数据分析:旅游景点销售门票和消费情况分析
数据分析:旅游景点销售门票和消费情况分析
文章目录
- 数据分析:旅游景点销售门票和消费情况分析
- 一、前言
- 二、数据准备
- 三、分析数据
- 四、用户购买门票数量分析
- 五、用户复购分析
- 六、用户回购分析
- 七、占比分析
- 1.每个月分层用户占比情况。
- 2.每月不同用户的占比
- 3.每月活跃用户的占比
- 4.每月回流用户占比
- 励志语录
一、前言
旅游景区作为旅游业持续发展的重要载体,在旅游业中起到中流砥柱的作用。随着人们的生活水平的不断提升,对旅游服务质量的要求也越来越高,特别是在旅游景区,大部分游客已经不再满足于现有的旅游服务水平,因此旅游景区服务质量的改善提升对旅游景区的发展具有一定的现实意义。目前,由于互联网大数据时代的来临,网络数据呈爆炸式增长,可以通过各种网站游客的评论数据获得游客对于旅游景区的感知情况。但这类数据随意性、社会性、分散性等特点,很难直接使用,文本分析技术应运而生。本文使用文本分析技术从冗杂的评论数据中识别出用户谈论的主要文本内容,提炼旅游景区应该主要关注问题。本文基于游客感知的视角,通过分析、挖掘游客对旅游景区的网络评论了解游客对景区形象的评价和感受。(来自于网络)
二、数据准备
1.导入所需要的模块。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei']# 用来正常显示中文标签
from datetime import datetime
2.导入数据,查看前十数据。
df = pd.read_csv(r"C:\Users\XWJ\Desktop\kelu.csv")
df.head()
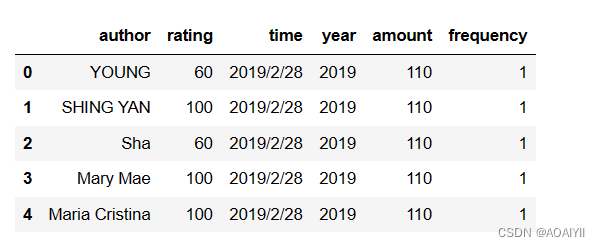
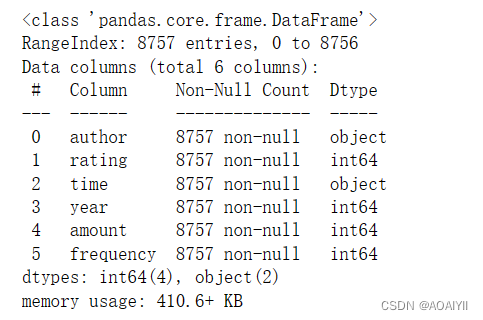
3.使用函数info():数据表的基本信息(维度,列名称,数据格式,所占空间等)。
df.info()
4…使用describe()函数,计算数据集中每列的总数、均值、标准差、最小值、25%、50%、75%分位数以及最大值。
df.describe()
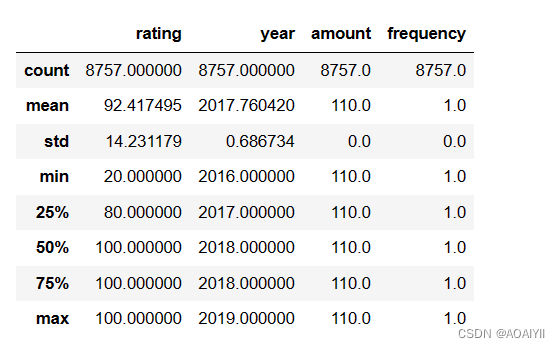
根据平均分92,和1/2分位得知,大多数用户评分在100,效果非常不错。
16年~19年门票价格都是110。
三、分析数据
1.每天销量分析。
df['time'] = pd.to_datetime(df['time'],format='%Y/%m/%d')
df.groupby('time')['rating'].count().plot(figsize=(12,4))
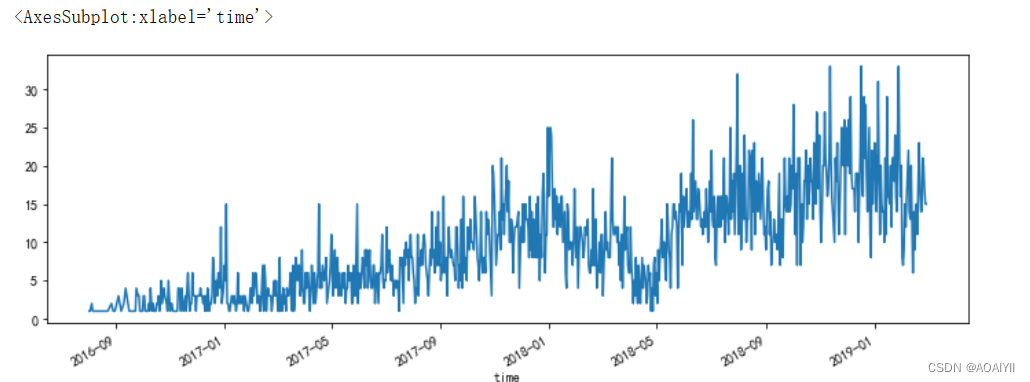
整体来看每日销量呈现上升趋势,但是在18年5月份前后(2,3,4)出现一次较大的波动,销量急剧下滑,猜测:台风,疫情,运营推广不利。
6年9月~17年1月,销量非常低,每天平均2-3张门票,猜测:101观景台门票刚刚上线发售,观景台刚刚对游客进行开放。
2.每月销量分析。
df['month'] = df['time'].values.astype('datetime64[M]') #保留月份精度的日期
df.head()
df.groupby('month')['rating'].count().plot(figsize=(12,4)) #按照月份进度进行计数
plt.xlabel('月份')
plt.ylabel('销售数量')
plt.title('16~19年每月销量分析')
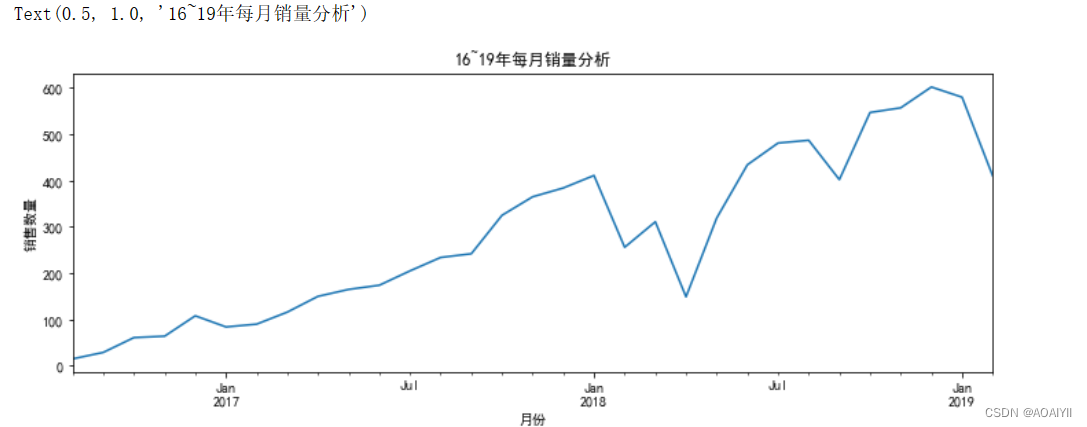
月份整体销量依然呈现上升趋势,但是在18年2,3,4月份月销量下滑明显。跟每天销量下降有关。猜测:台风,疫情,运营推广不利。
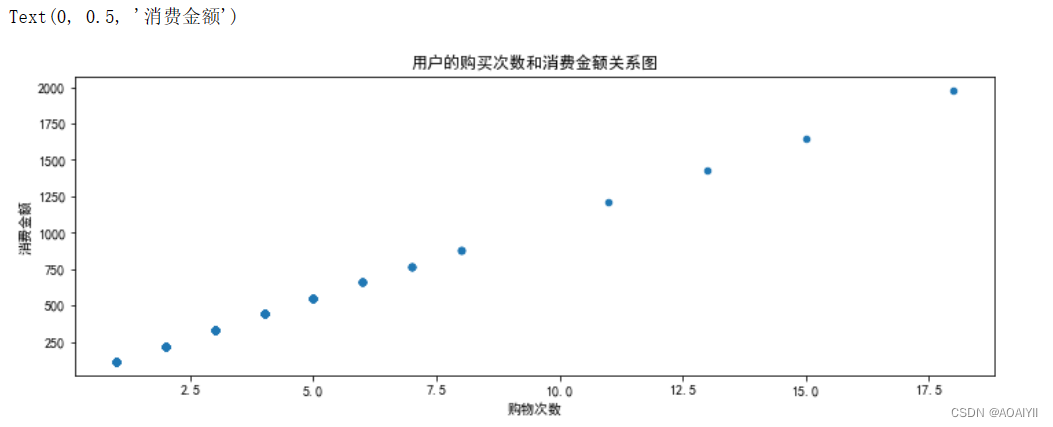
3.每个用户的购买量和消费金额分析。
df1 = pd.DataFrame({'name':['zhangsan','lisi'],'group':['A','B']
})
df2 = pd.DataFrame({'name':['wangwu','lisi'],'score':[88,90],'group':['C','D']
})
pd.merge(left=df1,right=df2,on='name',how='inner',suffixes=['_1','_2'])

#按照游客分组,统计每个游客的购买次数
grouped_count_author = df.groupby('author')['frequency'].count().reset_index()
#按照游客分组,统计每个游客的消费金额
grouped_sum_amount = df.groupby('author')['amount'].sum().reset_index()
user_purchase_retention = pd.merge(left=grouped_count_author,right=grouped_sum_amount,on='author',how='inner')
user_purchase_retention.tail(60)
user_purchase_retention.plot.scatter(x='frequency',y='amount',figsize=(12,4))
plt.title('用户的购买次数和消费金额关系图')
plt.xlabel('购物次数')
plt.ylabel('消费金额')
四、用户购买门票数量分析
1.用户购买门票数量。
df.groupby('author')['frequency'].count().plot.hist(bins=50) #影响柱子的宽度,宽度= (最大值-最小值)/bins
plt.xlim(1,17)
plt.xlabel('购买数量')
plt.ylabel('人数')
plt.title('用户购买门票数量直方图')
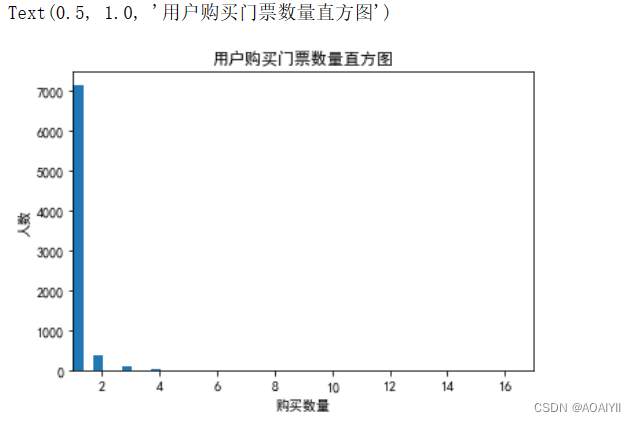
绝大多数用户购买过1张门票,用户在7000人次左右。
少数人购买过2~4张门票,猜测:可能是台北周边用户。
2.用户购买门票2次及以上情况分析。
df_frequency_2 = df.groupby('author').count().reset_index()
df_frequency_2.head()
df_frequency_2[df_frequency_2['frequency']>=2].groupby('author')['frequency'].sum().plot.hist(bins=50)
plt.xlabel('购买数量')
plt.ylabel('人数')
plt.title('购买门票在2次及以上的用户数量')
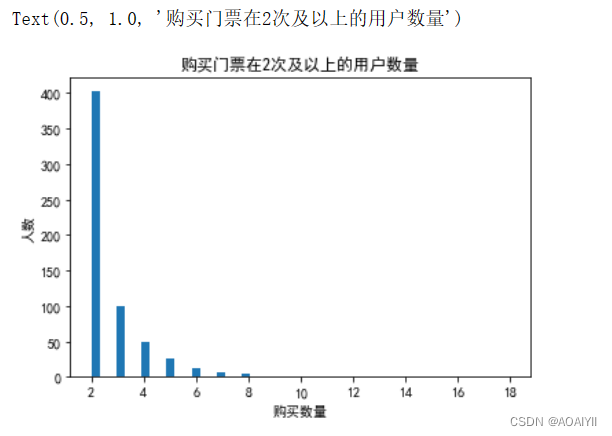
消费两次的用户在整体上占比较大,大于2次的用户占小部分,用户购买次数最多为8次。
3.查看购买2次及以上的具体人数。
df_frequency_2[df_frequency_2['frequency']>=2].groupby('frequency')['author'].count()

出去购买一次的顾客,可以看出购买2次有402人,购买3次的99人,以此类推得知大多数据倾向于购买2~5。
4.购买次数在1~5次之间的用户占比分析。
#1.按照用户进行分组 2.取出购买次数 3.过滤出1~5次用户 4.绘制饼图
df_frequency_gte_1 = df.groupby('author')['frequency'].count().reset_index()
#过滤出<=5次的用户
values = list(df_frequency_gte_1[df_frequency_gte_1['frequency']<=5].groupby('frequency')['frequency'].count())
print(values)
plt.pie(values,labels=['购买1次','购买2次','购买3次','购买4次','购买5次'],autopct='%1.1f%%')
plt.title('购买次数在1~5次之间的人数占比')
plt.legend()
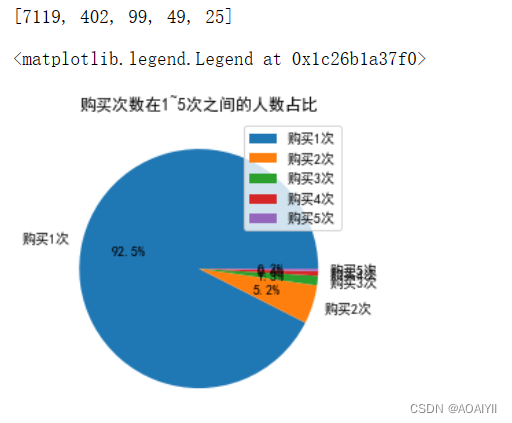
可以看出购买一次的占比83%,其次逐渐递减。并且递减比较明显,购买3.4.5的占比相近,人数都很少。
5.购买次数在2~5次之间的用户占比分析。
#过滤出>=2次并且<=5次的用户
df_frequency_gte_2 = df_frequency_2[df_frequency_2['frequency']>=2].reset_index()
values = list(df_frequency_gte_2[df_frequency_gte_2['frequency']<=5].groupby('frequency')['frequency'].count())
print(values)
plt.pie(values,labels=['购买2次','购买3次','购买4次','购买5次'],autopct='%1.1f%%')
plt.title('购买次数在2~5次之间的人数占比')
plt.legend()
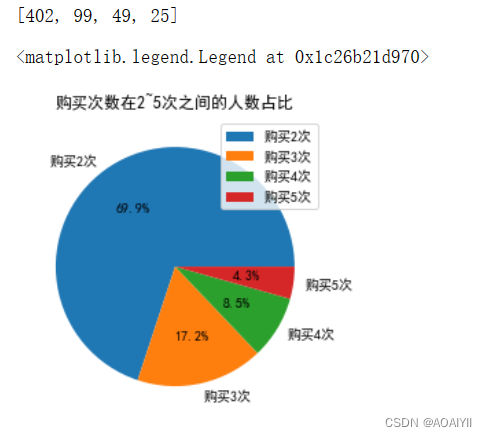
在2~5次之间,购买2.3次用户占比最大,综合占据了80%
五、用户复购分析
1.复购率分析。
复购率:在某一时间窗口内(多指一个月)内消费次数在两次及以上的用户在总消费用户的占比
三种情况:
消费次数>1,为复购用户,用1表示
消费次数=1,为非复购用户,用0表示
消费次数=0, 未消费用户,用na表示
applymap:df,处理每一个元素
apply:df,处理每一行或者每一列数据
map:Serise,处理每一个元素
pivot_count = df.pivot_table(index='author',columns='month',values='frequency',aggfunc='count').fillna(0)
pivot_count = pivot_count.applymap(lambda x: 1 if x>1 else np.NAN if x==0 else 0)
# pivot_count[pivot_count['2016-09-01']==1]
(pivot_count.sum()/pivot_count.count()).plot()
plt.xlabel('时间(月)')
plt.ylabel('百分比(%)')
plt.title('16~19年每月用户复购率')
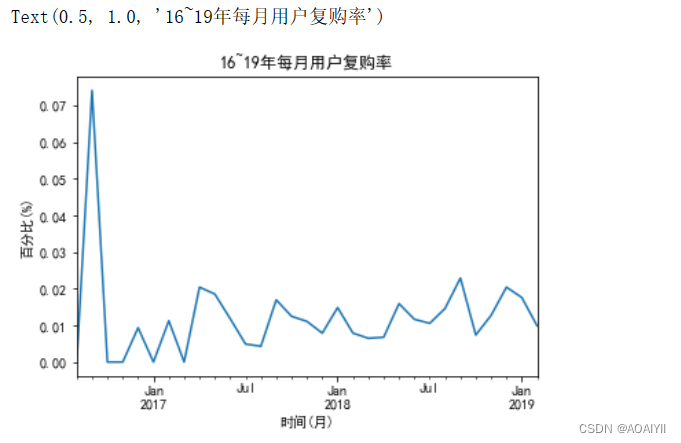
16年9月份复购率最高达到了7.5%,然后开始下降,趋于平稳在1.2%。
2.复购用户人数。
pivot_count.sum().plot()
plt.xlabel('时间/月')
plt.ylabel('复购人数')
plt.title('16~19年每月的复购人数折线图')
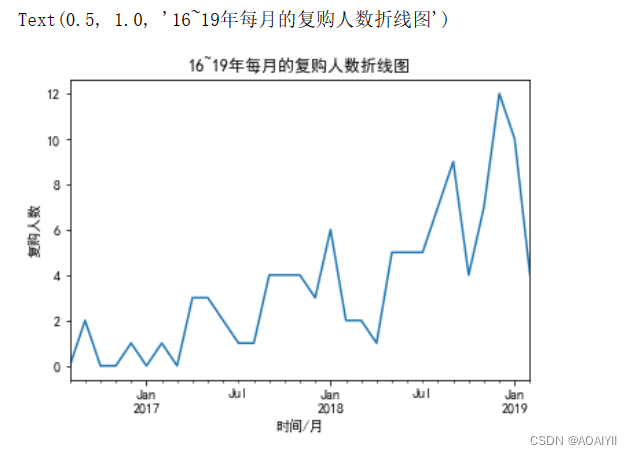
整体来看,复购人数长线上升趋势。
但是在18年2.3.4.10和19年2月份,复购人数下降较为明显,出现异常信号,需要和业务部门具体分析情况。
六、用户回购分析
1.回购率分析。
回购率:在某一个时间窗口内消费过的用户,在下一个时间窗口仍旧消费的占比
pivot_purchase = df.pivot_table(index='author',columns='month',values='frequency',aggfunc='count').fillna(0)
pivot_purchase.head()def purchase_return(data): #data:代表的是每一名游客的所有月份消费记录status = [] #存储每一个月回购状态for i in range(30):#遍历每一个月(最后一个月除外)####本月消费if data[i] == 1:if data[i+1] ==1:#下个月有消费,是回购用户,1status.append(1)else:#na|未消费status.append(0) #非回购用户,0else: ####本月未消费status.append(np.NaN)status.append(np.NaN)return pd.Series(status,pivot_purchase.columns)
pivot_purchase_return = pivot_purchase.apply(purchase_return,axis=1) #用户回购状态
(pivot_purchase_return.sum()/pivot_purchase_return.count()).plot()
plt.title('16年~19年每月的回购率')
plt.xlabel('月份')
plt.ylabel('回购率%')
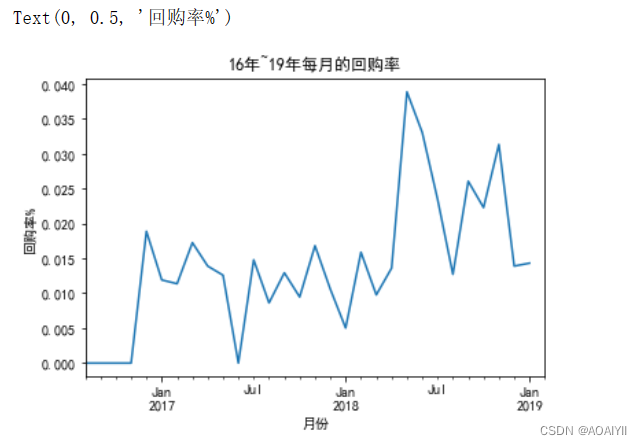
回购率最高在18年6月份,达到4%
整体来看,回购率呈现微弱上升趋势
出现了几次较大下滑,分别是17年6月份,18年1月份,18年8月份,19年1月份
2.回购人数分析。
pivot_purchase_return.sum().plot()
plt.title('16年~19年每月的回购人数')
plt.xlabel('月份')
plt.ylabel('回购人数')
print(pivot_purchase_return.sum())
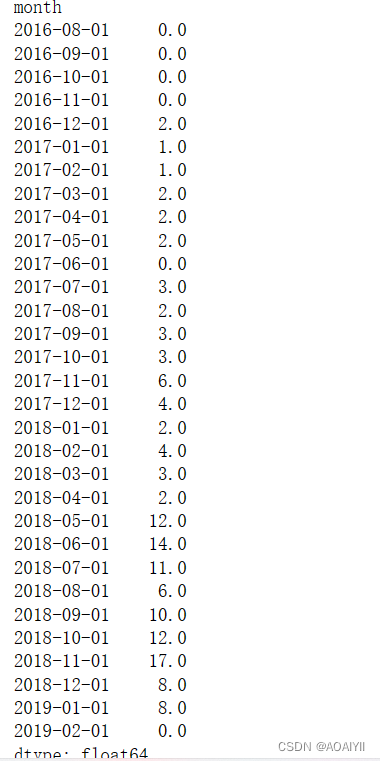
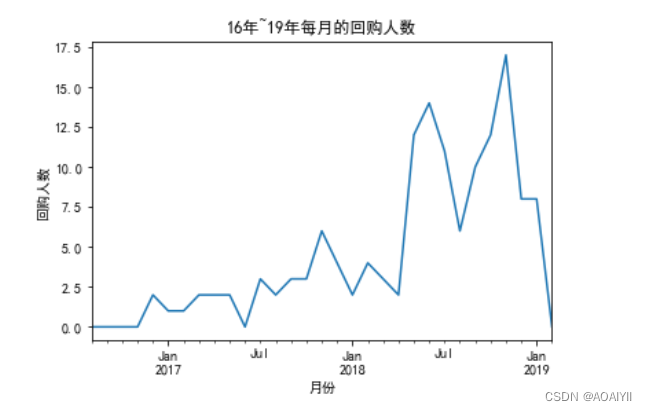
整体呈现上升趋势,回购人数最多时在18年11月份,人数未17人
其中有几次回购人数下降较为明显,主要在分别是17年6月份,18年1月份,18年8月份,19年1月份
七、占比分析
1.每个月分层用户占比情况。
#活跃用户|不活跃用户|回流用户|新用户
def active_status(data): #data:每一行数据(共31列)status = [] #存储用户31个月的状态(new|active|unactive|return|unreg)for i in range(31):#判断本月没有消费==0if data[i] ==0:if len(status)==0: #前几个月没有任何记录(也就是97年1月==0)status.append('unreg') else:#之前的月份有记录(判断上一个月状态)if status[i-1] =='unreg':#一直没有消费过status.append('unreg')else:#上个月的状态可能是:new|active|unative|reuturnstatus.append('unactive')else:#本月有消费==1if len(status)==0:status.append('new') #第一次消费else:#之前的月份有记录(判断上一个月状态)if status[i-1]=='unactive':status.append('return') #前几个月不活跃,现在又回来消费了,回流用户elif status[i-1]=='unreg':status.append('new') #第一次消费else:#new|activestatus.append('active') #活跃用户return pd.Series(status,pivot_purchase.columns) #值:status,列名:18个月份
pivot_purchase_status =pivot_purchase.apply(active_status,axis=1)
pivot_status_count =pivot_purchase_status.replace('unreg',np.NaN).apply(pd.value_counts)
pivot_status_count.T.plot.area()
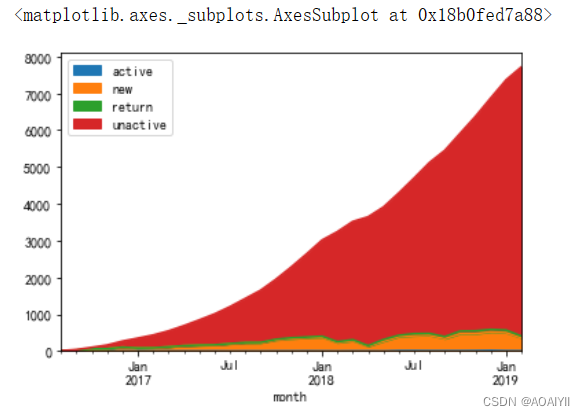
可以看出,红色(不活跃用户)占据网站用户的主体
橙色(新用户)从17年的1月~19年1月,呈现上升趋势;但是在18年4月份左右,新用户的量突然急剧下降,异常信号;
以后,新用户又开始逐渐上涨,回复稳定状态
绿色(回流用户),一直维持稳定稳定状态,但是在18年2~4月份,出现异常下降情况,异常信号;
2.每月不同用户的占比
return_rate = pivot_status_count.apply(lambda x:x/x.sum())
return_rate.T.plot()
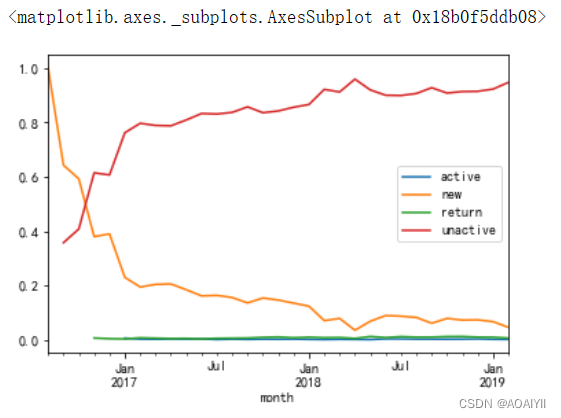
在17年1月份过后,网站用户主体由不活跃用户组成,新用户占比开始逐渐下降,并且趋于稳定,稳定在10%左右
活跃用户和会用户,一直很稳定,并且占比较小
16年9月前后,新用户和不活跃用户,发生较大的变化,猜测:活动或者节假日造成…
3.每月活跃用户的占比
return_rate.T['active'].plot(figsize=(12,6))
plt.xlabel('时间(月)')
plt.ylabel('百分比')
plt.title('每月活跃用户的占比分析')
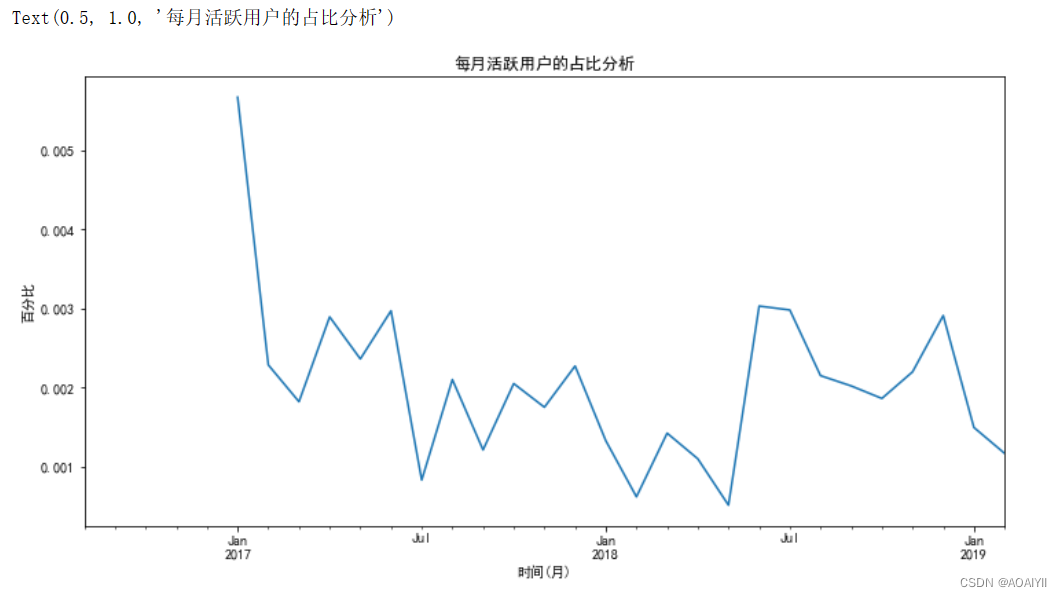
在17年1月份活跃用户占比较高,在0.5%,但是在1-2月份,急剧下降,猜测:春节的影响,或者温度
结合历年1~2月份销量来看,都会出现一定比例的下降,再次验证我们的猜测:春节的影响
在18年2月和5月出现异常,门票销量下降,猜测:雨水或者台风影响
4.每月回流用户占比
return_rate.T['return'].plot(figsize=(12,6))
plt.xlabel('时间(月)')
plt.ylabel('百分比')
plt.title('每月回流用户的占比分析')

整体来看,回流用户比例上升趋势,但是波动较大
在17年1月和6月,18年4月,19年2月,回流用户比例都出现了较大幅度下降,表现为异常信号
不论是回流用户还是活跃用户,在以上几个月份中都表现出下降趋势。
np.mean(return_rate.T['return'])
#0.00736823576229978
回流用户平均值在0.73%左右
在17年9月份以后,仅有连个异常点在平均值一下
在17年9月份以前,所有数据都显示出回流用户比例低于平均值,猜测:景点开放不久,很多游客尚未发现本景点;本景点在该平台上线不久
励志语录
人生从来没有固定的路线,决定你能够走多远的,并不是年龄,而是你的努力程度。无论到了什么时候,只要你还有心情对着糟糕的生活挥拳宣战,都不算太晚。迟做,总比不做好!
相关文章:
数据分析:旅游景点销售门票和消费情况分析
数据分析:旅游景点销售门票和消费情况分析 文章目录数据分析:旅游景点销售门票和消费情况分析一、前言二、数据准备三、分析数据四、用户购买门票数量分析五、用户复购分析六、用户回购分析七、占比分析1.每个月分层用户占比情况。2.每月不同用户的占比3…...
Android问题解决方案(一):Android 打空包后提示没有”android:exported“的属性设置
Android 打空包后提示没有”android:exported“的属性设置Android 打空包后提示没有”android:exported“的属性设置1、问题:2、文档3、参考链接:4、解决方案:Android 打空包后提示没有”android:exported“的属性设置 1、问题: …...
Portraiture2023最新版人像图像后期处理软件
2023全新发布Portraiture 4是专注于图像后期处理软件研发的 Imagenomic, LLC产品之一,在摄影爱好者中有点影响力。Portraiture可以将繁琐复杂的人像磨皮操作极致简化,不论是普通爱好者或专业后期处理人员,均能一键完成。凭借优秀的AI算法和多…...

链表OJ(七)删除有序链表中重复的元素-I -II
目录 删除有序链表中重复的元素-I 删除有序链表中重复的元素-II 删除有序链表中重复的元素-I 描述 删除给出链表中的重复元素(链表中元素从小到大有序),使链表中的所有元素都只出现一次 例如: 给出的链表为1→1→21→1→2,返回1…...

C语言经典编程题100例(81~100)
目录81、习题7-7 字符串替换82、习题8-10 输出学生成绩83、习题8-2 在数组中查找指定元素84、习题8-3 数组循环右移85、题8-9 分类统计各类字符个数86、习题9-2 计算两个复数之积87、习题9-6 按等级统计学生成绩88、习题11-1 输出月份英文名89、习题11-2 查找星期90、练习10-1 …...
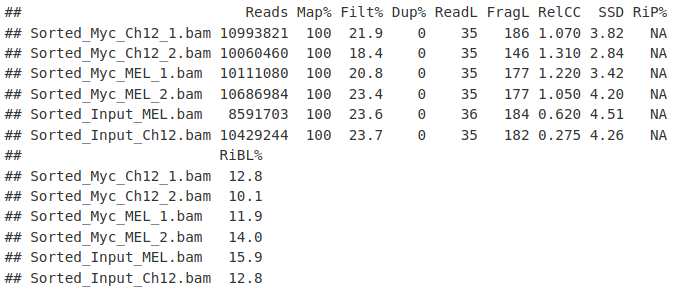
ChIP-seq 分析:数据质控实操(5)
1. 数据 今天将继续回顾我们在上一次中研究的 Myc ChIPseq。这包括用于 MEL 和 Ch12 细胞系的 Myc ChIPseq 及其输入对照。 可在此处[1]找到 MEL 细胞系中 Myc ChIPseq 的信息和文件可在此处[2]找到 Ch12 细胞系中 Myc ChIPseq 的信息和文件可以在此处[3]找到 MEL 细胞系的输入…...
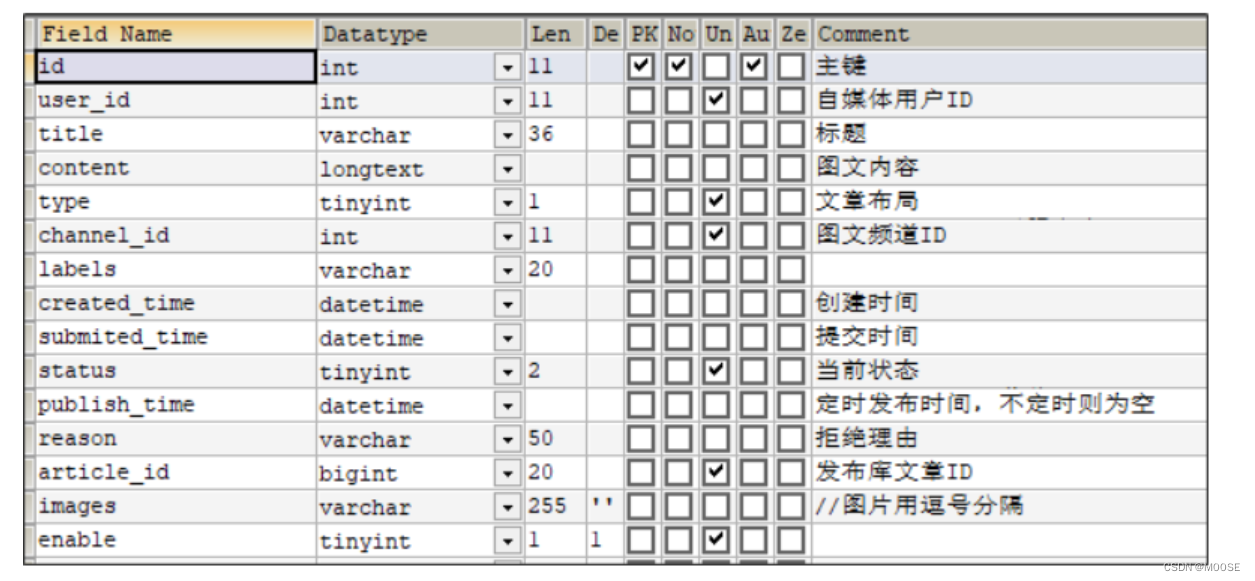
java黑马头条 day5自媒体文章审核 敏感词过滤算法DFA 集成RabbitMQ实现自动审核
自动审核流程介绍 做为内容类产品,内容安全非常重要,所以需要进行对自媒体用户发布的文章进行审核以后才能到app端展示给用户。2 WmNews 中status 代表自媒体文章的状态 status字段:0 草稿 1 待审核 2 审核失败 3 人工审核 4 人工审核通过 …...
python--matplotlib(1)
前言 Matplotlib画图工具的官网地址是 http://matplotlib.org/ Python环境下实现Matlab制图功能的第三方库,需要numpy库的支持,支持用户方便设计出二维、三维数据的图形显示。 正文 1.arange函数 arange函数需要三个参数,分别为起始点、终止…...
)
华为OD机试题 - 获取最大软件版本号(JavaScript)
最近更新的博客 华为OD机试题 - 任务总执行时长(JavaScript) 华为OD机试题 - 开放日活动(JavaScript) 华为OD机试 - 最近的点 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试题 - 最小步骤数(JavaScript) 华为OD机试题 - 任务混部(JavaScript) 华为OD机试题 - N 进…...
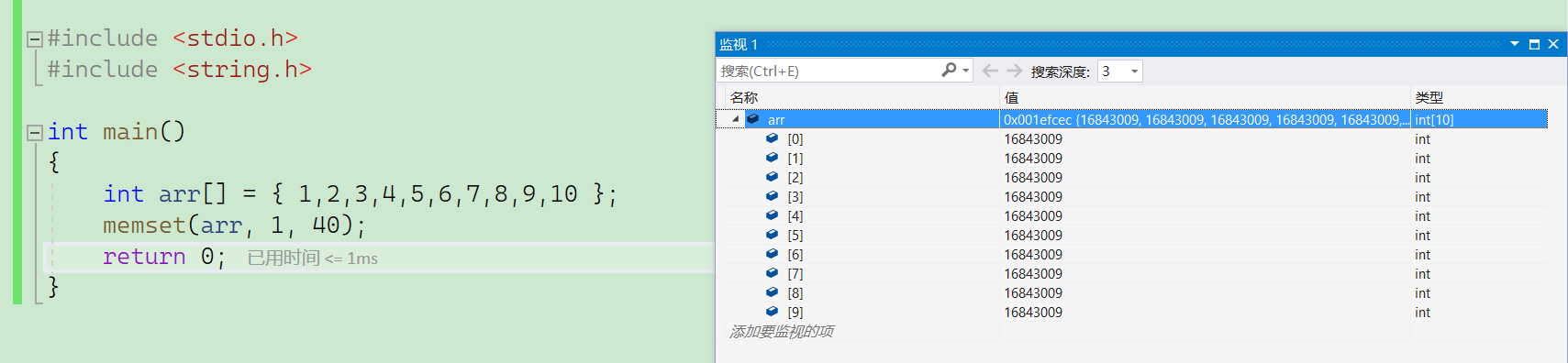
字符函数和字符串函数
字符串以\0为结束标志,strlen函数返回的是’\0’前的字符个数,不包括\0参数的指向的字符串必须是\0为结束标志,不然结果不确定函数的返回类型是size_t(无符号的整型)strlen的使用#include <stdio.h> #include <string.h&…...
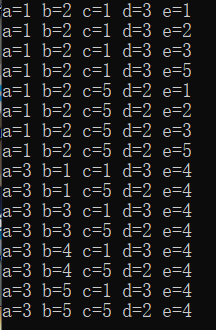
【猜名次】-C语言-题解
1. 描述: 5位运动员参加了10米台跳水比赛,有人让他们预测比赛结果: A选手说:B第二,我第三; B选手说:我第二,E第四; C选手说:我第一,D第二&#x…...
 和 hashCode() 的理解?)
对 equals() 和 hashCode() 的理解?
在 java.lang.Object 类中有两个非常重要的方法: public native int hashCode(); public boolean equals(Object obj) {return (this obj); }Object 类是类继承结构的基础,是每一个类的父类,都实现了Object 类中定义的方法。 equals()方法…...
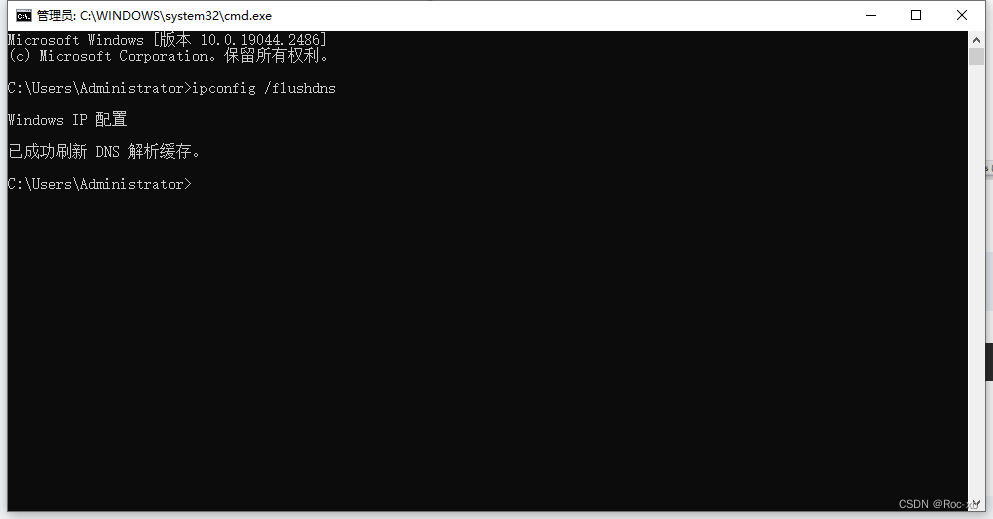
IDEA插件安装慢、超时、不成功问题如何解决?
目录 一、打开国内插件的节点IP地址 二、修改本地hosts文件 三、刷新DNS缓存 一、打开国内插件的节点IP地址 国内插件的节点IP地址查询: http://tool.chinaz.com/speedtest/plugins.jetbrains.com 在下方的检测结果中,找到一个解析时间最短的IP地址,解…...

软考高级之信息系统案例分析七重奏-《5》
五十、项目需求管理可能存在的问题。 1、未制定项目需求管理计划; 2、项目沟通存在问题; 3、项目经理缺乏必要的项目管理经验; 4、没有有效地管理需求变更控制; 5、没有有效地维护对需求进行跟踪管理; 6、没有按照规范的需求开发和需求管理的内容和流程开展需求工作…...
JUC并发编程 Ⅳ -- 共享模型之无锁
文章目录CAS 与 volatile问题引入代码分析volatile为什么无锁效率高CAS特点原子整数原子引用ABA 问题及解决原子数组原子(字段)更新器原子累加器UnsafeUnsafe CAS 操作管程即 monitor 是阻塞式的悲观锁实现并发控制,本文我们将通过非阻塞式的乐观锁的来实现并发控制…...

Spring之AOP实现
1. AOP的实现方式 使用AspectJ的编译器来改动class类文件实现增强(使用不广泛) ----- 编译阶段 这种对class类文件增强的, 也可以增强static静态方法, 而通过代理方式就无法实现静态方法的增强 可通过查看编译后class文件反编译后的java代码验证 agent增强(使用不广泛) ----- 类…...
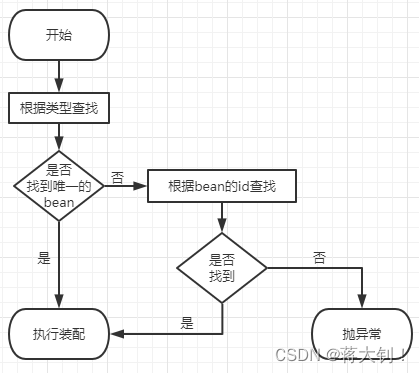
Spring之基于xml的自动装配、基于Autowired注解的自动装配
文章目录基于xml的自动装配①注解②扫描③新建Maven Module④创建Spring配置文件⑤标识组件的常用注解⑥创建组件⑦扫描组件⑧测试⑨组件所对应的bean的id基于注解的自动装配①场景模拟②Autowired注解③Autowired注解其他细节④Autowired工作流程Autowire 注解的原理Qualifier…...
轻量级任务调度平台)
【案例】--(非分布式)轻量级任务调度平台
目录 一、前言说明二、背景2.1、完成任务,顺便搭建了一个任务调度平台三、具体实现解析3.1、技术栈等选型3.2、完成具体功能解析(1)、支持基本任务功能(2)、支持日志收集功能(3)、支持用户异常,选择性关闭调度功能(4)、实时监控正在执行和任务队列的任务情况(5)、实时监控任务…...

key的作用原理与列表的遍历、追加、搜索、排序
目录 一、key的作用原理 二、实现列表遍历并对在列表最前方进行追加元素 三、实现列表过滤搜索 1、用computed计算属性来实现 2、用watch监听输入值的变化来实现 四、按年龄排序输出列表 一、key的作用原理 1. 虚拟DOM中key的作用: key是虚拟DOM对象的标识&a…...

SQL性能优化的47个小技巧,你了解多少?
收录于热门专栏Java基础教程系列(进阶篇) 1、先了解MySQL的执行过程 了解了MySQL的执行过程,我们才知道如何进行sql优化。 客户端发送一条查询语句到服务器;服务器先查询缓存,如果命中缓存,则立即返回存…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...

ubuntu系统文件误删(/lib/x86_64-linux-gnu/libc.so.6)修复方案 [成功解决]
报错信息:libc.so.6: cannot open shared object file: No such file or directory: #ls, ln, sudo...命令都不能用 error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directory重启后报错信息&…...