基于easyexcel的MySQL百万级别数据的excel导出功能
前言
最近我做过一个MySQL百万级别数据的excel导出功能,已经正常上线使用了。
这个功能挺有意思的,里面需要注意的细节还真不少,现在拿出来跟大家分享一下,希望对你会有所帮助。
原始需求:用户在UI界面上点击全部导出按钮,就能导出所有商品数据。
咋一看,这个需求挺简单的。
但如果我告诉你,导出的记录条数,可能有一百多万,甚至两百万呢?
这时你可能会倒吸一口气。
因为你可能会面临如下问题:
如果同步导数据,接口很容易超时。
如果把所有数据一次性装载到内存,很容易引起OOM。
数据量太大sql语句必定很慢。
相同商品编号的数据要放到一起。
如果走异步,如何通知用户导出结果?
如果excel文件太大,目标用户打不开怎么办?
我们要如何才能解决这些问题,实现一个百万级别的excel数据快速导出功能呢?
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://download.csdn.net
视频教程:https://doc.iocoder.cn/video/
1.异步处理
做一个MySQL百万数据级别的excel导出功能,如果走接口同步导出,该接口肯定会非常容易超时。
因此,我们在做系统设计的时候,第一选择应该是接口走异步处理。
说起异步处理,其实有很多种,比如:使用开启一个线程,或者使用线程池,或者使用job,或者使用mq等。
为了防止服务重启时数据的丢失问题,我们大多数情况下,会使用job或者mq来实现异步功能。
1.1 使用job
如果使用job的话,需要增加一张执行任务表,记录每次的导出任务。
用户点击全部导出按钮,会调用一个后端接口,该接口会向表中写入一条记录,该记录的状态为:待执行。
有个job,每隔一段时间(比如:5分钟),扫描一次执行任务表,查出所有状态是待执行的记录。
然后遍历这些记录,挨个执行。
需要注意的是:如果用job的话,要避免重复执行的情况。比如job每隔5分钟执行一次,但如果数据导出的功能所花费的时间超过了5分钟,在一个job周期内执行不完,就会被下一个job执行周期执行。
所以使用job时可能会出现重复执行的情况。
为了防止job重复执行的情况,该执行任务需要增加一个执行中的状态。
具体的状态变化如下:
执行任务被刚记录到执行任务表,是待执行状态。
当job第一次执行该执行任务时,该记录再数据库中的状态改为:执行中。
当job跑完了,该记录的状态变成:完成或失败。
这样导出数据的功能,在第一个job周期内执行不完,在第二次job执行时,查询待处理状态,并不会查询出执行中状态的数据,也就是说不会重复执行。
此外,使用job还有一个硬伤即:它不是立马执行的,有一定的延迟。
如果对时间不太敏感的业务场景,可以考虑使用该方案。
1.2 使用mq
用户点击全部导出按钮,会调用一个后端接口,该接口会向mq服务端,发送一条mq消息。
有个专门的mq消费者,消费该消息,然后就可以实现excel的数据导出了。
相较于job方案,使用mq方案的话,实时性更好一些。
对于mq消费者处理失败的情况,可以增加补偿机制,自动发起重试。
RocketMQ自带了失败重试功能,如果失败次数超过了一定的阀值,则会将该消息自动放入死信队列。
2.使用easyexcel
我们知道在Java中解析和生成Excel,比较有名的框架有Apache POI和jxl。
但它们都存在一个严重的问题就是:非常耗内存,POI有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。
百万级别的excel数据导出功能,如果使用传统的Apache POI框架去处理,可能会消耗很大的内存,容易引发OOM问题。
而easyexcel重写了POI对07版Excel的解析,之前一个3M的excel用POI sax解析,需要100M左右内存,如果改用easyexcel可以降低到几M,并且再大的Excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便。
需要在maven的pom.xml文件中引入easyexcel的jar包:
<dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.0.2</version>
</dependency>之后,使用起来非常方便。
读excel数据非常方便:
@Test
public void simpleRead() {String fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
}写excel数据也非常方便:
@Test
public void simpleWrite() {String fileName = TestFileUtil.getPath() + "write" + System.currentTimeMillis() + ".xlsx";// 这里 需要指定写用哪个class去读,然后写到第一个sheet,名字为模板 然后文件流会自动关闭// 如果这里想使用03 则 传入excelType参数即可EasyExcel.write(fileName, DemoData.class).sheet("模板").doWrite(data());
}easyexcel能大大减少占用内存的主要原因是:在解析Excel时没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析。
3.分页查询
百万级别的数据,从数据库一次性查询出来,是一件非常耗时的工作。
即使我们可以从数据库中一次性查询出所有数据,没出现连接超时问题,这么多的数据全部加载到应用服务的内存中,也有可能会导致应用服务出现OOM问题。
因此,我们从数据库中查询数据时,有必要使用分页查询。比如:每页5000条记录,分为200页查询。
public Page<User> searchUser(SearchModel searchModel) {List<User> userList = userMapper.searchUser(searchModel);Page<User> pageResponse = Page.create(userList, searchModel);pageResponse.setTotal(userMapper.searchUserCount(searchModel));return pageResponse;
}每页大小pageSize和页码pageNo,是SearchModel类中的成员变量,在创建searchModel对象时,可以设置设置这两个参数。
然后在Mybatis的sql文件中,通过limit语句实现分页功能:
limit #{pageStart}, #{pageSize}其中的pagetStart参数,是通过pageNo和pageSize动态计算出来的,比如:
pageStart = (pageNo - 1) * pageSize;4.多个sheet
我们知道,excel对一个sheet存放的最大数据量,是有做限制的,一个sheet最多可以保存1048576行数据。否则在保存数据时会直接报错:
invalid row number (1048576) outside allowable range (0..1048575)如果你想导出一百万以上的数据,excel的一个sheet肯定是存放不下的。
因此我们需要把数据保存到多个sheet中。
5.计算limit的起始位置
我之前说过,我们一般是通过limit语句来实现分页查询功能的:
limit #{pageStart}, #{pageSize}其中的pagetStart参数,是通过pageNo和pageSize动态计算出来的,比如:
pageStart = (pageNo - 1) * pageSize;如果只有一个sheet可以这么玩,但如果有多个sheet就会有问题。因此,我们需要重新计算limit的起始位置。
例如:
ExcelWriter excelWriter = EasyExcelFactory.write(out).build();
int totalPage = searchUserTotalPage(searchModel);if(totalPage > 0) {Page<User> page = Page.create(searchModel);int sheet = (totalPage % maxSheetCount == 0) ? totalPage / maxSheetCount: (totalPage / maxSheetCount) + 1;for(int i=0;i<sheet;i++) {WriterSheet writeSheet = buildSheet(i,"sheet"+i);int startPageNo = i*(maxSheetCount/pageSize)+1;int endPageNo = (i+1)*(maxSheetCount/pageSize);while(page.getPageNo()>=startPageNo && page.getPageNo()<=endPageNo) {page = searchUser(searchModel);if(CollectionUtils.isEmpty(page.getList())) {break;}excelWriter.write(page.getList(),writeSheet);page.setPageNo(page.getPageNo()+1);}}
}这样就能实现分页查询,将数据导出到不同的excel的sheet当中。
6.文件上传到OSS
由于现在我们导出excel数据的方案改成了异步,所以没法直接将excel文件,同步返回给用户。
因此我们需要先将excel文件存放到一个地方,当用户有需要时,可以访问到。
这时,我们可以直接将文件上传到OSS文件服务器上。
通过OSS提供的上传接口,将excel上传成功后,会返回文件名称和访问路径。
我们可以将excel名称和访问路径保存到表中,这样的话,后面就可以直接通过浏览器,访问远程excel文件了。
而如果将excel文件保存到应用服务器,可能会占用比较多的磁盘空间。
一般建议将应用服务器和文件服务器分开,应用服务器需要更多的内存资源或者CPU资源,而文件服务器需要更多的磁盘资源。
7.通过WebSocket推送通知
通过上面的功能已经导出了excel文件,并且上传到了OSS文件服务器上。
接下来的任务是要本次excel导出结果,成功还是失败,通知目标用户。
有种做法是在页面上提示:正在导出excel数据,请耐心等待。
然后用户可以主动刷新当前页面,获取本地导出excel的结果。
但这种用户交互功能,不太友好。
还有一种方式是通过webSocket建立长连接,进行实时通知推送。
如果你使用了SpringBoot框架,可以直接引入webSocket的相关jar包:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId>
</dependency>使用起来挺方便的。
我们可以加一张专门的通知表,记录通过webSocket推送的通知的标题、用户、附件地址、阅读状态、类型等信息。
能更好的追溯通知记录。
webSocket给客户端推送一个通知之后,用户的右上角的收件箱上,实时出现了一个小窗口,提示本次导出excel功能是成功还是失败,并且有文件下载链接。
当前通知的阅读状态是未读。
用户点击该窗口,可以看到通知的详细内容,然后通知状态变成已读。
8.总条数可配置
我们在做导百万级数据这个需求时,是给用户用的,也有可能是给运营同学用的。
其实我们应该站在实际用户的角度出发,去思考一下,这个需求是否合理。
用户拿到这个百万级别的excel文件,到底有什么用途,在他们的电脑上能否打开该excel文件,电脑是否会出现太大的卡顿了,导致文件使用不了。
如果该功能上线之后,真的发生发生这些情况,那么导出excel也没有啥意义了。
因此,非常有必要把记录的总条数,做成可配置的,可以根据用户的实际情况调整这个配置。
比如:用户发现excel中有50万的数据,可以正常访问和操作excel,这时候我们可以将总条数调整成500000,把多余的数据截取掉。
其实,在用户的操作界面,增加更多的查询条件,用户通过修改查询条件,多次导数据,可以实现将所有数据都导出的功能,这样可能更合理一些。
此外,分页查询时,每页的大小,也建议做成可配置的。
通过总条数和每页大小,可以动态调整记录数量和分页查询次数,有助于更好满足用户的需求。
9.order by商品编号
之前的需求是要将相同商品编号的数据放到一起。
例如:
编号 | 商品名称 | 仓库名称 | 价格 |
1 | 笔记本 | 北京仓 | 7234 |
1 | 笔记本 | 上海仓 | 7235 |
1 | 笔记本 | 武汉仓 | 7236 |
2 | 平板电脑 | 成都仓 | 7236 |
2 | 平板电脑 | 大连仓 | 3339 |
但我们做了分页查询的功能,没法将数据一次性查询出来,直接在Java内存中分组或者排序。
因此,我们需要考虑在sql语句中使用order by 商品编号,先把数据排好顺序,再查询出数据,这样就能将相同商品编号,仓库不同的数据放到一起。
此外,还有一种情况需要考虑一下,通过配置的总记录数将全部数据做了截取。
但如果最后一个商品编号在最后一页中没有查询完,可能会导致导出的最后一个商品的数据不完整。
因此,我们需要在程序中处理一下,将最后一个商品删除。
但加了order by关键字进行排序之后,如果查询sql中join了很多张表,可能会导致查询性能变差。
那么,该怎么办呢?
总结
最后用两张图,总结一下excel异步导数据的流程。
如果是使用mq导数据:

如果是使用job导数据:
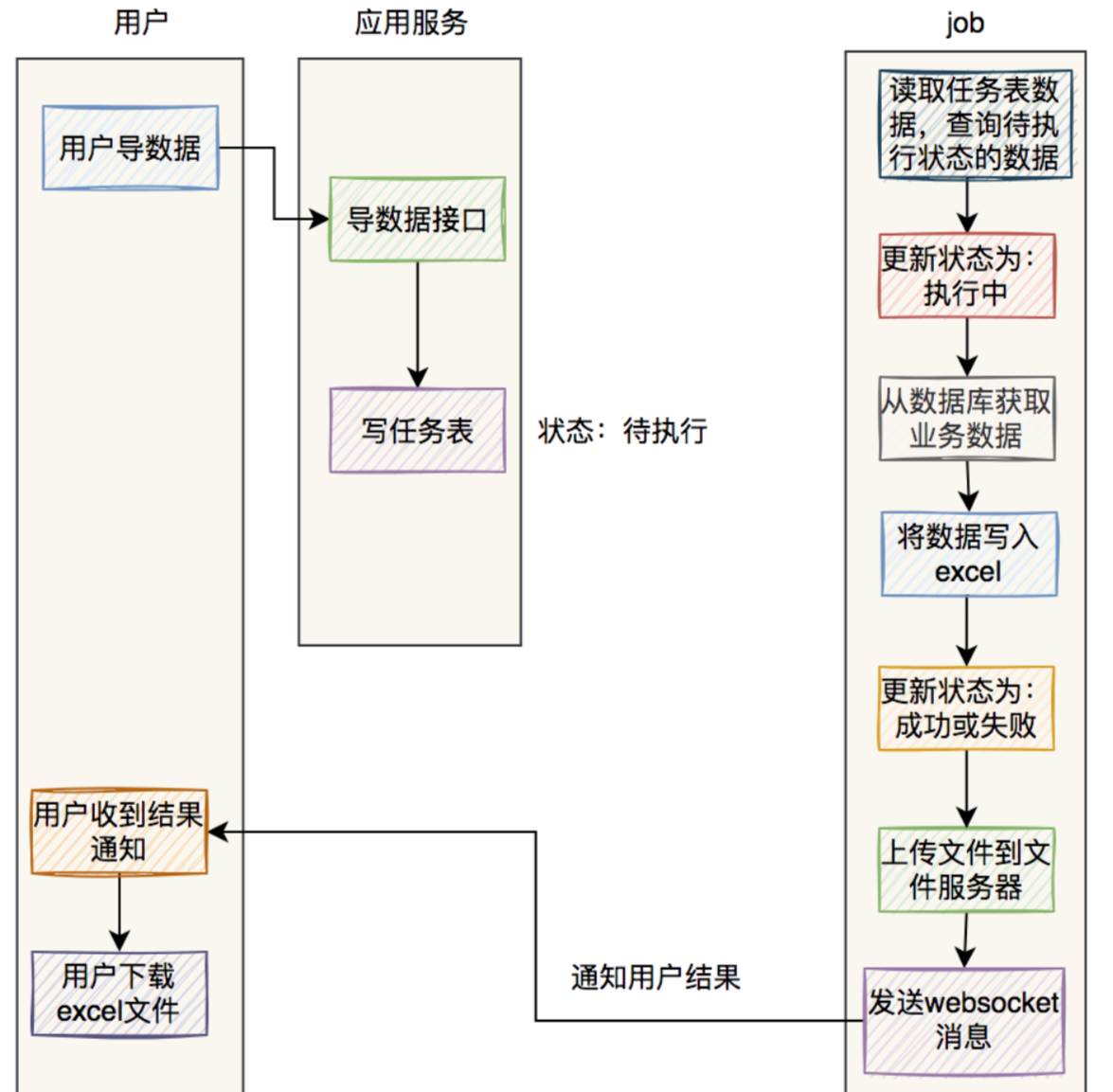
这两种方式都可以,可以根据实际情况选择使用。
相关文章:
基于easyexcel的MySQL百万级别数据的excel导出功能
前言最近我做过一个MySQL百万级别数据的excel导出功能,已经正常上线使用了。这个功能挺有意思的,里面需要注意的细节还真不少,现在拿出来跟大家分享一下,希望对你会有所帮助。原始需求:用户在UI界面上点击全部导出按钮…...

js-DOM02
1.DOM查询 - 通过具体的元素节点来查询 - 元素.getElementsByTagName() - 通过标签名查询当前元素的指定后代元素 - 元素.childNodes - 获取当前元素的所有子节点 - 会获取到空白的文本子节点 …...
作为一名开发工程师,我对 ChatGPT 的一些看法
ChatGPT 又又火了。 ChatGPT 第一次爆火是2022年12月的时候,我从一些球友的讨论中知道了这个 AI 程序。 今年2月,ChatGPT 的热火更加猛烈,这时我才意识到,原来上次的热火只是我们互联网圈子内部火了,这次是真真正正的破圈了,为大众所熟悉了。 这个 AI 程序是一个智能问…...

Flask中基于Token的身份认证
Flask提供了多种身份认证方式,其中基于Token的身份认证是其中一种常用方式。基于Token的身份认证通常是在用户登录之后,为用户生成一个Token,然后在每次请求时用户将该Token作为请求头部中的一个参数进行传递,服务器端在接收到请求…...
波奇学数据结构:时间复杂度和空间复杂度
数据结构:计算机存储,组织数据方式。数据之间存在多种特定关系。时间复杂度:程序基本操作(循环等)执行的次数大O渐进法表示法用最高阶的项来表示,且常数变为1。F(n)3*n^22n1//F(n)为…...

移动OA办公系统为企业带来便捷办公
移动OA系统是指企业员工同手机等移动设备来使用OA办公系统,在外出差的员工只需要通过OA系统的手机APP就可以接收相关的新信息。PC办公与移动OA办公的相结合,构建用户单位随时随地办公的一体化环境。 相比PC办公,移动OA办公给企业带来更多的便…...

什么是Type-c口?Type-c口有什么优势?
什么是Type-C接口 Type-C接口有哪些好处坏处 说起“Type-C”,相信大家都不会陌生,因为最近拿它大做文章的厂商着实不少,但要具体说清楚Type-C是什么,估计不少人只能说出“可以正反插”“USB的一种”之类的大概。其实,T…...
)
Go开发者常犯的错误,及使用技巧 (1)
代码规范 命名不规范 变量名要有意义,不能随便取a,b,c 如果只是纯粹的算法题,这样问题不大。但工程上的代码可读性要求较高,不能随意命名变量名,例如: for _, v : range userList {// ... }如果for语句块简短还好&…...

Servlet 作业
一、填空题1. Servlet 中使用Session 对象的步骤为:调用HttpServletRequest.getSession()的得到Session对象,查看Session对象,在会话中保存数据。2. http 全称是_HyperText Transfer Protocol3. 用户可以有多种方式请求Servlet,如…...

Hive高阶函数:explode函数、Lateral View侧视图、聚合函数、增强聚合
Hive高阶函数 文章目录Hive高阶函数explode函数Lateral View侧视图原理语法聚合函数增强聚合grouping setsCUBEROLL UPexplode函数 explode接收map、array类型的数据作为输入,然后把输入数据中的每个元素拆开变成一行数据,一个元素一行。explode执行效果…...

信息系统服务管理
一、信息系统服务业及发展二、信息系统工程监理的概念及发展三、信息系统运行维护的概念和发展 IT服务管理(ITSM) 四、信息技术服务管理的标准和框架 IT服务标准体系(ITSS) 一、信息系统服务业及发展 总结:前景很好 二、信息系…...
Windows10 安装ElasticStack8.6.1
一、安装ElasticSearch8.6.1 1.官网下载ElasticSearch8.6.1压缩包后解压 2.安装为服务 elasticsearch-service.bat install 3.运行 elasticsearch-service.bat start 4.通过浏览器访问 http://localhost:9200/ 提示需要登录,但不知密码是啥。 5.重置密码 ela…...
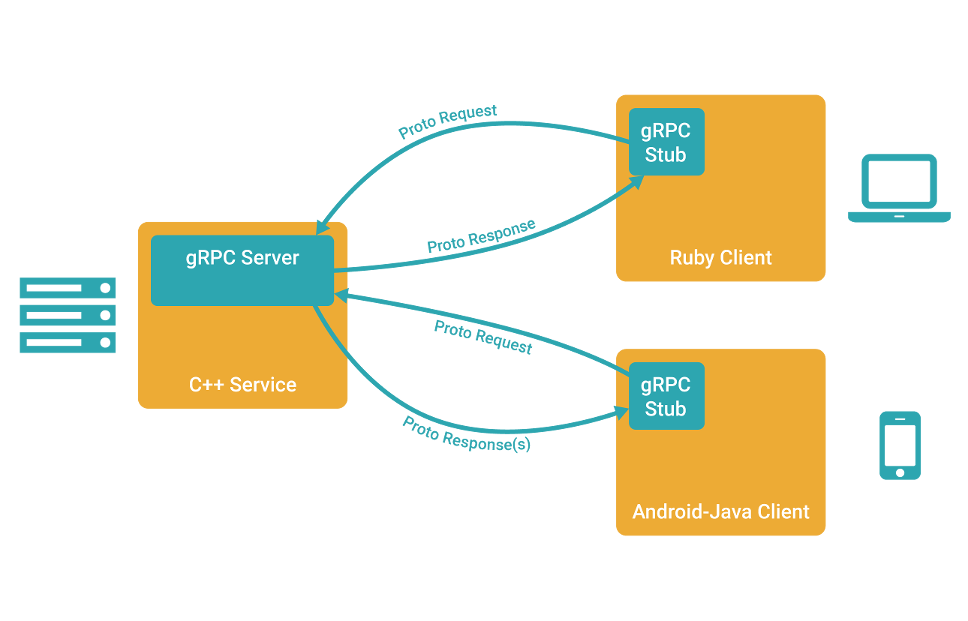
gRPC 非官方教程
一、 简介 gRPC的定义: 一个高性能、通用的开源RPC框架主要面向移动应用开发: gRPC提供了一种简单的方法来精确地定义服务和为iOS、Android和后台支持服务自动生成可靠性很强的客户端功能库。基于HTTP/2协议标准而设计,基于ProtoBuf(Protoc…...

6.2【人工智能与深度学习】RNN、GRU、远程服务管理、注意力、Seq2 搜索引擎和内存网络
【人工智能与深度学习】RNN、GRU、远程服务管理、注意力、Seq2 搜索引擎和内存网络底层原理介绍 深度学习架构循环神经网络(RNN)循环网络:摊开循环的网络的循环循环神经网络的技巧乘法模组注意模组门控循环单元(GRU)长期短期记忆(Long Short-Term Memory,简称LSTM)序列到序列…...

软件工程复习
软件工程简介 软件: -在执行时提供所需的功能和性能的指令; -使程序能够充分操作信息的数据结构; -描述这些程序的操作和使用情况的文档。 软件定义:计算机程序和相关文档。 软件特点:软件没有质量;它并不…...
)
将Nginx 核心知识点扒了个底朝天(二)
Nginx 是如何实现高并发的? 如果一个 server 采用一个进程(或者线程)负责一个request的方式,那么进程数就是并发数。那么显而易见的,就是会有很多进程在等待中。等什么?最多的应该是等待网络传输。 而 Nginx 的异步非阻塞工作方…...
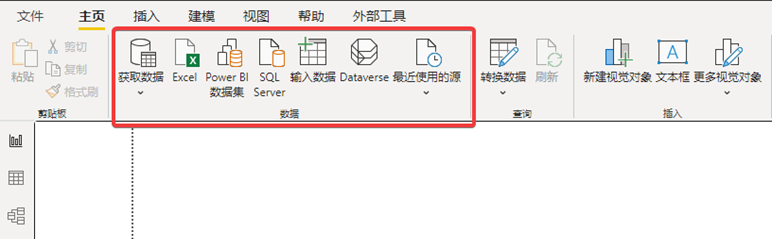
【PowerQuery】PowerBI 的PowerQuery支持的数据集成
PowerBI中的各个Power组件已经被深度集成到PowerBI中,不再作为像Excel一样的独立组件而存在。在PowerBI的界面中为了快速导入这些常用的数据,也有相应的快速导入界面。PowerBI的快速导入界面位于主页面中,下图就是PowerBI的快速导入界面。 在PowerBI中的数据导入界面相比Exc…...
scipy spatial transform Rotation库的源代码
前几日研究scipy的旋转,不知道具体里面怎么实现的,因此搜索一番。 发现Rotation在scipy的表达是用四元数的 https://github.com/jgagneastro/coffeegrindsize/edit/master/App/dist/coffeegrindsize.app/Contents/Resources/lib/python3.7/scipy/spatia…...
JAVA文件操作
JAVA文件操作 文章目录JAVA文件操作1.属性2.构造方法3.方法3.1创建文件3.2 文件删除3.3创建目录3.4文件名3.5 文件重命名3.6查看文件的可读性 Java中通过 java.io.file类来对文件(目录)进行抽象的描述。注意, 有File对象时,不代表真实存在该文件。1.属…...

字符串匹配 - 模式预处理:BM 算法 (Boyer-Moore)
各种文本编辑器的"查找"功能(CtrlF),大多采用Boyer-Moore算法,效率非常高。算法简介在 1977 年,Robert S. Boyer (Stanford Research Institute) 和 J Strother Moore (Xerox Palo Alto Research Center) 共…...

GlitchTip:开源错误追踪平台完全指南:Sentry替代方案的完整教程
GlitchTip:开源错误追踪平台完全指南:Sentry替代方案的完整教程 背景 在应用开发和运维过程中,错误追踪是保障服务质量的关键环节。Sentry 作为业界领先的错误追踪服务,提供了强大的错误收集和分析能力,但其云服务版…...

【权威认证|Pydantic v2+Starlette v1.12+FastAPI 2.0深度兼容报告】:为什么你的async generator在/ai/chat接口里静默失败?
第一章:FastAPI 2.0 异步 AI 流式响应 避坑指南FastAPI 2.0 对异步流式响应(StreamingResponse)的底层行为进行了关键调整,尤其在事件循环绑定、响应体缓冲策略及客户端断连检测方面与 1.x 版本存在显著差异。若沿用旧版流式生成器…...

如何免费阅读付费文章?终极智能内容解锁工具完全指南
如何免费阅读付费文章?终极智能内容解锁工具完全指南 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在这个信息爆炸的时代,你是否经常遇到这样的情况…...

塑胶件防裂实践:3D检测亲测有效
行业痛点分析在精密制造领域,塑胶件开裂是长期困扰工程师的顽疾。传统检测手段,如卡尺、三坐标测量机(CMM)或二维影像测量,存在明显局限。它们难以对复杂曲面、内部应力集中区域进行非接触式、全尺寸的量化评估&#x…...

P1122 最大子树和
题目描述 小明对数学饱有兴趣,并且是个勤奋好学的学生,总是在课后留在教室向老师请教一些问题。一天他早晨骑车去上课,路上见到一个老伯正在修剪花花草草,顿时想到了一个有关修剪花卉的问题。于是当日课后,小明就向老…...

14 年 Java 老码农,重启 CSDN:从 2012 到 2026,我的技术成长与重启之路
图:我的 CSDN 主页,2012 年 8 月 13 日注册,2014 年分享的第一篇 SSH 框架相关文章。 14 年过去,从青涩的 Java 工具类到现在的 DevOps 科研 AI,账号尘封多年,今天正式重启。 一、2012–2026:…...

网易云音乐无损音乐下载器:5分钟搞定你的私人音乐库终极方案
网易云音乐无损音乐下载器:5分钟搞定你的私人音乐库终极方案 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 还在为网易云音乐的无损音乐无…...
)
别再乱找了!Win11/Win10下WSL的wsl.conf和.wslconfig文件路径全解析(附修改教程)
WSL配置文件定位与修改实战指南:从路径解析到高效配置 1. 理解WSL配置体系的核心架构 每次启动WSL时,系统会按照特定顺序加载两类配置文件:.wslconfig和wsl.conf。这两者虽然名称相似,但作用域和功能定位完全不同,理解…...

Qwen3智能字幕对齐系统在CSDN技术视频生态中的应用实践
Qwen3智能字幕对齐系统在CSDN技术视频生态中的应用实践 1. 引言 做技术视频的博主和讲师们,应该都遇到过这样的烦恼吧。辛辛苦苦录完一个小时的编程教程,光是剪辑和加字幕就得再花上大半天。尤其是字幕,要么得自己一句一句听写,…...

告别右键菜单臃肿困境:ContextMenuManager如何实现40%效率提升
告别右键菜单臃肿困境:ContextMenuManager如何实现40%效率提升 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 当你右键点击文件时,是否遇…...