求职季哪种 Python 程序员能拿高薪?

本文以Python爬虫、数据分析、后端、数据挖掘、全栈开发、运维开发、高级开发工程师、大数据、机器学习、架构师这10个岗位,从拉勾网上爬取了相应的职位信息和任职要求,并通过数据分析可视化,直观地展示了这10个职位的平均薪资和学历、工作经验要求。
文章很长,耐心观看。
01
爬虫准备
1、先获取薪资和学历、工作经验要求
由于某网数据加载是动态加载的,需要我们分析。分析方法如下:
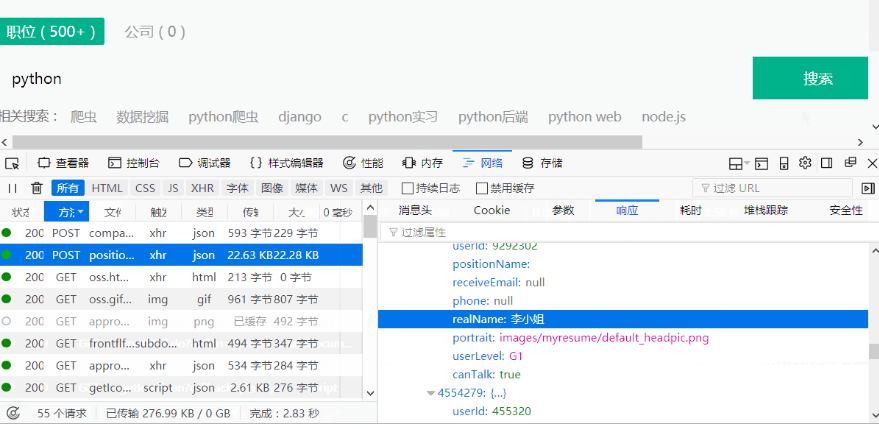
我们发现网页内容是通过post请求得到的,返回数据是json格式,那我们直接拿到json数据即可。
我们只需要薪资和学历、工作经验还有单个招聘信息,返回json数据字典中对应的英文为:positionId,salary, education, workYear(positionId为单个招聘信息详情页面编号)。相关操作代码如下:
- 文件存储:
def file_do(list_info):# 获取文件大小file_size = os.path.getsize(r'G:\lagou_anv.csv')if file_size == 0:# 表头name = ['ID','薪资', '学历要求', '工作经验']# 建立DataFrame对象file_test = pd.DataFrame(columns=name, data=list_info)# 数据写入file_test.to_csv(r'G:\lagou_anv.csv', encoding='gbk', index=False)else:with open(r'G:\lagou_anv.csv', 'a+', newline='') as file_test:# 追加到文件后面writer = csv.writer(file_test)# 写入文件writer.writerows(list_info)
- 基本数据获取:
# 1. post 请求 url
req_url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# 2.请求头 headers
headers = {'Accept': 'application/json,text/javascript,*/*;q=0.01','Connection': 'keep-alive','Cookie': '你的Cookie值,必须加上去','Host': 'www.lagou.com','Referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=','User-Agent': str(UserAgent().random),
}def get_info(headers):# 3.for 循环请求(一共30页)for i in range(1, 31):# 翻页data = {'first': 'true','kd': 'Python爬虫','pn': i}# 3.1 requests 发送请求req_result = requests.post(req_url, data=data, headers=headers)req_result.encoding = 'utf-8'print("第%d页:"%i+str(req_result.status_code))# 3.2 获取数据req_info = req_result.json()# 定位到我们所需数据位置req_info = req_info['content']['positionResult']['result']print(len(req_info))list_info = []# 3.3 取出具体数据for j in range(0, len(req_info)):salary = req_info[j]['salary']education = req_info[j]['education']workYear = req_info[j]['workYear']positionId = req_info[j]['positionId']list_one = [positionId,salary, education, workYear]list_info.append(list_one)print(list_info)# 存储文件file_do(list_info)time.sleep(1.5)
- 运行结果:

2、根据获取到的positionId 来访问招聘信息详细页面
- 根据
positionId还原访问链接:
position_url = []
def read_csv():# 读取文件内容with open(r'G:\lagou_anv.csv', 'r', newline='') as file_test:# 读文件reader = csv.reader(file_test)i = 0for row in reader:if i != 0 :# 根据positionID补全链接url_single = "https://www.lagou.com/jobs/%s.html"%row[0]position_url.append(url_single)i = i + 1print('一共有:'+str(i-1)+'个')print(position_url)
- 访问招聘信息详情页面,获取职位描述(岗位职责和岗位要求)并清理数据:
def get_info():for position_url in position_urls:work_duty = ''work_requirement = ''response00 = get_response(position_url,headers = headers)time.sleep(1)content = response00.xpath('//*[@id="job_detail"]/dd[2]/div/p/text()')# 数据清理j = 0for i in range(len(content)):content[i] = content[i].replace('\xa0',' ')if content[i][0].isdigit():if j == 0:content[i] = content[i][2:].replace('、',' ')content[i] = re.sub('[;;.0-9。]','', content[i])work_duty = work_duty+content[i]+ '/'j = j + 1elif content[i][0] == '1' and not content[i][1].isdigit():breakelse:content[i] = content[i][2:].replace('、', ' ')content[i] = re.sub('[、;;.0-9。]','',content[i])work_duty = work_duty + content[i]+ '/'m = i# 岗位职责write_file(work_duty)print(work_duty)# 数据清理j = 0for i in range(m,len(content)):content[i] = content[i].replace('\xa0',' ')if content[i][0].isdigit():if j == 0:content[i] = content[i][2:].replace('、', ' ')content[i] = re.sub('[、;;.0-9。]', '', content[i])work_requirement = work_requirement + content[i] + '/'j = j + 1elif content[i][0] == '1' and not content[i][1].isdigit():# 控制范围breakelse:content[i] = content[i][2:].replace('、', ' ')content[i] = re.sub('[、;;.0-9。]', '', content[i])work_requirement = work_requirement + content[i] + '/'# 岗位要求write_file2(work_requirement)print(work_requirement)print("-----------------------------")
- 运行结果:


3、四种图可视化数据+数据清理方式
- 矩形树图:
# 1.矩形树图可视化学历要求
from pyecharts import TreeMap
education_table = {}
for x in education:education_table[x] = education.count(x)
key = []
values = []
for k,v in education_table.items():key.append(k)values.append(v)data = []
for i in range(len(key)) :dict_01 = {"value": 40, "name": "我是A"}dict_01["value"] = values[i]dict_01["name"] = key[i]data.append(dict_01)
tree_map = TreeMap("矩形树图", width=1200, height=600)
tree_map.add("学历要求",data, is_label_show=True, label_pos='inside')
- 玫瑰饼图:
# 2.玫瑰饼图可视化薪资
import re
import math
'''
# 薪水分类
parameter : str_01--字符串原格式:20k-30k
returned value : (a0+b0)/2 --- 解析后变成数字求中间值:25.0
'''
def assort_salary(str_01):reg_str01 = "(\d+)"res_01 = re.findall(reg_str01, str_01)if len(res_01) == 2:a0 = int(res_01[0])b0 = int(res_01[1])else :a0 = int(res_01[0])b0 = int(res_01[0])return (a0+b0)/2from pyecharts import Pie
salary_table = {}
for x in salary:salary_table[x] = salary.count(x)key = ['5k以下','5k-10k','10k-20k','20k-30k','30k-40k','40k以上']
a0,b0,c0,d0,e0,f0=[0,0,0,0,0,0]for k,v in salary_table.items():ave_salary = math.ceil(assort_salary(k))print(ave_salary)if ave_salary < 5:a0 = a0 + velif ave_salary in range(5,10):b0 = b0 +velif ave_salary in range(10,20):c0 = c0 +velif ave_salary in range(20,30):d0 = d0 +velif ave_salary in range(30,40):e0 = e0 +velse :f0 = f0 + v
values = [a0,b0,c0,d0,e0,f0]pie = Pie("薪资玫瑰图", title_pos='center', width=900)
pie.add("salary",key,values,center=[40, 50],is_random=True,radius=[30, 75],rosetype="area",is_legend_show=False,is_label_show=True)
- 普通柱状图:
# 3.工作经验要求柱状图可视化
from pyecharts import Bar
workYear_table = {}
for x in workYear:workYear_table[x] = workYear.count(x)
key = []
values = []
for k,v in workYear_table.items():key.append(k)values.append(v)
bar = Bar("柱状图")
bar.add("workYear", key, values, is_stack=True,center= (40,60))
- 词云图:
import jieba
from pyecharts import WordCloud
import pandas as pd
import re,numpystopwords_path = 'H:\PyCoding\Lagou_analysis\stopwords.txt'
def read_txt():with open("G:\lagou\Content\\ywkf_requirement.txt",encoding='gbk') as file:text = file.read()content = text# 去除所有评论里多余的字符content = re.sub('[,,。. \r\n]', '', content)segment = jieba.lcut(content)words_df = pd.DataFrame({'segment': segment})# quoting=3 表示stopwords.txt里的内容全部不引用stopwords = pd.read_csv(stopwords_path, index_col=False,quoting=3, sep="\t", names=['stopword'], encoding='utf-8')words_df = words_df[~words_df.segment.isin(stopwords.stopword)]words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False)test = words_stat.head(200).valuescodes = [test[i][0] for i in range(0, len(test))]counts = [test[i][1] for i in range(0, len(test))]wordcloud = WordCloud(width=1300, height=620)wordcloud.add("必须技能", codes, counts, word_size_range=[20, 100])wordcloud.render("H:\PyCoding\Lagou_analysis\cloud_pit\ywkf_bxjn.html")
02
Python爬虫岗位




关键词解析:
- 学历:本科
- 工作月薪:10k-30k
- 工作经验:1-5年
- 技能:分布式、多线程、框架、Scrapy、算法、数据结构、数据库
综合:爬虫这个岗位在学历要求上比较放松,大多数为本科即可,比较适合想转业的老哥小姐姐,学起来也不会特别难。而且薪资待遇上也还算比较优厚,基本在10k以上。不过唯一对工作经验要求还是比较高的,有近一半的企业要求工作经验要达到3年以上。
03
Python数据分析岗位




关键词解析:
- 学历:本科(硕士比例有所增高)
- 工作月薪:10k-30k
- 工作经验:1-5年
- 技能:SAS、SPSS、Hadoop、Hive、数据库、Excel、统计学、算法
综合:数据分析这个岗位在学历要求上比爬虫要求稍微高一些,硕士比例有所提升,专业知识上有一定要求。薪资待遇上也还算比较优厚,基本在10k以上,同时薪资在30k-40k的比例也有所上升。对工作经验要求还是比较高,大部分的企业要求工作经验要达到3年以上。
04
Python后端岗位
学历要求
工作月薪
工作经验要求
后端技能




关键词解析:
- 学历:本科
- 工作月薪:10k-30k
- 工作经验:3-5年
- 技能:Flask、Django、Tornado、Linux、MySql、Redis、MongoDB、TCP/IP、数学(哈哈)
综合:web后端这个岗位对学历要求不高,但专业知识上有很大要求,得会Linux操作系统基本操作、三大主流数据库的使用、以及三大基本web框架的使用等计算机相关知识,总体来说难道还是比较大。薪资待遇上也比较优厚,基本在10k以上,同时薪资在30k-40k的比例也有近20%。对工作经验要求还是比较高,大部分的企业要求工作经验要达到3年以上。
05
Python数据挖掘岗位




关键词解析:
- 学历:本科(硕士)
- 工作月薪:20k-40k
- 工作经验:3-5年
- 技能:学历(hhh)、Hadoop、Spark、MapReduce、Scala、Hive、聚类、决策树、GBDT、算法
综合:数据挖掘这个岗位,在学历要求是最高的,虽然还是本科居多,但硕士比例明显增加,还有公司要求博士学历。在专业知识上也有很大要求,得会Linux操作系统基本操作、大数据框架Hadoop、Spark以及数据仓库Hive的使用等计算机相关知识,总体来说难道还是比较大。薪资待遇上特别优厚,基本在20k以上,薪资在30k-40k的比例也有近40%,对工作经验要求还是比较高,大部分的企业要求工作经验要达到3年以上。
06
Python全栈开发岗位




关键词解析:
- 学历:本科
- 工作月薪:10k-30k
- 工作经验:3-5年
- 技能:测试、运维、管理、开发、数据结构、算法、接口、虚拟化、前端
综合:全栈开发这个岗位什么都要懂些,什么都要学些,在学历要求上并不太高,本科学历即可,在专业知识上就不用说了,各个方面都得懂,还得理解运用。薪资待遇上也还可以,基本在10k以上,薪资在30k-40k的比例也有近20%。对工作经验要求还是比较高,大部分的企业要求工作经验要达到3年以上。总体来说,就我个人而言会觉得全栈是个吃力多薪水少的岗位。
07
Python运维开发岗位




关键词解析:
- 学历:本科
- 工作月薪:10k-30k
- 工作经验:3-5年
- 技能:SVN、Git、Linux、框架、shell编程、mysql,redis,ansible、前端框架
综合:运维开发这个岗位在学历要求上不高,除开占一大半的本科,就是专科了。工作经验上还是有一些要求,大多数要求有3-5年工作经验。从工资上看的话,不高也不低,20k以上也占有62%左右。要学习的东西也比较多,前端、后端、数据库、操作系统等等。
08
Python高级开发工程师岗位




关键词解析:
- 学历:本科
- 工作月薪:20k左右
- 工作经验:3-5年
- 技能:WEB后端、MySQL、MongoDB、Redis、Linux系统(CentOS)、CI/CD 工具、GitHub
综合:高级开发工程师这个岗位在学历要求上与运维开发差不多,薪资也相差不大,22%以上的企业开出了30k以上的薪资,65%左右企业给出20k以上的薪资。当然,对工作经验上还是要求较高,有近一半的企业要求工作经验要达到3年以上。
09
Python大数据岗位




关键词解析:
- 学历:本科(硕士也占比很大)
- 工作月薪:30k以上
- 工作经验:3-5年
- 技能:前端开发、 MySQL、Mongo、Redis、Git
、Flask、Celery、Hadoop/HBase/Spark/Hive、Nginx
综合:现在是大数据时代,大数据这个岗位也是相当火热,在学历要求上几乎与运维开发一模一样。当然,可能数据上出现了巧合,本科居多,工作经验上1-5年占据一大半,薪资上也基本上在20k以上,该岗位薪资在20k以上的企业占了55%左右。
10
Python机器学习岗位




关键词解析:
- 学历:本科(硕士也占比很大)
- 工作月薪:30k以上
- 工作经验:3-5年
- 技能:Machine Learning,Data Mining,Algorithm
研发,算法,Linux,决策树,TF,Spark+MLlib,Cafe
综合:机器学习这个岗位在学历要求上比较严格,虽然看起来是本科居多,但对于刚毕业或毕业不久的同学,如果只是个本科,应聘还是很有难度的。当然机器学习岗位薪资特高,60%在30k以上,近90%在20k以上,97%在10k以上。除开对学历要求比较高外,对工作经验要求也比较高,有近一半的企业要求工作经验要达到3年以上。
11
Python架构师岗位




关键词解析:
- 学历:本科
- 工作月薪:30k以上
- 工作经验:5-10年
- 技能:Flask,Django,MySQL,Redis,MongoDB,Hadoop,Hive,Spark,ElasticSearch,Pandas,Spark/MR,Kafka/rabitmq
综合:架构师这个岗位单从学历上看不出什么来,但在薪资上几乎与机器学习一样,甚至比机器学习还要高,机器学习中月薪40k以上的占23.56%,架构师中月薪40k以上的占30.67%。在学历要求上比机器学习要略低,本科居多,但在工作经验上一半以上的企业要求工作经验在5-10年。在必要技能上也要求特别严格,比之前说过的全栈开发师有过之而无不及。
看着这月薪,我是超级想去了,你呢?
12
写在最后
从上文可以看出,Python相关的各个岗位薪资还是不错的,基本上所有岗位在10k以上的占90%,20k以上的也基本都能占60%左右。而且学历上普遍来看,本科学历占70%以上。唯一的是需要工作经验,一般得有个3-5年工作经验,也就是如果24岁本科毕业,27岁就有很大机会拿到月薪20k以上。有没有很心动?
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

👉Python必备开发工具👈
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉100道Python练习题👈
检查学习结果。

👉面试刷题👈

资料领取
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码输入“领取资料” 即可领取

相关文章:
求职季哪种 Python 程序员能拿高薪?
本文以Python爬虫、数据分析、后端、数据挖掘、全栈开发、运维开发、高级开发工程师、大数据、机器学习、架构师这10个岗位,从拉勾网上爬取了相应的职位信息和任职要求,并通过数据分析可视化,直观地展示了这10个职位的平均薪资和学历、工作经…...

如何选择好的IB课程学校?
在上海除了拼中考,你还可以走一条更有“选择权”的路——国际化学校! 然而选择学校时,让家长最头痛的事情,莫过于为孩子选择什么样的国际化课程。 今天我们来聊聊IB课程! 三大主流国际课程中,被公认含金量最…...

2023美赛ABCDEF题思路+参考文献+代码
选题建议、ABCDEF题参考文献、ABCDEF题思路(后续更新视频和代码)、D题数据、数据集及处理方式已更新,其他日内更新。下文包含:2023年美国大学生数学建模竞赛(以下简称美赛)A - F题思路解析、选题建议、代码…...
DataEase 制作数据可视化大屏经验分享
前言 DataEase 简介 DataEase 是开源的数据可视化分析工具,帮助用户快速分析数据并洞察业务趋势,从而实现业务的改进与优化。DataEase 支持丰富的数据源连接,能够通过拖拉拽方式快速制作图表,并可以方便地与他人分享。 更多详细介…...

前端基础-2day
前端基础 这里写目录标题前端基础div和span标签div 标签span标签列表有序列表无序列表自定义列表图片超链接标签表格 table表格合并表单标签表单控键属性div和span标签 div 标签 没有具体的含义,用于划分页面区域,独占一行 快捷键:div{}*3 …...

在线一键JS混淆还原
当今,随着互联网的发展,越来越多的网站开始使用JavaScript来实现动态交互和用户体验。但是,由于JavaScript代码的开放性和易于复制,网站管理员需要采取一些措施来保护他们的代码。这就是JavaScript混淆工具产生的原因。 jsjiami.…...

Java基本语法
目录 一、注释方式 1、单行注释 // 2、多行注释 /*...*/ 3、文档注释 /**....*/ 二、标识符和关键字 三、数据类型 拓展及面试题讲解 1、整数拓展 进制 二进制0b 八进制0 十六进制0x 2、字符拓展 编码Unicode表 2字节 0~65536 3、字符串拓展 4、布尔值拓展 一、注释方式…...

什么表单设计工具能快速提升办公效率?
在信息化快速发展的年代,谁能掌握更先进的技术,谁就能拥有更广阔的发展前景。在以前的办公环境中,传统的表单制作工具占据了主流地位,随着办公自动化的快速发展,传统表单工具的弊端也暴露出来了,采用更先进…...
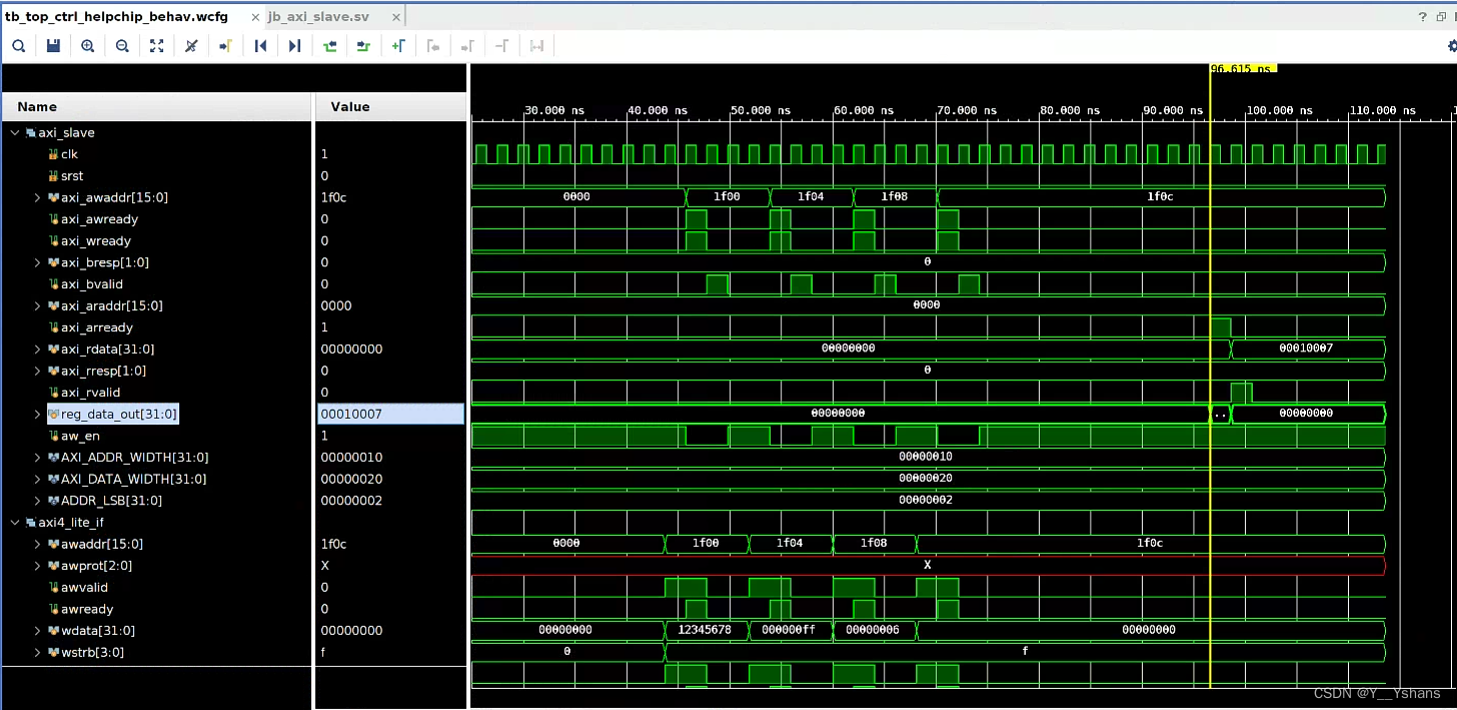
SystemVerilog——Axi4Lite_To_Localbus
摘要:用SystemVerilog对Axi4转localbus进行编写与仿真 如果需要从PS端对PL进行寄存器的读写操作,从znyq M_AXI_HPM_FPD出来,经过axi_interconnect 模块分出多个通道(不同的地址),经过一个axi_slave模块&am…...

硬件_IMX6ULL的LCD控制器
硬件_IMX6ULL的LCD控制器 文章目录硬件_IMX6ULL的LCD控制器一、 LCD控制器模块介绍1.1 硬件框图1.2 数据传输与处理1.3 时序控制二、 LCD控制器寄存器简介2.1 LCDIF_CTRL寄存器2.2 LCDIF_CTRL1寄存器2.3 LCDIF_TRANSFER_COUNT寄存器2.4 LCDIF_VDCTRL0寄存器2.5 LCDIF_VDCTRL1寄…...

ICLR 2022—你不应该错过的 10 篇论文(下)
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 ICLR 2023已经放榜,但是今天我们先来回顾一下去年的ICLR 2022! ICLR 2022将于2022年 4 月 25 日星期一至 4 月 29 日星期五在线举行(连续第三年!&#x…...

国内外优秀程序员的私域博客大全
文章目录 国内外优秀程序员的私域博客大全**国内的优秀程序员****国外的优秀程序员**结语国内外优秀程序员的私域博客大全 国内的优秀程序员 1、风雪之隅-惠新宸 擅长领域:PHP、PECL等 Laruance惠新宸——国内最有影响力的PHP技术专家,PHP开发组核心成员, Zend顾问, PHP7及…...

【C++ Primer Plus】第六章:分支语句和逻辑运算符
文章目录第六章 分支语句和逻辑运算符6.1 字符函数库cctype6.2 ?:运算符6.3 读取数字的输入6.4 cin的处理过程char类型intdoublechar数组使用char数组来存储输入6.5 写入到文本文件中6.6 读取文本文件6.7 总结第六章 分支语句和逻辑运算符 6.1 字符函数库cctype C从C语言继承…...

堡垒机的主要功能是什么?为什么需要堡垒机?
堡垒机是一种用于管理和控制服务器的工具,其主要功能是为管理人员提供安全、便捷的远程管理和操作方式。为什么需要堡垒机呢?下面我们将详细阐述堡垒机的主要功能和必要性。 一、堡垒机的主要功能: ①、用户认证和授权管理:堡垒机…...
记录spring中Transactional事务注解失效的六个场景
记录spring中Transactional事务注解失效的六个场景 方法内的自调用 原因:通过this内部调用其他带有Transactional注解的方法,是通过this进行调用,并没有通过cglib代理对象进行调用,导致方法未被增强导致无法检测内部事务 解决方…...

【23种设计模式】行为型模式详细介绍(下)
前言 本文为 【23种设计模式】行为型模式 相关内容介绍,下边将对访问者模式,模板模式,策略模式,状态模式,观察者模式,备忘录模式,中介者模式,迭代器模式,解释器模式&…...
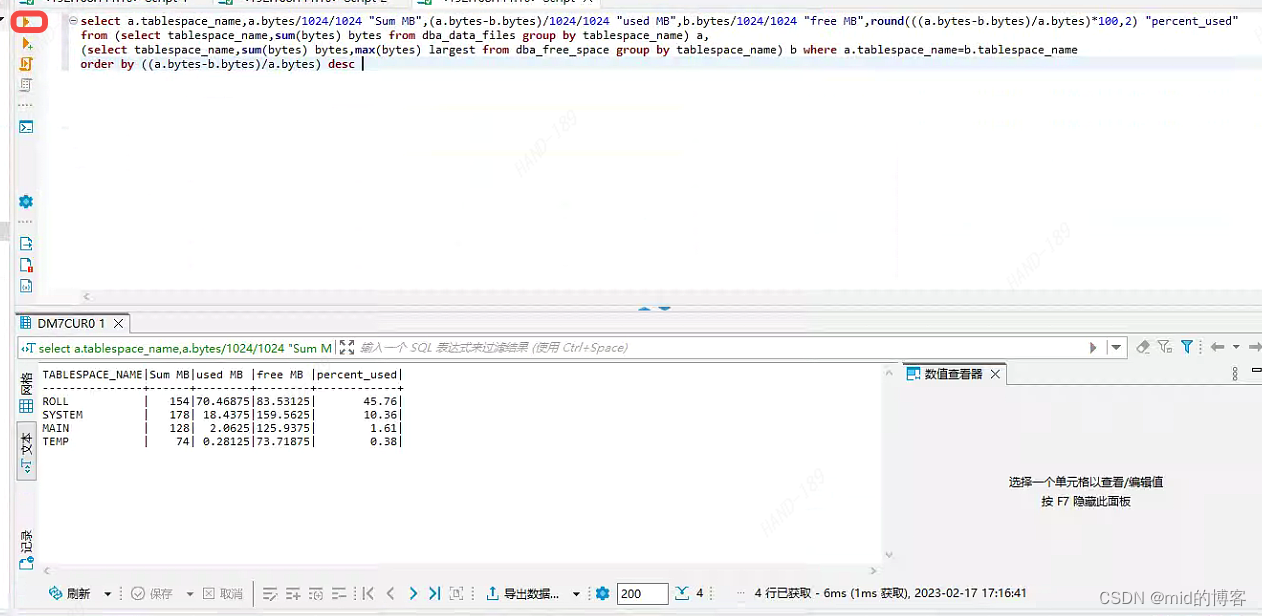
dbeaver工具连接达梦数据库
、一 概述 DBeaver 是一个基于 Java 开发,免费开源的通用数据库管理和开发,DBeaver 采用 Eclipse 框架开发,支持插件扩展,并且提供了许多数据库管理工具:ER 图、数据导入/导出、数据库比较、模拟数据生成等࿰…...
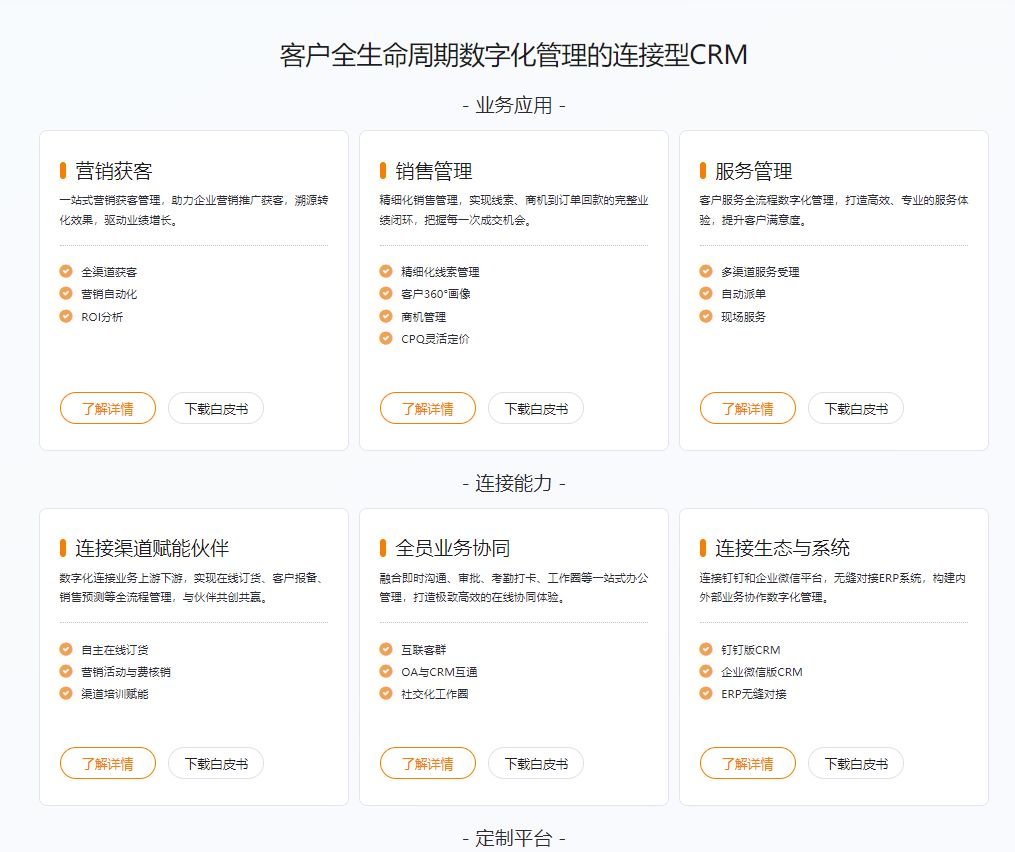
比Teambition、Worktile 更适合研发团队的几大工具盘点
Worktile 和 Teambitiom 哪个更好?两个产品各有特点。1.Teambition 优势:操作简单、个人版永不收费、更适合小型团队;2.Teambition 劣势:无法满足中大型团队复杂的项目管理、自定义能力弱、无法与钉钉以外的工具打通等;…...

matlab图像处理常用功能以及函数
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、matlab灰度处理相关二、形态学的一些函数1.腐蚀2.膨胀3.开运算4.闭运算三、其他一些可能会用到的方法1.使用hough进行直线检测2.圆检测3.闭合形状检测4.寻找…...

eBPF 之 ProgramType、AttachType和InputContext
1. ProgramType 定义定义在 include/uapi/linux/bpf.h 文件中,不同 Linux 版本会有变化,以下是 Linux 5.19 版本定义:enum bpf_prog_type {BPF_PROG_TYPE_UNSPEC,BPF_PROG_TYPE_SOCKET_FILTER,BPF_PROG_TYPE_KPROBE,BPF_PROG_TYPE_SCHED_CLS,…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...
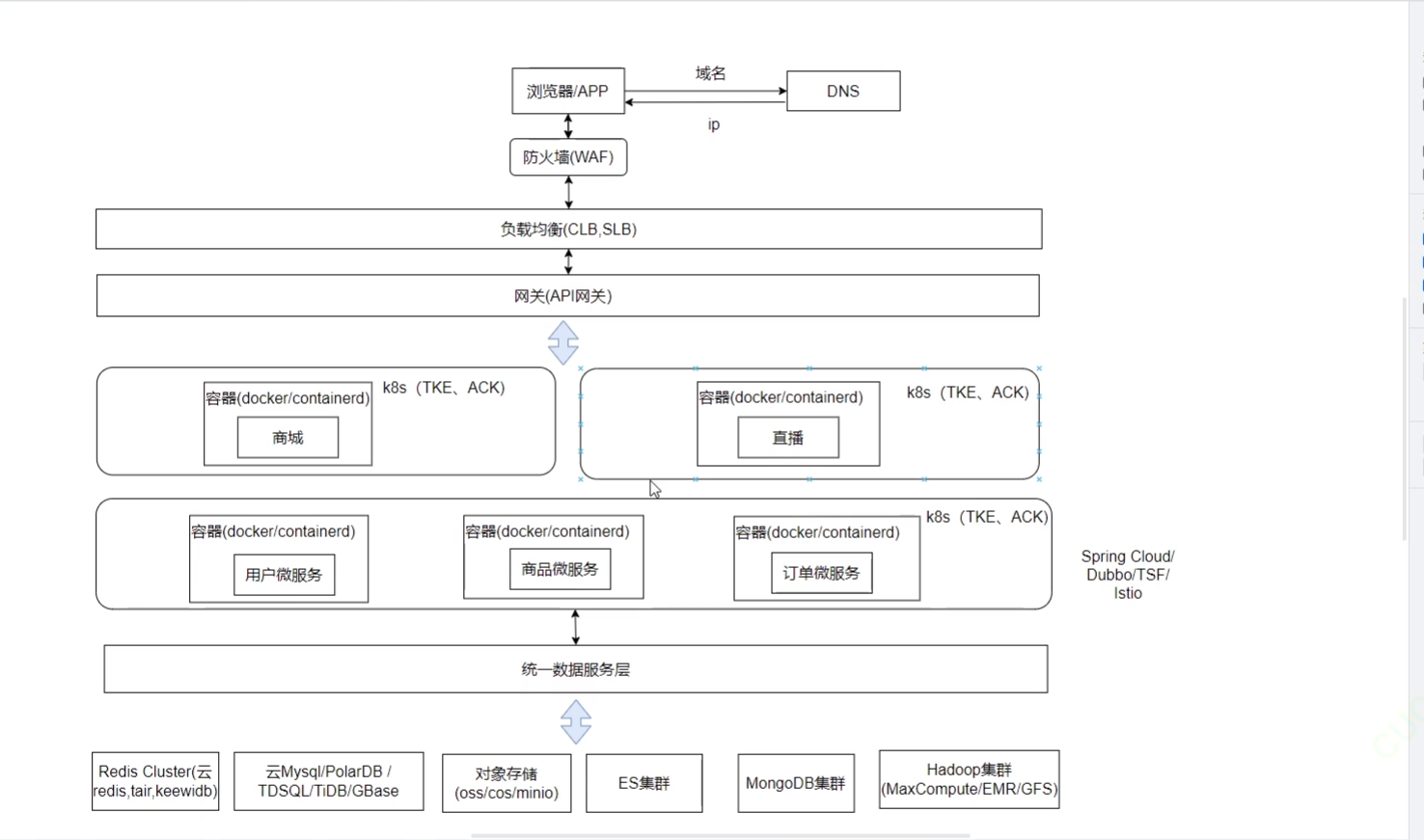
《Docker》架构
文章目录 架构模式单机架构应用数据分离架构应用服务器集群架构读写分离/主从分离架构冷热分离架构垂直分库架构微服务架构容器编排架构什么是容器,docker,镜像,k8s 架构模式 单机架构 单机架构其实就是应用服务器和单机服务器都部署在同一…...

【HarmonyOS 5】鸿蒙中Stage模型与FA模型详解
一、前言 在HarmonyOS 5的应用开发模型中,featureAbility是旧版FA模型(Feature Ability)的用法,Stage模型已采用全新的应用架构,推荐使用组件化的上下文获取方式,而非依赖featureAbility。 FA大概是API7之…...
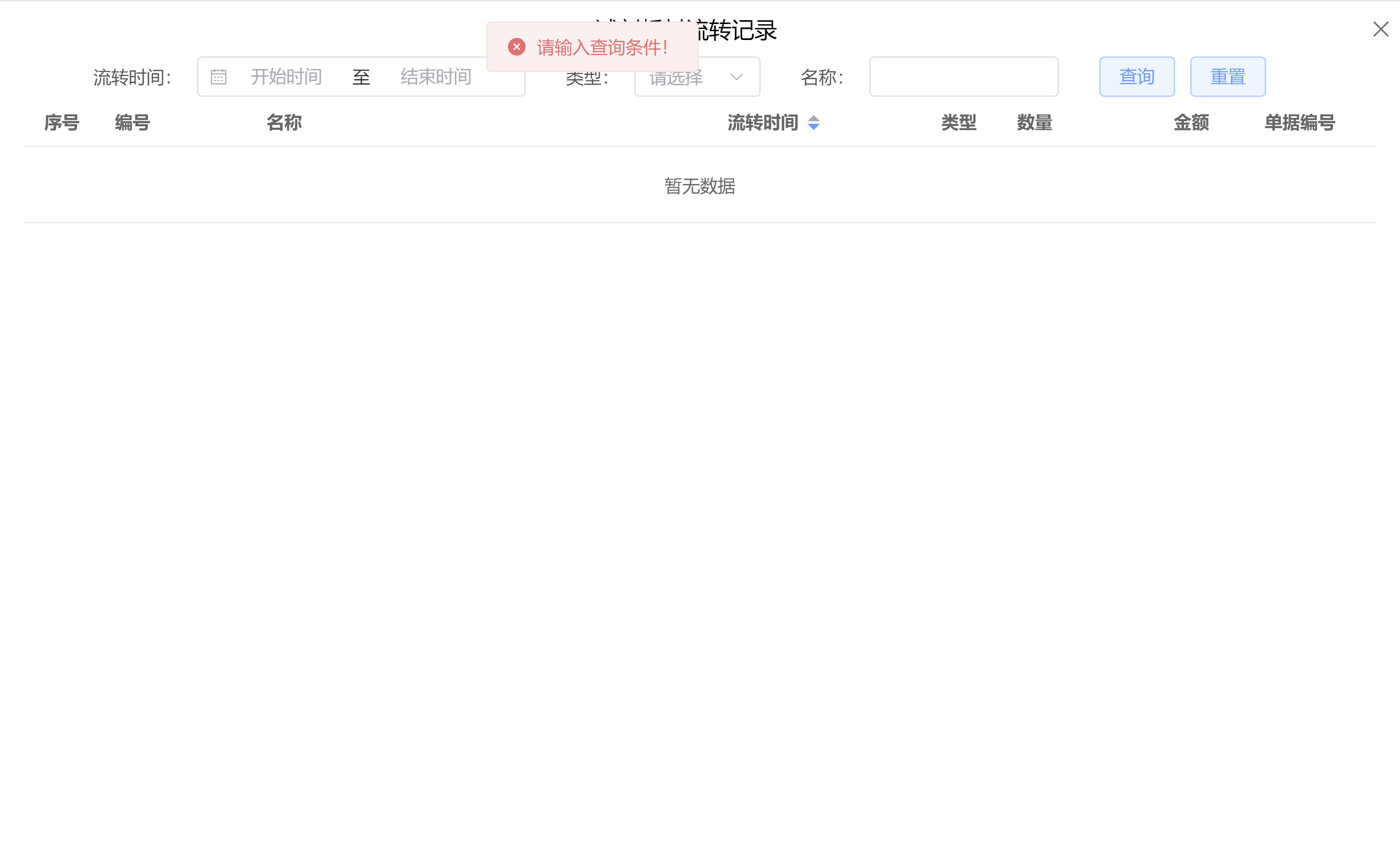
Java后端检查空条件查询
通过抛出运行异常:throw new RuntimeException("请输入查询条件!");BranchWarehouseServiceImpl.java // 查询试剂交易(入库/出库)记录Overridepublic List<BranchWarehouseTransactions> queryForReagent(Branch…...

命令行关闭Windows防火墙
命令行关闭Windows防火墙 引言一、防火墙:被低估的"智能安检员"二、优先尝试!90%问题无需关闭防火墙方案1:程序白名单(解决软件误拦截)方案2:开放特定端口(解决网游/开发端口不通)三、命令行极速关闭方案方法一:PowerShell(推荐Win10/11)方法二:CMD命令…...