【100天精通python】Day29:文件与IO操作_XML文件处理
目录
专栏导读
一、XML文件概述
1. 标签和元素
2. 嵌套结构
3. 属性
4. 命名空间
5. CDATA节
6. 注释
7. 验证与验证语言
8. 扩展性
二、XML文件处理常见操作
1. 解析XML文件
2. 创建和编辑XML文件
3. 修改XML文件
4. 查询XML元素
5 遍历XML元素
6. 删除XML元素
7. 使用lxml库
8. 处理XML命名空间
命名空间的基本概念
在XML中声明命名空间
使用XPath与命名空间
默认命名空间
处理多个命名空间
三、 XML文件操作常见问题与解决
1. XML文件不存在或无法打开
2. 解析错误
3. 查询元素不存在
4. 节点文本为空
专栏导读

专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html

一、XML文件概述
XML(eXtensible Markup Language)是一种用于描述结构化数据的标记语言。它被广泛用于数据存储、传输和交换,适用于各种应用领域,如Web开发、配置文件、数据交换和数据存储等。XML的主要特点包括:
1. 标签和元素
XML使用标签(Tag)来标识数据的不同部分,每个标签包含在尖括号中,如<tag>。标签可以用来定义元素(Element),表示数据的具体部分。元素可以包含文本、属性、子元素等。
2. 嵌套结构
XML允许元素嵌套在其他元素内部,从而创建层次结构,用于表示复杂的数据关系。
<bookstore><book><title>XML Basics</title><author>John Smith</author></book><book><title>Advanced XML</title><author>Jane Doe</author></book>
</bookstore>
3. 属性
XML元素可以具有属性(Attributes),用于提供有关元素的附加信息。属性位于元素的开始标签内部。
<book title="XML Basics"><author>John Smith</author>
</book>
4. 命名空间
XML支持使用命名空间(Namespace)来避免元素名的冲突。命名空间通过为元素名称添加前缀来区分不同的命名空间。
<ns1:book xmlns:ns1="http://example.com/ns1"><ns1:title>XML Basics</ns1:title>
</ns1:book>
5. CDATA节
CDATA节允许在元素内部包含文本数据,即使其中包含特殊字符也不会被解析。
<description><![CDATA[This is some <b>bold</b> text.]]></description>
6. 注释
XML支持添加注释,用于对数据进行解释说明或标记。
<!-- This is a comment -->
<book><!-- Book information goes here -->
</book>
7. 验证与验证语言
XML文档可以使用验证语言(如DTD、XML Schema、RELAX NG等)进行验证,以确保其结构和内容符合预期。
8. 扩展性
XML的设计初衷是具有极高的扩展性,允许用户根据需要定义自己的元素和结构,以满足特定的数据表示需求。
总之,XML是一种通用的、可扩展的数据表示格式,用于在不同应用和系统之间传输和存储数据。尽管XML在一些场景中逐渐被JSON、YAML等其他格式取代,但在某些情况下,仍然是非常有用和重要的数据交换工具。
二、XML文件处理常见操作
在Python中,处理XML文件涉及到多种常用操作。以下是一些常见的XML文件处理操作:
1. 解析XML文件
使用内置的xml.etree.ElementTree模块解析XML文件。
import xml.etree.ElementTree as ETtree = ET.parse("data.xml")
root = tree.getroot()# 遍历根元素的子元素
for child in root:print("Element:", child.tag)for sub_element in child:print(" Sub Element:", sub_element.tag, "Value:", sub_element.text)
2. 创建和编辑XML文件
使用xml.etree.ElementTree模块创建和编辑XML文件。
import xml.etree.ElementTree as ETroot = ET.Element("data")item1 = ET.SubElement(root, "item")
ET.SubElement(item1, "name").text = "John"
ET.SubElement(item1, "age").text = "30"item2 = ET.SubElement(root, "item")
ET.SubElement(item2, "name").text = "Alice"
ET.SubElement(item2, "age").text = "25"tree = ET.ElementTree(root)
tree.write("output.xml")
3. 修改XML文件
使用xml.etree.ElementTree模块可以修改XML文件
import xml.etree.ElementTree as ETtree = ET.parse("data.xml")
root = tree.getroot()# 修改数据
for child in root:if child.find("name").text == "John":child.find("age").text = "31"tree.write("modified.xml")
4. 查询XML元素
使用XPath表达式来查询和选择XML元素。
import xml.etree.ElementTree as ETtree = ET.parse("data.xml")
root = tree.getroot()# 使用XPath查询
for item in root.findall("./item[name='John']"):age_element = item.find("age")if age_element is not None:print("John's age:", age_element.text)
5 遍历XML元素
遍历XML文档的元素,以访问、处理和操作其中的数据。
# 遍历子元素
for child in root:print("Element:", child.tag)for sub_element in child:print(" Sub Element:", sub_element.tag, "Value:", sub_element.text)
6. 删除XML元素
可以使用remove()方法删除XML元素。
import xml.etree.ElementTree as ETtree = ET.parse("data.xml")
root = tree.getroot()# 删除元素
for item in root.findall("./item[name='Alice']"):root.remove(item)tree.write("updated.xml")
7. 使用lxml库
lxml是一个高效且功能强大的Python库,用于处理XML和HTML数据。它基于C语言的libxml2和libxslt库构建而成,提供了快速、灵活和易于使用的API,适用于解析、创建、修改和查询XML和HTML文档。这个完整的代码示例涵盖了lxml库的一些常见操作,帮助你理解如何使用lxml处理XML数据。
假设我们有一个名为data.xml的XML文件:
<root xmlns:ns1="http://example.com/ns1" xmlns:ns2="http://example.com/ns2"><ns1:item><ns1:name>John</ns1:name><ns1:age>30</ns1:age></ns1:item><ns2:item><ns2:name>Alice</ns2:name><ns2:age>25</ns2:age></ns2:item>
</root>
下面是使用lxml库的一些常见操作示例:
from lxml import etree# 解析XML文件
tree = etree.parse("data.xml")
root = tree.getroot()# 定义命名空间
namespaces = {"ns1": "http://example.com/ns1", "ns2": "http://example.com/ns2"}# 查询并输出John的年龄
john_age = root.xpath("//ns1:item[ns1:name='John']/ns1:age", namespaces=namespaces)[0]
print("John's age:", john_age.text)# 遍历所有item元素
for item in root.xpath("//ns1:item", namespaces=namespaces):name = item.find("ns1:name", namespaces=namespaces).textage = item.find("ns1:age", namespaces=namespaces).textprint("Name:", name, "Age:", age)# 创建新元素
new_item = etree.Element("{http://example.com/ns1}item")
new_name = etree.SubElement(new_item, "{http://example.com/ns1}name")
new_name.text = "Eve"
new_age = etree.SubElement(new_item, "{http://example.com/ns1}age")
new_age.text = "28"# 添加新元素到根元素
root.append(new_item)# 修改Alice的年龄
alice_age = root.xpath("//ns2:item[ns2:name='Alice']/ns2:age", namespaces=namespaces)[0]
alice_age.text = "26"# 删除John的元素
john_item = root.xpath("//ns1:item[ns1:name='John']", namespaces=namespaces)[0]
root.remove(john_item)# 将修改写回XML文件
tree.write("output_lxml.xml", pretty_print=True)
无论使用内置的
xml.etree.ElementTree还是lxml库,处理XML文件时都要考虑数据的结构和格式,以确保正确地解析、创建、修改和操作XML数据。
8. 处理XML命名空间
如果XML文件使用了命名空间,需要使用命名空间前缀来访问和操作元素。
namespaces = {"ns": "http://example.com/ns1"}
for element in root.findall("ns:book", namespaces):print("Book Title:", element.find("ns:title", namespaces).text)
XML命名空间(Namespace)是一种机制,用于在XML文档中标识和区分不同来源的元素和属性,以避免名称冲突。命名空间在处理多个XML文档合并、数据交换和数据共享时非常有用。XML命名空间通过为元素和属性名称添加前缀来定义,使其在不同的命名空间中唯一。
命名空间的基本概念
- 命名空间URI(Namespace URI): 命名空间的唯一标识符,通常是一个URL或URI,用于表示命名空间的名称。
- 命名空间前缀(Namespace Prefix): 一个短字符串,用于在XML文档中标识使用了哪个命名空间。通常以
xmlns关键字声明,如xmlns:prefix="namespace_uri"。
在XML中声明命名空间
<root xmlns:ns1="http://example.com/ns1"><ns1:element>Content</ns1:element>
</root>
在上面的例子中,xmlns:ns1="http://example.com/ns1"声明了一个名为ns1的命名空间前缀,与URI http://example.com/ns1 相关联。因此,ns1:element 中的 ns1 表示这个元素属于指定的命名空间。
使用XPath与命名空间
XPath查询语句中的元素名也需要使用命名空间前缀来定位。
from lxml import etreetree = etree.parse("data.xml")
root = tree.getroot()namespaces = {"ns": "http://example.com/ns1"}
for element in root.findall("ns:element", namespaces):print("Element:", element.text)
默认命名空间
XML中还可以使用默认命名空间,但在XPath中使用默认命名空间稍有不同。默认命名空间在XPath中没有前缀。
<root xmlns="http://example.com/ns1"><element>Content</element>
</root>
from lxml import etreetree = etree.parse("data.xml")
root = tree.getroot()namespaces = {"default": "http://example.com/ns1"}
for element in root.findall(".//default:element", namespaces):print("Element:", element.text)
处理多个命名空间
如果XML中包含多个命名空间,需要在查询中使用相应的命名空间前缀。
<root xmlns:ns1="http://example.com/ns1" xmlns:ns2="http://example.com/ns2"><ns1:element>Content 1</ns1:element><ns2:element>Content 2</ns2:element>
</root>
from lxml import etreetree = etree.parse("data.xml")
root = tree.getroot()namespaces = {"ns1": "http://example.com/ns1", "ns2": "http://example.com/ns2"}
for element in root.findall("ns1:element", namespaces):print("Element from ns1:", element.text)
for element in root.findall("ns2:element", namespaces):print("Element from ns2:", element.text)
XML命名空间是一种重要的概念,特别是在处理多个XML文档合并、交换数据和共享数据时。通过正确理解和使用命名空间,可以避免名称冲突,确保数据的正确性和一致性。
三、 XML文件操作常见问题与解决
处理XML文件时,可能会遇到一些特殊的异常情况,需要进行特殊的异常处理。以下是一些可能的特殊异常情况及其处理方法:
1. XML文件不存在或无法打开
问题: 当指定的XML文件不存在或无法打开时,会引发FileNotFoundError异常。
处理方法: 在打开文件之前,使用try和except语句捕获异常,进行相应的处理。
import xml.etree.ElementTree as ETtry:tree = ET.parse("data.xml")root = tree.getroot()
except FileNotFoundError:print("XML file not found.")
except ET.ParseError:print("Error parsing XML file.")
2. 解析错误
问题: 解析XML文件时,如果文件格式不符合XML规范,会引发xml.etree.ElementTree.ParseError异常。
处理方法: 捕获ParseError异常,进行错误处理。
import xml.etree.ElementTree as ETtry:tree = ET.parse("data.xml")root = tree.getroot()
except ET.ParseError:print("Error parsing XML file.")
3. 查询元素不存在
问题: 当使用XPath查询时,如果查询的元素不存在,会引发TypeError或AttributeError等异常。
处理方法: 在使用查询结果之前,检查是否存在查询的元素,以避免引发异常。
import xml.etree.ElementTree as ETtree = ET.parse("data.xml")
root = tree.getroot()name_element = root.find("./item[name='NonExistentName']")
if name_element is not None:print("Name:", name_element.text)
else:print("Name not found.")
4. 节点文本为空
问题: 有时节点的文本可能为空,访问节点的text属性可能引发AttributeError异常。
处理方法: 在访问节点文本属性之前,使用if语句检查节点是否具有文本。
import xml.etree.ElementTree as ETtree = ET.parse("data.xml")
root = tree.getroot()age_element = root.find("./item[name='John']/age")
if age_element is not None and age_element.text:age = age_element.text
else:age = "Age not available"print("Age:", age)
处理XML文件时,要注意捕获特定的异常类型,并根据异常的类型进行适当的处理。这有助于在处理异常时提供更有用的错误信息和解决方案。
相关文章:
【100天精通python】Day29:文件与IO操作_XML文件处理
目录 专栏导读 一、XML文件概述 1. 标签和元素 2. 嵌套结构 3. 属性 4. 命名空间 5. CDATA节 6. 注释 7. 验证与验证语言 8. 扩展性 二、XML文件处理常见操作 1. 解析XML文件 2. 创建和编辑XML文件 3. 修改XML文件 4. 查询XML元素 5 遍历XML元素 6. 删除XML元…...
人工智能的未来:探索下一代生成模型
推荐:使用 NSDT场景编辑器 助你快速搭建可编辑的3D应用场景 生成式 AI 目前能够做什么,以及探索下一波生成式 AI 模型需要克服的当前挑战? 如果你跟上科技世界的步伐,你就会知道生成式人工智能是最热门的话题。我们听到了很多关于…...

C++ 运算符重载为非成员函数
运算符也可与重载为非成员函数。这时运算所需要的操作数都需要通过函数的形参表来传递,在形参表中形参从左到右的顺序就是运算符操作数的顺序。如果需要访问运算符参数对象的私有成员,可以将该函数声明为友元函数。 【提示】不用机械地将重载运算符的非…...

[国产MCU]-BL602开发实例-定时器
定时器 文章目录 定时器1、BL602定时器介绍2、定时器驱动API介绍3、定时器使用实例3.1 单次计时3.2 持续计时通用定时器,用于定时,当时间到达我们所设置的定时时间会产生定时中断,可以用来完成定时任务。本文将详细介绍如何使用BL602的定时器功能。 1、BL602定时器介绍 BL6…...

re学习(29)攻防世界-CatFly(复原反汇编)
因为这是一个.dll文件,在Linux上运行一下: 找到主要函数:(以及由上面三部分对应的代码部分) __int64 __fastcall main(int a1, char **a2, char **a3) {size_t v3; // rbx__int16 v5[4]; // [rsp10h] [rbp-4B0h] B…...

Android WIFI-概率性不能自连
1.连上wifi时同步保存wifi密码,避免连上wifi后马上断电重启由于密码没保存导致不能自动重连wifi packages/modules/Wifi/service/java/com/android/server/wifi/SupplicantStaIfaceHal.java @@ -66,6 +66,7 @@ import com.android.server.wifi.WifiNative.SupplicantDeathEve…...

用Python批量复制文件,方法有9种,方便快捷
前言 大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 当我们复制一个文件时用复制粘贴就可以了,如果是多个文件呢? 就会很麻烦了! 今天给大家介绍一下用Python批量复制文件,方法有九种!希望对你有帮助 1. Shutil Copy…...
《凤凰架构》第一章——服务架构演进史
前言 刚开始决定弄懂文中所提到的所有东西,就像我写ByteByteGo呢几篇文章一样,把每一句话都弄懂。但是对于《凤凰架构》来说,这有点太费时间了,并且没有必要,有些东西可能永远都不会用到,但文章为了全面的…...

【iPhone】手机还有容量,拍视频却提示 iPhone 储存空间已满
文章目录 前言解决方案 结语 前言 今天在用 iPhone 录像的时候突然提醒我 iPhone储存空间已满 你没有足够的储存空间来录制视频” 可我明明还有 20G 的容量 我非常疑惑,因为我之前还剩1个G都能录像,现在20G反而不行了,于是重启了手机&#…...
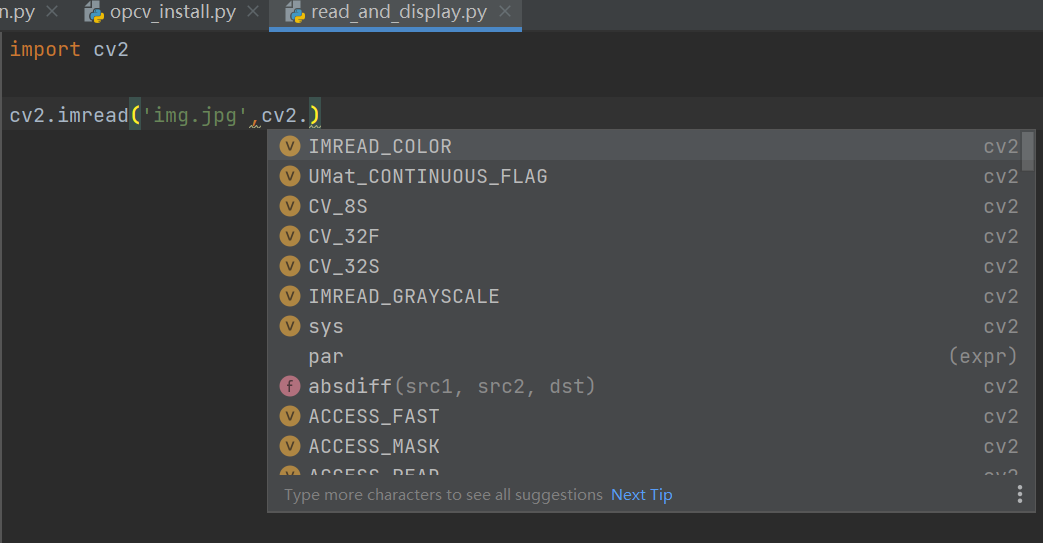
pycharm中opencv库导入 cv2. 无函数提示跳出解决方法
pycharm中opencv库导入 cv2. 无函数提示跳出解决方法 1、找到当前解释器安装目录 例如: 2、进入D:\Python37\Lib\site-packages\cv2文件,进入cv2文件夹: 找到cv2.pyd, 把cv2.pyd复制一份,放到上层文件夹下,即site-p…...
week3
题解: 前序遍历性质: 节点按照 [ 根节点 | 左子树 | 右子树 ] 排序。 中序遍历性质: 节点按照 [ 左子树 | 根节点 | 右子树 ] 排序。 通过以上三步,可确定 三个节点 :1.树的根节点、2.左子树根节点、3.右子树根节点。 之后进行…...
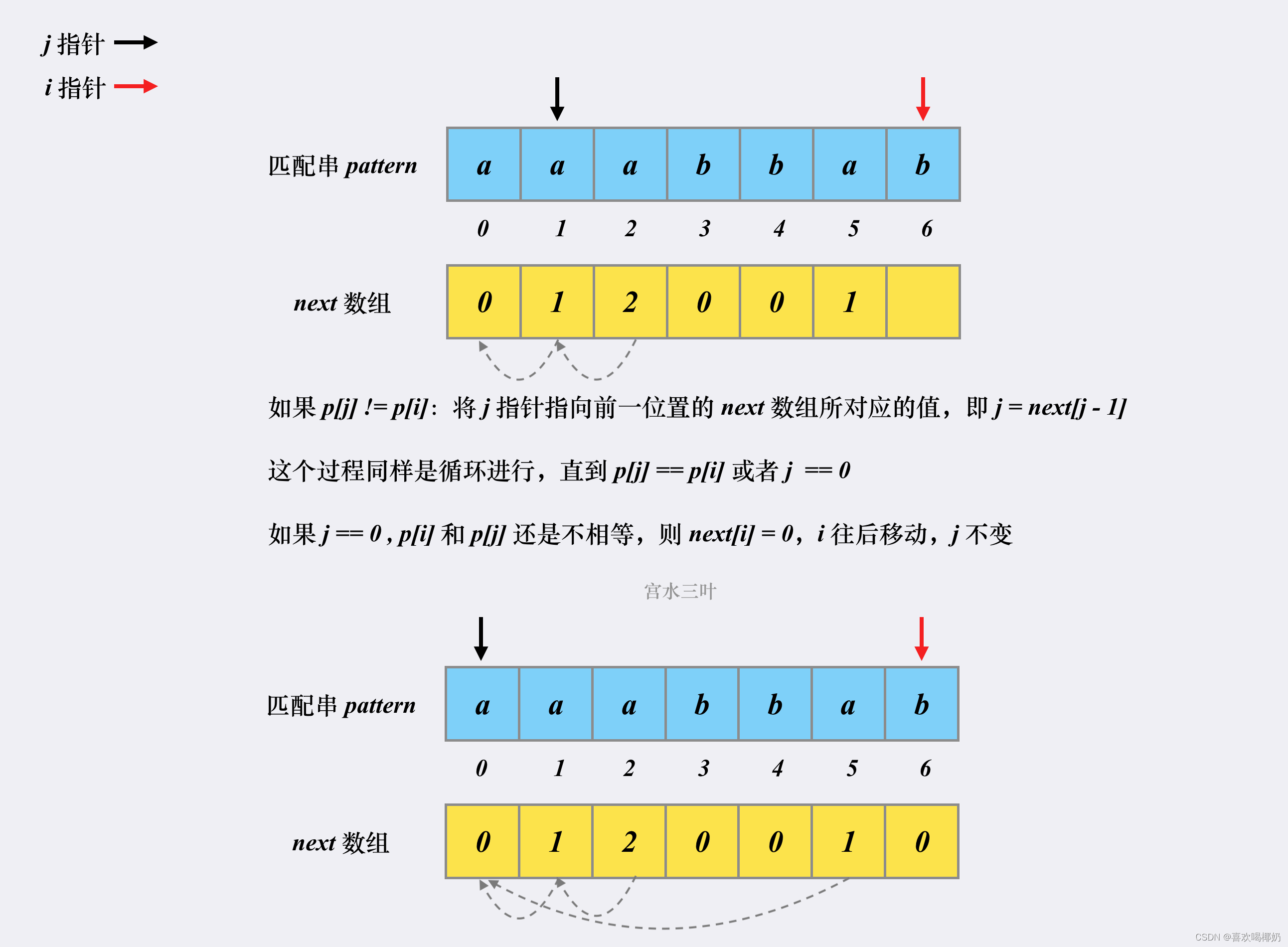
LeetCode28.找出字符串中第一个匹配项的下标
28.找出字符串中第一个匹配项的下标 目录 28.找出字符串中第一个匹配项的下标题目描述解法一:朴素的模式匹配解法二:KMP算法KMP解决的问题类型最长公共前后缀KMP算法过程next数组的构建代码实现 题目描述 给你两个字符串haystack和needle,请…...
爬虫009_字符串高级_替换_去空格_分割_取长度_统计字符_间隔插入---python工作笔记028
然后再来看字符串的高级操作 取长度 查找字符串下标位置 判断是否以某个字符,开头结尾 计算字符出现次数 替换...
Windows 安装Tensorflow2.1、Pycharm开发环境
文章目录 1、安装anaconda2、安装Tensoflow2.1、创建虚拟环境2.2、安装Tensorflow依赖2.3、验证Tensorflow是否成功 3、配置pycharm环境4、错误记录 1、安装anaconda https://www.anaconda.com/download 打开命令行工具,出现base就表示安装成功了,表示当…...
)
【javaScript】数组的常用方法(自用记忆版)
目录 一、操作方法 增 push() unshift() splice() concat() 删 pop() shift() splice() slice() 改 splice() 查 indexOf() includes() find() 二、排序方法 reverse() sort() 三、转换方法 join() 四、迭代方法 some() every() forEach…...
全新二开美化版UI好看的社区源码下载/反编译版
2023全新二开美化版UI精美的社区源码下载/反编译版 之前我分享过Rule原版,相信大家已经有很多人搭建好了。这次我要分享的是RuleAPP的二开美化版(请尊重每个作者的版权),这个版本没有加密,可以进行反编译,…...
Docker 发布一个springboot项目
文章目录 1、新建SpringBootDemo项目并打包2、使用Dockerfile打包(基础用法)进一步maven源码打包法 3、更进一步(maven插件打包)docker-maven-pluginspring-boot-maven-plugin前提条件本地环境配置项目环境配置maven插件打包运行校…...

办公信息系统安全基本技术要求
范围 本标准规定了办公信息系统的安全基本技术要求。 本标准适用于指导党政部门的办公信息系统建设,包括在系统设计、产品采购、系统集成等方面应遵循的基本原则,以及应满足的基本技术要求。涉密办公信息系统的建设管理应依据相关国家保密法规和标准要…...

有效管理IT问题的5个原则
问题管理就是发现未知的、隐藏的问题,这是根本原因, 这是您 IT 帮助台无穷无尽的工单来源。当您实施有效的 问题管理,您的 IT 团队可以超越消防模式,专注于战略 IT 目标。以下是可以帮助您实现一流问题管理的五个原则:…...

【MongoDB】解决ProxmoxVE下CentOS7虚拟机安装MongoDB6后启动失败的问题
目录 安装步骤: 2.1 配置yum源 2.2 安装MongoDB 2.3 启 动MongoDB ProxmoxVE上新装的CentOS7.4虚拟机,安装MongoDB6。 安装步骤: 2.1 配置yum源 # 创建mongodb yum源(https://www.mongodb.co...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

破解路内监管盲区:免布线低位视频桩重塑停车管理新标准
城市路内停车管理常因行道树遮挡、高位设备盲区等问题,导致车牌识别率低、逃费率高,传统模式在复杂路段束手无策。免布线低位视频桩凭借超低视角部署与智能算法,正成为破局关键。该设备安装于车位侧方0.5-0.7米高度,直接规避树枝遮…...