neo4j查询语言Cypher详解(二)--Pattern和类型
Patterns
图形模式匹配是Cypher的核心。它是一种用于通过应用声明性模式从图中导航、描述和提取数据的机制。在MATCH子句中,可以使用图模式定义要搜索的数据和要返回的数据。图模式匹配也可以在不使用MATCH子句的情况下在EXISTS、COUNT和COLLECT子查询中使用。
图模式使用类似于在白板上绘制属性图的节点和关系的语法来描述数据。在白板上,节点绘制为圆圈,关系绘制为箭头。Cypher将圆圈表示为一对括号,箭头表示为破折号和大于或小于符号: ()-->()<--()
这些节点和关系的简单模式构成了路径模式的构建块,可以匹配固定长度的路径。除了讨论简单的模式外,本章还将介绍更复杂的模式,展示如何匹配可变长度的模式,内联过滤器以提高查询性能,以及如何向路径模式添加循环和非线性形状。
概念
Node patterns
每个图模式至少包含一个节点模式。最简单的图形模式是单个空节点模式: MATCH ()。
空节点模式匹配属性图中的每个节点。为了获得对匹配节点的引用,需要在node模式中声明一个变量: MATCH (n)
通过这个变量引用,可以访问节点:MATCH (n) RETURN n.name
向节点模式添加Label表达式意味着只返回具有匹配标签的节点。MATCH (n:Stop)
更复杂模式:MATCH (n:(TrainStation&BusStation)|StationGroup)
属性名称和值的映射可用于基于与指定值的相等性来匹配节点属性。MATCH (n { mode: 'Rail' })
更一般的谓词可以用WHERE子句表示。MATCH (n:Station WHERE n.name STARTS WITH 'Preston')
Relationship patterns
最简单的关系模式: --。此模式匹配任何方向的关系,并且不过滤任何关系类型或属性。与节点模式不同,关系模式不能在两端没有节点模式的MATCH子句中使用。
为了获得对模式匹配的关系的引用,需要在模式中声明一个关系变量,方法是在破折号之间的方括号中添加变量名:-[r]-
为了匹配特定的方向,在左侧或右侧分别加上<或>: -[r]->
若要匹配关系类型,在冒号后添加类型名称: -[:CALLS_AT]->
与节点模式类似,可以添加属性名称和值的映射,以基于与指定值的相等性来过滤关系的属性: -[{ distance: 0.24, duration: 'PT4M' }]->。WHERE子句可以用于更一般的谓词: -[r WHERE time() + duration(r.duration) < time('22:00') ]->。
Path patterns
任何有效的路径都以一个节点开始和结束,每个节点之间都有关系(如果有多个节点)。路径模式具有相同的限制,对于所有有效的路径模式,以下条件为真:
-
它们至少有一个节点模式。
-
它们以节点模式开始和结束。
-
它们在节点和关系之间交替。
这些都是有效的路径模式:
()
(s)--(e)
(:Station)--()<--(m WHERE m.departs > time('12:00'))-->()-[:NEXT]->(n)
无效路径模式:
--> //无节点
()--> //尾部没有节点
()-->-->() //节点和关系之间无交替
路径模式匹配
Equijoins
等量连接是一种对路径的操作,它要求多个节点或路径之间的关系相同。通过在多个节点模式或关系模式中声明相同的变量来指定节点或关系之间的相等性。等量连接允许在路径模式中指定循环。
MATCH (n:Station {name: 'London Euston'})<-[:CALLS_AT]-(s1:Stop)-[:NEXT]->(s2:Stop)-[:CALLS_AT]->(:Station {name: 'Coventry'})<-[:CALLS_AT]-(s3:Stop)-[:NEXT]->(s4:Stop)-[:CALLS_AT]->(n)
RETURN s1.departs+'-'+s2.departs AS outbound,s3.departs+'-'+s4.departs AS `return`
量化路径模式
通过使用量化路径模式来匹配不同长度的路径,从而允许您搜索长度未知或在特定范围内的路径。
在搜索可从锚节点到达的所有节点、查找连接两个节点的所有路径,或者遍历可能具有不同深度的层次结构时,量化路径模式可能非常有用。
量化路径模式通过将路径模式的重复部分提取到括号中并应用量词来解决此问题。该量词指定要匹配的提取模式的可能重复范围。第一步是识别重复模式,
((:Stop)-[:NEXT]->(:Stop)){1,3}
(:Stop)-[:NEXT]->(:Stop) |
(:Stop)-[:NEXT]->(:Stop)(:Stop)-[:NEXT]->(:Stop) |
(:Stop)-[:NEXT]->(:Stop)(:Stop)-[:NEXT]->(:Stop)(:Stop)-[:NEXT]->(:Stop)这里的联合运算符(|)仅用于说明;以这种方式使用它不是Cypher语法的一部分。在上面的扩展中,如果两个节点模式彼此相邻,它们必须匹配相同的节点:服务的下一个部分从上一个部分结束的地方开始。因此,它们可以被重写为具有任何过滤条件组合的单节点模式。在本例中,这是微不足道的,因为应用于这些节点的过滤只是标签Stop:
MATCH (:Station { name: 'Denmark Hill' })<-[:CALLS_AT]-(d:Stop)((:Stop)-[:NEXT]->(:Stop)){1,3}(a:Stop)-[:CALLS_AT]->(:Station { name: 'Clapham Junction' })
RETURN d.departs AS departureTime, a.arrives AS arrivalTime
量化关系
量化关系允许以更简洁的方式重写一些简单的量化路径模式。
MATCH (d:Station { name: 'Denmark Hill' })<-[:CALLS_AT]-(n:Stop)((:Stop)-[:NEXT]->(:Stop)){1,10}(m:Stop)-[:CALLS_AT]->(a:Station { name: 'Clapham Junction' })
WHERE m.arrives < time('17:18')
RETURN n.departs AS departureTimeMATCH (d:Station { name: 'Denmark Hill' })<-[:CALLS_AT]-(n:Stop)-[:NEXT]->{1,10}(m:Stop)-[:CALLS_AT]->(a:Station { name: 'Clapham Junction' })
WHERE m.arrives < time('17:18')
RETURN n.departs AS departureTime
量词{1,10}的作用域是关系模式-[:NEXT]->,而不是与之相邻的节点模式。更一般地说,其中量化路径模式中包含的路径模式具有以下形式:
(() <relationship pattern> ()) <quantifier>
//可以简化为
<relationship pattern> <quantifier>
Group variables
顾名思义,这个属性表示两个站点之间的距离。为了返回连接一对station的每个服务的总距离,需要一个变量来引用所遍历的每个关系。类似地,要提取每个Stop的出发地和到达地属性,需要引用遍历的每个节点的变量。在这个在Denmark Hill和Clapham Junction之间匹配服务的示例中,变量l和m被声明为匹配stop, r被声明为匹配关系。变量origin只匹配路径中的第一个Stop:
MATCH (:Station { name: 'Denmark Hill' })<-[:CALLS_AT]-(origin)((l)-[r:NEXT]->(m)){1,3}()-[:CALLS_AT]->(:Station { name: 'Clapham Junction' })在量化路径模式中声明的变量称为组变量。之所以这样称呼它们,是因为当在量化路径模式之外引用时,它们是匹配中绑定到的节点或关系的列表。要理解如何考虑组变量绑定到节点或关系的方式,可以扩展量化路径模式,并观察不同变量如何匹配到整体匹配路径的元素。

(l1)-[r1:NEXT]->(m1) |
(l1)-[r1:NEXT]->(m1)(l2)-[r2:NEXT]->(m2) |
(l1)-[r1:NEXT]->(m1)(l2)-[r2:NEXT]->(m2)(l3)-[r3:NEXT]->(m3)
每个变量的下标表示它们属于路径模式重复的哪个实例。
l => [n2, n3, n4]
r => [r2, r3, r4]
m => [n3, n4, n5]
最短路径
MATCH p = shortestPath((hby)-[:LINK*]-(cnm))
WHERE hby.name = 'Hartlebury' AND cnm.name = 'Cheltenham Spa'
RETURN [n in nodes(p) | n.name] AS stopsMATCH p = shortestPath((hby)-[:LINK*]-(cnm))
WHERE all(link in relationships(p) WHERE link.distance < 20) ANDhby.name = 'Hartlebury' AND cnm.name = 'Cheltenham Spa'
RETURN [n in nodes(p) | n.name] AS stopsMATCH p = allShortestPaths((hby)-[link:LINK*]-(psh))
WHERE hby.name = 'Hartlebury' AND psh.name = 'Pershore'
RETURN [n in nodes(p) | n.name] AS stops
量化路径模式断言
primer
语法和语义
//节点模式
nodePattern ::= "(" [ nodeVariable ] [ labelExpression ][ propertyKeyValueExpression ] [ "WHERE" booleanExpression ] ")"//关系模式
relationshipPattern ::= fullPattern | abbreviatedRelationshipfullPattern ::="<-[" patternFiller "]-"| "-[" patternFiller "]->"| "-[" patternFiller "]-"abbreviatedRelationship ::= "<--" | "--" | "-->"patternFiller ::= [ relationshipVariable ] [ typeExpression ][ propertyKeyValueExpression ] [ "WHERE" booleanExpression ]//Lable 表达式
labelExpression ::= ":" labelTerm
//
labelTerm ::=labelIdentifier| labelTerm "&" labelTerm| labelTerm "|" labelTerm| "!" labelTerm| "%"| "(" labelTerm ")"
//
propertyKeyValueExpression ::="{" propertyKeyValuePairList "}"propertyKeyValuePairList ::=propertyKeyValuePair [ "," propertyKeyValuePair ]propertyKeyValuePair ::= propertyName ":" valueExpression
//
pathPattern ::= [{ simplePathPattern | quantifiedPathPattern }]+simplePathPattern ::= nodePattern[ { relationshipPattern | quantifiedRelationship } nodePattern ]*quantifiedPathPattern ::="(" fixedPath [ "WHERE" booleanExpression ] ")" quantifierfixedPath ::= nodePattern [ relationshipPattern nodePattern ]+ quantifiedRelationship ::= relationshipPattern quantifier
Quantifiers
quantifier ::="*" | "+" | fixedQuantifier | generalQuantifier
fixedQuantifier ::= "{" unsignedInteger "}"
generalQuantifier ::= "{" lowerBound "," upperBound "}"
lowerBound ::= unsignedInteger
upperBound ::= unsignedInteger
unsignedInteger ::= [0-9]+
| Variant | Canonical form | Description |
|---|---|---|
{m,n} | {m,n} | Between m and n iterations. |
+ | {1,} | 1 or more iterations. |
* | {0,} | 0 or more iterations. |
{n} | {n,n} | Exactly n iterations. |
{m,} | {m,} | m or more iterations. |
{,n} | {0,n} | Between 0 and n iterations. |
{,} | {0,} | 0 or more iterations. |
请注意,带有量词{1}的量化路径模式不等同于固定长度的路径模式。尽管最终的量化路径模式将与其中包含的固定长度路径在没有量词的情况下匹配,但量词的存在意味着路径模式中的所有变量都将作为组变量公开。
Graph patterns
graphPattern ::=pathPattern [ "," pathPattern ]* [ "WHERE" booleanExpression ]
Node pattern pairs
编写一对相邻的节点模式是无效的语法。例如,以下所有操作都会引发语法错误:
然而,相邻的节点模式对的放置是有效的,它间接来自于量化路径模式的扩展。
量化路径模式迭代
当一个量化的路径模式被展开时,包含在其括号中的固定路径模式被重复和链接。这导致成对的节点模式彼此相邻。
((x:X)<--(y:Y)){3}
通过重复三次固定路径模式(x: x)←-(y: y)来扩展它,并在变量上添加索引以表明没有隐含的等量连接
(x1:X)<--(y1:Y)(x2:X)<--(y2:Y)(x3:X)<--(y3:Y)
结果是两对节点模式最终彼此相邻,(y1:Y)(x2:X)和(y2:Y)(x3:X)。在匹配过程中,每对节点模式将匹配相同的节点,这些节点将满足节点模式中谓词的连接。例如,在第一对中,y1和x2将绑定到同一个节点,并且该节点必须具有X和y的标签。这种扩展和绑定如下图所示:
简单路径模式和量化路径模式
量化路径模式对
当两个量化路径模式相邻时,第一模式的最后一次迭代的最右节点与第二模式的第一次迭代的最左节点合并。例如,以下相邻的模式:
((:A)-[:R]->(:B)){2} ((:X)<--(:Y)){1,2}
将匹配与以下两个路径模式匹配的路径的并集相同的路径集:
(:A)-[:R]->(:B&A)-[:R]->(:B&X)<--(:Y)
(:A)-[:R]->(:B&A)-[:R]->(:B&X)<--(:Y&X)<--(:Y)
零迭代
如果量词允许模式的零次迭代,例如{0,3},那么该模式的第0次迭代将导致两边的节点模式配对。
(:X) ((a:A)-[:R]->(b:B)){0,1} (:Y)
//匹配
(:X&Y) // 节点具有X,Y标签
(:X&A)-[:R]->(:B&Y)
变长关系
在Neo4j 5.9中引入量化路径模式和量化关系的语法之前,Cypher中匹配可变长度路径的唯一方法是使用可变长度关系。这个语法仍然可用。
| Variant | Description |
|---|---|
* | 1 or more iterations. |
*n | Exactly n iterations. |
*m..n | Between m and n iterations. |
*m.. | m or more iterations. |
*..n | Between 1 and n iterations. |
| Variable-length relationship | Equivalent quantified path pattern |
|---|---|
(a)-[*2]->(b) | (a) (()-[]->()){2,2} (b) |
(a)-[:KNOWS*3..5]->(b) | (a) (()-[:KNOWS]->()){3,5} (b) |
(a)-[r*..5 {name: 'Filipa'}]->(b) | (a) (()-[r {name: 'Filipa'}]->()){1,5} (b) |
可变长度关系的变量可以在后续模式中使用,以引用该变量绑定到的关系列表。这与绑定到单个节点或关系的变量的等量连接相同。
值和类型
Cypher支持一系列数据值。在编写Cypher查询时,不可能声明数据类型。相反,Cypher将自动推断给定值的数据类型。
Property types
属性类型:BOOLEAN、DATE、DURATION、FLOAT、INTEGER、LIST、LOCAL DATETIME、LOCAL TIME、POINT、STRING、ZONED DATETIME和ZONED TIME。
-
属性类型可以从Cypher查询返回。
-
属性类型可以用作参数。
-
属性类型可以存储为属性。
-
属性类型可以用Cypher字面值构造。
简单类型的同构列表可以存储为属性,但一般列表(请参阅构造类型)不能存储为属性。作为属性存储的列表不能包含空值。
Cypher还提供了对字节数组的传递支持,字节数组可以作为属性值存储。由于性能原因,支持字节数组,因为使用Cypher的泛型LIST(其中每个INTEGER都有64位表示)的成本太高。但是,字节数组不被Cypher视为第一类数据类型,因此它们没有文字表示。
结构类型
结构类型:NODE、RELATIONSHIP和PATH。
-
结构类型可以从Cypher查询返回。
-
结构类型不能用作参数。
-
结构类型不能存储为属性。
-
结构类型不能用Cypher字面值构造。
NODE数据类型包括:id、label(s)和属性映射。注意标签不是值,而是模式语法的一种形式。
RELATIONSHIP数据类型包括:id、关系类型、属性映射、开始节点id和结束节点id。
PATH数据类型是节点和关系的交替序列。
构造类型
构造类型中:LIST和MAP。
-
可以从Cypher查询返回构造类型。
-
构造类型可以用作参数。
-
构造的类型不能存储为属性(同构列表除外)。
-
构造类型可以用Cypher字面值构造。
LIST数据类型可以是简单值的同构集合,也可以是异构的有序值集合,每个值都可以具有任何属性、结构类型或构造类型。
MAP数据类型是(键、值)对的异构、无序集合,其中键是文字,而值可以具有任何属性、结构类型或构造类型。
构造类型值也可以包含null。
类型同义词
| Type | Synonyms |
|---|---|
ANY | ANY VALUE |
BOOLEAN | BOOL |
DATE | |
DURATION | |
FLOAT | |
INTEGER | INT, SIGNED INTEGER |
LIST<INNER_TYPE> | ARRAY<INNER_TYPE>, INNER_TYPE LIST, INNER_TYPE ARRAY |
LOCAL DATETIME | TIMESTAMP WITHOUT TIMEZONE |
LOCAL TIME | TIME WITHOUT TIMEZONE |
MAP | |
NODE | ANY NODE, VERTEX, ANY VERTEX |
NOTHING | |
NULL | |
PATH | |
POINT | |
PROPERTY VALUE | ANY PROPERTY VALUE |
RELATIONSHIP | ANY RELATIONSHIP, EDGE, ANY EDGE |
STRING | VARCHAR |
ZONED DATETIME | TIMESTAMP WITH TIMEZONE |
ZONED TIME | TIME WITH TIMEZONE |
所有Cypher类型都包含空值。要使它们不可为空,可以将not NULL附加到类型的末尾(例如BOOLEAN not NULL, LIST<FLOAT not NULL>)。
属性类型明细
| Type | Min. value | Max. value | Precision |
|---|---|---|---|
BOOLEAN | False | True | - |
DATE | -999_999_999-01-01 | +999_999_999-12-31 | Days |
DURATION | P-292471208677Y-6M-15DT-15H-36M-32S | P292471208677Y6M15DT15H36M32.999999999S | Nanoseconds |
FLOAT | Double.MIN_VALUE [1] | Double.MAX_VALUE | 64 bit |
INTEGER | Long.MIN_VALUE | Long.MAX_VALUE | 64 bit |
LOCAL DATETIME | -999_999_999-01-01T00:00:00 | +999_999_999-12-31T23:59:59.999999999 | Nanoseconds |
LOCAL TIME | 00:00:00 | 23:59:59.999999999 | Nanoseconds |
POINT | Cartesian: (-Double.MAX_VALUE, -Double.MAX_VALUE)Cartesian_3D: (-Double.MAX_VALUE, -Double.MAX_VALUE, -Double.MAX_VALUE)WGS_84: (-180, -90)WGS_84_3D: (-180, -90, -Double.MAX_VALUE) | Cartesian: (Double.MAX_VALUE, Double.MAX_VALUE)Cartesian_3D: (Double.MAX_VALUE, Double.MAX_VALUE, Double.MAX_VALUE)WGS_84: (180, 90)WGS_84_3D: (180, 90, Double.MAX_VALUE) | The precision of each coordinate of the POINT is 64 bit as they are floats. |
STRING | - | - | - |
ZONED DATETIME | -999_999_999-01-01T00:00:00+18:00 | +999_999_999-12-31T23:59:59.999999999-18:00 | Nanoseconds |
ZONED TIME | 00:00:00+18:00 | 23:59:59.999999999-18:00 | Nanoseconds |
时间类型
| Type | Date support | Time support | Time zone support |
|---|---|---|---|
DATE | √ | ||
LOCAL TIME | √ | ||
ZONED TIME | √ | √ | |
LOCAL DATETIME | √ | √ | |
ZONED DATETIME | √ | √ | √ |
DURATION | - | - | - |
相比之下,DURATION不是即时类型。DURATION表示时间量,捕获两个瞬间之间的时间差,并且可以为负值。
新的版本,类型名字有所改变
| Type | Old type name |
|---|---|
DATE | Date |
LOCAL TIME | LocalTime |
ZONED TIME | Time |
LOCAL DATETIME | LocalDateTime |
ZONED DATETIME | DateTime |
DURATION | Duration |
空间类型
null操作
逻辑操作
逻辑运算符(AND、OR、XOR、NOT)将null作为三值逻辑的未知值。
| a | b | a AND b | a OR b | a XOR b | NOT a |
|---|---|---|---|---|---|
false | false | false | false | false | true |
false | null | false | null | null | true |
false | true | false | true | true | true |
true | false | false | true | true | false |
true | null | null | true | null | false |
true | true | true | true | false | false |
null | false | false | null | null | null |
null | null | null | null | null | null |
null | true | null | true | null | null |
总结:
AND:只要有一个为false,则为false。OR:只要有一个为true,则为true。
IN
IN操作符遵循类似的逻辑。如果Cypher可以确定列表中存在某物,则结果将为真。任何包含null且没有匹配元素的列表都将返回null。否则,结果将为false。
| Expression | Result |
|---|---|
2 IN [1, 2, 3] | true |
2 IN [1, null, 3] | null |
2 IN [1, 2, null] | true |
2 IN [1] | false |
2 IN [] | false |
null IN [1, 2, 3] | null |
null IN [1, null, 3] | null |
null IN [] | false |
使用all、any、none和single遵循类似的规则。如果结果可以确定地计算出来,则返回true或false。否则将产生null。
[ ]
访问带有null的list或map将返回null
返回null的表达式
-
从列表中获取缺失的元素:
[][0],head([])。 -
试图访问节点或关系上不存在的属性:
n.missingProperty。 -
当任何一方为空时的比较:1 < null。
-
包含null的算术表达式:1 + null。
-
某些函数调用的任何参数都为空:例如,sin(null)。
LIST
RETURN [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] AS list
RETURN range(0, 10)[3] AS element //range创建LIST
RETURN range(0, 10)[-3] AS element //下标支持负数
RETURN range(0, 10)[0..3] AS list //切片
RETURN range(0, 10)[0..-5] AS list //
RETURN range(0, 10)[-5..] AS list //
RETURN range(0, 10)[..4] AS list //
RETURN range(0, 10)[15] AS list //超过索引的单个元素返回null。
RETURN range(0, 10)[5..15] AS list //超过索引的LIST 元素截断。
MAP
RETURN {key: 'Value', listKey: [{inner: 'Map1'}, {inner: 'Map2'}]}Map 投影
Cypher支持Map投影,它允许从节点、关系和其他Map值构造Map投影。
Map投影以绑定到要进行投影的图形实体的变量开始,并包含一组逗号分隔的映射元素,由{和}括起来。
map_variable {map_element, [, ...n]}
MAP投影将一个或多个键值对投影到MAP投影。有四种不同类型的MAP投影元素:
-
属性选择器:将属性名称作为键进行投影,并将map_variable中的值作为投影的值。
-
字面量实体 :这是一个键值对,值是一个任意的表达式键:
<expression>。 -
变量选择器:投影一个变量,变量名作为键,变量指向的值作为投影的值。它的语法就是变量。
-
所有属性选择器:从map_variable值投射所有键值对。
-
如果map_variable指向null,则整个MAP投影的值将为null。
-
映射中的键名必须是
STRING类型。
MATCH (keanu:Person {name: 'Keanu Reeves'})-[:ACTED_IN]->(movie:Movie)
WITH keanu, collect(movie{.title, .released}) AS movies
RETURN keanu{.name, movies: movies} // name属性作为一个元素,movies字面量,作为KEY, movies变量作为VALUE,是个LIST
| keanu |
|---|
{movies: [{title: "The Devils Advocate", released: 1997}, {title: "The Matrix Revolutions", released: 2003}, {title: "The Matrix Resurrections", released: 2021}, {title: "The Matrix Reloaded", released: 2003}, {title: "The Matrix", released: 1999}], name: "Keanu Reeves"} |
| Rows: 1 |
类型转换
参考 Functions
附录
参考
https://neo4j.com/docs/cypher-manual/current/patterns/
https://neo4j.com/docs/cypher-manual/current/values-and-types/
https://neo4j.com/docs/cypher-manual/current/functions/
相关文章:
neo4j查询语言Cypher详解(二)--Pattern和类型
Patterns 图形模式匹配是Cypher的核心。它是一种用于通过应用声明性模式从图中导航、描述和提取数据的机制。在MATCH子句中,可以使用图模式定义要搜索的数据和要返回的数据。图模式匹配也可以在不使用MATCH子句的情况下在EXISTS、COUNT和COLLECT子查询中使用。 图…...

动态规划(用空间换时间的算法)原理逻辑代码超详细!参考自《算法导论》
动态规划(用空间换时间的算法)-实例说明和用法详解 动态规划(DP)思想实例说明钢条切割问题矩阵链乘法问题 应用满足的条件和场景 本篇博客以《算法导论》第15章动态规划算法为本背景,大量引用书中内容和实例࿰…...

Jmeter添加cookie的两种方式
jmeter中添加cookie可以通过配置HTTP Cookie Manager,也可以通过HTTP Header Manager,因为cookie是放在头文件里发送的。 实例:博客园点击添加新随笔 https://i.cnblogs.com/EditPosts.aspx?opt1 如果未登录,跳转登录页…...
【ArcGIS Pro二次开发】(58):数据的本地化存储
在做村规工具的过程中,需要设置一些参数,比如说导图的DPI,需要导出的图名等等。 每次导图前都需要设置参数,虽然有默认值,但还是需要不时的修改。 在使用的过程中,可能会有一些常用的参数,希望…...

React配置代理服务器的5种方法
五种方法的介绍 以下是五种在React项目中配置代理服务器的方法的使用场景和优缺点: 1. 使用 http-proxy-middleware 中间件: 使用场景:适用于大多数React项目,简单易用。优点:配置简单,易于理解和维护。…...

树莓派:5.jar程序自启运行
搞了好长时间才搞定,普通的jar文件好启动。神奇的在于在ssh里启动GPIO可以操作,但是自启动GPIO不能控制。第二天才想明白估计是GPIO的操作权限比较高,一试果然如此,特此记录。 1、copy程序文件和sh文件在Public下 piraspberrypi…...

Vivado中SmartConnect和InterConnect的区别
前言:本文章为FPGA问答系列,我们会定期整理FPGA交流群(包括其他FPGA博主的群)里面有价值的问题,并汇总成文章,如果问题多的话就每周整理一期,如果问题少就每两周整理一期,一方面是希…...

了解HTTP代理日志:解读请求流量和响应信息
嗨,爬虫程序员们!你们是否在了解爬虫发送的请求流量和接收的响应信息上有过困扰?今天,我们一起来了解一下。 首先,我们需要理解HTTP代理日志的基本结构和内容。HTTP代理日志是对爬虫发送的请求和接收的响应进行记录的文…...

排序-堆排序
给你一个整数数组 nums,请你将该数组升序排列。 输入:nums [5,2,3,1] 输出:[1,2,3,5] 输入:nums [5,1,1,2,0,0] 输出:[0,0,1,1,2,5] 思路直接看我录制的视频吧 算法-堆排序_哔哩哔哩_bilibili 实现代码如下所示&…...

挑战Open AI!!!马斯克宣布成立xAI.
北京时间7月13日凌晨,马斯克在Twitter上宣布:“xAI正式成立,去了解现实。”马斯克表示,推出xAI的原因是想要“了解宇宙的真实本质”。Ghat GPT横空出世已有半年,国内外“百模大战”愈演愈烈,AI大模型的现状…...
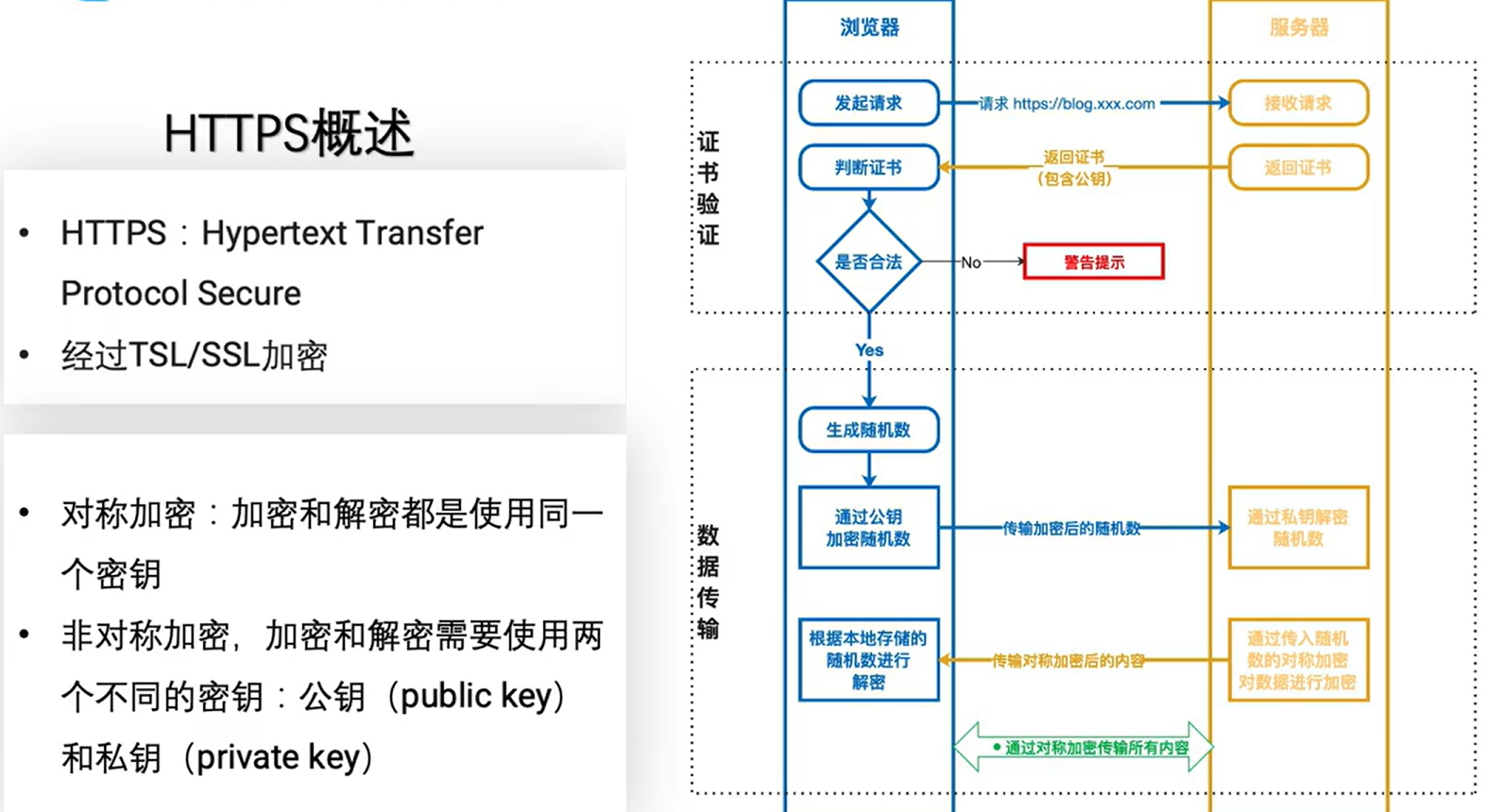
HTTP协议学习笔记1
初识HTTP 输入网址进入网页过程发生了什么? DNS解析:浏览器会向本地DNS服务器发出域名解析请求,如果本地DNS服务器中没有对应的IP地址,则会向上级DNS服务器继续发出请求,直到找到正确的IP地址为止。 建立TCP连接&…...
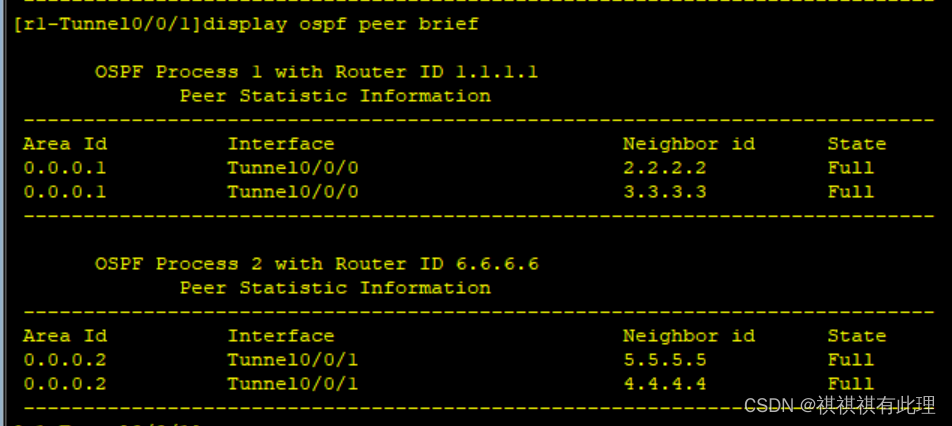
【网络基础实战之路】基于OSPF协议建立两个MGRE网络的实验详解
系列文章传送门: 【网络基础实战之路】设计网络划分的实战详解 【网络基础实战之路】一文弄懂TCP的三次握手与四次断开 【网络基础实战之路】基于MGRE多点协议的实战详解 【网络基础实战之路】基于OSPF协议建立两个MGRE网络的实验详解 PS:本要求基于…...

【学习日志】2023.Aug.6,支持向量机的实现
2023.Aug.6,支持向量机的实现 参考了大佬的代码,但有些地方似乎还有改进的空间,我加了注释 #codingutf-8 #Author:Dodo #Date:2018-12-03 #Email:lvtengchaopku.edu.cn #Blog:www.pkudodo.com数据集:Mnist 训练集数量࿱…...

LeetCode_动态规划_中等_1749.任意子数组和的绝对值的最大值
目录 1.题目2.思路3.代码实现(Java) 1.题目 给你一个整数数组 nums 。一个子数组 [numsl, numsl1, …, numsr-1, numsr] 的 和的绝对值 为 abs(numsl numsl1 … numsr-1 numsr) 。请你找出 nums 中和的绝对值 最大的任意子数组(可能为空…...

无涯教程-Perl - 环境配置
在开始编写Perl程序之前,让我们了解如何设置我们的Perl环境。 您的系统更有可能安装了perl。只需尝试在$提示符下给出以下命令- $perl -v 如果您的计算机上安装了perl,那么您将收到以下消息: This is perl 5, version 16, subversion 2 (v5.16.2) b…...

QT显示加载动画
文章目录 一、前言二、使用1.FormLoading.h2.FormLoading.cpp 一、前言 项目中在下发指令时,结果异步返回,可能需要一段时间,因此需要用到加载动画。 用的比较简单,就是新建Widget子窗口,放一个Label,使用…...
原型模式(C++)
定义 使用原型实例指定创建对象的种类,然后通过拷贝这些原型来创建新的对象。 应用场景 在软件系统中,经常面临着“某些结构复杂的对象”的创建工作;由于需求的变化,这些对象经常面临着剧烈的变化,但是它们却拥有比较稳定一致的…...

web浏览器打开本地exe应用
一、如何使web浏览器打开本地exe应用? 浏览器打开本地exe程序我们可以使用ActiveXObject方法,但是只支持IE,谷歌、火狐等浏览器并不支持此操作。 那问题来了,我们又该如何操作? 经过本博主的不断学习探索终于找到了一…...
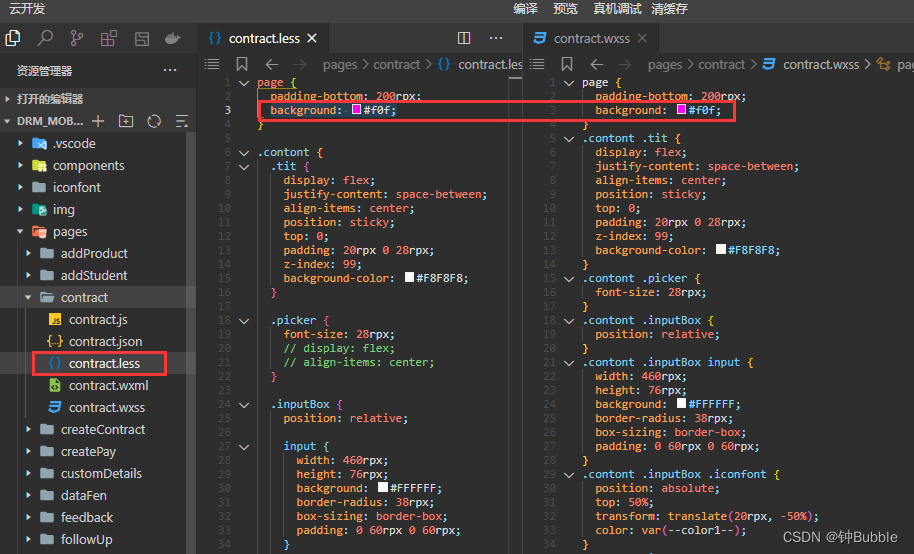
微信小程序如何配置并使用less?
1,检查微信开发者工具(工具版本1.03)————这步很重要不然后面按步骤实行后会发现急死你也还是不管用,我之前死在过这一步,所以大家不要再次踩坑了 ~ ~ 。。。 2,在VScode中下载Less插件 3,…...

【Spring】反射动态修改Bean实例的私有属性值
Cannot cast org.springframework.http.client.InterceptingClientHttpRequestFactory to org.springframework.http.client.OkHttp3ClientHttpRequestFactory 由于RestTemplate在自定义初始化时顺序比较早,想在启动后跟进yum或者注解配置修改初始化的值时ÿ…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...