如何成为顶级开源项目的贡献者
概述
对于程序员来讲,成为顶级开源项目的贡献者是一件有意义的事,当然,这也绝非易事。如果你正从事人工智能有关的工作,那么你一定了解诸如Google Tensorflow,Facebook Pytorch这样的开源项目。下面我们就说一说如何成为这些顶级的开源项目的Contributor。
准备
1.首先你必须成为github的使用者,并已经熟悉了github上托管代码的基本逻辑。
2.对于顶级的开源项目,一般需要你去签署一份Contributor License Agreement(简称CLA),例如Tensorflow项目,个人签署TF individual CLA,公司签署TF corporate CLA,Pytorch中的部分项目则需要签署Facebook CLA,这样你的代码才允许被接收。
3.让你编写的代码风格更规范,一般的开源项目都要求为Google Python Style,即使是Pytorch都是遵循该规范,更不要说Google自家的Tensorflow了。
4.你贡献的代码往往由类或者函数构成(文档贡献除外),因此你需要单元测试程序,它和代码注释一样,是代码共享过程中必不可少的一部分。没有它,即使你的代码正确无误也不会被merge,最终还是会被要求提供单元测试脚本。
5.很多开源项目要求你的每个py脚本都要以许可证书开头,比如Tensorflow,这是它的python许可证书示例: Python license example,当然,这很简单。
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# =============================================================================
工具
接下来我们将介绍相关工具的使用,它能够有效的帮助我们来完成贡献前的准备工作,比如:代码规范和单元测试等。
代码规范工具
为了满足代码满足Google Style的要求,我们首先需要一个代码规范检测工具,这里我们使用官方推荐的pylint。
安装:
pip install pylint
使用:
# 使用pylint检测脚本代码,默认将按照PEP8标准
# 这里我们需要指定配置文件,即按照Google Style标准
# myfile.py代表你写好的python脚本文件
pylint --rcfile=pylintrc myfile.py
pylintrc内容请参照: pylintrc
又因为我们初始写的代码往往随意性过强,可能直接用pylint需要修改的地方太多,可能对你幼小的心灵造成重创,因此,这里也带来很多开源项目推荐的另外一款工具:black,它能够直接帮你修改代码中出现的基本问题(仍然存在很多问题无法被判定,需要使用pylint检测)。
安装:
pip install black
使用:
# 这里的-l代表代码的每行最大长度
# 默认是88,但是Google Style要求为80
# 因此这里指定为80
black myfile.py -l 80
代码样式示例:
def my_op(tensor_in, other_tensor_in, my_param, other_param=0.5,output_collections=(), name=None):"""My operation that adds two tensors with given coefficients.Args:tensor_in: `Tensor`, input tensor.other_tensor_in: `Tensor`, same shape as `tensor_in`, other input tensor.my_param: `float`, coefficient for `tensor_in`.other_param: `float`, coefficient for `other_tensor_in`.output_collections: `tuple` of `string`s, name of the collection tocollect result of this op.name: `string`, name of the operation.Returns:`Tensor` of same shape as `tensor_in`, sum of input values with coefficients.Example:>>> my_op([1., 2.], [3., 4.], my_param=0.5, other_param=0.6,output_collections=['MY_OPS'], name='add_t1t2')[2.3, 3.4]"""with tf.name_scope(name or "my_op"):tensor_in = tf.convert_to_tensor(tensor_in)other_tensor_in = tf.convert_to_tensor(other_tensor_in)result = my_param * tensor_in + other_param * other_tensor_intf.add_to_collection(output_collections, result)return result
output = my_op(t1, t2, my_param=0.5, other_param=0.6,output_collections=['MY_OPS'], name='add_t1t2')
单元测试工具
·单元测试对于团队开发十分重要,是检验代码质量的重要依据,因此你的每一份完整的代码都要配备单元测试脚本。这里我们使用python主流的单元测试工具unittest。
· 安装:
pip install unittest
使用: 这里只去演示核心的使用方法,更具体的内容请参照unittest文档
# 导入unittest工具包
import unittest# 我们首先要建立一个测试类,它将包含你所有需要进行测试的函数
# 这个类不使用__init__(self),但可以使用setUp(self)来定义公有部分
# 它需要继承unittest.TestCase, 类名往往也建议以Test开头
class TestStringMethods(unittest.TestCase):# 类的里面依次是你需要进行测试的函数# 这些函数建议以test_开头# 这些函数一般情况不设置参数,而是直接在函数中具体化需要的参数# 当然你也可以设置原始的参数,然后在外部具体化参数并调用该函数# 在测试函数中必须存在assert...来断定测试结果# 常用的assert...包括: assertEqual, assertTrue, assertFalse,# assertRaises, assertIn, assertNotIn, assertIs, assertIsNot...def test_upper(self,):# 使用assertEqual判断两个字符串是否相等self.assertEqual("foo".upper(), "FOO",)def test_isupper(self,):# 使用assertTrue/False断定条件为真/假self.assertTrue("FOO".isupper())self.assertFalse("Foo".isupper())def test_split(self,):# 设定任意输入s = "hello world"# 使用assertIn断定列表包含关系self.assertIn(s.split(), [["hello", "world"]],)# 注意:这里with self.assertRaises来断定异常with self.assertRaises(TypeError):s.split("asd")# 这里是主函数,如果使用python运行该脚本测试,则必须存在
# 如果使用pytest(后面会介绍),则可以省略
if __name__ == "__main__":# 使用unittest.main运行所有继承unittest.TestCase的类unittest.main()
装饰器的使用: unittest最常使用方法之一就是类/函数的装饰器。
# 对于一些特殊需要强制跳过的测试的类/函数使用下方装饰器,但你必须说明原因
# @unittest.skip("长得太帅,不需要测试,给我跳过!")# 如果条件为真,则该测试被强制跳过。比如:检测GPU是否可用
# @unittest.skipIf(TEST_CUDA, "CUDA available")# 除非条件为真,否则该测试被强制跳过。比如: 检测某些依赖包是否安装
# @unittest.skipUnless(has_unittest, "unittest dependencies are not installed")# 函数异常测试的表达方式,函数出现异常则测试通过,比之前说的内部异常粒度更大
# @unittest.expectedFailureimport torch
try:import unittest
except ImportError:has_unittest = False
else:has_unittest = Trueif torch.cuda.is_available():TEST_CUDA = True
else:TEST_CUDA = False# 条件为真,不跳过
@unittest.skipUnless(has_unittest, "unittest dependencies are not installed")
# 条件为真,跳过;条件为假,不跳过
@unittest.skipIf(TEST_CUDA, "CUDA available")
class TestStringMethods(unittest.TestCase):def test_upper(self,):self.assertEqual("foo".upper(), "FOO",)@unittest.skip("长得太帅,不需要测试,给我跳过!")def test_isupper(self,):self.assertTrue("FOO".isupper())self.assertFalse("Foo".isupper())@unittest.expectedFailuredef test_split(self,):s = "hello world"self.assertIn(s.split(), [["hello", "world"]],)# 这里预计抛出异常,但实际没有异常,本质上这也算一种异常# 可以使用@unittest.expectedFailurewith self.assertRaises(TypeError):s.split("ZMZ")if __name__ == "__main__":unittest.main()
运行你的测试脚本:
# 建议使用pytest执行测试脚本,你的python中往往自带这个工具包
# 这时你不必写下主函数,并且他的输出形式更美观
pytest test_myfile.py
输出效果:
======================== test session starts =========================
platform linux -- Python 3.7.3, pytest-5.0.1, py-1.8.0, pluggy-0.12.0
rootdir: /root
plugins: remotedata-0.3.1, celery-4.3.0, doctestplus-0.3.0, arraydiff-0.3, openfiles-0.3.2
collected 3 itemstest_myfile.py sx. [100%]=========== 1 passed, 1 skipped, 1 xfailed in 0.34 seconds ===========
真实单元测试脚本请参考Pytorch Tests和Tensorflow Tests
过程
在准备成为贡献者之前,要确保你已经能够熟练使用该项目。进而明确你要贡献源码的类型,是Fix Bug还是Implement New Feature(实现新特性)。当然,对一个新手贡献者来讲,Fix Bug是你的不二选择。除非你已经通过自己的实践,明确了要做贡献的具体内容,否则,建议你需要遵循以下步骤:
第一步:
从开源项目的Github Issues中寻找open的问题,这里是Tensorflow Issues, Pytorch Issues,仔细阅读大家提出的问题,这将帮你在寻找问题上节约大量时间,同时你可以在讨论区看到有关技术的讨论或已经提交的PR,进一步明确自己是否应该参与该问题的解决。(有很多开源项目的issue会带有"contributions welcome"的标签,可以优先看一看。)
第二步:
当你明确了自己要解决的问题,在正式写代码之前,你需要fork这个开源项目到你自己的Github仓库,然后再将该仓库clone到自己指定的服务器上,这样最后你才可以提交PR。
# 例如:
git clone https://github.com/AITutorials/tensorflow.git
到这里你可以通过git remote -v发现我们只与自己远程仓库进行了连接(origin/master)。
此时我们还需要与开源项目的远程仓库建立连接(upstream/master)
# 以tensorflow为例建立连接
git remote add upstream https://github.com/tensorflow/tensorflow.git# 查看到upstream
git remote -v
然后你就需要建立一个自己的分支,当然,你可以先查看一下远程的分支情况
# 查看远程分支
git branch -a# 创建自己的远程分支cnsync
git checkout -b cnsync
第三步:
通过第二步你已经拿到了项目的源码并创建了自己分支,这时就要开始你的表演,coding + review,你之前准备的代码规范工具和单元测试工具将派上用场。
第四步:
提交代码你的代码并在github中创建一个PR。
# 把内容添加到暂存区
git add .# 提交更改的内容
git commit -m "添加你的改变说明"# push到自己的远程仓库
git push origin cnsync
注意:这里虽然你只push到了自己的远程仓库,但其实你的远程仓库和源项目的仓库是连接的。也就是说,此时你可以通过操作自己的远程仓库决定是否将创建一个源项目的PR(这些过程可以在你刚刚fork的项目页面中实现,包括填写PR的title和comment,有时你也需要在title中添加一个标记,如[Draft]/[WIP]/[RFR]等等)。
第五步:
耐心的等待,如果你是PR是一个Ready For Review的状态,它将很快进入自动化测试的流程以及评委会的介入,不久后你将收到一些反馈,你的代码方案可能被采纳,可能需要更多的修改或测试。
相关文章:

如何成为顶级开源项目的贡献者
概述 对于程序员来讲,成为顶级开源项目的贡献者是一件有意义的事,当然,这也绝非易事。如果你正从事人工智能有关的工作,那么你一定了解诸如Google Tensorflow,Facebook Pytorch这样的开源项目。下面我们就说一说如何成…...

Threads and QObjects
QThread inherits QObject. It emits signals to indicate that the thread started or finished executing, and provides a few slots as well. QThread 派生于 QObject。QThread 会发射信号通知线程启动或终止执行任务,并且也会提供槽函数使用。 More interest…...

Tcp是怎样进行可靠准确的传输数据包的?
概述 很多时候,我们都在说Tcp协议,Tcp协议解决了什么问题,在实际工作中有什么具体的意义,想到了这些我想你的技术会更有所提升,Tcp协议是程序员编程中的最重要的一块基石,Tcp是怎样进行可靠准确的传输数据…...
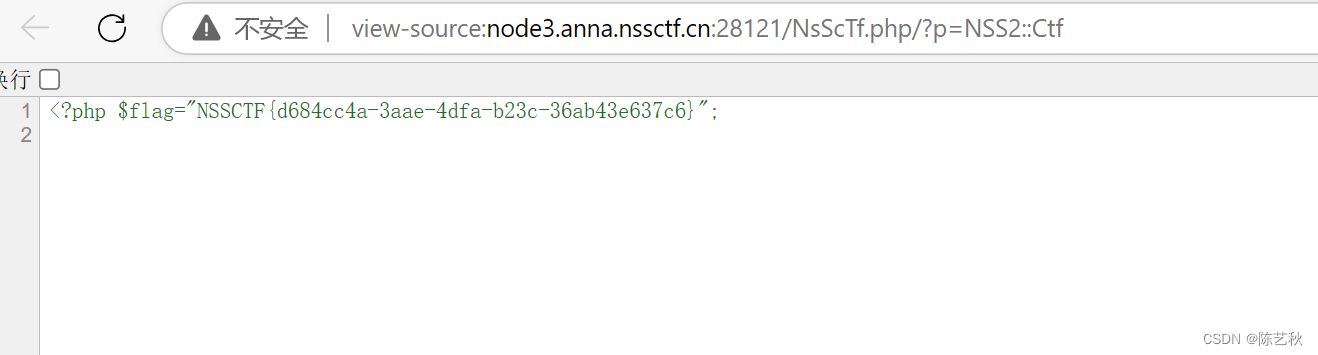
[SWPUCTF 2022 新生赛]numgame
这道题有点东西网页一段计算框,只有加和减数字,但是永远到大不了20,页面也没啥特别的,准备看源码,但是打不开,我以为是环境坏掉了,看wp别人也这样,只不过大佬的开发者工具可以打开&a…...

java异常机制分析
java异常机制分析 本文实例分析了java的异常机制,分享给大家供大家参考。相信有助于大家提高大家Java程序异常处理能力。具体分析如下: 众所周知,java中的异常(Exception)机制很重要,程序难免会出错,异常机制可以捕获…...

浅谈Python中的内存管理 程序的内存布局
Python中的内存管理 Python 的内存管理是通过私有堆空间来实现的。这个私有堆内存中存储了所有 Python 对象和数据结构。Python 的解释器自身则拥有对堆空间的访问权,程序员不能直接访问这个私有堆,但可以通过解释器的 API 来进行某些操作。 以下是 Py…...

(具体解决方案)训练GAN深度学习的时候出现生成器loss一直上升但判别器loss趋于0
今天小陶在训练CGAN的时候出现了绷不住的情况,那就是G_loss(生成器的loss值)一路狂飙,一直上升到了6才逐渐平稳。而D_loss(判别器的loss值)却越来越小,具体的情况就看下面的图片吧。其实这在GAN…...
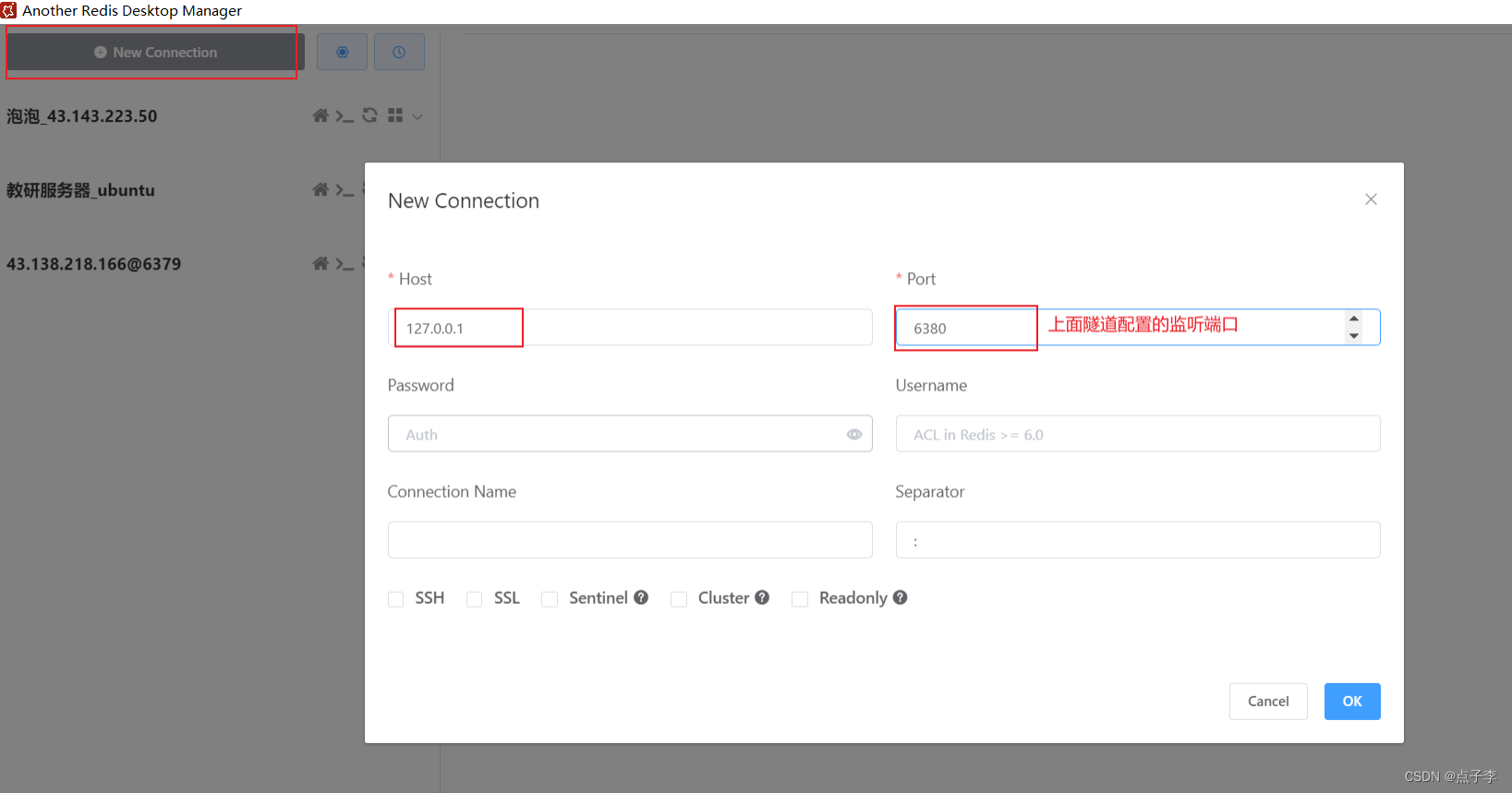
Redis 安装以及配置隧道连接
目录 1.CentOS 1. 安装Redis 2. Redis 启动和停⽌ 3. 操作Redis 2.Ubuntu 1. 安装Redis 2. Redis 启动/停⽌ 3. 操作 Redis 3.开启隧道 3.1 Xshell 配置隧道 3.2 windTerm 配置隧道 3.3 FinalShell配置隧道 4.可视化客户端连接 Another Redis Desktop Manager 1.Cen…...
FFmpeg 使用总结
FFmpeg 简介 FFmpeg的名称来自MPEG视频编码标准,前面的“FF”代表“Fast Forward”,FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。可以轻易地实现多种视频格式之间的相互转换。包括如下几个部分…...
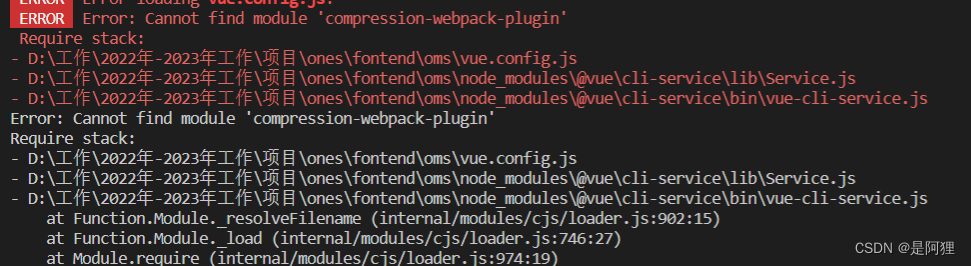
出现Error: Cannot find module ‘compression-webpack-plugin‘错误
错误: 解决:npm install --save-dev compression-webpack-plugin1.1.12 版本问题...
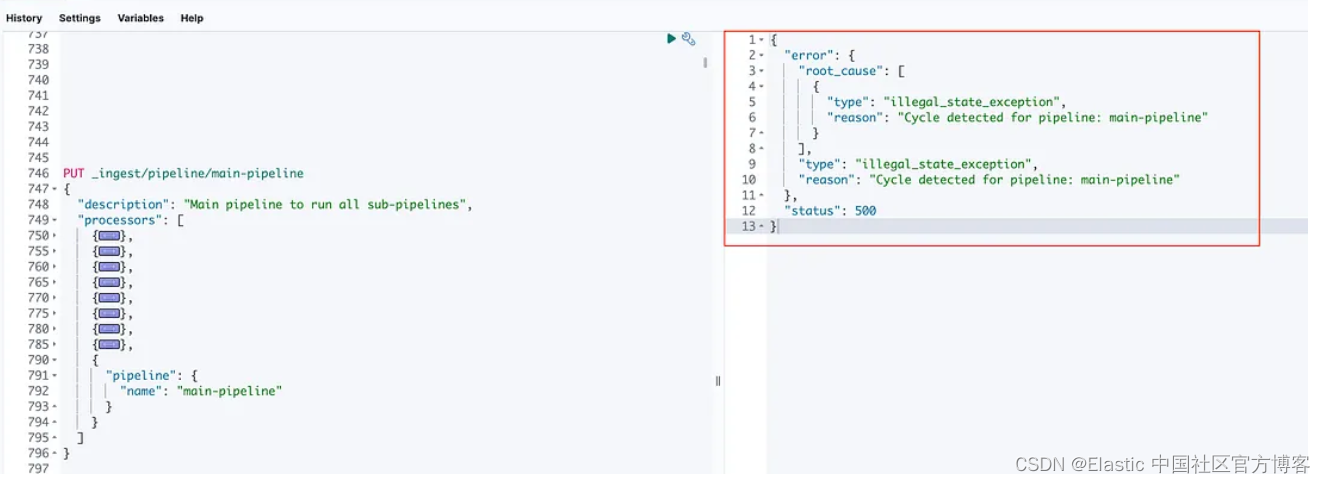
Elasticsearch 摄取管道 — 检测到管道的死循环
在数据处理和摄取领域,管道在组织和自动化数据从源到目的地的流动方面发挥着至关重要的作用。 管道是数据按顺序通过的一系列处理阶段,每个阶段负责特定任务。 然而,有时,管道可能会遇到一个重大挑战,称为 “Cycle det…...

C# ListBox自动滚动方法
1、方法1:添加记录后,选择最后一条记录,让滚动条滚动到底部,再自动取消 listBox1.Items.Add(t ":a good day"); listBox1.SelectedIndex listBox1.Items.Count - 1; listBox1.SelectedIndex -1; //是否取消选中行…...
Promise + XHR实现请求数据)
使用(Ajax原理)Promise + XHR实现请求数据
使用Promise XHR获取省份列表 步骤: * 1. 创建Promise对象 * 2. 执行XHR异步代码,获取省份列表 * 3. 关联成功或失败函数,做后续处理 代码示例 <script>// 1. 创建Promise对象const p new Promise((resolve,reject) > {// 2. 执行…...
【HTML】<input>
分类 text password number button reset submit hidden radio checkbox file image color range tel email(火狐有校验,360浏览器无校验。) url datetime(火狐、360浏览器不支持) search date、month、week、time、da…...

数据结构中一些零碎且易忘的知识点
树 并查集: 并查集的应用: 判断连通性、判环Kruskal算法排序并查集 并查集的存储方式 逻辑:双亲表示法的树存储:数组 并查集的时间复杂度(m为并查集长度) find:优化前为 O ( m ) O(m) O(m)&…...
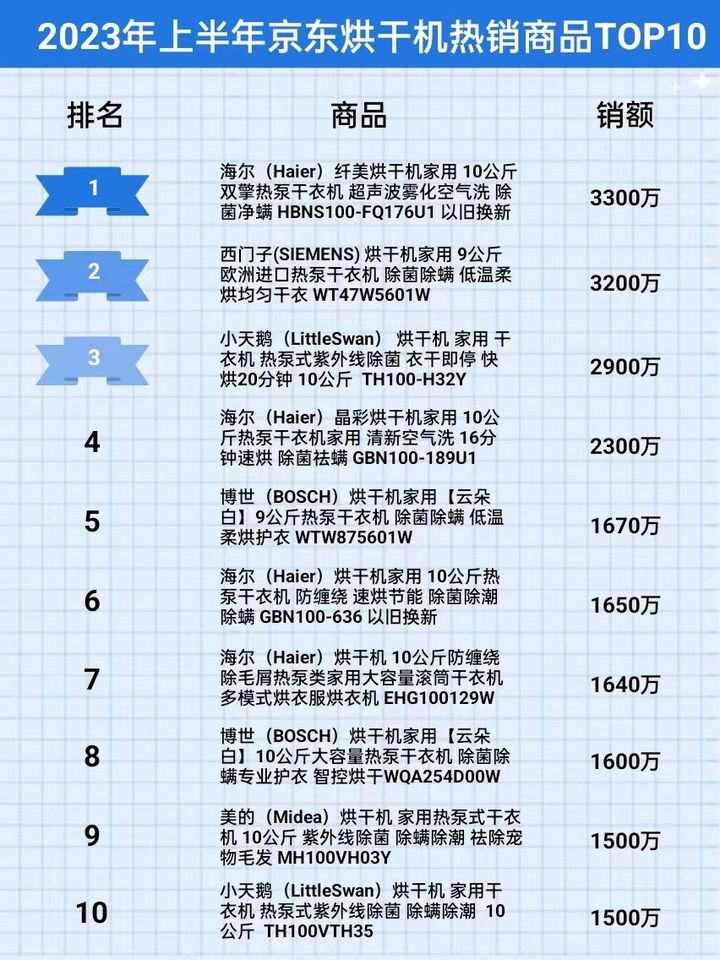
2023上半年京东烘干机行业品牌销售排行榜(京东商品数据)
随着人们消费水平的提高,追求健康品质消费的用户越来越多,这样的消费升级为市场的发展带来很大的动力。同时,随着洗衣机市场趋向饱和,增长趋于平缓,更新换代和结构升级成为行业的主旋律。 在这一市场背景下࿰…...

ADS版图画封装学习笔记
ADS版图画封装 因为晶体管ATF54143在ADS中是没有封装的,所以要在ADS中画ATF54143的封装,操作步骤如下: 在ADS中新建layout,命名为ATF54143_layout, 根据datasheet知道封装的大小,进行绘制 在layout的con…...
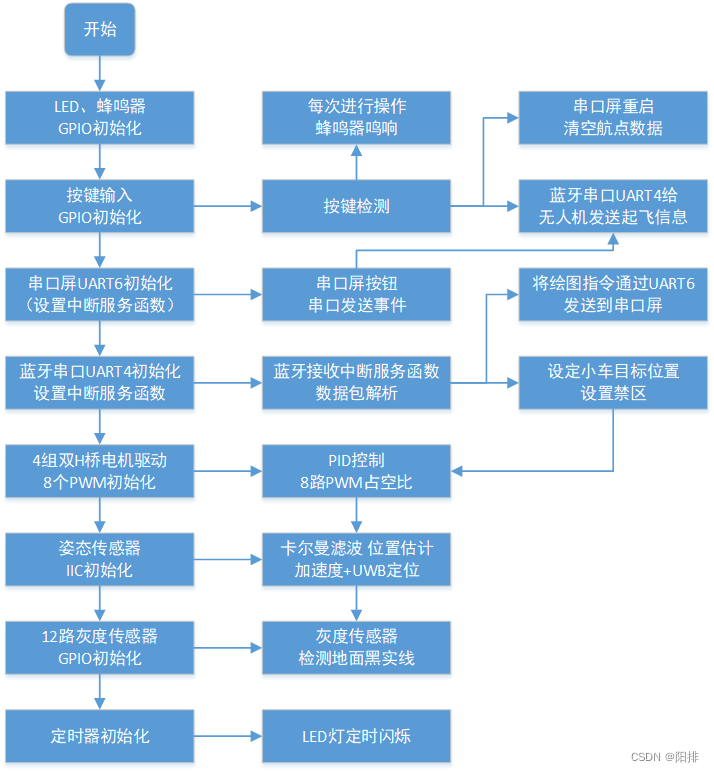
空地协同智能消防系统——无人机、小车协同
1 题目 1.1 任务 设计一个由四旋翼无人机及消防车构成的空地协同智能消防系统。无人机上安装垂直向下的激光笔,用于指示巡逻航迹。巡防区域为40dm48dm。无人机巡逻时可覆盖地面8dm宽度区域。以缩短完成全覆盖巡逻时间为原则,无人机按照规划航线巡逻。发…...

篇二十二:解释器模式:处理语言语法
篇二十二:"解释器模式:处理语言语法" 开始本篇文章之前先推荐一个好用的学习工具,AIRIght,借助于AI助手工具,学习事半功倍。欢迎访问:http://airight.fun/。 另外有2本不错的关于设计模式的资料…...
【LeetCode 75】第二十一题(1207)独一无二的出现次数
目录 题目: 示例: 分析: 代码运行结果: 题目: 示例: 分析: 用两个unordered_map来分别存放每个数字的出现次数和出现的次数这个数,有点绕,比如说有给的数组有两个1,那么第一个map存放的是(1,2),表示1这个数子出现了两次,而第二个map存放的是(2,true),表示有出现次数为2的数…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...