机器学习深度学习——卷积神经网络(LeNet)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——池化层
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
卷积神经网络(LeNet)
- 引言
- LeNet
- 模型训练
- 小结
引言
之前的内容中曾经将softmax回归模型和多层感知机应用于Fashion-MNIST数据集中的服装图片。为了能应用他们,我们首先就把图像展平成了一维向量,然后用全连接层对其进行处理。
而现在已经学习过了卷积层的处理方法,我们就可以在图像中保留空间结构。同时,用卷积层代替全连接层的另一个好处是:模型更简单,所需参数更少。
LeNet是最早发布的卷积神经网络之一,之前出来的目的是为了识别图像中的手写数字。
LeNet
总体看,由两个部分组成:
1、卷积编码器:由两个卷积层组成
2、全连接层密集快:由三个全连接层组成
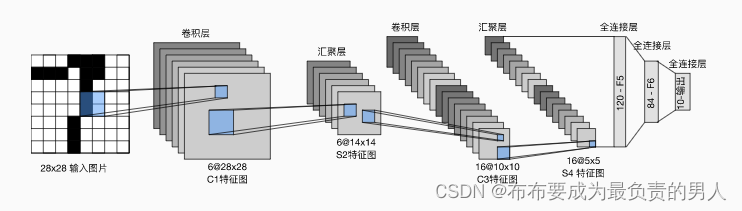
上图中就是LeNet的数据流图示,其中汇聚层也就是池化层。
最终输出的大小是10,也就是10个可能结果(0-9)。
每个卷积块的基本单元是一个卷积层、一个sigmoid激活函数和平均池化层(当年没有ReLU和最大池化层)。每个卷积层使用5×5卷积核和一个sigmoid激活函数。
这些层的作用就是将输入映射到多个二维特征输出,通常同时增加通道的数量。(从上图容易看出:第一卷积层有6个输出通道,而第二个卷积层有16个输出通道;每个2×2池操作(步幅也为2)通过空间下采样将维数减少4倍)。卷积的输出形状那是由批量大小、通道数、高度、宽度决定。
为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本(也就是把四维的输入转换为全连接层期望的二维输入,第一维索引小批量中的样本,第二维给出给个样本的平面向量表示)。
LeNet的稠密块有三个全连接层,分别有120、84和10个输出。因为我们在执行分类任务,所以输出层的10维对应于最后输出结果的数量(代表0-9是个结果)。
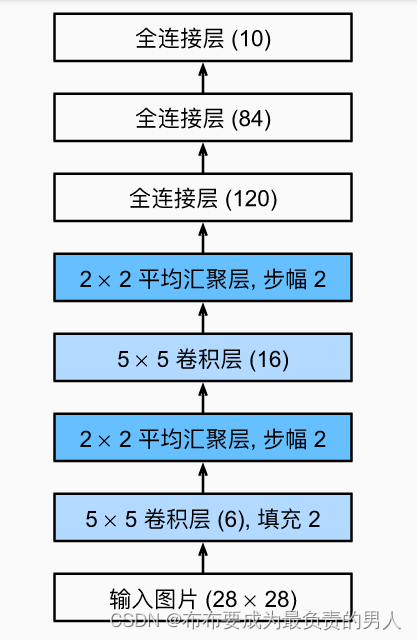
深度学习框架实现此类模型非常简单,用一个Sequential块把需要的层连接在一个就可以了,我们对原始模型做一个小改动,去掉最后一层的高斯激活:
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(# 输入图像和输出图像都是28×28,因此我们要先进行填充2格nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10)
)上面的模型图示就为:
我们可以先检查模型,在每一层打印输出的形状:
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:X = layer(X)print(layer.__class__.__name__, 'output shape:\t', X.shape)输出结果:
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
模型训练
既然已经实现了LeNet,现在可以查看它在Fashion-MNIST数据集上的表现:
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
计算成本较高,因此使用GPU来加快训练。为了进行评估,对之前的evaluate_accuracy进行修改,由于完整的数据集位于内存中,因此在模型使用GPU计算数据集之前,我们需要将其复制到显存中。
def evaluate_accuracy_gpu(net, data_iter, device=None):"""使用GPU计算模型在数据集上的精度"""if isinstance(net, nn.Module):net.eval() # 设置为评估模式if not device:device = next(iter(net.parameters())).device# 正确预测的数量,总预测的数量metric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):# BERT微调所需(后面内容)else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1]
要使用GPU,我们要在正向和反向传播之前,将每一小批量数据移动到我们GPU上。
如下所示的train_ch6类似于之前定义的train_ch3。以下训练函数假定从高级API创建的模型作为输入,并进行相应的优化。
使用Xavier来随机初始化模型参数。有关于Xavier的推导和原理可以看下面的文章:
机器学习&&深度学习——数值稳定性和模型化参数(详细数学推导)
与全连接层一样,使用交叉熵损失函数和小批量随机梯度下降,代码如下:
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device): #@save"""用GPU训练模型"""def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):# 训练损失之和,训练准确率之和,样本数metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i+1) / num_batches, (train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
此时我们可以开始训练和评估LeNet模型:
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()
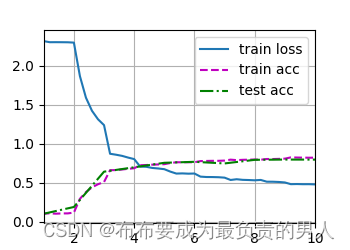
运行输出(这边我没有用远程的GPU,在自己本地跑了,本地只有CPU):
training on cpu
loss 0.477, train acc 0.820, test acc 0.795
8004.2 examples/sec on cpu
运行图片:
小结
1、卷积神经网络(CNN)是一类使用卷积层的网络
2、在卷积神经网络中,我们组合使用卷积层、非线性激活函数和池化层
3、为了构造高性能的卷积神经网络,我们通常对卷积层进行排列,逐渐降低其表示的空间分辨率,同时增加通道数
4、传统卷积神经网络中,卷积块编码得到的表征在输出之前需要由一个或多个全连接层进行处理
相关文章:
机器学习深度学习——卷积神经网络(LeNet)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——池化层 📚订阅专栏:机器学习&&深度学习 希望文章对你们有所帮助 卷积神…...

Pytorch Tutorial【Chapter 2. Autograd】
Pytorch Tutorial 文章目录 Pytorch TutorialChapter 2. Autograd1. Review Matrix Calculus1.1 Definition向量对向量求导1.2 Definition标量对向量求导1.3 Definition标量对矩阵求导 2.关于autograd的说明3. grad的计算3.1 Manual手动计算3.2 backward()自动计算 Reference C…...

Python第三方库国内镜像下载地址
Python第三方库国内镜像下载地址 一、清华大学二、中国科技大学三、安装方法 一、清华大学 https://pypi.tuna.tsinghua.edu.cn/simple 二、中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple 三、安装方法 例如 pyhook3 插件的安装方法,执行下面命令安装…...
服务端机器一般部署在哪里)
从浏览器输入url到页面加载(七)服务端机器一般部署在哪里
前言 上一节,我们说到了CDN和路由器的关系,说到了公有地址,说到了通信线路服务,这一节跳过那些看不懂的深层知识,直接开始说web服务器。 1. 服务端机器为什么不部署在公司内部 记得在之前的一段时间里,公…...
Pytorch深度学习-----神经网络之Sequential的详细使用及实战详解
系列文章目录 PyTorch深度学习——Anaconda和PyTorch安装 Pytorch深度学习-----数据模块Dataset类 Pytorch深度学习------TensorBoard的使用 Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Co…...
安全基础 --- https详解 + 数组(js)
CIA三属性:完整性(Confidentiality)、保密性(Integrity)、可用性(Availability),也称信息安全三要素。 https 核心技术:用非对称加密传输对称加密的密钥,然后…...

vue加载大量数据优化
在Vue中加载大量数据并形成列表时,可以通过以下方法来优化性能: 分页加载:不要一次性加载所有的数据,而是分批加载数据,每次只加载当前页需要显示的数据量。可以使用第三方库如vue-infinite-loading来实现无限滚动加载…...

WebRTC 之音视频同步
在网络视频会议中, 我们常会遇到音视频不同步的问题, 我们有一个专有名词 lip-sync 唇同步来描述这类问题,当我们看到人的嘴唇动作与听到的声音对不上的时候,不同步的问题就出现了 而在线会议中, 听见清晰的声音是优先…...
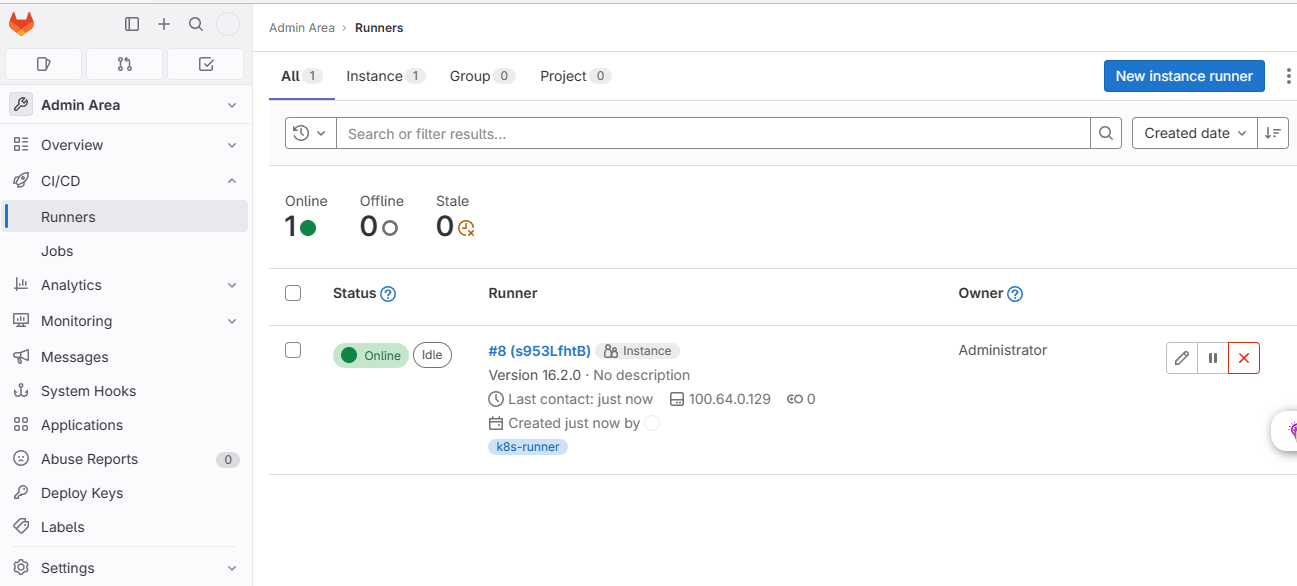
kubernetes基于helm部署gitlab-runner
kubernetes基于helm部署gitlab-runner 这篇博文介绍如何在 Kubernetes 中使用helm部署 GitLab-runner。 先决条件: 已运行的 Kubernetes 集群已运行的 gitlab 实例 项目地址:https://gitlab.com/gitlab-org/charts/gitlab-runner 官方文档ÿ…...

深度学习和OpenCV的对象检测(MobileNet SSD图像识别)
基于深度学习的对象检测时,我们主要分享以下三种主要的对象检测方法: Faster R-CNN(后期会来学习分享)你只看一次(YOLO,最新版本YOLO3,后期我们会分享)单发探测器(SSD,本节介绍,若你的电脑配置比较低,此方法比较适合R-CNN是使用深度学习进行物体检测的训练模型; 然而,…...
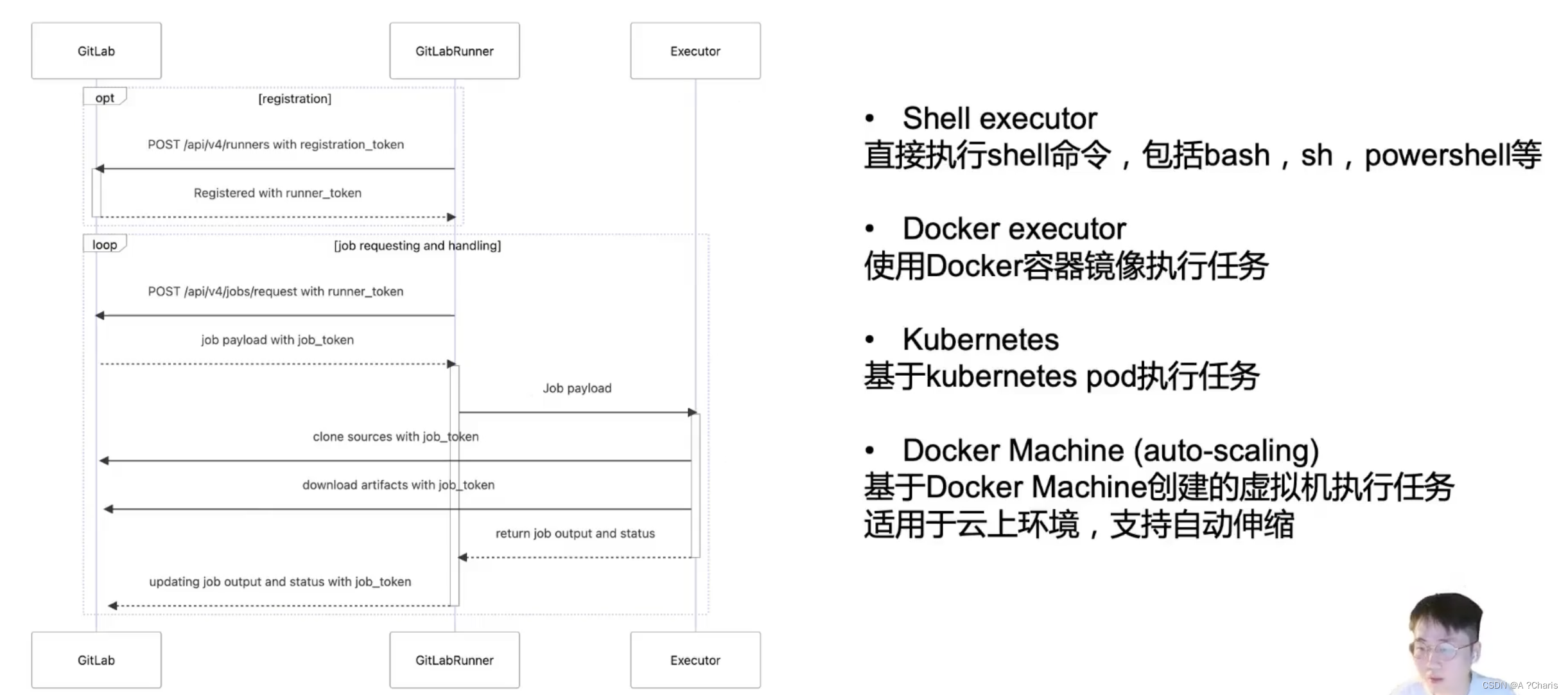
Gitlab CI/CD笔记-第一天-GitOps和以前的和jenkins的集成的区别
一、GitOps-CI/CD的流程图与Jenkins的流程图 从上图可以看到: GitOps与基于Jennkins技术栈的CI/CD流程,无法从Jenkins集成其他第三方开源的项目来实现换成了Gitlab来进行集成。 好处在于:CI 一个工具Gitlab就行了,但CD部分依旧是…...

有关OpenBSD, NetBSD, FreeBSD -- 与GPT对话
1 介绍一下 - OpenBSD, NetBSD, FreeBSD 当谈论操作系统时,OpenBSD、NetBSD和FreeBSD都是基于BSD(Berkeley Software Distribution)的操作系统,它们各自是独立开发的,并在BSD许可下发布。这些操作系统有很多共同点,但也有一些差异。以下是对它们的简要介绍: OpenBSD: O…...
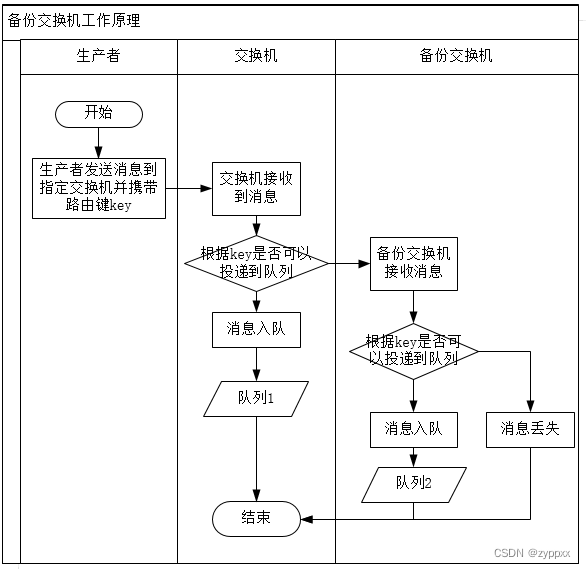
RabbitMQ 备份交换机和死信交换机
为处理生产者生产者将消息推送到交换机中,交换机按照消息中的路由键即自身策略无法将消息投递到指定队列中造成消息丢失的问题,可以使用备份交换机。 为处理在消息队列中到达TTL的过期消息,可采用死信交换机进行消息转存。 通过上述描述可知&…...

Linux 中利用设备树学习Ⅳ
系列文章目录 第一章 Linux 中内核与驱动程序 第二章 Linux 设备驱动编写 (misc) 第三章 Linux 设备驱动编写及设备节点自动生成 (cdev) 第四章 Linux 平台总线platform与设备树 第五章 Linux 设备树中pinctrl与gpio(…...
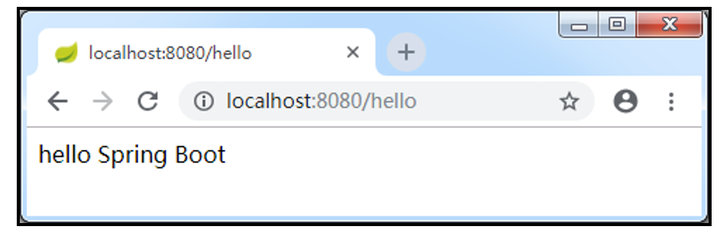
使用Spring Initializr方式构建Spring Boot项目
除了可以使用Maven方式构建Spring Boot项目外,还可以通过Spring Initializr方式快速构建Spring Boot项目。从本质上说,Spring lnitializr是一个Web应用,它提供了一个基本的项目结构,能够帮助我们快速构建一个基础的Spring Boot项目…...
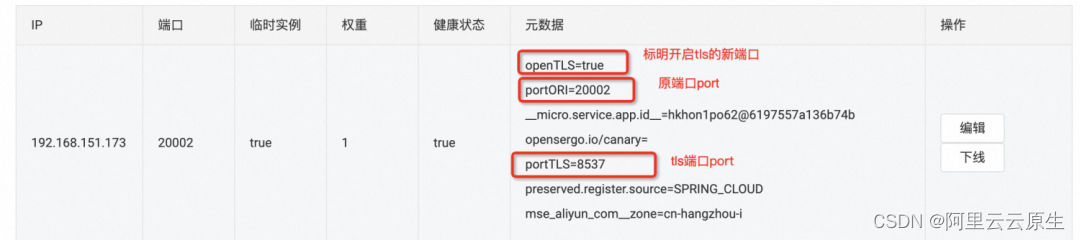
Sentinel 2.0 微服务零信任的探索与实践
作者:涯客、十眠 从古典朴素的安全哲学谈起 网络安全现状 现在最常见的企业网络安全架构便是在企业网络边界处做安全防护,而在企业网络内部不做安全防范。这确实为企业的安全建设省了成本也为企业提供了一定的防护能力。但是这类比于现实情况的一个小…...
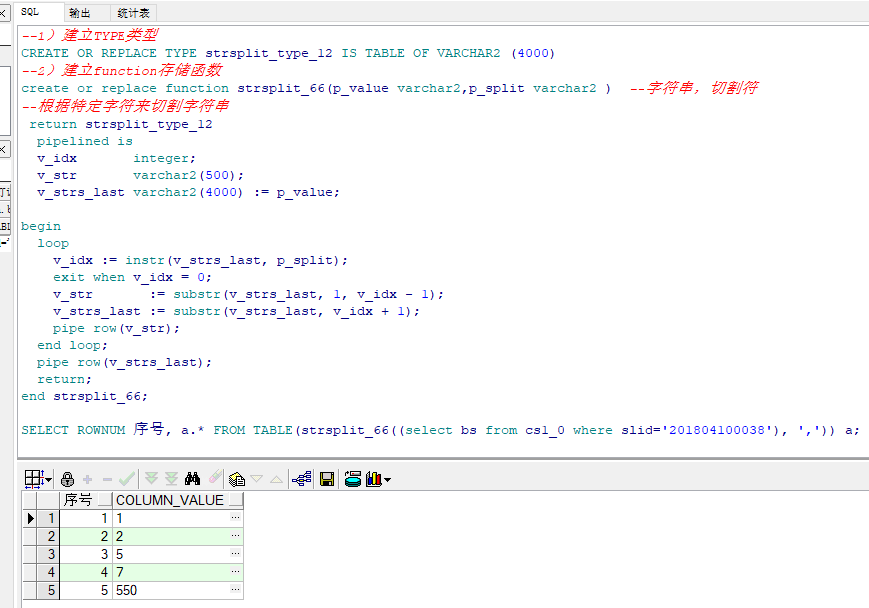
Oracle以逗号分隔的字符串拆分为多行数据实例详解
前言 近期在工作中遇到某表某字段是可扩展数据内容,信息以逗号分隔生成的,现需求要根据此字段数据在其它表查询相关的内容展现出来,第一想法是切割数据,以逗号作为切割符,以下为总结的实现方法,以供大家参…...
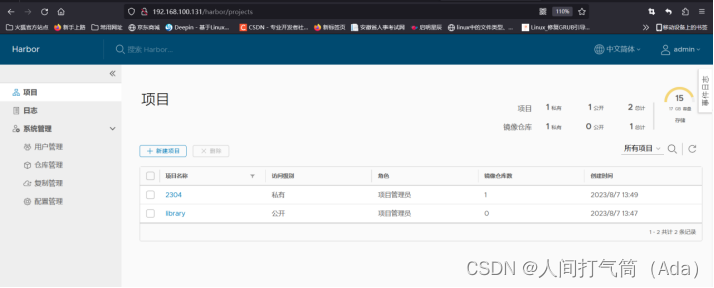
harbor仓库安装部署(1.6.1)
目录 1、关闭防火墙 2、安装docker-ce(所有主机) 3、配置阿里云镜像加速器 4、部署Docker Compose 服务 5、部署 Harbor 服务 6、下载 Harbor 安装程序(两台harbor主机) 7、配置 Harbor 参数文件 8、启动并安装 Harbor …...

FastAPI 构建 API 高性能的 web 框架(一)
如果要部署一些大模型一般langchainfastapi,或者fastchat, 先大概了解一下fastapi,本篇主要就是贴几个实际例子。 官方文档地址: https://fastapi.tiangolo.com/zh/ 1 案例1:复旦MOSS大模型fastapi接口服务 来源:大语言模型工程…...

Spring框架中的Bean的生命周期
Spring Bean 的生命周期总体分为四个阶段:实例化 》属性注入》初始化》销毁 实例化: (1)实例化bean:根据配置文件中Bean的定义,利用java Reflection 反射技术创建Bean的实例! 属性注入&#…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...