半监督学习(主要伪标签方法)
半监督学习
1. 引言
- 应用场景:存在少量的有标签样本和大量的无标签样本的场景。在此应用场景下,通常标注数据是匮乏的,成本高的,难以获取的,与之相对应的是却存在大量的无标注数据。
- 半监督学习的假设:决策边界应避开较高密度的区域。
- 利用未有标记的样本来训练一个比仅使用有标记的样本可以获得的性能更好的模型
1.1 半监督学习方法
半监督学习方法的分类:
- 一致性规范化/一致性训练:对未标注数据进行扰动,两者的预测不存在显著的差异。模型则对原数据和扰动数据进行一致性训练。(有点像对比学习)
- 基于代理标签的方法:这种方法利用标记集上的训练模型,通过基于一些启发式方法标记未标记集的实例来产生额外的训练样本。这些方法也可以被称为自举[14]算法。这些方法中包含了自我训练、协同训练和多视角学习。
- 生成式模型:类似于监督设置,在一个任务上学习到的特征可以转移到其他下游任务上。生成模型需要从原数据分布中学习可迁移特征,用于监督任务。(有点像上游代理任务,下游监督微调)
- 基于图的方法:标注数据和非标注数据点可以认为是图的节点,通过计算标注节点 x i \ x_i xi和非标注节点 x j \ x_j xj之间的相似性,来传递标记数据的标签到未标记数据。相当于通过样本之间的相似性,来为未标注数据赋标签。
1.2 主要半监督学习假设
- 平滑假设:如果两个数据输入在原高维空间是相似的,那么经过模型后的输出也应该相似。
- 聚类假设:如果点都在一个簇中,则他们应属于同一类。
- 流形假设:(高维)数据(大致)位于一个低维流形上。
1.3 相关问题
- 主动学习:在主动学习[140,63]中,该学习算法提供了大量的未标记数据点,能够以交互式的方式请求从未标记的集合中标记任何给定的示例。
- 迁移学习和领域适配:迁移学习[116,162]是用来改进一个领域上的学习器,称为目标领域,通过转移从相关领域学习到的知识,称为源领域。
- 弱监督学习:为了克服对大型手工标记和昂贵的训练集的需求,大多数规模可观的深度学习系统都使用了某种形式的弱监督:通过使用廉价的注释器[126]等策略构建的质量较低、但规模较大的训练集。在弱监督学习中,目标与在监督学习中相同,然而,提供的不是一个地面真相标记的训练集,而是一个或多个弱注释的训练集,这可能来自人群工作人员,是启发式规则的输出,远程监督[106]的结果,或其他分类器的输出(伪标签)。例如,在弱监督语义分割中,像素级标签的获取难度更大,成本也更高,于是使用其他不精确的注释,例如,图像标签[159,184,161,97,94]、点[9]、涂鸦[100]和边界框[144,31]。在这种情况下,可以使用SSL方法来提高性能,此外,如果有有限数量的强标记的样本可用,同时仍然利用弱标记的样本。
- 有噪声标签学习:由于标签噪声会对深度学习方法的性能产生负面影响,因此如果噪声显著,那么从噪声标签中学习[46,52]可能具有挑战性。
1.4 评估半监督学习的方式
用给定的SSL方法训练一个深度学习模型,性能测试结果在原始带标签的测试集上。这为对比和消融实验的设计起指导作用,若要评估或者比较SSL的在真实数据中的性能,需注意以下几点。
- 共享实现:若要比较不同SSL策略的性能,则应该保证内部深度学习模型和超参应该一致。
- 高质量的监督基线:应该与使用有标签的监督训练结果进行比较,类似于在保证其他情况不变的情况下,一个是用了SSL策略,一个是只用监督学习,两者进行性能比较。
- 与迁移学习进行比较:另一个比较SSL方法的可靠基线,则是可以通过在大型标记数据集上训练模型来获得,然后在小的有标签数据集上微调。(一个数据集到另一个数据集)。
- 考虑到类分布不匹配:有标签样本和无标签样本之间可能存在标签类别分布不匹配的情况。同样,这种不匹配在现实应用中仍然普遍存在,在现实应用中,未标记数据与标记数据可能有不同的类分布。为了更好地采用SSL,需要解决这种差异的影响。
- 改变已标记数据和未标记数据的数量:这对消融实验有指导意义,通过改变有标记样本的数量和无标记样本的数量,进而研究模型所表现的性能变化。
- 实际中较小的验证集:在研究SSL的大多数情况下其实都是用的大型有标签的公开数据集,这种数据集的验证集样本数量都会明显的大于SSL中所谓的标记样本集 D l \ D_l Dl,也就是说验证集会大大多于训练集,在这种设置下,广泛的超参数调优可能会导致对验证集的过拟合。相比之下,小的验证集限制了选择模型[20,45]的能力,从而导致对SSL方法的性能进行了更现实的评估。——即降低验证集的样本量,评估模型的性能。
2. 一致性正则化(Consistency Regularization)
目前许多研究的假设都是利用聚类假设而进行训练的,这些方法都基于一个概念,即如果给一个无标签样本增加扰动,那么扰动数据的预测和原数据的预测不会有明显的改变,在聚类假设下,具有不同真实标签的数据点应当在低密度区域分隔开,因此,某样本在扰动后的预测结果发生类别变化的可能性也该很小。
更正式地说,通过一致性正则化,我们倾向于对相似数据点给出一致预测的函数 f θ \ f_{\theta} fθ。因此,与其最小化在输入空间的零维数据点上的分类成本,正则化的模型使每个数据点周围的流形上的成本最小化,使决策边界远离未标记的数据点,并平滑数据所在的流形[193]。这意思就说扰动数据和原数据认为是“相似数据”。
对于无标签数据 D u \ D_u Du,一致性正则化的目的是最小化原数据和扰动数据输出之间的距离,距离衡量指标有MSE,KL散度,JS散度。

3. 熵最小化(Entropy Minimization)
在上一节中,在保持集群假设的设置中,我们强制执行预测的一致性,以将决策边界推到低密度区域,来避免对来自具有不同类的同一聚类的样本进行分类,这违反了聚类的假设。另一种执行这一点的方法是使网络做出置信度(低熵)预测,对于未标记的数据,而不管预测的类如何,阻止决策边界通过数据点附近,否则它将被迫产生低置信度的预测。这是通过添加一个损失项来实现的,以最小化预测函数 f θ ( x ) \ f_{\theta}(x) fθ(x)的熵。
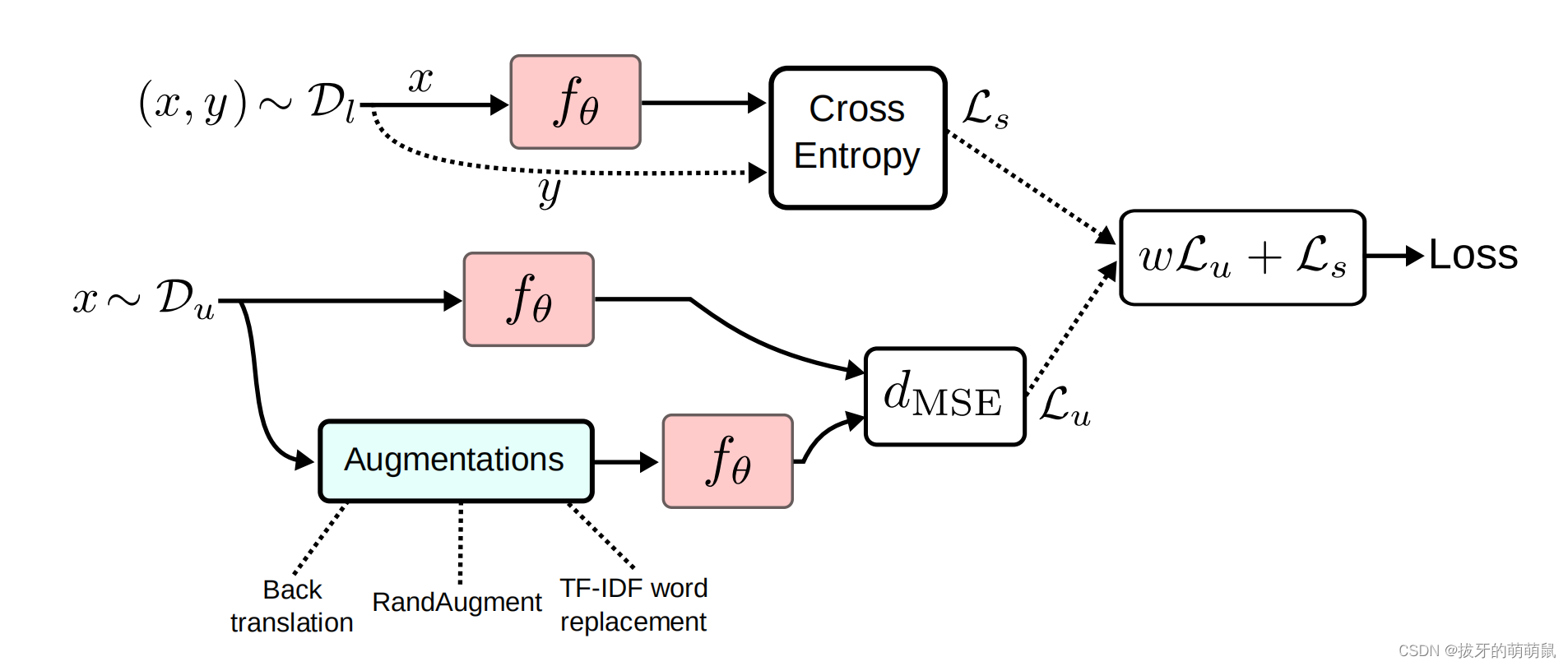
在我看来就是在训练的时候同时输入有标签数据和无标签数据对模型进行训练,两部分损失,一部分就是常规的交叉熵损失,一部分还是一致性准则,扰动样本和原样本的输出距离应该近。
4. 代理标签方法
代理标签方法是一类SSL算法,它在未标记的数据上生成代理标签,使用预测函数本身或它的某些变体,而不需要任何监督。这些代理标签与标记数据一起用作目标,提供一些额外的训练信息,即使产生的标签往往是嘈杂的或弱的,并不能反映地面的真相。
这些方法主要可以分为2类(这似乎就是伪标签的思路):
- 自训练,即模型本身产生代理标签,
- 以及多视图学习,其中代理标签是由根据不同的数据视图进行训练的模型产生的。
4.1 自训练(Self-training)
在自训练中,1)少量的标签数据 D l \ D_l Dl先被用来训练模型,再用这个训练好的模型来给未标注数据 D u \ D_u Du指派伪标签。因此,给定一个未标注数据 x \ x x,用此模型先预测其在各类上的概率分布,然后再成对添加数据和伪标签 ( x , arg max f θ ( x ) ) \ (x,\arg\max{f_\theta(x)}) (x,argmaxfθ(x))到训练集中,这里有个前提就是最大概率值应该大于某个阈值 τ \ \tau τ。
第二阶段是使用未标注数据集 D u \ D_u Du的增强数据训练模型,并且利用这个模型又反过来标注未标注数据集 D u \ D_u Du,这个过程需要不断的重复直至模型无法再标注出高置信度的样本。
其他的启发式方法可以用来决定保留哪些代理标签的样本,例如2)使用相对置信度而不是绝对置信度,其中,在一个epoch中具有最高置信度的样本要进行排序,选出其中前n个具有伪标签的样本到训练集 D l \ D_l Dl中。自训练(Self-training)与熵最小化(Entropy Minimization)相似。在这两种情况下,网络都训练输出高置信度的预测。
这种方法的主要缺点是模型无法纠正自己的错误,任何偏差和错误的分类都可以迅速放大,从而导致在未标记的数据点上产生置信度高但错误的代理标签。(这个确实存在,我在实验中似乎产生了大量的错误伪标签)
案例1:
Billion-scale semi-supervised learning for image classifification
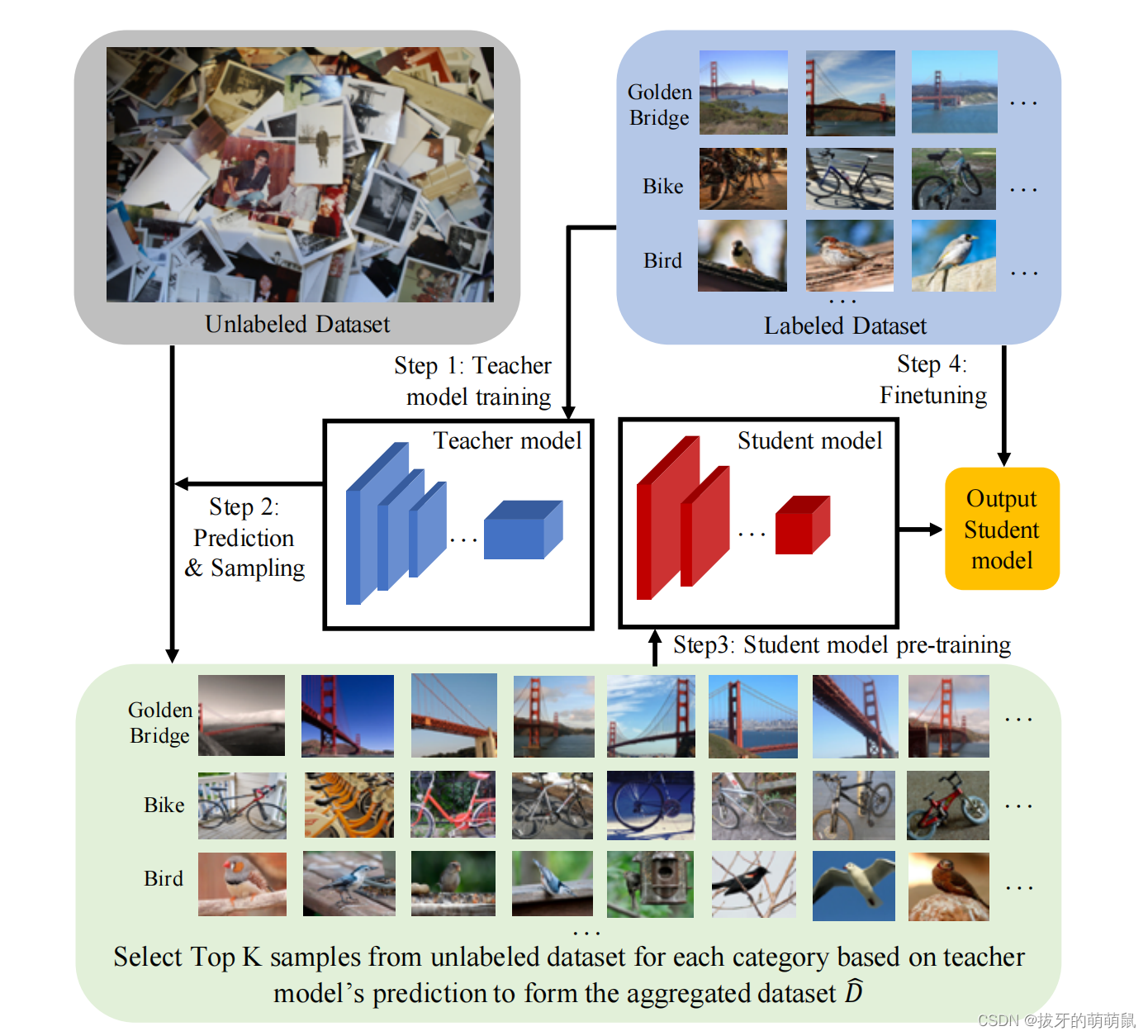
- 在少量标记数据集上训练一个teacher model
- teacher model在无标记数据集上进行预测,对softmax后最大概率进行排序,找出top-k的样本出来制作伪标签
- 用这个伪标签数据集训练student model
- 最后用最初的少量标记数据对student model进行微调。
案例2
Self-training with Noisy Student improves ImageNet classifification
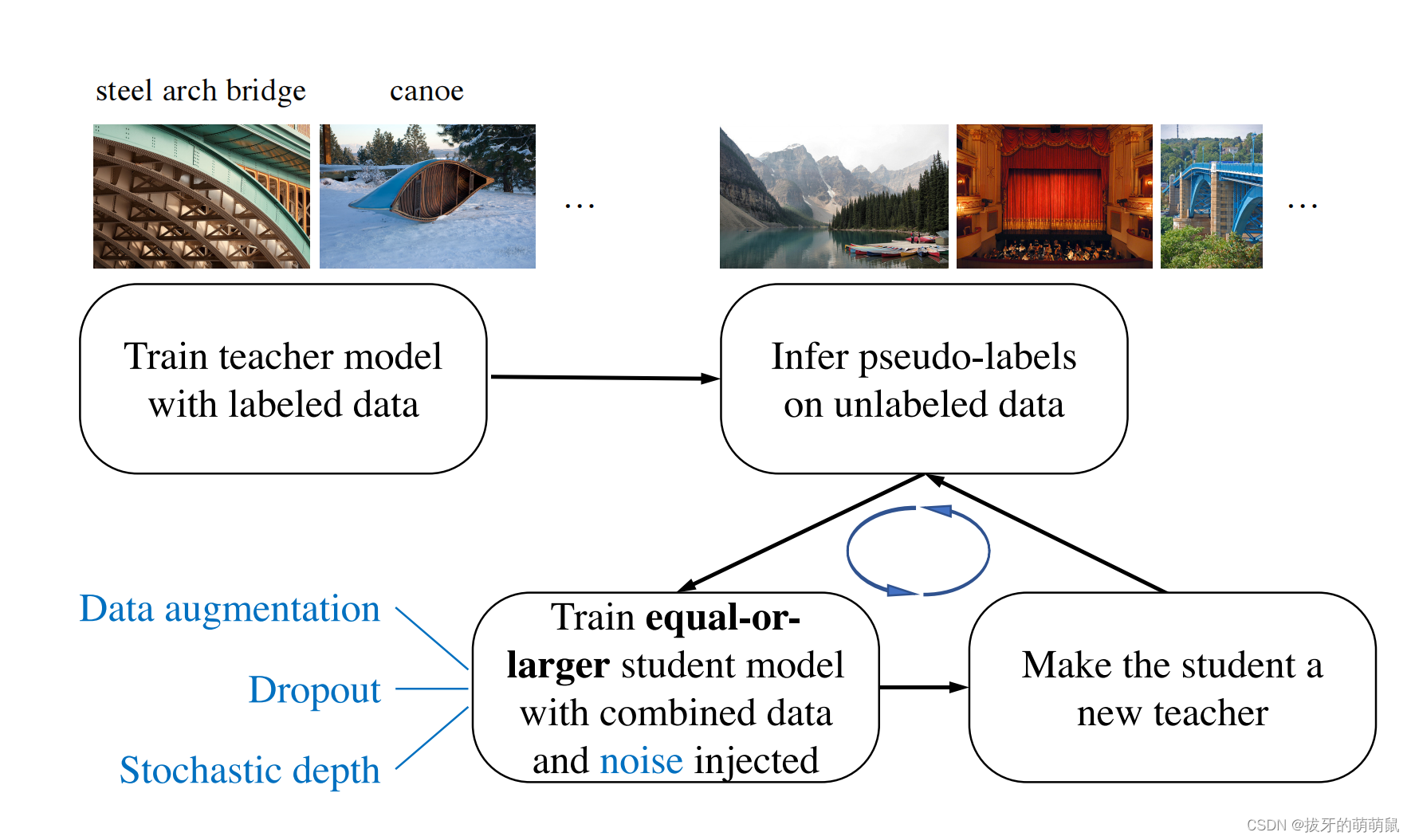
- teacher和student的角色是迭代交互的
- 第一步先用有标记的训练集训练一个teacher网络
- 用teacher网络的预测造伪标签数据
- 将伪标签数据和原先有标签数据集合并
- 此时对数据注入噪声(Dropout,数据增强,Stochastic depth),同时换更大的模型(可选),然后训练出一个student网络
- 用此student网络又来预测一波,然后生成伪标签,此时student的角色就变成了teacher。
- 重复3-6.
先举着两个例子,知道自训练是什么东西就行,其他的改进方法就需要继续阅读文献找。
4.2 多视图训练(Multi-view training)
多视图训练在实际应用中是很常见的,视图可以是来自原数据的不同观测手段比如:图像的颜色信息,纹理信息。多视图训练之目的在于学习一个不同的预测函数,这个预测函数是对原数据的 x \ x x的某个视图 v i ( x ) \ v_i(x) vi(x)进行建模(相当于说一个视图一个函数,多个视图就有多个预测函数需要训练)。然后对所有的预测函数进行联合优化,最终增强模型的泛化能力。理想情况下,各视图相互补充,以便生成的模型可以协作以提高彼此的性能。
协同训练
协同训练要求原数据点 x \ x x可以用两种条件独立的视图进行表示,并且两个视图各自可以充分地用于训练一个好的模型。在标记数据集 D l \ D_l Dl的特定视图上进行训练得到两个预测函数 f θ 1 f_{\theta_1} fθ1和 f θ 2 \ f_{\theta_2} fθ2后,开始标注代理标签的进程。在每次迭代中,若 f θ j \ f_{\theta_j} fθj对某未标注数据的预测输出所对应的概率值高于了某阈值 τ \ \tau τ,那么这个未标注数据则被加入到 f θ i \ f_{\theta_i} fθi的的训练集中。所以说,其中一个模型是拿来提供标注的,另外一个是用这个伪标签数据监督训练的。
像这种训练策略一般是用在多模态数据上,比如RGB-D数据,还有图像-文本数据,他们各自就是不同的视图,所以可以使用协同训练的策略。
但是实际上图像分类这些任务只有一种数据视图,所以在实践当中是用两种不同的分类器或者不同的参数配置。两个视图 v 1 ( x ) v_1(x) v1(x)和 v 2 ( x ) \ v_2(x) v2(x)可以通过注入噪声和应用不同的数据增强来生成。如对抗性扰动生成不同的视图:Deep co-training for semi-supervised image recognition.
三级训练 (Tri-Training)
我觉得这部分叫“三个训练”比较合适,这个训练策略的思路是应用三个不同的模型,这三个模型首先都要在有标记训练集 D l \ D_l Dl上训练。然后再用这三个模型对未标记数据集进行预测。生成伪标签的策略是:如果预测结果中有两个保持一致,那么这个数据就加入到剩下那个模型的训练集中。如果没有任何数据点被添加到任何模型的训练集上,那么训练就会停止。所以这看起来是造了三个数据集。这个方法的缺陷是计算占用的资源会特别大。
多视图训练就差不多了解到这里。总结来看,要么就是数据增强或者噪声形成多组增强数据,用阈值造伪标签,要么就是多整几个模型平行训练造伪标签。
5. 统一型方法( Holistic Methods)
目前出现的工作多为统一型方法,其目的在于将当前主要的SSL方法(前面那些思路)统一到一个框架中去,以实现更好的性能。 以下是Match系列:MixMatch, ReMixMatch, FixMatch.
MixMatch
-
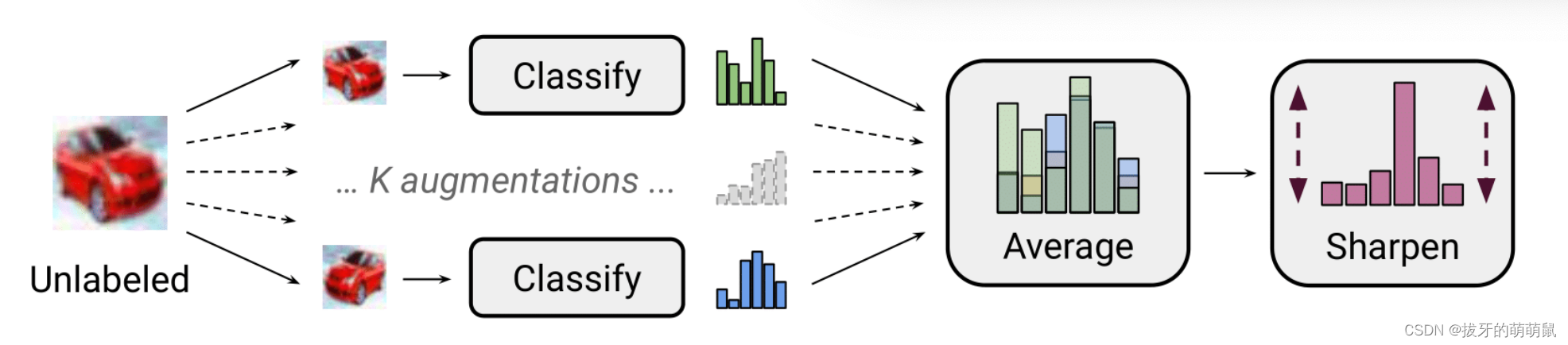
数据增强:对一个batch内有标签数据进行增强,对无标签数据进行 K \ K K次叠加增强,生成 K \ K K个无标签数据的增强样本序列。
-
标签猜测:给无标签数据造伪标签。还是用在有标签数据集上训练的网络进行预测,只不过这里的预测是对 K \ K K个无标签数据增强的样本序列进行 K \ K K次预测。这 K \ K K个预测肯定都是一个关于各个类别概率的矢量,然后再把这些取平均,得到一个平均类别概率矢量,通过这个平均预测得到伪标签(从后面的叙述来看,这里所谓的标签其实是一个概率分布),所以这个伪标签的值就是所有 K \ K K个增强样本的伪标签。
-
锐化(Sharpening):为了让模型可产生更高置信度的预测并且最小化输出分布的熵,第二步产生的代理标签(在C个类上的概率分布),需要用类别分布的temperature进行锐化调整。
( y ^ ) k = ( y ^ ) k 1 T ∑ k = 1 C ( y ^ ) k 1 T (\hat{y})_k=\frac{(\hat{y})_k^{\frac{1}{T}}}{\sum_{k=1}^{C}(\hat{y})_k^{\frac{1}{T}}} (y^)k=∑k=1C(y^)kT1(y^)kT1
这里面的 k \ k k是对应类别概率的下标,锐化操作都是用在未标记数据集中。这个 T \ T T是放在了每个概率的右上角的,所以这是一个非线性变换,相当于自变量是 1 / T \ 1/T 1/T的对数函数了。
-
MixUp:上述的操作最终会形成两个新的增强batch。其中一个batch是有标签样本的增强 L \ L L,另外一个batch是无标签样本及其锐化后的概率分布标签 U \ U U。需要注意的是无标签batch里面的样本是有 K \ K K个增强样本的,所以是原本体量的 K \ K K倍,并且无标签样本集也用这些增强样本替换掉了。最后一步是,混合这两个batch的中的样本,形成一个新的batch W = S h u f f l e ( C o n c a t ( L , U ) ) \ W=Shuffle(Concat(L,U)) W=Shuffle(Concat(L,U))。可以看到还用上了随机shuffle。在这之后还要再切成两截,第一截 W 1 \ W_1 W1和 L \ L L一样长,第二截 W 2 \ W_2 W2和 U \ U U一样长。
然后再使用mixup函数,这是一种数据增强的手段,一开始我还以为我看错了这两个公式,查了原文确实是这样mixup的,当然,数据和标签是同步mixup的,可以查mixup的原文。
L ′ = M i x U p ( L , W 1 ) L'=MixUp(L,W_1) L′=MixUp(L,W1)U ′ = M i x U p ( U , W 2 ) U'=MixUp(U,W_2) U′=MixUp(U,W2)
构建好了连个数据集后,对于 L ′ \ L' L′数据集,使用CE损失进行监督训练损失,对于 U ′ \ U' U′数据集则使用一致性损失(MSE)。因而损失占两部分:
l o s s = l o s s s + w ⋅ l o s s u loss=loss_s+w\cdot loss_u loss=losss+w⋅lossu
(生成式模型略)
相关文章:
半监督学习(主要伪标签方法)
半监督学习 1. 引言 应用场景:存在少量的有标签样本和大量的无标签样本的场景。在此应用场景下,通常标注数据是匮乏的,成本高的,难以获取的,与之相对应的是却存在大量的无标注数据。半监督学习的假设:决策…...
)
datePicker一个或多个日期组件,如何快捷选择多个日期(时间段)
elementUI的组件文档中没有详细说明type"dates"如何快捷选择一个时间段的日期,我们可以通过picker-options参数来设置快捷选择: <div class"block"><span class"demonstration">多个日期</span><el…...

【语音合成】微软 edge-tts
目录 1. edge-tts 介绍 2. 代码示例 1. edge-tts 介绍 https://github.com/rany2/edge-tts 在Python代码中使用Microsoft Edge的在线文本到语音服务 2. 代码示例 import asyncio # pip install edge_tts import edge_tts TEXT """给我放首我喜欢听的歌曲…...

elevation mapping学习笔记3之使用D435i相机离线或在线订阅点云和tf关系生成高程图
文章目录 0 引言1 数据1.1 D435i相机配置1.2 协方差位姿1.3 tf 关系2 离线demo2.1 yaml配置文件2.2 launch启动文件2.3 数据录制2.4 离线加载点云生成高程图3 在线demo3.1 launch启动文件3.2 CMakeLists.txt3.3 在线加载点云生成高程图0 引言 elevation mapping学习笔记1已经成…...
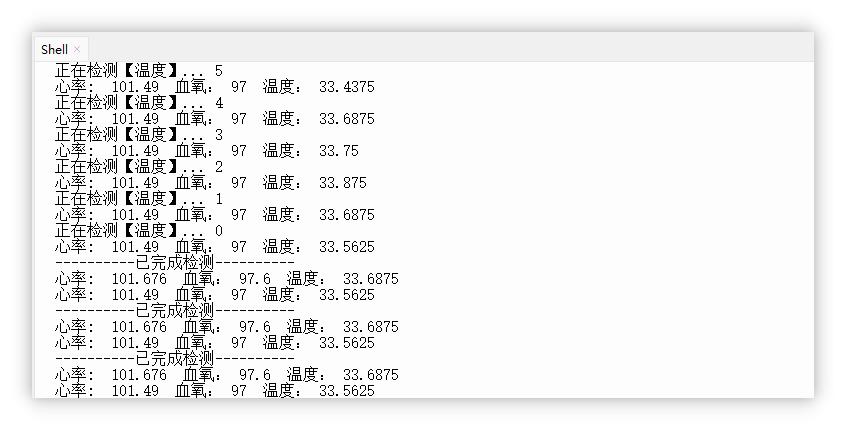
ESP32 Max30102 (3)修复心率误差
1. 运行效果 2. 新建修复心率误差.py 代码如下: from machine import sleep, SoftI2C, Pin, Timer from utime import ticks_diff, ticks_us from max30102 import MAX30102, MAX30105_PULSE_AMP_MEDIUM from hrcalc import calc_hr_and_spo2BEATS = 0 # 存储心率 FINGER_F…...

16-4_Qt 5.9 C++开发指南_Qt 应用程序的发布
文章目录 1. 应用程序发布方式2. Windows 平台上的应用程序发布 1. 应用程序发布方式 用 Qt 开发一个应用程序后,将应用程序提供给用户在其他计算机上使用就是应用程序的发布。应用程序发布一般会提供一个安装程序,将应用程序的可执行文件及需要的运行库…...

oracle容灾备份怎么样Oracle容灾备份
随着科学技术的发展和业务的增长,数据安全问题越来越突出。为了保证数据的完整性、易用性和保密性,公司需要采取一系列措施来防止内容丢失的风险。 Oracle是一个关系数据库管理系统(RDBMS),OracleCorporation是由美国软件公司开发和维护的。该系统功能…...

AcWing 4957:飞机降落
【题目来源】https://www.acwing.com/problem/content/4960/【题目描述】 有 N 架飞机准备降落到某个只有一条跑道的机场。 其中第 i 架飞机在 Ti 时刻到达机场上空,到达时它的剩余油料还可以继续盘旋 Di 个单位时间,即它最早可以于 Ti 时刻开始降落&…...

强化学习研究 PG
由于一些原因, 需要学习一下强化学习。用这篇博客来学习吧, 用的资料是李宏毅老师的强化学习课程。 深度强化学习(DRL)-李宏毅1-8课(全)_哔哩哔哩_bilibili 这篇文章的目的是看懂公式, 毕竟这是我的弱中弱。 强化…...

uniapp微信小程序 401时重复弹出登录弹框问题
APP.vue 登陆成功后,保存登陆信息 if (res.code 200) {uni.setStorageSync(loginResult, res)uni.setStorageSync(token, res.token);uni.setStorageSync(login,false);uni.navigateTo({url: "/pages/learning/learning"}) }退出登录 toLogout: func…...
Cloud Studio实战——热门视频Top100爬虫应用开发
最近Cloud Studio非常火,我也去试了一下,感觉真的非常方便!我就以Python爬取B站各区排名前一百的视频,并作可视化来给大家分享一下Cloud Studio!应用链接:Cloud Studio实战——B站热门视频Top100爬虫应用开…...

php 去除二维数组重复
在 PHP 中,我们常常需要对数组进行处理和操作。有时候,我们需要去除数组中的重复元素,这里介绍一种针对二维数组的去重方法。 以下是列举一些常见的方法: 方法一:使用 array_map 和 serialize 函数 array_map 函数可以…...
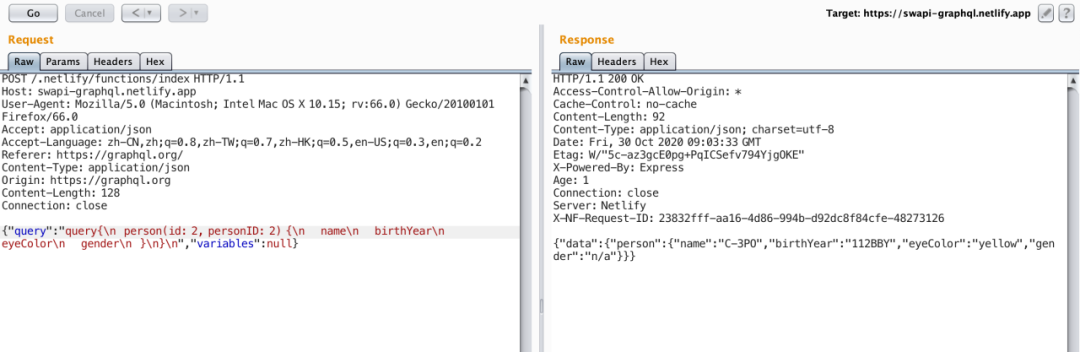
玩转graphQL
转载至酒仙桥的玩转graphQL - SecPulse.COM | 安全脉搏 前言 在测试中我发现了很多网站开始使用GraphQL技术,并且在测试中发现了其使用过程中存在的问题,那么,到底GraphQL是什么呢?了解了GraphQL后能帮助我们在渗透测试中发现哪些…...
.__init__()的含义)
神经网络super(XXX, self).__init__()的含义
学习龙良曲老师的课程,在77节有这样一段代码 import torch from torch import nnclass Lenet5(nn.Module):def __init__(self):super(Lenet5,self).__init__()那么,super(XXX, self).init()的含义是什么? Python中的super(Net, self).init()…...
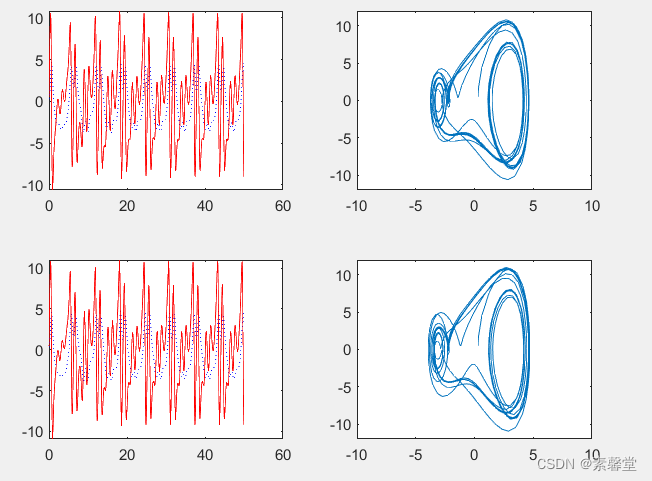
45.杜芬方程解仿真解曲线(matlab程序)
1.简述 Dufing方程是一种重要的动力系统山,是反映工程物理系统中非线性现象和混沌动力学行为的极其重要的方程式。通过Duffing方程可以探讨铁磁谐振电路中的分岔、拟周期运动、子谐波振荡。而在非线性与混沌系统的研究中,Duffing方程展示了丰富的混沌动力…...
服务器数据恢复-EXT3分区误删除邮件的数据恢复案例
服务器数据恢复环境: 一台服务器有一组由8块盘组建的RAID5阵列,EXT3文件系统。 服务器故障: 由于工作人员的误操作导致文件系统中的邮件丢失。用户需要恢复丢失的邮件数据。 服务器数据恢复过程: 1、将故障服务器中所有磁盘以只…...

C 语言的逗号运算符
逗号运算符 comma operator 逗号运算符最常用在 for 循环的循环头中. 程序示例: #include<stdio.h> #define FIRST_OZ 46 #define NEXT_OZ 20int main(void) {int ounces;float cost;printf("ounces cost\n");for (ounces 1, cost FIRST_OZ…...
无人车沿着指定线路自动驾驶与远程控制的实践应用
有了前面颜色识别跟踪的基础之后,我们就可以设定颜色路径,让无人车沿着指定线路做自动驾驶了,视频:PID控制无人车自动驾驶 有了前几章的知识铺垫,就比较简单了,也是属于颜色识别的一种应用,主要…...

C++ 多态性——纯虚函数与抽象类
抽象类是一种特殊的类,它为一个类族提供统一的操作界面。抽象类是为了抽象和设计的目的而建立的。可以说,建立抽象类,就是为了通过它多态地使用其中的成员函数。抽象类处于类层次的上层,一个抽象类自身无法实例化,也就…...

小程序如何使用防抖和节流?
防抖(Debounce)和节流(Throttle)都是用来优化函数执行频率的技术,特别在处理用户输入、滚动等频繁触发的情况下,它们可以有效减少函数的执行次数,从而提升性能和用户体验。但它们的工作方式和应…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...