2 shmget()创建共享内存:2.3 ipcs指令:2.4 shmctl()接口:2.5 shmat()/shmdt()接口:2.6 共享内存没有访问控制:2.7 通过管道对共享内存进…...

“从零开始学习Spring Boot:快速搭建Java后端开发环境“
标题:从零开始学习Spring Boot:快速搭建Java后端开发环境 摘要:本文将介绍如何从零开始学习Spring Boot,并详细讲解如何快速搭建Java后端开发环境。通过本文的指导,您将能够快速搭建一个基于Spring Boot的Java后端开发…...
)
行为型-状态模式(State Pattern)
概述 状态模式是一种行为设计模式,它可以让对象在内部状态改变时改变它的行为。简而言之,状态模式允许对象在不同状态下更改其行为,而不需要通过使用大量的条件语句进行手动更改。 优点: 状态模式将与特定状态相关的行为分散到…...

大厂领导为什么喜欢跨层与下属聊天
作为一个在大厂里面浸淫十几年的loser,平时主要精力没用在技术提升上,对于大厂的人情世故各类八卦倒是研究的透彻。 如果你细心观察,会发现一些大的公司里面,领导喜欢跨层与下属去沟通聊天,我待过几家比较大的公司&am…...
三)
Android 面试题 避免OOM(内存优化)三
🔥 OOM介绍(out of memory 内存溢出)🔥 Android和java中都会出现由于不良代码引起的内存泄露,为了使Android应用程序能够快速高效的运行,Android每个应用程序都会有专门Dalvik虚拟机实例来运行,…...

SpringBoot集成Lock4j 底层使用Redission 实现分布锁
Lock4j 在分布式系统中,实现锁的功能对于保证数据一致性和避免并发冲突是非常重要的。Lock4j是一个简单易用的分布式锁框架,而Redisson是一个功能强大的分布式解决方案,可以与Lock4j进行集成。 操作步骤 第一步:添加依赖 首先&…...

TortoiseSVN操作使用
说明 SVN常用于程序代码版本控制,由于业务需求需将生产资料通过SVN进行管控,涉及人员众多,权限分支管理需要细化,特此记录SVN的学习操作. 前言 版本控制是管理信息修改的艺术,它一直是程序员最重要的工具,程序员经常会花时间作出小的修改, 然…...

第五篇-ChatGLM2-6B模型下载
下载chatglm2-6b模型文件 https://huggingface.co/THUDM/chatglm2-6b方法一:huggingface页面直接点击下载 一个一个下载,都要下载方法二:snapshot_download下载文件 可以使用如下代码下载 创建下载环境 conda create --name hfhub pytho…...
)
【Matlab】基于长短期记忆网络的数据分类预测(Excel可直接替换数据)
【Matlab】基于长短期记忆网络的数据分类预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码6.完整代码7.运行结果1.模型原理 “基于长短期记忆网络的数据分类预测”是一种利用长短期记忆网络(Long Short-Term Memory, LSTM)进行数据分类任务…...

C++网络编程 TCP套接字基础知识,利用TCP套接字实现客户端-服务端通信
1. TCP 套接字编程流程 1.1 概念 流式套接字编程针对TCP协议通信,即是面向对象的通信,分为服务端和客户端两部分。 1.2 服务端编程流程: 1)加载套接字库(使用函数WSAStartup()),创建套接字&…...

苍穹外卖-day07
苍穹外卖-day07 本项目学自黑马程序员的《苍穹外卖》项目,是瑞吉外卖的Plus版本 功能更多,更加丰富。 结合资料,和自己对学习过程中的一些看法和问题解决情况上传课件笔记 视频:https://www.bilibili.com/video/BV1TP411v7v6/?sp…...

简化Java单元测试数据
用EasyModeling简化Java单元测试 EasyModeling 是我在2021年圣诞假期期间开发的一个 Java 注解处理器,采用 Apache-2.0 开源协议。它可以帮助 Java 单元测试的编写者快速构造用于测试的数据模型实例,简化 Java 项目在单元测试中准备测试数据的工作&…...

P1041 [NOIP2003 提高组] 传染病控制
题目 题目背景 本题是错题,后来被证明没有靠谱的多项式复杂度的做法。测试数据非常的水,各种玄学-做法都可以通过,不代表算法正确。因此本题题目和数据仅供参考。 近来,一种新的传染病肆虐全球。蓬莱国也发现了零星感染者&#…...

TypeScript -- 基础类型
文章目录 TypeScript -- 基础类型let 和 const基本类型写法布尔类型 -- boolean数字类型 -- number字符串类型 -- string数组类型元组类型枚举类型 -- enum任意类型 -- any空值 -- voidNull 和 Undefined不存在的类型 -- never对象 -- object类型断言 TypeScript – 基础类型 1…...

Cookie 与 Session 的作用及区别、结合使用
Cookie的作用 在网站中,http请求是无状态的。也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户。 Cookie的出现就是为了解决这个问题,第一次登录后服务器返回一些数据(Cookie&a…...

【Redis】面试题
1. 为什么要用缓存 1. 提高系统的读写性能。 2. 减轻数据库的压力,防止大量的请求到达数据库,让数据库压力剧增,拖垮数据库。redis数据存储在内存中,高效的数据结构,读写数据比数据库快。 将热点数据存储在redis当中&…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...
阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘 安装虚拟环境: 1、安装virtualenv pip install virtualenv 2.创建新的虚拟环境: virtualenv myenv 3、激活虚拟环境(激活环境可以在当前环境下安装包) source myenv/bin/activate 此时,终端…...

高防服务器价格高原因分析
高防服务器的价格较高,主要是由于其特殊的防御机制、硬件配置、运营维护等多方面的综合成本。以下从技术、资源和服务三个维度详细解析高防服务器昂贵的原因: 一、硬件与技术投入 大带宽需求 DDoS攻击通过占用大量带宽资源瘫痪目标服务器,因此…...
2025-05-08-deepseek本地化部署
title: 2025-05-08-deepseek 本地化部署 tags: 深度学习 程序开发 2025-05-08-deepseek 本地化部署 参考博客 本地部署 DeepSeek:小白也能轻松搞定! 如何给本地部署的 DeepSeek 投喂数据,让他更懂你 [实验目的]:理解系统架构与原…...

python打卡day49@浙大疏锦行
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 一、通道注意力模块复习 & CBAM实现 import torch import torch.nn as nnclass CBAM(nn.Module):def __init__…...

python读取SQLite表个并生成pdf文件
代码用于创建含50列的SQLite数据库并插入500行随机浮点数据,随后读取数据,通过ReportLab生成横向PDF表格,包含格式化(两位小数)及表头、网格线等美观样式。 # 导入所需库 import sqlite3 # 用于操作…...