NLPCC 出版部分相关源码记录
目录
Download
Unzip
Author
Title
Affiliation
Check number of tex
Zip
Rename
Delete
Download
import requests
from bs4 import BeautifulSoup# 登录网站并获取登录后的 session
def login(username, password):login_url = 'https://example.com/login'session = requests.session()login_data = {'username': username,'password': password,# 其他登录参数}response = session.post(login_url, data=login_data)if response.status_code == 200:print("登录成功!")return sessionelse:print("登录失败!")return None# 获取文件列表页面中的文件链接
def get_file_links(session, file_list_url):response = session.get(file_list_url)soup = BeautifulSoup(response.text, 'html.parser')file_links = []# 使用 BeautifulSoup 解析文件列表页面,获取文件链接# 例如:file_links = soup.find_all('a', class_='file-link')return file_links# 批量下载文件
def download_files(session, file_links, download_path):for link in file_links:file_url = link['href']file_name = link.text.strip()response = session.get(file_url, stream=True)if response.status_code == 200:# 保存文件到本地with open(f"{download_path}/{file_name}", 'wb') as file:for chunk in response.iter_content(chunk_size=8192):file.write(chunk)print(f"{file_name} 下载成功!")else:print(f"{file_name} 下载失败!")def main():username = 'your_username'password = 'your_password'file_list_url = 'https://example.com/files' # 文件列表页面的 URLdownload_path = 'downloaded_files' # 本地下载路径# 登录网站并获取登录后的 sessionsession = login(username, password)if session:# 获取文件列表页面中的文件链接file_links = get_file_links(session, file_list_url)if file_links:# 批量下载文件download_files(session, file_links, download_path)else:print("未找到文件链接!")else:print("登录失败,请检查用户名和密码!")# if __name__ == "__main__":
# main()
import requests
from bs4 import BeautifulSoupdef login(username, password):login_url = 'https://softconf.com/nlpcc/Main-2023/login/scmd.cgi?scmd=login'session = requests.session()login_data = {"username": username,"password": password}response = session.post(login_url, data=login_data)# print(response.text)if response.status_code == 200:print("登录成功!")return sessionelse:print("登录失败!")return Noneusername, passwd = "用户名", "密码"
session = login(username, passwd)import reids = {214,215,220,221,222,225,229,233,235,238,239,241,246,250,251,252,254,256,258,260,264,271,285,292,299,301,306,307,308,}
file_list_url = "https://softconf.com/nlpcc/Main-2023/pub/scmd.cgi?scmd=manager&ToPage=monitorFinalSubmissions&FromPage=Main"
response = session.get(file_list_url)
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table', id='t1')
links = table.find_all('a')
all_urls = [link.get('href') for link in links]
urls = []
for i in range(len(all_urls)):if all_urls[i] and all_urls[i].startswith('scmd.cgi?scmd=submitPaperCustom'):if (m := re.search(r"passcode=(\d+)X-.+", all_urls[i])) is not None:# print(m.group(1))if int(m.group(1)) in ids:urls.append((int(m.group(1)), "https://softconf.com/nlpcc/Main-2023/pub/"+all_urls[i]))
print(len(urls)==len(ids))
print(urls)import time
import os
from tqdm.auto import tqdmdef download_files(session, urls:dict, paper_id:int):for file_name, file_url in urls.items():response = session.get(file_url, stream=True)save_dir = f"./downloads/{paper_id}/"os.makedirs(save_dir, exist_ok=True)if response.status_code == 200:# 保存文件到本地with open(f"{save_dir}/{file_name}", 'wb') as file:for chunk in response.iter_content(chunk_size=8192):file.write(chunk)# print(f"{paper_id}_{file_name} 下载成功!")else:print(f"{paper_id}_{file_name} 下载失败!")for paper_id, url in tqdm(urls):response = session.get(url)soup = BeautifulSoup(response.text, 'html.parser')links = soup.find_all('a')urls_ = map(lambda link: link.get('href') if link else "", links)pdf_url = [link.get('href') for link in links if link.get('href') and link.get('href').endswith("fieldid=Final_Manuscript")][0]zip_url = [link.get('href') for link in links if link.get('href') and link.get('href').endswith("fieldid=Source_File")][0]copyright_url = [link.get('href') for link in links if link.get('href') and link.get('href').endswith("fieldid=CopyRight_Springer")][0]downloads_urls = {"Final_Manuscript.pdf": pdf_url, "Source_File.zip":zip_url, "CopyRight.pdf":copyright_url}downloads_urls = {"CopyRight.pdf":copyright_url}# print(downloads_urls)try:download_files(session, downloads_urls, paper_id)except:pass# breaktime.sleep(2)Unzip
import zipfile
import os
import pathlibdef unzip_file(zip_filepath, dest_path):with zipfile.ZipFile(zip_filepath, 'r') as zip_ref:zip_ref.extractall(dest_path)# 使用方法
root_dir = pathlib.Path("./downloads/")
for directory in root_dir.iterdir():try:unzip_file(directory/"Source_File.zip", directory/"Source_File")except Exception as e:print(e)print(directory)# break
import pathlibroot_dir = pathlib.Path("./downloads/")
for directory in root_dir.iterdir():path = directory/"Source_File"path_true = pathlib.Path(path)dir_outputs_tex_true = path_true/"outputs_tex"dir_outputs_tex_true.mkdir(exist_ok=True)if (path/"submission.tex").exists():dir_outputs_tex = pathlib.PurePosixPath("outputs_tex")path_tex = pathlib.PurePosixPath("submission.tex")path_aux = dir_outputs_tex/"submission.aux"! cd {path_true} & pdflatex -output-directory={dir_outputs_tex} -synctex=0 -interaction=nonstopmode -file-line-error {path_tex}! cd {path_true} & bibtex {path_aux}! cd {path_true} & pdflatex -output-directory={dir_outputs_tex} -synctex=0 -interaction=nonstopmode -file-line-error {path_tex}! cd {path_true} & pdflatex -output-directory={dir_outputs_tex} -synctex=0 -interaction=nonstopmode -file-line-error {path_tex}else:print(directory)
def compile2pdf(directory):directory = pathlib.Path(directory)path = directory/"Source_File"path_true = pathlib.Path(path)dir_outputs_tex_true = path_true/"outputs_tex"dir_outputs_tex_true.mkdir(exist_ok=True)if (path/"submission.tex").exists():dir_outputs_tex = pathlib.PurePosixPath("outputs_tex")path_tex = pathlib.PurePosixPath("submission.tex")path_aux = dir_outputs_tex/"submission.aux"! cd {path_true} & pdflatex -output-directory={dir_outputs_tex} -synctex=0 -interaction=nonstopmode -file-line-error {path_tex}! cd {path_true} & bibtex {path_aux}! cd {path_true} & pdflatex -output-directory={dir_outputs_tex} -synctex=0 -interaction=nonstopmode -file-line-error {path_tex}! cd {path_true} & pdflatex -output-directory={dir_outputs_tex} -synctex=0 -interaction=nonstopmode -file-line-error {path_tex}else:print(directory)compile2pdf("downloads/306")def is_same_file(file1, file2):with open(file1, 'rb') as f1, open(file2, 'rb') as f2:return f1.read() == f2.read()import PyPDF2from PyPDF2 import PdfReaderdef extract_text_from_pdf(file_path):with open(file_path, 'rb') as file:pdf = PdfReader(file)text = ""for page in range(len(pdf.pages)):text += pdf.pages[page].extract_text()return text, len(pdf.pages)def compare_pdfs(file_path1, file_path2):text1, n_1 = extract_text_from_pdf(file_path1)text2, n_2 = extract_text_from_pdf(file_path2)return text1 == text2, n_1, n_2root_dir = pathlib.Path("./downloads/")
for directory in root_dir.iterdir():camera_ready = directory/"Final_Manuscript.pdf"compiled = directory/"Source_File"/"outputs_tex"/"submission.pdf"try: ok, n1, n2 = compare_pdfs(camera_ready, compiled)if not ok:print(f"Not same: {directory}")print(n1, n2, sep=' ')except Exception as e:print(e)print(f"Fail to compare: {directory}")print("=========================================================================")
Author
import redef extract_author(tex_file_path):with open(tex_file_path, 'r', encoding='utf-8') as tex_file:tex_content = tex_file.read()# Use regular expression to find the \author partpattern = r"^\\author{\s*(.*?)\s*}\s+\%"matches = re.search(pattern, tex_content, re.DOTALL|re.MULTILINE)if matches:return matches.group(1)else:return ""tex_file_path = "downloads\\215\\Source_File\\submission.tex" # Replace with the path to your .tex file
author = extract_author(tex_file_path)authors = []
root_dir = pathlib.Path("./downloads/")
for directory in root_dir.iterdir():tex_file_path = directory/"Source_File"/"submission.tex"print(f"------{directory}---------")if tex_file_path.exists():author = extract_author(tex_file_path)# author = re.sub(r"\\.*", "", author)# author = re.sub(r"[^\w\s]", "", author)# author = re.sub(r"\s*?\n\s*", ",", author)# author = author[:-1] if author.endswith(',') else author# author = re.sub(r'(?<=,)(?=[^,]*$)', 'and ', author) #将最后一个逗号换成 `and`# # author = re.sub(r',(?=[^,]*$)', ' and ', author) #将最后一个逗号换成 `and`authors.append(author)print(author)else:print(f"Fail to open tex: {tex_file_path}")authors.append("")print('====================================================================')
import pandas as pd# 将列表转换为DataFrame
df = pd.DataFrame(authors, columns=["author"])# 保存DataFrame到Excel文件
file_path = "./author.xlsx"
df.to_excel(file_path, index=False)
Title
import redef extract_title(tex_file_path):with open(tex_file_path, 'r', encoding='utf-8') as tex_file:tex_content = tex_file.read()# Use regular expression to find the \author partpattern = r"^\\title{\s*(.*?)\s*}\s+\%"matches = re.search(pattern, tex_content, re.DOTALL|re.MULTILINE)if matches:return matches.group(1)else:return ""# tex_file_path = "downloads\\215\\Source_File\\submission.tex" # Replace with the path to your .tex file
# author = extract_author(tex_file_path)authors = []
root_dir = pathlib.Path("./downloads/")
for directory in root_dir.iterdir():tex_file_path = directory/"Source_File"/"submission.tex"print(f"------{directory}---------")if tex_file_path.exists():author = extract_title(tex_file_path)author = re.sub(r"\s*\\\\\s*", " ", author)author = re.sub(r"\\.*", "", author)authors.append(author)print(author)else:print(f"Fail to open tex: {tex_file_path}")authors.append("")print('====================================================================')
import pandas as pd# 将列表转换为DataFrame
df = pd.DataFrame(authors, columns=["title"])# 保存DataFrame到Excel文件
file_path = "./title.xlsx"
df.to_excel(file_path, index=False)
Affiliation
import redef extract_affiliation(tex_file_path):with open(tex_file_path, 'r', encoding='utf-8') as tex_file:tex_content = tex_file.read()# Use regular expression to find the \author partpattern = r"^\\institute{\s*(.*?)\s*}\s+\%"matches = re.search(pattern, tex_content, re.DOTALL|re.MULTILINE)if matches:return matches.group(1)else:return ""# tex_file_path = "downloads\\215\\Source_File\\submission.tex" # Replace with the path to your .tex file
# author = extract_author(tex_file_path)authors = []
root_dir = pathlib.Path("./downloads/")
i = 2
for directory in root_dir.iterdir():tex_file_path = directory/"Source_File"/"submission.tex"print(f"------{i} {directory}---------")i += 1if tex_file_path.exists():author = extract_affiliation(tex_file_path)# author = re.sub(r"\s*\\\\\s*", " ", author)# author = re.sub(r"\\.*", "", author)authors.append(author)print(author)else:print(f"Fail to open tex: {tex_file_path}")authors.append("")print('====================================================================')
import pandas as pd# 将列表转换为DataFrame
df = pd.DataFrame(authors, columns=["affiliation"])# 保存DataFrame到Excel文件
file_path = "./affiliation.xlsx"
df.to_excel(file_path, index=False)
Check number of tex
import pathlib
root_dir = pathlib.Path("./downloads/")def num_tex(dirctory: pathlib.Path):num = 0for d in dirctory.iterdir():num += (d.suffix=='.tex')return numfor d in root_dir.iterdir():src = d/"Source_File"if num_tex(src)>1:print(d)Zip
import os
import zipfiledef zip_directory(directory_path, zip_path):"""压缩目录到zip文件:param directory_path: 要压缩的目录路径:param zip_path: zip文件保存路径"""with zipfile.ZipFile(zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:for root, _, files in os.walk(directory_path):for file in files:file_path = os.path.join(root, file)zipf.write(file_path, os.path.relpath(file_path, directory_path))# # 示例用法
# directory_to_compress = '/path/to/source_directory'
# zip_file_path = '/path/to/destination.zip'
# zip_directory(directory_to_compress, zip_file_path)
Rename
import pathlib
root_dir = pathlib.Path("./downloads/")for d in list(root_dir.iterdir()):src = d/"Source_File"zip_directory(src, src.parent/"source.zip")submi = d/"Final_Manuscript.pdf"submi.rename(submi.with_name("submission.pdf"))cprt = d/"CopyRight.pdf"cprt.rename(cprt.rename(cprt.with_name("copyright.pdf")))
Delete
import pathlib
import shutil
import os
root_dir = pathlib.Path("./downloads/")for d in list(root_dir.iterdir()):src = d/"Source_File.zip"os.remove(src)相关文章:

NLPCC 出版部分相关源码记录
目录 Download Unzip Author Title Affiliation Check number of tex Zip Rename Delete Download import requests from bs4 import BeautifulSoup# 登录网站并获取登录后的 session def login(username, password):login_url https://example.com/loginsession re…...

【Windbg】通过网络调试windows内核
环境 windows版本:win10_x64 1901 windbg版本:1.2306.12001.0 HOST 1、windbg软件设置。 点击菜单文件,然后如下图操作。 2、等待连接。 ************* Waiting for Debugger Extensions Gallery to Initialize **************>>&…...
代码随想录算法训练营之JAVA|第二十四天| 93. 复原 IP 地址
今天是第24天刷leetcode,立个flag,打卡60天。 算法挑战链接 93. 复原 IP 地址https://leetcode.cn/problems/restore-ip-addresses/ 第一想法 题目理解:将一串数字字符串变成正确的ip格式的字符串。 这类题目是切分字符串,ip一…...
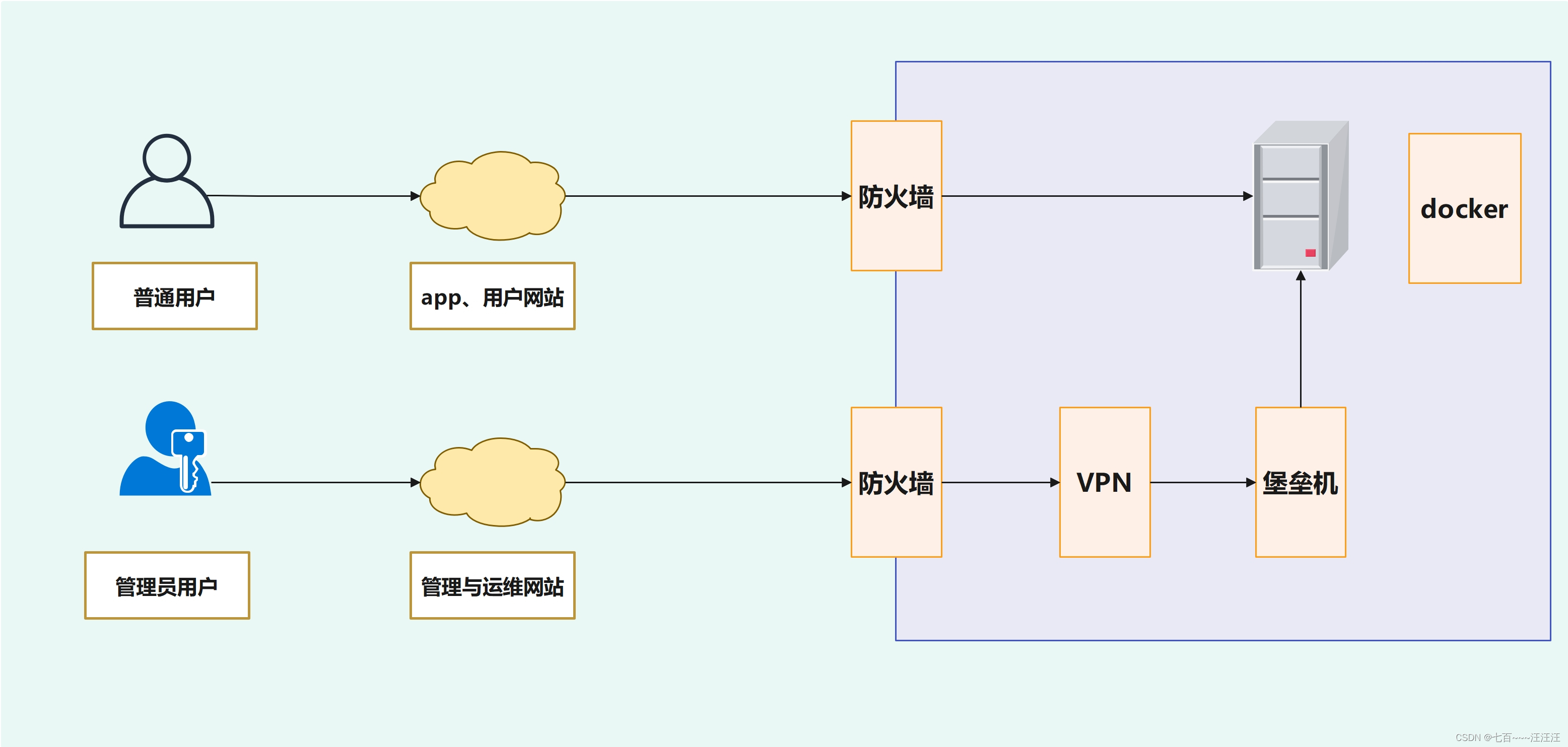
网络安全 Day30-运维安全项目-堡垒机部署
运维安全项目-堡垒机部署 1. 运维安全项目-架构概述2. 运维安全项目之堡垒机2.1 堡垒机概述2.2 堡垒机选型2.3 环境准备2.4 部署Teleport堡垒机2.4.1 下载与部署2.4.2 启动2.4.3 浏览器访问teleport2.4.4 进行配置2.4.5 安装teleport客户端 2.5 teleport连接服务器 1. 运维安全…...

电脑文件夹备份命令
电脑文件夹备份 cmd窗口输入shell:startup 将备份.bat文件放到,自启动文件夹下 bat文件内容写以下就可以了 Xcopy "D:\文件\" "F:\文件备份\" /E/H/C/I/y...

RocketMQ Learning(一)
目录 一、RocketMQ 0、RocketMQ的产品发展 1、RocketMQ安装 1.1、windows下的安装 注意事项 1.2、Linux下的安装 1.3、源码的安装 1.4、控制台 2、消息发送方式 2.1、发送同步消息 2.2、发送异步消息 2.3、单向发送 3、消息消费方式 3.1、负载均衡模式࿰…...
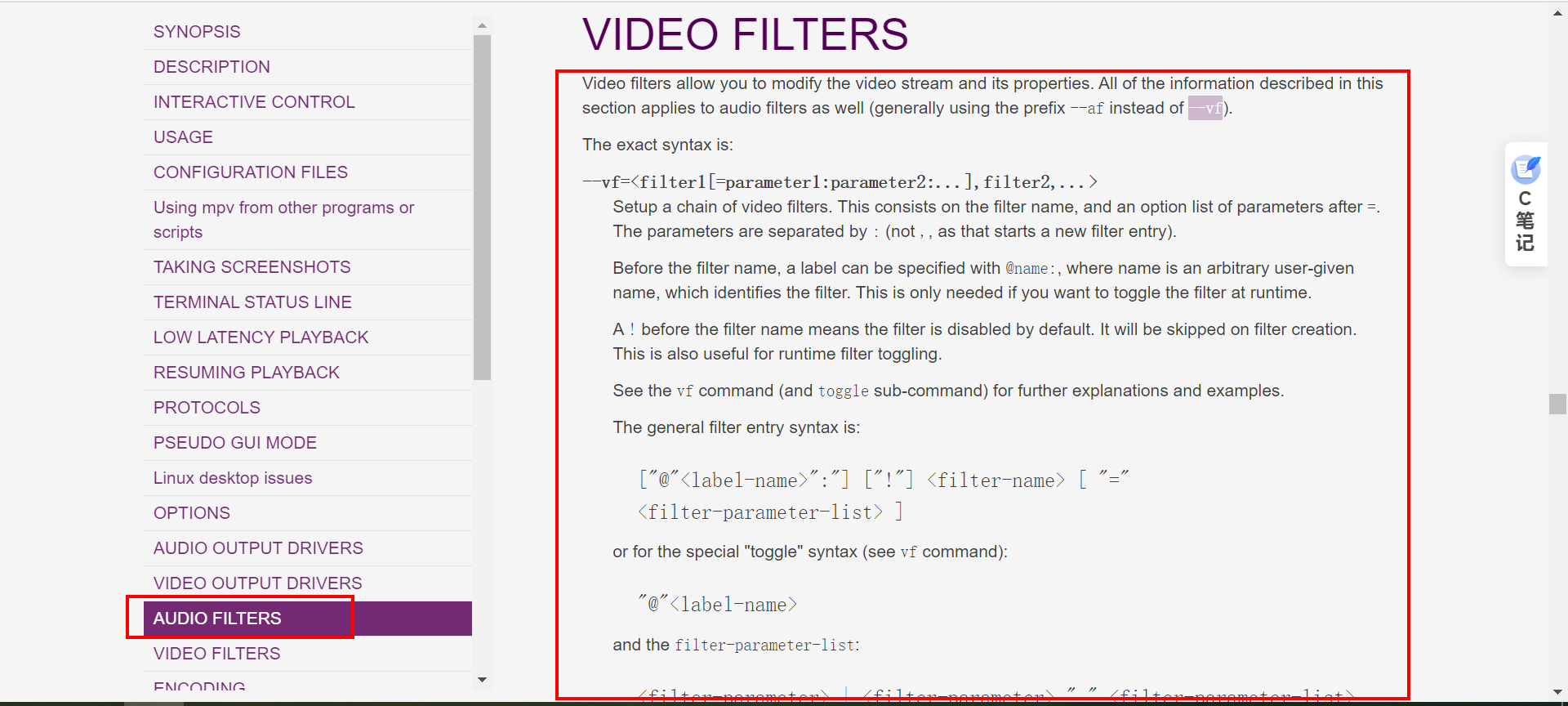
libmpv使用滤镜处理视频进行播放
一、前言 作为一个功能强大的多媒体框架,libmpv为开发者提供了广泛的功能和灵活的控制权。滤镜是libmpv的一个重要特性,允许开发者对视频进行各种实时处理和增强,从而满足用户对于个性化、创意化和高质量视频体验的需求。 滤镜是一种在视频渲染过程中应用特定效果的技术。…...

Harbor.cfg 配置文件参数详解
目录 Harbor.cfg 配置文件参数详解 所需参数: hostname: ui_url_protocol: max_job_workers: db_password: customize_crt: ssl_cert: ssl_cert_key: secretkey_path&#…...

模仿火星科技 基于cesium+ 贴地测量+可编辑
当您进入Cesium的编辑贴地测量世界,下面是一个详细的操作过程,帮助您顺利使用这些功能: 1. 创建提示窗: 启动Cesium应用,地图场景将打开,欢迎您进入编辑模式。在屏幕的一角,一个友好的提示窗将…...

模仿火星科技 基于cesium+角度测量+高度测量+可编辑
1. 创建提示窗: 启动Cesium应用,地图场景将打开,欢迎您进入编辑模式。 在屏幕的一角,一个友好的提示窗将呈现,随着您的操作,它会为您提供有用的信息和指导。 2. 绘制面积: 轻轻点击鼠标左键&a…...

Codeforces の 动态规划
Codeforces Round 785 (Div. 2) - C. Palindrome Basis dp(9/100) 题目链接 思路:整数划分基础上加一个判断回文的条件 整数划分思路:背包容量为n,物品有体积为1~n n种,每种无数个,求使背包恰好装满的方案数——完全背…...
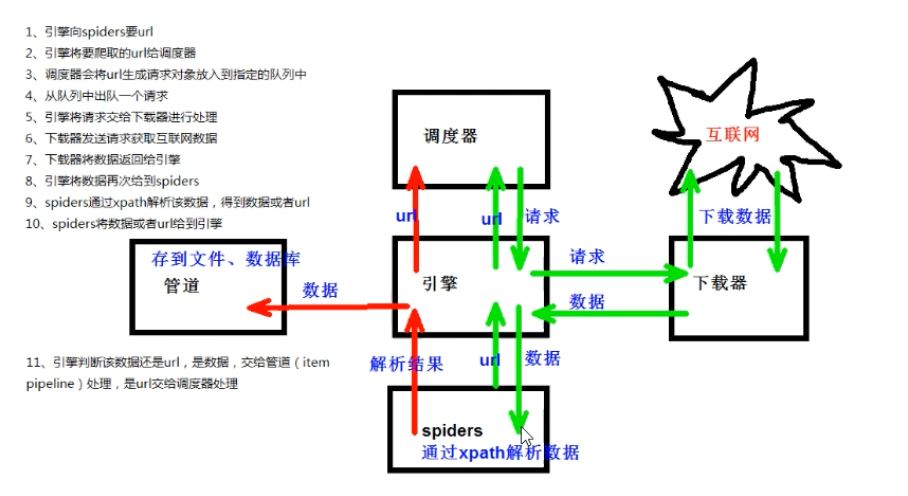
数学建模-爬虫系统学习
尚硅谷Python爬虫教程小白零基础速通(含python基础爬虫案例) 内容包括:Python基础、Urllib、解析(xpath、jsonpath、beautiful)、requests、selenium、Scrapy框架 python基础 进阶(字符串 列表 元组 字典…...
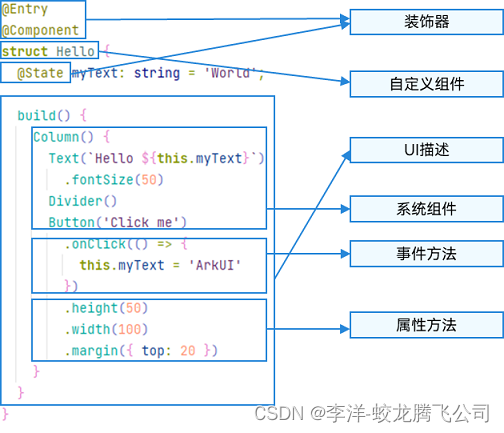
HarmonyOS/OpenHarmony应用开发-ArkTS语言渲染控制概述
ArkUI通过自定义组件的build()函数和builder装饰器中的声明式UI描述语句构建相应的UI。 在声明式描述语句中开发者除了使用系统组件外,还可以使用渲染控制语句来辅助UI的构建,这些渲染控制语句包括控制组件是否显示的条件渲染语句,基于数组数…...

【力扣刷题 | 第二十五天】
目录 前言: 474. 一和零 - 力扣(LeetCode) 总结: 前言: 今天我们依旧暴打动态规划 474. 一和零 - 力扣(LeetCode) 给你一个二进制字符串数组 strs 和两个整数 m 和 n 。 请你找出并返回 strs 的最大子集…...
GO学习之 函数(Function)
GO系列 1、GO学习之Hello World 2、GO学习之入门语法 3、GO学习之切片操作 4、GO学习之 Map 操作 5、GO学习之 结构体 操作 6、GO学习之 通道(Channel) 7、GO学习之 多线程(goroutine) 8、GO学习之 函数(Function) 9、GO学习之 接口(Interface) 文章目录 GO系列前言一、什么是…...

Jstack线上问题排查
1.top查找出哪个进程消耗的cpu高。执行top命令,默认是进程视图,其中PID是进程号(记下进程号) 2.top中shifth 或“H”查找出哪个线程消耗的cpu高 (记下最高的几个线程号) jstack 进程号 >> pid-cpu.…...

VIM 编辑器: Bram Moolenaar
VIM 用了很长时间, 个人的 VIM 配置文件差不多10年没有更新了。以前写程序的时候, 编辑都用这个。 linux kernel, boost规模的代码都不在话下。现在虽然代码写的少了,依然是我打开文件的首选。 现在用手机了,配个蓝牙键…...

鸿蒙应用开发指南:从零开始构建一款智能音乐播放器
介绍 随着鸿蒙操作系统的发布,开发者们迫不及待地想要探索鸿蒙应用的开发。本篇博客将以构建一款智能音乐播放器为例,带你一步步了解鸿蒙应用开发的技术要点和实践。我们将使用HarmonyOS的开发环境和MarkDown进行排版,方便你快速上手。 准备…...
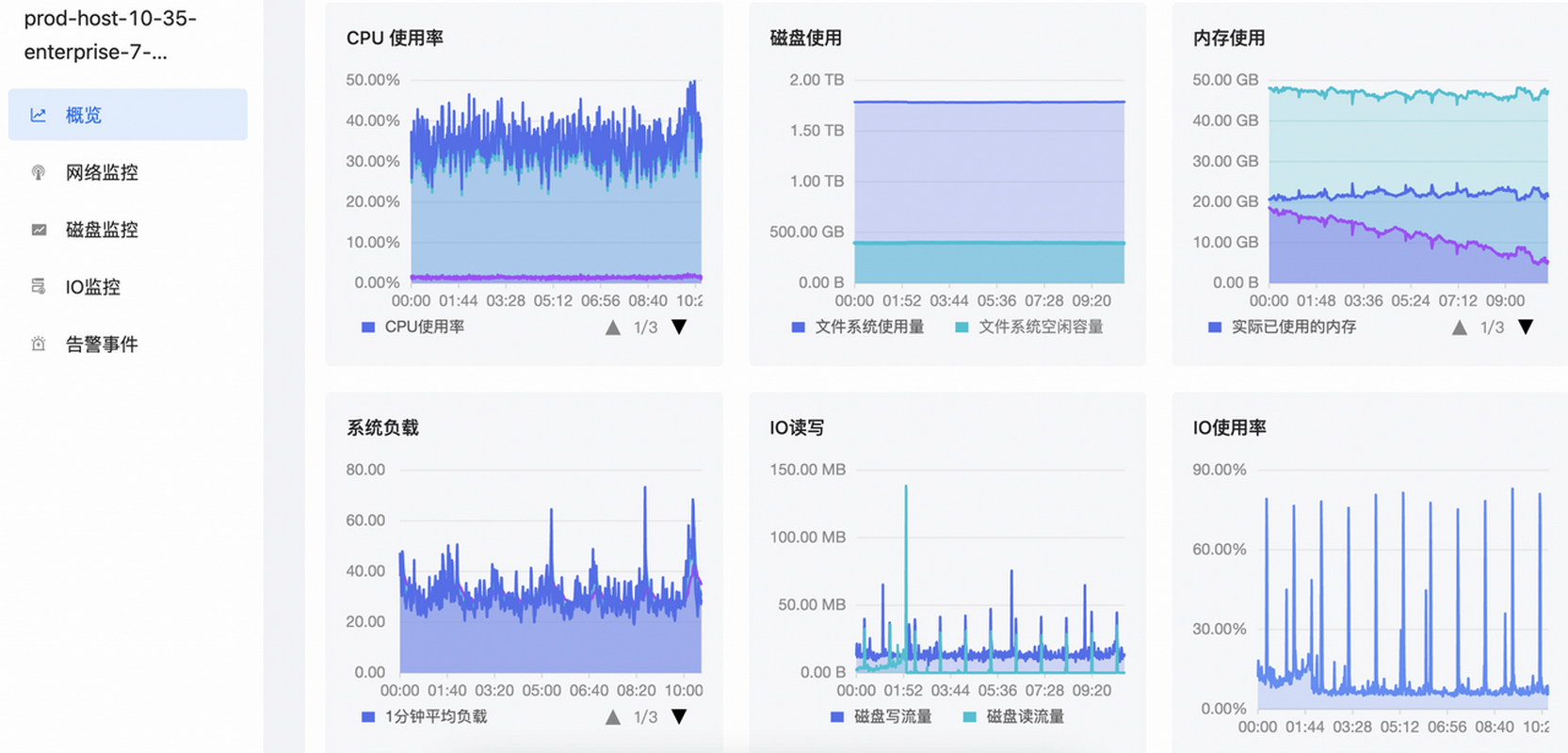
如何实现对主机的立体监控?
主机监控是保证系统稳定性和性能的重要环节之一,那应该如何实现对主机的立体监控? 本期EasyOps产品使用最佳实践,我们将为您揭晓: 主机应该如何分组和管理? 主机监控应该关注哪些关键性指标? 背 景 通…...
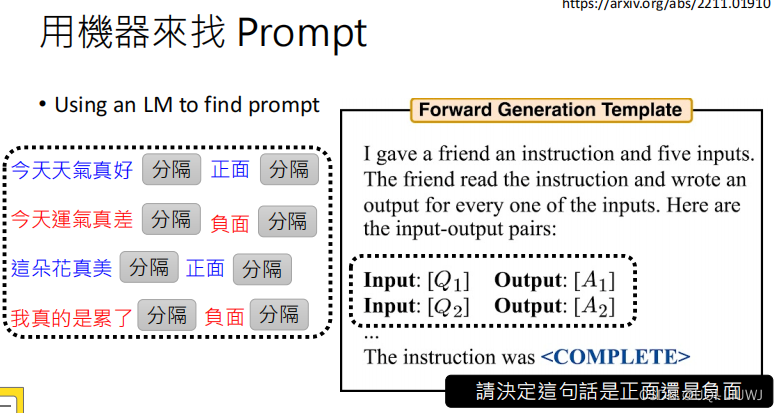
机器学习笔记:李宏毅ChatGPT Finetune VS Prompt
1 两种大语言模型:GPT VS BERT 2 对于大语言模型的两种不同期待 2.1 “专才” 2.1.1 成为专才的好处 Is ChatGPT A Good Translator? A Preliminary Study 2023 Arxiv 箭头方向指的是从哪个方向往哪个方向翻译 表格里面的数值越大表示翻译的越好 可以发现专门做翻…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

Python 高效图像帧提取与视频编码:实战指南
Python 高效图像帧提取与视频编码:实战指南 在音视频处理领域,图像帧提取与视频编码是基础但极具挑战性的任务。Python 结合强大的第三方库(如 OpenCV、FFmpeg、PyAV),可以高效处理视频流,实现快速帧提取、压缩编码等关键功能。本文将深入介绍如何优化这些流程,提高处理…...
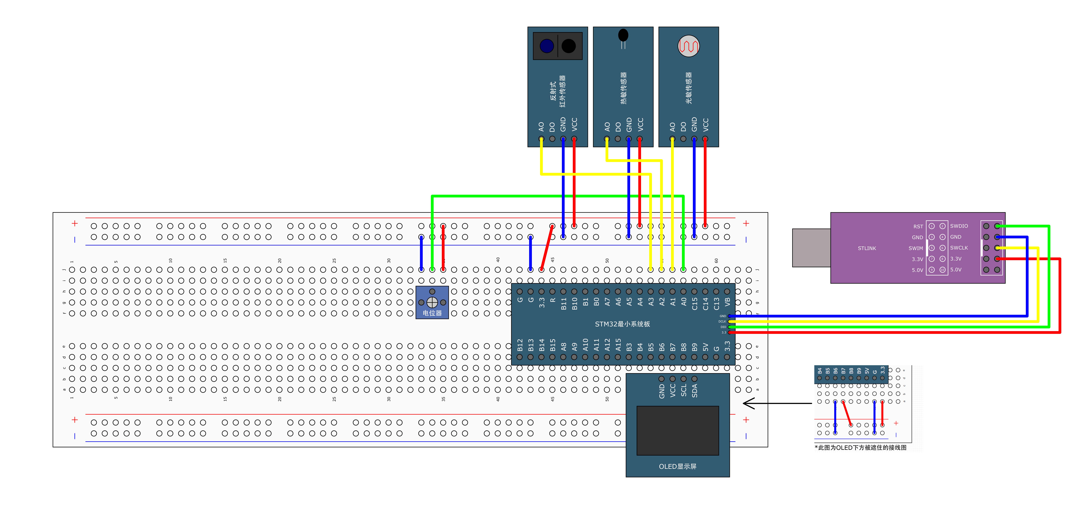
STM32标准库-ADC数模转换器
文章目录 一、ADC1.1简介1. 2逐次逼近型ADC1.3ADC框图1.4ADC基本结构1.4.1 信号 “上车点”:输入模块(GPIO、温度、V_REFINT)1.4.2 信号 “调度站”:多路开关1.4.3 信号 “加工厂”:ADC 转换器(规则组 注入…...