LISA:通过大语言模型进行推理分割
论文:https://arxiv.org/pdf/2308.00692
代码:GitHub - dvlab-research/LISA
摘要
尽管感知系统近年来取得了显著的进步,但在执行视觉识别任务之前,它们仍然依赖于明确的人类指令来识别目标物体或类别。这样的系统缺乏主动推理和理解隐含用户意图的能力。在这项工作中,我们提出了一种新的分割任务-推理分割。该任务的目的是在给定复杂且隐式的查询文本的情况下输出分割mask。此外,我们建立了一个由一千多个图像指令对组成的基准,将复杂的推理和世界知识纳入评估目的。最后,我们提出了LISA:大型语言指导分割助手(large Language Instructed Segmentation Assistant),它继承了多模态大型语言模型(LLM)的语言生成能力,同时还具有生成分割掩码的能力。我们使用<SEG>标记扩展原始词汇表,并提出嵌入作为掩码范式来解锁分割功能。值得注意的是,LISA可以处理以下情况:1)复杂推理;2)世界知识;3)解释性答案;4)多回合对话。此外,当只在无推理数据集上训练时,它显示出强大的zero shot能力。此外,仅使用239对推理分割图像指令对模型进行微调可以进一步提高性能。实验表明,该方法不仅开启了新的推理分割能力,而且在复杂推理分割和标准参考分割任务中都是有效的。

背景
在这项工作中,我们引入了一种新的分割任务-推理分割,它需要基于涉及复杂推理的隐式查询文本生成二进制分割mask。
值得注意的是,查询文本并不局限于简单的引用(例如,“橘子”),而是涉及复杂推理或世界知识的更复杂的描述(例如,“高质量的食物含有维生素C”)。为了完成这一任务,模型必须具备两个关键能力:1)与图像联合推理复杂和隐式的文本查询;2)生成分割掩码。
尽管一些研究已经将robust的推理能力集成到多模态llm中以适应视觉输入,但这些模型中的大多数主要集中在文本生成任务上,并且在执行以视觉为中心需要细粒度fine-grained的输出格式的任务时仍然不足,例如分割。
通过将分割掩码表示为嵌入,LISA获得了分割能力,并从端到端训练中获益。
贡献
1) 我们引入了推理分割任务,该任务需要基于隐含的人类指令进行推理。这项任务强调了自我推理能力的重要性,这对于构建一个真正智能的感知系统至关重要。
2) 我们建立了一个推理分割基准,ReasonSeg,包含一千多个图像指令对。这个基准对于评估和鼓励社区开发新技术至关重要。
3) 我们提出了我们的模型- LISA,它采用嵌入作为掩码范式来合并新的分割功能。当在无推理数据集上训练时,LISA在推理分割任务上表现出强大的零射击能力,并且通过对239对涉及推理的图像指令对进行微调,进一步提高了性能。我们相信LISA将促进感知智能的发展,并激发这一方向的新进展。
相关工作
图像分割 IMAGE SEGMENTATION
语义分割的目的是为图像中的每个像素分配一个类标签。
大量研究提出了多种设计(如编码器-解码器、扩展卷积、金字塔池模块、非局部算子等)来有效地编码语义信息。
实例分割研究和全视分割为实例级分段引入了各种架构创新,包括基于DETR (Carion et al., 2020)的结构、mask attention 和 dynamic convolution。
最近,Kirillov等人(2023)引入了SAM,使用数十亿个高质量掩码进行训练,支持边界框和点作为提示,同时展示了出色的分割质量。X-Decoder (Zou et al., 2023a)在视觉和语言之间架起了桥梁,将多个任务统一在一个模型中。SEEM (Zou et al., 2023b)进一步支持各种人类交互方法,包括文本、音频和涂鸦。然而,这些研究主要关注多任务的兼容性和统一,而忽视了新功能的注入。
在这项工作中,我们提出了LISA来解决推理分割任务,并通过自我推理能力增强现有的视觉分割器。
多模态大语言模型 MULTI-MODAL LARGE LANGUAGE MODEL
受llm卓越的推理能力的激励,研究人员正在探索将这些能力转移到视觉领域的方法,开发多模态llm。
Flamingo(Alayrac,2022)采用交叉注意结构来关注视觉情境,从而实现视觉情境学习。
BLIP-2 (Li et al., 2023b)和mPLUG-OWL (Ye et al., 2023)等模型提出用视觉编码器编码图像特征,然后将其与文本嵌入一起输入LLM。
Otter (Li et al., 2023a)通过对拟议的MIMIC-IT数据集进行上下文指令调优,进一步整合了鲁棒的少镜头功能。LLaVA (Liu et al., 2023b)和MiniGPT-4 (Zhu et al., 2023)首先进行图像-文本特征对齐,然后进行指令调优。
此外,众多著作(Wu et al., 2023;Yang et al., 2023b;沈等,2023;Liu et al., 2023c;Yang等人,2023a)利用即时工程,通过API调用连接独立模块,但没有端到端培训的好处。
最近,有一些研究探讨了LLM和视觉任务多模态之间的交集。
VisionLLM (Wang et al., 2023)通过指令调优为多个以视觉为中心的任务提供了灵活的交互界面,但未能充分利用llm进行复杂的推理。
Kosmos -2 (Peng et al., 2023)构建了基于图像-文本对的大规模数据,为llm注入了基于的能力。GPT4RoI (Zhang et al., 2023)引入空间框作为输入,在区域-文本对上训练模型
相比之下,我们的工作旨在
1)有效地将分割能力注入到多模态llm中
2)解锁当前感知系统的自我推理能力。
Reasoning Segmentation 推理分割介绍

问题定义
推理分割任务是给定一个输入图像ximg和一个隐式查询文本指令xtxt,输出一个二值分割maskM
查询文本可能不是简单的短语(例如,“垃圾桶”),而是包含更复杂的表达式(例如,“应该把垃圾放入的东西”)或更长的句子(例如,“烹饪后,吃完食物,我们可以把剩下的食物和残羹冷炙扔在哪里?”),这涉及到复杂的推理或世界知识。
基准 Benchmark
在缺乏定量评价的情况下,为推理分割任务建立一个基准是十分必要的。为了确保可靠的评估,我们从OpenImages (Kuznetsova et al., 2020)和ScanNetv2 (Dai et al., 2017)中收集了一组不同的图像,并用隐含的文本指令和高质量的目标掩码对它们进行注释。我们的文字说明包括两种类型:1)短句;2)长句子,如图2所示。所得的ReasonSeg基准测试总共包含1218个图像指令对。该数据集进一步划分为三个部分:train、val和test,分别包含239、200和779个图像指令对。由于基准测试的主要目的是评估,因此验证和测试集包含更多的图像指令样本。
方法
模型结构

Embedding as Mask
VisionLLM (Wang et al., 2023)可以通过将分割掩码解析为多边形序列,支持将分割掩码表示为纯文本,并允许在现有多模态llm框架内进行端到端训练。然而,除非使用大量的数据和计算资源,否则多边形序列的端到端训练会引入优化挑战,并可能损害泛化能力。例如,训练一个7B模型,VisionLLM需要4 × 8 NVIDIA 80G A100 gpu和50个epoch,这在计算上是令人望而却步的。相比之下,训练LISA-7B只需要在8台NVIDIA 24G 3090 gpu 上训练10,000步。
为此,我们提出了嵌入作为掩码范式,将新的分割功能注入到多模态LLM中。
step1
Text
我们首先用一个新的令牌扩展原始的LLM词汇表,即<SEG>,它表示对segmentation输出的请求。给定文本指令xtxt和输入图像ximg,我们将它们输入到多模态LLM F中,LLM F反过来输出文本响应ytxt。

当LLM打算生成二进制分割掩码时,输出的ytxt应该包含一个<SEG>令牌。
然后,我们提取与<SEG>令牌对应的最后一层嵌入- hseg,并应用MLP投影层γ来获得hseg。
image
同时,视觉骨干神经网络从视觉输入图像中提取视觉嵌入。最后,hseg和f被馈送到解码器Fdec以产生最终的分割掩码M。解码器Fdec的详细结构参照Kirillov et al.(2023)。该过程可表述为

Training Objectives
损失函数
使用文本生成损失Lxt和segmentation mask损失Lmask对模型进行端到端训练。总目标L是这些损失的加权和,由λtxt和λmask决定:
![]()
具体来说,Ltxt是文本生成的自回归交叉熵损失,Lmask是掩码损失,这促使模型产生高质量的分割结果。为了计算Lmask,我们采用了每像素二进制交叉熵(BCE)损失和DICE损失的组合,相应的损失权重分别为λbce和λdice。给定真值目标ytxt和m,这些损失可以表示为:

Training Data Formulation 训练数据公式
我们的训练数据由三部分组成,全部来源于广泛使用的公共数据集。具体情况如下

Semantic Segmentation Dataset.语义分割数据集
语义分割数据集通常由图像和相应的多类标签组成。
在训练过程中,我们随机为每个图像选择几个类别。为了生成与可视化问答格式匹配的数据,我们使用了如下的问答模板
" USER: <IMAGE>你能分割这个图像中的{CLASS NAME}吗? "助理:是<SEG>,其中{CLASS NAME}是选择的类别,<IMAGE>表示图像patches token 的placeholder。
使用相应的二值分割掩码作为ground truth,提供mask loss监督。在训练过程中,我们还使用其他模板来生成QA数据,以保证数据的多样性。我们采用ADE20K,COCO-Stuff和LVIS-PACO零件分割数据集。
Vanilla Referring Segmentation Dataset 参考分割数据集
参考分割数据集提供输入图像和目标对象的显式简短描述。
因此,使用类似于“USER: <IMAGE>可以在此图像中分割{description}吗?”这样的模板很容易将它们转换为问答对。Assistant:当然,是<SEG>,其中{description}是给定的显式描述。本部分采用refCOCO、refCOCO+、refCOCOg和refCLEF数据集。
Visual Question Answering Dataset 图片问答数据集
为了保持多模态LLM原有的视觉问答(VQA)能力,我们还在训练过程中加入了VQA数据集。我们直接使用GPT-4生成的llava - instruction -150k数据(Liu et al., 2023b)。
可训练参数
为了保持预训练的多模态LLM F(即我们实验中的LLaVA)的泛化能力,我们利用LoRA (Hu et al., 2021)进行高效微调,并完全冻结视觉骨干区。解码器Fdec是完全微调的。此外,LLM的词嵌入和投影层γ也是可训练的。
实验
实验设置
网络结构
除非另有说明,我们采用LLaVA-7B-v1-1或LLaVA-13B-v1-1作为多模态LLM F
采用ViT-H SAM骨干网作为视觉骨干网。
γ的投影层是通道为[256,4096,4096]的MLP。
实现细节
8个NVIDIA 24G 3090 gpu
训练脚本基于deepspeed (Rasley et al., 2020)引擎。我们使用AdamW (Loshchilov & Hutter, 2017)优化器,学习率和权重衰减分别设置为0.0003和0。
我们也采用WarmupDecayLR作为学习率调度器,其中warmup迭代设置为100。
文本生成loss λtxt gen和掩码loss λmask的权值分别设为1.0和1.0,
bce loss λbce和dice loss λdice的权值分别设为2.0和0.5。
此外,每个设备的batch size设置为2,gradient accumulation step设置为10。在训练过程中,我们对语义分割数据集中的每个图像最多选择3个类别。
数据集
对于语义分割数据集,我们使用ADE20K (Zhou等人,2017)和COCO-Stuff (Caesar等人,2018)。此外,为了增强对物体某些部分的分割结果,我们还使用了部分语义分割数据集,包括PACO-LVIS (Ramanathan等人,2023)、PartImageNet (He等人,2022)和PASCAL-Part (Chen等人,2014);
对于参考分割数据集,我们使用了refCLEF, refCOCO, refCOCO+ (Kazemzadeh et al., 2014), and refCOCOg (Mao et al., 2016).
对于视觉问答(VQA)数据集,我们使用llava - instruction -150k数据集(Liu et al., 2023b)。为了避免数据泄露,我们在训练过程中排除了图像出现在refCOCO(+/g)验证集中的COCO样本。
此外,我们惊奇地发现,通过对ReasonSeg图像指令对的239个样本进行模型微调,模型的性能可以进一步提高。
评价指标
我们遵循之前大多数关于参考分割的工作(Kazemzadeh等人,2014;)gIoU是由所有每个图像的交集-联合(iou)的平均值定义的,而cIoU是由累积交集-联合定义的。由于cIoU对大面积物体的偏倚较大,且波动较大,所以首选gIoU。
实验结果
REASONING SEGMENTATION

只有真正理解了查询,模型才能很好地完成任务。现有的工作仅限于显式引用,没有适当的方法来理解隐式查询,而我们的模型利用多模态LLM来实现这一目标。
LISA-13B的性能大大优于7B,特别是在长查询场景下,这表明当前的性能瓶颈可能仍然在于理解查询文本,而更强大的多模态LLM可能会带来更好的结果
VANILLA REFERRING SEGMENTATION
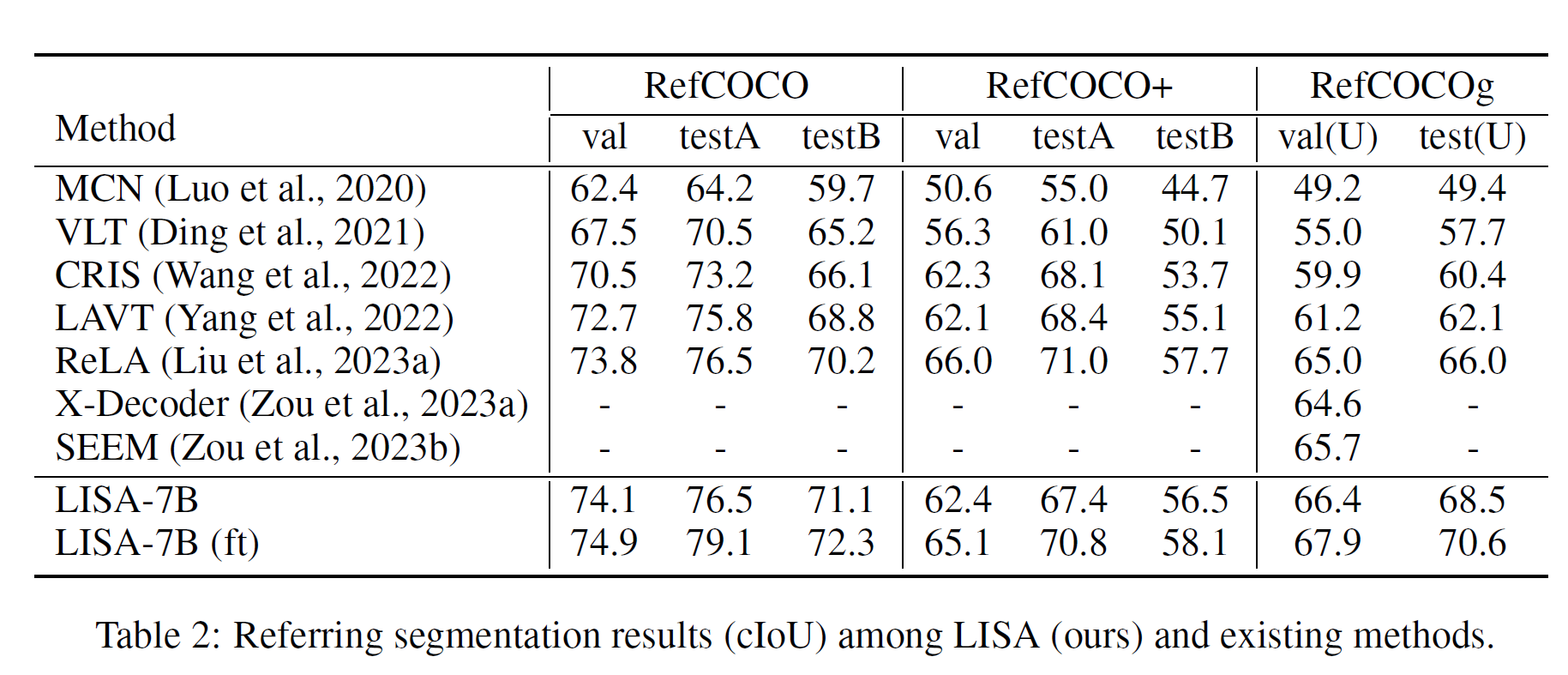
消融实验
除非另有说明,我们在验证集中报告LISA-7B的gIoU和cIoU指标。
视觉主干的设计选择

视觉骨干的设计选择是灵活的,不局限于SAM
SAM LoRA微调
我们注意到经过LoRA调优的SAM主干的性能不如冻结的主干。一个潜在的原因是微调削弱了原始SAM模型的泛化能力
SAM预训练权重
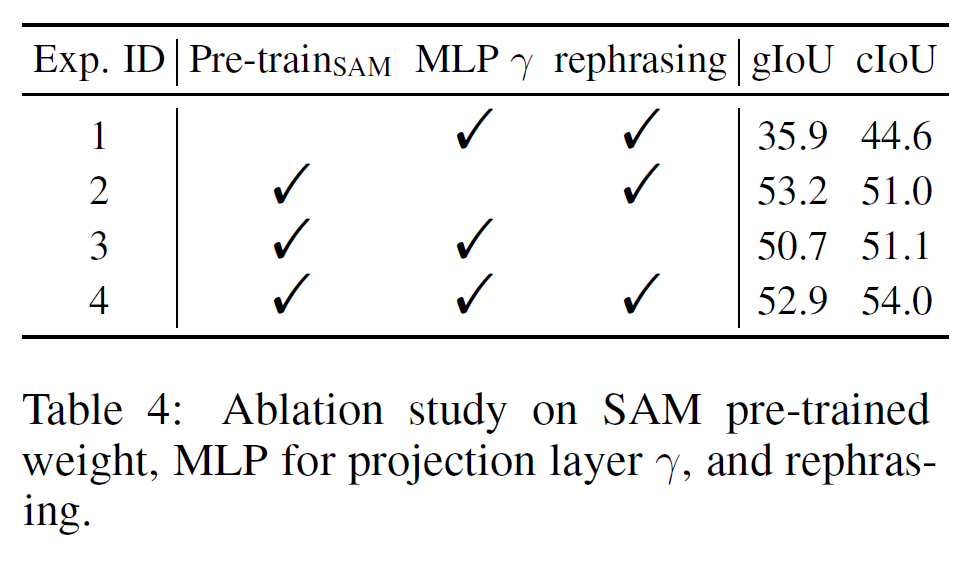
不带预训练权重性能大下降!
MLP vs.线性投影层
我们注意到使γ MLP在gIoU中的性能下降很小,但在cIoU中的性能相对较高↑
所有类型训练数据的贡献
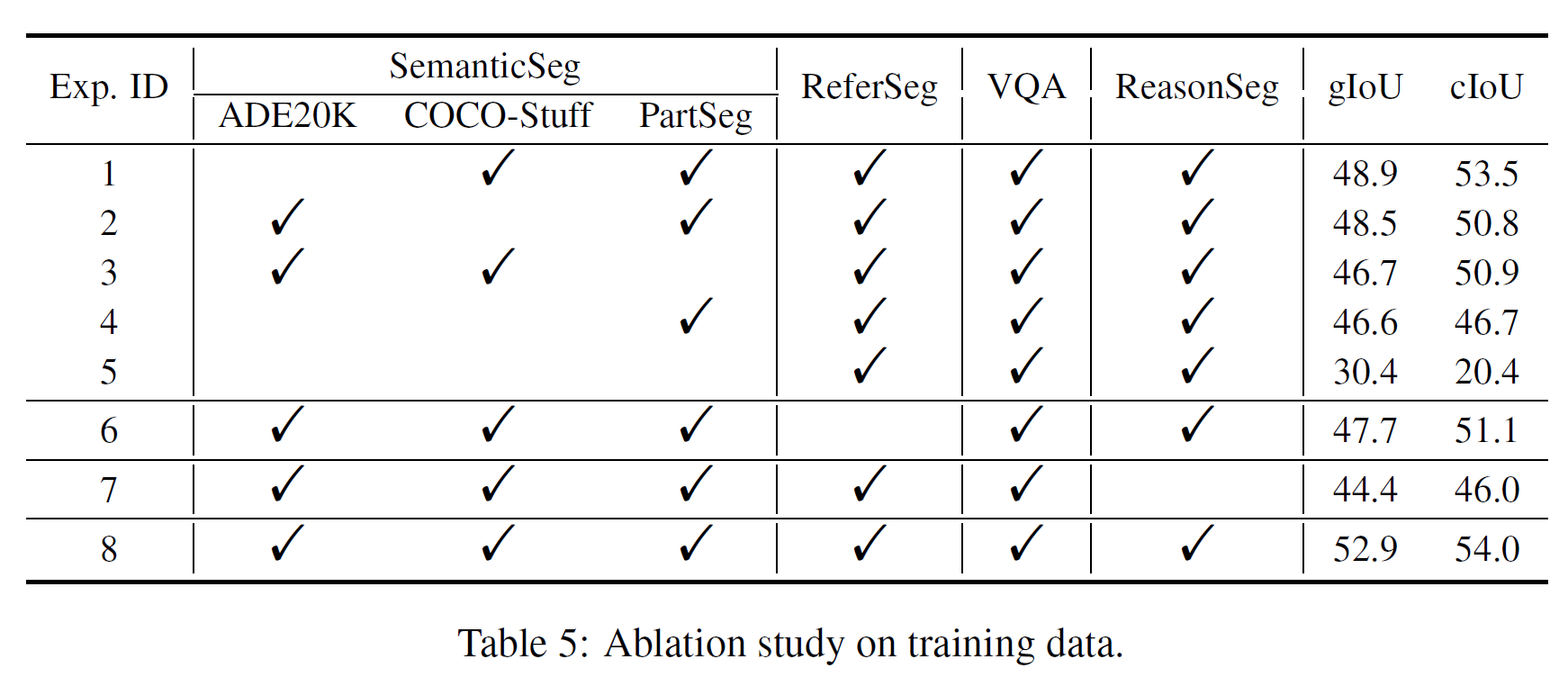
值得注意的是,在Exp. 4中,我们没有使用任何语义分割数据集,性能下降了很多。我们推测语义分割数据集为训练提供了大量的基真二值掩码,因为一个多类标签可以产生多个二值掩码。这表明语义分割数据集在训练中是至关重要的
GPT-3.5指令复述
在对推理分割图像指令对进行微调的过程中,我们使用GPT-3.5对文本指令进行改写,并随机选择一条。表4中实验3和实验4的对比表明,性能分别提高了2.2%和2.9% cIoU。该结果验证了该数据增强方法的有效性。
附录-一些实验结果


相关文章:
LISA:通过大语言模型进行推理分割
论文:https://arxiv.org/pdf/2308.00692 代码:GitHub - dvlab-research/LISA 摘要 尽管感知系统近年来取得了显著的进步,但在执行视觉识别任务之前,它们仍然依赖于明确的人类指令来识别目标物体或类别。这样的系统缺乏主动推理…...

opencv基础40-礼帽运算(原始图像减去其开运算)cv2.MORPH_TOPHAT
礼帽运算是用原始图像减去其开运算图像的操作。礼帽运算能够获取图像的噪声信息,或者得到比原始图像的边缘更亮的边缘信息。 例如,图 8-22 是一个礼帽运算示例,其中: 左图是原始图像。中间的图是开运算图像。右图是原始图像减开运…...
函数)
php中的array_filter()函数
php中的array_filter()函数用于筛选数组中的元素,并返回一个新的数组,新数组的元素是所有返回值为true的原数组元素。 array_filter()函数的使用语法如下: array_filter ( array $array [, callable $callback [, int $flag 0 ]] ) : array…...
ArcGIS Pro基础:【按顺序编号】工具实现属性字段的编号自动赋值
本次介绍一个字段的自动排序编号赋值工具,基于arcgis 的字段计算器工具也可以实现类似功能,但是需要自己写一段代码实现, 相对而言不是很方便。 如下所示,该工具就是【编辑】下的【属性】下的【按顺序编号】工具。 其操作方法是…...
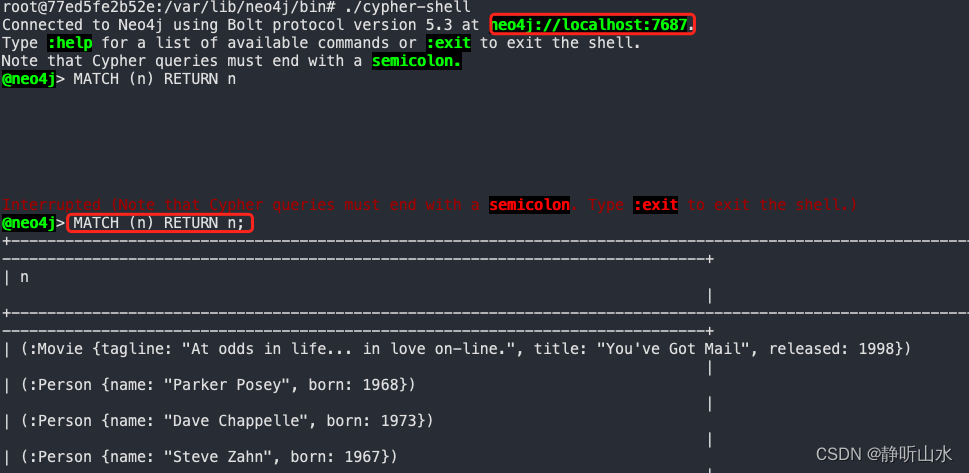
neo4j终端操作
1】进入容器 (base) xiaokkkxiaokkkdeMacBook-Pro ~ % docker exec -it 77ed5fe2b52e /bin/bash 2】启动、停止neo4j root77ed5fe2b52e:/var/lib/neo4j/bin# ./neo4j start Neo4j is already running (pid:7). Run with --verbose for a more detailed error message.root7…...

【深度学习】在 MNIST实现自动编码器实践教程
一、说明 自动编码器是一种无监督学习的神经网络模型,主要用于降维或特征提取。常见的自动编码器包括基本的单层自动编码器、深度自动编码器、卷积自动编码器和变分自动编码器等。 其中,基本的单层自动编码器由一个编码器和一个解码器组成,编…...
SpringBoot3基础用法
技术和工具「!喜新厌旧」 一、背景 最近在一个轻量级的服务中,尝试了最新的技术和工具选型; 即SpringBoot3,JDK17,IDEA2023,Navicat16,虽然新的技术和工具都更加强大和高效,但是适应采坑的过程…...

6、移除链表元素
方法1:原链表删除元素 伪代码: 首先判断头节点是否是待删除元素。(头节点和其他节点的删除方法不一样) while(head ! null && head->value target) //如果链表为 1 1 1 1 1,要删除元素1时用if就会失效 {h…...
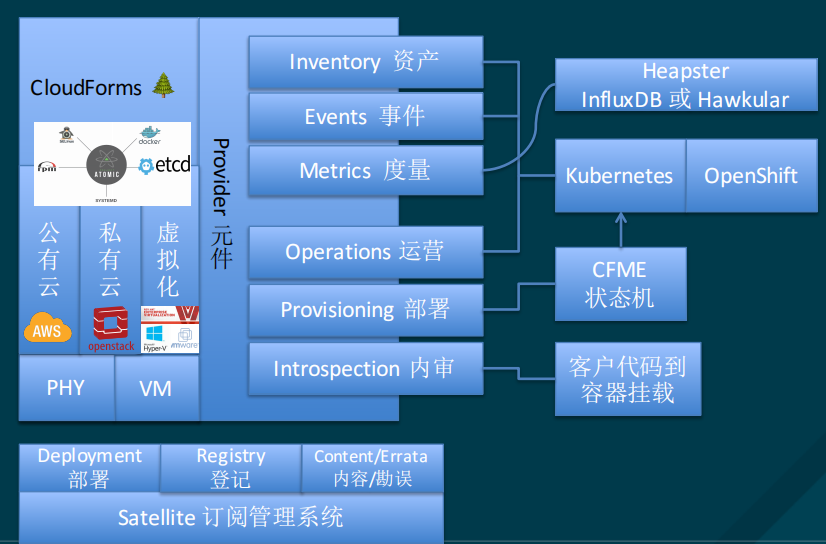
大厂容器云实践之路(一)
1-华为CCE容器云实践 华为企业云 | CCE容器引擎实践 ——从IaaS到PaaS到容器集群 容器部署时代的来临 IaaS服务如日中天 2014-2015年,大家都在安逸的使用IaaS服务; 亚马逊AWS的部署能力方面比所有竞争对手…...
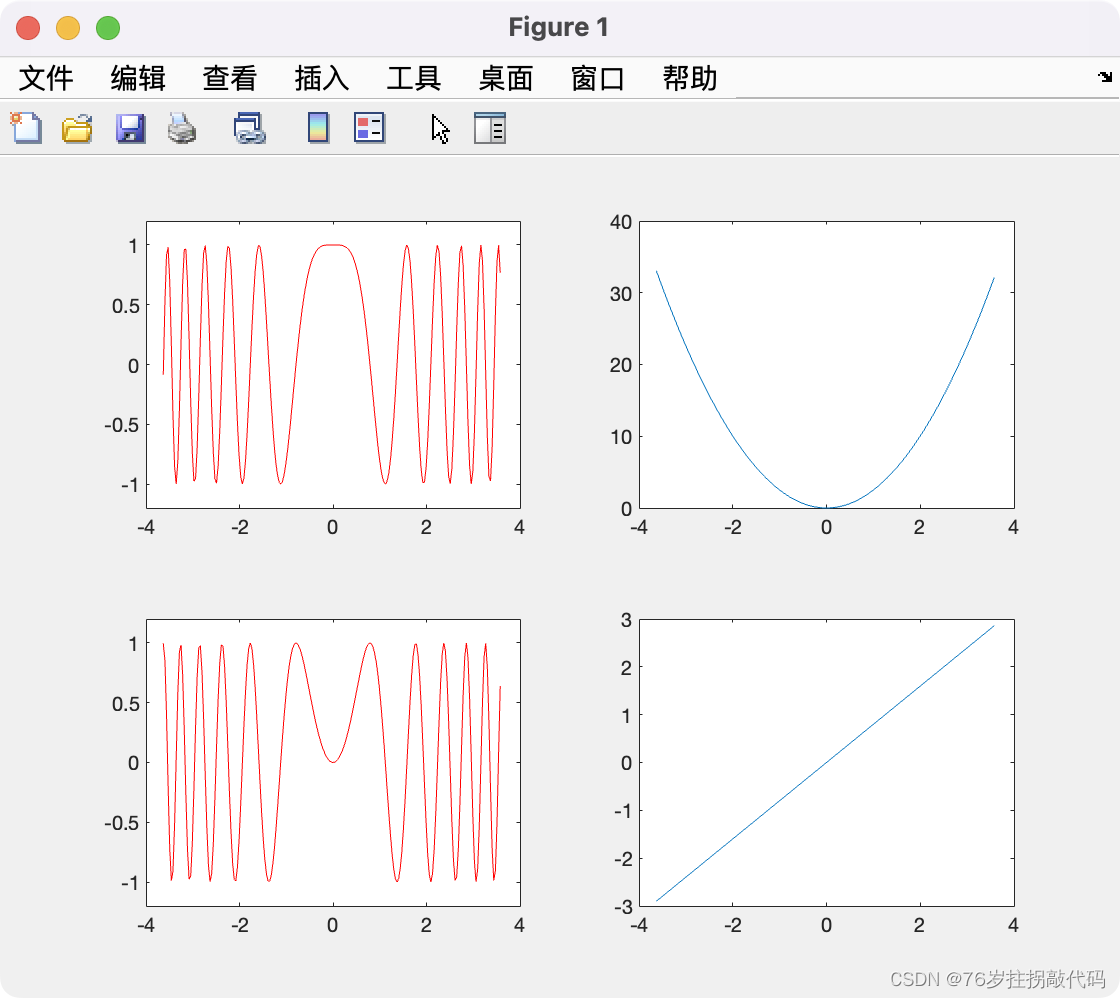
《合成孔径雷达成像算法与实现》Figure3.1
代码复现如下: clc close all clear all%参数设置 B 5.80e6; %信号带宽 T 7.26e-6; %脉冲持续时间 K B/T; %线性调频频率 alpha 5; %过采样率 F alpha*B; %采样频率 N F*T; %采样点数 dt T/N; …...
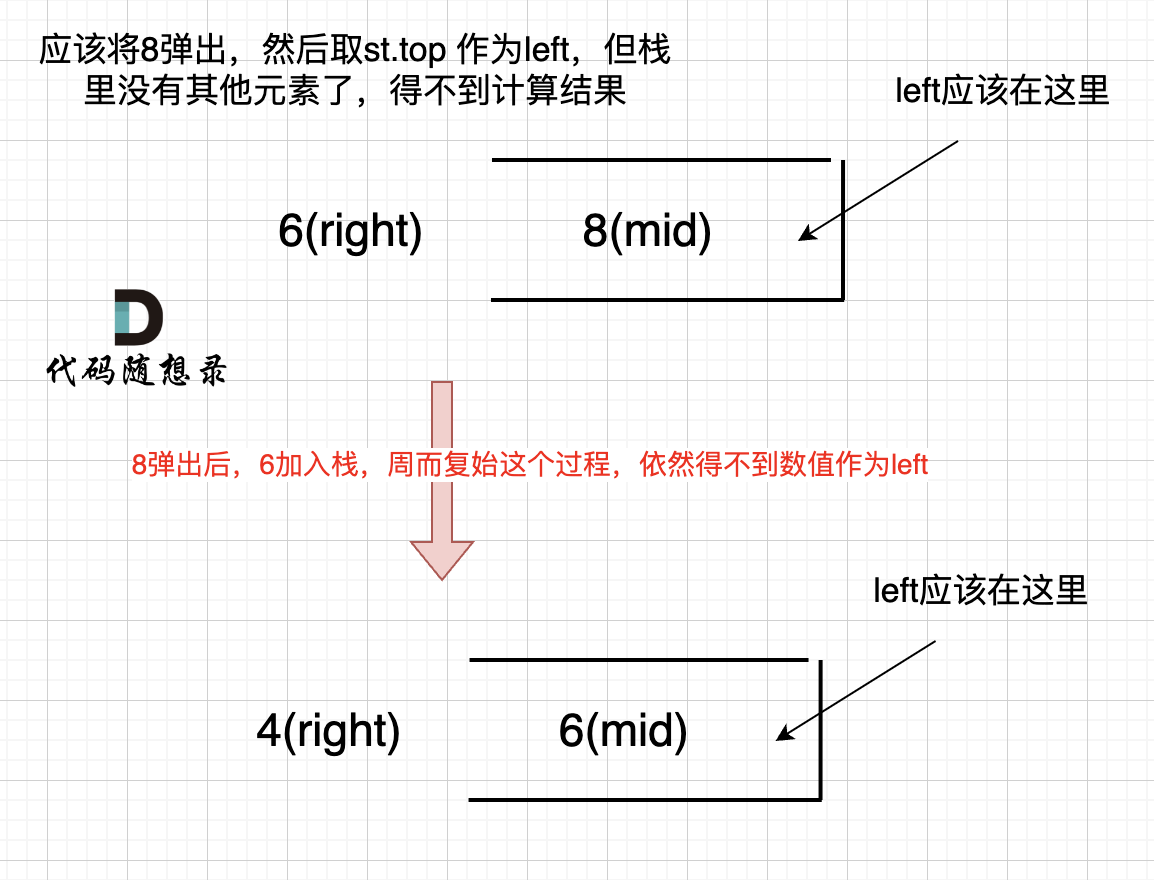
代码随想录算法训练营day60
文章目录 Day60 柱状图中最大的矩形题目思路代码 Day60 柱状图中最大的矩形 84. 柱状图中最大的矩形 - 力扣(LeetCode) 题目 给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。 求在该柱状图…...
Modbus TCP转Profibus DP网关modbus tcp报文解析
捷米JM-DPM-TCP网关。在Profibus总线侧作为主站,在以太网侧作为ModbusTcp服务器功能, 下面是介绍捷米JM-DPM-TCP主站网关组态工具的配置方法 2, Profibus主站组态工具安装 执行资料光盘中的安装文件setup64.exe或setup.exe安装组态工具。安装过程中一直…...

对 Promise 的理解
Promise 是异步编程的一种解决方案,它是一个对象,可以获取异步 操作的消息,他的出现大大改善了异步编程的困境,避免了地狱回调, 它比传统的解决方案回调函数和事件更合理和更强大。 所谓 Promise,简单说就…...

Vuex:Vue.js应用程序的状态管理模式
介绍 在Vue.js应用程序中,随着项目复杂度的增加,组件之间的数据共享和管理变得困难。为了解决这个问题,Vue.js提供了一个名为Vuex的状态管理模式。Vuex可以帮助我们更有效地组织、管理和共享应用程序的状态。 什么是Vuex? Vuex…...
Unity之ShaderGraph 节点介绍 Utility节点
Utility 逻辑All(所有分量都不为零,返回 true)Any(任何分量不为零,返回 true)And(A 和 B 均为 true)Branch(动态分支)Comparison(两个输入值 A 和…...
springboot()—— swagger
零、一张图读懂swagger 懂了,这玩意就是用swagger搞出来的! 就是一个后端开发自测的东西嘛! 一、概念 存在即合理,我们看一下swagger诞生的原因:在前后端分离的架构中,前端新增一个字段,后端就…...
Java课题笔记~ 关联映射
一、MyBatis关联查询 在关系型数据库中,表与表之间存在着3种关联映射关系,分别为一对一、一对多、多对多。 一对一:一个数据表中的一条记录最多可以与另一个数据表中的一条记录相关。列如学生与学号就属于一对一关系。 一对多:主…...

一零六七、JVM梳理
JVM? Java虚拟机,可以理解为Java程序的运行环境,可以执行Java字节码(Java bytecode)并提供了内存管理、垃圾回收、线程管理等功能 java内存区域划分?每块内存中都对应什么? 方法区:类的结构信息、常量池、…...

【CSS】网格布局(简单布局、网格合并、网格嵌套)
文章目录 CSS网格布局(Grid Layout)1. 简单布局2. 网格合并3. 网格嵌套4. 总结 CSS网格布局(Grid Layout) CSS网格布局(Grid Layout)是一种强大且灵活的CSS布局系统,允许开发者以网格形式组织和…...
06 Ubuntu22.04上的miniconda3安装、深度学习常用环境配置
下载脚本 我依然是在清华镜像当中寻找的脚本。这里找脚本真的十分方便,我十分推荐。 wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh 下载十分快速,10秒解决问题 运行miniconda3安装脚本 赋予执…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...