Pytorch深度学习-----神经网络之Sequential的详细使用及实战详解
系列文章目录
PyTorch深度学习——Anaconda和PyTorch安装
Pytorch深度学习-----数据模块Dataset类
Pytorch深度学习------TensorBoard的使用
Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Compose,RandomCrop)
Pytorch深度学习------torchvision中dataset数据集的使用(CIFAR10)
Pytorch深度学习-----DataLoader的用法
Pytorch深度学习-----神经网络的基本骨架-nn.Module的使用
Pytorch深度学习-----神经网络的卷积操作
Pytorch深度学习-----神经网络之卷积层用法详解
Pytorch深度学习-----神经网络之池化层用法详解及其最大池化的使用
Pytorch深度学习-----神经网络之非线性激活的使用(ReLu、Sigmoid)
Pytorch深度学习-----神经网络之线性层用法
文章目录
- 系列文章目录
- 一、什么是Sequential?
- 二、实战
- 1.不使用Sequential实现上述项目
- 2.采用Sequential对上述实战优化并在tensorboard中显示
一、什么是Sequential?
"Sequential"是一个时序容器,可以将各种层按顺序添加到容器中,从而简化神经网络模型的搭建。它可以从头开始构建模型,也可以在其他容器(如Sequential、Functional、Subclass)中构建模型,还可以与其他容器组合使用。
官网解释:
官网的举例应用
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(nn.Conv2d(1,20,5),nn.ReLU(),nn.Conv2d(20,64,5),nn.ReLU())# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(OrderedDict([('conv1', nn.Conv2d(1,20,5)),('relu1', nn.ReLU()),('conv2', nn.Conv2d(20,64,5)),('relu2', nn.ReLU())]))
二、实战
构建如下图所示的神经网络模型
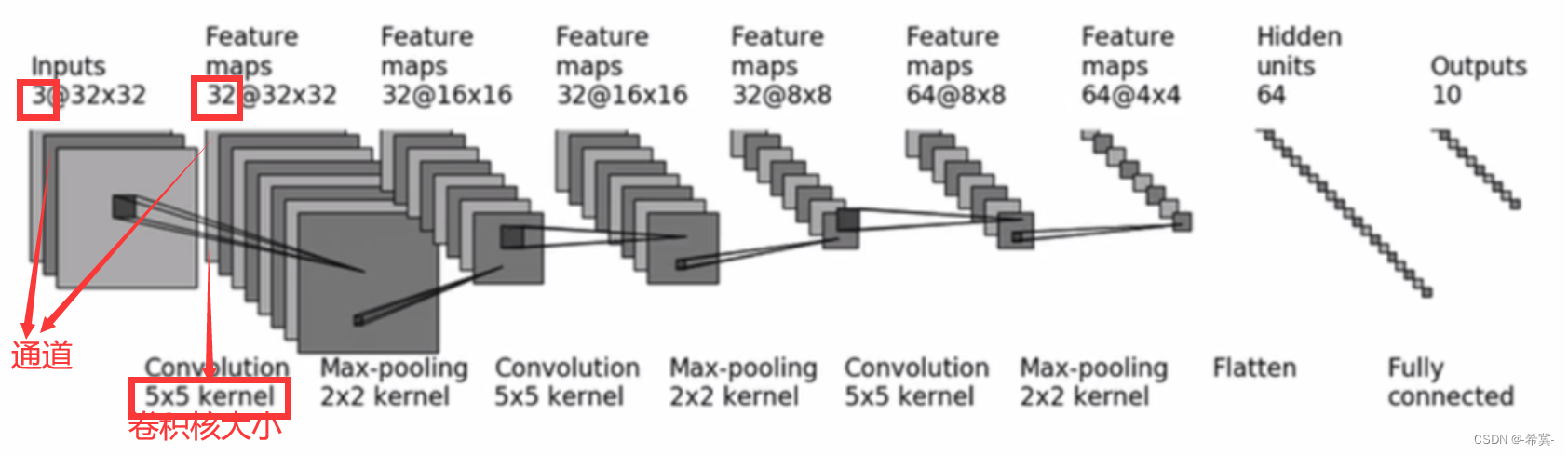
由上述可以观察到输入图像是3通道的32×32的,先后经过卷积层(5×5的卷积核)、最大池化层(2×2的池化核)、卷积层(5×5的卷积核)、最大池化层(2×2的池化核)、卷积层(5×5的卷积核)、最大池化层(2×2的池化核)、拉直、全连接层的处理,最后输出的大小为10。
1.不使用Sequential实现上述项目
在实战前先认识torch.ones():
torch.ones((64, 3, 32, 32)) 表示创建一个形状为 (64, 3, 32, 32) 的张量,其中张量的第一个维度表示批量大小,第二个维度表示通道数,第三和第四个维度表示图像的高度和宽度。在这个例子中,张量有 64 个样本,每个样本是一个 3通道、32x32 大小的图像。
这个张量的每个元素都被初始化为1,也就是说,张量的每个元素的值都是1。这个张量可以用于深度学习中的一些操作,例如卷积、池化等。
注意,这个张量的数据类型默认为 float。如果你需要使用其他数据类型,可以通过 dtype 参数进行指定。例如,要创建一个数据类型为 torch.int 的张量,可以这样做:
代码如下:
import torch t = torch.ones((64, 3, 32, 32), dtype=torch.int)
进入实战代码:
import torch# 准备数据集
input = torch.ones((64, 3, 32, 32))
# 根据图片描述搭建神经网络
"""
输入图像是3通道的32×32的,
先后经过卷积层(5×5的卷积核)、
最大池化层(2×2的池化核)、
卷积层(5×5的卷积核)、
最大池化层(2×2的池化核)、
卷积层(5×5的卷积核)、
最大池化层(2×2的池化核)、
拉直、
全连接层的处理,
最后输出的大小为10
"""class Lgl(torch.nn.Module):def __init__(self):super(Lgl, self).__init__()self.conv1 = torch.nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2)self.maxpool1 = torch.nn.MaxPool2d(kernel_size=2)self.conv2 = torch.nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2)self.maxpool2 = torch.nn.MaxPool2d(kernel_size=2)self.conv3 = torch.nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2)self.maxpool3 = torch.nn.MaxPool2d(kernel_size=2)self.flatten = torch.nn.Flatten()self.linear1 = torch.nn.Linear(1024,64)self.linear2 = torch.nn.Linear(64, 10)def forward(self, x):x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.linear1(x)x = self.linear2(x)return x
# 实例化
l = Lgl()
print(l)
# 进行上面的神经网络模型后
output = l(input)
print(output.shape)结果:
Lgl((conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(maxpool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(flatten): Flatten(start_dim=1, end_dim=-1)(linear1): Linear(in_features=1024, out_features=64, bias=True)(linear2): Linear(in_features=64, out_features=10, bias=True)
)
torch.Size([64, 10])
对其中padding=2参数设置的解释与计算:
由官网中给出的shape相关的计算可以得到padding

以上述为例
其中输出的高为Hout=32,输入的高为Hin=32,采样的步长dilation[0]=1,卷积核大小kernel_size[0]=5,移动的步长stride为1,将其带入到Hout的公式,计算过程如下:
32 =((32+2×padding[0]-1×(5-1)-1))+1,简化之后的式子为:
27+2×padding[0]=31,所以padding[0]=2。
2.采用Sequential对上述实战优化并在tensorboard中显示
在实战前先认识tensorboard中的add_graph()函数
在TensorBoard中,add_graph函数用于将PyTorch模型图添加到TensorBoard中。通过这个函数,您可以以可视化的方式展示模型的计算图,使其他人更容易理解您的模型结构和工作流程。
add_graph(model, input_to_model, strip_default_attributes=True)
参数说明:
model:要添加的PyTorch模型。
input_to_model:用于生成模型图的输入数据。
strip_default_attributes:是否删除模型中的默认属性,默认为True。
代码如下
import torch
from torch.utils.tensorboard import SummaryWriter# 准备数据集
input = torch.ones((64, 3, 32, 32))# 搭建一个自己的神经网络
class Lgl(torch.nn.Module):def __init__(self):super(Lgl, self).__init__()self.seq = torch.nn.Sequential(torch.nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),torch.nn.MaxPool2d(kernel_size=2),torch.nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),torch.nn.MaxPool2d(kernel_size=2),torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),torch.nn.MaxPool2d(kernel_size=2),torch.nn.Flatten(),torch.nn.Linear(1024, 64),torch.nn.Linear(64, 10))def forward(self, x):x = self.seq(x)return x
# 实例化
l = Lgl()
print(l)
# 进行上面的神经网络模型后
output = l(input)
print(output.shape)
# 在tensorboard中显示
writer = SummaryWriter("logs")
writer.add_graph(l, input) # 定义的模型,数据
writer.close()控制台结果:
Lgl((seq): Sequential((0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(6): Flatten(start_dim=1, end_dim=-1)(7): Linear(in_features=1024, out_features=64, bias=True)(8): Linear(in_features=64, out_features=10, bias=True))
)
torch.Size([64, 10])
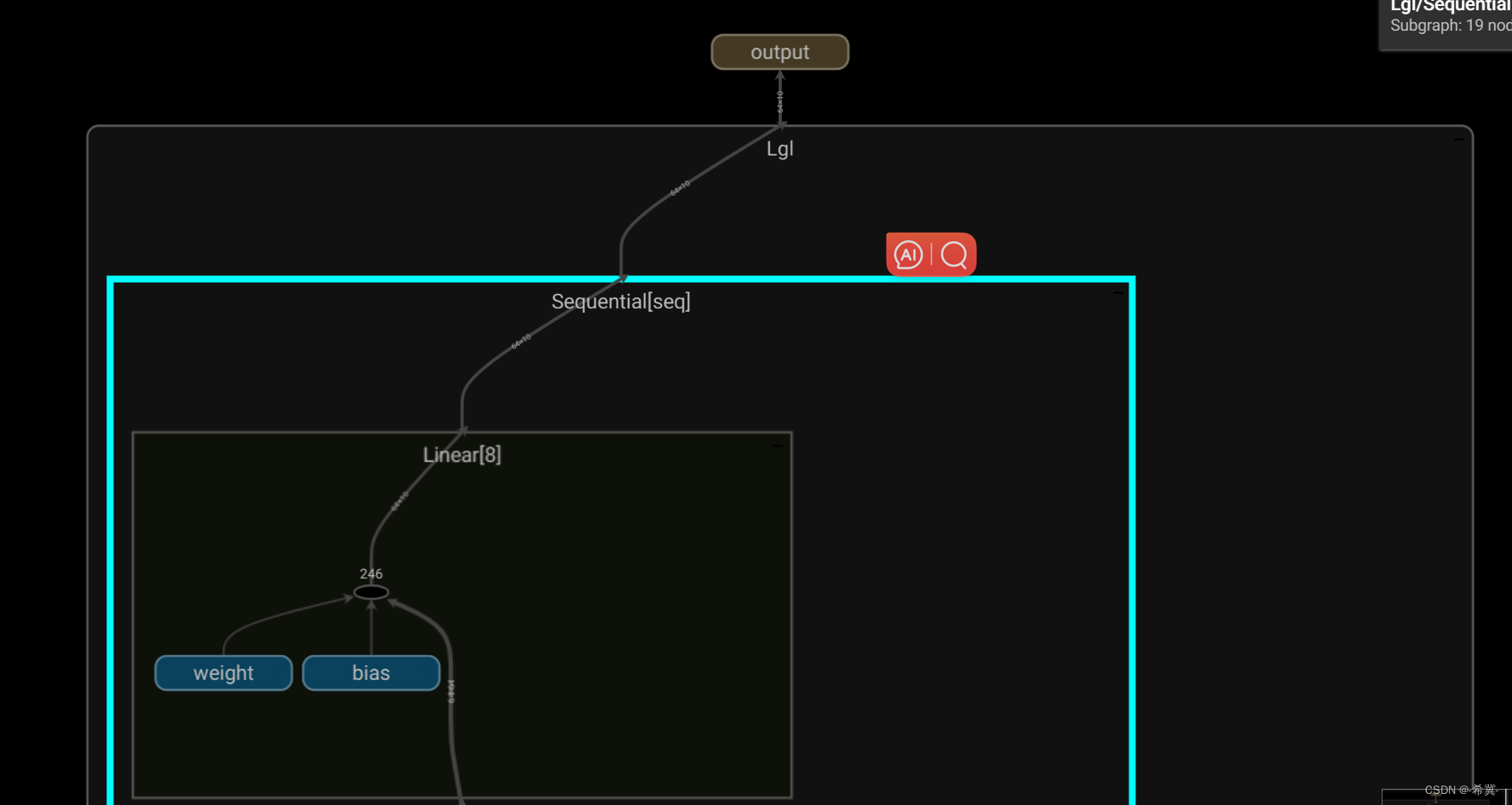
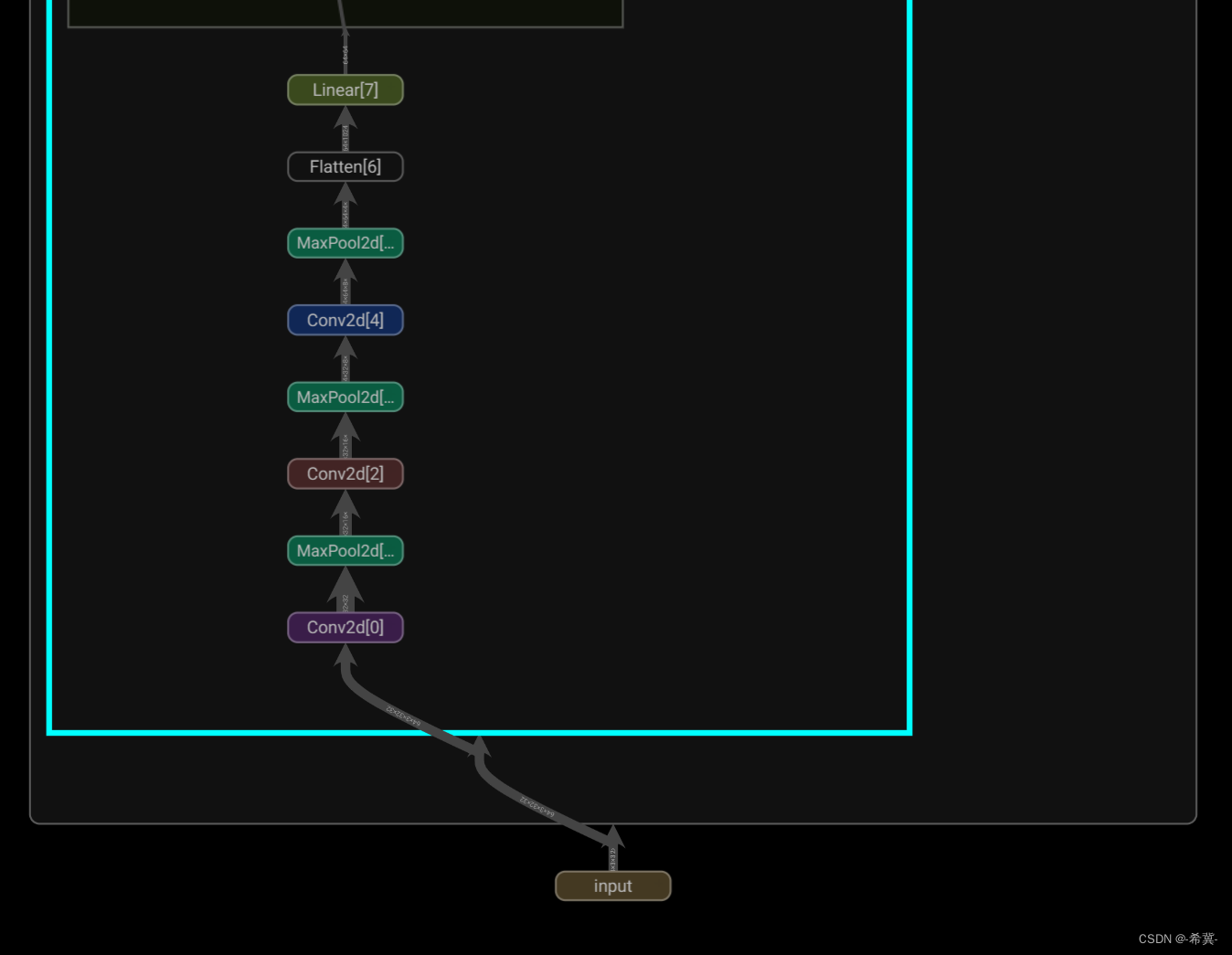
tensorboard中显示
相关文章:
Pytorch深度学习-----神经网络之Sequential的详细使用及实战详解
系列文章目录 PyTorch深度学习——Anaconda和PyTorch安装 Pytorch深度学习-----数据模块Dataset类 Pytorch深度学习------TensorBoard的使用 Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Co…...
安全基础 --- https详解 + 数组(js)
CIA三属性:完整性(Confidentiality)、保密性(Integrity)、可用性(Availability),也称信息安全三要素。 https 核心技术:用非对称加密传输对称加密的密钥,然后…...

vue加载大量数据优化
在Vue中加载大量数据并形成列表时,可以通过以下方法来优化性能: 分页加载:不要一次性加载所有的数据,而是分批加载数据,每次只加载当前页需要显示的数据量。可以使用第三方库如vue-infinite-loading来实现无限滚动加载…...

WebRTC 之音视频同步
在网络视频会议中, 我们常会遇到音视频不同步的问题, 我们有一个专有名词 lip-sync 唇同步来描述这类问题,当我们看到人的嘴唇动作与听到的声音对不上的时候,不同步的问题就出现了 而在线会议中, 听见清晰的声音是优先…...
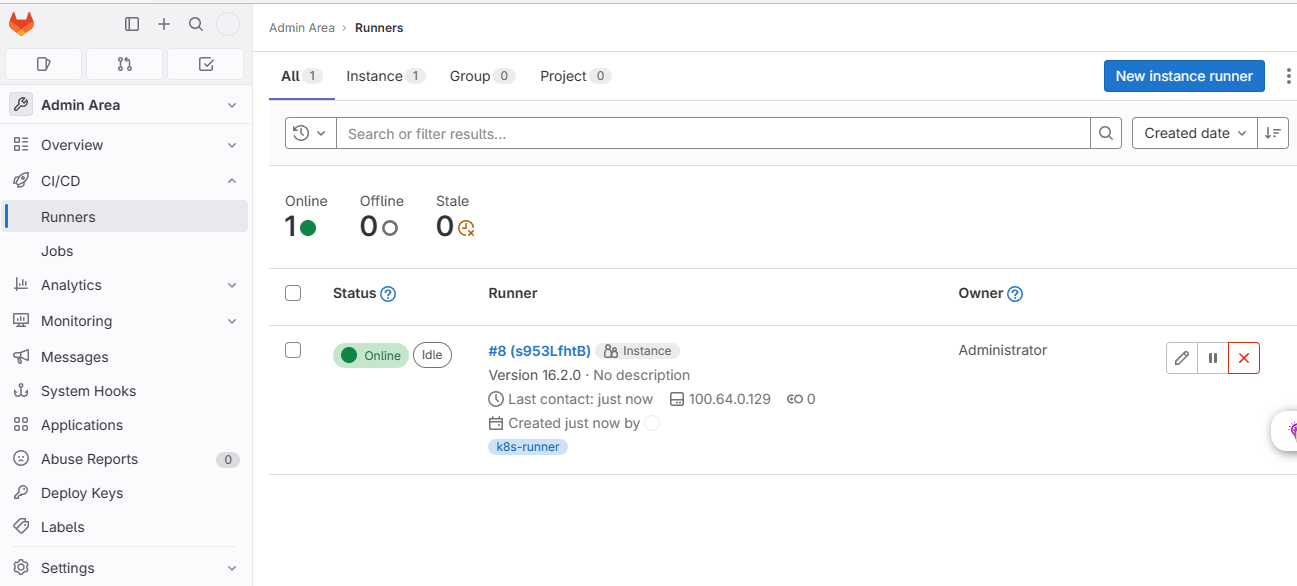
kubernetes基于helm部署gitlab-runner
kubernetes基于helm部署gitlab-runner 这篇博文介绍如何在 Kubernetes 中使用helm部署 GitLab-runner。 先决条件: 已运行的 Kubernetes 集群已运行的 gitlab 实例 项目地址:https://gitlab.com/gitlab-org/charts/gitlab-runner 官方文档ÿ…...

深度学习和OpenCV的对象检测(MobileNet SSD图像识别)
基于深度学习的对象检测时,我们主要分享以下三种主要的对象检测方法: Faster R-CNN(后期会来学习分享)你只看一次(YOLO,最新版本YOLO3,后期我们会分享)单发探测器(SSD,本节介绍,若你的电脑配置比较低,此方法比较适合R-CNN是使用深度学习进行物体检测的训练模型; 然而,…...
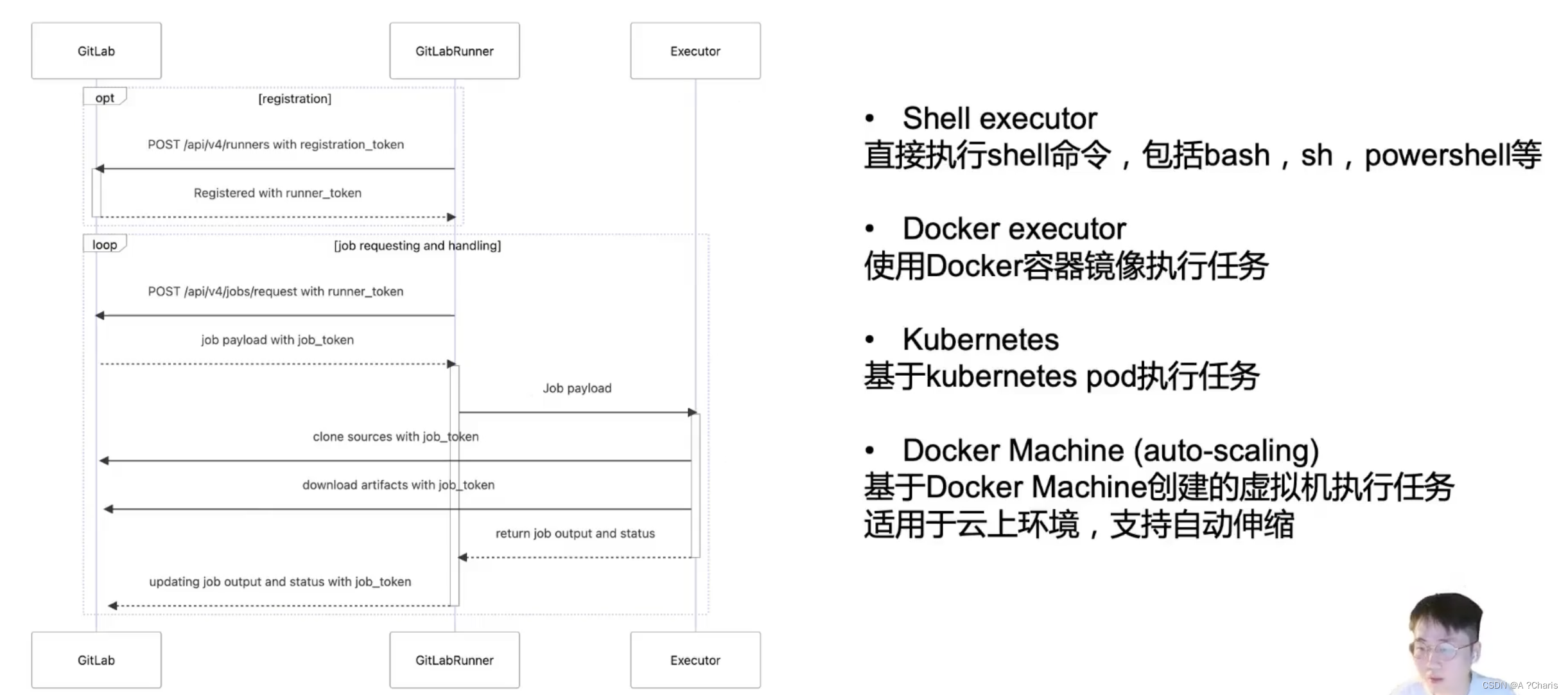
Gitlab CI/CD笔记-第一天-GitOps和以前的和jenkins的集成的区别
一、GitOps-CI/CD的流程图与Jenkins的流程图 从上图可以看到: GitOps与基于Jennkins技术栈的CI/CD流程,无法从Jenkins集成其他第三方开源的项目来实现换成了Gitlab来进行集成。 好处在于:CI 一个工具Gitlab就行了,但CD部分依旧是…...

有关OpenBSD, NetBSD, FreeBSD -- 与GPT对话
1 介绍一下 - OpenBSD, NetBSD, FreeBSD 当谈论操作系统时,OpenBSD、NetBSD和FreeBSD都是基于BSD(Berkeley Software Distribution)的操作系统,它们各自是独立开发的,并在BSD许可下发布。这些操作系统有很多共同点,但也有一些差异。以下是对它们的简要介绍: OpenBSD: O…...
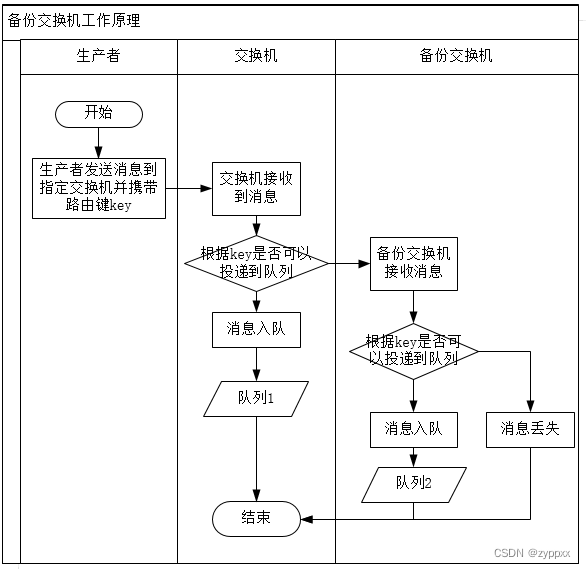
RabbitMQ 备份交换机和死信交换机
为处理生产者生产者将消息推送到交换机中,交换机按照消息中的路由键即自身策略无法将消息投递到指定队列中造成消息丢失的问题,可以使用备份交换机。 为处理在消息队列中到达TTL的过期消息,可采用死信交换机进行消息转存。 通过上述描述可知&…...

Linux 中利用设备树学习Ⅳ
系列文章目录 第一章 Linux 中内核与驱动程序 第二章 Linux 设备驱动编写 (misc) 第三章 Linux 设备驱动编写及设备节点自动生成 (cdev) 第四章 Linux 平台总线platform与设备树 第五章 Linux 设备树中pinctrl与gpio(…...
使用Spring Initializr方式构建Spring Boot项目
除了可以使用Maven方式构建Spring Boot项目外,还可以通过Spring Initializr方式快速构建Spring Boot项目。从本质上说,Spring lnitializr是一个Web应用,它提供了一个基本的项目结构,能够帮助我们快速构建一个基础的Spring Boot项目…...
Sentinel 2.0 微服务零信任的探索与实践
作者:涯客、十眠 从古典朴素的安全哲学谈起 网络安全现状 现在最常见的企业网络安全架构便是在企业网络边界处做安全防护,而在企业网络内部不做安全防范。这确实为企业的安全建设省了成本也为企业提供了一定的防护能力。但是这类比于现实情况的一个小…...
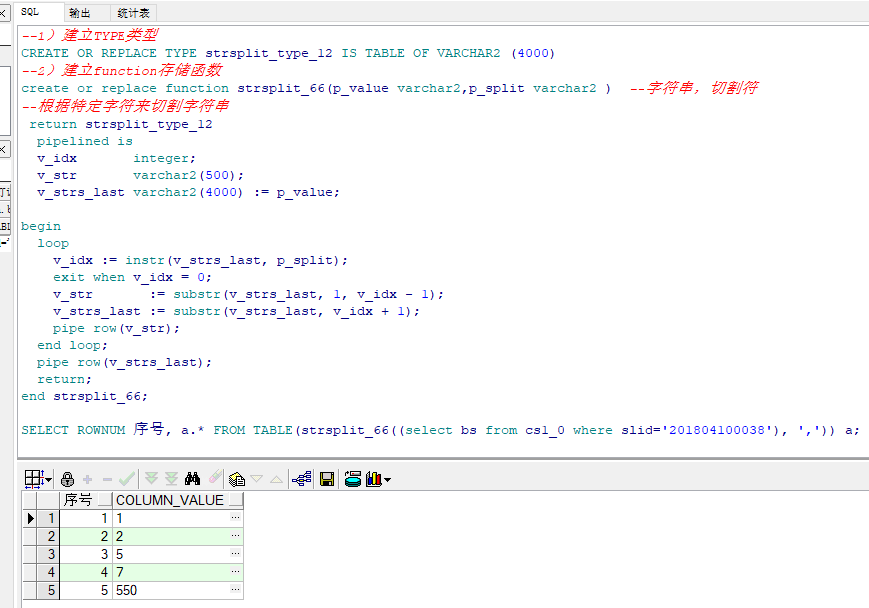
Oracle以逗号分隔的字符串拆分为多行数据实例详解
前言 近期在工作中遇到某表某字段是可扩展数据内容,信息以逗号分隔生成的,现需求要根据此字段数据在其它表查询相关的内容展现出来,第一想法是切割数据,以逗号作为切割符,以下为总结的实现方法,以供大家参…...
harbor仓库安装部署(1.6.1)
目录 1、关闭防火墙 2、安装docker-ce(所有主机) 3、配置阿里云镜像加速器 4、部署Docker Compose 服务 5、部署 Harbor 服务 6、下载 Harbor 安装程序(两台harbor主机) 7、配置 Harbor 参数文件 8、启动并安装 Harbor …...

FastAPI 构建 API 高性能的 web 框架(一)
如果要部署一些大模型一般langchainfastapi,或者fastchat, 先大概了解一下fastapi,本篇主要就是贴几个实际例子。 官方文档地址: https://fastapi.tiangolo.com/zh/ 1 案例1:复旦MOSS大模型fastapi接口服务 来源:大语言模型工程…...

Spring框架中的Bean的生命周期
Spring Bean 的生命周期总体分为四个阶段:实例化 》属性注入》初始化》销毁 实例化: (1)实例化bean:根据配置文件中Bean的定义,利用java Reflection 反射技术创建Bean的实例! 属性注入&#…...
vue3-ts-vite:vue 项目 配置 多页面应用
一、Vue项目,什么是多页面应用 Vue是一种单页面应用程序(SPA)框架,这意味着Vue应用程序通常只有一个HTML页面,而在该页面上进行动态的内容更改,而不是每次都加载新的HTML页面。 但是,有时候我…...
docker部署jenkins且jenkins中使用docker去部署项目
docker部署jenkins且jenkins中使用docker去部署项目 1、确定版本 2.346.1是最后一个支持jdk8的 2、编写docker-compose.yml并执行 在这个目录中新增data文件夹,注意data是用来跟docker中的文件进行映射的 docker-compose.yml version: "3.1" service…...

无锚框原理 TOOD:Task-aligned One-stage Object Detection
无锚框原理 TOOD:Task-aligned One-stage Object Detection 一 摘要二 引言TOOD设计 三 具体设计Task-aligned Head任务对齐的预测器 TAP预测对齐 TAL 任务对齐学习Task-aligned Sample Assignment多任务损失 一 摘要 一阶段目标检测通常通过优化两个子任务来实现&…...
配置Picgo图床之COS、OSS、Github图床
简介 PicGo是一款开源的图片上传和管理工具,它提供了简单易用的界面和丰富的功能,方便用户上传、管理和分享图片。 以下是PicGo的一些主要特点和功能: 图片上传:PicGo支持将本地图片快速上传到云存储服务,如七牛云、…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...
[ACTF2020 新生赛]Include 1(php://filter伪协议)
题目 做法 启动靶机,点进去 点进去 查看URL,有 ?fileflag.php说明存在文件包含,原理是php://filter 协议 当它与包含函数结合时,php://filter流会被当作php文件执行。 用php://filter加编码,能让PHP把文件内容…...