商品推荐系统浅析 | 京东云技术团队
一、综述
本文主要做推荐系统浅析,主要介绍推荐系统的定义,推荐系统的基础框架,简单介绍设计推荐的相关方法以及架构。适用于部分对推荐系统感兴趣的同学以及有相关基础的同学,本人水平有限,欢迎大家指正。
二、商品推荐系统
2.1 推荐系统的定义
推荐系统本质上还是解决信息过载的问题,帮助用户找到他们感兴趣的物品,深度挖掘用户潜在的兴趣。
2.2 推荐架构
其实推荐系统的核心流程只有召回、排序、重排。

请求流程
当一个用户打开一个页面,这个时候前端会携带用户信息(pin或者uuid等)去请求后台接口(通过color间接调用),当后台收到请求后一般会先根据用户标识进行分流获取相关策略配置(ab策略),这些策略去决定接下来会调用召回模块、排序模块以及重排模块的哪个接口。一般召回模块分多路召回,每路召回负责召回多个商品,排序和重排负责调整这些商品的顺序。最后挑选出合适的商品并进行价格、图片等相关信息补充展现给用户。用户会根据自己是否感兴趣选择点击或者不点击,这些涉及用户的行为会通过日志上报到数据平台,为之后效果分析和利用用户行为推荐商品奠定基础。

其实有些问题想说一说:
为什么要采取召回、排序、重排这种漏斗分层架构?

(1)从性能方面
终极:从百万级的商品库筛选出用户感兴趣的个位数级别的商品。
复杂的排序模型线上推断耗时严重,需要严格控制进入排序模型的商品数量。需要进行拆解
(2)从目标方面
召回模块:召回模块的任务是快速从大量的物品中筛选出一部分候选物品,目的是不要漏掉用户可能会喜欢的物品。召回模块通常采用多路召回,使用一些简化的特征或模型。
排序模块:排序模块的任务是精准排序,根据用户的历史行为、兴趣、偏好等信息,对召回模块筛选出的候选物品进行排序。排序模块通常使用一些复杂的模型。
重排模块:重排模块的任务是对排序模块的结果进行二次排序或调整,以进一步提高推荐的准确性和个性化程度。重排模块通常使用一些简单而有效的算法。
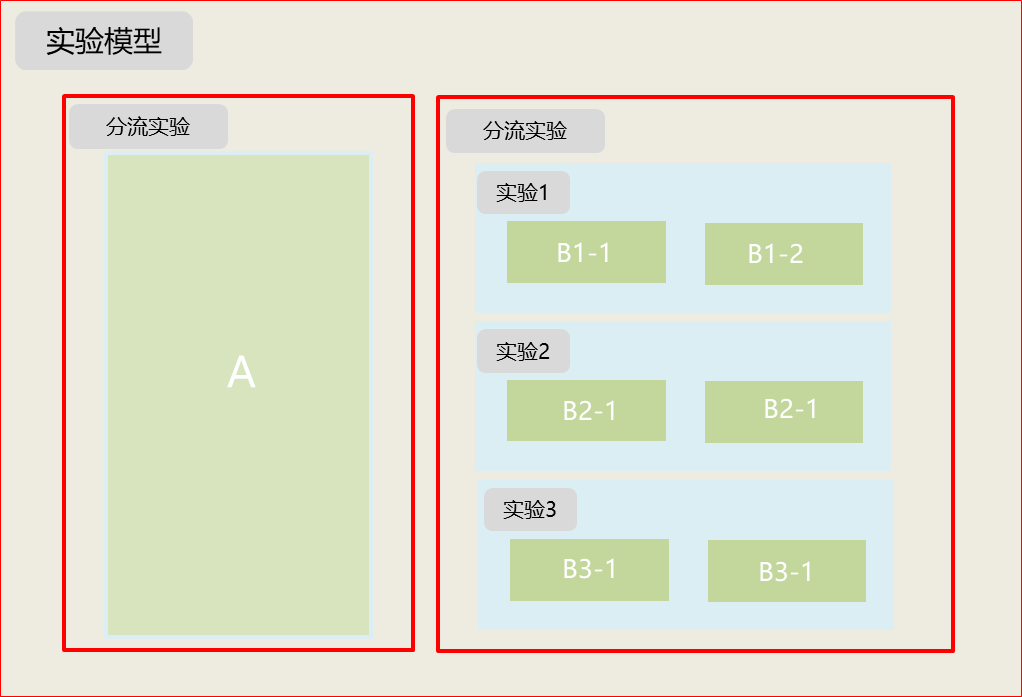
什么是ab实验?
参考论文:Overlapping Experiment Infrastructure: More, Better, Faster Experimentation(google2010)
只有在线实验才能真正评估模型优劣,ab实验可以快速验证实验的效果,快速迭代模型。减少上线新功能的风险。
ab算法:Hash(uuid+实验id+创建时间戳)%100
特性:分流+正交

2.3召回
召回层的存在仅仅是为用户从广阔的商品池子中初筛出一批还不错的商品。为了平衡计算速度与召回率(正样本占全部正样本的比例)指标之间的矛盾,采用多路召回策略,每路召回策略只考虑其中的单一特征或策略。
2.3.1多路召回的优劣
多路召回:采用不同的策略、特征或者简单模型分别召回一部分候选集,然后把候选集混合在一起供排序使用。召回率高,速度快,多路召回相互补充。
多路召回中每路召回的截断个数K是个超参数,需要人工调参,成本高;召回通路存在重合问题,冗余。
是否存在一种召回可以替代多路召回,向量召回应用而生,就目前而言,仍然是以向量召回为主,其他召回为辅的架构。
2.3.2召回分类
主要分为非个性化召回,个性化召回两大类。非个性化召回主要是进行热点推送,推荐领域马太效应严重,20%的商品贡献80%的点击。个性化召回主要是发掘用户感兴趣的商品,着重处理每个用户的差异点,提高商品的多样性,保持用户的粘性。
非个性化召回
(1) 热门召回
近7天高点击、高点赞、高销量商品召回
(2)新品召回
最新上架的商品召回
个性化召回
(1)标签召回、地域召回
标签召回:用户感兴趣的品类、品牌、店铺召回等
地域召回:根据用户的地域召回地域内的优质商品。
(2)cf召回
协同过滤算法是基于用户行为数据挖掘用户的行为偏好,从而根据用户的行为偏好为其推荐物品,其根据的是用户和物品的行为矩阵(共现矩阵)。用户行为一般包括浏览、点赞、加购、点击、关注、分享等等。
协同过滤分为三大类:基于用户的协同过滤(UCF)和基于物品的协同过滤(ICF)和基于模型的协同过滤(隐语义模型)。是否为用户推荐某个物品,首先要把用户和物品进行关联,而进行关联的点是另一个物品还是另一个用户,决定了这属于哪个类型的协同过滤。而基于隐语义模型是根据用户行为数据进行自动聚类挖掘用户的潜在兴趣特征。从而通过潜在兴趣特征对用户和物品进行关联。
基于物品的协同过滤(ICF):判断是否为用户推荐某个物品,首先根据用户历史行为记录的物品和这个物品的相似关系来推断用户对这个物品的兴趣度,从而判断我们是否推荐这个物品。整个协同过滤过程主要分为以下几步:计算物品之间的相似度,计算用户对物品的兴趣度,排序截取结果。
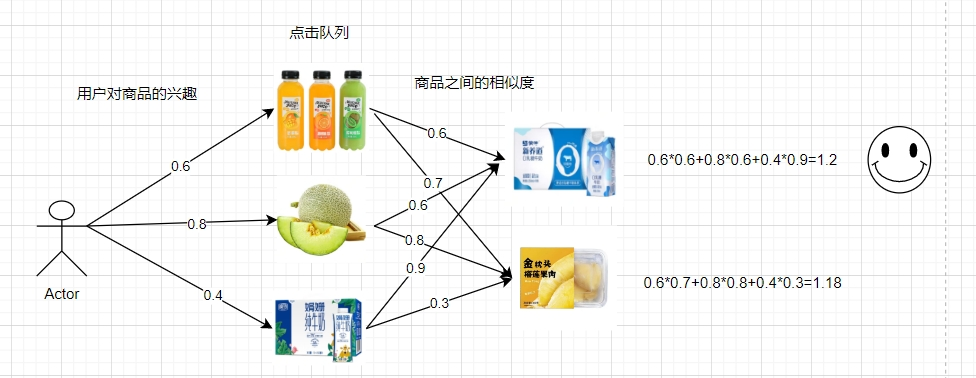
商品相似度计算:
衡量相似度主要有以下几种方式:夹角余弦距离,杰卡德公式。由于用户或物品的表示方式的多样性,使得这些相似度的计算非常灵活。我们可以利用用户和物品的行为矩阵来去计算相似度,也可以根据用户行为、物品属性和上下文关系构造用户和物品的向量表示去计算相似性。
夹角余弦距离公式: cosθ=(x1*x2+y1*y2)/(√(x12+y12 )*√(x22+y22 ))
杰卡德公式J(A,B)=(|A⋂B|)/(|A⋃B|)
| 商品a | 商品b | 商品c | 商品d | |
|---|---|---|---|---|
| 用户A | 1 | 0 | 0 | 1 |
| 用户B | 0 | 1 | 1 | 0 |
| 用户C | 1 | 0 | 1 | 1 |
| 用户D | 1 | 1 | 0 | 0 |
夹角余弦距离公式计算商品a和b的相似度:
Wab=(1*0+0*1+1*0+1*1)/(√(12+02+12+12 )*√(02+12+02+12 ))=1/√6
spark实现ICF:https://zhuanlan.zhihu.com/p/413159725
问题:冷启动问题,长尾效应。
(3)向量召回
向量化召回:通过学习用户与物品低维向量化表征,将召回建模成向量空间内的近邻搜索问题,有效提升了召回的泛化能力与多样性,是推荐引擎的核心召回通道。
向量:万物皆可向量化,Embedding就是用一个低维稠密的向量表示一个对象(词语或者商品),主要作用是将稀疏向量转换成稠密向量(降维的效果),这里的表示蕴含着一定的深意,使其能够表达出对象的一部分特征,同时向量之间的距离反映对象之间的相似性。
向量召回步骤:离线训练生成向量,在线向量检索。
1.离线训练生成向量
word2vec:词向量的鼻祖,由三层神经网络:输入层,隐藏层,输出层,隐藏层没有激活函数,输出层用了softmax计算概率。
目标函数

网络结构:

总的来说:输入是词语的序列,经过模型训练可以得到每个词语对应的向量。应用在推荐领域就是输入是用户的点击序列,经过模型训练得到每个商品的向量。
优劣:简单高效,但是只考虑了行为序列,没有考虑其他特征。
双塔模型:
网络结构:分别称为User塔和物品塔;其中User塔接收用户侧特征作为输入比如用户id、性别、年龄、感兴趣的三级品类、用户点击序列、用户地址等;Item塔接受商品侧特征,比如商品id、类目id、价格、近三天订单量等。数据训练:(正样本数据,1)(负样本,0)正样本:点击的商品,负样本:全局随机商品样本(或者同批次其他用户点击样本)

优劣:高效,完美契合召回特性,在线请求得到用户向量,检索召回item向量,泛化性高;用户塔和item塔割裂,只在最后做了交互。
2.在线向量检索
向量检索:是一种基于向量空间模型(Vector Space Model)的信息检索方法,用于在大规模文本集合中快速查找与查询向量最相似的文档向量。在信息检索、推荐系统、文本分类中得到广泛应用。
向量检索的过程是计算向量之间的相似度,最后返回相似度较高的TopK向量返回,而向量相似度计算有多种方式。计算向量相似性得方式有欧式距离、内积、余弦距离。归一化后,内积与余弦相似度计算公式等价。
向量检索的本质是近似近邻搜索(ANNS),尽可能减小查询向量的搜索范围,从而提高查询速度。
目前在工业界被大规模用到的向量检索算法基本可以分为以下3类:
- 局部敏感性哈希(LSH)
- 基于图(HNSW)
- 基于乘积量化
简单介绍LSH
LSH算法的核心思想是:将原始数据空间中的两个相邻数据点通过相同的映射或投影变换后,这两个数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小。
相比于暴力搜索遍历数据集中的所有点,而使用哈希,我们首先找到查询样本落入在哪个桶中,如果空间的划分是在我们想要的相似性度量下进行分割的,则查询样本的最近邻将极有可能落在查询样本的桶中,如此我们只需要在当前的桶中遍历比较,而不用在所有的数据集中进行遍历。当哈希函数数目H取得太大,查询样本与其对应的最近邻落入同一个桶中的可能性会变得很微弱,针对这个问题,我们可以重复这个过程L次(每一次都是不同得哈希函数),从而增加最近邻的召回率。
案例:基于word2vec实现向量召回

2.4排序
推荐系统的掌上明珠
排序阶段分为粗排和精排,粗排一般出现在在召回结果的数据量级比较大的时候。
进化历程

简单介绍Wide&Deep
背景:手动特征组合实现记忆性效果不错但是特征工程太耗费人力,并且未曾出现的特征组合无法记忆,不能进行泛化。
目的:使模型同时兼顾泛化和记忆能力(有效的利用历史信息并具有强大的表达能力)
(1)记忆能力 模型直接学习并利用历史数据中物品或者特征共现频率的能力,记忆历史数据的分布特点,简单模型容易发现数据中对结果影响较大的特征或者组合特征,调整其权重实现对强特征的记忆
(2)泛化能力 模型传递特征的相关性,以及发掘稀疏或者从未出现过的稀有特征和最终标签相关性的能力,即使是非常稀疏的特征向量输入也能得到稳定平滑的推荐概率。提高泛化性的例子:矩阵分解,神经网络

兼顾记忆和泛化能力 (结果的准确性和扩展性) wide部分专注模型记忆,快速处理大量历史行为特征,deep部分专注模型泛化,探索新世界,模型传递特征的相关性,发掘稀疏甚至从外出现过的稀有特征与最终标签的相关性的能力,具有强大的表达能力。最终将wide部分和deep部分结合起来,形成统一的模型。
wide部分就是基础的线性模型,表示为y=W^T X+b X特征部分包括基础特征和交叉特征。交叉特征在wide部分很重要,可以捕捉到特征间的交互,起到添加非线性的作用。
deep部分为embeding层+三层神经网络(relu),前馈公式

联合训练

优劣:为推荐/广告/搜索排序算法之后的发展奠定了重要基础,从传统算法跨越到深度学习算法,里程碑意义。兼顾记忆和泛化能力但是Wide侧仍需要手工组合特征。
参考论文:Wide & Deep Learning for Recommender Systems
2.5 重排
定义:对精排后的结果顺序进行微调,一方面实现全局最优、一方面满足业务诉求提升用户体验。比如打散策略,强插策略,提高曝光,敏感过滤
MMR算法
实现商品多样性问题
目的:在推荐结果准确性的同时保证推荐结果的多样性,为了平衡推荐结果的多样性和相关性
算法原理,如公式
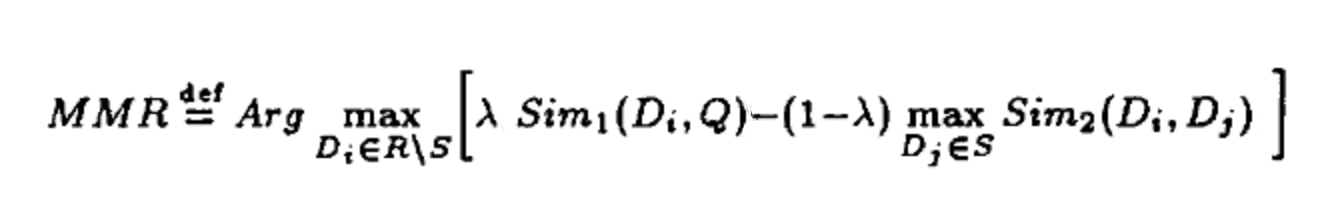
D:商品集合,Q:用户,S:已被选中的商品集合, R\S:R中未被选中的商品集合
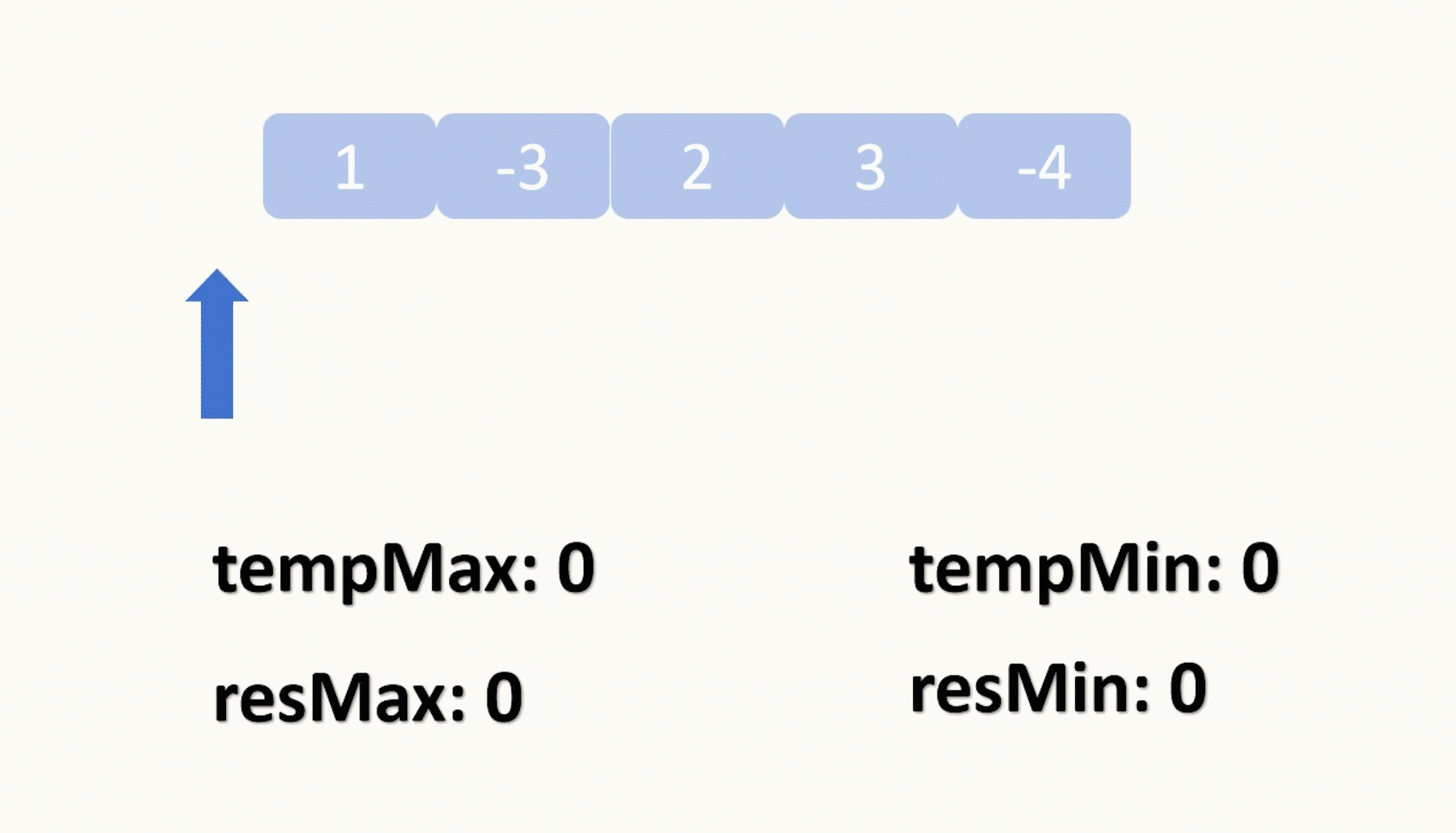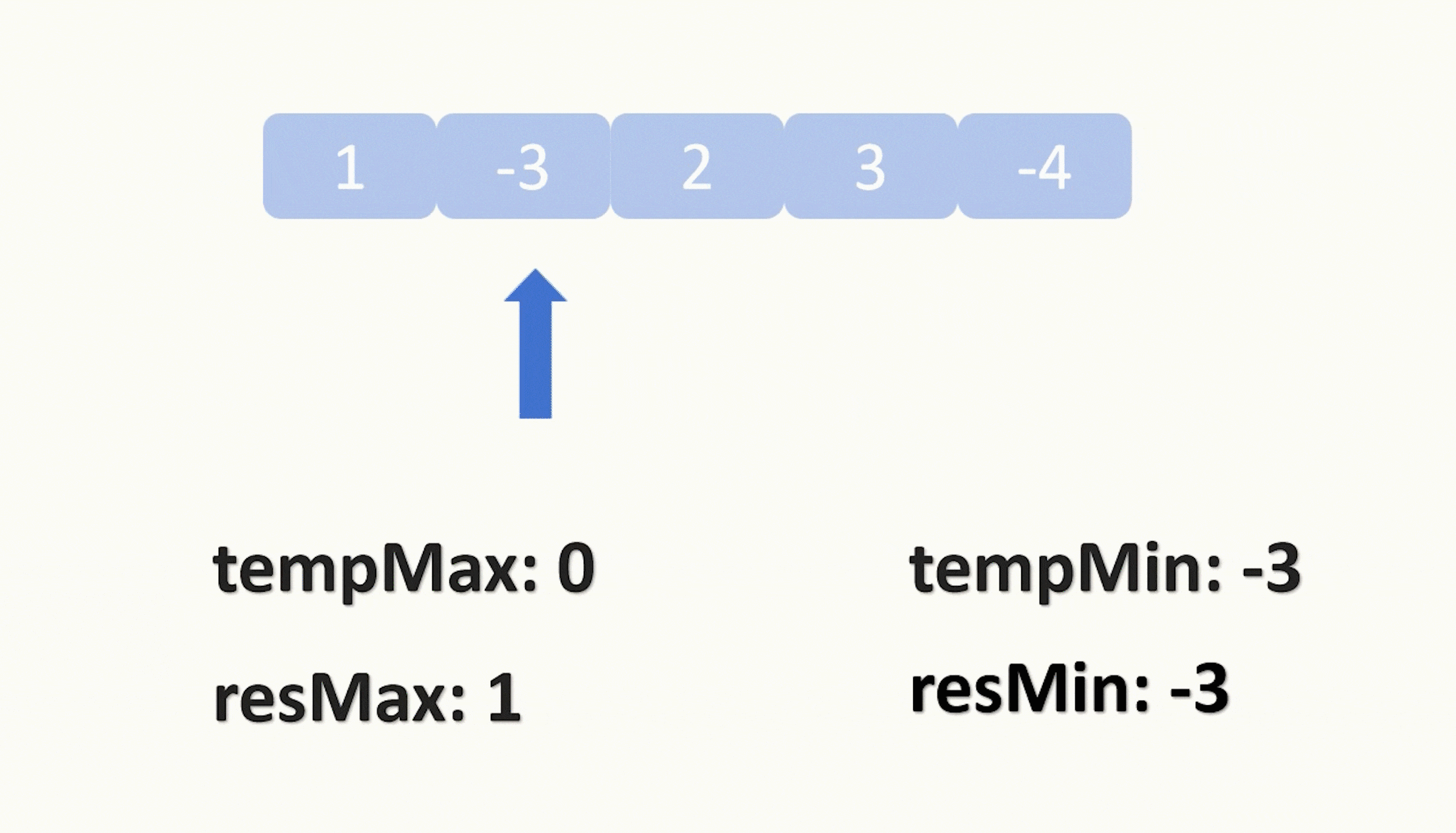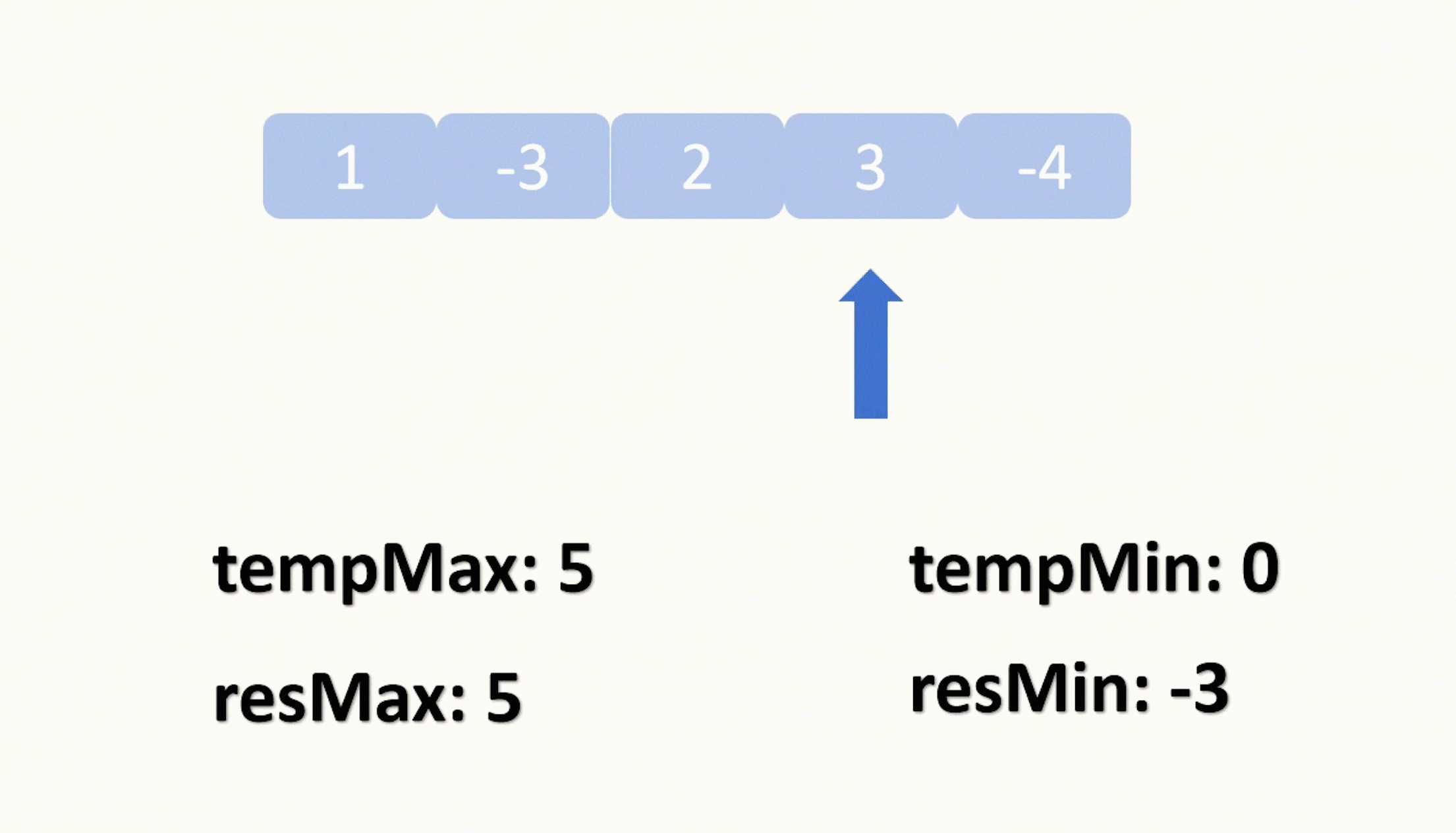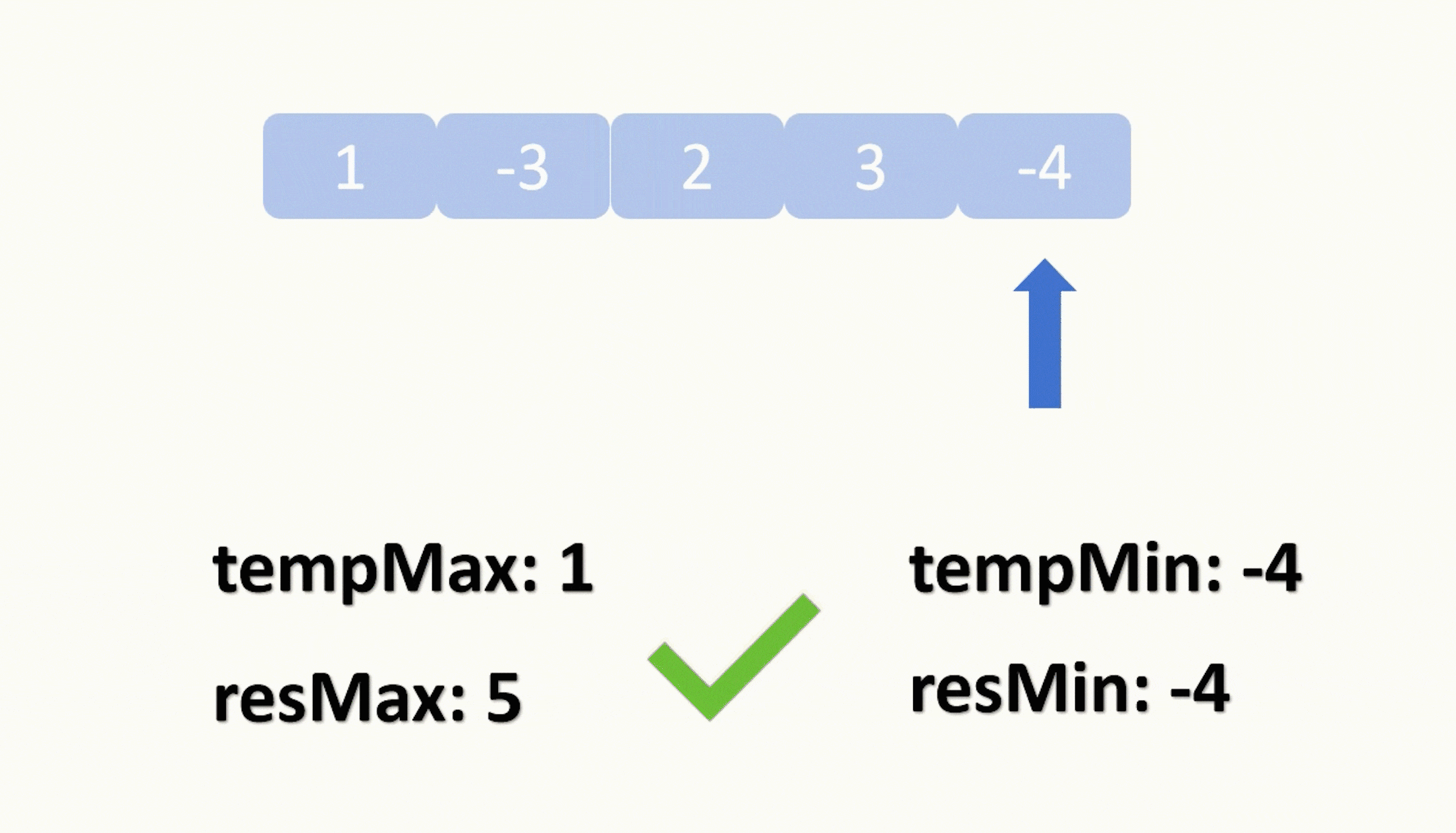
def MMR(itemScoreDict, similarityMatrix, lambdaConstant=0.5, topN=20):#s 排序后列表 r 候选项s, r = [], list(itemScoreDict.keys())while len(r) > 0:score = 0selectOne = None# 遍历所有剩余项for i in r:firstPart = itemScoreDict[i]# 计算候选项与"已选项目"集合的最大相似度secondPart = 0for j in s:sim2 = similarityMatrix[i][j]if sim2 > second_part:secondPart = sim2equationScore = lambdaConstant * (firstPart - (1 - lambdaConstant) * secondPart)if equationScore > score:score = equationScoreselectOne = iif selectOne == None:selectOne = i# 添加新的候选项到结果集r,同时从s中删除r.remove(selectOne)s.append(selectOne)return (s, s[:topN])[topN > len(s)]意义是选择一个与用户最相关的同时跟已选择物品最不相关的物品。时间复杂度O(n2) 可以通过限制选择的个数进行降低时间复杂度
工程实现:需要用户和物品的相关性和物品之间的相似性作为输入,用户和物品的相关性可以用排序模型的结果作为代替,物品之间的相似性可以通过协同过滤等算法得到商品向量,计算余弦距离。也可以简单得是否同一三级类目、同一店铺等表征
三、总结
就简单唠叨这么多啦,主要想让大家了解一下推荐系统,向大家介绍一下整个推荐架构,以及整个推荐都有哪些模块。由于本人水平有限,每个模块也没有讲的特别细,希望之后能在工作中继续学习这个领域,深挖细节,产出更好的东西呈现给大家。感谢!!!
作者:京东零售 闫先东
来源:京东云开发者社区
相关文章:
商品推荐系统浅析 | 京东云技术团队
一、综述 本文主要做推荐系统浅析,主要介绍推荐系统的定义,推荐系统的基础框架,简单介绍设计推荐的相关方法以及架构。适用于部分对推荐系统感兴趣的同学以及有相关基础的同学,本人水平有限,欢迎大家指正。 二、商品…...
【力扣每日一题】2023.8.8 任意子数组和的绝对值的最大值
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 题目给我们一个数组,让我们找出它的绝对值最大的子数组的和。 这边的子数组是要求连续的,让我们找出一个元素之和…...
SpringBoot Web开发静态资源处理
Web开发探究 简介 其实SpringBoot的东西用起来非常简单,因为SpringBoot最大的特点就是自动装配 使用SpringBoot的步骤: 1、创建一个SpringBoot应用,选择我们需要的模块,SpringBoot就会默认将我们的需要的模块自动配置好 2、手动…...
Dockerfile定制Tomcat镜像
Dockerfile中的打包命令 FROM : 以某个基础镜像作为此镜像的基础 RUN : RUN后面跟着linux常用命令,如RUN echo xxx >> xxx,注意,RUN 不能用于执行命令,因为每个RUN都是独立运行的,RUN 的cd对镜像中的…...
【计算机网络】概述及数据链路层
每一层只依赖于下一层所提供的服务,使得各层之间相互独立、灵活性好,已于实现和维护,并能促进标准化工作。 应用层:通过应用进程间的交互完成特定的网络应用,HTTP、FTP、DNS,应用层交互的数据单元被称为报…...

Java——基础语法(二)
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...

数据结构----算法--分治,快速幂
数据结构----算法–分治,快速幂 一.分治 1.分治的概念 分治法:分而治之 将一个问题拆解成若干个解决方式完全相同的问题 满足分治的四个条件 1.问题难度随着数据规模缩小而降低 2.问题可拆分 3.子问题间相互独立 4.子问题的解可合并 2.二分查找(折半搜索)…...

【ChatGPT 指令大全】怎么使用ChatGPT写履历和通过面试
目录 怎么使用ChatGPT写履历 寻求履历的反馈 为履历加上量化数据 把经历修精简 为不同公司客制化撰写履历 怎么使用ChatGPT通过面试 汇整面试题目 给予回馈 提供追问的问题 用 STAR 原则回答面试问题 感谢面试官的 email 总结 在职场竞争激烈的今天,写一…...

微服务:从header中获取用户存入当前线程
1、从网关gateway工程filter中解析token携带的当前用户信息并添加到header中 //获取token携带的idObject userid claimsBody.get("id");//在header中添加新的信息ServerHttpRequest serverHttpRequest request.mutate().headers(httpHeaders -> {httpHeaders.ad…...
C语言系列之原码、反码和补码
一.欢迎来到我的酒馆 讨论c语言中,原码、反码、补码。 目录 一.欢迎来到我的酒馆二.原码 二.原码 2.1在计算机中,所有数据都是以二进制存储的,但不是直接存储二进制数,而是存储二进制的补码。原码很好理解,就是对应的…...

程序框架——UI管理模块
UI基类BasePanel 负责帮助我们通过代码快速的找到所有的子控件,方便我们在子类中处理逻辑,节约找控件的工作量。 public class BasePanel : MonoBehaviour {//通过里式转换原则 来存储所有的控件private Dictionary<string, List<UIBehaviour>…...

MySQL 慢查询探究分析
目录 背景: mysql 整体结构: SQL查询语句执行过程是怎样的: 知道了mysql的整体架构,那么一条查询语句是怎么被执行的呢: 什么是索引: 建立索引越多越好吗: 如何发现慢查询࿱…...
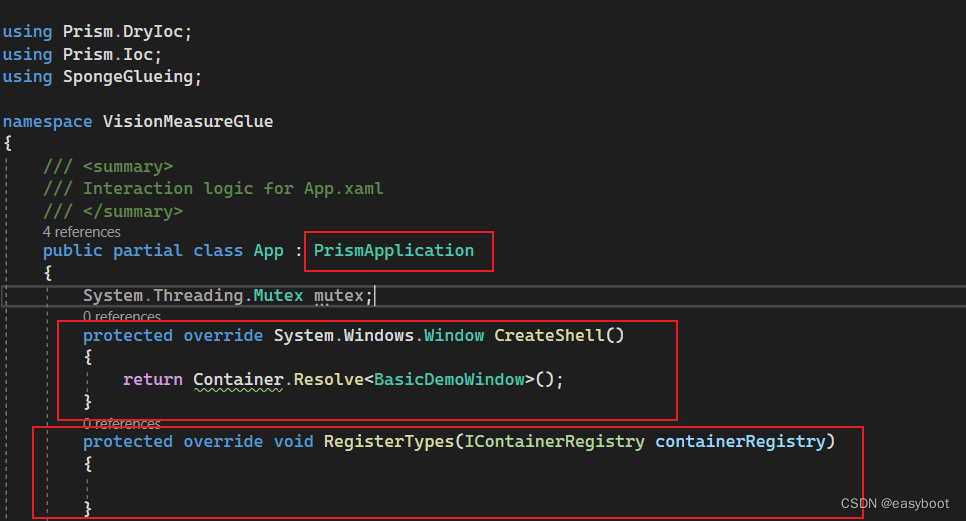
wpf 项目中使用 Prism + MaterialDesign
1.通过nuget安装MaterialDesign 2.通过nuget安装Prism 3.修改App.xmal <prism:PrismApplication x:Class"VisionMeasureGlue.App"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/…...

【Spring Boot】Thymeleaf模板引擎 — Thymeleaf页面布局
Thymeleaf页面布局 熟悉Thymeleaf的语法和表达式后,后面开发起来会更加得心应手。接下来好好研究一下Thymeleaf如何实现完整的Web系统页面布局。 1.引入代码片段 在模板中经常希望包含来自其他模板页面的内容,如页脚、页眉、菜单等。为了做到这一点&a…...

整理mongodb文档:删
个人博客 整理mongodb文档:删 求关注,哪儿不足,求大佬们指出,哪儿写的不够通俗易懂跟清晰,也求指出 文章概叙 本文主要是介绍了删除数据的几个方法,主要还是在介绍deleteMany、deleteOne以及remove,对于…...

篇二十三:设计模式的综合实例:构建完整项目
篇二十三:"设计模式的综合实例:构建完整项目" 开始本篇文章之前先推荐一个好用的学习工具,AIRIght,借助于AI助手工具,学习事半功倍。欢迎访问:http://airight.fun/。 另外有2本不错的关于设计模…...

FFmpeg常见命令行(三):FFmpeg转码
前言 在Android音视频开发中,网上知识点过于零碎,自学起来难度非常大,不过音视频大牛Jhuster提出了《Android 音视频从入门到提高 - 任务列表》。本文是Android音视频任务列表的其中一个, 对应的要学习的内容是:如何使…...

合宙Air724UG LuatOS-Air script lib API--scanCode
Table of Contents scanCode scanCode.request(cbFnc, timeout) scanCode 模块功能:扫码. 支持二维码、条形码扫描 scanCode.request(cbFnc, timeout) 设置扫码请求 参数 名称 传入值类型 释义 cbFnc function 扫码返回或者超时未返回的回调函数,回调…...
2023年新手如何学剪辑视频 想学视频剪辑如何入门
随着短视频、vlog等媒体形式的兴起,视频剪辑已经成为了热门技能。甚至有人说,不会修图可以,但不能不会剪视频。实际上,随着各种智能软件的发展,视频剪辑已经变得越来越简单。接下来,一起来看看新手如何学剪…...
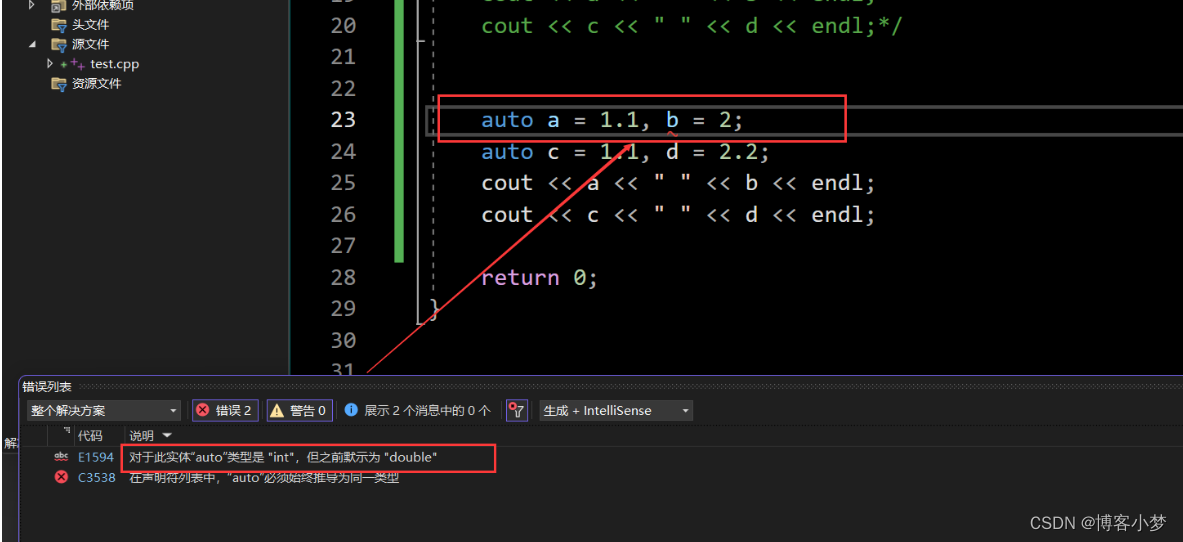
C++的auto究竟是何方神圣
C的auto究竟是何方神圣 前言🙌auto(C 11) 的使用细则auto是什么? auto声明的变量是在什么时期被编译器推导出来呢?为什么使用auto进行定义变量时,必须进行初始化? auto 的使用场景auto与指针和引…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...