pagehelper 优化自定义分页和排序位置
- pagehelper开源地址
- https://github.com/pagehelper/Mybatis-PageHelper
1.手写Count查询优化
源码分页count时首先是判断是否存在手写的 {业务查询id}_COUNT 的查询count统计
private Long count(Executor executor, MappedStatement ms, Object parameter,RowBounds rowBounds, ResultHandler resultHandler,BoundSql boundSql) throws SQLException {String countMsId = ms.getId() + countSuffix;Long count;//先判断是否存在手写的 count 查询MappedStatement countMs = ExecutorUtil.getExistedMappedStatement(ms.getConfiguration(), countMsId);if (countMs != null) {count = ExecutorUtil.executeManualCount(executor, countMs, parameter, boundSql, resultHandler);} else {if (msCountMap != null) {countMs = msCountMap.get(countMsId);}//自动创建if (countMs == null) {//根据当前的 ms 创建一个返回值为 Long 类型的 mscountMs = MSUtils.newCountMappedStatement(ms, countMsId);if (msCountMap != null) {msCountMap.put(countMsId, countMs);}}count = ExecutorUtil.executeAutoCount(this.dialect, executor, countMs, parameter, boundSql, rowBounds, resultHandler);}return count;}
手写count用法:
<select id="selectReportList" parameterType="xxxx" resultMap="xxx">****业务sql*****
</select >
<select id="selectReportList_COUNT" parameterType="xxxx" resultType="java.lang.Integer"> ****业务sql手写优化count*****
</select >
2.自定义分页排序位置
分页查询时复杂业务需要多表关联查询,关联表越多越影响查询效率;根据业务可将不影响查询结果的表分页后再查询需要自定义分页或排序位置
以mysql为例:
package com.github.pagehelper.dialect.helper;import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.regex.Pattern;import org.apache.ibatis.cache.CacheKey;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.mapping.ParameterMapping;
import org.apache.ibatis.reflection.MetaObject;
import org.apache.ibatis.session.RowBounds;import com.github.pagehelper.Page;
import com.github.pagehelper.dialect.AbstractHelperDialect;
import com.github.pagehelper.parser.OrderByParser;
import com.github.pagehelper.util.MetaObjectUtil;
import com.github.pagehelper.util.StringUtil;/*** 重写MySqlDialect满足自定义分页需求,* 类放在package 为 com.github.pagehelper.dialect.helper包覆盖源 码才生效*/
public class MySqlDialect extends AbstractHelperDialect {/*** 自定义分页key:*//*customizeLimit*/public static final String CUSTOMIZE_LIMIT="/\\*customizeLimit\\*/"; public static final Pattern customizeLimitFixed = Pattern.compile(CUSTOMIZE_LIMIT);/*** 自定义排序 key:*//*customizeOrderBy*/public static final String CUSTOMIZE_ORDERBY="/\\*customizeOrderBy\\*/"; public static final Pattern customizeOrderbyFixed = Pattern.compile(CUSTOMIZE_ORDERBY);@Overridepublic Object processPageParameter(MappedStatement ms, Map<String, Object> paramMap, Page page, BoundSql boundSql, CacheKey pageKey) {paramMap.put(PAGEPARAMETER_FIRST, page.getStartRow());paramMap.put(PAGEPARAMETER_SECOND, page.getPageSize());//处理pageKeypageKey.update(page.getStartRow());pageKey.update(page.getPageSize());//处理参数配置if (boundSql.getParameterMappings() != null) {List<ParameterMapping> newParameterMappings = new ArrayList<ParameterMapping>(boundSql.getParameterMappings());if (page.getStartRow() == 0) {newParameterMappings.add(new ParameterMapping.Builder(ms.getConfiguration(), PAGEPARAMETER_SECOND, int.class).build());} else {newParameterMappings.add(new ParameterMapping.Builder(ms.getConfiguration(), PAGEPARAMETER_FIRST, long.class).build());newParameterMappings.add(new ParameterMapping.Builder(ms.getConfiguration(), PAGEPARAMETER_SECOND, int.class).build());}MetaObject metaObject = MetaObjectUtil.forObject(boundSql);metaObject.setValue("parameterMappings", newParameterMappings);}return paramMap;}@Overridepublic String getPageSql(MappedStatement ms, BoundSql boundSql, Object parameterObject, RowBounds rowBounds, CacheKey pageKey) {String sql = boundSql.getSql();Page page = getLocalPage();//支持 order byString orderBy = page.getOrderBy();if (StringUtil.isNotEmpty(orderBy)) { pageKey.update(orderBy);if(customizeOrderbyFixed.matcher(sql).find()) {//自定义排序位置替换 sql = sql.replaceFirst(CUSTOMIZE_ORDERBY, " order by " + orderBy);}else {//源码逻辑sql = OrderByParser.converToOrderBySql(sql, orderBy);}}if (page.isOrderByOnly()) {return sql;}return getPageSql(sql, page, pageKey);}@Overridepublic String getPageSql(String sql, Page page, CacheKey pageKey) {if(customizeLimitFixed.matcher(sql).find()) {//自定义分页位置替换if (page.getStartRow() == 0) {sql = sql.replaceFirst(CUSTOMIZE_LIMIT, " LIMIT ? ");} else {sql = sql.replaceFirst(CUSTOMIZE_LIMIT, " LIMIT ?, ? ");}return sql;}else {//源码逻辑StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);sqlBuilder.append(sql);if (page.getStartRow() == 0) {sqlBuilder.append("\n LIMIT ? ");} else {sqlBuilder.append("\n LIMIT ?, ? ");}return sqlBuilder.toString();}}}用法示例
<select id="selectReportList" parameterType="xxxxx" resultType="xxxxx">SELECT tmp.*, ci.xx, ma.xx, mb.xx FROM(SELECT 查询结果FROM xxx puINNER JOIN xxx ccs ON pu.xx= ccs.xxINNER JOIN xxx wui ON wui.xx= pu.xx<where>查询查询条件 </where>/*customizeOrderBy*//*customizeLimit*/) tmpLEFT JOIN xxx ci ON tmp.xx= ci.xxLEFT JOIN xxx ma ON tmp.xx= ma.xx LEFT JOIN xxx mb ON tmp.xx = mb.xx </select>
3.控制查询是否需要Count
- 场景:业务中分页查询列表数据变化实时性不高,分页查询时只有查询第一页才统计count,避免重复的count统计
修改设置请求分页数据方法
/*** 设置请求分页数据(仅第一页查询count数)*/public static void startPageNoCount(){PageDomain pageDomain = TableSupport.buildPageRequest();Integer pageNum = pageDomain.getPageNum();Integer pageSize = pageDomain.getPageSize();String orderBy = SqlUtil.escapeOrderBySql(pageDomain.getOrderBy());Boolean reasonable = pageDomain.getReasonable();if(pageNum.intValue()==1) {//第一页查询countPageHelper.startPage(pageNum, pageSize, orderBy).setReasonable(reasonable);}else {PageHelper.startPage(pageNum, pageSize, false).setOrderBy(orderBy).setReasonable(reasonable);}}/*** 设置请求分页数据(仅第一页查询count数)*/public static void startPageNoCount(PageDomain pageDomain){pageDomain.setPageNum(Convert.toInt(pageDomain.getPageNum(), 1));pageDomain.setPageSize(Convert.toInt(pageDomain.getPageSize(), 10));Integer pageNum = pageDomain.getPageNum();Integer pageSize = pageDomain.getPageSize();String orderBy = SqlUtil.escapeOrderBySql(pageDomain.getOrderByNoScoreCase());//直接驼峰参数拼接Boolean reasonable = pageDomain.getReasonable();if(pageNum.intValue()==1) {//第一页查询countPageHelper.startPage(pageNum, pageSize, orderBy).setReasonable(reasonable);}else {PageHelper.startPage(pageNum, pageSize, false).setOrderBy(orderBy).setReasonable(reasonable);}}
原理基于 PageMethod.class 中startPage 方法控制实现
/*** 开始分页** @param pageNum 页码* @param pageSize 每页显示数量* @param count 是否进行count查询*/public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count) {return startPage(pageNum, pageSize, count, null, null);}
相关文章:

pagehelper 优化自定义分页和排序位置
pagehelper开源地址 https://github.com/pagehelper/Mybatis-PageHelper 1.手写Count查询优化 源码分页count时首先是判断是否存在手写的 {业务查询id}_COUNT 的查询count统计 private Long count(Executor executor, MappedStatement ms, Object parameter,RowBounds rowBound…...

Linux下查询文件夹中文件数量的方法
一、前言 在Linux系统中,我们经常需要查询文件夹中包含多少文件。本文将介绍三种在Linux中查询文件夹中文件数量的方法,帮助你轻松获取所需信息。 二、方法 1、使用ls命令和wc命令 使用ls命令的-l选项和管道操作符|结合wc命令来统计文件数量…...

PS透明屏,在科技展示中,有哪些优点展示?
PS透明屏是一种新型的显示技术,它将传统的显示屏幕与透明材料相结合,使得屏幕能够同时显示图像和透过屏幕看到背后的物体。 这种技术在商业展示、广告宣传、产品展示等领域有着广泛的应用前景。 PS透明屏的工作原理是利用透明材料的特性,通…...

Hbase-面试题
1. Hbase-region切分 自动切分,默认情况下 2.0版本,第一次region的数据达到256M,会进行切分,以后就是每达到10G切分一次,切分完成后,会进行负载均衡,均衡到其他regionserver预分区自定义rowke…...

图的宽度优先深度优先遍历
图常见的遍历方式有两种,一种是宽度优先遍历,一种是深度优先遍历。 宽度优先遍历 宽度优先遍历和之前介绍的二叉树的层级遍历类似,主要也是利用Queue来完成层级的遍历,除此之外,因为图中很可能有环,所以还…...

redis Set类型命令
Redis中的Set是一种无序、不重复的集合数据结构,它提供了一系列的操作命令用于对Set进行添加、删除和查找等操作。以下是Redis中Set类型常见的一些命令: SADD key member [member …]:将一个或多个成员添加到指定的集合中。 示例:…...

Netty框架自带类DefaultEventExecutorGroup的作用,用来做业务的并发
一、DefaultEventExecutorGroup的用途 DefaultEventExecutorGroup 是 Netty 框架中的一个类,用于管理和调度事件处理器(EventExecutor)的组。在 Netty 中,事件处理是通过多线程来完成的,EventExecutor 是处理事件的基…...

TCP的四次挥手与TCP状态转换
文章目录 四次挥手场景步骤TCP状态转换 四次挥手场景 TCP客户端与服务器断开连接的时候,在程序中使用close()函数,会使用TCP协议四次挥手。 客户端和服务端都可以主动发起。 因TCP连接时候是双向的,所以断开的时候也是双向的。 步骤 三次…...

【网络编程】实现一个简单多线程版本TCP服务器(附源码)
TCP多线程 🌵预备知识🎄 Accept函数🌲字节序转换函数🌳listen函数 🌴代码🌱Log.hpp🌿Makefile☘️TCPClient.cc🍀TCPServer.cc🎍 util.hpp 🌵预备知识 &…...

centos离线部署docker
有些内部环境需要离线部署,以下做一些备忘。 环境:centos7.9 准备文件: docker-20.10.9.tgz,下载地址 https://download.docker.com/linux/static/stable/x86_64/docker.service,内容见下文daemon.json,内…...
ffmpeg使用滤镜对视频进行处理播放
一、前言 在现代的多媒体处理中,视频和音频滤镜起着至关重要的作用。可以帮助开发者对视频和音频进行各种处理,如色彩校正、尺寸调整、去噪、特效添加等。而FFmpeg作为一个功能强大的开源多媒体框架,提供了丰富的滤镜库,使我们能够轻松地对多媒体文件进行处理和转换。 本…...

Ansible Handlers模块详解,深入理解Ansible Handlers 自动化中的关键组件
深入理解Ansible Handlers 自动化中的关键组件 在现代的IT环境中,自动化已经成为提高效率和减少错误的关键。Ansible作为一款流行的自动化工具,通过使用Playbooks来定义和执行任务。而Handlers作为Ansible的组件之一,在自动化过程中发挥着重要…...

threejs点击模型实现模型边缘高亮的选中效果--更改后提高帧率
先来个效果图 之前写的那个稍微有点问题,帧率只有30,参照官方代码修改后,帧率可以达到50了,在不全屏的状态下,帧率60 1.首先需要导入库 // 用于模型边缘高亮 import { EffectComposer } from "three/examples/js…...
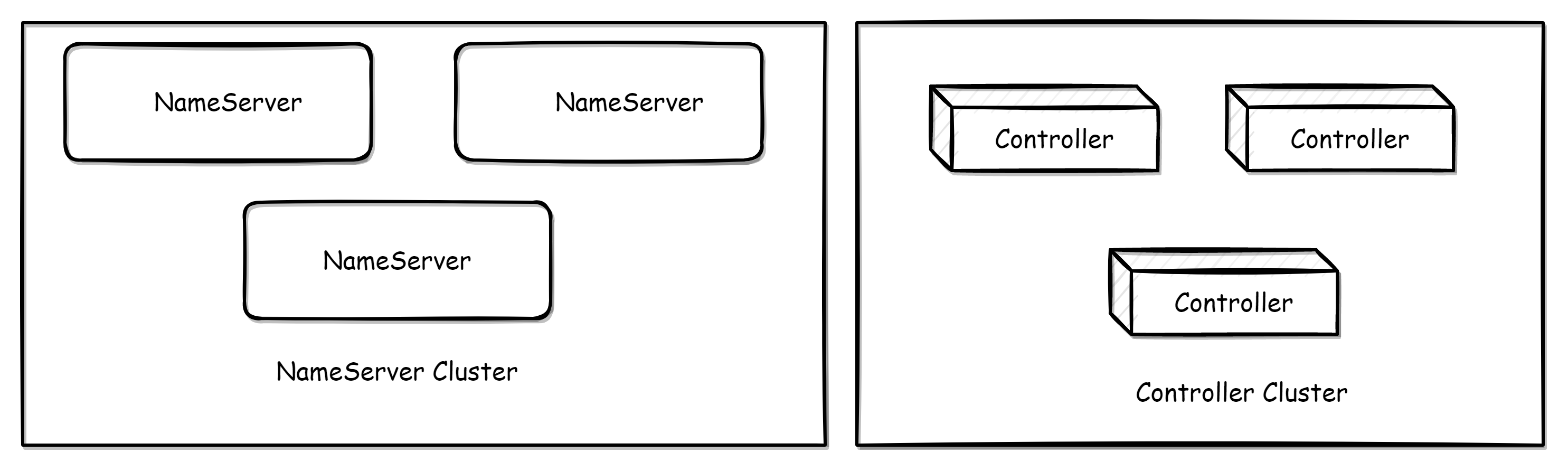
RocketMQ 主备自动切换模式部署
目录 主备自动切换模式部署 Controller 部署 Controller 嵌入 NameServer 部署 Controller 独立部署 Broker 部署 兼容性 升级注意事项 主备自动切换模式部署 该文档主要介绍如何部署支持自动主从切换的 RocketMQ 集群,其架构如上图所示ÿ…...

【MySQL】select相关
文章目录 迭代器distinct 关键字limit offset 关键字order by 列名 asc\descselect语句的执行顺序几点注意 迭代器 指向第一个元素 使用hasNext()进行判断后才进行取元素 resultSet:指向第一个元素前一个 distinct 关键字 去除一列中的重复元素 可以进行多行的去重…...

在Python中应用RSA算法实现图像加密:基于Jupyter环境的详细步骤和示例代码
一、引言 在当今的数字化社会中,信息安全问题备受关注。随着数字图像在生活中的应用越来越广泛,图像的安全性和隐私性也成为人们关心的焦点。如何在网络上安全地传输和存储图像已经成为一项重要的挑战。RSA(Rivest-Shamir-Adleman)算法作为一种被广泛应用的公钥密码体系,…...

Prometheus Blackbox Exporter 的 HTTP 探测指标中各个阶段的时间统计信息
在 Prometheus Blackbox Exporter 的 HTTP 探测指标中,probe_http_duration_seconds 指标包含各个阶段的时间统计信息。这些阶段代表了 HTTP 探测的不同阶段和指标。以下是各个阶段的含义: phase"dns_lookup":这是指进行 DNS 查找…...

数据结构之时间复杂度-空间复杂度
大家好,我是深鱼~ 目录 1.数据结构前言 1.1什么是数据结构 1.2什么是算法 1.3数据结构和算法的重要性 1.4如何学好数据结构和算法 2.算法的效率 3.时间复杂度 3.1时间复杂度的概念 3.2大O的渐进表示法 【实例1】:双重循环的时间复杂度…...

新一代构建工具 maven-mvnd
新一代构建工具 maven-mvnd mvnd的前世今生下载安装 mvndIDEA集成 mvnd的前世今生 maven 作为一代经典的构建工具,流行了很多年,知道现在依然是大部分Java项目的构建工具的首选;但随着项目复杂度提高,代码量及依赖库的增多使得ma…...
构建Docker容器监控系统(2)(Cadvisor +Prometheus+Grafana)
Cadvisor产品简介 Cadvisor是Google开源的一款用于展示和分析容器运行状态的可视化工具。通过在主机上运行Cadvisor用户可以轻松的获取到当前主机上容器的运行统计信息,并以图表的形式向用户展示。 接着上一篇来继续 部署Cadvisor 被监控主机上部署Cadvisor容器…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...