6.3.tensorRT高级(1)-yolov5模型导出、编译到推理(无封装)
目录
- 前言
- 1. YOLOv5导出
- 2. YOLOv5推理
- 3. 补充知识
- 总结
前言
杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。
本次课程学习 tensorRT 高级-yolov5模型导出、编译到推理(无封装)
课程大纲可看下面的思维导图

1. YOLOv5导出
我们来来学习 yolov5 onnx 的导出
我们先导出官方的 onnx 以及我们修改过后的 onnx 看看有什么区别
在官方 onnx 导出时,遇到了如下的问题:

最终发现是 pytorch 版本的原因,yolov5-6.0 有点老了,和现在的高版本的 pytorch 有些不适配也正常
因此博主拿笔记本的低版本 pytorch 导出的,如下所示:

我们再导出经过修改后的 onnx,如下所示:

我们利用 Netron 来看下官方的 onnx,首先是输入有 4 个维度,其中的 3 个维度都是动态,它的输出包含 4 项,实际情况下我们只需要 output 这 1 项就行,其次模型结构非常乱

我们再来看下修改后的模型,修改后的模型动态维度只有 batch,没有宽高,输出也只有一个,其次相比于之前更加简洁,更加规范

OK!知道二者区别后,我们看如何修改才能导出我们想要的 onnx 效果,首先是动态,保证 batch 维度动态即可,宽高不要动态。需要修改 yolov5-6.0 第 73 行,onnx 导出的代码,删除宽高的动态,修改后的代码如下:
# ======未修改的代码======# torch.onnx.export(model, im, f, verbose=False, opset_version=opset,
# training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
# do_constant_folding=not train,
# input_names=['images'],
# output_names=['output'],
# dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
# 'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
# } if dynamic else None)# ======修改后的代码======torch.onnx.export(model, im, f, verbose=False, opset_version=opset,training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,do_constant_folding=not train,input_names=['images'],output_names=['output'],dynamic_axes={'images': {0: 'batch'}, # shape(1,3,640,640)'output': {0: 'batch'} # shape(1,25200,85)} if dynamic else None)
修改后重新导出后可以发现输入 batch 维度动态,宽高不动态,但是似乎 output 还是动态的,这是因为在 output 这个节点之前还有引用 output 的关系在里面,所以造成了它的 shape 是通过计算得到的,而并不是通过确定的值指定得到的,它没有确定的值,所以需要我们接着改。

第二件事情我们来确保输出只有 1 项,把其它 3 项干掉,在 models/yolo.py 第 73 行,Detect 类中的返回值中删除不必要的返回值,修改后的代码如下:
# ======未修改的代码======# return x if self.training else (torch.cat(z, 1), x)# ======修改后的代码======return x if self.training else torch.cat(z, 1)
接着导出,可以看到输出变成 1 个了,如我们所愿

接下来我们删除 Gather Unsqueeze 等不必要的节点,这个主要是由于引用 shape 的返回值所带来的这些节点的增加,在 model/yolo.py 第 56 行,修改代码如下:
# ======未修改的代码======# bs, _, ny, nx = x[i].shape# ======修改后的代码======bs, _, ny, nx = map(int, x[i].shape)
可以看到干净了不少

但是还是有点脏的样子,诸如 ConstantOfShape 应该干掉,还有 reshape 节点可以看到 batch 维度不是 -1,当使用动态 batch 的时候会出问题,我们接着往下改
在 model/yolo.py 第 57 行,修改代码如下:
# ======未修改的代码======# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# if not self.training:
# ...
# z.append(y.view(bs, -1, self.no))# ======修改后的代码======bs = -1
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training:...z.append(y.view(-1, self.na * ny * nx, self.no))
再接着导出一下,可以看到此时的 Reshape 的 -1 在 batch 维度上

但是还是存在 ConstantOfShape 等节点,这个主要是由于 make_grid 产生的,我们需要让 anchor_grid 断开连接,把它变成一个常量值,直接存储下来,在 model/yolo.py 第 59 行,修改代码如下:
# ======未修改的代码======# if not self.training: # inference
# if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
# self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)# y = x[i].sigmoid()
# if self.inplace:
# y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
# y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
# else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
# xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
# wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
# y = torch.cat((xy, wh, y[..., 4:]), -1)
# z.append(y.view(bs, -1, self.no))# ======修改后的代码======if not self.training: # inferenceif self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)anchor_grid = (self.anchors[i].clone() * self.stride[i]).view(1, -1, 1, 1, 2)y = x[i].sigmoid()if self.inplace:y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xyy[..., 2:4] = (y[..., 2:4] * 2) ** 2 * anchor_grid # whelse: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xywh = (y[..., 2:4] * 2) ** 2 * anchor_grid # why = torch.cat((xy, wh, y[..., 4:]), -1)#z.append(y.view(bs, -1, self.no))z.append(y.view(bs, self.na * ny * nx, self.no))
接着再导出看下效果,可以看到多余部分的节点被干掉了,直接把它存储到 initializer 里面了,这就是我们最终想要达成的一个效果

Note:值的一提的是,在新版 yolov5 中的 onnx 模型导出时其实上述大部分部分问题已经考虑并解决了,但是依旧还是存在某些小问题,具体可参考 Ubuntu20.04部署YOLOv5
2. YOLOv5推理
onnx 导出完成后,接下来看看 C++ 推理时的代码
我们先去拿到 pytorch 推理时的结果,如下图所示:

推理过后的图片如下所示:

之后我们再到 tensorRT 里面看看推理后的效果
首先看看 main.cpp 中 build_model 部分,可以发现它和我们分类器的案例完全一模一样,先 make run 一下看是否能正常生成 yolov5s.trtmodel 如下所示:

可以看到模型生成和推理成功了,我们来看下 tensorRT 执行的效果:

我们再来看下 inference 部分,与分类器相比,无非就是预处理和后处理不一样,其它都差不多,然后就到了 letter box 阶段了,等比缩放居中长边对其并居中,代码如下:
// letter box
auto image = cv::imread("car.jpg");
// 通过双线性插值对图像进行resize
float scale_x = input_width / (float)image.cols;
float scale_y = input_height / (float)image.rows;
float scale = std::min(scale_x, scale_y);
float i2d[6], d2i[6];
// resize图像,源图像和目标图像几何中心的对齐
i2d[0] = scale; i2d[1] = 0; i2d[2] = (-scale * image.cols + input_width + scale - 1) * 0.5;
i2d[3] = 0; i2d[4] = scale; i2d[5] = (-scale * image.rows + input_height + scale - 1) * 0.5;cv::Mat m2x3_i2d(2, 3, CV_32F, i2d); // image to dst(network), 2x3 matrix
cv::Mat m2x3_d2i(2, 3, CV_32F, d2i); // dst to image, 2x3 matrix
cv::invertAffineTransform(m2x3_i2d, m2x3_d2i); // 计算一个反仿射变换cv::Mat input_image(input_height, input_width, CV_8UC3);
cv::warpAffine(image, input_image, m2x3_i2d, input_image.size(), cv::INTER_LINEAR, cv::BORDER_CONSTANT, cv::Scalar::all(114)); // 对图像做平移缩放旋转变换,可逆
cv::imwrite("input-image.jpg", input_image);int image_area = input_image.cols * input_image.rows;
unsigned char* pimage = input_image.data;
float* phost_b = input_data_host + image_area * 0;
float* phost_g = input_data_host + image_area * 1;
float* phost_r = input_data_host + image_area * 2;
for(int i = 0; i < image_area; ++i, pimage += 3){// 注意这里的顺序rgb调换了*phost_r++ = pimage[0] / 255.0f;*phost_g++ = pimage[1] / 255.0f;*phost_b++ = pimage[2] / 255.0f;
}
上述代码实现了 YOLOv5 中的 letterbox 操作,用于将输入图像按照等比例缩放并填充到指定大小的网络输入。首先,通过双线性插值计算缩放比例,然后构建一个 2x3 的仿射变换矩阵,用于将原图像按照缩放比例进行缩放,并将其填充到指定大小的输入图像中。接着,使用 cv::warpAffine 函数进行缩放和平移变换,得到输入图像 input_image。最后,将图像数据转换为网络输入格式,将像素值归一化到 0~1 之间,并存储到网络输入数据指针 input_data_host 中,以适应网络的输入要求
这个过程其实是可以通过我们之前讲的 warpAffine 来实现的,具体细节可参考 YOLOv5推理详解及预处理高性能实现,这里不再赘述,变换后的图像如下所示:

将输入图像做下预处理塞到 tensorRT 中推理,拿到推理后的结果后还需要进行后处理,具体后处理代码如下所示:
// decode box:从不同尺度下的预测狂还原到原输入图上(包括:预测框,类被概率,置信度)
vector<vector<float>> bboxes;
float confidence_threshold = 0.25;
float nms_threshold = 0.5;
for(int i = 0; i < output_numbox; ++i){float* ptr = output_data_host + i * output_numprob;float objness = ptr[4];if(objness < confidence_threshold)continue;float* pclass = ptr + 5;int label = std::max_element(pclass, pclass + num_classes) - pclass;float prob = pclass[label];float confidence = prob * objness;if(confidence < confidence_threshold)continue;// 中心点、宽、高float cx = ptr[0];float cy = ptr[1];float width = ptr[2];float height = ptr[3];// 预测框float left = cx - width * 0.5;float top = cy - height * 0.5;float right = cx + width * 0.5;float bottom = cy + height * 0.5;// 对应图上的位置float image_base_left = d2i[0] * left + d2i[2];float image_base_right = d2i[0] * right + d2i[2];float image_base_top = d2i[0] * top + d2i[5];float image_base_bottom = d2i[0] * bottom + d2i[5];bboxes.push_back({image_base_left, image_base_top, image_base_right, image_base_bottom, (float)label, confidence});
}
printf("decoded bboxes.size = %d\n", bboxes.size());// nms非极大抑制
std::sort(bboxes.begin(), bboxes.end(), [](vector<float>& a, vector<float>& b){return a[5] > b[5];});
std::vector<bool> remove_flags(bboxes.size());
std::vector<vector<float>> box_result;
box_result.reserve(bboxes.size());auto iou = [](const vector<float>& a, const vector<float>& b){float cross_left = std::max(a[0], b[0]);float cross_top = std::max(a[1], b[1]);float cross_right = std::min(a[2], b[2]);float cross_bottom = std::min(a[3], b[3]);float cross_area = std::max(0.0f, cross_right - cross_left) * std::max(0.0f, cross_bottom - cross_top);float union_area = std::max(0.0f, a[2] - a[0]) * std::max(0.0f, a[3] - a[1]) + std::max(0.0f, b[2] - b[0]) * std::max(0.0f, b[3] - b[1]) - cross_area;if(cross_area == 0 || union_area == 0) return 0.0f;return cross_area / union_area;
};for(int i = 0; i < bboxes.size(); ++i){if(remove_flags[i]) continue;auto& ibox = bboxes[i];box_result.emplace_back(ibox);for(int j = i + 1; j < bboxes.size(); ++j){if(remove_flags[j]) continue;auto& jbox = bboxes[j];if(ibox[4] == jbox[4]){// class matchedif(iou(ibox, jbox) >= nms_threshold)remove_flags[j] = true;}}
}
printf("box_result.size = %d\n", box_result.size());
上述代码实现了 YOLOv5 目标检测中的后处理步骤,将模型输出的预测框信息进行解码并进行非极大抑制(NMS)处理,得到最终的目标检测结果。
1. 解码预测框:从模型输出的预测中筛选出置信度(confidence)大于阈值(confidence_threshold)的预测框。然后根据预测框的中心点、宽度和高度,计算出预测框在原输入图像上的位置(image_base_left、image_base_right、image_base_top、image_base_bottom),并将结果存储在 bboxes 中。
2. 非极大抑制(NMS):对 bboxes 中的预测框进行按照置信度降序排序。然后使用 IOU 计算两个预测框的重叠程度。如果两个预测框的类别相同且 IOU 大于 NMS 阈值,则认为这两个预测框是重复的,将置信度较低的预测框从结果中移除。最终得到不重复的预测框,存储在 box_result 中。
整个后处理过程实现了从模型输出到最终目标检测结果的转换,包括解码预测框和非极大抑制。这样可以得到准确的目标检测结果,并去除冗余的重复检测框。
关于 decode 解码和 NMS 的具体细节可以参考 YOLOv5推理详解及预处理高性能实现
之前课程提到的 warpAffine 就可以替换为这里的预处理,用 CUDA 核函数进行加速,之前提到的 YoloV5 的核函数后处理也可以替换这里的后处理,从而达到高性能
整个 Yolov5 从模型的修改到导出再到推理拿到结果,没有封装的流程就如上述所示
3. 补充知识
对于 yolov5 如何导出模型并利用起来,你需要知道:
1. 修改 export_onnx 时的导出参数,使得动态维度指定为 batch,去掉 width 和 height 的指定
2. 导出时,对 yolo.py 进行修改,使得后处理能够简化,并将 anchor 合并到 onnx 中
3. 预处理部分采用 warpaffine,描述对图像的平移和缩放
关于 yolov5 案例的知识点:(from 杜老师)
1. yolov5 的预处理部分,使用了仿射变换,请参照仿射变换原理
- letterbox 采用双线性插值对图像进行 resize,并且使源图像和目标图像几何中心对齐


- 使用仿射变换实现 letterbox 的理由是
- 便于操作,得到变换矩阵即可
- 便于逆操作,实现逆矩阵映射即可
- 便于 cuda 加速,cuda 版本的加速已经在 cuda 系列中提到了 warpaffine 实现
- 该加速可以允许 warpaffine、normalize、除以255、减均值除以标准差、变换 RB 通道等等在一个核函数中实现,性能最好
2. 后处理部分,反算到图像坐标,实际上乘以逆矩阵
- 由于逆矩阵实际上有效自由度是 3,也就是 d2i 中只有 3 个数是不同的,其他都一样。也因此你看到的 d2i[0]、d2i[2]、d2i[5] 在起作用


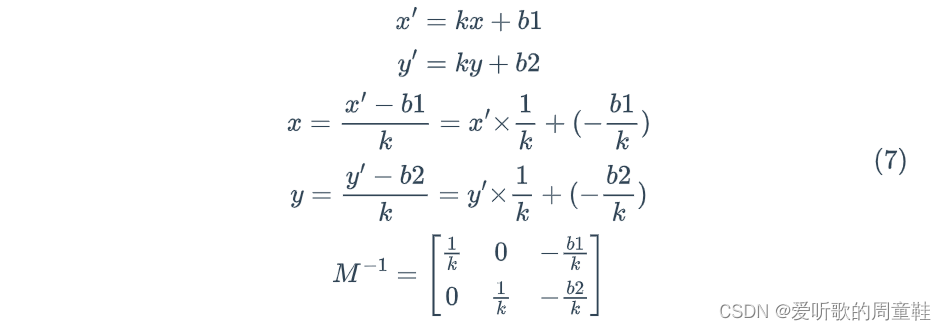
导出 yolov5-6.0 需要修改以下地方
# line 55 forward function in yolov5/models/yolo.py
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# modified into:bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
bs = -1
ny = int(ny)
nx = int(nx)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()# line 70 in yolov5/models/yolo.py
# z.append(y.view(bs, -1, self.no))
# modified into:
z.append(y.view(bs, self.na * ny * nx, self.no))############# for yolov5-6.0 #####################
# line 65 in yolov5/models/yolo.py
# if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
# self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
# modified into:
if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)# disconnect for pytorch trace
anchor_grid = (self.anchors[i].clone() * self.stride[i]).view(1, -1, 1, 1, 2)# line 70 in yolov5/models/yolo.py
# y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
# modified into:
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * anchor_grid # wh# line 73 in yolov5/models/yolo.py
# wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
# modified into:
wh = (y[..., 2:4] * 2) ** 2 * anchor_grid # wh
############# for yolov5-6.0 ###################### line 77 in yolov5/models/yolo.py
# return x if self.training else (torch.cat(z, 1), x)
# modified into:
return x if self.training else torch.cat(z, 1)# line 52 in yolov5/export.py
# torch.onnx.export(dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
# 'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85) 修改为
# modified into:
torch.onnx.export(dynamic_axes={'images': {0: 'batch'}, # shape(1,3,640,640)'output': {0: 'batch'} # shape(1,25200,85)
总结
本次课程学习了无封装的 yolov5 模型从导出到编译再到推理的全部过程,学习了如何修改一个 onnx 达到我们想要的结果,同时 yolov5 CPU 版本的预处理和后处理的学习也帮助我们进一步去理解 CUDA 核函数上的实现。
相关文章:
6.3.tensorRT高级(1)-yolov5模型导出、编译到推理(无封装)
目录 前言1. YOLOv5导出2. YOLOv5推理3. 补充知识总结 前言 杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。 本次课程学习 tensorRT 高级-yolov5模…...

如何利用设备数字化平台推动精益制造?
人工智能驱动技术的不断发展,尤其是基于机器学习的预测分析工具的使用,为制造业带来了全新的效率和价值水平。一直以来,精益生产(也叫精益制造)在制造业中扮演着重要角色,而现在通过与工业 4.0的融合&#…...
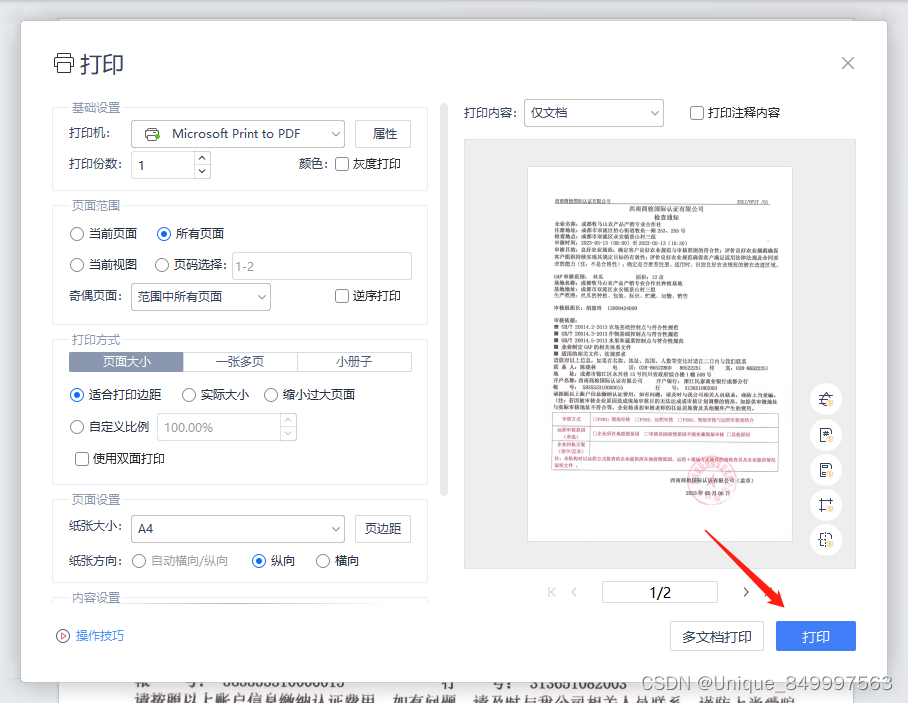
使用Wps减小PDF文件的大小
第一步、打开左上角的文件 第二步、点击打印选项 第三步、点击打印按钮...
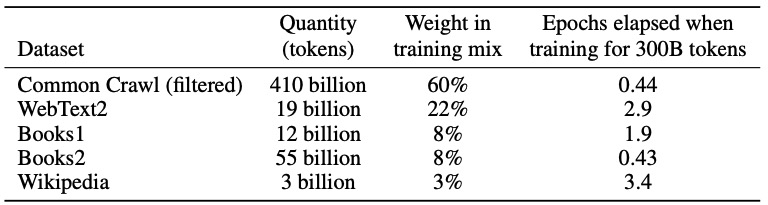
【深度学习】GPT-3
2020年5月,OpenAI在长达72页的论文《https://arxiv.org/pdf/2005.14165Language Models are Few-Shot Learners》中发布了GPT-3,共有1750亿参数量,需要700G的硬盘存储,(GPT-2有15亿个参数),它比GPT-2有了极大的改进。根…...
在登录界面中设置登录框、多选项和按钮(HTML和CSS)
登录框(Input框)的样式: /* 设置输入框的宽度和高度 */ input[type"text"], input[type"password"] {width: 200px;height: 30px; }/* 设置输入框的边框样式、颜色和圆角 */ input[type"text"], input[type&q…...
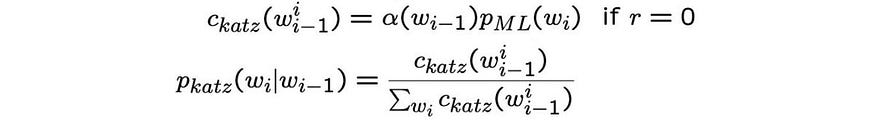
【语音识别】- 声学,词汇和语言模型
一、说明 语音识别是指计算机通过处理人类语言的音频信号,将其转换为可理解的文本形式的技术。也就是说,它可以将人类的口语语音转换为文本,以便计算机能够进一步处理和理解。它是自然语言处理技术的一部分,被广泛应用于语音识别助…...
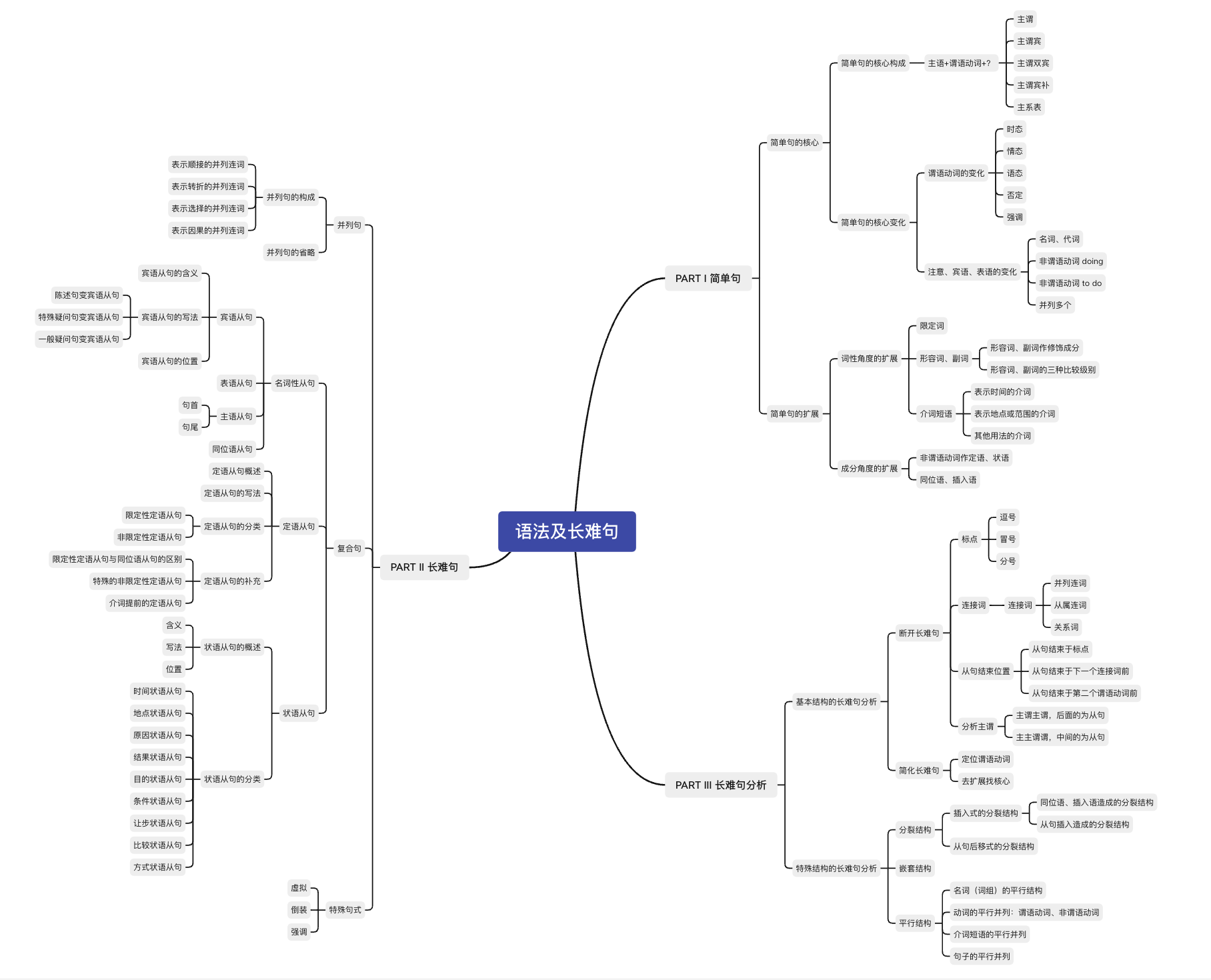
【考研英语语法及长难句】小结
【 考场攻略汇总 】 考点汇总 考场攻略 #1 断开长难句只看谓语动词,不考虑非谓语动词先找从句,先看主句 考场攻略 #2 抓住谓语动词,抓住句子最核心的表述动作或内容通过定位谓语动词,找到复杂多变的主语通过谓语动词的数量&…...

C# 反射
反射的概念:C#通过类型(Type)来创建对象,调用对象中的方法,属性等信息;B超就是利用了反射原理将超声波打在人的肚子上,然后通过反射波进行体内器官的成员; 反射提供的类:…...
Pytorch(二)
一、分类任务 构建分类网络模型 必须继承nn.Module且在其构造函数中需调用nn.Module的构造函数无需写反向传播函数,nn.Module能够利用autograd自动实现反向传播Module中的可学习参数可以通过named_parameters()返回迭代器 from torch import nn import torch.nn.f…...

Python 使用http时间同步设置系统时间源码
Python方式实现使用http时间同步设置系统时间源码,系统环境是ubuntu 12.04、Python2.7版本。需要使用到time、os及httplib方法。 Python使用http时间同步设置系统时间,源码如下: #-*-coding:utf8 -*- import httplib as client import time…...

golang sync.singleflight 解决热点缓存穿透问题
在 go 的 sync 包中,有一个 singleflight 包,里面有一个 singleflight.go 文件,代码加注释,一共 200 行出头。内容包括以下几块儿: Group 结构体管理一组相关的函数调用工作,它包含一个互斥锁和一个 map,map 的 key 是…...
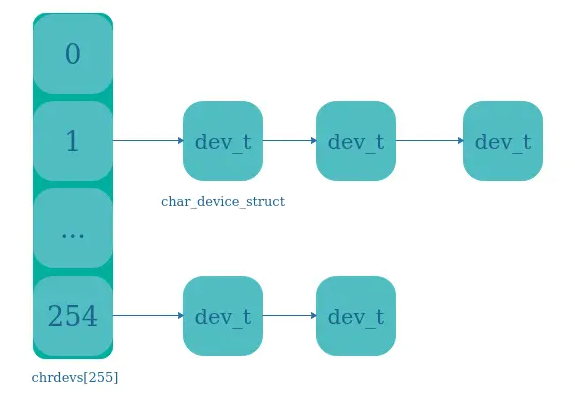
4、Linux驱动开发:设备-设备号设备号注册
目录 🍅点击这里查看所有博文 随着自己工作的进行,接触到的技术栈也越来越多。给我一个很直观的感受就是,某一项技术/经验在刚开始接触的时候都记得很清楚。往往过了几个月都会忘记的差不多了,只有经常会用到的东西才有可能真正记…...
调用Python)
C++(MFC)调用Python
环境: phyton版本:3.10 VS版本:VS2017 包含文件头:Python\Python310\include 包含库文件:Python\Python310\libs 程序运行期间,以下函数只需要调用一次即可,重复调用会导致崩溃 void Initial…...

深度学习实践——循环神经网络实践
系列实验 深度学习实践——卷积神经网络实践:裂缝识别 深度学习实践——循环神经网络实践 深度学习实践——模型部署优化实践 深度学习实践——模型推理优化练习 代码可见于: 深度学习实践——循环神经网络实践 0 概况1 架构实现1.1 RNN架构1.1.1 RNN架…...
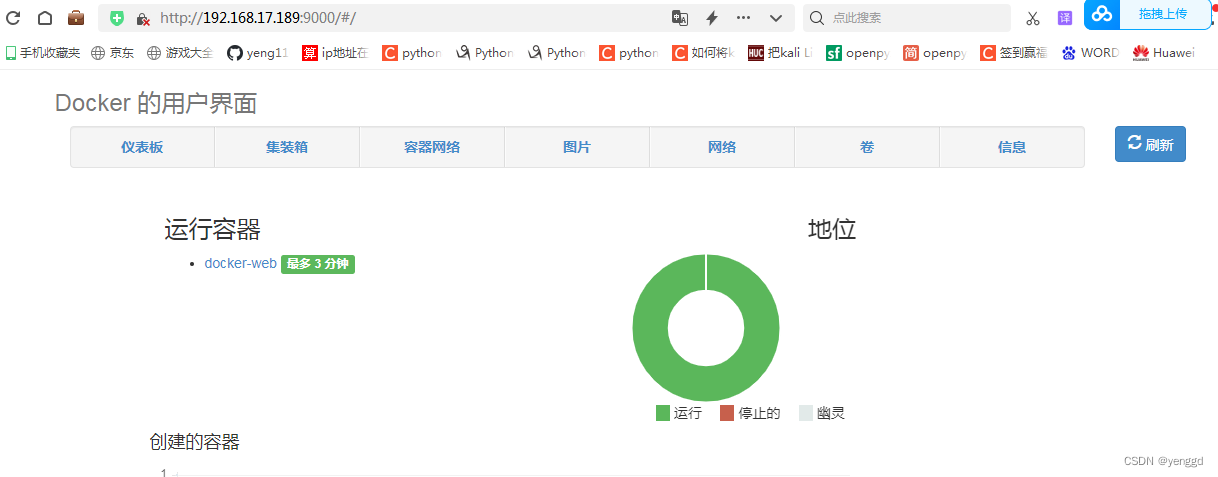
docker简单web管理docker.io/uifd/ui-for-docker
要先pull这个镜像docker.io/uifd/ui-for-docker 这个软件默认只能使用9000端口,别的不行,因为作者在镜像制作时已加入这一层 刚下下来镜像可以通过docker history docker.io/uifd/ui-for-docker 查看到这个端口已被 设置 如果在没有设置br0网关时&…...
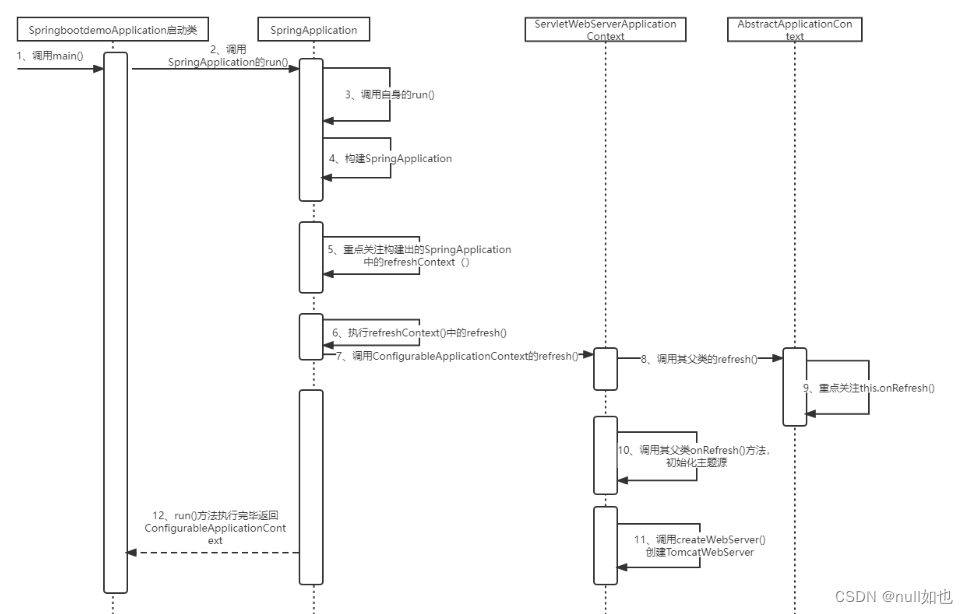
SpringBoot内嵌的Tomcat:
SpringBoot内嵌Tomcat源码: 1、调用启动类SpringbootdemoApplication中的SpringApplication.run()方法。 SpringBootApplication public class SpringbootdemoApplication {public static void main(String[] args) {SpringApplication.run(SpringbootdemoApplicat…...

企业级docker应用注意事项
现在很多企业使用容器化技术部署应用,绕不开的docker技术,在生产环境docker常用操作总结。参考:https://juejin.cn/post/7259275893796651069 1. 尽可能使用官方镜像 在docker hub 官方 使用后面带有 DOCKER OFFICIAL IMAGE 标签的镜像&…...

腾讯云高性能计算集群CPU服务器处理器说明
腾讯云高性能计算集群以裸金属云服务器为节点,通过RDMA互联,提供了高带宽和极低延迟的网络服务,能满足大规模高性能计算、人工智能、大数据推荐等应用的并行计算需求,腾讯云服务器网分享腾讯云服务器高性能计算集群CPU处理器说明&…...
tinkerCAD案例:23.Tinkercad 中的自定义字体
tinkerCAD案例:23.Tinkercad 中的自定义字体 原文 Tinkercad Projects Tinkercad has a fun shape in the Shape Generators section that allows you to upload your own font in SVG format and use it in your designs. I’ve used it for a variety of desi…...

Box-Cox 变换
Box-cox 变化公式如下: y ( λ ) { y λ − 1 λ λ ≠ 0 l n ( y ) λ 0 y^{(\lambda)}\left\{ \begin{aligned} \frac{y^{\lambda} - 1}{\lambda} && \lambda \ne 0 \\ ln(y) && \lambda 0 \end{aligned} \right. y(λ)⎩ ⎨ ⎧λyλ−1ln…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...