(2023Arxiv)Meta-Transformer: A Unified Framework for Multimodal Learning
论文链接:https://arxiv.org/abs/2307.10802
代码链接:https://github.com/invictus717/MetaTransformer
项目主页:https://kxgong.github.io/meta_transformer/
【注】:根据实验结果来看,每次输入一种数据源进行处理,不是多模态同时处理。
整体图:
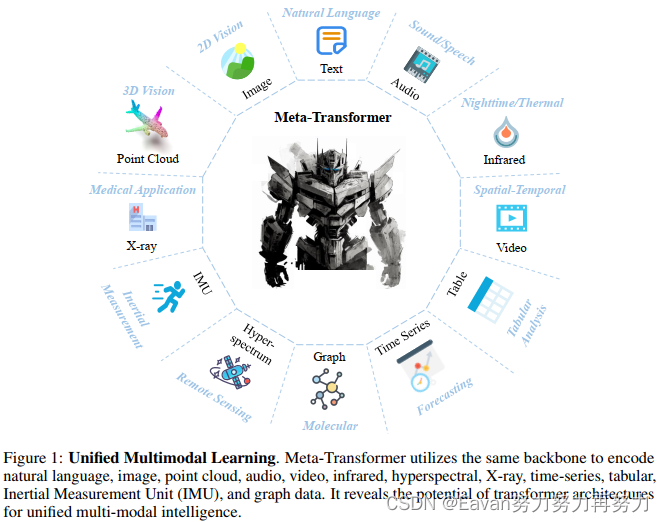
摘要:多模态学习旨在构建一个能处理来自多个模态相关信息的模型。尽管多模态领域已经有个多年的发展,但由于各个模态本质间的代沟,目前仍然面临设计一个能处理不同模态的统一网络的挑战,这些模态包括自然语言,2D图像,3D点云,音频,视频,时间序列,表格数据等。
本文提出了一个名为Meta-Transformer的框架,其利用冻结的编码器a frozen encoder进行多模态感知而不需要任何成对的多模态训练数据。在Meta-Transformer中,来自各个模态的原始输入数据被映射到a shared token space,让一个带有frozen parameters的解码器提取输入数据的高级语义特征。Meta-Transformer由3部分组成: a unified data tokenizer, a modality-shared encoder, task-spacific heads,是第一个用于执行具有不成对数据的12个模态的统一学习框架。
在不同benchmarks上的实验揭示Meta-Transformer能处理大量的任务,包括基础感知(text, image, point cloud, audio, video),实际应用(X-Ray, infrared, hyperspectral, IMU),和数据挖掘(graph, tabular, time-seris)。Meta Transformer预示着用Transformer开发统一的多模态智能的前景。
1. Intruduction
【多源知识介绍以及本文动机】人类大脑被认为是神经网络模型的灵感来源,它同时处理来自各种感官输入的信息,例如视觉、听觉和触觉信号。此外,来自一个源的知识可以很好地帮助对另一个源的知识的理解。然而,在深度学习中,由于模态差距很大,设计一个能够处理各种数据格式的统一网络是一项艰巨的任务。
【每种模态的特点,现有多模态统一框架介绍】每种数据模态都呈现独特的数据模式,这使得很难将在一种模态上训练的模型适应于另一种模态。 例如,图像由于密集的像素而表现出高度的信息冗余,而自然语言则不然 。 另一方面,点云在 3D 空间中分布稀疏,这使得它们更容易受到噪声的影响并且难以表示。 音频频谱图由跨频域的波组合组成,是时变且非平稳的数据模式。 视频数据包含一系列图像帧,这使其具有捕获空间信息和时间动态的独特能力。图数据将实体表示为图中的节点,将关系表示为图中的边,对实体之间复杂的多对多关系进行建模。由于各种数据模态固有的显着差异,通常的做法是利用不同的网络架构对每种模态进行单独编码。 例如,Point Transformer利用向量级位置注意力从 3D 坐标中提取结构信息,但它无法对图像、自然语言段落或音频频谱图切片进行编码。 因此,设计一个能够利用模态共享参数空间modality-share parameter space来编码多种数据模态的统一框架仍然是一个重大挑战。 最近,VLMO、OFA和 BEiT-3等统一框架的发展,通过对成对数据进行大规模多模态预训练,提高了网络多模态理解的能力,但他们更关注视觉和语言,并且无法跨模态共享整个编码器。
【由Transformer引出动机】Vaswani 等人于2017年提出Transformer 架构和注意力机制用于自然语言处理(NLP),其已经在在深度学习领域取得了显着的进步。 这些进步有助于增强不同模式的感知,例如 2D 视觉(包括 ViT和 Swin Transformer)、3D 视觉(例如 Point Transformer和 Point-ViT)和音频信号处理( AST)等。这些工作展示了基于 Transformer 的架构的多功能性,启发研究人员探索是否有可能开发能够统一多种模态的基础模型,最终在所有模态上实现人类水平的感知理解。
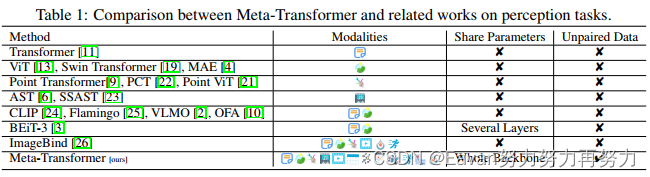
【本文做法】本文探索了transformer架构处理12种模态的潜能,包括(图像、自然语言、点云、音频频谱图、视频、红外、高光谱、X 射线、 IMU、表格、图表和时间序列数据),如图1所示。我们讨论了transformer用于每种模型的学习过程并将其统一到一个框架中。接下来,我们提出了一个统一的框架Meta-Transformer用于多模态学习,其是第一个使用同一组参数同时对来自十几种模态的数据进行编码的框架,可以采用更具凝聚力的方法进行多模态学习(如表 1 所示)。Meta-Transformer包括3个简单但有效的元素:
- a modality-specialist for data-to-sequence tokenization
- a modality-shared encoder for extracting representations across modalities
- task-specific heads for downstream tasks
具体地,Meta-Transformer先将多模态数据转换为贡献一个公共折叠空间的token sequences;然后,a modality-shared encoder with frozen parammeters提取表达,其仅更新下游任务头和轻量级tokenizers的参数来进一步适应各个任务。 最后,可以通过这个简单的框架有效地学习特定任务和通用模态表示。
【实验情况】本文在12种模态的各种benchmarks上进行了大量实验,通过专门利用 LAION-2B数据集的图像进行预训练,Meta-Transformer 在处理来自多种模式的数据方面表现出了卓越的性能,在不同的多模式学习任务中始终取得优于最先进方法的结果。
【本文贡献】
- 对于多模态研究,我们提出了一种新颖的框架,Meta-Transformer,它使统一编码器能够使用同一组参数同时从多种模态中提取表示;
- 对于多模态网络设计,我们全面检查了transformer成分的功能,例如embeddings、tokenization和encoders在处理各种模态时的功能。 Meta-Transformer 提供了宝贵的见解,并在开发能够统一所有模态的模态不可知框架方面激发了有希望的新方向;
- 在实验上,Meta-Transformer 在 12 种模态的各种数据集上取得了出色的性能,这验证了 Meta-Transformer 在统一多模态学习方面的进一步潜力。
2. Related Work
2.1 Single-Modality Perception
各种神经网络的发展促进了机器智能的感知。
MLP用于模式识别。最初,SVM和MLP被应用于文本,图像,点元和视频分类。这些创新工作证明了将人工智能引入模式识别的可行性。
循环&卷积神经网。Hopfield网络是循环网络的原始形式,LSTM和GRU进一步探索了RNN在序列建模的优势并应用于NLP任务中,其也被广泛地用于音频分析。同时,包括LeNet, AlexNet, VGG, GoogleNet, ResNet等CNN在图像识别中的成功很大程度地激发了其在其他领域地应用,比如文本分类,点云理解,语音分类。
Transformer。最近,Transformer架构已被应用于各种任务中,例如NLP中的文本理解和生成,图像中的分类、检测和分割,点云理解和音频识别。
然而,与 CNN 和 RNN 的应用类似,这些网络根据模态的不同属性进行修改。 模态不可知的学习modality-agnostic learning没有通用的架构。 更重要的是,来自不同模态的信息可以互补,设计一个可以对来自不同模态的数据进行编码并通过共享参数空间桥接这些复杂表示的框架非常重要。
2.2 Transformed-based Multimodal Perception
Transformer用于感知问题的优势在于全局感受野和相似性建模,这显着促进了多模态感知的发展。 MCAN提出了视觉和语言之间的深度模块化共同注意网络,通过简洁地最大化交叉注意来执行跨模态对齐,然后利用交叉注意力机制来桥接不同的模式。随着 pretrain finetune 范式的成功,更多的工作开始关注如何有效地对齐抽取自各模态的表达。 VL-BERT开创了使用 MLM 范式实现通用视觉语言理解的模态对齐表示。 然后 Oscar描述了视觉和纹理内容中的对象语义。 Vinvl 、Simvlm、VLMO、ALBEF和 Florence等框架进一步探索了跨视觉语言模态的联合表示在语义一致性方面的优势。
多模态模型还用于few-shot学习、序列到序列学习、对比学习。 BEiT-v3提出将图像作为外语,采用更细粒度的跨模态掩模和重建过程,共享部分参数。 MoMo进一步探索了训练策略和目标函数,同时对图像和文本使用相同的编码器。
尽管取得了这些进步,但由于模式之间的差异,设计统一的多模式网络仍然存在重大障碍。 此外,该领域的大多数研究都集中在视觉和语言任务上,可能不会直接解决 3D 点云理解、音频识别或其他模式等挑战。 Flamingo 模型代表了一种强大的few-shot学习器,但其向点云的可迁移性有限,并且利用一种模态的先验知识使其他模态受益仍然是一个挑战。 另一方面,现有的多模式方法尽管花费了昂贵的培训成本,但在更多模式上的可扩展性有限。 解决这些差异取决于使用同一组参数桥接不同的模式,类似于桥梁如何连接多个河岸。
3. Meta-Transformer
在本节中,我们将详细描述所提出的框架 Meta-Transformer。Meta-Transformer 统一了处理来自不同模态的数据的多个pipelines,并通过共享编码器实现文本、图像、点云、音频和其他 8 种模态的编码。 为了实现这一目标,Meta-Transformer由a modality-specialist for data-to-sequence tokenization,a modality-shared encoder for extracting representations across modalities,task-specific heads for downstream tasks组成。
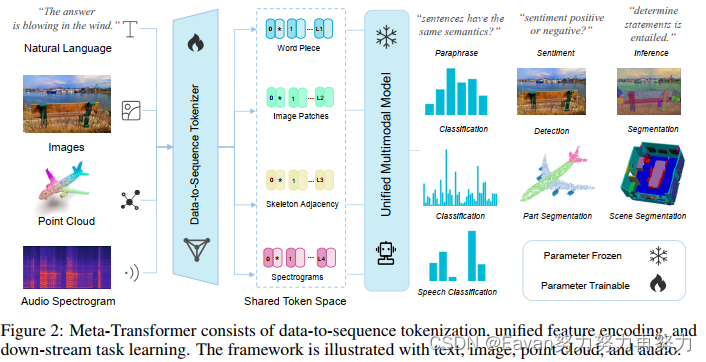
3.1 Preliminary

3.2 Data-to-Sequence Tokenization
我们提出了一种新颖的meta-tokenization scheme,旨在将各种模式的数据转换为token embeddings,所有的token embeddings都在一个共享的流形空间内。 然后,考虑到模态的实际特点,将该方法应用于tokenization,如图 3 所示。我们以文本、图像、点云和音频为例。
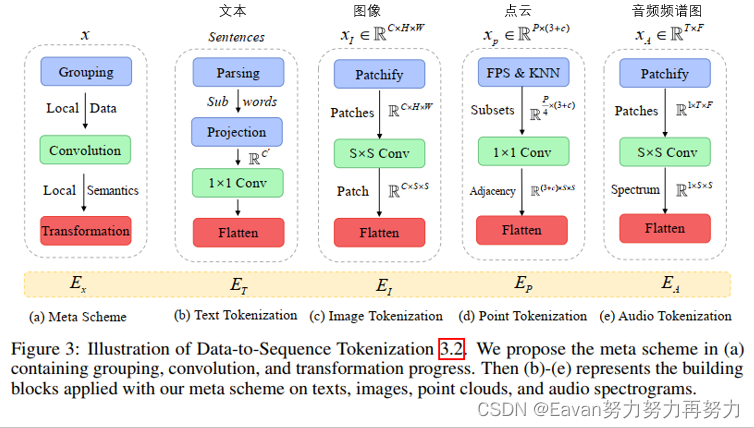

3.3 Unified Encoder
将原始输入转换为a token embedding sapce后,我们利用具有冻结参数的a unifired transformer encoder对来自不同模态的token embeddings进行编码。
预训练。 我们利用 ViT作为主干网络,并通过对比学习在 LAION-2B 数据集上对其进行预训练,这增强了generic token encoding的能力。 预训练后,我们冻结主干网络的参数。 此外,为了文本理解,我们利用 CLIP的预训练文本标记器将句子分割为子词并将子词转换为词嵌入。
模态不可知的学习。 按照常见做法,我们将a learnable token 添加到the sequence of token embeddings中,并且
token的最终隐藏状态 (
) 作为输入序列的summary representation,通常用于执行识别任务。为了强化位置信息,我们将position embeddings合并到token embeddings中。 回想一下,我们将输入数据标记为一维嵌入,因此,我们选择标准的learnable 1D position embeddings。 此外,我们没有观察到在图像识别中使用更复杂的 2D 感知位置嵌入可以带来显着的性能提升。 我们简单地通过逐元素加法操作融合位置嵌入和内容嵌入,然后将生成的嵌入序列输入编码器。
深度为 L 的 Transformer 编码器包含多个堆叠的多头自注意力 (MSA) 层和 MLP 块。input token embeddings首先被送到 MSA 层,然后是 MLP 块。 然后第(ℓ−1)个MLP块的输出作为第ℓ个MSA层的输入。 在每层之前附加层归一化(LN),并在每层之后应用残差连接。 MLP 包含两个线性 FC 层以及一个 GELU 非线性激活层。 transformer的公式为:
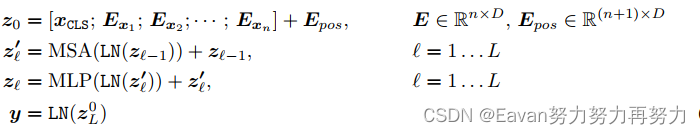
其中 E_x 表示来自提出的tokenizer的token embeddings,n表示tokens的数量。 我们使用位置嵌入E_{pos}来增强patch embeddings和learnable embedding。
3.4 Task-Specific Heads
获得learning representations后,我们将representations提供给特定于任务的头h,它主要由 MLP 组成,并且因模式和任务而异。 Meta-Transformer的学习目标可以概括为:
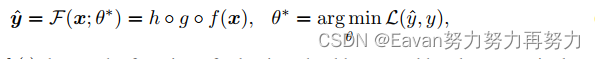
其中,分别定义了tokenizer, backbone, heads的函数。
4. Experiments
在本节中,我们对 12 种模式中的每一种进行实验。 我们展示了 Meta-Transformer 在多模式感知方面的潜力。 我们的实验设计总结如表 2 所示。

网络设置:遵循ViT的默认设置。 Meta-Transformer-B16F 表示带有base-scale encoder的Meta-Transformer,包含 12 个transformer blocks和 12 个注意力头,图像块大小为 16。对于base-scale encoder,嵌入维度为 768,输出维度为 MLP 为 3,072。 “F”和“T”分别表示编码器的参数被冻结和进一步调整。
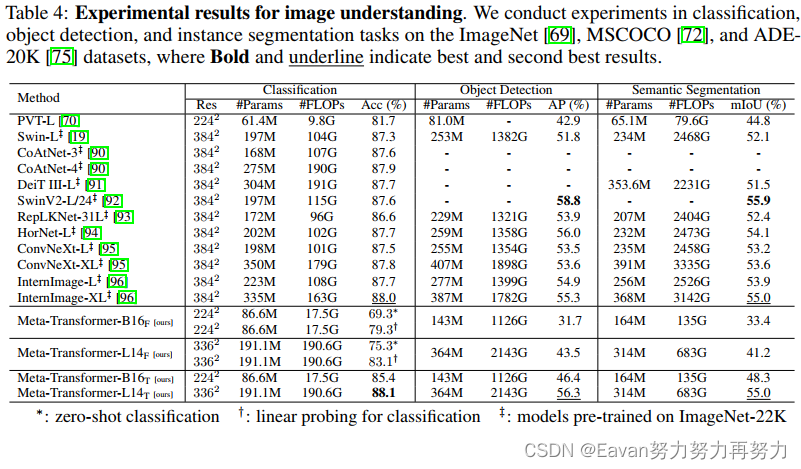
在图像理解上的实验结果:
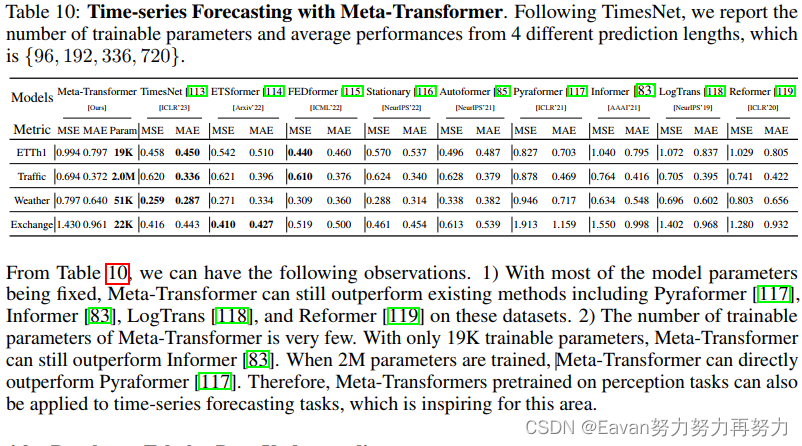
在时间序列预测的实验结果:
在其他问题的实验结果:略。
5. Limitation
Meta-Transformer的相关讨论如下:
复杂度:Meta-Transformer 需要 O(n2 × D) 计算来处理token embeddings [E1, · · ·, En]。 内存成本高、计算负担重,难以扩展。
方法:与 TimeSformer和 Graphormer中的Axial Attention mechanism相比,Meta-Transformer 缺乏时间和结构意识。这种限制可能会影响 Meta-Transformer 在时间和结构建模发挥关键作用的任务中的整体性能,例如视频理解、视觉跟踪或社交网络预测。
应用:Meta-Transformer主要发挥其在多模态感知方面的优势。它的跨模式生成能力仍然未知。 未来我们将致力于这方面的工作。
相关文章:
(2023Arxiv)Meta-Transformer: A Unified Framework for Multimodal Learning
论文链接:https://arxiv.org/abs/2307.10802 代码链接:https://github.com/invictus717/MetaTransformer 项目主页:https://kxgong.github.io/meta_transformer/ 【注】:根据实验结果来看,每次输入一种数据源进行处…...

解决Python读取图片路径存在转义字符
普遍解决路径中存在转义字符的问题的方法 普遍解决转义字符的问题,无非是以下这三种。 一、在路径前添加r 直接在路径前面加r,这种方法能够使字符保持原始的意思。 比如下面这种: pathr"D:\MindSpore\Dearui\source\ces\0AI.png&qu…...
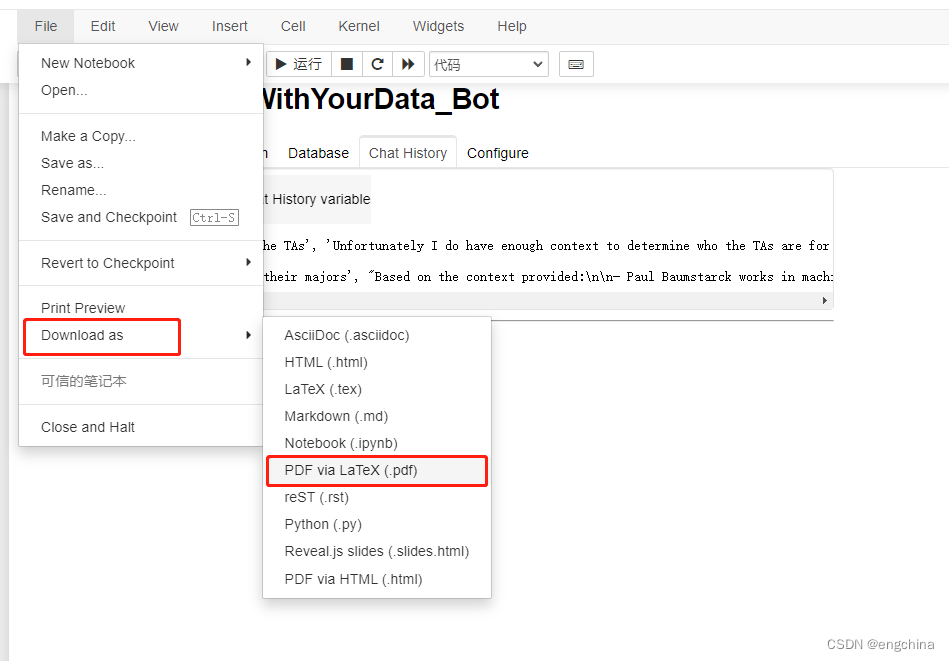
Windows 安装 pandoc 将 jupyter 导出 pdf 文件
Windows 安装 pandoc 将 jupyter 导出 pdf 文件 1. 下载 pandoc 安装文件2. 安装 pandoc3. 安装 nbconvert4. 使用 pandoc 1. 下载 pandoc 安装文件 访问 https://github.com/jgm/pandoc/releases,下载最新版安装文件,例如,3.1.6.1 版&#…...
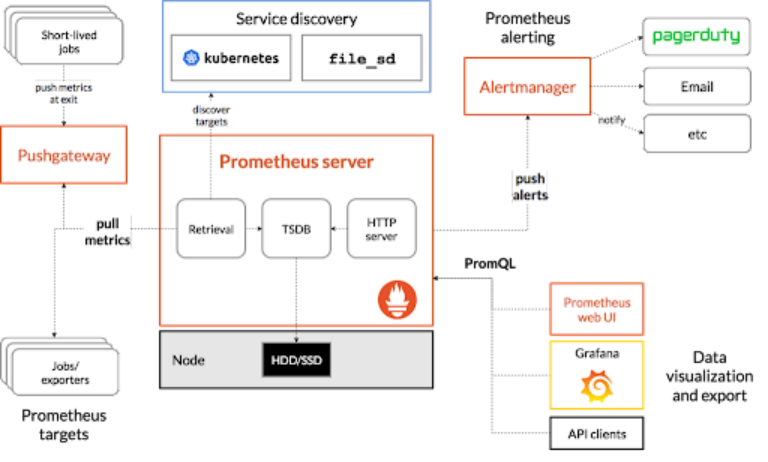
混合云环境实现K8S可观测的6大策略
2023年,原生云应用及平台发展迅猛。大量企业都在努力发挥其应用程序的最大潜力,以确保极致的用户体验并推动业务增长。 混合云环境的兴起和容器化技术(如Kubernetes)的采用彻底改变了现代应用程序的开发、部署和扩展方式。 在这个数字舞台上,…...

音视频 FFmpeg命令行搭建
文章目录 一、配置二、测试 一、配置 以FFmpeg4.2.1 win32为例 解压ffmpeg-4.2.1-win32-shared.zip 拷⻉可执⾏⽂件到C:\Windows拷⻉动态链接库到C:\Windows\SysWOW64 注:WoW64 (Windows On Windows64)是⼀个Windows操作系统的⼦系统,被设计⽤来处理许…...

ORACLE wallet实现无需输入用户名与密码登陆数据库 注意修改目录权限
wallet权限 linux 777 windows 需要修改.lck文件的owner 在ORACLE 10G前,我们在SHELL或JDBC中连接数据库时,都需要输入用户名与密码,并且都是明文。从1OGR2开始,ORACLE提供wallet这个工具,可以实现无需输入用户名与密…...

linux - 用户权限
认知root用户 无论是Windows、Macos、Linux均采用多用户的管理模式进行权限管理 在Linux系统中,拥有最大权限的账户名为: root(超级管理员) root用户拥有最大的系统操作权限,而普通用户在许多地方的权限是受限的。普通用户的权限,一般在其HOME目录内是不…...
计蒜客T1115——字符串判等
水题不解释,考研复习压力偶尔写一道换换心情还不错~ 这里有一个比较有趣的知识点,对于同时输入多个字符串时还要允许空格的输入,那么普通的cin函数就不能满足要求了,这里采用getline函数解决,如下: string …...

Android Framework工具——EA画图
EA 是一个著名的企业架构(Enterprise Architecture)工具,用于绘制和管理企业的架构图和过程模型。该工具提供了多种功能,包括建立业务流程图、数据流图、组织结构图、应用架构图等。EA工具可帮助企业进行战略规划、业务流程改进和系统开发等活动。 一、时序图 时序图(Seq…...
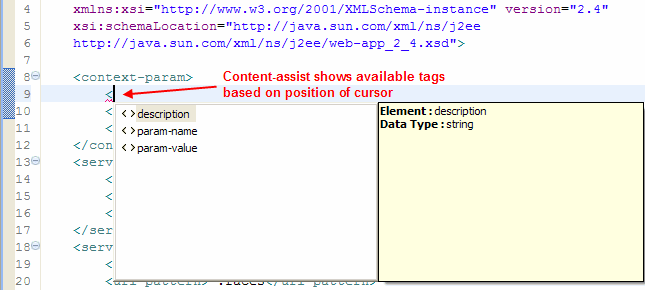
使用MyEclipse如何部署Descriptor (XML)编辑器?
Descriptor (XML) Editor编辑器包含了高级的XML编辑功能,在本文中您将了解到这些编辑功能、Web XML编辑等,此功能包含在MyEclipse中可用。 MyEclipse v2023.1.2离线版下载 1. Web XML 编辑器 MyEclipse Web XML编辑器包括高级XML编辑功能,…...

Codeforces Round 889 (Div. 2)C题题解
文章目录 [Dual (Hard Version)](https://codeforces.com/contest/1855/problem/C2)问题建模问题分析1.按元素值分类讨论,正负不同时存在时2.若正负同时存在时代码 Dual (Hard Version) 问题建模 给定n个数,n不超过20,且每个数ai,…...

无涯教程-Perl - Subroutines(子例程)
定义子程序 Perl编程语言中 Subroutine子程序定义的一般形式如下: sub subroutine_name {body of the subroutine } 调用该Perl Subroutine的典型方式如下- subroutine_name( list of arguments ); 在Perl 5.0之前的版本中,调用 Subroutine的语法略有不同&…...
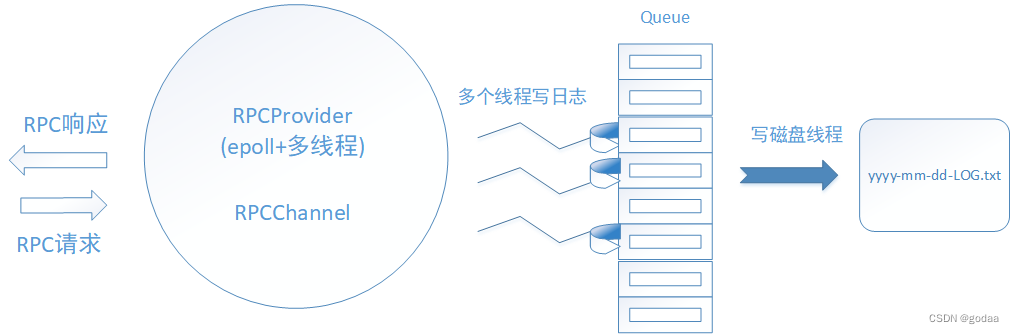
Rpc异步日志模块
Rpc异步日志模块作用 在一个大型分布式系统中,任何部署的分布式节点都可能发生崩溃,试想如果用普通的办法,即先排查哪个节点down掉了,找到down掉的节点后采取调试工具gdb调试该节点,进而排查宕机的原因。这中排查方法…...

python-pip
pip 路径 python 下载后自带pip ,在scripts 下,如 D:\install\python\Scripts numpy pip3 install numpy scipy matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simplepandas D:\install\python\Scripts>pip3 install pandas -i https://pypi.tuna.tsingh…...
无涯教程-Perl - getppid函数
描述 该函数返回父进程的进程ID。 语法 以下是此函数的简单语法- getppid返回值 该函数返回父进程的进程ID。 例 以下是显示其基本用法的示例代码- #!/usr/bin/perl$ppidgetppid();print "Parent Process ID $ppid\n";执行上述代码后,将产生以下输出- Paren…...
1.2 汽车电子控制系统的基本构成)
AUTOSAR规范与ECU软件开发(基础篇)1.2 汽车电子控制系统的基本构成
目录 前言 1、 传感器 2、 电子控制单元(ECU) 3、 执行器 前言 汽车电子控制系统主要由传感器(Sensor) 、 电子控制单元(Electronic Control Unit, ECU) 和执行器(Actuator) 组成(图1.1) ,对被控对象(Controlled Object)...
)
一个可以通过多个条件筛选的系统界面是如何实现的(springboot+mybatis)
比如我们有一个订单记录管理界面 条件可以通过订单号、商品名称、创建日期范围、价格范围。。。来进行筛选查询。 首先我们先确定数据库订单表(我这里就不做连表了,都放在一个表中)模拟一个订单表 order表 订单号商品名称创建日期价格地址…...
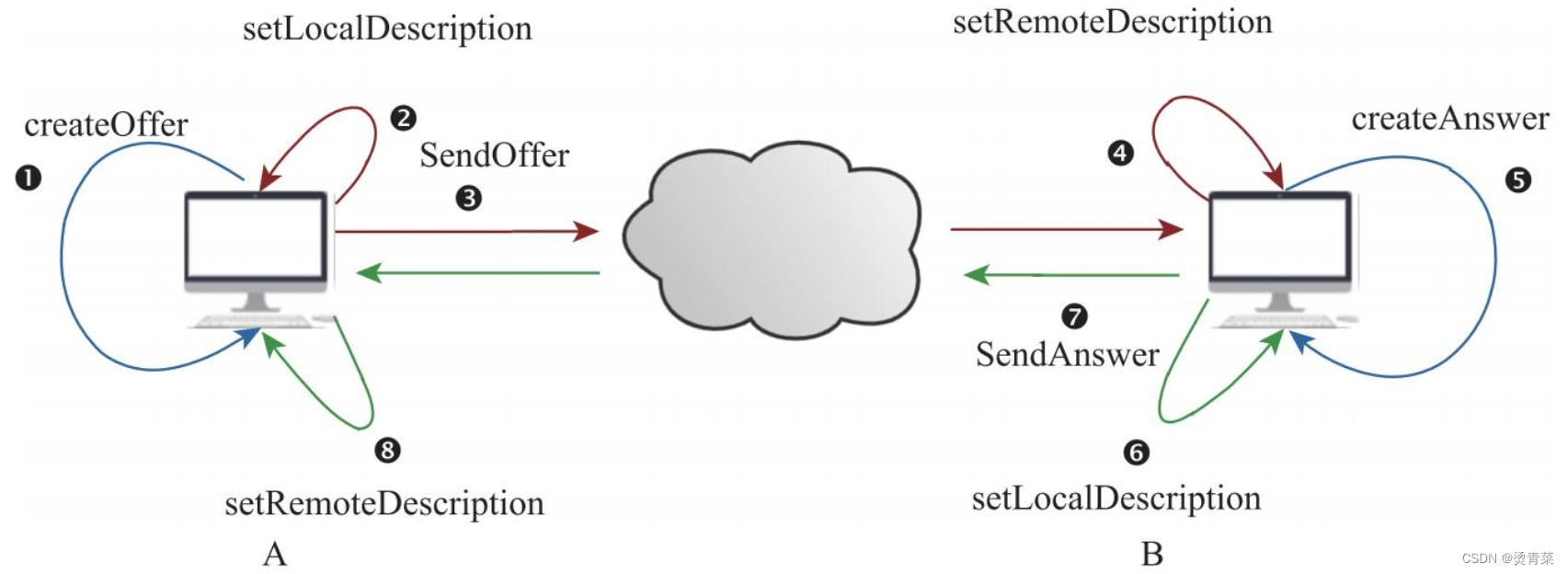
WebRTC | 实现数据流的一对一通信
目录 一、浏览器对WebRTC的支持 二、MediaStream与MediaStreamTrack 三、RTCPeerConnection 1. RTCPeerConnection与本地音视频数据绑定 2. 媒体协商SDP 3. ICE (1)Candidate信息 (2)WebRTC收集Candidate (3&…...
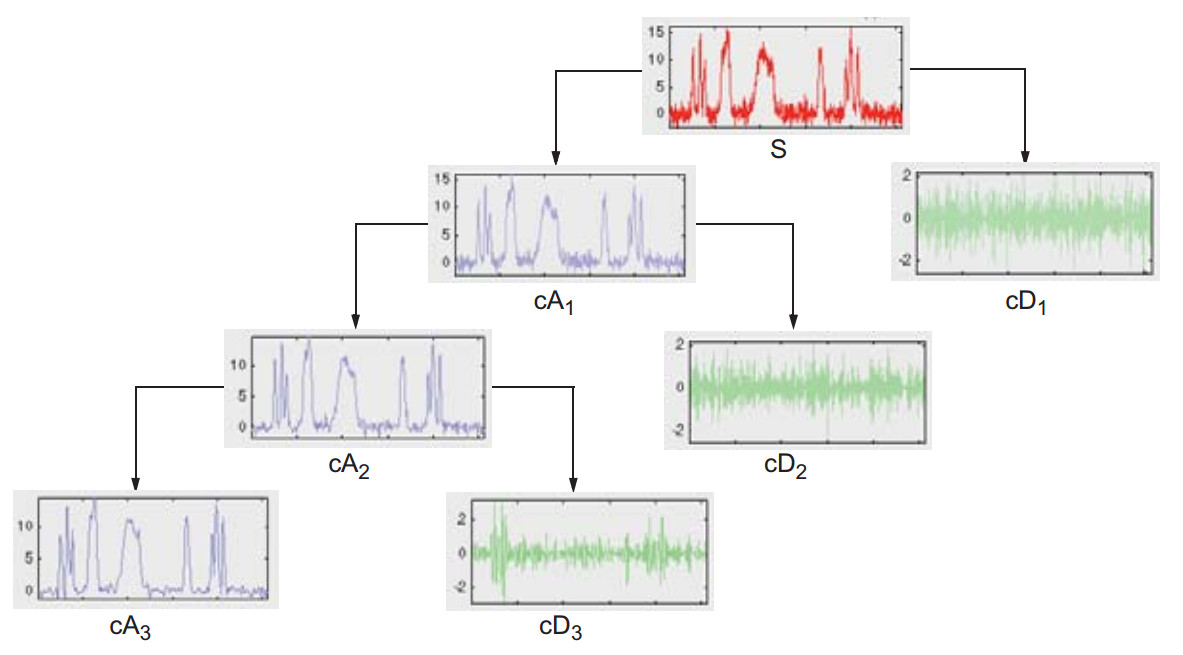
基于MATLAB小波变换的信号突变点检测
之前在不经意间也有接触过求突变点的问题。在我看来,与其说是求突变点,不如说是我们常常玩的"找不同"。给你两幅图像,让你找出两个图像中不同的地方,我认为这其实也是找突变点在生活中的应用之一吧。回到找突变点位置上…...
JUC并发编程(JUC核心类、TimeUnit类、原子操作类、CASAQS)附带相关面试题
目录 1.JUC并发编程的核心类 2.TimeUnit(时间单元) 3.原子操作类 4.CAS 、AQS机制 1.JUC并发编程的核心类 虽然java中的多线程有效的提升了程序的效率,但是也引发了一系列可能发生的问题,比如死锁,公平性、资源管理…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...

【HarmonyOS 5】鸿蒙中Stage模型与FA模型详解
一、前言 在HarmonyOS 5的应用开发模型中,featureAbility是旧版FA模型(Feature Ability)的用法,Stage模型已采用全新的应用架构,推荐使用组件化的上下文获取方式,而非依赖featureAbility。 FA大概是API7之…...