Elasticsearch: Prefix queries - 前缀查询
Prefix queries 被用于在查询时返回在提供的字段中包含特定前缀的文档。有时我们可能想使用前缀查询单词,例如 Leonardo 的 Leo 或 Marlon Brando、Mark Hamill 或 Martin Balsam 的 Mar。 Elasticsearch 提供了一个前缀查询,用于获取匹配单词开头部分(前缀)的记录。
准备数据
示例
我们先准备数据。我们想创建如下的一个 movies 的索引:
PUT movies
{"settings": {"analysis": {"analyzer": {"en_analyzer": {"tokenizer": "standard","filter": ["lowercase","stop"]},"shingle_analyzer": {"type": "custom","tokenizer": "standard","filter": ["lowercase","shingle_filter"]}},"filter": {"shingle_filter": {"type": "shingle","min_shingle_size": 2,"max_shingle_size": 3}}}},"mappings": {"properties": {"title": {"type": "text","analyzer": "en_analyzer","fields": {"suggest": {"type": "text","analyzer": "shingle_analyzer"}}},"actors": {"type": "text","analyzer": "en_analyzer","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"description": {"type": "text","analyzer": "en_analyzer","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"director": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"genre": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"metascore": {"type": "long"},"rating": {"type": "float"},"revenue": {"type": "float"},"runtime": {"type": "long"},"votes": {"type": "long"},"year": {"type": "long"},"title_suggest": {"type": "completion","analyzer": "simple","preserve_separators": true,"preserve_position_increments": true,"max_input_length": 50}}}
}我们接下来使用 _bulk 命令来写入一些文档到这个索引中去。我们使用这个链接中的内容。我们使用如下的方法:
POST movies/_bulk
{"index": {}}
{"title": "Guardians of the Galaxy", "genre": "Action,Adventure,Sci-Fi", "director": "James Gunn", "actors": "Chris Pratt, Vin Diesel, Bradley Cooper, Zoe Saldana", "description": "A group of intergalactic criminals are forced to work together to stop a fanatical warrior from taking control of the universe.", "year": 2014, "runtime": 121, "rating": 8.1, "votes": 757074, "revenue": 333.13, "metascore": 76}
{"index": {}}
{"title": "Prometheus", "genre": "Adventure,Mystery,Sci-Fi", "director": "Ridley Scott", "actors": "Noomi Rapace, Logan Marshall-Green, Michael Fassbender, Charlize Theron", "description": "Following clues to the origin of mankind, a team finds a structure on a distant moon, but they soon realize they are not alone.", "year": 2012, "runtime": 124, "rating": 7, "votes": 485820, "revenue": 126.46, "metascore": 65}....在上面,为了说明的方便,我省去了其它的文档。你需要把整个 movies.txt 的文件拷贝过来,并全部写入到 Elasticsearch 中。它共有1000 个文档。
Prefix 查询
我们使用如下的例子来进行查询:
GET movies/_search?filter_path=**.hits
{"_source": false, "fields": ["actors"], "query": {"prefix": {"actors.keyword": {"value": "Mar"}}}
}当我们搜索前缀 Mar 时,上面的查询获取了演员以 Mar 开头的电影。请注意,我们正在 actors.keyword 字段上运行前缀查询。它是一个 keyword 字段。返回的结果为:
{"hits": {"hits": [{"_index": "movies","_id": "RgJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"actors": ["Mark Wahlberg, Michelle Monaghan, J.K. Simmons, John Goodman"]}},{"_index": "movies","_id": "SQJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"actors": ["Mark Wahlberg, Kurt Russell, Douglas M. Griffin, James DuMont"]}},{"_index": "movies","_id": "awJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"actors": ["Mario Casas, Ana Wagener, José Coronado, Bárbara Lennie"]}},{"_index": "movies","_id": "ggJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"actors": ["Mark Wahlberg, Nicola Peltz, Jack Reynor, Stanley Tucci"]}},{"_index": "movies","_id": "mgJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"actors": ["Mark Rylance, Ruby Barnhill, Penelope Wilton,Jemaine Clement"]}},{"_index": "movies","_id": "xAJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"actors": ["Mark Ruffalo, Michael Keaton, Rachel McAdams, Liev Schreiber"]}},{"_index": "movies","_id": "3gJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"actors": ["Mark Huberman, Susan Loughnane, Steve Oram,Catherine Walker"]}},{"_index": "movies","_id": "EwJfWIYBfOmyc7Qq5giX","_score": 1,"fields": {"actors": ["Martin Freeman, Ian McKellen, Richard Armitage,Andy Serkis"]}},{"_index": "movies","_id": "MQJfWIYBfOmyc7Qq5giX","_score": 1,"fields": {"actors": ["Mark Wahlberg, Taylor Kitsch, Emile Hirsch, Ben Foster"]}},{"_index": "movies","_id": "tgJfWIYBfOmyc7Qq5giY","_score": 1,"fields": {"actors": ["Marilyn Manson, Mark Boone Junior, Sam Quartin, Niko Nicotera"]}}]}
}很显然,actors 的列表中都是以 Mar 为开头的列表。
注意:前缀查询是一个昂贵的查询 - 有时会破坏集群的稳定性。
我们不需要在字段块级别添加由 value 组成的对象。 相反,你可以创建一个缩短的版本,如下所示,为简洁起见:
GET movies/_search?filter_path=**.hits
{"_source": false,"fields": ["actors"],"query": {"prefix": {"actors.keyword": "Mar"}}
}由于我们希望在结果中找出匹配的字段,因此我们将通过在查询中添加高亮来突出显示结果。 我们向前缀查询添加一个 highlight 显示块。 这会突出一个或多个匹配的字段,如下面的清单所示。
GET movies/_search?filter_path=**.hits
{"_source": false,"query": {"prefix": {"actors.keyword": "Mar"}},"highlight": {"fields": {"actors.keyword": {}}}
}上面的搜索结果显示:
{"hits": {"hits": [{"_index": "movies","_id": "RgJfWIYBfOmyc7Qq5geX","_score": 1,"highlight": {"actors.keyword": ["<em>Mark Wahlberg, Michelle Monaghan, J.K. Simmons, John Goodman</em>"]}},{"_index": "movies","_id": "SQJfWIYBfOmyc7Qq5geX","_score": 1,"highlight": {"actors.keyword": ["<em>Mark Wahlberg, Kurt Russell, Douglas M. Griffin, James DuMont</em>"]}},{"_index": "movies","_id": "awJfWIYBfOmyc7Qq5geX","_score": 1,"highlight": {"actors.keyword": ["<em>Mario Casas, Ana Wagener, José Coronado, Bárbara Lennie</em>"]}},{"_index": "movies","_id": "ggJfWIYBfOmyc7Qq5geX","_score": 1,"highlight": {"actors.keyword": ["<em>Mark Wahlberg, Nicola Peltz, Jack Reynor, Stanley Tucci</em>"]}},{"_index": "movies","_id": "mgJfWIYBfOmyc7Qq5geX","_score": 1,"highlight": {"actors.keyword": ["<em>Mark Rylance, Ruby Barnhill, Penelope Wilton,Jemaine Clement</em>"]}},{"_index": "movies","_id": "xAJfWIYBfOmyc7Qq5geX","_score": 1,"highlight": {"actors.keyword": ["<em>Mark Ruffalo, Michael Keaton, Rachel McAdams, Liev Schreiber</em>"]}},{"_index": "movies","_id": "3gJfWIYBfOmyc7Qq5geX","_score": 1,"highlight": {"actors.keyword": ["<em>Mark Huberman, Susan Loughnane, Steve Oram,Catherine Walker</em>"]}},{"_index": "movies","_id": "EwJfWIYBfOmyc7Qq5giX","_score": 1,"highlight": {"actors.keyword": ["<em>Martin Freeman, Ian McKellen, Richard Armitage,Andy Serkis</em>"]}},{"_index": "movies","_id": "MQJfWIYBfOmyc7Qq5giX","_score": 1,"highlight": {"actors.keyword": ["<em>Mark Wahlberg, Taylor Kitsch, Emile Hirsch, Ben Foster</em>"]}},{"_index": "movies","_id": "tgJfWIYBfOmyc7Qq5giY","_score": 1,"highlight": {"actors.keyword": ["<em>Marilyn Manson, Mark Boone Junior, Sam Quartin, Niko Nicotera</em>"]}}]}
}我们之前讨论过,前缀查询在运行查询时会施加额外的计算压力。 幸运的是,有一种方法可以加快这种煞费苦心的性能不佳的前缀查询 —— 将在下一节中讨论。
加速前缀查询
这是因为引擎必须根据前缀(任何带字母的单词)得出结果。 因此,前缀查询运行起来很慢,但有一种机制可以加快它们的速度:在字段上使用 index_prefixes 参数。
我们可以在开发映射模式时在字段上设置 index_prefixes 参数。 例如,下面清单中的映射定义在我们为本练习创建的新索引 new_movies 上使用附加参数 index_prefixes 设置 title 字段(请记住,title 字段是 text 数据类型)。我们按照如下的命令来创建这个新索引:
PUT new_movies
{"settings": {"analysis": {"analyzer": {"en_analyzer": {"tokenizer": "standard","filter": ["lowercase","stop"]},"shingle_analyzer": {"type": "custom","tokenizer": "standard","filter": ["lowercase","shingle_filter"]}},"filter": {"shingle_filter": {"type": "shingle","min_shingle_size": 2,"max_shingle_size": 3}}}},"mappings": {"properties": {"title": {"type": "text","index_prefixes": {}},"actors": {"type": "text","analyzer": "en_analyzer","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"description": {"type": "text","analyzer": "en_analyzer","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"director": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"genre": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"metascore": {"type": "long"},"rating": {"type": "float"},"revenue": {"type": "float"},"runtime": {"type": "long"},"votes": {"type": "long"},"year": {"type": "long"},"title_suggest": {"type": "completion","analyzer": "simple","preserve_separators": true,"preserve_position_increments": true,"max_input_length": 50}}}
}在上面,我们为 new_movies 添加了如下的 index_prefixes 相:
"title": {"type": "text","index_prefixes": {},"analyzer": "en_analyzer","fields": {"suggest": {"type": "text","analyzer": "shingle_analyzer"}}}从清单中的代码可以看出,title 属性包含一个附加属性 index_prefixes。 这向引擎表明,在索引过程中,它应该创建带有预置前缀的字段并存储这些值。 我们使用如下的代码来写入数据到这个索引中:
POST _reindex
{"source": {"index": "movies"},"dest": {"index": "new_movies"}
}我们使用 reindex 把之前的 movies 里的文档写入到 new_movies 索引中去。
因为我们在上面显示的列表中的 title 字段上设置了 index_prefixes,所以 Elasticsearch 默认为最小字符大小 2 和最大字符大小 5 索引前缀。 这样,当我们运行前缀查询时,就不需要计算前缀了。 相反,它从存储中获取它们。
当然,我们可以更改 Elasticsearch 在索引期间尝试为我们创建的前缀的默认最小和最大大小。 这是通过调整 index_prefixes 对象的大小来完成的,如下面的清单所示。
PUT my-index-000001
{"mappings": {"properties": {"full_name": {"type": "text","index_prefixes": {"min_chars" : 1,"max_chars" : 10}}}}
}在清单中,我们要求引擎预先创建最小和最大字符长度分别为 4 个和 10 个字母的前缀。 注意,min_chars 必须大于 0,max_chars 应小于 20 个字符。 这样,我们就可以在索引过程中自定义 Elasticsearch 应该预先创建的前缀。
我们接着可以对 title 字段做类似下面的搜索:
GET new_movies/_search?filter_path=**.hits
{"_source": false,"fields": ["title"], "query": {"prefix": {"title": {"value": "ga"}}}
}在上面的搜索中,我们查询 titile 字段里 含有 ga 为开头的文档。上述搜索返回如下的结果:
{"hits": {"hits": [{"_index": "new_movies","_id": "BAJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"title": ["Guardians of the Galaxy"]}},{"_index": "new_movies","_id": "jQJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"title": ["The Great Gatsby"]}},{"_index": "new_movies","_id": "lQJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"title": ["Ah-ga-ssi"]}},{"_index": "new_movies","_id": "mwJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"title": ["The Hunger Games"]}},{"_index": "new_movies","_id": "sAJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"title": ["Beyond the Gates"]}},{"_index": "new_movies","_id": "ygJfWIYBfOmyc7Qq5geX","_score": 1,"fields": {"title": ["The Imitation Game"]}},{"_index": "new_movies","_id": "jQJfWIYBfOmyc7Qq5giY","_score": 1,"fields": {"title": ["Whisky Galore"]}},{"_index": "new_movies","_id": "nAJfWIYBfOmyc7Qq5giY","_score": 1,"fields": {"title": ["The Hunger Games: Mockingjay - Part 2"]}},{"_index": "new_movies","_id": "1QJfWIYBfOmyc7Qq5giY","_score": 1,"fields": {"title": ["Sherlock Holmes: A Game of Shadows"]}},{"_index": "new_movies","_id": "2gJfWIYBfOmyc7Qq5giY","_score": 1,"fields": {"title": ["American Gangster"]}}]}
}很显然,返回的结果里都含有 "ga" 为开头的单词。
相关文章:

Elasticsearch: Prefix queries - 前缀查询
Prefix queries 被用于在查询时返回在提供的字段中包含特定前缀的文档。有时我们可能想使用前缀查询单词,例如 Leonardo 的 Leo 或 Marlon Brando、Mark Hamill 或 Martin Balsam 的 Mar。 Elasticsearch 提供了一个前缀查询,用于获取匹配单词开头部分&a…...

GEE学习笔记 七十七:GEE学习方法简介
这是一篇关于学习方法的思考探索,当然我不会大篇文章介绍什么学习方法(因为我也不是这方面的专家?),这个只是总结一下我是如何学习GEE以及在学习中遇到问题时如何解决问题的。我写这篇文章的目的就是在和一些学习GEE的新同学接触…...
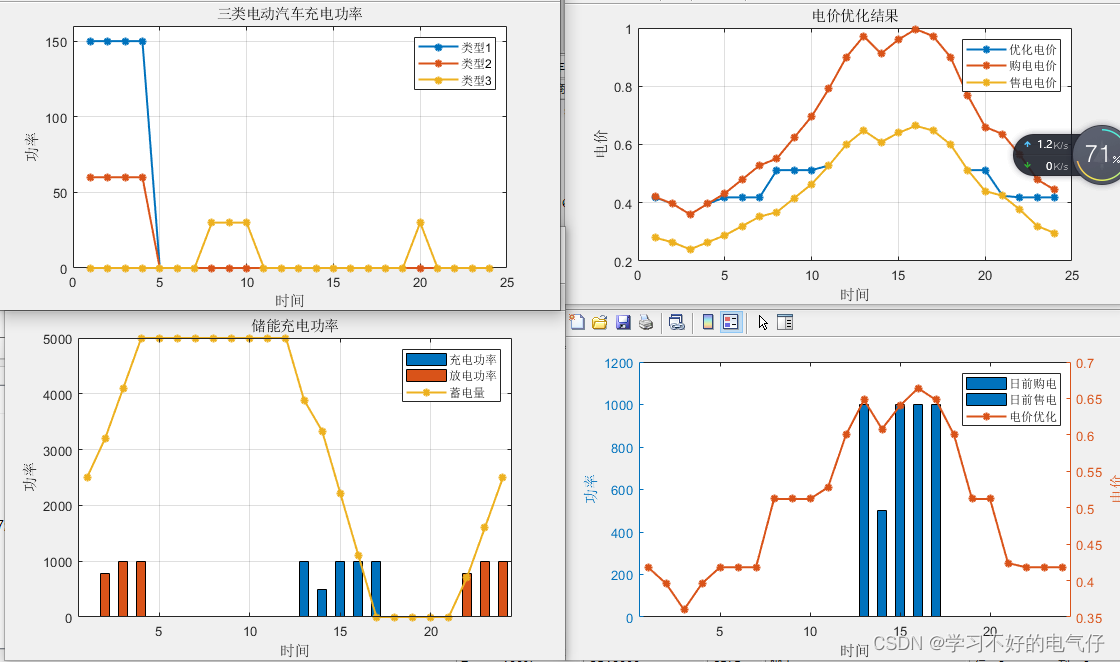
20基于主从博弈的智能小区代理商定价策略及电动汽车充电管理MATLAB程序
参考文档:《基于主从博弈的智能小区代理商定价策略及电动汽车充电管理》基本复现仿真平台:MATLABCPLEX/gurobi平台优势:代码具有一定的深度和创新性,注释清晰,非烂大街的代码,非常精品!主要内容…...
长按power键,点击重启按钮,系统重启流程一
1.有可能会涉及到如下文件 2.文件流程...

数据的TCP分段和IP分片
本文简述下TCP分段和IP分片的区别与联系。 我们知道,用户空间的数据拷贝到内核空间的TCP发送缓冲区(这个是一个结构体,叫sk_buffer,简称skb)后就由内核网络协议栈做后续的封装和发送处理了,用户无需考虑下…...
HTML中嵌入B站视频
HTML中嵌入B站视频 在网页中实现一个HTML播放器需要先从b站获取视频嵌入代码, 以前嵌入代码可以从视频分享那里拿到, 现在好像不行了 必须是自己投稿的视频, 从投稿管理页面才能找到 复制嵌入代码 建一个.html文件, 放入下面代码 <!DOCTYPE html> <html><head…...
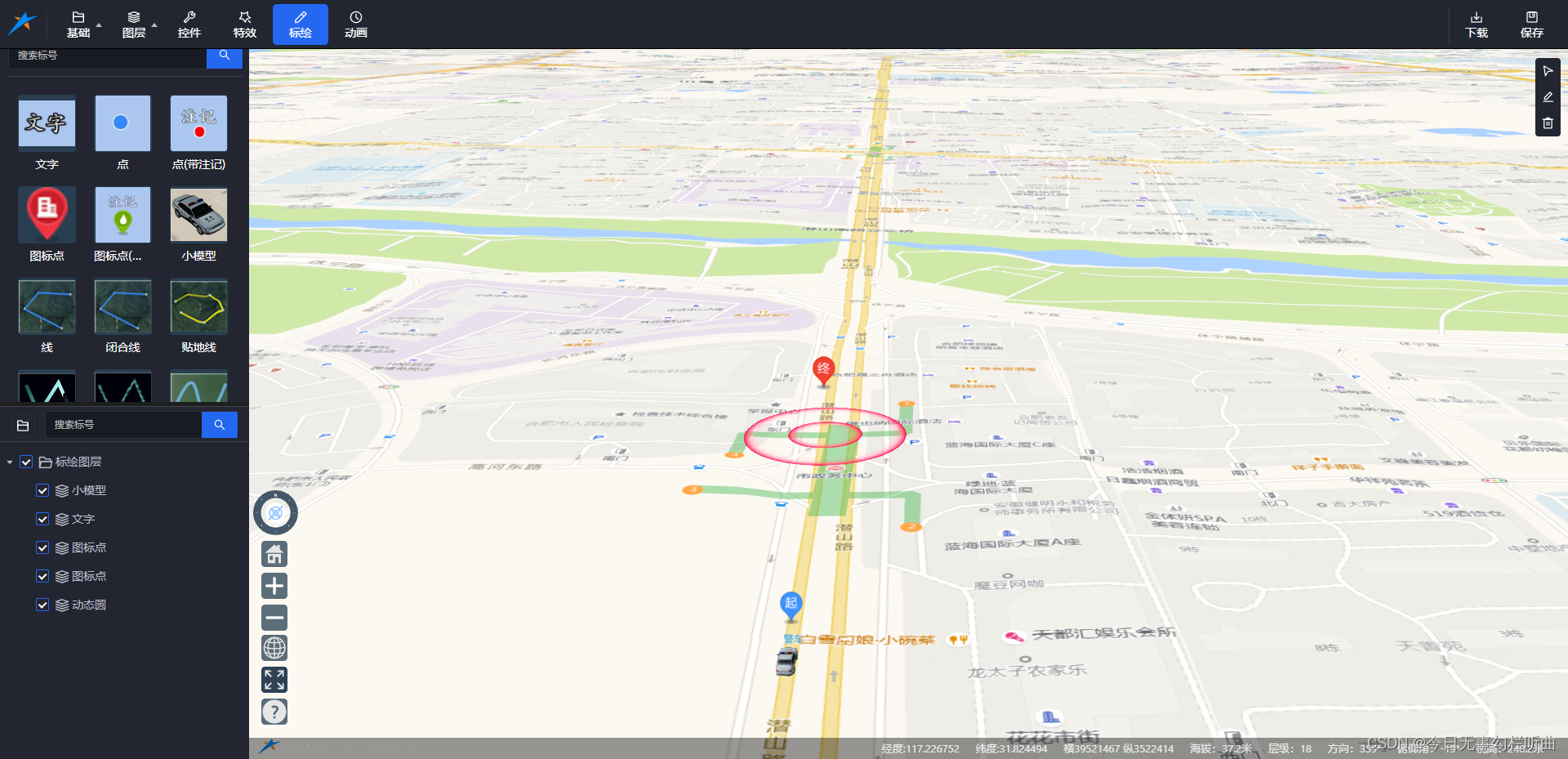
Mars3D Studio 的使用方法
Mars3D Studio的使用 1、介绍: mars3d Studio是mars3d研发团队于近期研发上线的一款 场景可视化编辑平台。拥有资源存档、团队协作、定制材质等丰富的功能。可以实现零代码构建一个可视化三维场景。 2、功能介绍 (1)数据上传:…...
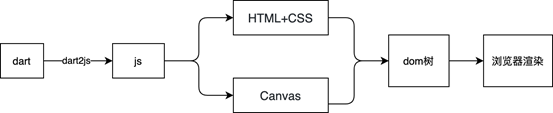
Flutter For Web实践
1 什么是Flutter Flutter是Google开源的一套UI工具包,帮助开发者通过一套代码库高效构建多平台精美应用,支持移动APP、web、桌面和嵌入式平台。Flutter和其他的跨平台解决方案的实现方式上有比较大的差异。 我们以React Native(下文简称RN&…...

【神级Python代码】作为技术xiao白如何制作一款超炫酷的黑客主题代码雨?牛逼就完了。(源码分享学习)
前言 哈喽,我是木子,今天给大家制作一款超级炫酷的代码啦。 提到《黑K帝国》,字符雨可谓是让人印象深刻。 所有文章完整的素材源码都在👇👇 粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。 …...

供应链挑战迎刃而解!桑迪亚国家实验室使出“量子杀手锏”
桑迪亚国家实验室的科学家Alicia Magann(右),Kenneth Rudinger(左上),Mohan Sarovar(左下)和Matthew Grace(未附图)开发了基于反馈的量子优化算法(…...
java程序设计-ssm博客管理系统
博客管理系统是一个用于创建、管理和发布博客文章的应用程序。它通常包括一个后台管理界面,用于管理用户、文章、评论、标签等数据。同时,它还包括一个前端界面,用于展示博客文章并提供交互功能,例如评论和分享。 博客管理系统可…...

从0到1一步一步玩转openEuler--17 openEuler DNF(YUM)检查更新
文章目录17.1 检查更新17.2 升级17.3 更新所有的包和它们的依赖DNF是一款Linux软件包管理工具,用于管理RPM软件包。DNF可以查询软件包信息,从指定软件库获取软件包,自动处理依赖关系以安装或卸载软件包,以及更新系统到最新可用版本…...
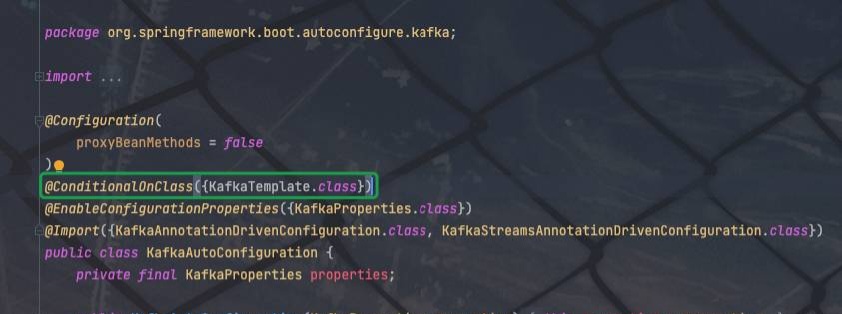
SpringBoot-自动配置-@Import注解与@EnableAutoConfiguration注解
Import注解 Enable* 底层依赖于 Import 注解导入一些类,使用 Import 导入的类会被 Spring 加载到 IOC 容器中Import 提供了4种用法: 1.导入Bean2.导入配置类3.导入ImportSelector实现类;一般用于加载配置文件中的类4.导入ImportBeanDefinitio…...

【笔记】C#一维数组、多维数组和交错数组的区别总结
文章目录前言数组的概念1,一维数组:2,多维数组:3,交错数组:区别总结结语前言 😄大家好,我是writer桑, 这是自己整理的 C# 数组笔记,方便自己学习的同时分享出…...
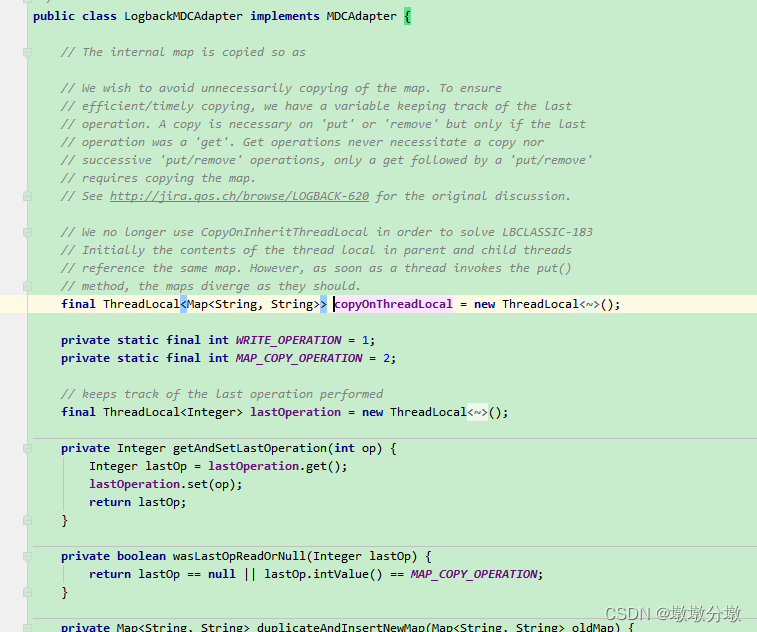
【SpringBoot】分布式日志跟踪—通过MDC实现全链路调用日志跟踪
一.MDC 1.MDC介绍 MDC(Mapped Diagnostic Context,映射调试上下文)是 log4j 和 logback 提供的一种方便在多线程场景下记录日志的功能。MDC 可以看成是一个与当前线程绑定的Map,可以往其中添加键值对。MDC 中包含的内容可以被同…...

【设计模式】创建型模式
简单工厂模式 系列综述: xxxxxxxxx 文章目录对象创建型模式简单(静态)工厂模式工厂方法模式参考博客😊点此到文末惊喜↩︎ 对象创建型模式 简单(静态)工厂模式 抽象原理 抽象产品基类 :定义了…...
Spark Catalyst 查询优化器原理
这里我们讲解一下SparkSQL的优化器系统Catalyst,Catalyst本质就是一个SQL查询的优化器,而且和 大多数当前的大数据SQL处理引擎设计基本相同(Impala、Presto、Hive(Calcite)等)。了解Catalyst的SQL优化流程&…...
贝叶斯分析法在市场调研中的应用
一、市场调研的需求场景 在营销活动的用研调研时,我们经常会去问用户在不同平台的品类付费情况,以对比大促期间本品和竞品分别在哪些品类上具有市场优势,他们之间的差距具体在哪里、差距有多大。假如根据调研问卷结果,我们知道拼多多用户有30%的人在大促购买生鲜类,而淘宝…...
JavaEE——MyBatis将查询结果集封装进POJO实体类
简单介绍 在之前的我们比较详细的介绍过MyBatis的配置信息的时候,在SQL映射文件中说过我们可以直接将结果集映射到我们的POJO实体类中,省去了我们自己处理查询结果集的时间和代码,接下来我们就来演示将单条数据和多条数据映射到我们POJO实体…...

C++11 包装器function
文章首发公众号:iDoitnow C提供了多个包装器,它们主要是为了给其他编程接口提供更一致或更合适的接口。C11提供了多个包装器,这里我们重点了解一下包装器function。 对于function, C 参考手册给出的定义为: 类模板 std::function…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...