OceanBase 4.0解读:兼顾高效与透明,我们对DDL的设计与思考
关于作者
谢振江,OceanBase 高级技术专家。 2015年加入 OceanBase, 从事存储引擎相关工作,目前在存储-索引与 DDL 组,负责索引,DDL 和 IO 资源调度相关工作。
回顾关系型数据库大规模应用以来的发展,从单机到分布式无疑是一个关键转变,促成它的是层出不穷的新业务和爆发增长的数据量。
一方面,更大的数据量意味着社会经济发展有了更多新可能,另一方面,它也对数据库提出了更高要求,以避免存储节点增多带来的运维成本上升和可能出现的新故障。因此,做好分布式数据库的透明性,像使用单机数据库一样使用分布式数据库成为提升用户体验的关键之一。而 DDL 作为数据库运维中常见的变更操作,它的执行自然应该对业务方和运维人员都透明。
“DDL 操作一定要等到夜深人静时”、“DDL操作执行时间很长,有时甚至需要几周时间”……这些问题不仅令一线运维人员抓狂,也是各个数据库厂商一直尝试突破的地方。OceanBase 认为,上述问题的完美解决取决于实现高效且透明的 DDL,即数据库应该尽可能快地执行 DDL,并保证 DDL 执行期间不影响业务方和运维人员的操作。
在 OceanBase 4.0 中,我们基于已有的原生 Online DDL 能力进行了创新:首先,为了提升 DDL 操作的可用性,我们自研了一套专门用于旁路写入的数据同步方法;此外,我们对 DDL 的单机性能和分布式执行的可扩展性进行优化,大幅提升用户 DDL 操作的响应速度;最后,4.0 进一步完善了原生 Online DDL 的框架能力,支持了主键变更、分区规则修改、修改列类型和修改字符集等功能。
我们希望透过这些新变化,帮助用户轻松应对各类复杂业务场景。本篇文章将讨论 OceanBase 如何实现高效且透明的 DDL,介绍 OceanBase 4.0 DDL 的新能力及设计思路:
-
更适合用户的 DDL 是什么样的;
-
OceanBase 如何做好 DDL;
-
来看看 4.0 DDL 有哪些新变化;
-
4.0 DDL 新功能上手实测。
更适合用户的 DDL,应该是什么样的?
要回答这个问题,我们需要先了解 DDL 的概念。在实际的数据库运维过程中,除了 SELECT,INSERT,UPDATE,DELETE 等这些常用的对数据本身进行操作处理的命令,还有 CREATE,ALTER ,DROP,TRUNCATE 等对表结构等数据库对象进行变更、与数据定义相关的命令,这些命令被称为 DDL。举例来说,常见的 DDL 操作有在表上增加新列、或给某列添加索引等。
在数据库发展早期,执行 DDL 语句被视为最昂贵的数据库操作之一,这是因为 DDL 操作通常会造成表不可读写,阻塞各类进行中的任务。如果表的数据量很大,会长时间中断数据库服务来执行 DDL,这对于被要求时刻在线的关键业务是难以接受的。因此,Online DDL 应运而生,它的提出主要是为了能够在执行 DDL 时,不阻塞正常的用户请求。目前市面上大部分数据库的 Online DDL 并未做到对用户完全透明:
-
大部分单机数据库在 Online DDL 过程中存在短暂加锁的操作,例如使用 MySQL 数据库在大事务场景中执行 DDL,可能会阻塞用户的请求;
-
受限于架构设计,目前业界许多分布式数据库实现的 Online DDL,在某些业务场景会对用户正常的请求造成影响;
-
此外,Online DDL 产生于单机数据库,它通常只关注 DDL 是否对正常用户请求产生影响,而对数据库节点发生异常,如宕机时的应对并未提及。
而随着数据量爆发时代的到来,DDL 的执行时长也会制约业务的迭代速度。在单机数据库中,通常会采用并行排序来尽可能加速 DDL 的执行,但它的执行速度受限于单机的性能瓶颈;到了分布式数据库,业界普遍使用模拟用户插入的方式来补全数据,然而这种方式并不能充分利用单台服务器的性能,也忽视了分布式可扩展能力提供的潜在性能。
可以这样说,仅靠传统意义上的 Online DDL 已无法很好地满足实际业务需求。
我们认为,更适合用户实际业务需求的 DDL 至少要具备以下两方面能力:一方面,DDL 的执行应避免对业务方的 DML、DQL 操作产生影响,分布式环境也不会被运维人员感知,即便发生宕机等异常,DDL 操作也能成功;另一方面,DDL 操作应具备在单机和分布式上良好的并行处理能力,帮助用户进行快速的业务创新。
OceanBase 如何做好 DDL
OceanBase 希望为用户提供一款高效并且足够透明的数据库产品。
在透明性方面:不同于单机数据库,我们需要解决 DDL 操作过程中分布式数据库多节点状态不一致的问题。在应对这个问题时,业界的大部分数据库采用了“DDL 优先”设计思路,然而这种思路会在一些业务场景对用户请求产生影响。而 OceanBase 采用的是“业务请求优先”设计思路,能避免对业务请求产生影响。此外,我们也尽量屏蔽用户对分布式数据库的感知,让用户像使用单机数据库一样,在分布式数据库中执行 DDL。
在执行效率方面:考虑到部分 DDL 操作会对数据进行补全,而该步骤往往是 DDL 操作中最耗时的,我们没有使用其他分布式数据库常用的模拟插入方式,而是借鉴了单机数据库的设计思路,并在分布式数据库中做到数据补全的性能可扩展,实现足够高效的 DDL。
▋ 业务请求优先的分布式 Online DDL
在介绍 OceanBase 的 Online DDL 前,不得不提的是分布式数据库领域中较为流行的 Google F1 在线异步 Schema 变更算法*(出自论文《Online, Asynchronous Schema Change in F1》)*,CockroachDB 等众多分布式数据库的 Online DDL 功能均基于这一算法实现。该算法的实际过程较为复杂,如果尝试用简单的话解释可以这样表述:由于执行 DDL 过程中不能对表进行禁写,大概率会出现不同节点有不同 schema 版本的情形,而该算法会通过引入多个中间状态的 schema,以保证数据的一致性。
进一步说,Google F1 数据库由于没有全局成员列表,所以在 DDL 执行过程中无法考虑机器和事务的状态,会强制地周期性往前推进 Schema 版本,而集群中需要保证同时使用的 Schema 版本不超过两个,因此,对于事务的执行时长有限制,并且如果发生节点获取不到最新 Schema 版本的情况,该节点会自杀退出,影响其上所有的事务执行。总结而言,F1 数据库会优先推进 DDL 的执行进程,而不考虑对事务状态的影响,因此,我们将 F1 数据库的设计思路称为 DDL 优先的设计。
与 Google F1 不同的是,OceanBase 的特点是有全局的成员列表,在 DDL 变更过程中,可以与 DDL 变更表格相关的成员进行协调,当所有节点的事务状态都满足 DDL 变更一致性所需的条件时,才推进接下来的 Schema 版本,这样可以避免限制正常事务的执行,在出现节点无法刷新到最新 Schema 版本时,OceanBase 不会杀掉节点,只会限制该节点正在执行 DDL 语句的表格相关的事务的执行,同时不影响其他表格的执行,因此,我们将 OceanBase 的设计思路称为业务请求优先的设计。
我们以建索引为例,测试 Google F1 和 OceanBase 在不同场景中执行 DDL 对业务请求的影响,结果如下:
| OceanBase 3.x | Google F1 | |
|---|---|---|
| 对正常事务的影响 | 无影响 | 限制执行时长 |
| 无法获取最新 Schema 时 | 进程存活,影响正在执行DDL表格的相关的用户事务 | 事务结束,进程自杀 |
| 节点宕机时 | 执行时间变长 | 无影响 |
表1 OceanBase 3.x 与 Google F1 建索引影响对比
而在 OceanBase 4.0 中,Online DDL 除了具备业务请求优先,对业务透明的特点之外,还在数据库节点出现异常场景时,增强了 DDL 操作的高可用特性,即使在节点宕机时,执行时间也不一定会变长,具体内容会在后文中详细描述。
▋ 高效的数据补全方式
数据库中有部分 DDL 操作需要对数据进行补全,比如建索引、加列等,OceanBase 从 1.4 版本开始将这些需要补全数据的 DDL 操作划分为两种模式:一种只需要在 Schema 上修改,异步进行补数据的方式,或称为 Instant DDL;另一种则是需要实时补全数据的 DDL。
对于需要实时补全数据的 DDL,业内大多数分布式数据库采用的是模拟用户插入的方式将数据补全,这种方案的优点是实现简单,可以复用 DML 的写入能力来完成数据写入,并同步到备副本、备库等,其缺点是性能差,数据写入时会经过 SQL、事务、内存排序的结构,在 LSM-Tree 存储架构中数据最终还要经过多次 compaction,步骤繁琐。因此,OceanBase 借鉴了单机数据库排序和旁路写入的思路进行数据补全。但与单机数据库不同的是,OceanBase 需要进行分布式排序,以及结合 LSM-Tree 存储架构展开优化以获得更好的性能。
一、分布式排序
在 OceanBase 3.x 版本中,DDL 中的分布式排序复用了旧的 SQL 执行框架中的分布式排序能力,其特点是具有分布式的性能可扩展性,但在单机的执行效率上有提升空间。而在 4.0 基于新的 SQL 执行框架进行分布式排序后,执行性能得到了大幅度提升。
二、结合 LSM-Tree 存储架构展开优化
不同于传统数据库的 B+Tree 的原地更新存储模型,LSM-Tree 存储架构的特点是增量数据会更新到增量的数据源 Memtable 中,不会对已写入磁盘的数据(SSTable)进行原地更新,只有在 Compaction 时,才会写入新的磁盘数据。这一特点为 OceanBase 加快 DDL 中的数据补全提供了极大的便利:一方面,对于加列这类操作,可以自然地做到 Instant DDL,只需要在 Compaction 的进行异步地数据补全;另一方面,对于建索引这类需要实时补全数据的 DDL 操作,DDL 与 DML 会协调获得一个补全数据的版本号,而该版本号之前的事务数据都已提交,可以直接将补全的数据写入到 SSTable 中,将 DML 产生的增量数据直接写入 Memtable 中,因此,建索引过程中的增量数据可以实时维护好,无需类似于原地更新存储的追数据过程。
经过数年的发展迭代,OceanBase 用户现在可以在线进行绝大部分 DDL 操作,包括:索引操作、列操作、生成列操作、外键操作、表操作,分区操作。
| 功能分类 | 支持的操作 | 是否Online | 需要操作哪些数据 |
|---|---|---|---|
| 添加索引 | 是 | Schema元数据,索引表数据 | |
| 删除索引 | 是 | Schema元数据 | |
| 重命名索引 | 是 | Schema元数据 | |
| 列操作 | 添加列 | 是 | Schema元数据,主表数据(Instant) |
| 删除列 | 是 | Schema元数据,主表数据(Instant) | |
| 重命名列 | 是 | Schema元数据 | |
| 重排列 | 是 | Schema元数据 | |
| 设置列默认值 | 是 | Schema元数据 | |
| 删除列默认值 | 是 | Schema元数据 | |
| 修改列类型 | 是 | Schema元数据,主表数据(Instant) | |
设置列约束为NULL | 是 | Schema元数据 | |
设置列约束为NOT NULL | 是 | Schema元数据,查询数据 | |
| 生成列操作 | 添加VIRTUAL列 | 是 | Schema元数据 |
删除VIRTUAL列 | 是 | Schema元数据 | |
添加STORED列 | 是 | Schema元数据,主表数据(Instant) | |
删除STORED列 | 是 | Schema元数据,主表数据(Instant) | |
| 外键操作 | 添加外键 | 是 | Schema元数据,查询表数据 |
| 删除外键 | 是 | Schema元数据 | |
| 表操作 | 修改行格式 | 是 | Schema元数据,主表数据(Instant) |
| 修改块大小 | 是 | Schema元数据,主表数据(Instant) | |
| 重命名表 | 是 | Schema元数据 | |
| 修改压缩算法 | 是 | Schema元数据,主表数据(Instant) | |
| 优化表空间 | 是 | Schema元数据,主表数据(Instant) | |
| 分区操作 | 添加分区 | 是 | Schema元数据 |
| 删除分区 | 是 | Schema元数据 | |
| Truncate分区 | 是 | Schema元数据,索引表数据(可选) |
表2 OceanBase 支持的 Online DDL 操作
来看看 4.0 DDL 有哪些新变化
▋ 伴随业务成长的 DDL 新功能
在研发 4.0 之前,我们了解到一些用户在新业务场景中需要经常对主键、分区等数据库对象的结构进行变更,由于这类 DDL 操作需要将原表的数据进行重写,我们称这一类 DDL 变更为需要数据重整的 DDL。
什么样的场景会需要数据重整的 DDL 呢?
- 修改分区规则: 某业务在一开始的规模较小,在业务规模增长后,数据量或者负载超过单机的规模,而业务的查询更新语句中,需要把某些列作为条件。此时需要按照这些列进行分区,将数据量或者负载打散到多个节点上;
- 修改字符集: 某业务刚开发时,误将某一列的字符集 collation 设置大小写不敏感,后来希望改造成大小写敏感的;
- 修改列类型: 某业务表的列一开始定义为 int 列,后来业务发生变化,int 不足以表达业务的场景,需要修改为 varchar 列;
- 修改主键: 某业务的主键一开始使用业务自定义的 ID 列作为主键,后来希望使用自增列来作为主键。
用户的业务成长不仅在于业务规模的增长,也在于业务对数据库功能的使用更加深入。因此,DDL 功能也必须长期支撑业务发展,伴随业务成长。我们发现,目前市面上的分布式数据库并未能对这类 DDL 操作提供良好的支持,一是功能支持上不够完善,例如部分数据库并不支持主键变更、分区规则变更等;二是部分数据库在做数据重整时会采用模拟用户重新插入数据的方法,将数据重新导出并插入一遍,效率较低并且可能与用户事务产生冲突。
在 4.0 之前的版本,OceanBase 对于数据重整的 DDL,通常会采用手工数据迁移的方法完成变更。这种方法总体上有四个步骤:在原表的基础上加入所做的 DDL 变更,创建出一张新的空表;将原表的数据导出;将导出后的数据写入新表;将原表重命名,并且将新表重命名为老表。这一方法存在许多不足,如:操作步骤复杂;任务失败时,需要借助外部工具或者人工来回滚所做的操作;迁移效率低;遇到节点宕机会提高幂等性的处理难度(比如无主键表场景)等。
4.0 能为用户提供原生的数据重整 DDL 变更功能,一条 DDL 命令即可完成所有操作,包括修改分区规则、主键操作、修改列类型、修改字符集等,用户无须关心 DDL 变更过程中出现的环境异常。
| 功能分类 | 支持的操作 |
|---|---|
| 主键操作 | 添加主键 |
| 删除主键 | |
| 修改主键 | |
| 列操作 | 修改列类型包括变短、变长、跨类型变更 |
| 修改自增列值 | |
| 添加自增列 | |
| 表操作 | 修改字符集修改表中所有已有数据的字符集 |
| 分区操作 | 重分区 *非分区表转成一级、二级分区; **一级分区转成其他一级或者二级分区;*二级分区转成一级分区或者其他二级分区; |
表3 4.0 DDL 新功能
为了支持好这些新功能,我们也对原生的 Online DDL 进行了扩展:
-
新增对多个依赖对象表格原子变更的能力;
-
大幅提升了原生 Online DDL 的数据补全性能;
-
旁路导入产生的数据也适用高可用的数据同步;
-
对表上的数据以及表的依赖对象的数据都进行数据一致性校验,保证 DDL 变更产生的数据正确性。
▋ 原子变更保证数据同步更新
原子变更能够保证用户在执行完 DDL 后,如果 DDL 是成功的,那么用户之后都会看到新变更后的表结构和数据,如果 DDL 是失败的,那么用户会看到变更之前的原表结构和数据。而进行需要重整数据的 DDL 变更会涉及到两方面的操作,一方面,需要对表上已有数据按照新的表格式进行修改;另一方面,需要对表上的依赖对象按照新的表格式进行修改,如索引、约束、外键和触发器等。
另外,由于分布式数据库中表上的数据可能分布在不同的节点上,这也会带来两个问题:
-
如何原子地将分布在不同节点的数据、多个依赖对象进行变更;
-
每个节点感知到最新变更后的表结构的时间会出现不同,如何保证在变更完成后,用户只看到变更后的表结构。
为此,我们设计了一套分布式环境下表结构的变更流程,能保证原子地对数据、多个依赖对象进行变更,并且用户在执行完 DDL 变更后,能够使用最新的表结构来对表格进行查询、DML 等操作。
在实际业务场景中,进行 DDL 变更也有可能会碰到数据库内核无法处理的异常。举例来说,我们有一个列类型为 int 的表格,该列上有一个唯一索引,我们将这个列类型修改为 tinyint,如果表中有多行的该列的列值超过了 tinyint 表示的范围,那么这些行的所有列都会被截断成 tinyint 的上界,导致多行在该列的列值有重复,不满足唯一性约束。此时,有可能数据已完成部分的重写,DDL 在碰到这类异常后主动回滚时,能够保证用户看到的是变更之前的原表的数据,而不是看到处于变更到一半的状态。
▋ 并行能力提升数据补全速度
业界分布式数据库普遍采用模拟用户插入作为迁移数据的方式,该方案存在两方面问题,一是可能会和正常业务产生行锁冲突,二是由于方案中对事务的并发控制、内存索引结构的线程安全控制、以及实际写入过程多次写入的情况,其性能与传统单机数据库会存在明显差距。
为了在设计层面降低 DDL 变更对业务的影响,同时让 DDL 具有更高的执行效率,我们使用类似于 OceanBase 中索引创建采用的分布式排序、旁路写入的方式将原表的数据迁移到新表。分布式排序方式节省事务、内存有序结构维护、多次compaction等逻辑,可以帮助用户节省 CPU 开销。而旁路写入能够避免数据写入到 Memtable 中以及出现多次 compaction 的情况,节省内存和 IO 开销。
OceanBase 4.0 基于新的并行执行框架,重新设计了 DDL 数据补全的分布式执行计划,该计划分为两部分,第一部分是采样和扫描算子,第二部分是排序和扫描算子。
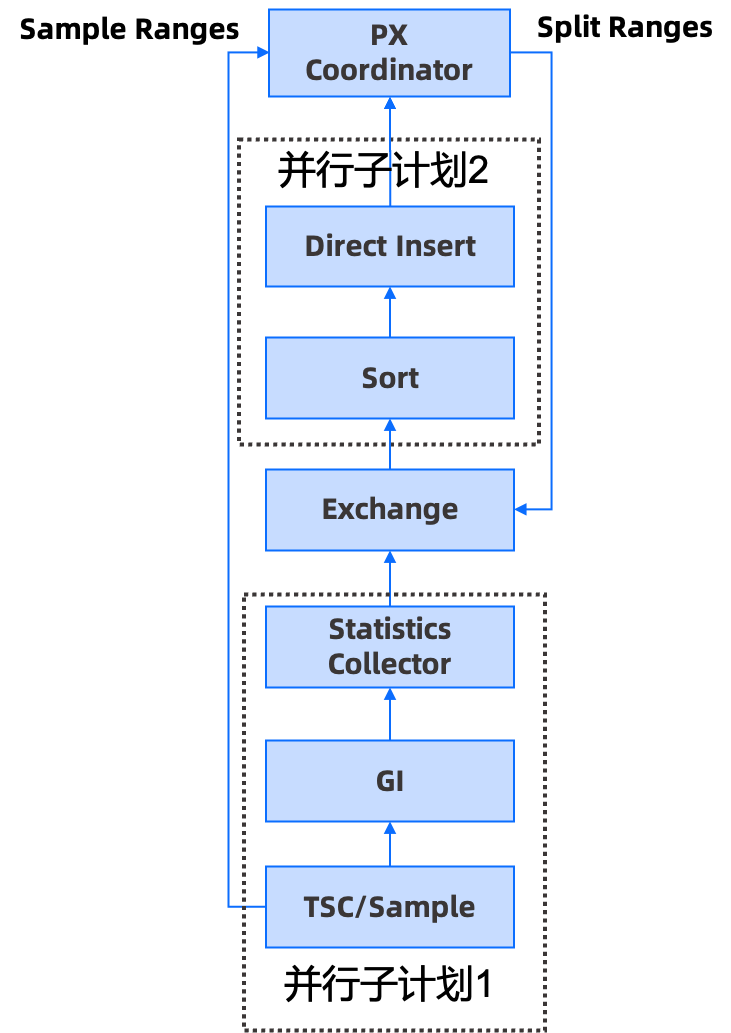
图1 OceanBase 4.0 DDL 数据补全分布式执行计划
该方案能充分利用分布式和单机并行能力:
第一、两个并行子计划可能是运行在多台机器上的,并且是新框架上同时调度起来的,能够形成并行子计划 1 往,并行子计划 2 吐行并处理的流水线;
第二、为了防止分区间的数据倾斜,我们将每个分区拆分成多份由不同的 sort 算子处理,每个 sort 算子会处理多个分区的数据,再结合采样划分算法,让每个分区的数据划分相对均衡,这样就能保证任务间的排序是均衡的。
另一方面,在单机执行效率上,我们通过一些技术提升了性能。如:在补数据流程中尽量使用向量化来进行批处理、写本机磁盘数据和网络同步数据并行化、更高效的采样算法、新框架的静态数据引擎避免行的元数据反复拷贝等。上述优化对于所有需要补全数据的场景,包括创建索引、数据重整的 DDL 性能提升都是有帮助的。
▋ 更严苛的可用性要求
分布式排序和旁路写入对数据补全的性能提升有很大的帮助,但同时会带来一个问题:旁路写入的数据如何同步到备副本和备库?OceanBase 4.0 版本中支持将旁路写入到 SSTable 的数据通过 PAXOS 同步到备副本和备库,在备副本和备库回放时,只需要将 SSTable 中宏块的数据地址和元数据信息回放到内存状态机中,这样做有如下好处:
-
旁路写入的数据也具备高可用能力,当少数派节点宕机时,不影响 DDL 执行;
-
旁路写入的数据是经过数据编码和通用压缩的,数据量一般比原表数据量少很多,数据同步性能好;
-
备库和备副本的执行逻辑统一,不再依赖特殊代码逻辑来处理数据同步,代码更易于维护。
▋ 更全面的数据一致性校验
在做数据重整的 DDL 时,需要将原表的数据迁移到新表,我们希望在 DDL 变更后,用户的数据是正确无误的。OceanBase 4.0 能够通过一致性校验保证 DDL 成功后,迁移数据和原表数据的一致性,即便 DDL 过程中发生了一些预期外异常导致数据不一致,OceanBase 也会回滚掉该 DDL 操作。展开来讲,OceanBase 4.0 会校验新表、新表上的索引、约束、外键等所有对象,只有所有表中的数据,依赖对象上的数据都是一致的,DDL 操作才可能成功。
4.0 DDL 新功能上手实测
▋ 新功能测试
一、主键操作
主键操作
- 添加主键
OceanBase(admin@test)>create table t1(c1 int);
Query OK, 0 rows affected (0.18 sec)--添加主键示例
OceanBase(admin@test)>alter table t1 add primary key(c1);
Query OK, 0 rows affected (1.28 sec)--添加主键验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) NOT NULL,PRIMARY KEY (`c1`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+-------------------------------------------------------+
1 row in set (0.03 sec)
- 删除主键
OceanBase(admin@test)>create table t1(c1 int primary key);
Query OK, 0 rows affected (0.19 sec)--删除主键示例
OceanBase(admin@test)>alter table t1 drop primary key;
Query OK, 0 rows affected (1.39 sec)--删除主键验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) NOT NULL
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+-------------------------------------------------------+
1 row in set (0.03 sec)
- 修改主键
OceanBase(admin@test)>create table t1(c1 int, c2 int primary key);
Query OK, 0 rows affected (0.18 sec)--修改主键示例
OceanBase(admin@test)>alter table t1 drop primary key, add primary key(c2);
Query OK, 0 rows affected (1.38 sec)--修改主键验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) DEFAULT NULL,`c2` int(11) NOT NULL,PRIMARY KEY (`c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+-------------------------------------------------------+
1 row in set (0.03 sec)
修改分区规则
- 非分区表转成一级、二级分区
--非分区表转成一级分区示例
OceanBase(admin@test)>alter table t1 partition by hash(c1) partitions 4;
Query OK, 0 rows affected (1.51 sec)--非分区表转成一级分区验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) DEFAULT NULL,`c2` datetime DEFAULT NULL
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0partition by hash(c1)
(partition p0,
partition p1,
partition p2,
partition p3) |
+-------+-------------------------------------------------------+
1 row in set (0.03 sec)
OceanBase(admin@test)>create table t1(c1 int, c2 datetime);
Query OK, 0 rows affected (0.18 sec)--非分区表转换成二级分区示例
OceanBase(admin@test)>alter table t1 partition by range(c1) subpartition by key(c2) subpartitions 5 (partition p0 values less than(0), partition p1 values less than(100));
Query OK, 0 rows affected (1.96 sec)--非分区表转换成二级分区验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) DEFAULT NULL,`c2` datetime DEFAULT NULL
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0partition by range(c1) subpartition by key(c2) subpartition template (
subpartition p0,
subpartition p1,
subpartition p2,
subpartition p3,
subpartition p4)
(partition p0 values less than (0),
partition p1 values less than (100)) |
+-------+-------------------------------------------------------+
1 row in set (0.04 sec)
- 一级分区转成其他一级或者二级分区
OceanBase(admin@test)>create table t1(c1 int, c2 datetime, primary key(c1, c2))-> partition by hash(c1) partitions 4;
Query OK, 0 rows affected (0.20 sec)--一级分区转换成其他一级分区示例
OceanBase(admin@test)>alter table t1 partition by key(c1) partitions 10;
Query OK, 0 rows affected (1.84 sec)--一级分区转换成其他一级分区验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) NOT NULL,`c2` datetime NOT NULL,PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0partition by key(c1)
(partition p0,
partition p1,
partition p2,
partition p3,
partition p4,
partition p5,
partition p6,
partition p7,
partition p8,
partition p9) |
+-------+--------------------------------------------------------+
1 row in set (0.03 sec)
OceanBase(admin@test)>create table t1(c1 int, c2 datetime, primary key(c1, c2))-> partition by hash(c1) partitions 4;
Query OK, 0 rows affected (0.19 sec)--一级分区转换成二级分区示例
OceanBase(admin@test)>alter table t1 partition by range(c1) subpartition by key(c2) subpartitions 5 (partition p0 values less than(0), partition p1 values less than(100));
Query OK, 0 rows affected (1.88 sec)--一级分区转换成二级分区验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) NOT NULL,`c2` datetime NOT NULL,PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0partition by range(c1) subpartition by key(c2) subpartition template (
subpartition p0,
subpartition p1,
subpartition p2,
subpartition p3,
subpartition p4)
(partition p0 values less than (0),
partition p1 values less than (100)) |
+-------+-------------------------------------------------------+
1 row in set (0.03 sec)
- 二级分区转成一级分区或者其他二级分区
OceanBase(admin@test)>create table t1(c1 int, c2 datetime, primary key(c1, c2)) partition by range(c1) subpartition by key(c2) subpartitions 5 (partition p0 values less than(0), partition p1 values less than(100));
Query OK, 0 rows affected (0.23 sec)--二级分区转换成一级分区示例
OceanBase(admin@test)>alter table t1 partition by key(c1) partitions 10;
Query OK, 0 rows affected (1.98 sec)--二级分区转换成一级分区验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) NOT NULL,`c2` datetime NOT NULL,PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0partition by key(c1)
(partition p0,
partition p1,
partition p2,
partition p3,
partition p4,
partition p5,
partition p6,
partition p7,
partition p8,
partition p9) |
+-------+--------------------------------------------------------+
1 row in set (0.03 sec)
OceanBase(admin@test)>create table t1(c1 int, c2 datetime, primary key(c1, c2)) partition by range(c1) subpartition by key(c2) subpartitions 5 (partition p0 values less than(0), partition p1 values less than(100));
Query OK, 0 rows affected (0.24 sec)--二级分区转换成其他二级分区示例
OceanBase(admin@test)>alter table t1 partition by hash(c1) subpartition by key(c2) subpartition template(subpartition sp0, subpartition sp1, subpartition sp2) PARTITIONS 5;
Query OK, 0 rows affected (2.07 sec)--二级分区转换成其他二级分区验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) NOT NULL,`c2` datetime NOT NULL,PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0partition by hash(c1) subpartition by key(c2) subpartition template (
subpartition sp0,
subpartition sp1,
subpartition sp2)
(partition p0,
partition p1,
partition p2,
partition p3,
partition p4) |
+-------+--------------------------------------------------------+
1 row in set (0.03 sec)
修改列类型
- 修改某列的列类型,包括变短、变长、跨类型变更、修改为自增列、修改字符集等等
OceanBase(admin@test)>create table t1(c1 varchar(32), c2 int, primary key(c1,c2));
Query OK, 0 rows affected (0.19 sec)--修改列类型:变短示例
OceanBase(admin@test)>alter table t1 modify c1 varchar(16);
Query OK, 0 rows affected (1.47 sec)--修改列类型:变短验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` varchar(16) NOT NULL,`c2` int(11) NOT NULL,PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+--------------------------------------------------------+
1 row in set (0.03 sec)
OceanBase(admin@test)>create table t1(c1 varchar(32), c2 int, primary key(c1,c2));
Query OK, 0 rows affected (0.17 sec)--修改列类型:变长示例
OceanBase(admin@test)>alter table t1 modify c1 varchar(48);
Query OK, 0 rows affected (0.17 sec)--修改列类型:变长验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` varchar(48) NOT NULL,`c2` int(11) NOT NULL,PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+--------------------------------------------------------+
1 row in set (0.01 sec)
OceanBase(admin@test)>create table t1(c1 int, c2 int, primary key(c1,c2));
Query OK, 0 rows affected (0.17 sec)--修改列类型:跨类型变更示例
OceanBase(admin@test)>alter table t1 modify c1 varchar(48);
Query OK, 0 rows affected (1.38 sec)--修改列类型:跨类型变更验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` varchar(48) NOT NULL,`c2` int(11) NOT NULL,PRIMARY KEY (`c1`, `c2`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+--------------------------------------------------------+
1 row in set (0.03 sec)
OceanBase(admin@test)>create table t1(c1 int, c2 int, primary key(c1,c2));
Query OK, 0 rows affected (0.18 sec)--修改列类型:将某列修改为自增列示例
OceanBase(admin@test)>alter table t1 modify c1 int auto_increment;
Query OK, 0 rows affected (0.58 sec)--修改列类型:将某列修改为自增列验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) NOT NULL AUTO_INCREMENT,`c2` int(11) NOT NULL,PRIMARY KEY (`c1`, `c2`)
) AUTO_INCREMENT = 1 AUTO_INCREMENT_MODE = 'ORDER' DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+--------------------------------------------------------+
1 row in set (0.01 sec)
OceanBase(admin@test)>create table t1 (c1 int, c2 varchar(32), c3 varchar(32), primary key (c1), unique key idx_test_collation_c2(c2));
Query OK, 0 rows affected (0.24 sec)--修改列类型:修改某列的字符集示例
OceanBase(admin@test)>alter table t1 modify column c2 varchar(32) charset gbk;
Query OK, 0 rows affected (2.12 sec)--修改列类型:修改某列的字符集验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) NOT NULL,`c2` varchar(32) CHARACTER SET gbk DEFAULT NULL,`c3` varchar(32) DEFAULT NULL,PRIMARY KEY (`c1`),UNIQUE KEY `idx_test_collation_c2` (`c2`) BLOCK_SIZE 16384 LOCAL
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+--------------------------------------------------------+
1 row in set (0.05 sec)
修改字符集
- 修改表中所有已有数据的字符集
OceanBase(admin@test)>create table t1 (c1 int, c2 varchar(32), c3 varchar(32), primary key (c1), unique key idx_test_collation_c2(c2));
Query OK, 0 rows affected (0.23 sec)--修改表中已有数据的字符集示例
OceanBase(admin@test)>alter table t1 CONVERT TO CHARACTER SET gbk COLLATE gbk_bin;
Query OK, 0 rows affected (2.00 sec)--修改表中已有数据的字符集验证
OceanBase(admin@test)>show create table t1;
+-------+-------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`c1` int(11) NOT NULL,`c2` varchar(32) COLLATE gbk_bin DEFAULT NULL,`c3` varchar(32) COLLATE gbk_bin DEFAULT NULL,PRIMARY KEY (`c1`),UNIQUE KEY `idx_test_collation_c2` (`c2`) BLOCK_SIZE 16384 LOCAL
) DEFAULT CHARSET = gbk COLLATE = gbk_bin ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
+-------+--------------------------------------------------------+
1 row in set (0.05 sec)
▋ 性能测试
我们以创建索引为例进行测试,往表格中导入一定行数的数据,测试建索引的时间,该时间主要消耗在索引数据补全,通过该测试可以评测出各个数据库的数据补全性能。
实验配置
表结构: create table t1(c1 int, c2 varchar(755)) partition by hash(c1) partitions 10;
数据量: 1000 万行;
资源配置: 单机,并行度 10,排序内存 128M;
测试场景:
create index i1 on t1(c1) global;
create index i1 on t1(c2) global;
create index i1 on t1(c1,c2) global;
create index i1 on t1(c2,c1) global;
**对比指标:**创建索引的耗时,单位为 s;
**对比产品:**单机数据库 MySQL、某分布式数据库 A 以及 OceanBase 4.0。
性能测试结果
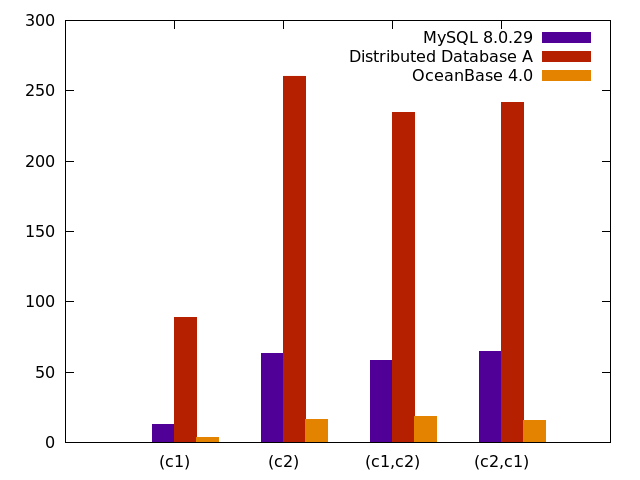
图2 性能测试对比
如上图所示,其中数据库 A 是通过模拟插入的方式来进行补全的,测试结果显示,OceanBase 索引构建性能,相对于数据库 A,提升了 10-20 倍,相对于 MySQL,提升了 3-4 倍。因此,使用排序和旁路写入方式来补全数据,能大幅提升索引构建性能。OceanBase 4.0 经过单机性能优化,数据补全的速度明显快于 MySQL。
写在最后
OceanBase 4.0 支持了常见的数据重整的 DDL 功能,包括修改主键、修改列类型、修改分区规则、修改字符集等。我们希望通过原子变更、更全面的数据一致性校验和高可用的数据同步技术,让用户只需要执行一条语句就能完成所需要的变更操作,无须考虑分布式环境中出现的异常场景,减少业务对分布式环境的感知,使用上更加透明。同时,我们提升了 DDL 的单机和分布式并行能力,加快 DDL 中数据补全的速度,使得 DDL 执行更加高效。
我们期待 4.0 对 DDL 功能的完善和优化,可以帮助用户从容应对多变的业务挑战。
相关文章:
OceanBase 4.0解读:兼顾高效与透明,我们对DDL的设计与思考
关于作者 谢振江,OceanBase 高级技术专家。 2015年加入 OceanBase, 从事存储引擎相关工作,目前在存储-索引与 DDL 组,负责索引,DDL 和 IO 资源调度相关工作。 回顾关系型数据库大规模应用以来的发展,从单机到分布式无…...

Qt线程池
目录1、线程池是什么?2、Qt线程池2.1、用法例程2.2、线程池对性能的提升2.3、运行算法单线程写法线程池写法1、线程池是什么? 线程池是一种线程使用模式,它管理着一组可重用的线程,可以处理分配过来的可并发执行的任务。 线程池设…...

设置table中的tbody
<!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>设置table中的tbody</title> </head> <body> <script> // 这里有json数据,是jav…...
2023美赛A题完整数据!思路代码数据数学建模
选取内蒙古河套灌区(典型干旱区)2010-2020年气温,降雨,蒸散发和水汽压月数据 包括四种主要作物及其占比 内容截图如下: 链接为:https://www.jdmm.cc/file/2708703 同时还提供参考代码和参考文章的选项~…...
Node.js安装与配置
Node.js安装与配置 前言 本篇博文记录了Node.js安装与环境变量配置的详细步骤,旨在为将来再次配置Node.js时提供指导方法。 另外:Node.js版本请根据自身系统选择,安装位置、全局模块存放位置和环境变量应根据自身实际情况进行更改。 Node…...
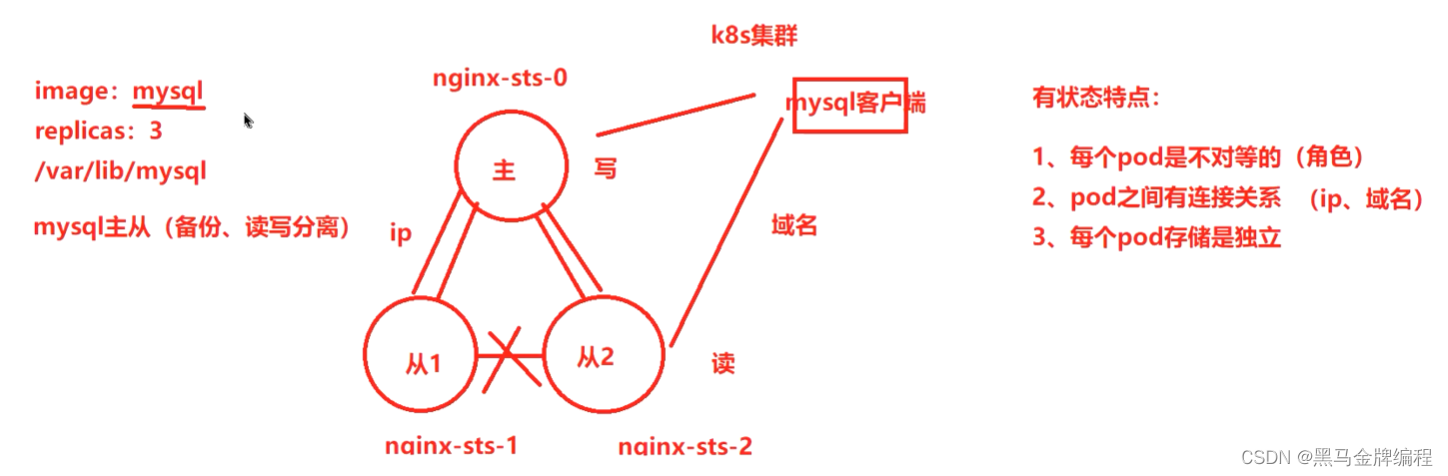
k8s(存储)数据卷与数据持久卷
为什么需要数据卷? 容器中的文件在磁盘上是临时存放的,这给容器中运行比较重要的应用程序带来一些问题问题1:当容器升级或者崩溃时,kubelet会重建容器,容器内文件会丢失问题2:一个Pod中运行多个容器并需要共…...
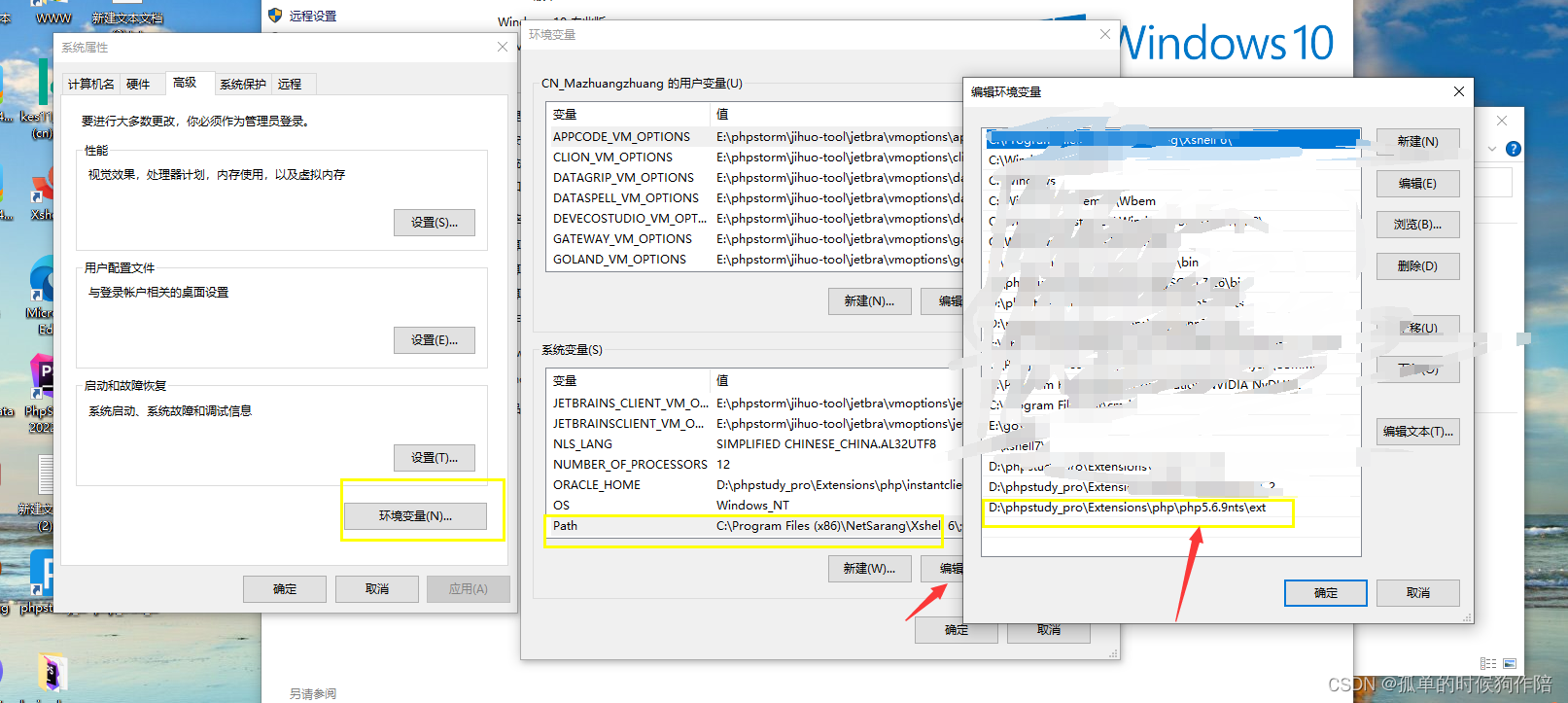
php5.6.9安装sqlsrv扩展(windows)
报错:Marning: PHP Startup: Unable to load dynamic 1library D:lphpstudy_prolExtensionslphpl(phps.6.9ntslextphp_ pdo_sqlsry 56 nts′找不到指定的模块。in Unknown on line 0 整整搞了一天才终于解决 我用的是phpstudy_pro(也就是小皮v8.1版本)&…...
参数检查 cookie黑名单 POST参数检查参考代码)
URL黑名单 扫描工具ua特征 GET(args)参数检查 cookie黑名单 POST参数检查参考代码
资源宝分享www.httple.net 文章目录URL黑名单扫描工具ua特征GET(args)参数检查cookie黑名单POST参数检查注:请先检查是否已设置URL白名单,若已设置URL白名单,URL黑名单设置将失效 多个URL配置需换行,一行只允许填写一个。可直接填…...

【软考系统架构设计师】2022下论文写作历年真题
【软考系统架构设计师】2022下论文写作历年真题 试题四 论湖仓一体架构及其应用(75分) 试题四 论湖仓一体架构及其应用 随着5G、大数据、人工智能、物联网等技术的不断成熟,各行各业的业务场景日益复杂,企业数据呈现出大规模、多…...

推荐3个好用的scrum敏捷项目管理工具
结合对工具的了解和使用心得,介绍在管理scrum中常见的一些工具基础的scrum工具:1、物理白板物理白板是实施scrum最简单直接的方式。之前我也说过,一些利弊。数据不能够沉淀等等。2、Excel表格表格的形式就是如果多人编辑时,不能实…...

每日学术速递2.17
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 Subjects: cs.LG 1.Decoupled Model Schedule for Deep Learning Training 标题:深度学习训练的解耦模型时间表 作者:Hongzheng Chen, Cody Hao Yu, Shuai Zheng, Zhen Zhang,…...
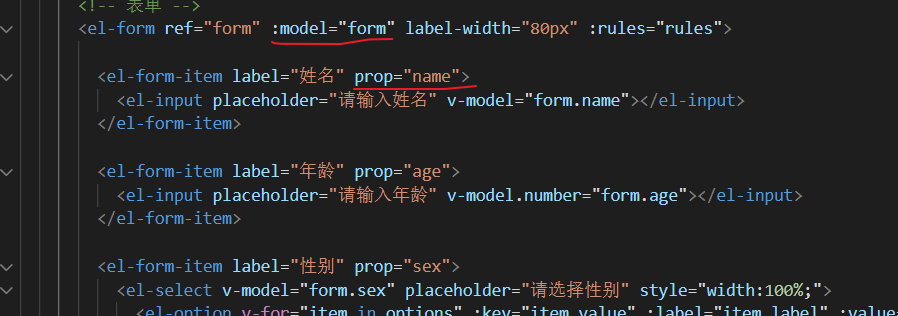
ElementUI`resetFields()`方法避坑
使用ElementUI中的resetFields()方法有哪些注意点 场景一 场景一:当编辑弹出框和新增弹出框共用时,编辑数据后关闭编辑弹出框时调用this.$refs.form.resetFields()无法清空弹出框 问题代码: // 点击新增按钮handleAdd() {this.dialogVi…...
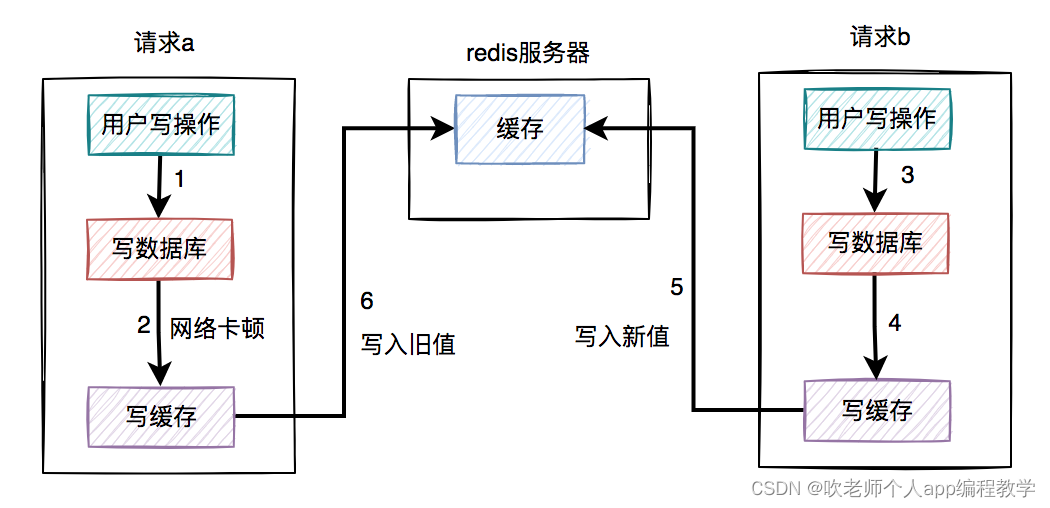
如何保证数据库和缓存双写一致性?
前言 数据库和缓存(比如:redis)双写数据一致性问题,是一个跟开发语言无关的公共问题。尤其在高并发的场景下,这个问题变得更加严重。 我很负责的告诉大家,该问题无论在面试,还是工作中遇到的概率…...

Hinge Loss 和 Zero-One Loss
文章目录Hinge Loss 和 Zero-One LossHinge LossZero-One LossHinge Loss 和 Zero-One Loss 维基百科:https://en.wikipedia.org/wiki/Hinge_loss 图表说明: 纵轴表示固定 t1t1t1 的 Hinge loss(蓝色)和 Zero-One Lossÿ…...

Linux下zabbix_proxy实施部署
简介 zabbix proxy 可以代替 zabbix server 收集性能和可用性数据,然后把数据汇报给 zabbix server,并且在一定程度上分担了zabbix server 的压力. zabbix-agent可以指向多个proxy或者server zabbix-proxy不能指向多个server zabbix proxy 使用场景: 1,监控远程区…...
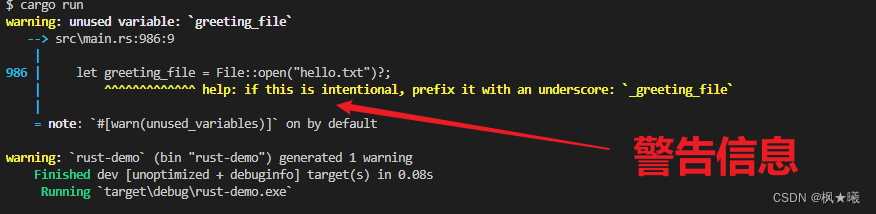
Rust之错误处理(二):带结果信息的可恢复错误
开发环境 Windows 10Rust 1.67.1VS Code 1.75.1项目工程 这里继续沿用上次工程rust-demo 带结果信息的可恢复错误 大多数错误并没有严重到需要程序完全停止的程度。有时,当一个函数失败时,它的原因是你可以很容易地解释和应对的。例如,如…...
[ vulhub漏洞复现篇 ] Drupal Core 8 PECL YAML 反序列化任意代码执行漏洞(CVE-2017-6920)
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

如何将数据库结构导入到word
在navicat执行查询语句 SELECT COLUMN_NAME 备注, COLUMN_COMMENT 名称, COLUMN_TYPE 数据类型, false as 是键 FROM INFORMATION_SCHEMA.COLUMNS where -- wx 为数据库名称,到时候只需要修改成你要导出表结构的数据库即可 table_schema yuncourt_ai AND -- articl…...
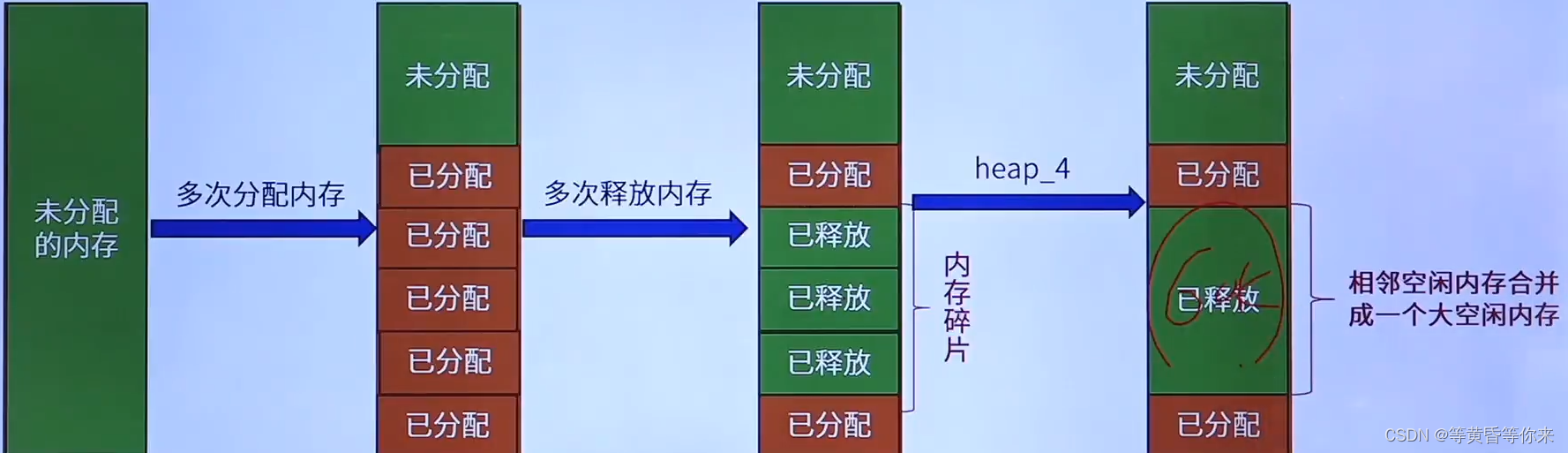
FreeRTOS内存管理 | FreeRTOS十五
目录 说明: 一、FreeRTOS内存管理 1.1、动态分配与用户分配内存空间 1.2、标准C库动态分配内存缺点 1.3、FreeRTOS的五种内存管理算法优缺点 1.4、heap_1内存管理算法 1.5、heap_2内存管理算法 1.6、heap_3内存管理算法 1.7、heap_4内存管理算法 1.8、hea…...
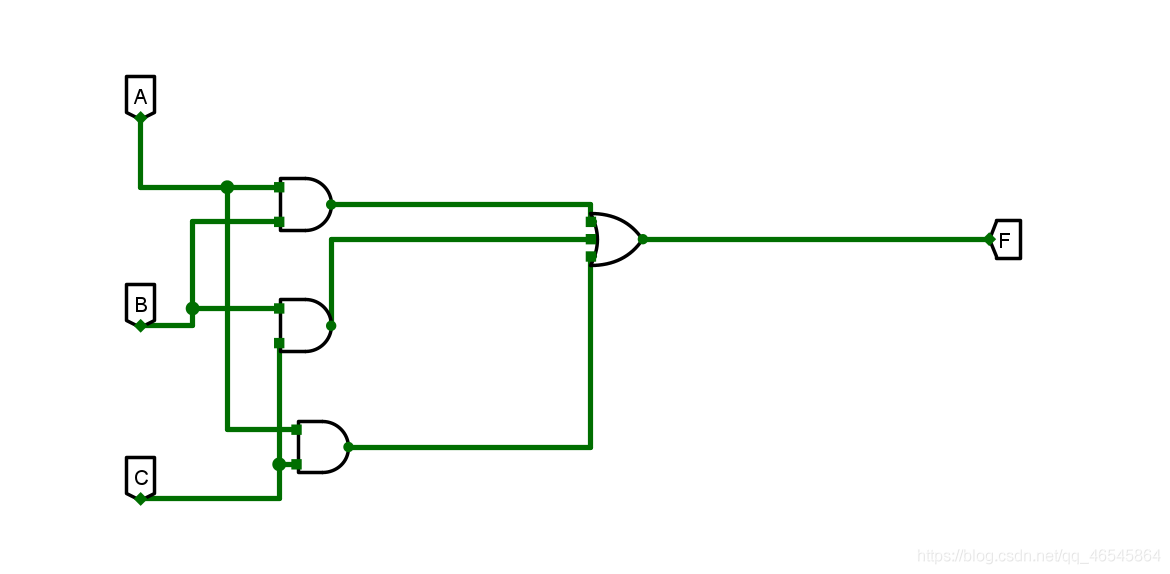
【数字电路】数字电路的学习核心
文章目录前言一、电子电路知识体系二、数电的学习目标三、数字电路分析例子四、数字电路设计例子总结前言 用数字信号完成对数字量进行算术运算和逻辑运算的电路称为数字电路,或数字系统。由于它具有逻辑运算和逻辑处理功能,所以又称数字逻辑电路。现代…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...

vue3 daterange正则踩坑
<el-form-item label"空置时间" prop"vacantTime"> <el-date-picker v-model"form.vacantTime" type"daterange" start-placeholder"开始日期" end-placeholder"结束日期" clearable :editable"fal…...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...
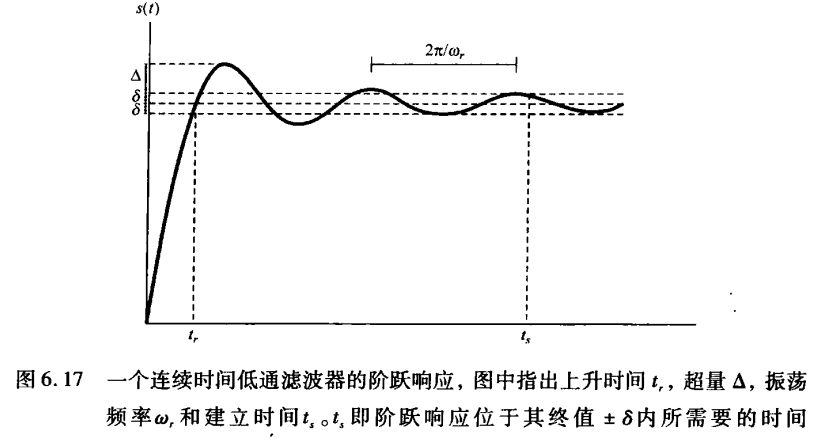
《信号与系统》第 6 章 信号与系统的时域和频域特性
目录 6.0 引言 6.1 傅里叶变换的模和相位表示 6.2 线性时不变系统频率响应的模和相位表示 6.2.1 线性与非线性相位 6.2.2 群时延 6.2.3 对数模和相位图 6.3 理想频率选择性滤波器的时域特性 6.4 非理想滤波器的时域和频域特性讨论 6.5 一阶与二阶连续时间系统 6.5.1 …...

数据库正常,但后端收不到数据原因及解决
从代码和日志来看,后端SQL查询确实返回了数据,但最终user对象却为null。这表明查询结果没有正确映射到User对象上。 在前后端分离,并且ai辅助开发的时候,很容易出现前后端变量名不一致情况,还不报错,只是单…...