极兔一面:10亿级ES海量搜索狂飙10倍,该怎么办?
背景说明:
ES高性能全文索引,如果不会用,或者没有用过,在面试中,会非常吃亏。
所以ES的实操和底层原理,大家要好好准备。
另外,ES调优是一个非常、非常核心的面试知识点,大家要非常重视。
在40岁老架构师 尼恩的读者交流群(50+)中,其ES相关面试题是一个非常、非常高频的交流话题。
近段时间,有小伙伴面试极兔,说遇到一个ES 海量数据 调优的面试题:
ES在承载海量数据,在查询时会存在什么问题?如何优化?
社群中,还遇到过大概的变种:
形式1:10亿级 ES 索引单次查询在5-10s,要调优10倍?怎么办?
形式2:ES 海量索引单次查询速度太慢?如何调优?
形式3:ES 在数据量很大的情况下(数十亿级别)如何提高查询效率?
形式4:后面的变种,应该有很多变种…,具体可以在尼恩社群交流。
这里,对这个面试题系列,尼恩给大家 做一下系统化、体系化的梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,
让面试官爱到 “不能自已、口水直流”。
同时,也一并把这个 题目以及参考答案,收入咱们的《尼恩Java面试宝典》 V48版,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平,实现技术自由。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从这里获取:码云
首先说一下自己对ES性能的认识
首先可以说明一下自己的使用经验:ES 性能并没有想象中那么好的。
下面是一个权威数据,腾讯云的ES集群性能数据:3个节点性能测试,吞吐量中位数 50qps。

ES集群吞吐量的测试数据
参见:Elasticsearch Service 8核32G 3节点集群性能测试 - 产品简介 - 文档中心 - 腾讯云 (tencent.com)
所以,很多时候ES数据量大了,特别是有几亿条数据的时候,实际上性能很差。
在这事上,尼恩就有切实体会。
在2017、2018年左右,尼恩维护一个30个节点的集群架构,亿级文档。 数据规模大概1亿doc, 1TB的容量。
在那个集群上,有的慢搜索,最长rt在5-10s。
你可能会蒙? 怎么那么久, 5~10s?
记得当时候,17年的时候,尼恩为30个节点的es集群做优化,吞吐量 从 5qps 优化到 100qps, 竟然,耗费了1个月
当然,最终,尼恩借用秒杀理论搞定 并发场景的 性能问题,实现了 在 瞬间高并发 流量(1W用户同时访问)的情况下,用户的rt在2秒以内
特别说明,尼恩的秒杀不是一般的秒杀,至少抽取了3个大型项目的工业实操,具体请参考尼恩的秒杀架构。
总之,ES 性能优化,是一个很大的难题。
在解决的时候,不要期待着随手调一个参数、两个参数,就可以万能的应对所有的性能慢的场景。
解决这个问题,要系统化、体系化、全面化思考。
那么:要做到数十亿数据查询,毫秒级响应,有哪些措施呢?
措施一:调大内存,缓存越大越好
调大内存,缓存越大越好,主要指的是Filesystem Cache越大越好。
ES的内存在构成上比较复杂,具体请参考 尼恩3高笔记中的:Data Node 内存溢出的快速恢复方案
为啥要调大Filesystem Cache呢?
ES查询的时候,会有大量的mmap操作,在mmap操作的时候,OS会将磁盘文件里的segment数据,加载到 Filesystem Cache 缓存里面去。
完整Filesystem Cache 的内容,请参见尼恩的葵花宝典,对这部分难点内容的介绍,非常系统和全面。
总之,ES严重依赖于底层的 filesystem cache,你如果给 filesystem cache 更多的内存,尽量让内存可以容纳所有的 idx segment file 索引数据文件,
那么在搜索的时候,就基本都是走内存的,性能会非常高。
具体来说:性能差距究竟可以有多大?
我们之前很多的测试和压测,如果通过磁盘IO完成搜索,一般秒级返回,可能是,1秒、5秒、10秒。
但如果是走 filesystem cache,那么一般来说性能比走磁盘IO要快一个数量级,基本上就是10ms、50ms、100ms、几百毫秒不等。
这里,还可以给面试官说点真实的数据。
假设一套 es 节点有 3 台机器,每台机器,64G内存,总内存就是 64 * 3 = 192G。
每台机器给 es jvm heap 是 32G,留给 filesystem cache 是 32G,
总共集群里给 filesystem cache 的就是 32 * 3 = 96G 内存。
而此时,整个磁盘上索引数据文件,假设在 3 台机器上一共占用了 1T 的磁盘容量,es 数据量是 1T,那么每台机器的数据量是 300G。
此时:
- filesystem cache 的内存才 100G,
- es 数据量是 1T
十分之一的数据可以放内存,十分之9的数据,在查询命中的时候,需要进行临时的磁盘加载。
结论是:十分之9的搜索操作,性能在 秒级。
提升性能的策略是,提升内存命中的比例,两个思路:
- 拼命调大内存。
- 减少索引index 索引大小。
所以:亿级索引、海量索引的调优措施之一,简单来讲,希望全部命中在内存,而不是在磁盘。
或者说:如果 缓存不了全部数据,那就至少可以容纳你的总数据量的一半。
比如:索引数据控制在 100G,如果内存留给 filesystem cache 的是 100G,这样的话,数据几乎全部走内存来搜索,性能非常之高,一般可以在 1 秒以内。
问题是,增大内存是高成本的措施,很多公司,不一定舍得这份投入。
怎么办?
措施二:缩容,缩小index 索引
如果第一点做不到,怎么办呢?
没有必要在一个点死耗,条条道路同罗马,东方不亮西方亮。
增大内存搞不定的话,可以逆向思考。就是:减少索引index 索引大小。
目标就一个:还是把索引加载到内存,或者至少能加载一半。
比如有一行数据,id,name,age … 30 个字段。而搜索的时候,只需要根据 name,age 2个字段来搜索。
这样搜索的时候,其余的28个字段是和搜索无关的,占了90%以上。结果这部分搜索无关数据,硬是占据了 es 机器上的 filesystem cache 的空间,单条数据的数据量越大,就会导致 filesystem cahce 能缓存的数据就越少。
所以,优化的策略就是,减少索引index 数据量。
仅仅写入 es 中要用来检索的少数几个字段就可以了,比如说就写入id,name,age 三个字段。
那么问题来了:在哪里存放全量数据呢?
一般是建议用 es + hbase 架构。es中保存hbase的key, 根据key 去habse取全量数据。
hbase 的特点是适用于海量数据的在线存储,就是对 hbase 可以写入海量数据,但是不要做复杂的搜索。
当然,在hbase中做很简单的一些根据 rowkey或者范围进行查询的这么一个操作就可以了。
用 es + hbase 架构,从 es 中根据 name 和 age 去搜索,拿到的结果可能就 20 个 rowkey,然后根据rowkey(doc id)到 hbase 里去查询每个 doc id 对应的完整的数据,给查出来,再返回给前端。
关于完整 es + hbase 架构, 非常重要,也非常精彩,是一个大大的简历亮点, 关于这个实操,尼恩后面会进行详细介绍,具体请关注群消息。
优化的结果:
然后你从 es 检索可能就花费 100ms,然后再根据 es 返回的 id 去 hbase 里查询,查 20 条数据,可能也就耗费个 100ms,
- 架构整改之前,1T 数据都放 es,会每次查询都是 5~10s
- 架构整改之后,现在可能性能就会很高,每次查询就是 200ms。
结论:性能提升50倍多。
措施三:冷热分离
如果索引的数据量,还是减不下来,怎么办。
比如说,无论怎么进行索引的瘦身,无论怎么进行索引的缩容,索引还是远大于内存。
比如,索引瘦身之后,还是有300G,而 filesystem cache 只有100G,索引大小,远远大于内存大小,怎么办?
条条道路同罗马,东方不亮西方,办法总比问题多。
方法之一:冷热分离
方式之2:数据预热
方式之3:…
怎么做冷热分离呢?
- 冷数据:将大量的访问很少、频率很低的数据,单独写一个索引
- 热数据:将大量的访问很大、频率很高的数据,单独写一个索引
目标还是一个:搜索的时候进行内存IO,而不是磁盘IO。
为啥磁盘IO慢,请参见尼恩的葵花宝典。
这样可以确保热数据在被加载到filesystem os cache 之后.
怎么能保证冷索引,不把热索引从内存寄出去呢?
这个主要是 Linux 内核的 LRU内存淘汰算法导致的,当系统内存不足时,Memcached 和 Redis 都是使用 LRU算法 来淘汰内存的。
尼恩提示,这里很容易出现连环炮面试题: 内存淘汰算法 相关的试题。
LRU(Least Recently Used) 中文翻译是 最近最少使用 的意思,其原理就是:当内存不足时,淘汰系统中最少使用的内存,这样对系统性能的损耗是最小的。用过 Memcached 或者 Redis 的同学应该都了解过 LRU算法。
有关内存淘汰算法,请看尼恩的 caffeine 底层源码和实操,
里边介绍了lru、lfu、window-tiny-lfu三大内存淘汰算法,非常细致。
足以秒晕面试官。
一般来说,由于热数据频繁访问,一般就会比较高的概率留在 filesystem os cache 里,不会让冷数据给冲刷掉。
假设有 6 台机器,2 个索引,一个放冷数据,一个放热数据,每个索引 3 个 shard。
大量的时间是在访问热数据 index,热数据可能就占总数据量的 10%,此时数据量很少,几乎全都驻留 filesystem cache 里面了,就可以通过内存IO完成,而不是磁盘IO,从而实现性能优化。
少量的冷数据访问,可能大量数据是在磁盘上的,此时性能差点,也无所谓了。
冷热分离之后,保障了90%的请求在1s以内。
措施四:数据预热
冷热分离之后,如何确保热数据,一直处于 filesystem cache 里?
有效的措施是:数据预热
怎么预热呢?
简单的说,就是提前访问一下,让数据进入 filesystem cache 里面去。
复杂点的措施,就是做一个专门的缓存预热子系统,就是对热数据每隔一段时间,访问一下,让数据进入 filesystem cache 里面去。
那么,那些是热点数据呢?怎识别热点数据呢?
比如电商秒杀,你可以将平时查看最多的一些商品,比如说 iphone 8,可以提前访问一次,刷到 filesystem cache 里去。搜索的时候,直接从内存里搜索了,没有走磁盘IO,速度很快。
有些热点数据是可以提前预知的,但是更多的热点数据,不实时产生的的,老天爷都不知道什么时候到了,怎么办?
这里涉及到 热点探测系统。
有了,缓存预热子系统可以和热点探测子系统结合,进行 动态的缓存预热。
热点探测子系统和缓存预热子系统怎么结合?具体请参考 尼恩的 《100W级qps 三级缓存架构与实操》架构笔记
提前预热之后,数据已经到了缓存,这样下次别人访问的时候,性能一定会好很多。
举个例子,拿微博来说,一些大V数据,或者一下其他的平时看的人很多的数据,就是使用 热点探测子系统和缓存预热子系统结合的路子,每隔一会儿, 探测到热点数据之后,预热子系统就去搜索一下热数据,刷到 filesystem cache 里去。
后面用户去搜索大V,实际他们就是直接从内存里搜索了,没有走磁盘IO,速度很快。
比如电商秒杀,对于一下未知的热点商品,通过热点探测之后,存预热子系统可以主动访问一次,刷到 filesystem cache 里去。
总之,热点探测子系统和缓存预热子系统的架构,非常重要, 具体请参考 尼恩的 《100W级qps 三级缓存架构与实操》 架构笔记
措施五:索引模型优化
在ES的优化中,索引模型优化、或者说索引结构优化,也很重要。
es 能支持的操作就那么多,很多操作性能低,不要在搜索的时候,执行各种复杂的乱七八糟的操作。
换句话说,对索引进行优化的时候,直接索引最终的结果数据,而不是过程数据、中间数据。
最好是先在 Java 系统里就完成数据的处理,比如说数据的关联,将关联好的数据直接写入 es 中。
搜索的时候,就不需要利用 es 的搜索语法来完成 join 之类的关联搜索了。
对于一些太复杂的操作,比如 join/nested/parent-child 搜索都要尽量避免,性能都很差的。
如果真的有那种操作,尽量在 document 模型设计的时候,写入的时候就完成。
另外对于一些太复杂的操作,比如 join/nested/parent-child 搜索都要尽量避免,性能都很差的。
关于索引结构的优化,有非常多的优化手段,根据自己的场景去定制化使用:
- 字段拉平**:**将复合字段拆分为多个不同字段,查询时减少查询的字段个数。
- 提前建立 mapping:预先建立 mapping,而不是让 ES 自动生成数据类型,加速检索**。**
- 使用 keyword 代替 int/long/numeric
为啥使用 keyword 代替 int/long/numeric?
对于keyword类型的term query,ES使用的是倒排索引。但是numeric类型为了能有效的支持范围查询,它的存储结构并不是倒排索引。
倒排索引在内存里维护了词典 (Term Dictionary)和文档列表(Postings List)的映射关系,倒排索引本身对于精确匹配查询是非常快的,直接从字典表找到term,然后就直接找到了posting list。
措施六:查询优化
查询优化的措施太多,随便说几点,面试官基本就满意了:
- 分页性能优化
- 能用term就不用match_phrase
- 使用过滤器优化查询
然后告诉面试官,这些都要根据业务场景,具体分析。
查询优化1:分页性能优化
es 的分页是较坑的,为啥呢?
举个例子吧,假如每页是 100 条数据,现在要查询第 10页, 分页的时候,总共需要查到 1000条,再截取一个page,
如果有个 3 个 shard,实际上是会把每个 shard 上存储的前 1000 条数据,都查到一个协调节点上,
那么协调节点就有3000 条数据,接着协调节点对这 3000 条数据进行一些合并、处理,再获取到最终第 10 页的 10 条数据。
ES必须得从每个 shard 都查 1000 条数据过来,然后根据你的需求进行排序、筛选等等操作,最后再次分页,拿到里面第 10 页的数据。
翻页的时候,翻的越深,比如 1000,每个 shard 返回的数据就越多,而且协调节点处理的时间越长。
用 es 作分页,前几页就几十毫秒,翻到 10 页或者几十页的时候,基本上就要 5~10 秒才能查出来一页数据了。
那么怎么做分页性能优化?
简单的措施:就是限制翻页的数量,不让翻到很大的page。
为啥可以这么处理呢?实际上,搜索引擎返回的结果,都是模糊匹配的,越到后面,结果越模糊, 对用户的价值不大。
一般情况下,追求前几页,提供给用户价值大的结果。
很多搜索系统,不提供大页码的翻页。
面试官来一个连环炮?业务要求,一定要深度翻页,改怎么处理。
请参见 《尼恩Java面试宝典》的另一个面试题答案:《es 深度翻页的三大绝招》
查询优化2:能用term就不用match_phrase
The Lucene nightly benchmarks show that a simple term query is about 10 times as fast as a phrase query, and about 20 times as fast as a proximity query (a phrase query with slop).
官方说:
- term查询比match_phrase性能要快10倍,
- term查比带slop的match_phrase(proximity——match)快20倍。
能用term就不用match_phrase,举个简单例子
GET /my_index/my_type/_search
{"query": {"match_phrase": {"title": "quick fox"}}
}变为GET /my_index/my_type/_search
{"query": {"term": {"title": "quick fox"}}
}
match_phrase的执行流程如下?
match_phrase查询首先解析查询字符串,产生一个词条列表。
然后会搜索所有的词条,但只保留包含了所有搜索词条的文档,并且词条的位置要邻接。
比如,搜索 quick fox时,如果没有文档含有邻接在一起的quick和fox词条, 一个针对短语quick fox的查询不会匹配我们的任何文档。
proximity match: slop参数告诉match_phrase查询词条能够相隔多远时仍然将文档视为匹配。
我们以一个简单的例子来阐述这个概念。
为了让查询quick fox能够匹配含有quick brown fox的文档,我们需要slop的值为1.
match和match_phrase的区别
match:
只要简单的匹配到了一个term,就会将term对应的文档作为结果返回,扫描倒排索引,扫描到了就完事
match_phrase:
首先要扫描到所有term的文档列表,找到包含所有term的文档列表,然后对每个文档都计算每个term的position,是否符合指定的范围,需要进行复杂的运算,才能判断能否通过slop移动,匹配到这个文档。
match和match_phrase的性能比较
match 的性能比match_phrase和proximity match(有slop的match_phrase)要高得多。
因为后两者都需要计算position的距离
match query比natch_phrase的性能要高10倍,比proximity match(有slop的match phrase)要高20倍。
但是Elasticsearch性能是很强大的,基本都在毫秒级。
match可能是几毫秒,match phrase和proximity match也基本在几十毫秒和几百毫秒之前。
那么,如何对match和match_phrase的性能优化?
具体的措施是:先缩小范围,再打分。
具体来说,优化match_phrase和proximity match的性能,一般就是减少要进行proximity match搜索的文档的数量。
主要的思路就是用match query先过滤出需要的数据,然后在用proximity match来根据term距离提高文档的分数,同时proximity match只针对每个shard的分数排名前n个文档起作用,来重新调整它们的分数,这个过程称之为重打分rescoring。
主要是因为一般用户只会分页查询,只会看前几页的数据,所以不需要对所有的结果进行proximity match操作。也就是使用match + proximity match同时实现召回率和精准度。
默认情况下,match也许匹配了1000个文档,proximity match需要对每个doc进行一遍运算,判断能否slop移动匹配上,然后去贡献自己的分数。
但是很多情况下,match出来也许是1000个文档,其实用户大部分情况下都是分页查询的,可以就看前5页,每页就10条数据,也就50个文档。
所以,proximity match只要对前50个doc进行slop移动去匹配,去贡献自己的分数即可,不需要对全部1000个doc都去进行计算和贡献分数。
这个时候通过window_size这个参数即可实现限制重打分rescoring的文档数量。示例:
GET /test_index/_search
{"query": {"match": {"test_field": "java spark"}},"rescore": {"query": {"rescore_query": {"match_phrase": {"test_field": {"query": "java spark","slop": 10}}}},"window_size": 50}
}
查询优化3:使用过滤器优化查询
elasticsearch提供了一种特殊的缓存,即过滤器缓存(filter cache),用来储存过滤器的结果.
被缓存的过滤器不需要消耗过多的内存,因为他们只储存了哪些文档能与过滤器相匹配的相关信息,而且可供后续所有与之相关的查询重复使用,从而极大的提高了查询性能
执行下面这个查询:
{"query":{"bool":{"must":[{"term":{"name":"joe"} },{"term":{"year":1981}}]}}
}
该查询能查询出满足指定姓名和出生年代条件的足球运动员,只有同时满足两个条件的查询才可以被缓存起来。
优化这个查询:
人名有太多可能性,它不是完美的缓存候选对象,而年代是,我们使用另一种查询方法,该查询组合了查询类型与过滤器:
{"query":{"filtered":{"query":{"term":{"name":"joe"}},"filter":{"term":{"year":1981}}}}
}
第一次执行该查询以后,过滤器会被es缓存起来,如果后续的其他查询也要使用该过滤器,则她会被重复使用,避免es重复加载相关数据
40岁老架构师尼恩提示
问题回答到这里,已经30分钟过去了,面试官已经爱到 “不能自已、口水直流” 啦。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从这里获取:码云
参考文献:
《尼恩的10Wqps秒杀架构笔记》
《尼恩的100Wqps三级缓存架构笔记》
《横扫全网ElasticSeach高可用实操架构笔记》
https://blog.csdn.net/whzhaochao/article/details/49126037
https://blog.csdn.net/wuzhangweiss/article/details/101156910
https://blog.csdn.net/Jerome_s/article/details/44992549
推荐阅读:
《响应式圣经:10W字,实现Spring响应式编程自由》
《全链路异步,让你的 SpringCloud 性能优化10倍+》
《Linux命令大全:2W多字,一次实现Linux自由》
《阿里一面:你做过哪些代码优化?来一个人人可以用的极品案例》
《网易二面:CPU狂飙900%,该怎么处理?》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《场景题:假设10W人突访,你的系统如何做到不 雪崩?》
《2个大厂 100亿级 超大流量 红包 架构方案》
《Nginx面试题(史上最全 + 持续更新)》
《K8S面试题(史上最全 + 持续更新)》
《操作系统面试题(史上最全、持续更新)》
《Docker面试题(史上最全 + 持续更新)》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《Flux、Mono、Reactor 实战(史上最全)》
《sentinel (史上最全)》
《Nacos (史上最全)》
《TCP协议详解 (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《nacos高可用(图解+秒懂+史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
《单例模式(史上最全)》
《红黑树( 图解 + 秒懂 + 史上最全)》
《分布式事务 (秒懂)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
《Docker原理(图解+秒懂+史上最全)》
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
《Zookeeper Curator 事件监听 - 10分钟看懂》
《Netty 粘包 拆包 | 史上最全解读》
《Netty 100万级高并发服务器配置》
《Springcloud 高并发 配置 (一文全懂)》
相关文章:
极兔一面:10亿级ES海量搜索狂飙10倍,该怎么办?
背景说明: ES高性能全文索引,如果不会用,或者没有用过,在面试中,会非常吃亏。 所以ES的实操和底层原理,大家要好好准备。 另外,ES调优是一个非常、非常核心的面试知识点,大家要非…...
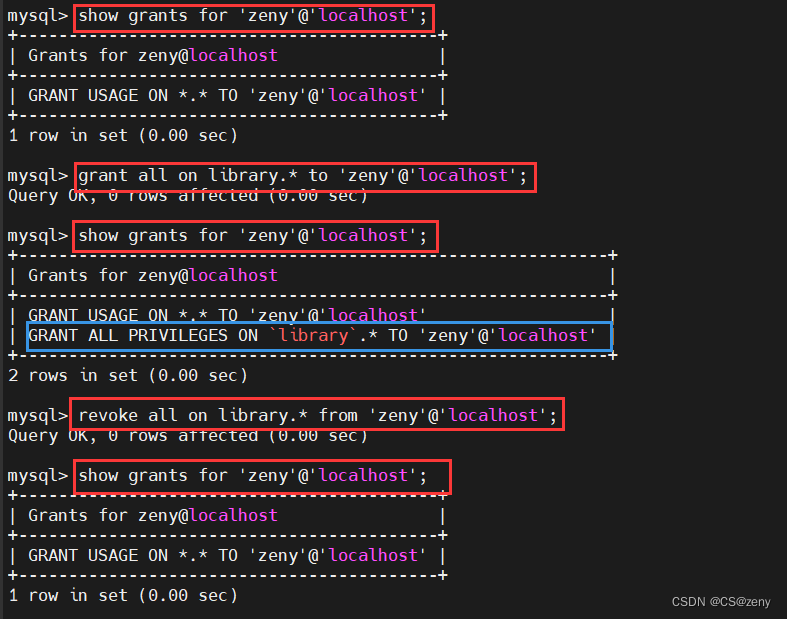
【Mysql基础 —— SQL语句(一)】
文章目录概述使用启动/停止mysql服务连接mysql客户端数据模型SQLSQL语句分类DDL数据库操作表操作查询创建数据类型修改删除DML添加数据修改数据删除数据DQL基础查询条件查询聚合函数分组查询排序查询分页查询执行顺序DCL管理用户权限控制概述 数据库(Database&#…...
 | 机试题算法思路)
华为OD机试 - 新员工座位安排系统(Python) | 机试题算法思路
最近更新的博客 华为OD机试 - 招聘(Python) | 备考思路,刷题要点,答疑 【新解法】华为OD机试 - 五键键盘 | 备考思路,刷题要点,答疑 【新解法】华为OD机试 - 热点网络统计 | 备考思路,刷题要点,答疑 【新解法】华为OD机试 - 路灯照明 | 备考思路,刷题要点,答疑 【新解…...

MySQL - 介绍
前言 本篇介绍认识MySQL,重装mysql操作 如有错误,请在评论区指正,让我们一起交流,共同进步! 本文开始 1.什么是数据库? 数据库: 一种通过SQL语言操作管理数据的软件; 重装数据库的卸载数据库步骤 : ① 停止MySQL服…...

ChatGPT国内镜像站初体验:聊天、Python代码生成等
ChatGPT国内镜像站初体验,聊天、Python代码生成。 (本文获得CSDN质量评分【92】)【学习的细节是欢悦的历程】Python 官网:https://www.python.org/ Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单………...
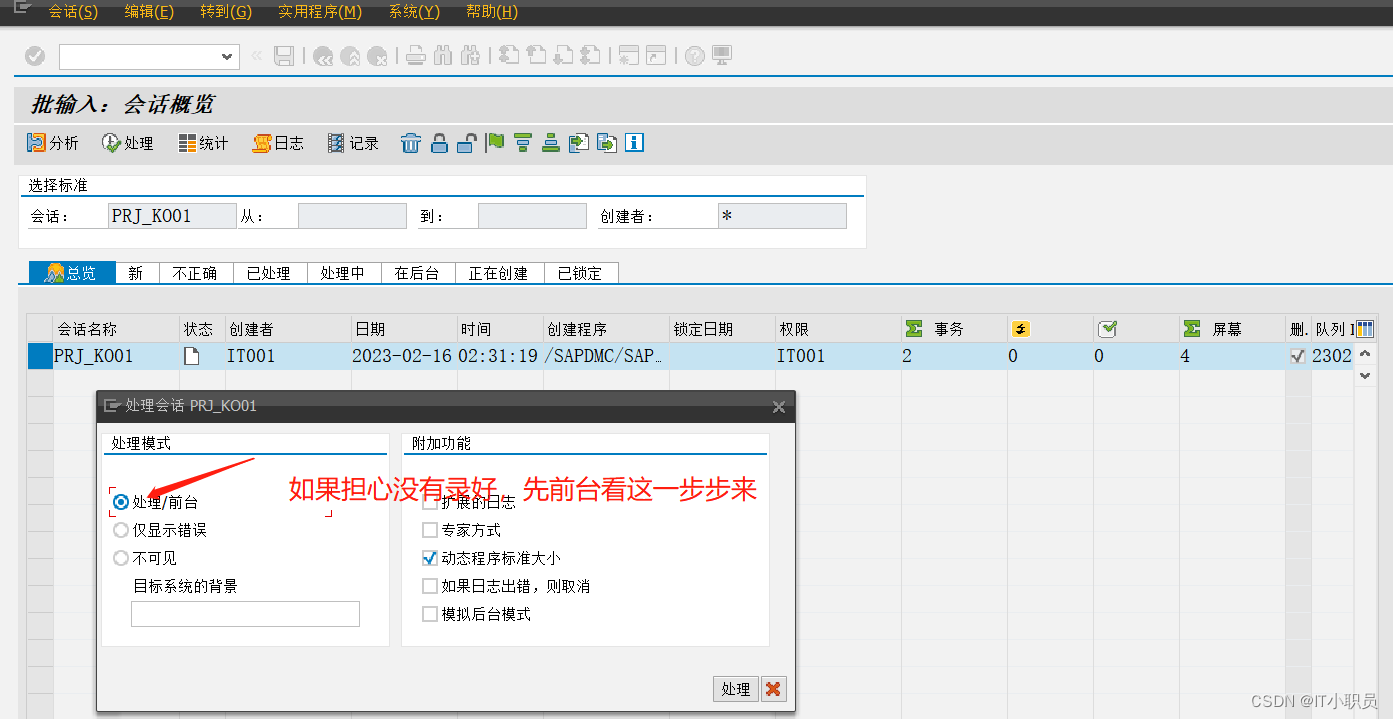
SAP数据导入工具(LSMW) 超级详细教程(批量导入内部订单)
目录 第一步:记录批导步骤编辑数据源对应字段 第二步:维护数据源 第三步:维护数据源对应字段(重要) 第四步:维护数据源关系。 第五步:维护数据源与导入字段的对应关系。 第六步࿰…...
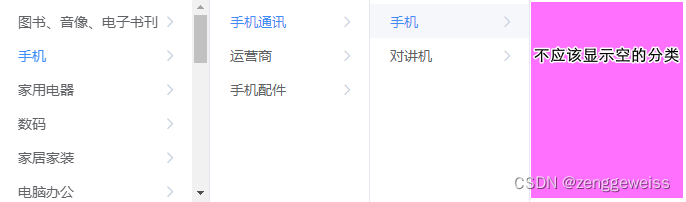
第9天-商品服务(电商核心概念,属性分组开发及分类和品牌的级联更新)
1.电商核心概念 1.1.SPU与SKU SPU:Standard Product Unit(标准化产品单元) 是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个 产品的特性。 决定商品属性的值 SKU:Stock…...

动漫人物眼睛画法
本期的动漫绘画课程教大家来学习动漫人物眼睛画法,结合板绘软件从草稿开始一步步教你画出动漫人物眼睛,不用报动漫培训班也能学会,快来跟着本期的动漫人物眼睛画法教程试试吧! 动漫人物眼睛画法步骤教程: 注意&#x…...

张晨光-JAVA零基础保姆式JDBC技术教程
JDBC文档 JDBC概述 JDBC概述 Java DataBase Connectivity Java 数据库连接技术 JDBC的作用 通过Java语言操作数据库,操作表中的数据 SUN公司为**了简化、**统一对数据库的操作,定义了一套Java操作数据库的规范,称之为JDBC JDBC的本质 是官方…...
)
华为OD机试 - 最多提取子串数目(Python)
最多提取子串数目 题目 给定由 [a-z] 26 个英文小写字母组成的字符串 A 和 B,其中 A 中可能存在重复字母,B 中不会存在重复字母 现从字符串 A 中按规则挑选一些字母,可以组成字符串 B。 挑选规则如下: 1) 同一个位置的字母只能被挑选一次 2) 被挑选字母的相对先后顺序不…...

LeetCode-1237. 找出给定方程的正整数解【双指针,二分查找】
LeetCode-1237. 找出给定方程的正整数解【双指针,二分查找】题目描述:解题思路一:双指针。首先我们不管f是什么,即function_id等于什么不管。但是我们可以调用customfunction中的f函数,然后我们遍历x,y(1 < x, y &l…...

广度优先搜索算法 - 迷宫找路
广度优先搜索算法1 思考问题1.1 这个迷宫需不需要指定入口和出口?2 先粗略实现2.1 源码2.2 源码解释3 优化代码3.1 优化读取文件部分3.2 增加错误处理4 再优化-让程序变得更加灵活4.1 用户外部可以循环输入入口和出口5 完整代码这是一个提问者的提出的问题ÿ…...

泡脚材料简记
文章目录一般条件中药包(药粉)泡脚丸中药包(药材)艾叶生姜益母草藏红花食盐花椒白醋柠檬藿香泡脚私方紫苏叶、白术、白芍、黄芪、青皮、柴胡、夜交藤、丹参、当归,每种各10g艾叶、花椒、肉桂、桂枝、红花干姜30克、小茴…...
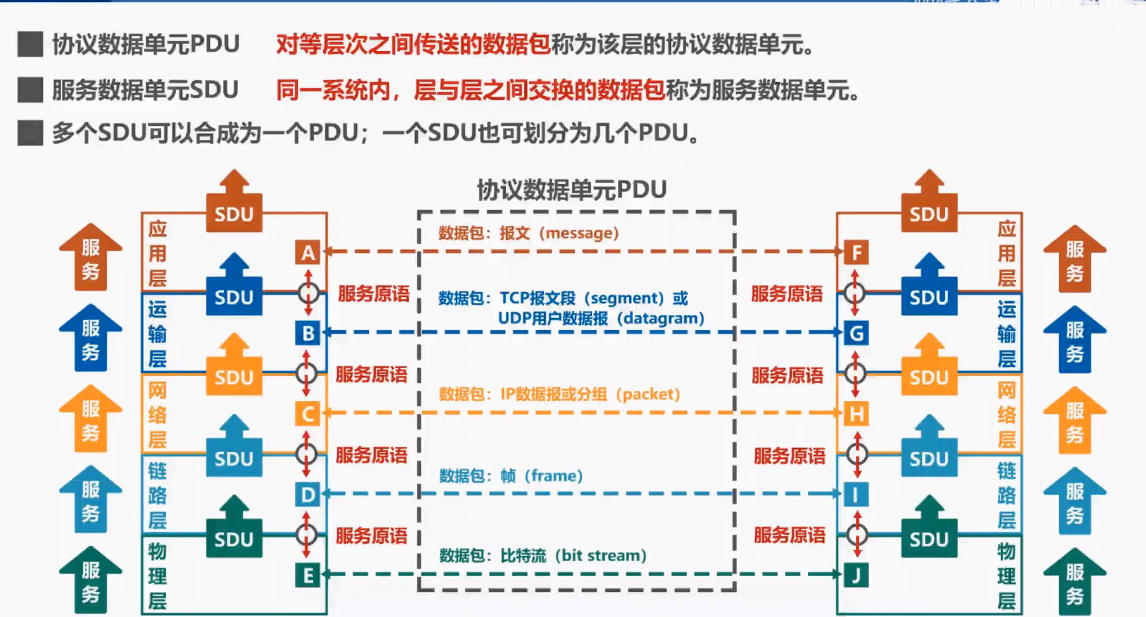
【计算机网络】因特网概述
文章目录因特网概述网络、互联网和因特网互联网历史与ISP标准化与RFC因特网的组成三种交换方式电路交换分组交换和报文交换三种交换方式的对比与总结计算机网络的定义和分类计算机网络的定义计算机网络的分类计算机网络的性能指标速率带宽吞吐量时延时延带宽积往返时间利用率丢…...

STC单片机 VS/HX1838红外接收和发送实验
STC单片机 VS/HX1838红外接收和发送实验 📌相关篇《STC单片机获取红外解码从串口输出》🔨所使用的红外接收头VS1838 📋VS1838引脚定义🌿5MM发射头,940nm红外发射二极管 红外遥控发射头。(外观看起来和普通的发光二极管没有什么差异,购买时需要注意确认)。 🔰采用的…...

前端开发常用案例(一)
前端开发常用案例1.实现三角形百度热榜样式分页效果小米商城自动轮播图效果二级下拉菜单效果时间轴效果展示音乐排行榜效果鼠标移入文字加载动画鼠标悬停缩放效果1.实现三角形 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8…...

Linux 日志查找常用命令
1.1 cat、zcat cat -n app.log | grep "error":查询日志中含有某个关键字error的信息,显示行号。 cat -n app.log | grep "error" --color:查询日志中含有某个关键字error的信息,显示行号,带颜色…...
CleanMyMac4.12.5最新版安装下载教程
告别硬盘空间不足,让您的Mac极速如新CleanMyMac是一款强大的 Mac 清理、加速工具和健康卫士,让您的 Mac 加快启动速度。CleanMyMac是一款专业的Mac清理软件,可智能清理mac磁盘垃圾和多余语言安装包,快速释放电脑内存,轻…...

RFID射频识别技术(四) RFID高频电路基础|课堂笔记|10月11日
2022年10月11日 week7 目录 第四讲: RFID高频电路基础 一、RLC(串联)电路的阻抗...
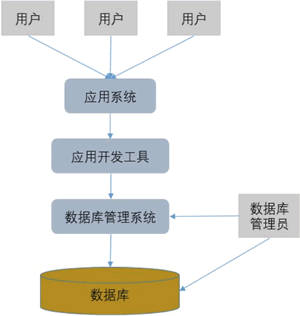
数据库系统是什么?它由哪几部分组成?
数据库系统(Database System,DBS)由硬件和软件共同构成。硬件主要用于存储数据库中的数据,包括计算机、存储设备等。软件部分主要包括数据库管理系统、支持数据库管理系统运行的操作系统,以及支持多种语言进行应用开发…...

解决 DVWA 联合注入报错:Illegal mix of collations for operation ‘UNION‘ 全指南
一、问题背景在 DVWA 靶场进行 SQL 联合注入测试时,很多小伙伴都会遇到一个经典报错:plaintextIllegal mix of collations for operation UNION这个报错的本质原因非常明确:执行UNION操作时,参与联合查询的多个结果集的字符集&…...
)
OpenGL天空盒实战:从零搭建到环境反射效果(附完整代码)
OpenGL天空盒实战:从零搭建到环境反射效果(附完整代码) 在3D图形开发中,天空盒技术是实现环境氛围营造的基础手段。想象一下,当你站在游戏场景中抬头望去,远处的山脉、流动的云层和深邃的星空共同构成了沉浸…...

基于模糊控制的改进DWA算法功能详解
改进动态窗口DWA算法,模糊控制自适应调整评价因子权重,matlab代码 这段代码是一个基于动态窗口法(Dynamic Window Approach,DWA)的路径规划算法的实现。下面我将对代码进行分析,并解释算法的优势、需要注意…...

利用快马平台快速搭建esp8266物联网原型,十分钟完成温湿度监测系统
利用快马平台快速搭建esp8266物联网原型,十分钟完成温湿度监测系统 最近在做一个智能家居的小项目,需要实时监测房间的温湿度数据。作为硬件小白,我选择了性价比超高的ESP8266开发板,配合DHT11传感器就能实现基础功能。但最让我头…...

Blender 3MF插件:让3D打印设计流程更智能的5个关键步骤
Blender 3MF插件:让3D打印设计流程更智能的5个关键步骤 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 还在为3D打印文件格式转换而烦恼吗?想象一…...

Xinference 集群部署实战:从零到生产环境的完整指南
1. 为什么选择Xinference集群? 在AI模型推理领域,我们常常面临两个核心痛点:单机性能瓶颈和资源利用率低下。想象一下,你正在运行一个大型语言模型,每次推理都要等待十几秒,同时GPU利用率却只有30%左右——…...

Snap.Hutao:如何用这款开源工具箱优化你的原神游戏体验?
Snap.Hutao:如何用这款开源工具箱优化你的原神游戏体验? 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trendin…...
:继承与多态——is-a关系彻底理解)
Python从入门到精通(第17章):继承与多态——is-a关系彻底理解
开头导语 这是本系列第17章。继承和多态是面向对象最核心的概念,但也是被误解最多的概念。继承的本质是“复用”,而不是“is-a”的语言描述;多态的本质是“同一接口,不同实现”,而不是“子类Override父类方法”这个动作本身。本章会从实际场景出发,讲清楚继承的适用边界…...

3步高效获取国家教育平台电子课本:tchMaterial-parser智能解析工具全攻略
3步高效获取国家教育平台电子课本:tchMaterial-parser智能解析工具全攻略 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本…...

提升五倍效率:基于快马平台优化openclaw数据采集工作流
最近在做一个数据采集项目时,发现传统的手动编写爬虫脚本效率实在太低了。每次遇到反爬机制或者需要调整采集策略时,都要花大量时间修改代码。后来尝试用openclaw结合InsCode(快马)平台来优化工作流,效率直接提升了五倍多,这里分享…...