《Hadoop篇》------HDFS与MapReduce
目录
一、HDFS角色职责总结
二、CheckPoint机制
三、Mapreduce序列化
四、Mapper
4.1、官方介绍
4.2、Split计算
4.3、Split和block对应关系
4.4、启发式算法
五、MapTask整体的流程
六、压缩算法
6.1、压缩算法适用场景
6.2、压缩算法选择
6.2.1、Gzip压缩
6.2.2、Bzips压缩
6.2.3、Lzo压缩
七、ResourceManager
八、Yarn角色
九、任务调度策略
9.1、FIFO Scheduler(先进先出调度器)
9.2、Capacity Scheduler(容量调度器)
9.3、Fair Scheduler(公平调度器)
一、HDFS角色职责总结
Namenode:接受客户端的请求,维护整个HDFS集群目录树,元数据信息的存储由namenode负责
Datanode:主要是负责数据块的存储,定期向namenode汇报block
SecondaryNamenode:SecondaryNamenode不是第二个namenode,当namenode宕机时,不能由SecondaryNamenode顶替
二、CheckPoint机制
dfs.namenode.checkpoint.period=3600 #两次checkpoint的时间间隔
dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录
dfs.namenode.checkpoint.check.period=60 #检测的触发条件是否满足60s
dfs.namenode.checkpoint.max-retries=3 #最大的重试次数
上面配置只要有一个满足条件就会触发checkpoint机制
三、Mapreduce序列化
“将一个对象编码成一个字节流”称为序列化该对象(Serializing);相反的处理过程称为反序列化(Deserializing)。
自定义bean对象想要序列化传输,必须实现序列化接口,注意反序列化的顺序和序列化的顺序完全一致。
四、Mapper
4.1、官方介绍
one map task for each InputSpilt
每个切片都是由一个mapTask处理
4.2、Split计算
切片数量决定了MapTask的数量
4.3、Split和block对应关系
假设切片是跨block的,也就是说maptask读取数据的时候,会出现以下几种情况
1、最理想的情况:有数据低负载(最佳本地化读取)
2、折中的情况:没数据(本节点没有所需的数据,这个时候就需要跨节点读取,这个所跨的节点是同一机架的,换句话说,如果本节点没有数据,你就需要看同一个机架的其他节点是否有需要的数据)
3、最差的情况,带宽占有率会很高,尽量避免:跨机架(不要跨数据中心,如果同一个机架没有所需要的数据,那只能跨机架读取其他节点的数据)
4.4、启发式算法
假设Hadoop的拓扑结构如下:
1、HDFS的block3个
2、某个InputSplit包含3个block,大小分别是100,150和75
3、准备4个机架,每个机架2个节点,数据的分布如下图所示

按机架排序(rack2>rack1>rack3>rack4)
按机架内部的节点的数据量排(rack2:node4>node3)(rack1:node1>node2)
得出:node4>node3>node1>node2....
最佳的host列表{node4,node3,node1}
结论:当使用基于FileInputFormat实现InputFormat的时候,为了提高mapTask本地化读取数据,应该尽量使得InputSplit的大小和block相等。
五、MapTask整体的流程
1、Read阶段:MapTask通过用户编写的RecodReader去读取数据,从输入的InputSplit中解析出key/value键值对
2、Map阶段:这个阶段将解析的key/value交给用户编写的map()函数处理,并产生一系列的key/value键值对
3、Collect阶段:当用户编写的map()函数,处理完成之后,会调用OutputCollector.collect()输出结果,在该函数内部,它会生成key/value分片,并且写入到一个环形缓冲区,将来缓冲区的数据达到溢出值,内存中的数据就会刷入到磁盘。
4、Split阶段:溢出阶段,当环形缓冲区满了,数据溢出到磁盘生成一些小文件。数据写入磁盘之前,先要对数据进行一次本地化的排序操作,分区操作,并且必要的时候,还要对数据进行合并、压缩操作
5、Combine阶段:当所有的数据处理完成之后,mapTask对所有的临时文件进行一次合并,以确保最终只会生成一个数据文件。
六、压缩算法
压缩可以说是mapreduce一种优化的策略
6.1、压缩算法适用场景
1、数据进入到map端的时候可以进行压缩
2、Map端的数据传输到reduce端的时候可以进行压缩
3、Reduce端将数据输出的时候可以选择压缩
6.2、压缩算法选择
1、Bzip2压缩率是最高的,这种压缩算法比较适合IO密集型的Job
2、在运算密集型的job的时候,优先考虑lzo
6.2.1、Gzip压缩
优点:压缩比比较高,而且解压和压缩速度也比较快,hadoop本身也是支持这种压缩算法,在应用处理当中,gzip格式文件就和处理普通文件是一样的,大部分的Linux系统都是自带gzip命令,使用方便
缺点:不支持切分(split逻辑切分)
应用场景:当你的文件压缩之后可以到(或者是小于等于一个blocksize大小)blocksize可以考虑使用它(或者说如果你的文件用gzip压缩之后文件大小在128M,我们就可以考虑使用这个gzip算法)
6.2.2、Bzips压缩
优点:支持split,具有很高的压缩比,hadoop本身也是支持这种算法,在linux系统里面,自带bzip2,使用方便。
缺点:压缩速度和解压速度都是很慢的,不支持native本地
应用场景:使用的场景针对那种速度要求不高、对压缩比要求高、对冷数据进行持久化存储的场景,即IO密集型场景
6.2.3、Lzo压缩
优点:压缩、解压缩速度都是比较快的,压缩率不会很高。本身不支持split,给Lzo压缩的文件加上索引,就支持分片了,它是hadoop当中较为流行的压缩格式,注意的是,linux服务器默认是不支持这个压缩格式,需要单独的安装
缺点:压缩比比gzip更低,hadoo本身不支持这个格式,需要额外的安装。代码还需要做特殊处理
应用场景:用于这种运算密集型的job
七、ResourceManager
ResourceManager有两个重要的组件:Scheduler,Application Manager
八、Yarn角色
Yarn结构里的核心角色ResourceManager,Application,Nodemanager
九、任务调度策略
9.1、FIFO Scheduler(先进先出调度器)
先进先出的策略,简单来说按照提交作业的先后顺序运行。Hadoop1.x默认的资源调度器是FIFO的方式。它按照作业的优先级高低,再按照到达时间的先后选择被执行的作业
9.2、Capacity Scheduler(容量调度器)
支持多个队列,每个队列可配置一定的资源量,每个队列采用FIFO调度策略,为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定
9.3、Fair Scheduler(公平调度器)
公平调度是一种赋予作业(job)资源的方法,它的目的是让所有的作业随着时间的推移,都能平均的获得等同的共享资源。所有的job具有相同的资源,当单独一个作业在运行时,它将使用整个集群。
相关文章:
《Hadoop篇》------HDFS与MapReduce
目录 一、HDFS角色职责总结 二、CheckPoint机制 三、Mapreduce序列化 四、Mapper 4.1、官方介绍 4.2、Split计算 4.3、Split和block对应关系 4.4、启发式算法 五、MapTask整体的流程 六、压缩算法 6.1、压缩算法适用场景 6.2、压缩算法选择 6.2.1、Gzip压缩 6.2…...

网络爬虫简介
前言 没什么可以讲的所以就介绍爬虫吧 介绍 网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。 网路搜索引擎等站点通过…...
通过4个月的自动化学习,现在我也拿到了25K的offer
毕业后的5年,是拉开职场差距的关键时期。有人通过这5年的努力,实现了大厂高薪,有人在这5年里得到贵人的赏识,实现了职级的快速拔升,还有人在这5年里逐渐掉队,成了职场里隐身一族,归于静默。 而…...

分库分表了解
数据切分根据其切分类型,可以分为两种方式:垂直(纵向)切分和水平(横向)切分一:垂直(纵向)切分【基于表或字段划分,表结构不同】1:垂直分库根据业务…...
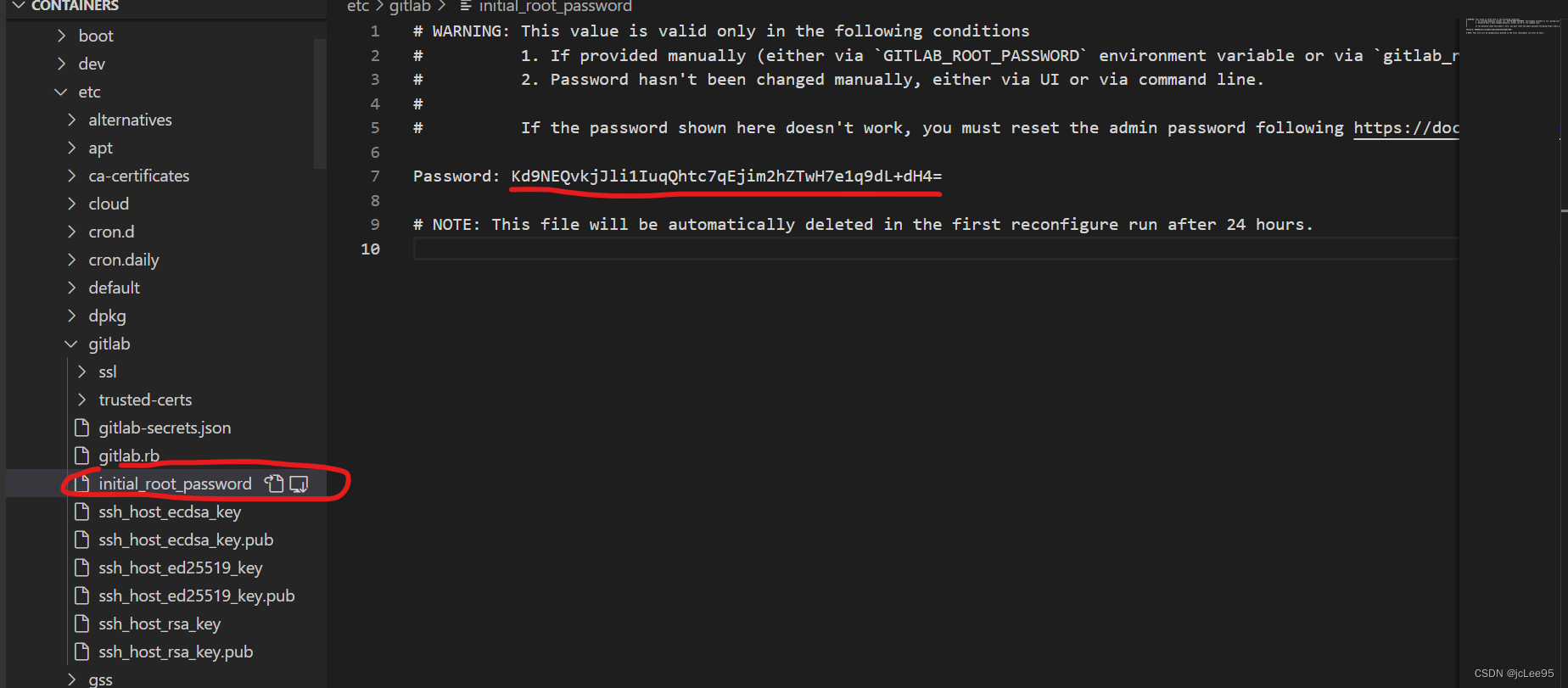
docker中 gitlab 安装、配置和初始化
小笔记:gitlab配置文件 /etc/gitlab/gitlab.rb 配置项jcLee95 的CSDN博客:https://blog.csdn.net/qq_28550263?spm1001.2101.3001.5343 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/1…...

有哪些好用的C++Json库?
文章目录RapidJSONJSON for Modern CBoost.PropertyTreeJanssonPicoJSONC REST SDKnlohmann json(ky用的这个)jsoncpp(cw用的这个)RapidJSON RapidJSON是一个快速、高效的C JSON解析器和生成器,支持SAX和DOM两种解析模…...

Docker 快速上手学习入门教程
目录 1、docker 的基础概念 2、怎样打包和运行一个应用程序? 3、如何对 docker 中的应用程序进行修改? 4、如何对创建的镜像进行共享? 5、如何使用 volumes 名称对容器中的数据进行存储?// 数据挂载 6、另一种挂载方式&…...
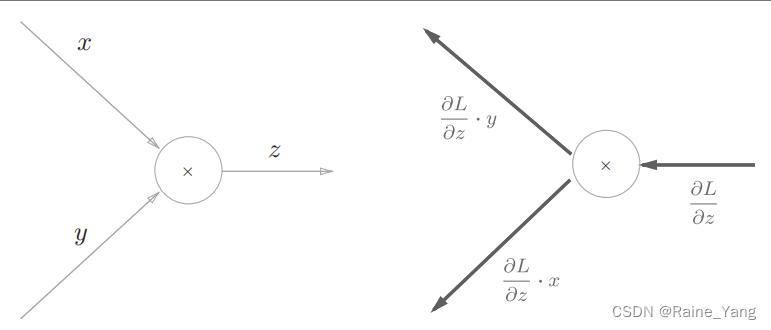
深度学习笔记:误差反向传播(1)
1 计算图 计算图使用图(由节点和边构成的图)来表达算式。 如图,我们用节点代表运算符号,用边代表传入的参数,即可算出购买苹果和橘子的总价格。 2 计算图的局部计算 局部计算意味着每个节点只处理和其相关的运算&…...
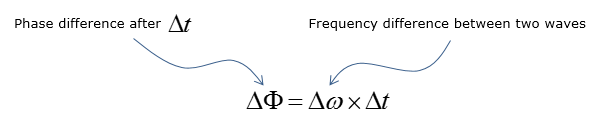
锁相环(1)
PLL代表相位锁定环。顾名思义,如下图所示,PLL是一种具有反馈循环的电路,可将反馈信号的相/频率保持与参考输入信号的相/频率相同(锁定)。 如下图所示,如果参考输入和反馈输入之间存在相位差,则…...

2023金三银四跳槽必会Java核心知识点笔记整理
现在互联网大环境不好,互联网公司纷纷裁员并缩减 HC,更多程序员去竞争更少的就业岗位,整的 IT 行业越来越卷。身为 Java 程序员的我们就更不用说了,上班 8 小时需要做好本职工作,下班后还要不断提升技能、技术栈&#…...

二十四节气—雨水,好雨知时节,当春乃发生。
雨水,是二十四节气之第2个节气。 雨水节气不仅表明降雨的开始及雨量增多,而且表示气温的升高,意味着进入气象意义的春天。 雨水节是一个非常富有想象力和人情味的节气,在这一天,不管下不下雨都充满着一种雨意蒙蒙的诗…...

为什么要使用数据库?
随着互联网技术的高速发展,预计2020 年底全世界网民的数量将达到 50 亿。网民数量的增加带动了网上购物、微博,网络视频等产业的发展。那么,随之而来的就是庞大的网络数据量。 大量的数据正在不断产生,那么如何安全有效地存储、检…...

【原创】java+swing+mysql图书管理系统设计与实现
图书管理系统是一个比较常见的系统,今天我们主要介绍如何使用javaswiingmysql去开发一个cs架构的图书管理系统,方便学生进行图书借阅。 功能分析: 宿舍报修管理系统的使用角色,一般分为管理员和学生,管理员主要进行学…...

图论 —— 强连通分量
概念 连通图 无向图 G G G 中,若对任意两点 V i , V j V_i, V_j V<...
:物理层和链路层,通道复用,MAC地址,CSMA/CD协议,PPP点对点协议)
计算机网络(二):物理层和链路层,通道复用,MAC地址,CSMA/CD协议,PPP点对点协议
文章目录一、物理层主机之间的通信方式通道复用技术常见的宽带接入技术二、链路层MAC地址和IP地址分别有什么作用为什么有了MAC地址之后还需要IP地址为什么有了IP地址还需要MAC地址以太网中的CSMA/CD协议数据链路层上的三个基本问题PPP协议一、物理层 主机之间的通信方式 单工…...

英语基础-定语从句的特殊用法及写作应用
1. 定语从句的引导词省略的情况 1. that 引导定语从句,从句中缺宾语/表语,that可省略; This is the book that he likes. I like the shirt that you gave me. We do not agree on the plan that you make. China is not the country th…...

[数据结构]---八大经典排序算法详解
🐧作者主页:king&南星 🏰专栏链接:c 文章目录一、八大排序算法复杂度对比二、基于比较的排序算法1.冒泡排序2.选择排序3.插入排序4.希尔排序5.直观感受四种算法的时间复杂度三、基于非比较的排序算法1.基数排序2.箱(桶)排序四…...
Go语言设计与实现 -- 反射
Go的反射有哪些应用? IDE中代码的自动补全对象序列化fmt函数的相关实现ORM框架 什么情况下需要使用反射? 不能明确函数调用哪个接口,需要根据传入的参数在运行时决定。不能明确传入函数的参数类型,需要在运行时处理任意对象。 …...

利用5G工业网关实现工业数字化的工业互联网解决方案
5G工业网关是一种用于将工业生产环境中的数据连接到工业互联网的解决方案。它可以利用高带宽、高速率、低时延的5G网络连接工业现场的PLC、传感器、工业设备和云端数据中心,从而实现工业数字化。 物通博联工业互联网解决方案 物通博联5G工业网关的使用步骤&#x…...
朋友当上项目测试组长了,我真的羡慕了
最近我发现一个神奇的事情,我一个朋友居然已经当上了测试项目组长,据我所知他去年还是在深圳的一家创业公司做苦逼的测试狗,短短8个月,到底发生了什么? 于是我立刻私聊他八卦一番。 原来他所在的公司最近正在裁员&am…...

在 AMD Ryzen AI 7 H350 Radeon 860M 上使用 Ollama 运行 GPU 加速
本文介绍了如何在搭载 AMD Ryzen AI 7 H350 及 Radeon 860M 显卡的系统上,配置 Ollama 以利用 GPU 运行 AI 模型。 一、安装 AMD 驱动程序 首先,请安装最新的 AMD 驱动程序,以确保系统能够正确识别并调用显卡硬件。 驱动程序下载地址&…...

保姆级教程:在Quartus Prime 18.0中手把手配置NCO IP核并完成Modelsim仿真
保姆级教程:在Quartus Prime 18.0中手把手配置NCO IP核并完成Modelsim仿真 数字信号处理是FPGA开发中的核心技能之一,而数控振荡器(NCO)作为生成精确频率信号的关键IP核,在通信系统、雷达信号处理等领域有着广泛应用。…...

深入解析build.prop:从基础参数到高级定制指南
1. build.prop文件到底是什么? 第一次在Android系统目录里看到build.prop这个文件时,我也是一头雾水。这玩意儿看起来就像个普通的文本文件,但里面密密麻麻的参数却让人望而生畏。后来才发现,它其实是Android系统的"身份证&q…...

京东抢购自动化:用Python脚本实现毫秒级响应的高效抢购方案
京东抢购自动化:用Python脚本实现毫秒级响应的高效抢购方案 【免费下载链接】jd-assistantV2 京东抢购助手:包含登录,查询商品库存/价格,添加/清空购物车,抢购商品(下单),抢购口罩,查询订单等功…...

Magisk Alpha深度隐匿实战:从Momo检测到BL列表的终极配置
1. 为什么需要深度隐匿Root环境? 最近两年,银行类APP和游戏厂商的检测手段越来越严格。我去年用某银行APP时,明明Root已经隐藏得很好,结果转账时突然弹出"设备环境异常"的提示,直接中断交易。后来才知道是新…...

工程师提升TVA产品缺陷识别精度的实操指南
AI算法是TVA系统识别焊接点缺陷的核心,作为负责系统优化的工程师,算法优化的质量直接决定检测精度与效率。在汽车零部件焊接点检测中,由于缺陷种类繁杂(气孔、咬边、虚焊等)、形态多样、隐蔽性强,算法优化过…...

2026届毕业生推荐的AI辅助写作网站实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 身为智能写作辅助工具的DeepSeek,于学术论文创作里呈现出明显效能,用…...

mask rcnn,fasterrcnn,ssd,yolov5,6,7,8在win10,ubuntu环境搭建,代跑数据集,yolov8yolov7Yolov9Yolov10
mask rcnn,fasterrcnn,ssd,yolov5,6,7,8在win10,ubuntu环境搭建,代跑数据集, yolov8 yolov7 Yolov9 Yolov10...

如何用Depressurizer拯救混乱的Steam游戏库?3个高效管理技巧
如何用Depressurizer拯救混乱的Steam游戏库?3个高效管理技巧 【免费下载链接】Depressurizer A Steam library categorizing tool. 项目地址: https://gitcode.com/gh_mirrors/de/Depressurizer 你是否也曾面对Steam库里上百款游戏却找不到想玩的那一款&…...

开源SCADA系统FUXA的SVG编辑器列表过滤功能:从线性列表到智能管理的技术演进
开源SCADA系统FUXA的SVG编辑器列表过滤功能:从线性列表到智能管理的技术演进 【免费下载链接】FUXA Web-based Process Visualization (SCADA/HMI/Dashboard) software 项目地址: https://gitcode.com/gh_mirrors/fu/FUXA 在工业自动化领域,SCADA…...