YOLOv5-Backbone模块实现
🍨 本文为🔗365天深度学习训练营 中的学习记录博客
🍦 参考文章地址: 365天深度学习训练营-第P8周:YOLOv5-Backbone模块实现
🍖 作者:K同学啊
一、前期准备
1.设置GPU
import torch
from torch import nn
import torchvision
from torchvision import transforms,datasets,models
import matplotlib.pyplot as plt
import os,PIL,pathlibdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
devicedevice(type='cuda')
2.导入数据
data_dir = './weather_photos/'
data_dir = pathlib.Path(data_dir)data_paths = list(data_dir.glob('*'))
classNames = [str(path).split('\\')[1] for path in data_paths]
classNames['cloudy', 'rain', 'shine', 'sunrise']
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸# transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])test_transform = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder(data_dir,transform=train_transforms)
total_dataDataset ImageFolder
Number of datapoints: 1125
Root location: weather_photos
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=PIL.Image.BILINEAR)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
total_data.class_to_idx{'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3}
3.划分数据集
train_size = int(0.8*len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data,[train_size,test_size])
train_dataset,test_dataset(<torch.utils.data.dataset.Subset at 0x1e42b97f4f0>,
<torch.utils.data.dataset.Subset at 0x1e42b196a30>)
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)for X,y in test_dl:print('Shape of X [N, C, H, W]:', X.shape)print('Shape of y:', y.shape)breakShape of X [N, C, H, W]: torch.Size([4, 3, 224, 224])
Shape of y: torch.Size([4])
二、搭建包含Backbone模块的模型
1.搭建模型
import torch.nn.functional as Fdef autopad(k, p=None): # kernel, padding# Pad to 'same'if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolutiondef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))class SPPF(nn.Module):# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocherdef __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * 4, c2, 1, 1)self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)def forward(self, x):x = self.cv1(x)with warnings.catch_warnings():warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warningy1 = self.m(x)y2 = self.m(y1)return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
"""
这个是YOLOv5, 6.0版本的主干网络,这里进行复现
(注:有部分删改,详细讲解将在后续进行展开)
"""
class YOLOv5_backbone(nn.Module):def __init__(self):super(YOLOv5_backbone, self).__init__()self.Conv_1 = Conv(3, 64, 3, 2, 2) self.Conv_2 = Conv(64, 128, 3, 2) self.C3_3 = C3(128,128)self.Conv_4 = Conv(128, 256, 3, 2) self.C3_5 = C3(256,256)self.Conv_6 = Conv(256, 512, 3, 2) self.C3_7 = C3(512,512)self.Conv_8 = Conv(512, 1024, 3, 2) self.C3_9 = C3(1024, 1024)self.SPPF = SPPF(1024, 1024, 5)# 全连接网络层,用于分类self.classifier = nn.Sequential(nn.Linear(in_features=65536, out_features=100),nn.ReLU(),nn.Linear(in_features=100, out_features=4))def forward(self, x):x = self.Conv_1(x)x = self.Conv_2(x)x = self.C3_3(x)x = self.Conv_4(x)x = self.C3_5(x)x = self.Conv_6(x)x = self.C3_7(x)x = self.Conv_8(x)x = self.C3_9(x)x = self.SPPF(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = YOLOv5_backbone().to(device)
model略
2.查看详细模型
# 统计模型参数量以及其他指标
import torchsummary as summary
summary.summary(model, (3, 224, 224))略
三、训练模型
1.编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,一共900张图片num_batches = len(dataloader) # 批次数目,29(900/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss2.编写测试函数
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,8(255/32=8,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss3.正式训练
import copyoptimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数epochs = 20train_loss = []
train_acc = []
test_loss = []
test_acc = []best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)# 保存最佳模型到 best_modelif epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)print('Done')。。。
Epoch:18, Train_acc:95.0%, Train_loss:0.142, Test_acc:91.6%, Test_loss:0.236, Lr:1.00E-04
Epoch:19, Train_acc:92.8%, Train_loss:0.193, Test_acc:88.0%, Test_loss:0.278, Lr:1.00E-04
Epoch:20, Train_acc:94.6%, Train_loss:0.160, Test_acc:92.0%, Test_loss:0.220, Lr:1.00E-04
Done
四、结果可视化
1.Loss与Accuracy图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()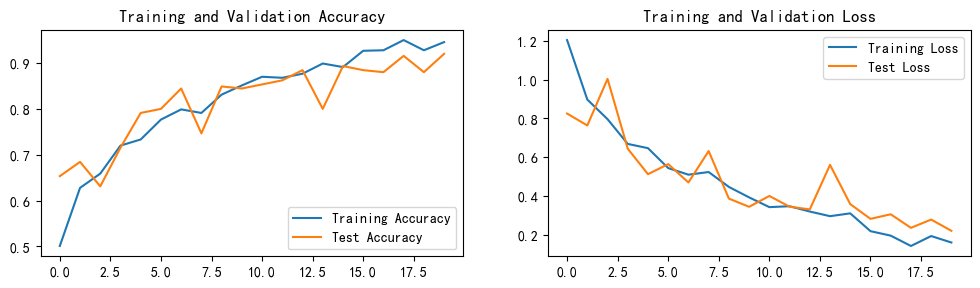
2.模型评估
# 将参数加载到model当中
best_model.load_state_dict(torch.load(PATH, map_location=device))
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss(0.92, 0.21799196774352886)
# 查看是否与我们记录的最高准确率一致
epoch_test_acc0.92
相关文章:
YOLOv5-Backbone模块实现
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍦 参考文章地址: 365天深度学习训练营-第P8周:YOLOv5-Backbone模块实现🍖 作者:K同学啊一、前期准备1.设置GPUimport torch from torch impor…...
【C语言】程序环境和预处理
🌇个人主页:平凡的小苏 📚学习格言:别人可以拷贝我的模式,但不能拷贝我不断往前的激情 🛸C语言专栏:https://blog.csdn.net/vhhhbb/category_12174730.html 小苏希望大家能从这篇文章中收获到许…...
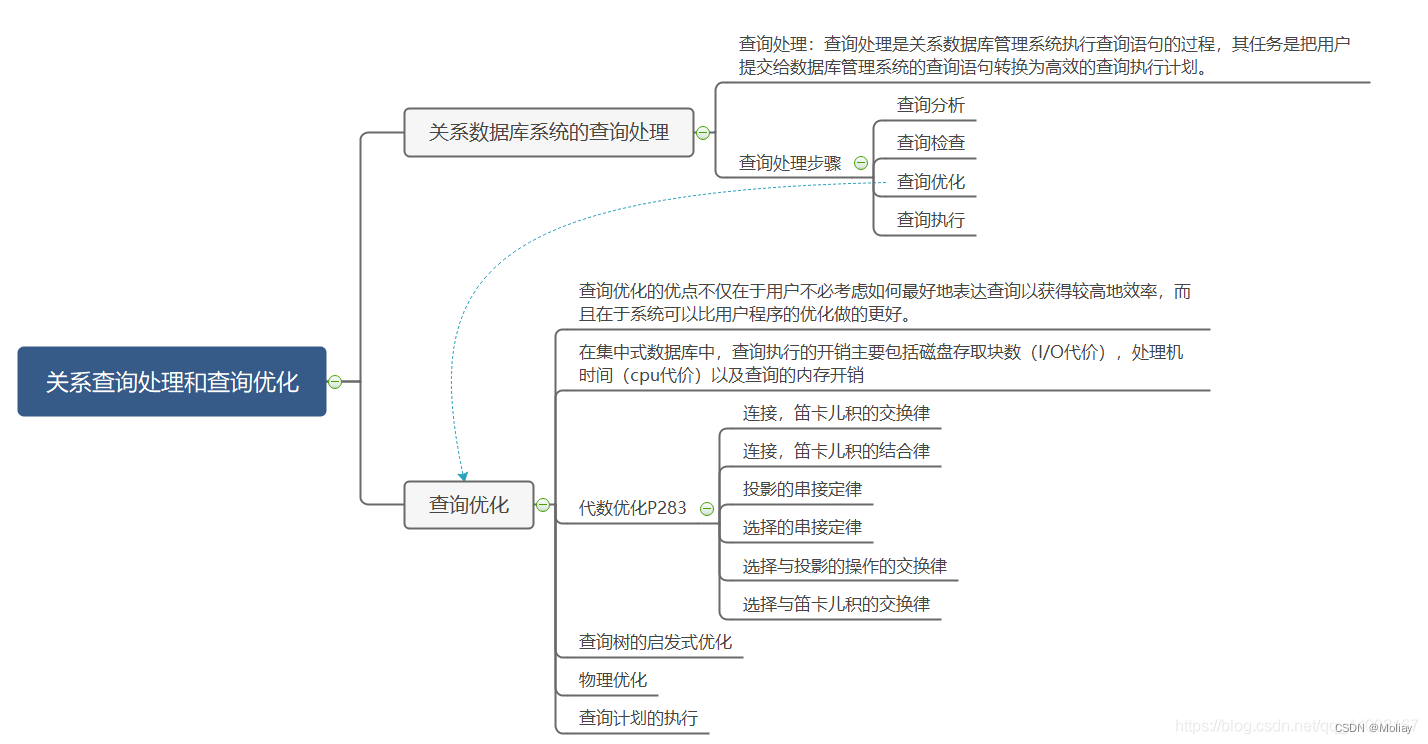
9.关系查询处理和查询优化
其他章节索引 梳理 名词解释 代数优化:是指关系代数表达式的优化,也即按照一定规则,通过对关系代数表达式进行等价变换,改变代数表达式中操作的次序和组合,使查询更高效物理优化:是指存取路径和底层操作算…...

计算机组成原理(三)
5.掌握定点数的表示和应用(主要是无符号数和有符号数的表示、机器数的定点表示、数的机器码表示); 定点数:小数点位置固定不变。 定点小数:小数点固定在数值位与符号位之间; 定点整数:小…...

C. Least Prefix Sum codeforces每日一题
🚀前言 🚀 大家好啊,这里是幸麟 🧩 一名普通的大学牲,最近在学习算法 🧩每日一题的话难度的话是根据博主水平来找的 🧩所以可能难度比较低,以后会慢慢提高难度的 🧩此题标…...
ASEMI三相整流模块MDS100-16图片,MDS100-16尺寸
编辑-Z ASEMI三相整流模块MDS100-16参数: 型号:MDS100-16 最大重复峰值反向电压(VRRM):1600V 最大RMS电桥输入电压(VRMS):1700V 最大平均正向整流输出电流(IF&#…...

【第37天】斐波那契数列与爬楼梯 | 迭代的鼻祖,递推与记忆化
本文已收录于专栏🌸《Java入门一百例》🌸学习指引序、专栏前言一、递推与记忆化二、【例题1】1、题目描述2、解题思路3、模板代码4、代码解析5.原题链接三、【例题1】1、题目描述2.解题思路3、模板代码4、代码解析5、原题链接三、推荐专栏四、课后习题序…...
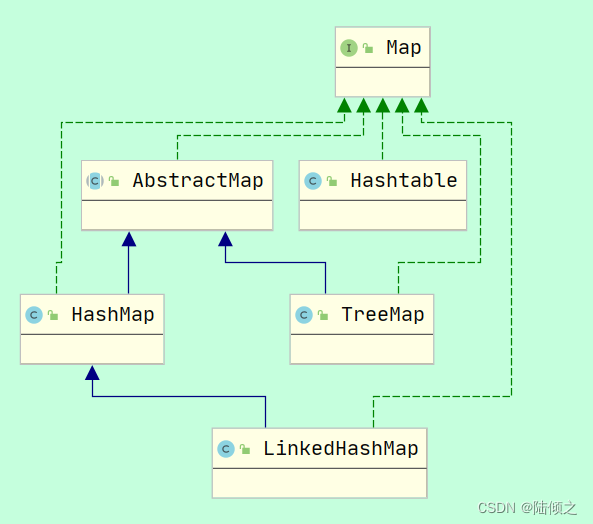
Map集合
Map集合 Map接口的简介 Map用于保存具有映射关系的数据,Map里保存着两组数据:key和value,它们都可以使任何引用类型的数据,但key不能重复。所以通过指定的key就可以取出对应的value。 Map 没有继承 Collection 接口,…...
PyQt5编程扩展 3.2 资源文件的使用
目录 本例运行效果: 设计Qt窗体 建立项目 放一个Group Box 放三个Label 放一个Horizontal Slider 放两个Line Edit 层次结构 布局 放一个Group Box 放两个Label 放两个Line Edit 放一个Push Button 层次结构 布局 放一个frame 层次结构 布局 窗体…...

Linux系统之文件共享目录设置方法
Linux系统之文件共享目录设置方法一、本次实践目的二、检查本地系统环境1.检查系统版本2.检查系统内核三、创建相关用户及用户组1.创建共享目录2.创建测试用户账号3.创建用户组4.设置用户的属组5.查看admin和IT用户组成员6.查看所有用户信息四、共享目录权限设置1.设置/data/so…...
上海亚商投顾:三大指数均涨超1% 芯片板块集体大涨
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。市场情绪三大指数今日低开高走,午后集体涨超1%,创业板指盘中涨超1.7%。芯片板块集体大涨,…...

Harbor私有仓库部署与管理
目录 前言 一、Harbor概述 二、Harbor 的特性 三、Harbor的构成 四、Harbor构建Docker私有仓库 1、环境配置 2、案例需求 3、部署Harbor服务 3.1、部署docker compose服务 3.2 下载或上传Harbor安装程序 3.3、启动Harbor 3.4、查看Harbor启动镜像 4、物理机访问se…...

互联网架构之 “高可用” 详解
一、什么是高可用 高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。 假设系统一直能够提供服务,我们说系统的可用性是100%。 如果系统每运行…...
分布式高级篇4 —— 商城业务(2)
一、订单服务1、订单基本概念2、订单基本构成3、订单状态4、订单流程5、配置拦截器拦截订单请求6、订单确认页模型抽取7、订单确认页vo封装8、Feign 远程调用请求头丢失问题\*\*\*\*\* 惨痛教训9、Feign 异步调用请求头丢失问题10、查看库存状态11、模拟计算运费12、接口幂等性…...

二分查找基本原理
二分查找基本原理1.二分查找1.1 基本概念1.2 二分查找查找步骤1.2.1 中间索引不能整除,取整数作为中间索引1.2.2 索引不能整除,整数1作为中间索引1.3 二分查找大O记法表示2. 二分查找代码实现1.二分查找 1.1 基本概念 二分法(折半查找)是一…...

【Python实战案例】Python3网络爬虫:“可惜你不看火影,也不明白这个视频的分量......”m3u8视频下载,那些事儿~
前言 哈喽!上午好嘞,各位小可爱们!有没有等着急了呀~ 由于最近一直在学习新的内容,所以耽搁了一下下,抱歉.jpg 双手合十。 所有文章完整的素材源码都在👇👇 粉丝白嫖源码福利,请移…...

UE4:使用样条生成随机路径,并使物体沿着路径行走
一、关于样条的相关知识 参考自:样条函数 - 馒头and花卷 - 博客园 三次样条(cubic spline)插值 - 知乎 B-Spline(三)样条曲线的性质 - Fun With GeometryFun With Geometry 个人理解的也不是非常深,但是大概要知道的就是样条具…...
)
计算机组成原理(判断题)
计算机控制器是根据事先编好的程序,根据其指令来进行控制只会每一步骤的操作; 面向主存的双总线结构计算机系统,因在CPU与主存之间增加了一组存储器总线,由于通过存储器总线访存,提高了CPU的访存速度,也减轻…...

error: failed to push some refs to ... 就这篇,一定帮你解决
目录 一、问题产生原因 二、解决办法 三、如果还是出问题,怎么办?(必杀) 一、问题产生原因 当你直接在github上在线修改了代码,或者是直接向某个库中添加文件,但是没有对本地库同步,接着你想…...
DAMA数据管理知识体系指南之数据仓库和商务智能管理
第9章 数据仓库和商务智能管理 9.1简介 数据仓库(Data Warehouse,DW)由两个主要部分构成:首先是一个整合的决策支持数据库,其次是用于收集、清洗、转换、存储来自于各种操作型数据源和外部数据源数据的相关软件程序。两者结合以支持历史的、…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...