Spark12: SparkSQL入门
一、SparkSQL
Spark SQL和我们之前讲Hive的时候说的hive on spark是不一样的。hive on spark是表示把底层的mapreduce引擎替换为spark引擎。而Spark SQL是Spark自己实现的一套SQL处理引擎。Spark SQL是Spark中的一个模块,主要用于进行结构化数据的处理。它提供的最核心的编程抽象,就是DataFrame。
DataFrame=RDD+Schema 。
它其实和关系型数据库中的表非常类似,RDD可以认为是表中的数据,Schema是表结构信息。DataFrame可以通过很多来源进行构建,包括:结构化的数据文件,Hive中的表,外部的关系型数据库,以及RDD
注意:
Spark1.3出现的 DataFrame ,Spark1.6出现了 DataSet ,在Spark2.0中两者统一,DataFrame等于DataSet[Row]
二、SparkSession
要使用Spark SQL,首先需要创建一个SpakSession对象。SparkSession中包含了SparkContext和SqlContext,所以说想通过SparkSession来操作RDD的话需要先通过它来获取SparkContext 这个SqlContext是使用sparkSQL操作hive的时候会用到的。
SparkSession包含了SparkContext和SqlContext
(1)SparkContext 用于操作RDD
(2)SqlContext 用于操作hive
正常使用SparkSession操作DataFrame就可以了
三、创建DataFrame
使用SparkSession,可以从RDD、HIve表或者其它数据源创建DataFrame
那下面我们来使用JSON文件来创建一个DataFrame
1. 引用依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.4.3</version>
<!-- <scope>provided</scope>--></dependency>2. Scala代码
package com.sanqian.scala.sqlimport org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSessionobject SqlDemoScala {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local")//创建SparkSession对象,里面包含SparkContext和SqlContextval sparkSession = SparkSession.builder().appName("SqlDemoScala").config(conf).getOrCreate()//读取json文件, 创建DataFrameval df = sparkSession.read.json("D:\\data\\spark\\student.json")//查DataFrame中的数据df.show()sparkSession.stop()}
}
3. Java代码
package com.sanqian.java.sql;import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;public class SqlDemoJava {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setMaster("local");//创建SparkSession对象,里面包含SparkContext和SqlContextSparkSession sparkSession = SparkSession.builder().appName("SqlDemoJava").config(conf).getOrCreate();//读取json文件,获取DataSet<Row>Dataset<Row> df = sparkSession.read().json("D:\\data\\spark\\student.json");df.show();sparkSession.stop();}
}
4. DataFrame 和DataSet的转换
由于DataFrame等于DataSet[Row],它们两个可以互相转换,所以创建哪个都是一样的。咱们前面的scala代码默认创建的是DataFrame,java代码默认创建的是DataSet。
尝试对他们进行转换
1)在Scala代码中将DataFrame转换为DataSet[Row],对后面的操作没有影响
//将DataFrame转换为DataSet[Row]
val stuDf = sparkSession.read.json("D:\\student.json").as("stu")2)在Java代码中将DataSet[Row]转换为DataFrame
//将Dataset<Row>转换为DataFrame
Dataset<Row> stuDf = sparkSession.read().json("D:\\student.json").toDF();四、DataFrame常见算子操作
1. 官方文档

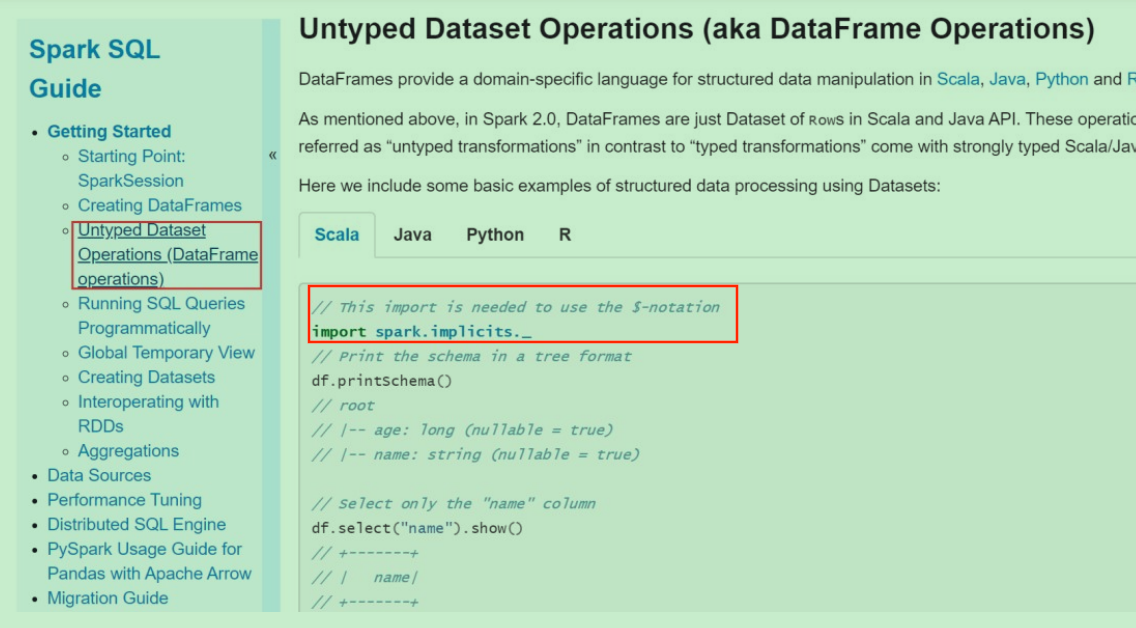
2. DataFrame算子
• printSchema() : 打印schema信息
• show() :默认显示所有的数据,可以通过参数控制显示多少条
• select() : 查询数据中指定字段信息,在使用$对数据做一些操作,需要添加隐式转换函数,否则语法报错
• filter()、where() :对数据进行 过滤,where底层调用的就是filter
• groupBy() : 对数据进行分组求和
• count() : 求和
注意:在使用$对数据做一些操作,需要添加隐式转换函数,否则语法报错
import sparkSession.implicits._
Scala代码
package com.sanqian.scala.sqlimport org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSessionobject DataFrameOpScala {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setMaster("local")val sparkSession = SparkSession.builder().appName("DataFrameOpScala").config(conf).getOrCreate()val df = sparkSession.read.json("D:\\data\\spark\\student.json")//打印schema信息df.printSchema()//默认显示所有数据,可以通过参数控制显示多少条df.show(2)//查询数据中的指定字段信息df.select("name", "age").show()//在使用select的时候可以对数据做一些操作,需要添加隐式转换函数,否则语法报错import sparkSession.implicits._df.select($"name", $"age" + 1).show()df.filter($"age" > 18).show()//对数据进行分组求和df.groupBy("age").count().show()sparkSession.stop()}
}
Java代码
package com.sanqian.java.sql;import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import static org.apache.spark.sql.functions.col;public class DataFrameOpJava {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setMaster("local");//创建SparkSession对象,里面包含SparkContext和SqlContextSparkSession sparkSession = SparkSession.builder().appName("DataFrameOpJava").config(conf).getOrCreate();Dataset<Row> ds = sparkSession.read().json("D:\\data\\spark\\student.json");//打印schema信息ds.printSchema();ds.show(2);ds.select("name", "age").show();//在select的时候可以对数据做一些操作,需要引入import static org.apache.spark.sql.functions.col;ds.select(col("name"), col("age").plus(1)).show();//对数据进行过滤ds.filter(col("age").gt(18)).show();ds.where(col("age").gt(18)).show();//对数据进行分组求和ds.groupBy("age").count().show();sparkSession.stop();}
}
这些就是针对DataFrame的一些常见的操作。但是现在这种方式其实用起来还是不方便,只是提供了一些类似于可以操作表的算子,很对一些简单的查询还是可以的,但是针对一些复杂的操作,使用算子写起来就很麻烦了,所以我们希望能够直接支持用sql的方式执行,Spark SQL也是支持的。
五、DataFrame的sql操作
想要实现直接支持sql语句查询DataFrame中的数据
需要两步操作
1. 先将DataFrame注册为一个临时表
2. 使用sparkSession中的sql函数执行sql语句
1. Scala代码
package com.sanqian.scala.sqlimport org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSessionobject DataFrameSqlScala {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setMaster("local")val sparkSession = SparkSession.builder().appName("DataFrameOpScala").config(conf).getOrCreate()val df = sparkSession.read.json("D:\\data\\spark\\student.json")//将DataFrame注册为一个临时表df.createOrReplaceTempView("student")//使用sql查询临时表中的数据sparkSession.sql("select age, count(*) as num from student group by age").show()sparkSession.stop()}
}
2. Java代码
package com.sanqian.java.sql;import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;public class DataFrameSqlJava {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setMaster("local");//创建SparkSession对象,里面包含SparkContext和SqlContextSparkSession sparkSession = SparkSession.builder().appName("DataFrameOpJava").config(conf).getOrCreate();Dataset<Row> ds = sparkSession.read().json("D:\\data\\spark\\student.json");ds.createOrReplaceTempView("student");sparkSession.sql("select age, count(*) as num from student group by age").show();sparkSession.stop();}
}
六、RDD转换为DataFrame
为什么要将RDD转换为DataFrame?
在实际工作中我们可能会先把hdfs上的一些日志数据加载进来,然后进行一些处理,最终变成结构化的数据,希望对这些数据做一些统计分析,当然了我们可以使用spark中提供的transformation算子来实现,只不过会有一些麻烦,毕竟是需要写代码的,如果能够使用sql实现,其实是更加方便的。所以可以针对我们前面创建的RDD,将它转换为DataFrame,这样就可以使用dataFrame中的一些算子或者直接写sql来操作数据了。
Spark SQL支持这两种方式将RDD转换为DataFrame1. 反射方式
2. 编程方式
(一)反射方式
下面来看一下反射方式:
这种方式是使用反射来推断RDD中的元数据。基于反射的方式,代码比较简洁,也就是说当你在写代码的时候,已经知道了RDD中的元数据,这样的话使用反射这种方式是一种非常不错的选择。Scala具有隐式转换的特性,所以spark sql的scala接口是支持自动将包含了case class的RDD转换为DataFrame的
下面来举一个例子
1. scala代码
package com.sanqian.scala.sqlimport org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSessionobject RddToDataFrameByReflectScala {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setMaster("local")val sparkSession = SparkSession.builder().appName("RddToDataFrameByReflectScala").config(conf).getOrCreate()val sc = sparkSession.sparkContextval rdd = sc.parallelize(Array(("jack", 18), ("tom", 20), ("jess", 30)))//基于反射直接将包含Student对象的RDD转换为DataFrame//需要导入隐式转换import sparkSession.implicits._val df = rdd.map(tup => Student(tup._1, tup._2)).toDF()df.createOrReplaceTempView("student")//执行sql查询val rdd2 = sparkSession.sql("select name, age from student where age > 18")rdd2.show()//将DataFrame转化为RDDrdd2.map(row => Student(row(0).toString, row(1).toString.toInt)).collect().foreach(println(_))//使用row的getAs()方法,获取指定列名的值rdd2.map(row => Student(row.getAs[String]("name"), row.getAs[Int]("age"))).collect().foreach(println(_))sparkSession.stop()}
}
//定义一个Student
case class Student(name: String, age: Int)
2. java代码
package com.sanqian.java.sql;import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
import sun.awt.windows.WPrinterJob;import java.io.Serializable;
import java.util.Arrays;
import java.util.List;public class RddToDataFrameByReflectJava {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setMaster("local");//创建SparkSession对象,里面包含SparkContext和SqlContextSparkSession sparkSession = SparkSession.builder().appName("RddToDataFrameByReflectJava").config(conf).getOrCreate();//获取SparkContext//从sparkSession中获取的是scala中的sparkContext,所以需要转换成java中的sparkContextJavaSparkContext sc = JavaSparkContext.fromSparkContext(sparkSession.sparkContext());Tuple2<String, Integer> t1 = new Tuple2<>("jack", 18);Tuple2<String, Integer> t2 = new Tuple2<>("tom", 20);Tuple2<String, Integer> t3 = new Tuple2<>("jess", 30);JavaRDD<Tuple2<String, Integer>> rdd = sc.parallelize(Arrays.asList(t1, t2, t3));JavaRDD<Student> rdd2 = rdd.map(new Function<Tuple2<String, Integer>, Student>() {@Overridepublic Student call(Tuple2<String, Integer> tup) throws Exception {return new Student(tup._1, tup._2);}});//注意:Student这个类必须声明为public,并且必须实现序列化Dataset<Row> df = sparkSession.createDataFrame(rdd2, Student.class);df.createOrReplaceTempView("student");//执行sql查询Dataset<Row> df2 = sparkSession.sql("select name, age from student where age > 18");df2.show();//将DataFrame转化为RDD,注意:这里需要转为JavaRDDJavaRDD<Row> resRDD = df2.javaRDD();//从row中取数据,封装成student,打印到控制台List<Student> resList = resRDD.map(new Function<Row, Student>() {@Overridepublic Student call(Row row) throws Exception {return new Student(row.getAs("name").toString(), Integer.parseInt(row.getAs("age").toString()));}}).collect();for(Student stu: resList){System.out.println(stu);}sparkSession.stop();}
}(二)编程方式
这种方式是通过编程接口来创建DataFrame,你可以在程序运行时动态构建一份元数据,就是Schema,然后将其应用到已经存在的RDD上。这种方式的代码比较冗长,但是如果在编写程序时,还不知道RDD的元数据,只有在程序运行时,才能动态得知其元数据,那么只能通过这种动态构建元数据的方式。也就是说当case calss中的字段无法预先定义的时候,就只能用编程方式动态指定元数据了。
1. Scala代码
package com.sanqian.scala.sqlimport org.apache.spark.SparkConf
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}/*** 需求:使用编程方式实现RDD转换为DataFrame**/
object RddToDataFrameByProgramScala {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local")//创建SparkSession对象,里面包含SparkContext和SqlContextval sparkSession = SparkSession.builder().appName("RddToDataFrameByProgramScala").config(conf).getOrCreate()//获取SparkContextval sc = sparkSession.sparkContextval dataRDD = sc.parallelize(Array(("jack", 18), ("tom", 20), ("jessic", 30)))//组装rowRDDval rowRDD = dataRDD.map(tup => Row(tup._1, tup._2))//指定元数据信息【这个元数据信息就可以动态从外部获取了,比较灵活】val schema = StructType(Array(StructField("name", StringType, true),StructField("age", IntegerType, true)))//组装DataFrameval stuDf = sparkSession.createDataFrame(rowRDD, schema)//下面就可以通过DataFrame的方式操作dataRDD中的数据了stuDf.createOrReplaceTempView("student")//执行sql查询val resDf = sparkSession.sql("select name,age from student where age > 18")//将DataFrame转化为RDDval resRDD = resDf.rddresRDD.map(row => (row(0).toString, row(1).toString.toInt)).collect().foreach(println(_))sparkSession.stop()}
}2. Java代码
package com.sanqian.java.sql;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import scala.Tuple2;import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;public class RddToDataFrameByProgramJava {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setMaster("local");
//创建SparkSession对象,里面包含SparkContext和SqlContextSparkSession sparkSession = SparkSession.builder().appName("RddToDataFrameByProgramJava").config(conf).getOrCreate();//获取SparkContext//从sparkSession中获取的是scala中的sparkContext,所以需要转换成java中的sparkContextJavaSparkContext sc = JavaSparkContext.fromSparkContext(sparkSession.sparkContext());Tuple2<String, Integer> t1 = new Tuple2<String, Integer>("jack", 18);Tuple2<String, Integer> t2 = new Tuple2<String, Integer>("tom", 20);Tuple2<String, Integer> t3 = new Tuple2<String, Integer>("jessic",30);JavaRDD<Tuple2<String, Integer>> dataRDD = sc.parallelize(Arrays.asList(t1, t2, t3));
//组装rowRDDJavaRDD<Row> rowRDD = dataRDD.map(new Function<Tuple2<String, Integer >, Row >() {@Overridepublic Row call (Tuple2 < String, Integer > tup) throws Exception {return RowFactory.create(tup._1, tup._2);}});
//指定元数据信息ArrayList<StructField> structFieldList = new ArrayList<StructField>();structFieldList.add(DataTypes.createStructField("name", DataTypes.StringType, true));structFieldList.add(DataTypes.createStructField("age", DataTypes.IntegerType, true));StructType schema = DataTypes.createStructType(structFieldList);
//构建DataFrameDataset<Row> stuDf = sparkSession.createDataFrame(rowRDD, schema);stuDf.createOrReplaceTempView("student");
//执行sql查询Dataset<Row> resDf = sparkSession.sql("select name,age from student where age > 18");
//将DataFrame转化为RDD,注意:这里需要转为JavaRDDJavaRDD < Row > resRDD = resDf.javaRDD();List<Tuple2<String, Integer>> resList = resRDD.map(new Function<Row, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> call(Row row) throws Exception {return new Tuple2<String, Integer>(row.getString(0), row.getInt(1));}}).collect();for (Tuple2<String, Integer> tup : resList) {System.out.println(tup);}sparkSession.stop();}
}七、load和save操作
对于Spark SQL的DataFrame来说,无论是从什么数据源创建出来的DataFrame,都有一些共同的load和save操作。
load操作主要用于加载数据,创建出DataFrame;
save操作,主要用于将DataFrame中的数据保存到文件中。
我们前面操作json格式的数据的时候好像没有使用load方法,而是直接使用的json方法,这是什么特殊用法吗?查看json方法的源码会发现,它底层调用的是format和load方法
def json(paths: String*): DataFrame = format("json").load(paths : _*)注意:如果看不到源码,需要点击idea右上角的download source提示信息下载依赖的源码。
我们如果使用原始的format和load方法加载数据,此时如果不指定format,则默认读取的数据源格式是parquet,也可以手动指定数据源格式。Spark SQL 内置了一些常见的数据源类型,比如json, parquet, jdbc, orc, csv, text 通过这个功能,就可以在不同类型的数据源之间进行转换了。
1. Scala代码
package com.sanqian.scala.sqlimport org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSessionobject LoadAndSaveOpScala {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local")//创建SparkSession对象,里面包含SparkContext和SqlContextval sparkSession = SparkSession.builder().appName("LoadAndSaveOpScala").config(conf).getOrCreate()//读取数据val stuDf = sparkSession.read.format("json").load("D:\\data\\spark\\student.json")//保存数据stuDf.select("name", "age").write.format("csv").save("hdfs://bigdata01:9000/out-save001")sparkSession.stop()}
}2. Java代码
package com.sanqian.java.sql;import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;public class LoadAndSaveOpJava {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setMaster("local");//创建SparkSession对象,里面包含SparkContext和SqlContextSparkSession sparkSession = SparkSession.builder().config(conf).appName("LoadAndSaveOpJava").getOrCreate();//读取数据Dataset<Row> df = sparkSession.read().format("json").load("D:\\data\\spark\\student.json");//保存数据df.select("name", "age").write().format("csv").save("hdfs://bigdata01:9000/out-save002");sparkSession.stop();}
}
八、SaveMode
Spark SQL对于save操作,提供了不同的save mode。
主要用来处理,当目标位置已经有数据时应该如何处理。save操作不会执行锁操作,并且也不是原子的,因此是有一定风险出现脏数据的。
| SaveMode | 解释 | |
| 1 | SaveMode.ErrorIfExists (默认) | 如果目标位置已经存在数据,那么抛出一个异常 |
| 2 | SaveMode.Append | 如果目标位置已经存在数据,那么将数据追加进去 |
| 3 | SaveMode.Overwrite | 如果目标位置已经存在数据,那么就将已经存在的数据删除,用新数据进行覆盖 |
| 4 | SaveMode.Ignore | 如果目标位置已经存在数据,那么就忽略,不做任何操作 |
//保存数据df.select("name", "age").write().format("csv").mode(SaveMode.Append).save("hdfs://bigdata01:9000/out-save002");执行之后的结果确实是追加到之前的结果目录中了
九、内置函数
Spark中提供了很多内置的函数
(1)聚合函数: avg, count, countDistinct, first, last, max, mean, min, sum, sumDistinct
(2)集合函数:array_contains, explode, size
(3)日期/时间函数: datediff, date_add, date_sub, add_months, last_day, next_day, months_between, current_date, current_timestamp, date_format
(4)数学函数:abs, ceil, floor, round
(5)混合函数:if, isnull, md5, not, rand, when
(6)字符串函数:concat, get_json_object, length, reverse, split, upper
(7)窗口函数:denseRank, rank, rowNumber
其实这里面的函数和hive中的函数是类似的
注意: SparkSQL中的SQL函数文档不全,其实在使用这些函数的时候,大家完全可以去查看hive中sql的文档,使用的时候都是一样的。
相关文章:
Spark12: SparkSQL入门
一、SparkSQL Spark SQL和我们之前讲Hive的时候说的hive on spark是不一样的。hive on spark是表示把底层的mapreduce引擎替换为spark引擎。而Spark SQL是Spark自己实现的一套SQL处理引擎。Spark SQL是Spark中的一个模块,主要用于进行结构化数据的处理。它提供的最核…...

show profile和trance分析SQL
目录 一.show profile分析SQL 二.trance分析优化器执行计划 一.show profile分析SQL Mysql从5.0.37版本开始增加了对show profiles和show profile语句的支持。show profiles能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。。 通过have_profiling参数,能够…...
[AI生成图片] 效果最好的Midjourney 的介绍和使用
Midjourney介绍: 是一个文本生成图片的扩散模型,能够根据输入的任何文本生成令人难以置信的图像,让数十亿人在几秒钟内创造惊人的艺术。为方便用户控制和快速生成图片,打开后在页面底部输入文本内容,稍等一小会&#…...
 的核心原理)
Vue.use( ) 的核心原理
首先来思考几个问题: Vue.use是什么? vue.use() 是vue提供的一个静态方法,主要是为了注册插件,增加vue的功能。 Vue.use( plugin ) plugin只能是Object 或 Function vue.use()做了什么工作? 该js如果是对象 该对象…...
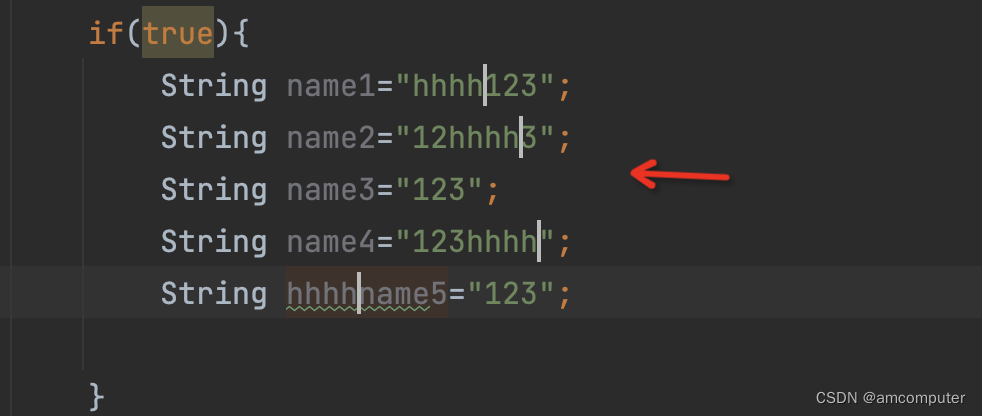
idea同时编辑多行-winmac都支持
1背景介绍 idea编辑器非常强大,其中一个功能非常优秀,很多程序员也非常喜欢用。这个功能能够大大大提高工作效率-------------多行代码同时编辑 2win 2.1方法1 按住alt鼠标左键上/下拖动即可 这样选中多行后,可以直接多行编辑。 优点&a…...

亿级高并发电商项目-- 实战篇 --万达商城项目 十一(编写商品搜索功能、操作商品同步到ES、安装RabbitMQ与Erlang,配置监听队列与消息队列)
👏作者简介:大家好,我是小童,Java开发工程师,CSDN博客博主,Java领域新星创作者 📕系列专栏:前端、Java、Java中间件大全、微信小程序、微信支付、若依框架、Spring全家桶 Ǵ…...

数据结构概述和稀疏数组
数据结构和算法内容介绍 1)算法是程序的灵魂,优秀的程序可以在海量数据计算时,仍然保持高速计算 数据结构和算法概述 1)程序 数据结构算法 2)学好数据结构可以编写出更加漂亮,更加有效率的代码 3&…...
宝塔搭建实战人才求职管理系统adminm前端vue源码(三)
大家好啊,我是测评君,欢迎来到web测评。 上一期给大家分享骑士cms后台admin前端vue在本地运行打包、宝塔发布部署的方式,本期给大家分享,后台adminm移动端后台vue前端怎么在本地运行,打包,实现线上功能更新…...

服务器是干什么用的?
首先,什么是服务器?服务器是提供计算服务器和网络服务的设备。服务器和计算机由CPU、硬盘、内存、系统总线等组成。比如我们访问一个网站,点击这个网站会发出访问请求,服务器会响应服务请求,进行相应的处理,…...

C++ 之结构体与共用体
文章目录参考描述结构体使用(基本)声明初始化先创建后初始化C 11 列表初始化使用(进阶)结构数组声明(拓展)声明及创建声明及初始化匿名结构体细节外部声明与内部声明成员赋值共用体存储空间匿名共用体同化尾…...
)
Java基础知识汇总(良心总结)
1. 前言 本文章是对Java基础知识进行了汇总,方便大家学习。 申明:文章的内容均来自黑马程序员,博主只是将其搬到了CSDN上以共享给大家学习 2. 目录 Day01 Java学习笔记之《开章》 Day02 Java学习笔记之《运算符》 Day03 Java学习笔记之《流程…...
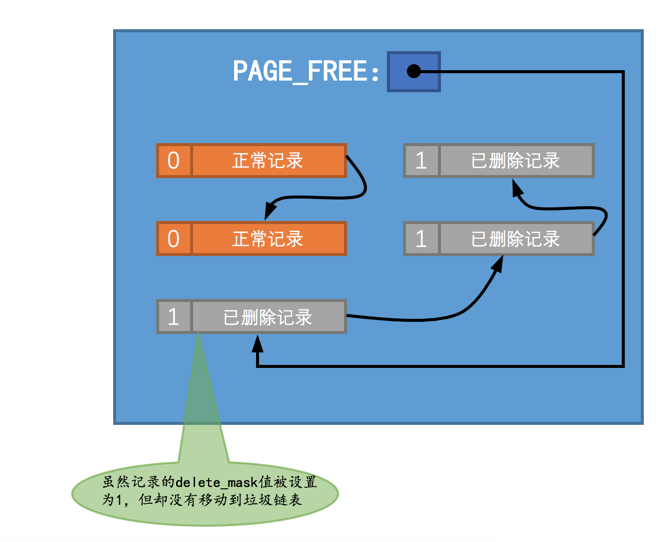
InnoDB之Undo log格式
1. 前言 InnoDB有两大日志模块,分别是redo log和undo log。为了避免磁盘随机写,InnoDB设计了redo log,数据写入时只写缓冲页和redo log,脏页由后台线程异步刷盘,哪怕系统崩溃也能根据redo log恢复数据。但是我们漏了一…...

一问学习StreamAPI终端操作
Java Stream管道流是用于简化集合类元素处理的java API。 在使用的过程中分为三个阶段: 将集合、数组、或行文本文件转换为java Stream管道流管道流式数据处理操作,处理管道中的每一个元素。上一个管道中的输出元素作为下一个管道的输入元素。管道流结果…...
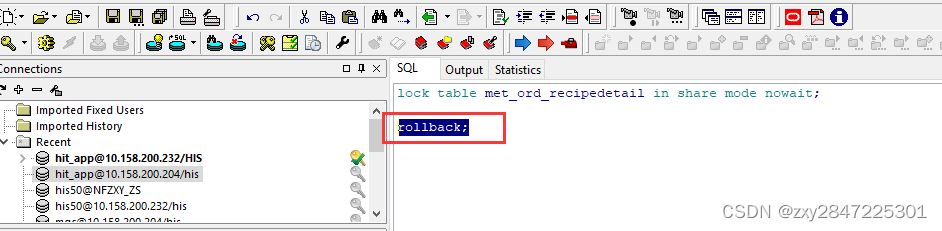
在屎山代码中快速找到想要的代码法-锁表法(C#)
由于本人水平有限,文中有写得不对的地方请指正,本文的方法有些投机取巧,实在是没招的情况下可以酌情使用,如有侵权,请联系删除。 前几天接到一个需求,要在医嘱签署时对检验项目进行分方操作,分…...
网页设计html期末大作业
网页设计html期末大作业网页设计期末大作业-自制网站大一期末作业,外卖网站设计网页设计期末大作业-精美商城-首页框架网页设计期末大作业-自制网站 有导航栏,轮播图,按钮均可点进去,如下图所示 点我下载资源》》》》 大一期末…...
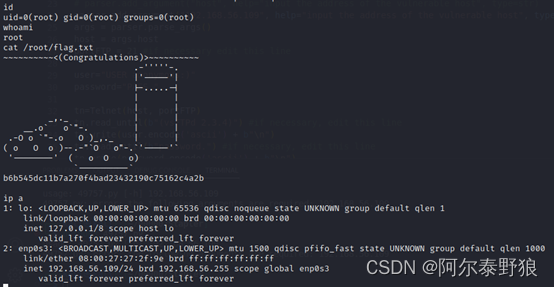
实战打靶集锦-006-Stapler
**写在前面:**记录博主的一次打靶经历。 目录1. 主机发现2. 端口发现3. 服务枚举4. 服务探查4.1 FTP探查4.1.1 匿名登录4.1.2 Elly用户4.1.3 John用户4.1.4 EXP搜索4.2 dnsmasq探查4.2.1 基础信息获取4.2.2 EXP搜索4.3 WEB应用探查4.3.1 浏览器访问4.3.2 目录扫描4.…...
致远OAA6版安装
准备工作,操作系统winserver2019,sqlserver2019。致远OA安装包0.SeeyonInstall.zip相关下载:winserver2019下载地址:cn_windows_server_2019_updated_july_2020_x64_dvd_2c9b67da.iso magnet:?xturn:btih:22A410DEA1B0886354A34D…...
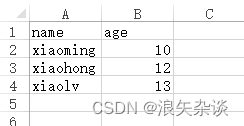
python实用脚本(六)—— pandas库的使用(生成、读取表格)
本期主题: python的pandas使用 往期链接: python实用脚本(一)—— 批量修改目标文件夹下的文件名python实用脚本(二)—— 使用xlrd读取excelpython实用脚本(三)—— 通过有道智云AP…...

字符集、ASCII、GBK、UTF-8、Unicode、乱码、字符编码、解码问题等
编码解码一、背景二、字符的相关概念三、字符集3.1 ASCII[ˈski]3.1.1 ASCII的编码方式3.1.2 EASCII3.2 GBK3.2.1 GB 2312-803.2.2 GBK的制订3.2.3 GBK的实现方式3.3 Unicode(统一码、万国码)3.3.1 Unicode的出现背景3.3.2 Unicode的编写方式3.3.3 Unico…...

Java 布隆过滤器
你在么?在!一定在么?不在!一定不在么? 你想要100%的准去性,还是99%的准确性附带较高的速度和较小的资源消耗。 任何算法,任何经营收到的背后,都是时间效益 资源消耗 准确性的平衡&am…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...

C#中的CLR属性、依赖属性与附加属性
CLR属性的主要特征 封装性: 隐藏字段的实现细节 提供对字段的受控访问 访问控制: 可单独设置get/set访问器的可见性 可创建只读或只写属性 计算属性: 可以在getter中执行计算逻辑 不需要直接对应一个字段 验证逻辑: 可以…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...

LabVIEW双光子成像系统技术
双光子成像技术的核心特性 双光子成像通过双低能量光子协同激发机制,展现出显著的技术优势: 深层组织穿透能力:适用于活体组织深度成像 高分辨率观测性能:满足微观结构的精细研究需求 低光毒性特点:减少对样本的损伤…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...