SpringCloud学习路线(11)——分布式搜索ElasticSeach场景使用
一、DSL查询文档
(一)DSL查询分类
ES提供了基于JSON的DSL来定义查询。
1、常见查询类型:
- 查询所有: 查询出所有的数据,例如,match_all
- 全文检索(full text)查询: 利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
- match_query
- multi_match_query
- 精确查询: 根据精确词条值查找数据,一般查找精确值,例如:
- ids
- range
- term
- 地理(geo)坐标查询: 根据经纬度查询,例如:
- geo_distance
- geo_bounding_box
- 复合(compound)查询: 复合查询可以将伤处查询条件组合起来,合并查询条件,例如:
- bool
- function_score
2、查询的基本语法
GET /indexName/_search
{"query": {"查询类型": {"查询条件": "条件值"}}
}
3、match_all的使用
GET /indexName/_search
{"query": {"match_all": { }}
}
查询效果
{"took" : 446,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "test","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"info" : "这是我的ES拆分Demo","age" : 18,"email" : "zengoo@163.com","name" : {"firstName" : "Zengoo","lastName" : "En"}}}]}
}
(二)全文检索查询
全文检索查询,会对用户输入内容分词,常用于搜索框搜索。
1、match查询
(1)结构
GET /indexName/_search
{"query": {"match": { "FILED": "TEXT"}}
}
(2)简单使用
GET /test/_search
{"query": {"match": { "info": "ES" #当有联合属性all,进行匹配,就可以进行多条件匹配,按照匹配数量来确定权值大小。}}
}
使用结果
{"took" : 71,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.2876821,"hits" : [{"_index" : "test","_type" : "_doc","_id" : "1","_score" : 0.2876821,"_source" : {"info" : "这是我的ES拆分Demo","age" : 18,"email" : "zengoo@163.com","name" : {"firstName" : "Zengoo","lastName" : "En"}}}]}
}
2、multi_match查询
从使用效果上,与条件查询的"all"字段相同。
(1)结构
GET /indexName/_search
{"query": {"multi_match": { "query": "TEXT","fields": ["FIELD1", "FIELD2"]}}
}
(2)简单使用
GET /test/_search
{"query": {"multi_match": {"query": "ES","fields": ["info","age"]}}
}
(三)精准查询
精确查询一般是查找精确值,所以不会对搜索条件分词。
1、term: 根据词条精确值查询,在商城项目中,通常会用在类型筛选上。
(1)结构
GET /test/_search
{"query": {"term": {"FIELD": {"value": "VALUE"}}}
}
(2)简单使用
GET /test/_search
{"query": {"term": {"city": {"value": "杭州" #精确值}}}
}
2、range: 根据值范围查询,在商城项目中,通常会用在价值筛选上。
(1)结构
GET /test/_search
{"query": {"range": {"FIELD": {"gte": 10,"lte": 20}}}
}
(2)简单使用
GET /test/_search
{"query": {"range": {"price": {"gte": 699, #最低值,gte 大于等于,gt 大于"lte": 1899 #最高值,lte 小于等于,lt 小于}}}
}
(四)地理坐标查询
1、geo_distance: 查询到指定中心小于某个距离值的所有文档(圆形范围圈)。
(1)结构
GET /indexName/_search
{"query": {"geo_distance": {"distance": "15km","FIELD": "13.21,121.5"}}
}
(2)简单使用
GET /test/_search
{"query": {"geo_distance": {"distance": "20km","location": "13.21,121.5"}}
}
2、geo_bounding_box: 查询geo_point值落在某个举行范围的所有文档(矩形范围圈)。
(1)结构
GET /indexName/_search
{"query": {"geo_bounding_box": {"FIELD": {"top_left": {"lat": 31.1,"lon": 121.5},"bottom_right": {"lat": 30.9,"lon": 121.7}}}}
}
(五)复合查询
复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。
1、function score: 算分函数查询,可以控制文档相关性算分,控制文档排名。
当我们利用match查询时,文档结果会根据搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
例如,在搜索CSDNJava。
[{"_score": 17.85048,"_source": {"name": "Java语法菜鸟教程"}},{"_score": 12.587963,"_source": {"name": "Java语法W3CScool"}},{"_score": 11.158756,"_source": {"name": "CSDNJava语法学习树"}},
]
相关算法:
- 最开始的算分算法:TF(词条频率) = 词条 / 文档词条总数
- 避免公共词条改良的算分算法:TF-IDF算法
- IDF(逆文档频率) = Log( 文档总数 / 包含词条的文档总数 )
- socre = (∑(i,n) TF) * IDF
- BM25算法: 现在默认采用的算法,该算法比较复杂,其词频曲度最终会趋于水平。
(1)结构
GET /hotel/_search
{"query": {"function_socre": { #查询类型"query": { #查询原始数据"match": {"all": "外滩"}},"functions": [ #解析方法{"filter": { # 过滤条件"term": {"id": "1"}},"weight": 10 # score算分方法,weight是直接以常量为函数结果,其它的还有feild_value_factor:以某字段作为函数结果,random_score: 随机值作为函数结果,script_score:定义计算公式}],"boost_mode": "multiply" # 加权模式,定义function score 与 query score的运算方式,包括 multiply:两者相乘(默认);replace:用function score 替换 query score;其它: sum、avg、max、min}}
}
(2)简单使用
需求: 将用户给的词条排名靠前
需要考虑的元素:
- 哪些文档需要算分加权 : 包含词条内容的文档
- 算分函数是什么: weight
- 加权模式用哪个: sum
实现:
GET /hotel/_search
{"query": {"function_socre": { # 算分算法"query": {"match": {"all": "速8快捷酒店"}},"functions": [ {"filter": { # 满足条件,品牌必须是速8"term": {"brand": "速8"}},"weight": 2 #算分权重为 2}],"boost_mode": "sum"}}
}
2、复合查询 Boolean Query
子查询的组合方式:
- must: 必须匹配每个子查询,类似 “与”
- should: 选择性匹配子查询,类似 “或”
- must_not: 排除匹配模式,不参与算分,类似 “非”
- filter: 必须匹配,不参与算分
实现案例
#搜查位置位于上海,品牌为“皇冠假日”或是“华美达”,并且价格500<price<600元,且评分大于等于45的酒店
GET /hotel/_search
{"query": {"bool": {"must": [ # 必须匹配的条件{ "term": { "city: "上海" } }],"should": [ # 可以匹配到条件{ "term": { "brand": "皇冠假日" } },{ "term": { "brand": "华美达" } }],"must_not": [ #不匹配的条件{ "range": { "price": {"lte": 500, "gte": 600} }}],"filter": [ #筛选条件{ "range": { "score": { "gte": 45 } } }]} }
}
二、搜索结果处理
(一)排序
ES支持对搜索结果排序,默认根据(_score)来排序,可以排序的字段类型有:keyword、数值类型、地理坐标类型、日期类型等
1、结构:
# 普通类型排序
GET /test/_search
{"query": {"match_all": {}},"sort": [{"FIELD": {"order": "desc" # 排序字段和排序方式ASC、DESC}}]
}# 地理坐标型排序
GET /test/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"FIELD": { #精度维度"lat": 40,"lon": -70},"order": "asc","unit": "km"}}]
}
2、实现案例
排序需求: 按照用户评价降序,评价相同的按照价格升序。
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"score": { # 简化结构可以使用,"score": "desc""order": "desc"},"price": {"order": "asc"}}]
}
排序需求: 按照距离用户位置的距离进行升序。
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"location": {"lat": 40.58489,"lon": -70.59873},"order": "asc","unit": "km"}}]
}
(二)分页
修改分页参数
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"price": "asc"}],"from": 100, # 分页开始的位置,默认为0"size": 20, # 期望获取的文档总数
}
深度分页问题
当我们将ES做成一个集群服务,那么我们需要选择前10的数据时,ES底层会如何去实现呢?
ES由于使用的是倒排索引,每一台ES都会分片数据。
1、每个数据分片上都排序并查询前1000条文档。
2、聚合所有节点的结果,在内存中重新排序选出前1000条文档。
3、从前1000挑中,选取from=990,size=10的文档
如果搜索页数过深,或者结果集过大,对内存和CPU的消耗越高,因此ES设置的结果集查询上限是10000条。
如何解决深度分页的问题?
- seach after: 分页时需要排序,原理是从上一次的排序值开始,查询下一页数据(官方推荐)。
- scroll: 原理是将排序数据形成缓存保存在内存(官方不推荐)。
(三)高亮
1、概念: 在搜索结果中搜索关键字突出显示。
2、原理
- 将搜索结果中的关键字用标签标记出来
- 在页面中给标签添加css样式
3、语法:
GET /indexName/_search
{"query": {"match": {"FIELD": "TEXT"}},"highlight": { #高亮字段"fields": {"FIELD": {"pre_tags": "<em>", #标签前缀"post_tags": "</em>", #标签后缀"require_field_match": "false" #判断该字段是否与前面查询的字段匹配}}}
}
三、RestClient查询文档
(一)实现简单查询案例
//1、准备Request
SearchRequest request = new SearchRequest("hotel");
//2、组织DSL参数,QueryBuilders是ES的查询API库
request.source().query(QueryBuilders.matchAllQuery());
//3、发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、解析响应结果,搜索结果会放置在Hits集合中
SearchHits searchHits = response.getHits();
//5、查询总数
long total = searchHits.getTotalHits().value;
//6、查询的结果数组
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit: hits) {//得到source,source就是查询出来的实体信息String json = hit.getSourceAsString();//序列化HotelDoc hotelDoc = JSON.parseObject(json,HotelDoc.class);
}
(二)match查询
//1、准备Request
SearchRequest request = new SearchRequest("hotel");
//2、组织DSL参数,QueryBuilders是ES的查询API库
//单字段查询
request.source().query(QueryBuilders.matchQuery("all","皇家"));
//多字段查询
//request.source().query(QueryBuilders.multiMatchQuery("皇家","name","buisiness"));
//3、发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、解析响应结果,搜索结果会放置在Hits集合中
SearchHits searchHits = response.getHits();
//5、查询总数
long total = searchHits.getTotalHits().value;
//6、查询的结果数组
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit: hits) {//得到source,source就是查询出来的实体信息String json = hit.getSourceAsString();//序列化HotelDoc hotelDoc = JSON.parseObject(json,HotelDoc.class);
}
(三)精确查询
//词条查询
QueryBuilders.termQuery("city","杭州");
//范围查询
QueryBuilders.rangeQuery("price").gte(100).lte(150);
(四)复合查询
//创建布尔查询
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//添加must条件
boolQuery.must(QueryBuilders.termQuery("city","杭州"));
//添加filter条件
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
(五)排序、分页、高亮
1、排序与分页
// 查询
request.source().query(QueryBuilders.matchAllQuery());
// 分页配置
request.source().from(0).size(5);
// 价格排序
request.source().sort("price", SortOrder.ASC);
2、高亮
高亮查询请求
request.source().highlighter(new HighLightBuilder().field("name").requireFieldMatch(false));
处理高亮结果
// 获取source
HotelDoc hotelDoc = JSON.parseObject(hit.getSourceAsString(), HotelDoc.class);
// 处理高亮
Map<String, HighlightFields> highlightFields = hit.getHighlightFields();
if(!CollectionUtils.isEmpty(highlightFields)) {// 获取字段结果HighlightField highlightField = highlightFields.get("name");if (highlightField != null) {// 去除高亮结果数组的第一个String name = highlightField.getFragments()[0].string();hotelDoc.setName(name);}
}
相关文章:
——分布式搜索ElasticSeach场景使用)
SpringCloud学习路线(11)——分布式搜索ElasticSeach场景使用
一、DSL查询文档 (一)DSL查询分类 ES提供了基于JSON的DSL来定义查询。 1、常见查询类型: 查询所有: 查询出所有的数据,例如,match_all全文检索(full text)查询: 利用…...

负数补码表示
负数补码作用 在计算机中加法和减法采用同一电路,即用加法表示减法,如7 - 2 5变成7 ( -2) 5,这样减法的电路不用另行设计,但计算机中数据以二进制存储,没有负号,因此设计负数补码代…...
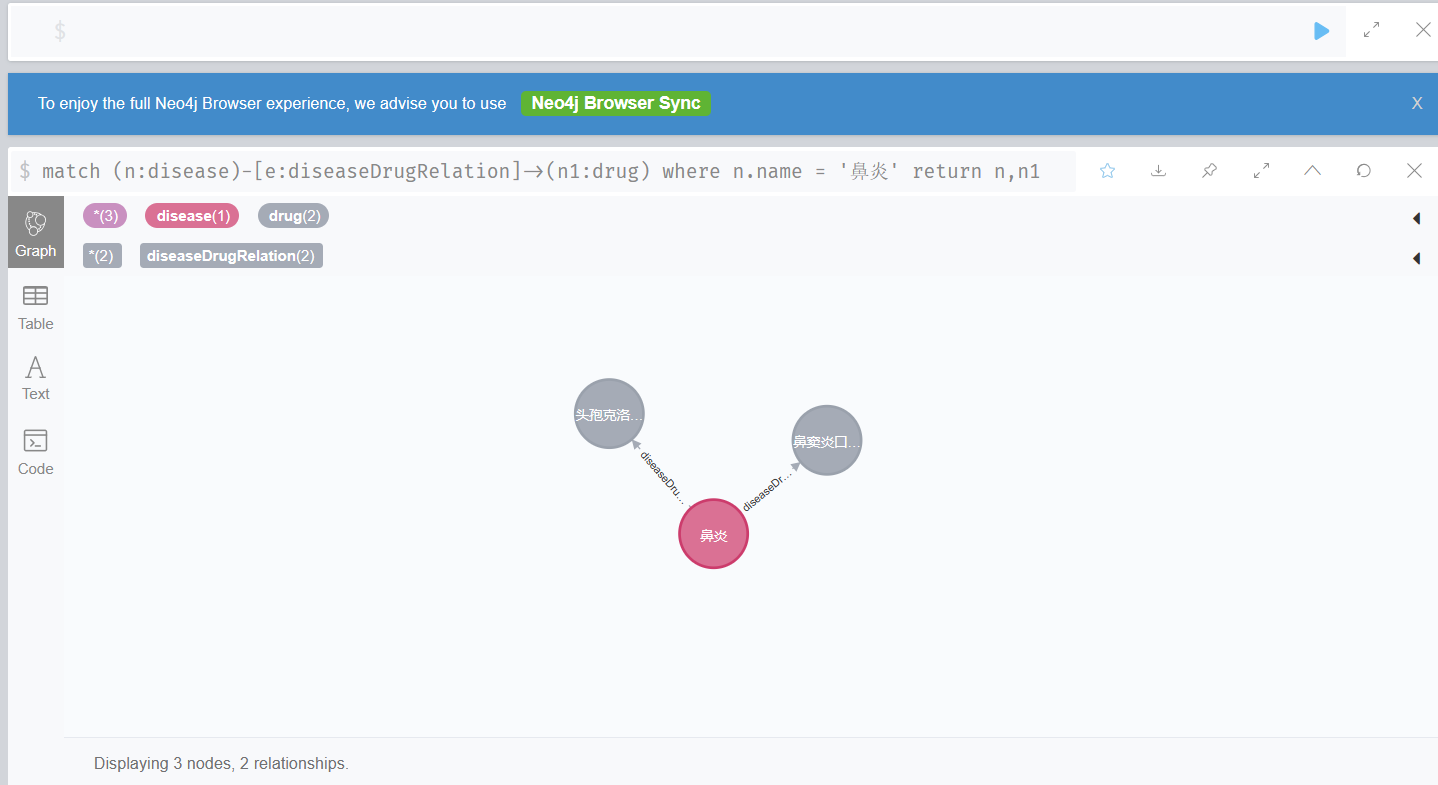
ChatGPT结合知识图谱构建医疗问答应用 (一) - 构建知识图谱
一、ChatGPT结合知识图谱 在本专栏的前面文章中构建 ChatGPT 本地知识库问答应用,都是基于词向量检索 Embedding 嵌入的方式实现的,在传统的问答领域中,一般知识源采用知识图谱来进行构建,但基于知识图谱的问答对于自然语言的处理…...
C++ 类和对象
面向过程/面向对象 C语言是面向过程,关注过程,分析出求解问题的步骤,通过函数调用逐步解决问题 C是基于面对对象的,关注的是对象——将一件事拆分成不同的对象,依靠对象之间的交互完成 引入 C语言中结构体只能定义…...

c# 此程序集中已使用了资源标识符
严重性 代码 说明 项目 文件 行 禁止显示状态 错误 CS1508 此程序集中已使用了资源标识符“BMap.NET.WindowsForm.BMapControl.resources” BMap.NET.WindowsForm D:\MySource\Decompile\BMap.NET.WindowsForm\CSC 1 活动 运行程序时&a…...

WPF实战学习笔记30-登录、注册服务添加
登录、注册服务添加 添加注册数据类型添加注册UI修改bug UserDto的UserName更改为可null类型Resgiter 添加加密方法修改控制器 添加注册数据类型 添加文件MyToDo.Share.Models.ResgiterUserDto.cs using System; using System.Collections.Generic; using System.Linq; us…...

GDAL C++ API 学习之路 OGRGeometry 圆弧类 OGRCircularString
OGRCircularString Class <ogrsf_frmts.h> OGRCircularString 类是 OGR 几何库中的一个类,用于表示圆弧字符串(circular string)类型的几何图形。圆弧字符串是由一系列圆弧段组成的几何图形,每个圆弧段由三个点定义…...
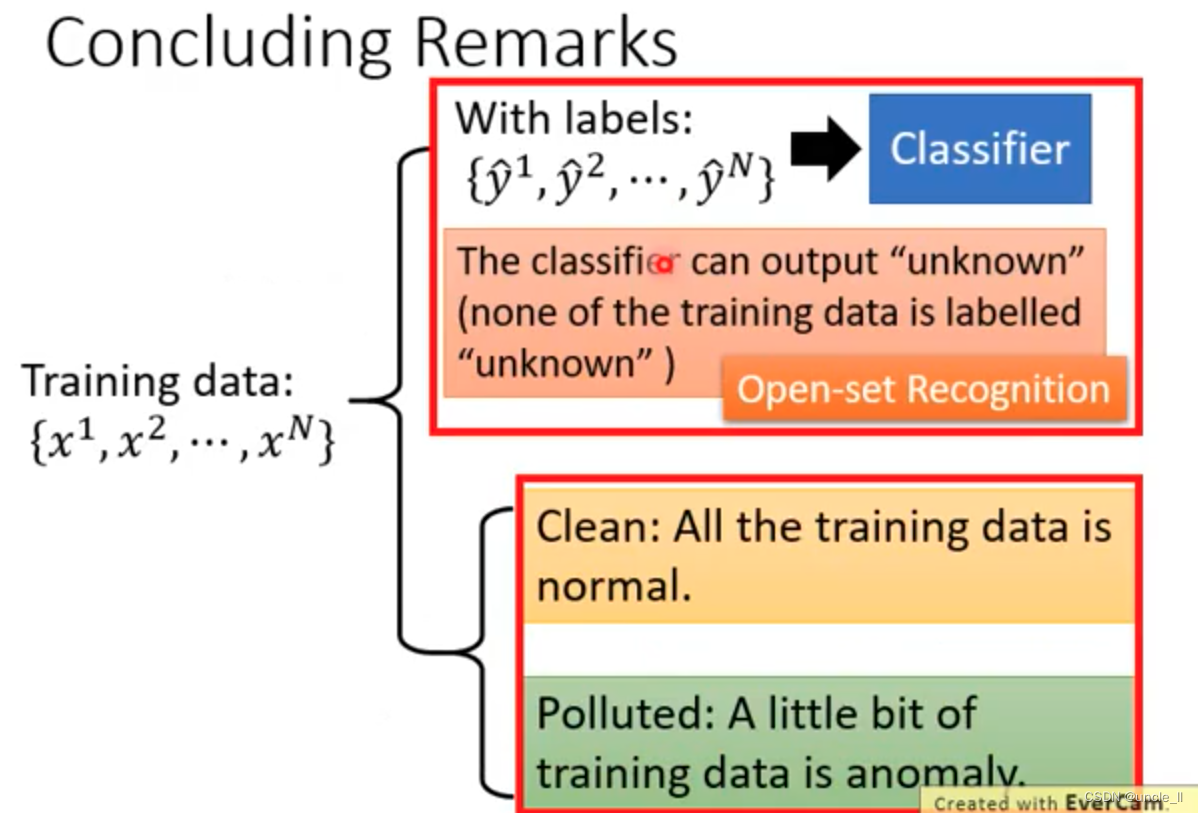
机器学习:异常检测
问题定义 anomaly,outlier, novelty, exceptions 不同的方法使用不同的名词定义这类问题。 应用 二分类 假如只有正常的数据,而异常的数据的范围非常广的话(无法穷举),二分类这些不好做。另外就…...

flask中的蓝图
flask中的蓝图 在 Flask 中,蓝图(Blueprint)是一种组织路由和服务的方法,它允许你在应用中更灵活地组织代码。蓝图可以大致理解为应用或者应用中的一部分,可以在蓝图中定义路由、错误处理程序以及静态文件等。然后可以…...

Spring Cloud+Spring Boot+Mybatis+uniapp+前后端分离实现知识付费平台免费搭建
Java版知识付费-轻松拥有知识付费平台 多种直播形式,全面满足直播场景需求 公开课、小班课、独立直播间等类型,满足讲师个性化直播场景需求;低延迟、双向视频,亲密互动,无论是互动、答疑,还是打赏、带货、…...
)
uniapp 瀑布流 (APP+H5+微信小程序)
WaterfallsFlow.vue <template><view class"wf-page" :class"props?.paddingC ? paddingC : "><!-- left --><view><view id"left" ref"left" v-if"leftList.length"><viewv-for…...
医疗小程序:提升服务质量与效率的智能平台
在医疗行业,公司小程序成为提高服务质量、优化管理流程的重要工具。通过医疗小程序,可以方便医疗机构进行信息传播、企业展示等作用,医疗机构也可以医疗小程序提供更便捷的预约服务,优化患者体验。 医疗小程序的好处 提升服务质量…...

ComPDFKit 转档SDK OCR表格识别功能
我们非常高兴地宣布,适用于 Windows、iOS、Android 和服务器的 ComPDFKit 转档SDK 1.8.0 现已发布!在该版本中,OCR 功能支持了表格识别,优化了OCR文字识别率。PDF to HTML 优化了html 文件结构,使转换后的 HTML 文件容…...

华为OD机考--阿里巴巴黄金箱
题目内容 贫如洗的樵夫阿里巴巴在去砍柴的路上,无意中发现了强盗集团的藏宝地,藏宝地有编号从0~N的箱子每个箱子上面贴有一个数字箱子中可能有一个黄金宝箱。 黄金宝箱满足排在它之前的所有箱子数字和等于排在它之后的所有箱子数字之和; 一个箱子左边部分…...

mybatis-config.xml-配置文件详解
文章目录 mybatis-config.xml-配置文件详解说明文档地址:配置文件属性解析properties 属性应用实例 settings 全局参数定义应用实例 typeAliases 别名处理器举例说明 typeHandlers 类型处理器environments 环境environment 属性应用实例 mappers配置 mybatis-config.xml-配置文…...

【雕爷学编程】MicroPython动手做(18)——掌控板之声光传感器
知识点:什么是掌控板? 掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED…...
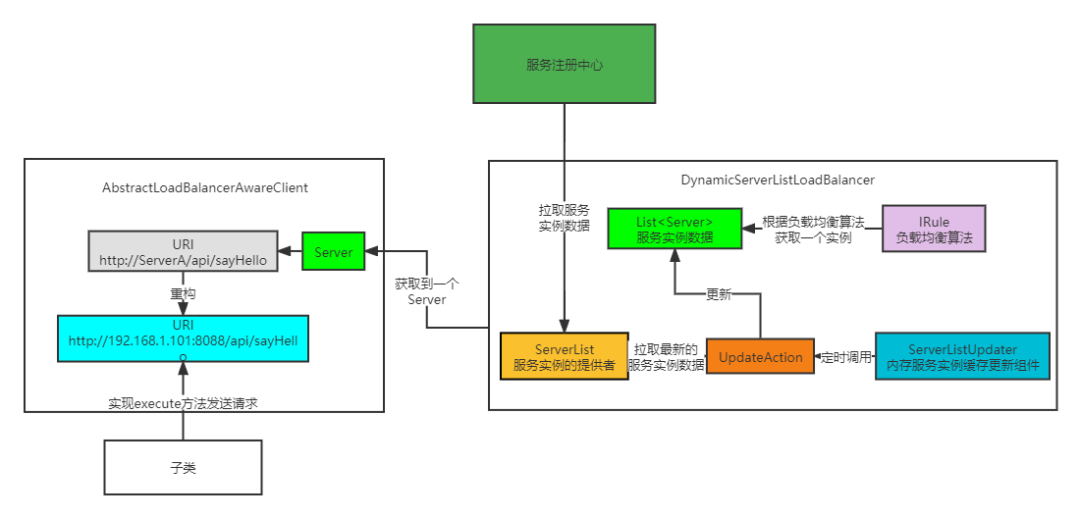
Ribbon源码
学了feign源码之后感觉,这部分还是按运行流程分块学合适。核心组件什么的,当专业术语学妥了。序章:认识真正のRibbon 但只用认识一点点 之前我们学习Ribbon的简单使用时,都是集成了Eureka-client或者Feign等组件,甚至在…...

Linux下在终端输入密码隐藏方法
Linux系统中,如何将在终端输入密码时将密码隐藏? 最近做简单的登录界面时,不做任何操作的话,在终端输入密码的同时也会显示输入的密码是什么,这样对于隐蔽性和使用都有不好的体验。那么我就想到将密码用字符*隐藏起来…...

【ARM 常见汇编指令学习 3 -- ARM64 无符号位域提取指令 UBFX】
文章目录 ARM64 无符号位域提取指令 上篇文章:ARM 常见汇编指令学习 2 – 存储指令 STP 与 LDP 下篇文章:ARM 常见汇编指令学习 4 – ARM64 比较指令 cbnz 与 b.ne 区别 ARM64 无符号位域提取指令 在代码中如何监控寄存器的某1bit, 或者某几…...
求分享如何批量压缩视频的容量的方法
视频内存过大,不但特别占内存,而且还会使手机电脑出现卡顿的现象,除此之外,如果我们想发送这些视频文件可能还会因为内存太大无法发送。因此,我们可以批量地压缩视频文件的内存大小,今天小编要来分享一招&a…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

前端工具库lodash与lodash-es区别详解
lodash 和 lodash-es 是同一工具库的两个不同版本,核心功能完全一致,主要区别在于模块化格式和优化方式,适合不同的开发环境。以下是详细对比: 1. 模块化格式 lodash 使用 CommonJS 模块格式(require/module.exports&a…...
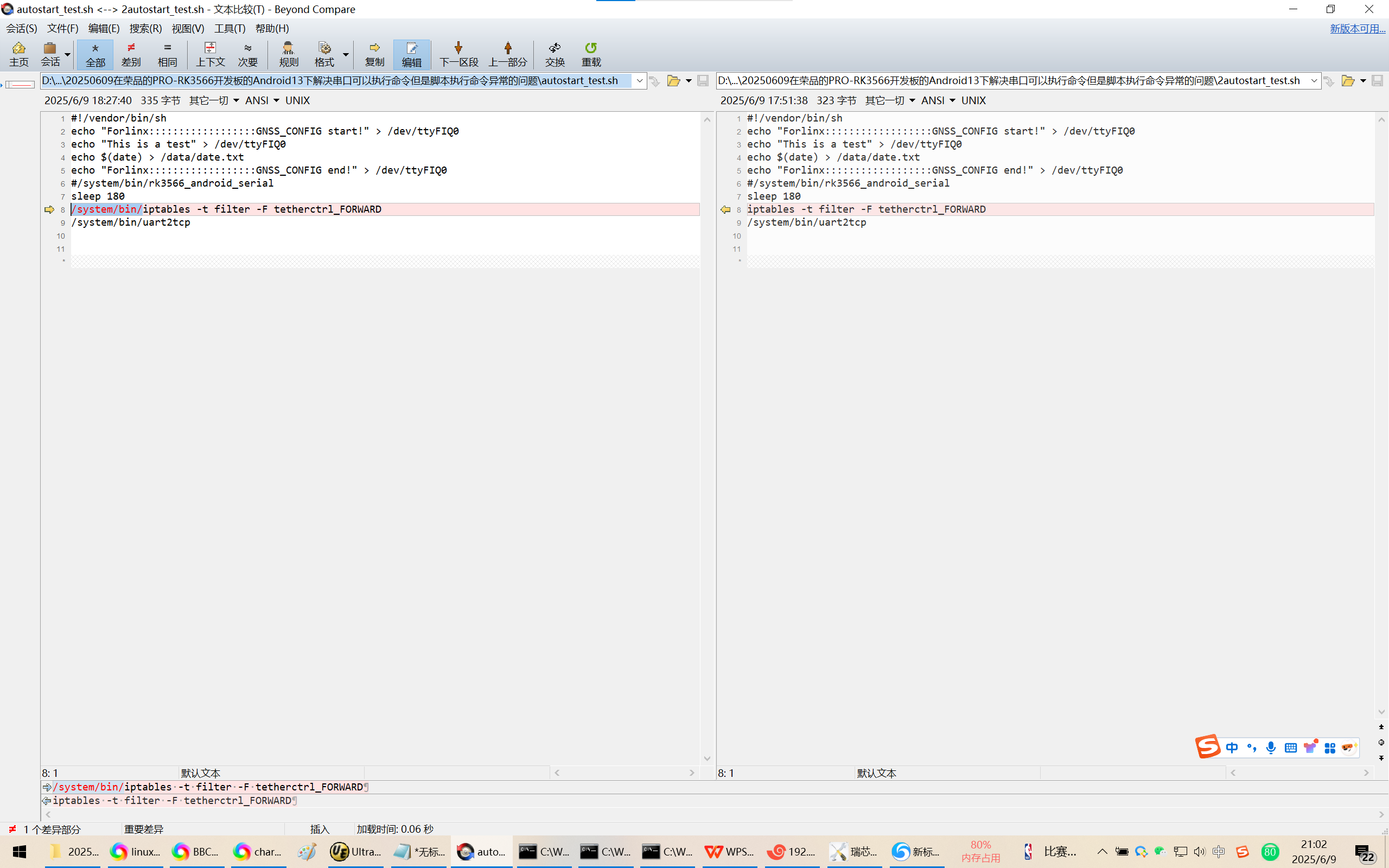
20250609在荣品的PRO-RK3566开发板的Android13下解决串口可以执行命令但是脚本执行命令异常的问题
20250609在荣品的PRO-RK3566开发板的Android13下解决串口可以执行命令但是脚本执行命令异常的问题 2025/6/9 20:54 缘起,为了跨网段推流,千辛万苦配置好了网络参数。 但是命令iptables -t filter -F tetherctrl_FORWARD可以在调试串口/DEBUG口正确执行。…...
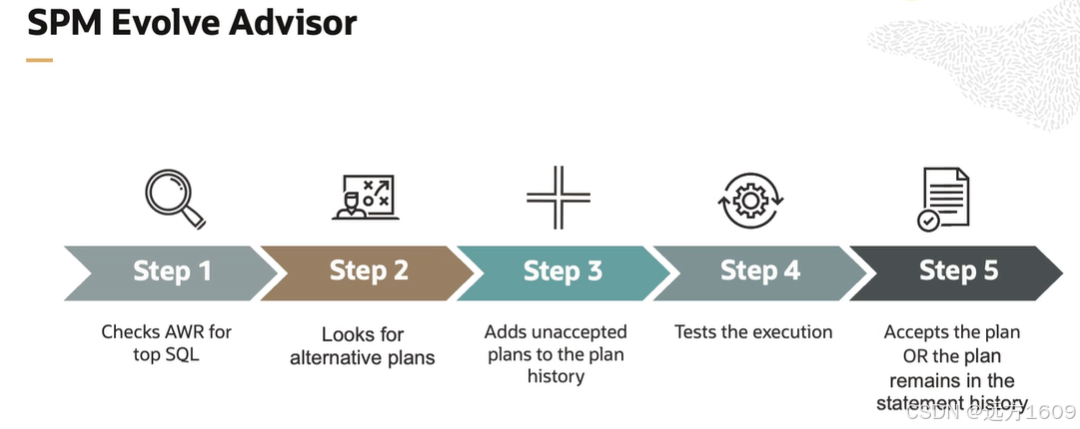
21-Oracle 23 ai-Automatic SQL Plan Management(SPM)
小伙伴们,有没有迁移数据库完毕后或是突然某一天在同一个实例上同样的SQL, 性能不一样了、业务反馈卡顿、业务超时等各种匪夷所思的现状。 于是SPM定位开始,OCM考试中SPM必考。 其他的AWR、ASH、SQLHC、SQLT、SQL profile等换作下一个话题…...
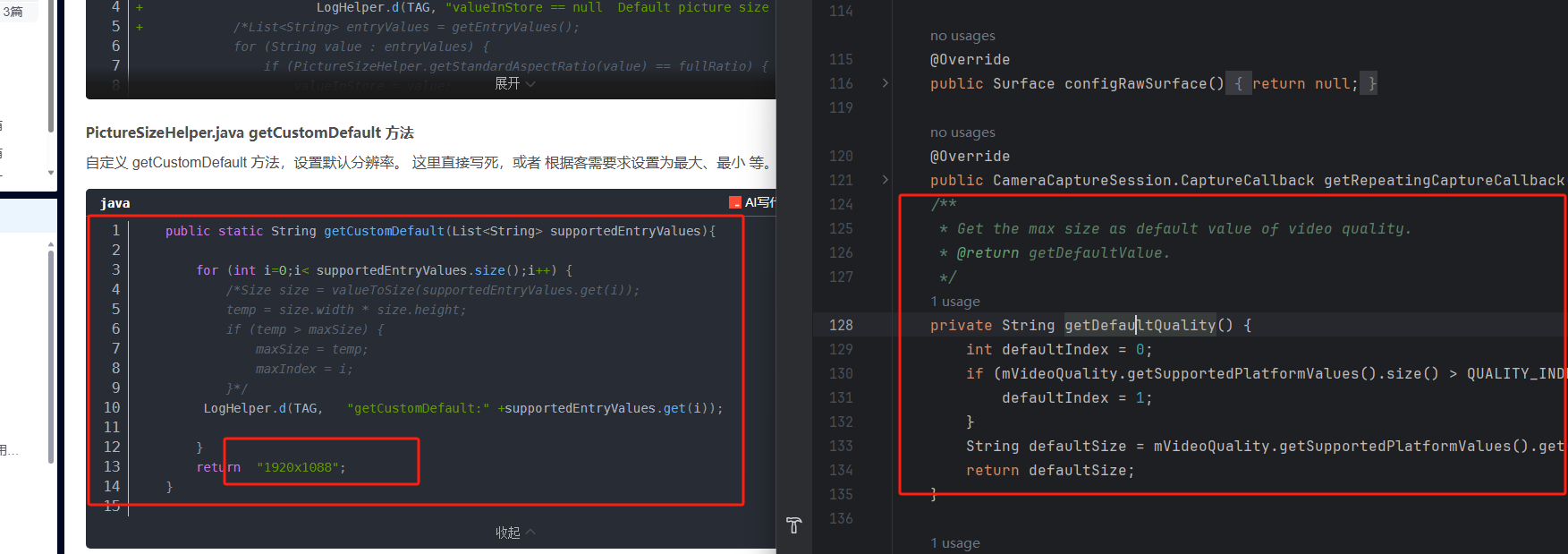
MTK-Android12-13 Camera2 设置默认视频画质功能实现
MTK-Android12-13 Camera2 设置默认视频画质功能实现 场景:部分客户使用自己的mipi相机安装到我们主板上,最大分辨率为1280720,但是视频画质默认的是640480。实际场景中,在默认视频分辨率情况下拍出来的视频比较模糊、预览也不清晰…...