苏宁数据治理实战方法论和三字经
随着移动互联网和大数据的蓬勃发展,“数据即资产”的理念深入人心。大数据已发展成为具有战略意义的生产资料,在各行各业发挥着极其重要的作用,而大数据也给很多企业带来了前所未有的自豪感和自信感。
但是,大数据真的是越“大”越好吗?大数据到达一定的规模,其所需承载的集群资源成本、数据开发维护成本和数据管理成本,将会呈几何式增长,同样也将会带来一笔巨额的开销。
如果缺少科学有效的治理管控,就会出现大量的“负”数据资产,这不仅会吞噬公司的利润,还会极大影响数据业务的发展以及平台运行的稳定。
很多大数据公司都会面临这样一些窘境:
- 新开发的数据任务,赶紧上,却发现集群资源不够了。
- 早上要跑完的任务,上午还没跑完,报表什么时候能看到?
- 上个月刚删了很多数据,存储又快满了,每天还有大量的数据在增长。
- 小文件数量这么多,集群 NameNode 内存快要爆了……
一个个头疼的问题接踵而至,面对这些问题我们是不是得换一个视角,给大数据集群资源来一场瘦身,取其精华、去其糟粕,让大数据集群资源环境更加健康,数据开发工作更加高效,公司投入产出比更加合理。
所以,大数据集群资源治理(以下简称“治理”)的工作亟待开展。
治理为何难以推动?
大多数公司在大数据发展初期都是野蛮生长的,它们更关注的是拥有更多的数据,更快速的完成数据业务开发,即使集群资源不够了,增加机器远比开展治理来得更快。
治理工作涉及众多的职能线与部门,角色不同,立场不同,治理投入度也不同。
即使集群资源达到一定规模,不得不治理时,各组织仍会以开发业务为核心,治理工作对他们来说优先级并不高,这也直接影响着治理效果。
治理工作如何开展?
苏宁认为,治理工作需要从组织保障和治理工具两方面协同推进。公司的支持至关重要,有助于建设统一的数据文化,推进成立数据治理委员会,明确各组织的职责,制定治理制度、标准和流程等,以专职的治理团队负责治理工具建设和整体运营推进。
不同于传统数据资产管理,大数据集群资源治理聚焦计算资源和存储资源的缩容,在保障平台性能和稳定性的同时,又需要考量数据资产管理的赋能。
大数据集群资源的治理工作应结合公司现状,集中精力解决当前最大痛点,优先治理紧急的、投入产出比高的治理项。
对于紧急的治理项,如果涉及的部门和用户较少,能够通过面对面、邮件、社交媒体进行沟通,在短时间内解决的,采用线下手工治理方式。
对于非紧急治理项,涉及的部门和用户较广,并且需要长期治理的,则采用线上工具辅助治理,以减少人力投入成本。
为此,苏宁启动了“巡湖工程”、“千迁工程”等专项治理工程:
- 巡湖工程,主要任务是对大数据集群资源进行全面的巡检和治理。
- 千迁工程,是对高算力的 Hive 任务,进行分批次迁移至 SparkSQL 计算平台,同时保障治理工作的全面性和聚焦性。
在治理工作方式的演进上,苏宁采用了四个步骤:线下手工治理、半工具化治理、工具化治理和自驱动治理,最终实现各组织自我驱动型的治理常态。
典型治理场景和方案
大数据集群资源治理是一项庞大且复杂的工程,苏宁结合自己的治理经历,从计算治理、存储治理、性能和稳定性治理三个方面,分享一下典型的治理场景和解决方案。
计算治理
毫无疑问,CPU 和内存是集群的稀缺资源,保障集群资源算力是首要任务。
一旦计算资源缺乏,将面临数据采集、数据存储、数据加工、数据稽核等一系列数据作业的延误,甚至崩溃。
如何降低计算资源的消耗,提高任务执行的性能,缩短任务产出的时间,是计算治理的核心目标。
以下主要从任务复算治理、任务异常治理、任务削峰平谷治理、任务资源配置治理、计算框架优化几个角度,分别介绍计算治理优化。
①任务复算治理
数仓建设过程中,往往存在事实表与维度表多次关联、事实表与事实表多次关联的现象,造成数据的重复计算。
任务复算治理,是面向大数据离线任务 Hive、SparkSQL 等 SQL 类的任务,通过对表与表关联的 union、join、子查询复杂关联等语法进行解析,识别重复计算的任务及其读取的关联表(源表)数据,并以此推动公共模型建设,减少任务重复计算。
其中,表关联 union 方式识别比较简单,示例如下:
②任务异常治理
任务出错率是衡量任务是否需要治理的重要指标,出错率过高意味着这个任务是没有价值的,一般可以被清除。如果任务确实需要使用,则必须进行优化。
以下作为一个参考,阈值可根据实际情况进行调整:
另外,当任务的目标表在一个或多个调度周期内未作更新,可认定为该任务未产出数据,任务清除下线的可能性很大。
③任务削峰平谷治理
从全天来看,任务执行会有明显的忙闲时之分。大部分公司的忙时主要集中在凌晨 0 点至 8 点,其余时间段相对为闲时,这就造成了忙时计算资源严重紧缺。
大家都想在早上 8 点前跑完任务,但是不是每个忙时任务都有这个必要呢?通过对忙时任务产出表的被读时间进行分析,可以识别出不合理调度执行的任务。
比如,如果任务在早上 8 点跑完,其写入的目标表在中午 12 点才被读取,是否可以将该任务避开忙时执行?
④任务资源配置治理
这里主要谈一下 Spark Streaming 实时任务资源治理。Spark Streaming 和 Spark 处理逻辑是相同的,都是收到外部数据流之后按照时间切分。
“微批”处理一个个切分后的文件,往往会存在资源分配过多的现象,这很容易被识别。
由上图可见,将数据按照时间划分成 N 等分。假设每批次 A 的间隔时长:batch_time;处理 B 的时长:total_delay;等待 C 的时长:wait_time。
当出现 batch_time>>total_delay 时,当前任务占用的资源会浪费 wait_time。
通过缩减任务资源或多个任务合并成一个任务的方式来治理,都可以提升资源利用率。
虽然 total_delay 会加长,只要整体处理时间还在原定计划内,即可满足业务需求。
⑤计算框架优化
计算框架越来越多,也越来越成熟完善,选择适合自己的计算框架是关键。比如,由 Hive 任务迁移至 SparkSQL 任务、Storm 任务迁移至 Flink 任务,会带来性能上的明显提升。
但是,在海量数据任务的前提下,任务迁移绝非易事,需要综合考虑迁移的方案以及涉及的成本和风险。
存储治理
在数据爆发式增长的今天,存储资源的有效使用也面临着一系列的挑战。如何降低存储资源的消耗,节省存储成本,是存储治理的目标。
以下主要从生命周期管理、数据压缩治理、数据复存治理、数据价值治理几个角度介绍存储治理优化。
①生命周期管理
根据表生命周期对表进行清理删除,是最常见有效的存储治理方式。为降低数据丢失风险,可以先对表进行 rename 或通过 ranger 禁止表读写权限(相当于逻辑删除),7 天观察期过后删除至回收站,回收站默认保留 3 天后进行最终删除。
如果表的生命周期设置不合理(过长),也可以根据表的类型、业务情况进行稽核整改。
②数据压缩治理
数据压缩治理是最简单有效的存储治理方式。数据压缩的好处显而易见,可以直接节省磁盘空间,提升磁盘利用率,并且加速网络传输。
但同时数据的压缩和解压,需要消耗计算资源。如果集群计算资源紧缺,并且数据经常被读,则建议根据实际场景选择合适的数据压缩方式。
在不同的存储格式和压缩算法下,简单查询、大宽表查询和复杂查询的执行表现均有差异,具体需结合实际场景选择使用。
③数据复存治理
比较简单的方式是通过解析 Hive 任务、SparkSQL 任务的代码逻辑,分析代码中的读表、写表、条件、字段函数,识别读表和写表是否重复存储。
另外,也可以通过表名、字段名的相似度进行识别,并结合某些周期产出数据,抽样进行相似度对比分析和识别。
如果表数据出现重复存储,还需要根据链路血缘关系找出上游任务,对整个链路上的表及上游任务实施“一锅端”治理。
④数据价值治理
梳理当前业务价值,从数据应用层(包括报表、指标、标签)源头分析投入产出比,对整体链路资源进行“从上至下”的价值治理。
如果表长时间未作更新(如 32 天)或未被读取,往往表明这张表价值很低,甚至没有价值,则可对表进行清理删除,这时可以优先考虑治理大表、分区表、高成本表。
性能和稳定性治理
集群的性能和稳定性治理涉及众多方面,这里重点谈一下小文件治理和数据倾斜治理。
①小文件治理
HDFS 虽然支持水平扩展,但是不适合大量小文件的存储。因为 NameNode 将文件系统的元数据存放在内存中,导致存储的文件数目受限于 NameNode 内存大小。当集群到了一定规模,NameNode 内存就会成为瓶颈。
小文件治理需要根据当前集群的文件数量,定义合适的小文件大小,比如小于 1M。
治理方式需要考虑从源头控制,在任务中配置文件合并参数,在 HDFS 存储之前进行小文件合并,但这又会延长任务执行时间。
所以,可选择在闲时进行周期性的小文件合并。另外,也可以设置小文件占比阈值,根据阈值触发小文件合并。
②数据倾斜治理
很多时候,我们在用 Hive 或 Spark 任务取数,只是跑了一个简单的 join 语句,却跑了很长时间,往往会觉得这是集群资源不够导致的,但是很大情况下,是出现了“数据倾斜”的情况。
数据倾斜,在 MapReduce 编程模型中十分常见,大量的相同 key 被 partition 分配到一个分区里,造成了“某些任务累死,还拖了后腿,其他任务闲死”的情况,这并不利于资源最大化的有效利用。
由上图可见,通过对任务执行的监控日志分析,可以很方便的找出数据倾斜任务。
结合具体产生原因、数据分布和业务变化,有针对性的优化任务,任务执行时间能缩短几十倍以上,效果非常明显。
治理工具需要具备哪些能力?
面向治理责任人、项目主管、公司领导及治理运营人员,苏宁构建了统一的集群资源治理平台,全局把控集群计算资源、存储资源、性能和稳定性的整体情况,通过平台“识别通知、治理优化、监督考核”的支撑能力,实现一站式治理服务和闭环流程,降低治理投入的工作量,提升治理成效。
后记
苏宁建设了较为成熟的数据治理体系和标准流程,多项治理工作同步推进,均取得了显著的成果,为公司节约了可观的服务器资源投入成本。
并且,随着治理工作的推进,各组织也更主动的开展源头治理,大大减轻了事后治理的工作量。
治理工作不会一蹴而就,也不如前端业务那么容易出彩,显得“朴实无华”。每一位治理工作者都在背后默默的坚守付出,孜孜不倦地保障着大数据集群资源的最大化有效利用。
未来,苏宁大数据治理团队仍将持续推进治理工作,进一步提升治理工具产品支撑能力,赋能治理工作常态化、工具化和智能化。
我们崇尚科技与艺术的结合,最后赋诗一首,希望能帮助有需要的同仁更好的理解这项工作,更快的实现治理目标。
《苏宁数据治理 三字经》
--韦真
数之初,量本小。猛增长,遇瓶颈。
缺管理,实难控。若不治,随可崩。
若广治,惧其繁。治之道,贵以专。
高层挺,强执行。定职责,齐协作。
察现状,诊问题。能识别,准定位。
控增量,降存量。摊成本,明方向。
始源头,理价值。视场景,择平台。
宜压缩,需清理。去冗余,平峰谷。
治理急,线下先。累经验,建工具。
能优化,可评估。须考核,纳监督。
体系化,智能化。一站式,闭环式。
存储易,算力难。若有方,皆可成。
相关文章:

苏宁数据治理实战方法论和三字经
随着移动互联网和大数据的蓬勃发展,“数据即资产”的理念深入人心。大数据已发展成为具有战略意义的生产资料,在各行各业发挥着极其重要的作用,而大数据也给很多企业带来了前所未有的自豪感和自信感。 但是,大数据真的是越“大”越…...
)
创建型设计模式:3、单例模式(C++实现实例 线程安全)
目录 1、单例模式(Singleton Pattern)的含义 2、单例模式的优缺点 (1)优点: (2)缺点: 3、C实现单例模式的示例(简单) 4、C实现单例模式的示例ÿ…...

JavaWeb学习笔记
Maven:自动导入配置jar包。 Maven项目架构管理工具:核心思想:约定大于配置 Maven:环境优化 1.修改web.xml为最新的 <?xml version"1.0" encoding"UTF-8"?> <web-app xmlns"http://xmlns.jcp.org/xml/ns/javaee&…...

ad+硬件每日学习十个知识点(24)23.8.4(时序约束,SignalTap Ⅱ)
文章目录 1.建立时间和保持时间2.为什么要建立时序约束?3.SignalTap Ⅱ4.SignalTap Ⅱ使用方法5.HDL的仿真软件(modelsim)6.阻抗匹配 1.建立时间和保持时间 答: 2.为什么要建立时序约束? 答: 3.Sign…...

FortiGate防火墙日志审计运维
环境介绍 CPU:8核,内存:16GB,硬盘:100GB 操作系统版本:CentOS-7-x86_64-DVD-2003 平台版本:鸿鹄2.7.0 安装组件 安装环境支持确认 鸿鹄计算引擎使用了 AVX2 高级指令集做向量计算加速…...

基于yolo v5与Deep Sort进行车辆以及速度检测与目标跟踪实战
项目实验结果展示: 基于yolo v5与Deep Sort进行车辆以及速度检测与目标跟踪实战——项目可以私聊 该项目可以作为毕业设计,以及企业级的项目开发,主要包含了车辆的目标检测、目标跟踪以及车辆的速度计算,同样可以进行二次开发。 …...
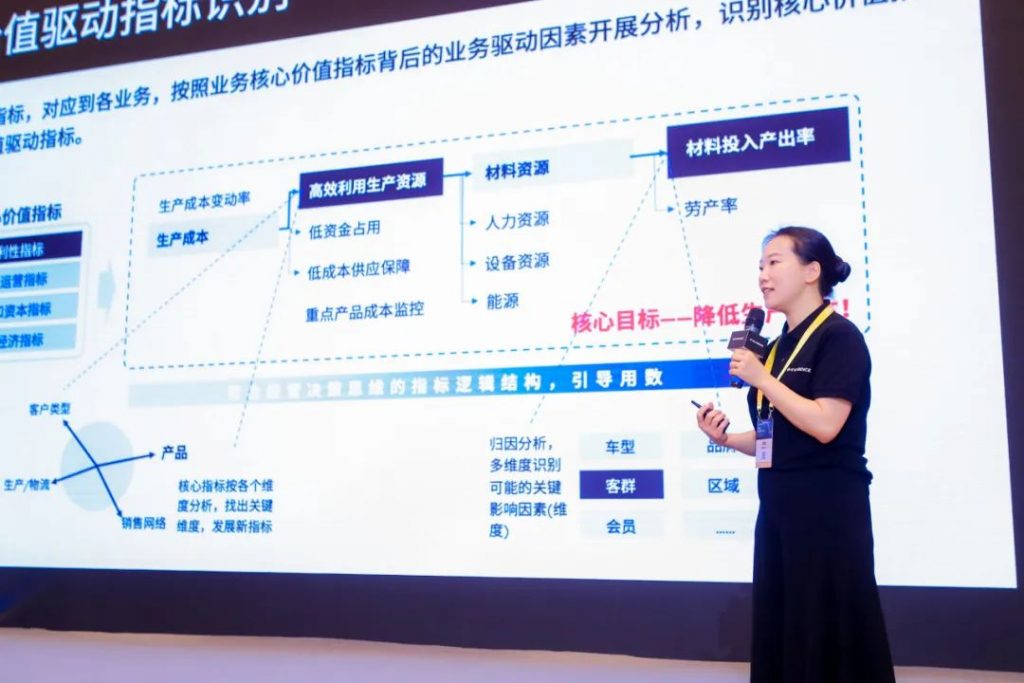
以指标驱动,保险、零售、制造企业开启精益敏捷运营的新范式
近日,以“释放数智生产力”为主题的 Kyligence 用户大会在上海前滩香格里拉大酒店成功举行。大会包含上午的主论坛和下午的 4 场平行论坛,并举办了闭门会议、Open Day 等活动。来自金融、零售、制造、医药等行业的客户及合作伙伴带来了超过 23 场主题演讲…...
MyBatis-动态SQL-foreach
目录 标签有以下常用属性: 小结 <froeach> <foreach>标签有以下常用属性: collection:指定要迭代的集合或数组的参数名(遍历的对象)。item:指定在迭代过程中的每个元素的别名(遍历…...

VUE框架:vue2转vue3全面细节总结(3)路由组件传参
大家好,我是csdn的博主:lqj_本人 这是我的个人博客主页: lqj_本人_python人工智能视觉(opencv)从入门到实战,前端,微信小程序-CSDN博客 最新的uniapp毕业设计专栏也放在下方了: https://blog.csdn.net/lbcy…...

音视频技术开发周刊 | 305
每周一期,纵览音视频技术领域的干货。 新闻投稿:contributelivevideostack.com。 大神回归学界:何恺明宣布加入 MIT 「作为一位 FAIR 研究科学家,我将于 2024 年加入麻省理工学院(MIT)电气工程与计算机科学…...

vue 图片base64转化
import html2canvas from ‘html2canvas’ html2canvas(canvasDom, options).then(canvas > { //此时的图片是base64格式的,我们将图片格式转换一下 let type ‘png’; let imgData canvas.toDataURL(type); // 照片格式处理 let _fixType function(type) { …...

TS学习03-类
类 calss A {name: stringconstructor(name:string) {this.name name}greet() {return hello, this.name} } let people new A(RenNing)继承 子类是一个派生类,他派生自父类(基类),通过 extends关键字 派生类通常被称作 子类…...
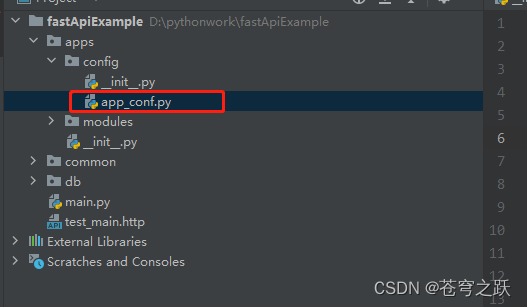
FastAPI(七)应用配置
目录 一、在apps下新建文件夹config 二、新建配置文件app_conf.py 一、在apps下新建文件夹config 二、新建配置文件app_conf.py from functools import lru_cachefrom pydantic.v1 import BaseSettingsclass AppConfig(BaseSettings):app_name: str "Windows10 插件&qu…...
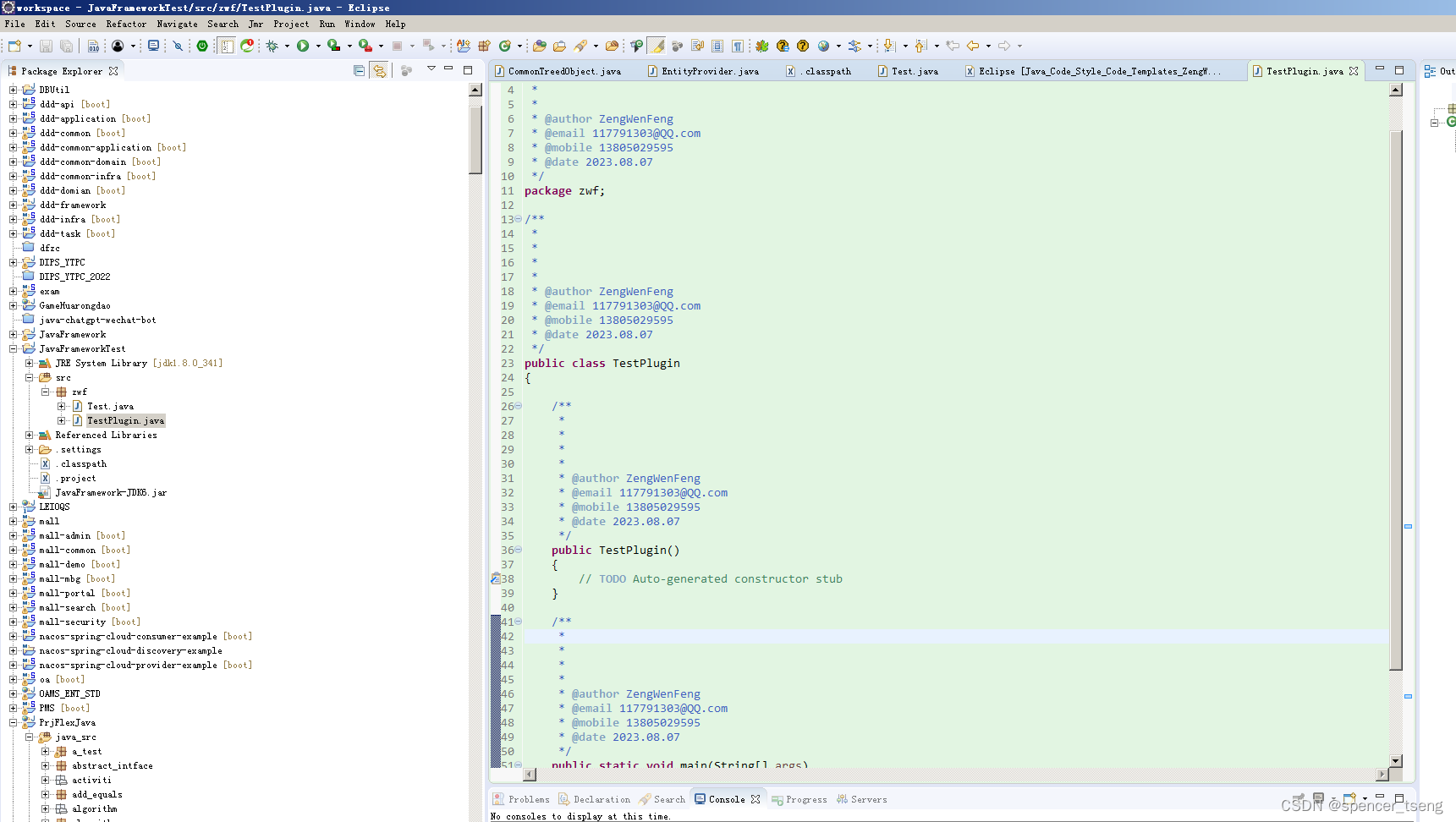
eclipse Java Code_Style Code_Templates
Preferences - Java - Code Style - Code Templates Eclipse [Java_Code_Style_Code_Templates_ZengWenFeng] 2023.08.07.xml 创建一个新的工程,不然有时候不生效,旧项目可能要重新导入eclipse 创建一个测试类试一试 所有的设置都生效了...
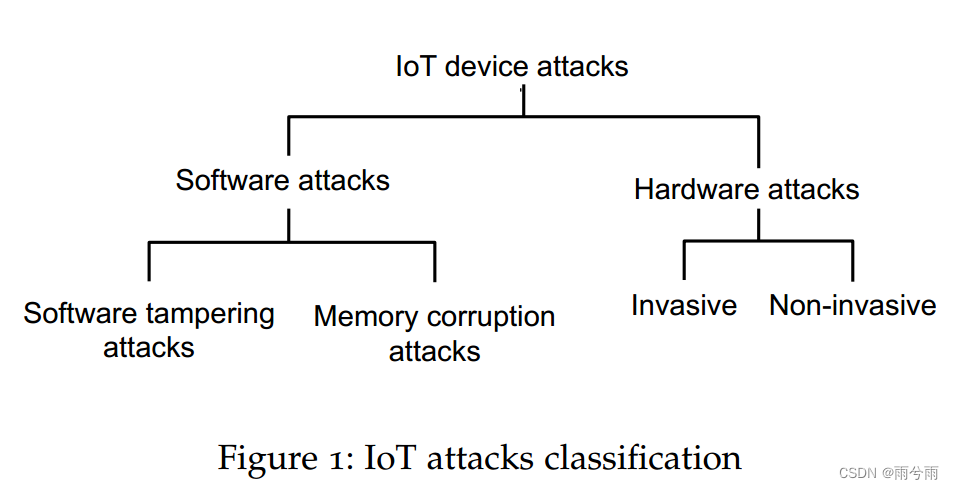
01《Detecting Software Attacks on Embedded IoT Devices》随笔
2023.08.05 今天读的是一篇博士论文 论文传送门:Detecting Software Attacks on Embedded IoT Devices 看了很长时间,发现有一百多页,没看完,没看到怎么实现的。 摘要 联网设备的增加使得嵌入式设备成为各种网络攻击的诱人目标&…...
APP外包开发的学习流程
学习iOS App的开发是一项有趣和富有挑战性的任务,是一个不断学习和不断进步的过程。掌握基础知识后,不断实践和尝试新的项目将使您的技能不断提升。下面和大家分享一些建议,可以帮助您开始学习iOS App的开发。北京木奇移动技术有限公司&#…...

第0章 环境搭建汇总
mini商城第0章 环境搭建汇总 本文是整个mini商城的前置文档,所有用到的技术安装都在本篇文档中有详细描述。所有软件安装不分先后顺序,只是作为一个参考文档,需要用到什么技术软件,就按照文档安装什么软件,切不可一上来全部安装一遍。 文章中有些截图中服务器地址是192.16…...

大数据培训课程-《机器学习从入门到精通》上新啦
《机器学习从入门到精通》课程是一门专业课程,面向人工智能技术服务,课程系统地介绍了Python编程库、分类、回归、无监督学习和模型使用技巧以及算法和案例充分融合。 《机器学习从入门到精通》课程亮点: 课程以任务为导向,逐步学…...
暗黑版GPT流窜暗网 降低犯罪门槛
随着AIGC应用的普及,不法分子利用AI技术犯罪的手段越来越高明,欺骗、敲诈、勒索也开始与人工智能沾边。 近期,专为网络犯罪设计的“暗黑版GPT”持续浮出水面,它们不仅没有任何道德界限,更没有使用门槛,没有…...

数电与Verilog基础知识之同步和异步、同步复位与异步复位
同步和异步是两种不同的处理方式,它们的区别主要在于是否需要等待结果。同步是指一个任务在执行过程中,必须等待上一个任务完成后才能继续执行下一个任务;异步是指一个任务在执行过程中,不需要等待上一个任务完成,可以…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...