密度峰值聚类算法(DPC)
密度峰值聚类算法
- 目录
- DPC算法
- 1.1 DPC算法的两个假设
- 1.2 DPC算法的两个重要概念
- 1.3 DPC算法的执行步骤
- 1.4 DPC算法的优缺点
- matlab代码
- 密度计算函数
- 计算delta
- 寻找聚类中心点
- 聚类算法
目录
DPC算法
1.1 DPC算法的两个假设
1)类簇中心被类簇中其他密度较低的数据点包围;
2)类簇中心间的距离相对较远。
1.2 DPC算法的两个重要概念
1)局部密度
设有数据集为 ,其中 ,N为样本个数,M为样本维数。
对于样本点i的局部密度,局部密度有两种计算方式,离散值采用截断核的计算方式,连续值则用高斯核的计算方式。

式中dij为数据点 i 与数据点 j 的欧氏距离,dc为数据点i的邻域截断距离。
采用截断核计算的局部密度ρi等于分布在样本点i的邻域截断距离范围内的样本点个数;而利用高斯计算的局部密度ρi等于所有样本点到样本点i的高斯距离之和。
DPC算法的原论文指出,对于较大规模的数据集,截断核的计算方式聚类效果较好;而对于小规模数据集,高斯核的计算方式聚类效果更为明显。

1.3 DPC算法的执行步骤

1.4 DPC算法的优缺点
优点:
1)不需要事先指定类簇数;
2)能够发现非球形类簇;
3)只有一个参数需要预先取值。
缺点:
1)当类簇间的数据密集程度差异较大时,DPC算法并不能获得较好的聚类效果;
2)DPC算法的样本分配策略存在分配连带错误。
matlab代码
密度计算函数
计算密度,利用截断核算法,pdist2是计算欧式距离的,对于每个idata_len进行计算所有的点的欧式距离,利用求和函数进行求取密度
function data_density=cal_density(data,cut_dist)%%利用截断核的方式进行计算data_len=size(data,1);%%size(data,1)是获取data的行数,size(data,2)是获取列数data_density=zeros(1,data_len);%%for idata_len=1:data_lentemp_dist=pdist2(data,data(idata_len,:));%计算第i行的点和data中所有点的欧式距离data_density(idata_len)=sum(temp_dist<=cut_dist);%%temp_dist中所有数据同cut_dist进行比较%%disp(data_density(idata_len))end
end
计算delta
两种情况:
对于密度最高的值,选取距离其最远的距离
对于密度最低的值,选取距离其最近的距离
function data_delta=cal_delta(data,data_density)data_len=size(data,1);data_delta=zeros(1,data_len);for idata_len=1:data_lenindex=data_density>data_density(idata_len);%%index中存的是所有大于idata_len密度值的下标if sum(index)~=0data_delta(idata_len)=min(pdist2(data(idata_len,:),data(index,:)));elsedata_delta(idata_len)=max(pdist2(data(idata_len,:),data));end%{两种情况:对于密度最高的值,选取距离其最远的距离对于密度最低的值,选取距离其最近的距离%}end
end
寻找聚类中心点
首先计算决策值,之后进行排序,选择前后项差值较大的点作为疑似中心点,然后对每个疑似中心点找出小于两倍截断距离的疑似中心点并选取其中具有最大密度的点,最后进行去重
function [center,center_index]=find_center(data,data_delta,data_density,cut_dist)R=data_density.*data_delta;%计算决策值figure;plot(R,'*','Color','red')[sort_R,R_index]=sort(R,"descend");%sort_R是排序好的序列,R_index是sort_R中元素在原来的R中的位置gama=abs(sort_R(1:end-1)-sort_R(2:end));%计算sort_R临近的两项之间的距离%disp(gama)[sort_gama,gama_idnex]=sort(gama,"descend");%对差值进行降序排列gmeans=mean(sort_gama(2:end));%求平均值%gmeans=mean(sort_gama);%寻找疑似聚类中心点,疑似聚类中心:第i项比第i+1项的差值大于平均差值,就认为第i项是疑似聚类中心temp_center=data(R_index(gama>gmeans),:);temp_center_index=R_index(gama>gmeans);%进一步筛选中心点temp_center_dist=pdist2(temp_center,temp_center); temp_center_len=size(temp_center,1);center=[];center_index=[];%判断中心点之间距离是否小于2倍截断距离并中心点去重for icenter_len=1:temp_center_lentemp_index=find(temp_center_dist(icenter_len,:)<2*cut_dist);%返回比2*截断距离小的下标[~,max_density_index]=max(data_density(temp_center_index(temp_index)));%找出符合条件的最大值的索引if sum(center_index==temp_center_index(temp_index(max_density_index)))==0%如果不在center_index中则加入center=[center;temp_center(temp_index(max_density_index),:)];%每个数据是坐标,因此垂直拼接center_index=[center_index,temp_center_index(temp_index(max_density_index))];%{if icenter_len<=1disp(center)end%}end%center(icenter_len,:)=temp_center(temp_index(max_density_index),:);end
end
%{
[A,B]相当于水平拼接A和B,即horzcat(A,B)
[A;B]相当于垂直拼接A和B,即vertcat(A,B)
%}
聚类算法
对于中心点:归于自身
对于非中心点:首先选择密度比自身大的点,然后不断选择其中密度最小的点,判断是否为中心点,是则归于此点,否则继续迭代
function cluster=Clustering(data,center,center_index,data_density)data_len=size(data,1);data_dist=pdist2(data,data);cluster=zeros(1,data_len);% 标记中心点序号for i=1:size(center_index,2)cluster(center_index(i))=i;end% 对数据密度进行降序排序[sort_density,sort_index]=sort(data_density,"descend");for idata_len=1:data_len%判断当前数据点是否被分类if cluster(sort_index(idata_len))==0near=sort_index(idata_len);while 1near_density=find(data_density>data_density(near));%找出密度比near大的点near_dist=data_dist(near,near_density);%选取其中最小值[~,min_index]=min(near_dist);if cluster(near_density(min_index))%若为中心点则可加入,否则不能,继续迭代查找cluster(sort_index(idata_len))=cluster(near_density(min_index));break;elsenear=near_density(min_index);endendendend
end
相关文章:
密度峰值聚类算法(DPC)
密度峰值聚类算法目录DPC算法1.1 DPC算法的两个假设1.2 DPC算法的两个重要概念1.3 DPC算法的执行步骤1.4 DPC算法的优缺点matlab代码密度计算函数计算delta寻找聚类中心点聚类算法目录 DPC算法 1.1 DPC算法的两个假设 1)类簇中心被类簇中其他密度较低的数据点包围…...
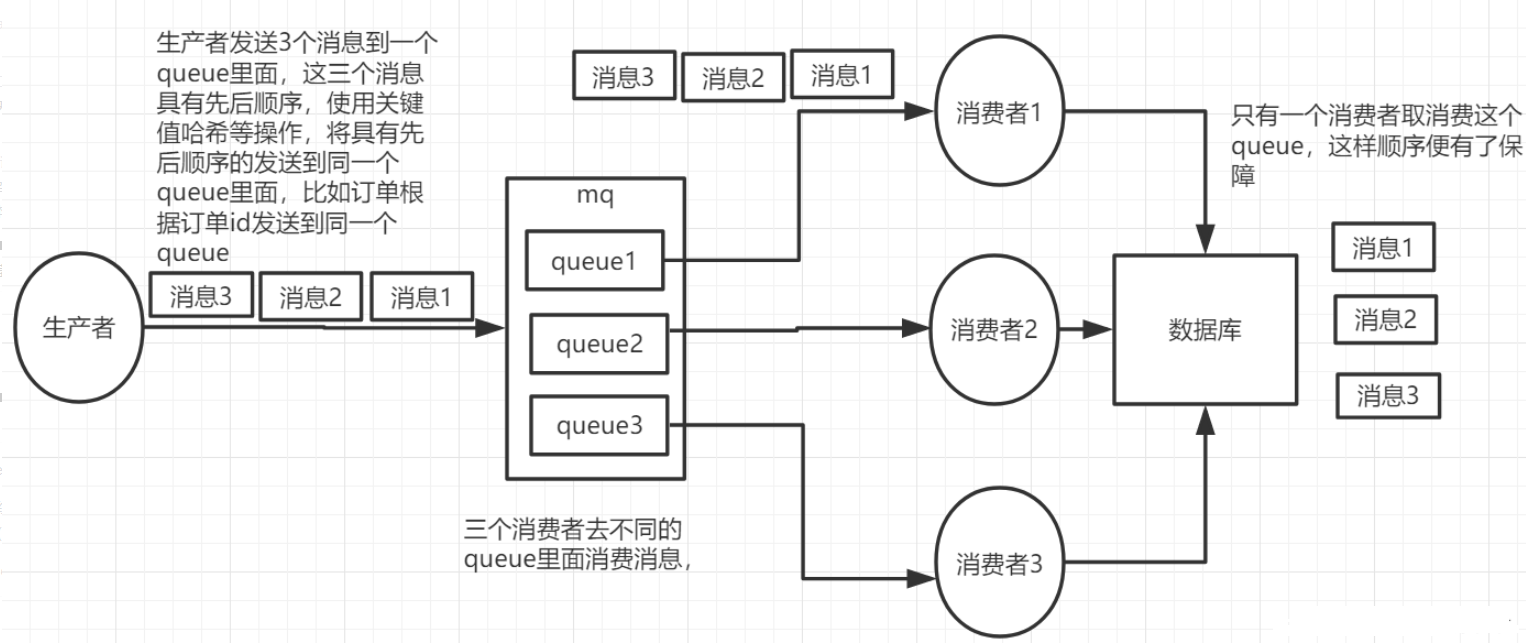
RabbitMQ相关问题
文章目录避免重复消费(保证消息幂等性)消息积压上线更多的消费者,进行正常消费惰性队列消息缓存延时队列RabbitMQ如何保证消息的有序性?RabbitMQ消息的可靠性、延时队列如何实现数据库与缓存数据一致?开启消费者多线程消费避免重复消费(保证消…...

操作系统 三(存储管理)
一、 存储系统的“金字塔”层次结构设计原理:cpu自身运算速度很快。内存、外存的访问速度受到限制各层次存储器的特点:1)主存储器(主存/内存/可执行存储器)保存进程运行时的程序和数据,内存的访问速度远低于…...

day34 贪心算法 | 860、柠檬水找零 406、根据身高重建队列 452、用最少数量的箭引爆气球
题目 860、柠檬水找零 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。 顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。 每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个…...

使用canvas给上传的整张图片添加平铺的水印
写在开头 哈喽,各位倔友们又见面了,本章我们继续来分享一个实用小技巧,给图片加水印功能,水印功能的目的是为了保护网站或作者版权,防止内容被别人利用或白嫖。 但是网络中,是没有绝对安全的,…...
[安装之4] 联想ThinkPad 加装固态硬盘教程
方案:保留原有的机械硬盘,再加装一个固态硬盘作为系统盘。由于X250没有光驱,这样就无法使用第二个2.5寸的硬盘。还好,X250留有一个M.2接口,这样,就可以使用NGFF M.2接口的固态硬盘。不过,这种接…...
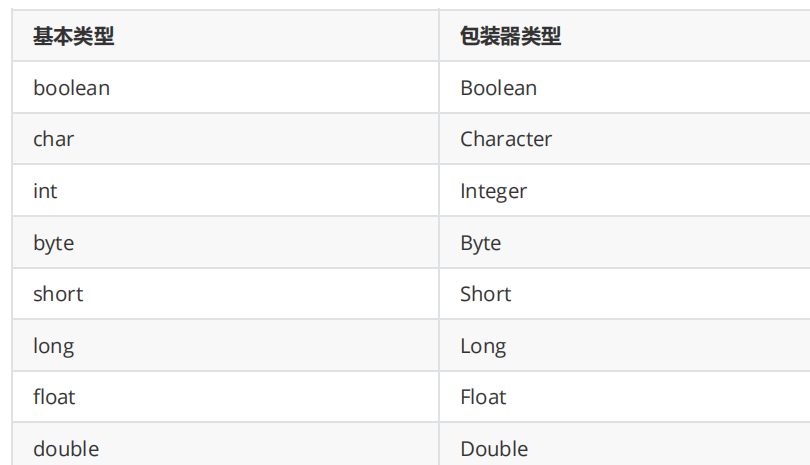
Java数据类型、基本与引用数据类型区别、装箱与拆箱、a=a+b与a+=b区别
文章目录1.Java有哪些数据类型2.Java中引用数据类型有哪些,它们与基本数据类型有什么区别?3.Java中的自动装箱与拆箱4.为什么要有包装类型?5.aab与ab有什么区别吗?1.Java有哪些数据类型 8种基本数据类型: 6种数字类型(4个整数型…...
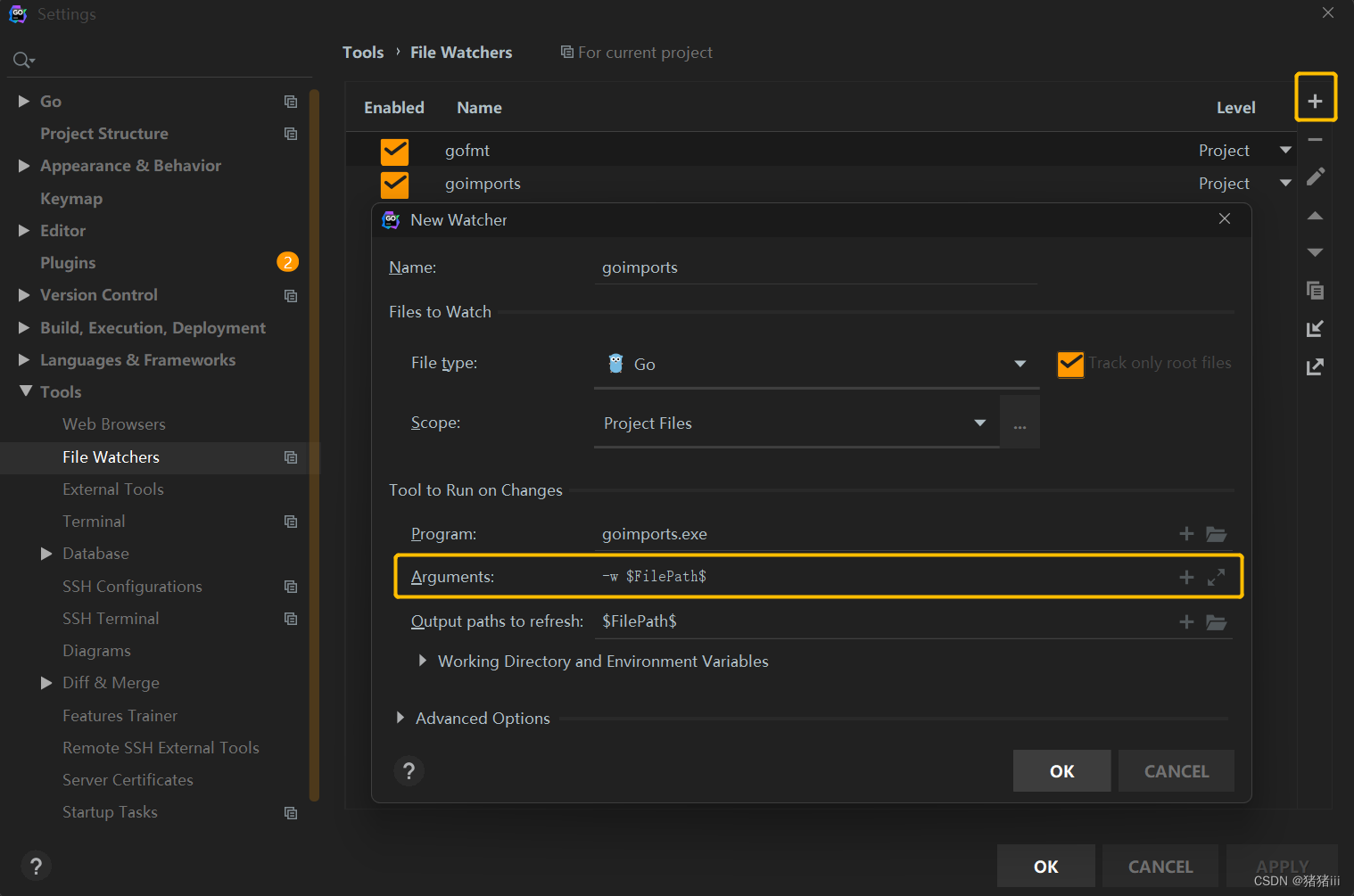
GoLang设置gofmt和goimports自动格式化
目录 设置gofmt gofmt介绍 配置gofmt 设置goimports goimports介绍 配置goimports 设置gofmt gofmt介绍 Go语言的开发团队制定了统一的官方代码风格,并且推出了 gofmt 工具(gofmt 或 go fmt)来帮助开发者格式化他们的代码到统一的风格…...

【k8s】如何搭建搭建k8s服务器集群(Kubernetes)
搭建k8s服务器集群 服务器搭建环境随手记 文章目录搭建k8s服务器集群前言:一、前期准备(所有节点)1.1所有节点,关闭防火墙规则,关闭selinux,关闭swap交换,打通所有服务器网络,进行p…...
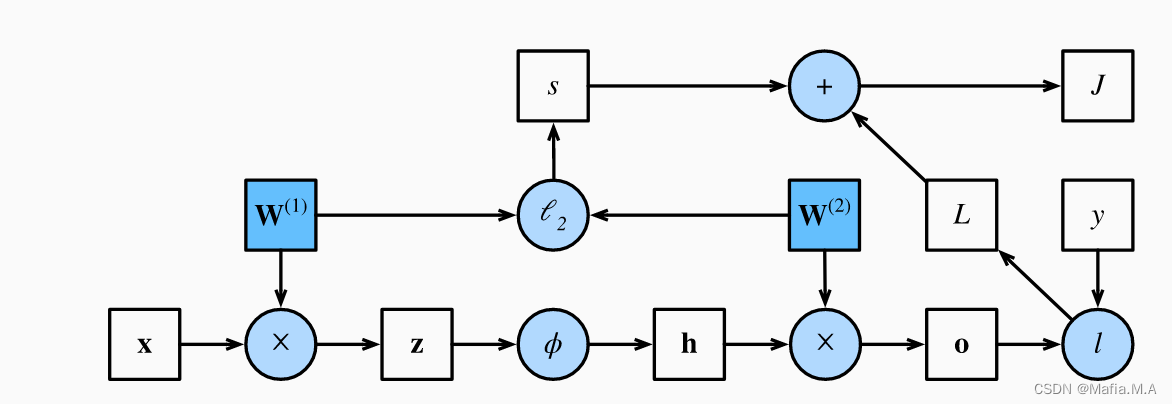
DIDL4_前向传播与反向传播(模型参数的更新)
前向传播与反向传播前向传播与反向传播的作用前向传播及公式前向传播范例反向传播及公式反向传播范例小结前向传播计算图前向传播与反向传播的作用 在训练神经网络时,前向传播和反向传播相互依赖。 对于前向传播,我们沿着依赖的方向遍历计算图并计算其路…...

链表学习之链表划分
链表解题技巧 额外的数据结构(哈希表);快慢指针;虚拟头节点; 链表划分 将单向链表值划分为左边小、中间相等、右边大的形式。中间值为pivot划分值。 要求:调整之后节点的相对次序不变,时间复…...
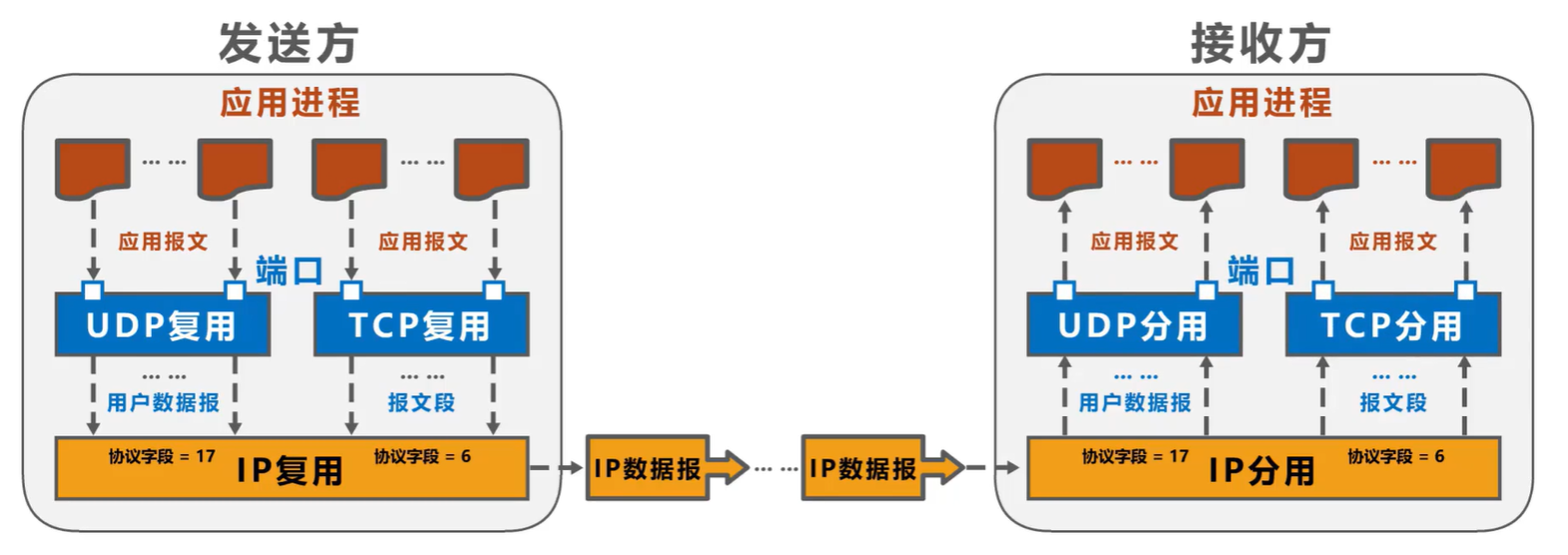
(考研湖科大教书匠计算机网络)第五章传输层-第一、二节:传输层概述及端口号、复用分用等概念
获取pdf:密码7281专栏目录首页:【专栏必读】考研湖科大教书匠计算机网络笔记导航 文章目录一:传输层概述(1)概述(2)从计算机网络体系结构角度看传输层(3)传输层意义二&am…...

C#:Krypton控件使用方法详解(第七讲) ——kryptonHeader
今天介绍的Krypton控件中的kryptonHeader,下面开始介绍这个控件的属性:控件的样子如上图所示,从上面控件外观来看,这个控件有三部分组成。第一部分是前面的图片,第二部分是kryptonHeader1文本,第三部分是控…...

5年软件测试工程师分享的自动化测试经验,一定要看
今天给大家分享一个华为的软件测试工程师分享的关于自动化测试的经验及干货。真的后悔太晚找他要了, 纯干货。一定要看完! 1.什么是自动化测试? 用程序测试程序,用代码取代思考,用脚本运行取代手工测试。自动化测试涵…...

什么是猜疑心理?小猫测试网科普小作文
什么是猜疑心理?猜疑心理是说一个人心中想法偏离了客观事实,牵强附会,往往是指不好的一面,对别人的一言一行都充满了不良的解读,认为这些对自己都有针对性,目的性,对自己都是不利的。猜疑心理重…...

Redis命令行对常用数据结构String、list、set、zset、hash等增删改查操作
1.Redis命令的小套路 - NX:not exist - EX:expire - M:multi 2.基本操作 ①切换数据库 Redis默认有16个数据库。 115 # Set the number of databases. The default database is DB 0, you can select 116 # a different one on a per-con…...

mycobot 使用教程
(1) 树莓派4B ubuntu系统调整swap空间与使SD卡快速扩容参考:https://www.bilibili.com/read/cv14825069https://blog.csdn.net/weixin_45824920/article/details/114381292?spm1001.2101.3001.6650.1&utm_mediumdistribute.pc_relevant.none-task-blog-2%7Edef…...
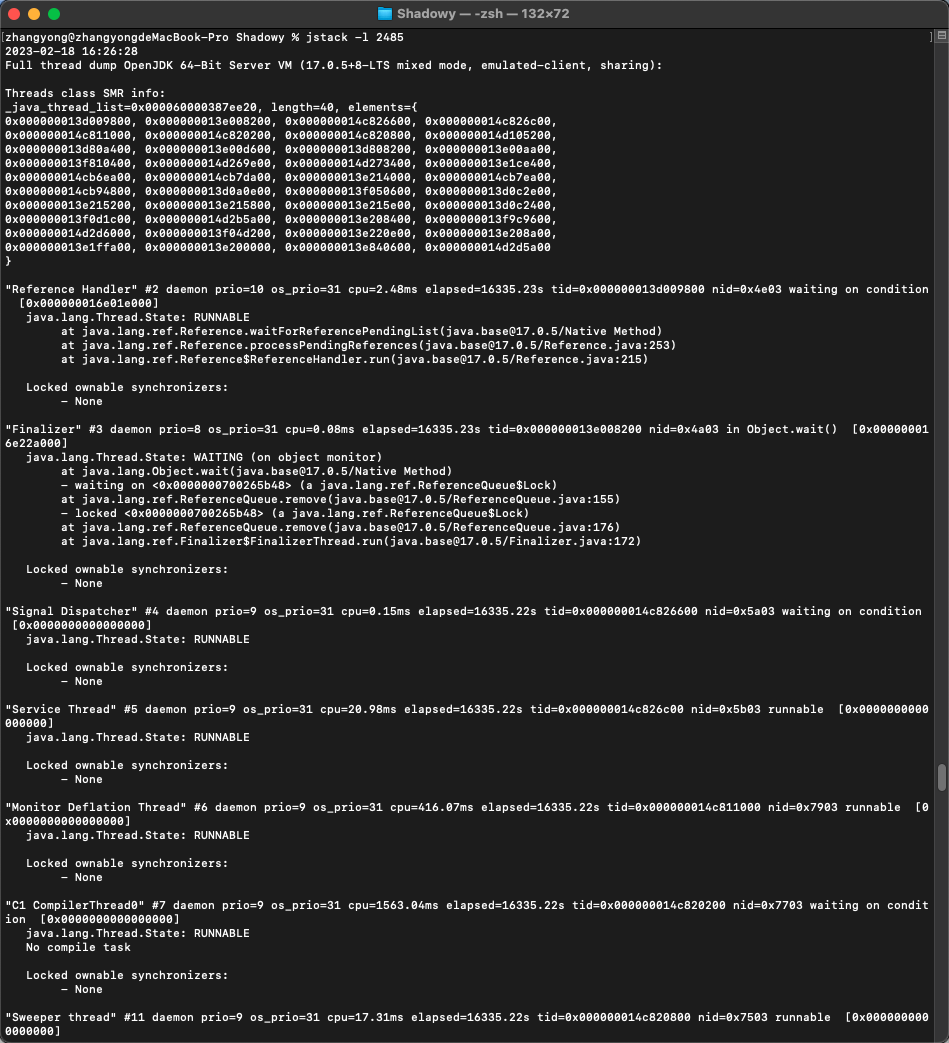
JVM学习总结,虚拟机性能监控、故障处理工具:jps、jstat、jinfo、jmap、Visual VM、jstack等
上篇:JVM学习总结,全面介绍运行时数据区域、各类垃圾收集器的原理使用、内存分配回收策略 参考资料:《深入理解Java虚拟机》第三版 文章目录三,虚拟机性能监控、故障处理工具1)jps:虚拟机进程状况工具2&…...

指针笔记(指针数组和指向数组的指针,数组中a和a的区别等)
指针数组和指向数组的指针 int *p[4]和int (*p)[4]有何区别? 前者是一个指针数组,数组大小为4,每一个元素都是一个指向int的指针 后者是指向int[4]类型数组的指针 以上代码若运行会报如下错误 main函数中定义的a数组本质是一个指向int[2]的…...

MySQL ---基础概念
目录 餐前小饮:什么是服务器?什么是数据库服务器? 一、数据库服务软件 1. 常见数据库产品 2.如何开启和停止MySQL服务 二、数据库术语及语法 1.数据库术语 2.SQL语法结构 3.SQL 语法要点 三、SQL分类 1.数据定义语言(D…...

技术赋能B端拓客:号码核验行业的迭代与价值升级,氪迹科技法人股东号码核验系统,阶梯式价格
2026年,B端市场竞争进入白热化阶段,拓客逻辑已从“规模扩张”转向“价值深耕”,“精准、高效、低成本”成为所有拓客团队的核心追求。号码核验作为B端拓客的前置基础性环节,其服务质量直接决定线索价值、人力效能与投入回报比&…...

OpenClaw安全加固指南:Phi-3-vision本地化部署的权限控制
OpenClaw安全加固指南:Phi-3-vision本地化部署的权限控制 1. 为什么需要安全加固? 上周我在调试一个自动处理发票的OpenClaw流程时,差点酿成大祸。这个流程需要读取财务部门的加密压缩包,解压后提取PDF发票进行OCR识别ÿ…...

电商网站SEO网站结构应该如何设计
电商网站SEO网站结构设计的关键点 在当今数字化时代,电商网站的成功离不开搜索引擎优化(SEO)。一个精心设计的网站结构不仅能提升网站的用户体验,还能大大提高在搜索引擎上的排名。电商网站SEO网站结构应该如何设计呢?…...

Krita 5.3.0 与 6.0.0 发布:功能升级与技术革新
文本与工具革新,Krita 功能升级Krita 5.3.0 和 6.0.0 正式推出,带来了一系列显著的功能改进。文本工具被完全重写,支持在画布上进行所见即所得编辑,还能支持 OpenType 的所有特性以及文本置入形状,这大大提升了文字处理…...

学习框架和推理引擎有什么区别
学习框架和推理引擎通常分别应用在 AI 大模型的训练和推理 (运行)阶段。模型的核心任务是从大量数据中学习规律,完成特定预测或者生成任务,前者即“模型训练”,后者即“模型运行”。在模型训练时ÿ…...

Omni-Vision Sanctuary 企业级部署架构设计:高可用与弹性伸缩
Omni-Vision Sanctuary 企业级部署架构设计:高可用与弹性伸缩 1. 企业级AI部署面临的挑战 当企业决定在生产环境中部署Omni-Vision Sanctuary这类AI服务时,通常会遇到几个关键挑战。首先是服务可用性问题,任何计划外停机都可能直接影响业务…...

如何在Charmbracelet Log中实现结构化日志记录的5个技巧
如何在Charmbracelet Log中实现结构化日志记录的5个技巧 【免费下载链接】log A minimal, colorful Go logging library 🪵 项目地址: https://gitcode.com/gh_mirrors/log1/log Charmbracelet Log是一款轻量级且色彩丰富的Go日志库,支持结构化日…...
)
别再只玩单机了!用AirSim+Python实现你的第一个无人机编队(附完整代码)
从单机到编队:用AirSim和Python打造你的第一支无人机小队 想象一下,当你第一次在AirSim中成功让无人机起飞时的兴奋感——现在,是时候将这份快乐乘以N倍了。本文将带你跨越单机操作的舒适区,进入无人机编队控制的新世界。不需要复…...

【测试之道】第四篇:分层测试论 —— 金字塔、奖杯与蜂巢:构建你的质量防御阵型
专栏进度:04 / 10 (测试理论专题) 在不同的架构(单体、微服务、前端驱动)下,测试资源的分配比例是完全不同的。盲目套用模板是测试经理最容易犯的错误。 一、 经典模型:测试金字塔 (Testing Pyramid) 由 Mike Cohn 提出…...

3个核心优势:BG3 Mod Manager的模组管理创新特性
3个核心优势:BG3 Mod Manager的模组管理创新特性 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 博德之门3(Baldurs Gate 3&…...