文本匹配SimCSE模型代码详解以及训练自己的中文数据集
前言
在上一篇博客文本匹配中的示例代码中使用到了一个SimCSE模型,用来提取短文本的特征,然后计算特征相似度,最终达到文本匹配的目的。但是该示例代码中的短文本是用的英文短句,其实SimCSE模型也可以用于中文短文本的特征提取,本篇博客就基于苏沐剑发表于科学空间的中文任务还是SOTA吗?我们给SimCSE补充了一些实验博客中使用到的代码,来记录一下代码梳理的笔记,并且使用自己的数据集在这篇代码上进行训练。另外,关于这个模型的原理细节等,可以参考别的博主写的内容,还有就是作者的论文,这些会附在最后的参考链接。
代码详解
数据导入部分
数据导入部分的代码主要有三个步骤,(1)从txt中读取文本数据,常规操作,这里没什么可说的;
datasets = {'%s-%s' % (task_name, f):load_data('%s%s/%s.%s.data' % (data_path, task_name, task_name, f))for f in ['train', 'valid', 'test']
}
(2)将读取到的文本句子转换成id向量,同样也是常规操作;
def convert_to_ids(data, tokenizer, maxlen=64):"""转换文本数据为id形式"""a_token_ids, b_token_ids, labels = [], [], []for d in tqdm(data):token_ids = tokenizer.encode(d[0], maxlen=maxlen)[0]a_token_ids.append(token_ids)token_ids = tokenizer.encode(d[1], maxlen=maxlen)[0]b_token_ids.append(token_ids)labels.append(d[2])a_token_ids = sequence_padding(a_token_ids)b_token_ids = sequence_padding(b_token_ids)return a_token_ids, b_token_ids, labels
(3)第三步则是写了一个class,使用了一个生成器,完成数据batch读取。这里需要注意的是,每个batch中,同一个文本数据,输入了两次,一个batch中的两个一样的文本输入,由于模型最后一层的加入了dropout,模型输出结果是有些许差别的,这样有差别的输出,则可以互为label,这也是SimCSE模型巧妙的地方。
class data_generator(DataGenerator):"""训练语料生成器"""def __iter__(self, random=False):batch_token_ids = []for is_end, token_ids in self.sample(random):batch_token_ids.append(token_ids) ##同一条文本输入两次batch_token_ids.append(token_ids) ##同一条文本输入两次if len(batch_token_ids) == self.batch_size * 2 or is_end:batch_token_ids = sequence_padding(batch_token_ids)batch_segment_ids = np.zeros_like(batch_token_ids)batch_labels = np.zeros_like(batch_token_ids[:, :1])yield [batch_token_ids, batch_segment_ids], batch_labelsbatch_token_ids = []
模型定义部分
这个模型的定义其实很简单,就是用bert作为特征提取的基础模型,然后再bert模型输出的基础上加上一个dropout操作,就是代码中的pooling层,核心代码就是下面几行
bert = build_transformer_model(config_path,checkpoint_path,model=model,with_pool='linear',dropout_rate=dropout_rate)
outputs, count = [], 0
while True:try:output = bert.get_layer('Transformer-%d-FeedForward-Norm' % count).outputoutputs.append(output)count += 1except:break
output = bert.output
# 最后的编码器
encoder = Model(bert.inputs, output)
模型的损失函数
模型的损失函数是所有代码中最难理解的部分,虽然代码只有十几行,但是最需要花费时间去理解的。
在阐述这个SimCSE模型的损失函数代码之前,首先要搞清楚,这个模型是要解决什么问题,其目的主要是为了提取短文本的特征,使得相似的句子,提取出来的特征距离更近,不同语义的句子,特征距离越远,这样使得提取出来的文本特征更具有辨识度,和人脸识别原理很类似,这就是对比学习模型系列想要达到的目的。
在了解了对比学习的大致原理之后,再来看代码,下面是解释
idxs = K.arange(0, K.shape(y_pred)[0])
这行代码就是模型输出的一个维度(模型输入的batchsize),构建一个索引,比如,模型输入batchsize为6,那idxs则就是[0,1,2,3,4,5]
idxs_1 = idxs[None, :]
这就是给idxs增加一个维度,使其变成[[0,1,2,3,4,5]]
idxs_2 = (idxs + 1 - idxs % 2 * 2)[:, None]
这行代码比较关键,目的是让idxs向量中数值是奇数的赋值为它的前一个数,数值为偶数的则赋值为它后一个索引值,这个一前一后的赋值,就是它相似度最大的索引值(排除自己)。这里需要解释一下的是,这里每个索引值背后代表的是SimCSE模型输出的一个个的提取到的文本特征向量,维度是1*738,和bert模型输出应该是一样的维度。而这里为什么要取一前一后的赋值索引,这因为数据导入时候,在每个batch里面同一条文本被相邻的导入了两次,那么这两个相邻的文本,经过SimCSE模型提取到的特征也是最为相似的,其相似度要接近1,而每个batch里面不相邻的模型输出,则应该是0,这样模型才能达到收敛的效果
y_true = K.equal(idxs_1, idxs_2)
y_true = K.cast(y_true, K.floatx())
这两行代码就是可以将y_true变成一个batchsize * batchsize大小的相似度矩阵,相似度的规则和上面描述的一样
生成y_true的中间值,其实可以打印出来看看,设定 y_pred为[‘a’, ‘a’, ‘b’, ‘b’, ‘c’, ‘c’]时候,整个调试代码如下:
from bert4keras.backend import keras, Kimport tensorflow as tfy_pred = ['a', 'a', 'b', 'b', 'c', 'c']session = tf.Session()
# 张量转化为ndarrayidxs = K.arange(0, K.shape(y_pred)[0])
array = session.run(idxs)
print('1', array)idxs_1 = idxs[None, :]
array = session.run(idxs_1)
print('2', array)idxs_2 = (idxs + 1 - idxs % 2 * 2)[:, None]
array = session.run(idxs_2)
print('3', array)y_true = K.equal(idxs_1, idxs_2)
array = session.run(y_true)
print('4', array)y_true = K.cast(y_true, K.floatx())array = session.run(y_true)
print('5',array)
y_pred = K.l2_normalize(y_pred, axis=1)
similarities = K.dot(y_pred, K.transpose(y_pred))
similarities = similarities - tf.eye(K.shape(y_pred)[0]) * 1e12
similarities = similarities * 20
这几行代码就是计算SimCSE模型预测出来每个batch里的每个文本特征之间的相似度,特征越相似,K.dot(y_pred, K.transpose(y_pred)),特征向量点乘越接近1,similarities = similarities - tf.eye(K.shape(y_pred)[0]) * 1e12,则是为了消除相似度矩阵对角线上的元素,即同一条特征自身与自身点乘的结果。
loss = K.categorical_crossentropy(y_true, similarities, from_logits=True)
最后用交叉熵损失来定义模型最后的输出损失
训练自己的数据
在这个模型需要训练自己的数据,首先是环境搭建:
jieba-0.42.1
bert4keras-0.10.5
keras-2.3.1
cudatoolkit 10.0.130
cudnn 7.6.0
tensorflow-gpu 1.13.1
然后准备数据集,格式如下:
txt这个标签,0,1可以有,也可以没有
接着就是下载预训练模型,bert的模型,下载之后,修改eval.py中的数据集和预训练模型的路径,将其修改成自己的路径
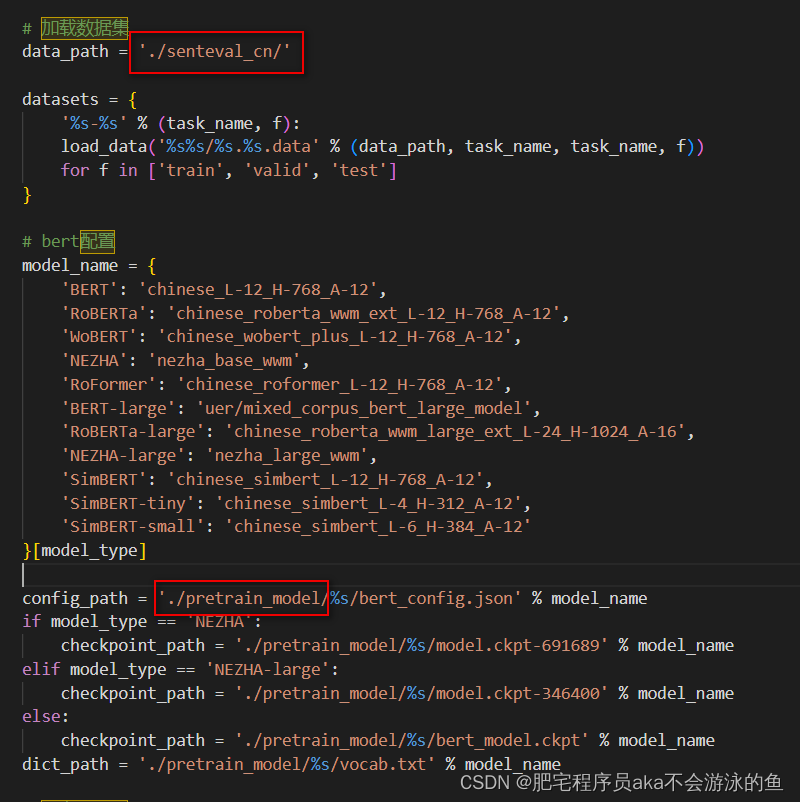
最后运行代码训练模型即可得到预测结果

参考链接
SimCSE论文及源码解读
SimCSE的loss实现源码解读
SimCSE: Simple Contrastive Learning of Sentence Embeddings
princeton-nlp/SimCSE
相关文章:
文本匹配SimCSE模型代码详解以及训练自己的中文数据集
前言 在上一篇博客文本匹配中的示例代码中使用到了一个SimCSE模型,用来提取短文本的特征,然后计算特征相似度,最终达到文本匹配的目的。但是该示例代码中的短文本是用的英文短句,其实SimCSE模型也可以用于中文短文本的特征提取&a…...
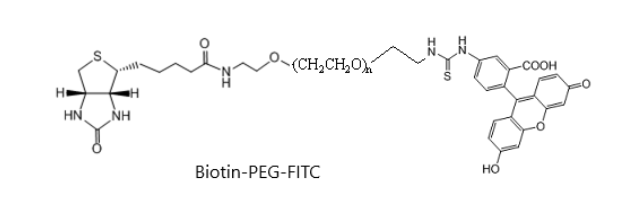
Biotin-PEG-FITC 生物素聚乙二醇荧光素;FITC-PEG-Biotin 科研用生物试剂
结构式: Biotin-PEG-FITC 生物素聚乙二醇荧光素 英文名称:Biotin-PEG-Fluorescein 中文名称:生物素聚乙二醇荧光素 外观:黄色液体、半固体或固体,取决于分子量。 溶剂:溶于大部分有机溶剂,…...

FISCO BCOS 搭建区块链,在SpringBoot中调用合约
一、搭建区块链 使用的是FISCO BCOS 和 WeBASE-Front来搭建区块链,详细教程: https://blog.csdn.net/yueyue763184/article/details/128924144?spm1001.2014.3001.5501 搭建好能达到下图效果即可: 二、部署智能合约与导出java文件、SDK证…...

面试官:int和Integer有什么区别?
回答思路: 原始数据类型和包装类介绍 主要区别(数据使用内存) 自动装箱、自动拆箱机制和实践原则 回答总结: int 是8种基本数据类型(byte、boolean、char、short、int、long、float、double)之一ÿ…...

MFC常用技巧
MFC常用技巧1、句柄MFC中如何获取窗口的句柄2、字符串CString转char*Unicode下char *转换为CString3、Visual C 64 位迁移的常见问题(数据类型、指针类型的长度问题)4、c - 将_beginthread返回的uintptr_t转换为HANDLE是否安全1、句柄 MFC中如何获取窗口…...

C++ —— 多态
目录 1.多态的概念 2.多态的定义及实现 2.1构成多态的两个硬性条件 2.2虚函数的重写 2.3override和final 3.抽象类 3.1接口继承和实现继承 4.多态原理 4.1虚函数表 4.2原理 4.3静态绑定和动态绑定 5.单继承和多继承体系的虚函数表 5.1单继承体系的虚函数表 5.2多继…...
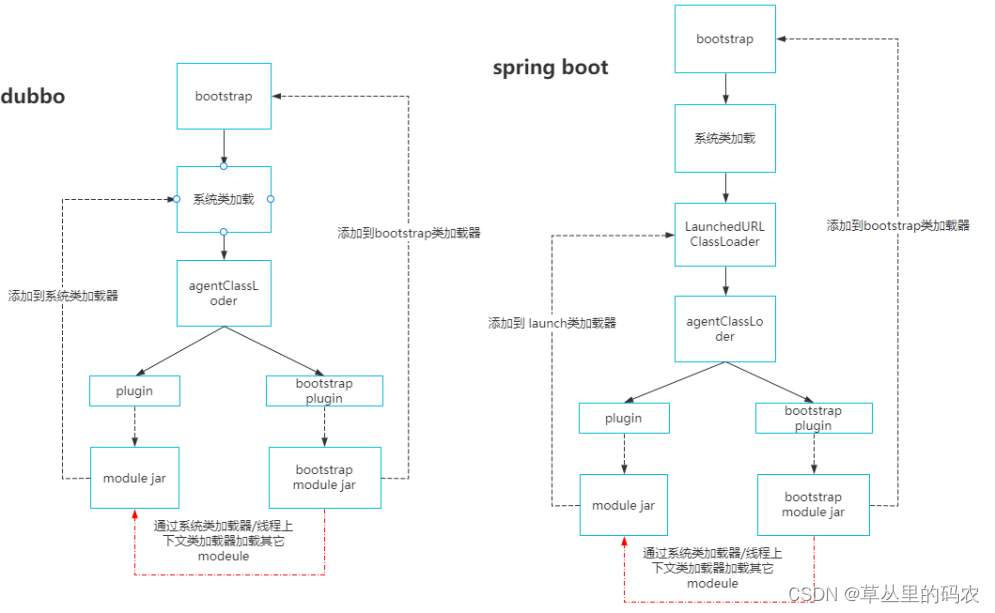
java agent设计开发概要
agent开发设计 agent 开发的一些心得,适合熟悉agent或者有agent开发需求的同学 1 有个基础的agent,是java 标准的agent。这是agent代码入口 2 设计包结构, 基础agent agent下有plugin,加载plugin可以自己定义一个类加载器 plugin࿱…...
node.js笔记-模块化(commonJS规范),包与npm(Node Package Manager)
目录 模块化 node.js中模块的分类 模块的加载方式 模块作用域 向外共享模块作用域中的成员 向外共享成员 包与npm(Node package Manager) 什么是包? 包的来源 为什么需要包? 查找和下载包 npm下载和卸载包命令 配置np…...
)
Linux 磁盘坏块修复处理(错误:read error: Input/output error)
当磁盘出现坏块时,你对所关联的文件进行读取时,一般会出现 read error: Input/output error 这样的错误。 反过来讲,当你看到 read error: Input/output error 这种错误时,很大可能就是磁盘出现了坏块问题。 解决步骤:…...

API 面试四连杀:接口如何设计?安全如何保证?签名如何实现?防重如何实现?
下面我们就来讨论下常用的一些API设计的安全方法,可能不一定是最好的,有更牛逼的实现方式,但是这篇是我自己的经验分享. 一、token 简介 Token:访问令牌access token, 用于接口中, 用于标识接口调用者的身份、凭证,减…...
操作系统题目收录(六)
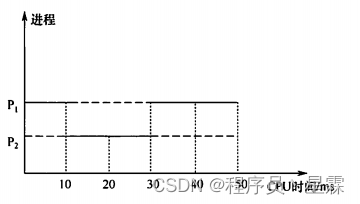
1、某系统采用基于优先权的非抢占式进程调度策略,完成一次进程调度和进程切换的系统时间开销为1us。在T时刻就绪队列中有3个进程P1P_1P1、P2P_2P2和P3P_3P3,其在就绪队列中的等待时间、需要的CPU时间和优先权如下表所示。若优先权值大的进程优先获…...
2023年十款开源测试开发工具推荐!
今天为大家奉献一篇测试开发工具集锦干货。在本篇文章中,将给大家推荐10款日常工作中经常用到的测试开发工具神器,涵盖了自动化测试、性能压测、流量复制、混沌测试、造数据等。 1、AutoMeter-API 自动化测试平台 AutoMeter 是一款针对分布式服务&…...
MySQL慢查询分析和性能优化
1 背景我们的业务服务随着功能规模扩大,用户量扩增,流量的不断的增长,经常会遇到一个问题,就是数据存储服务响应变慢。导致数据库服务变慢的诱因很多,而RD最重要的工作之一就是找到问题并解决问题。下面以MySQL为例子&…...
C++学习笔记(四)
组合、继承。委托(类与类之间的关系) 复合 queue类里有一个deque,那么他们的关系叫做复合。右上角的图表明复合的概念。上图的特例表明,queue中的功能都是通过调用c进行实现(adapter)。 复合关系下的构造和…...

【4】深度学习之Pytorch——如何使用张量处理时间序列数据集(共享自行车数据集)
表格数据 表格中的每一行都独立于其他行,他们的顺序页没有任何关系。并且,没有提供有关行之前和行之后的列编码信息。 表格类型的数据是指通过表格的形式表示的数据,它以行和列的方式组织数据。表格中的每一行代表一个数据项,每…...

mulesoft MCIA 破釜沉舟备考 2023.02.10.01
mulesoft MCIA 破釜沉舟备考 2023.02.10.01 1. What is a defining charcateristic of an integration-Platform-as-a-Service(iPaaS)?2. An application deployed to a runtime fabric environment with two cluster replicas is designed to periodically trigger of flow f…...

干货 | PCB拼板,那几条很讲究的规则!
拼板指的是将一张张小的PCB板让厂家直接给拼做成一整块。一、为什么要拼板呢,也就是说拼板的好处是什么?1.为了满足生产的需求。有些PCB板太小,不满足做夹具的要求,所以需要拼在一起进行生产。2.提高SMT贴片的焊接效率。只需要过一…...

笔试题-2023-思远半导体-数字IC设计【纯净题目版】
回到首页:2023 数字IC设计秋招复盘——数十家公司笔试题、面试实录 推荐内容:数字IC设计学习比较实用的资料推荐 题目背景 笔试时间:2022.08.20应聘岗位:数字IC设计工程师笔试时长:90min笔试平台:牛客网题目类型:填空题(2道),不定项选择题(3道),单选题(2道),问…...
canvas根据坐标点位画图形-canvas拖拽编辑单个图形形状
首先在选中图形的时候需要用鼠标右击来弹出选择框,实现第一个编辑节点功能 在components文件夹下新建右键菜单 RightMenu文件: <template><div v-show"show" class"right-menu" :style"top:this.ypx;left:this.xpx…...

JavaEE 初阶 — 确认应答机制
文章目录确认应答机制(安全机制)1 什么是后发先至问题1 如何解决后发先至问题确认应答机制(安全机制) 确认应答 是实现可靠传输的最核心机制。 这里指的 可靠传输 不是说 100% 可以把消息发给接收方,而是尽力而为&…...

MAA助手:明日方舟自动化工具完整技术指南与实战教程
MAA助手:明日方舟自动化工具完整技术指南与实战教程 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitco…...
 脚本语法详解:从入门到实战)
Windows Batch (.bat) 脚本语法详解:从入门到实战
文章目录一、 引言:什么是 Batch 脚本?二、 创建和运行 Bat 文件三、 基础语法与命令1. 注释2. 命令回显3. 变量4. 控制流:条件判断 (IF)5. 循环 (FOR)6. 跳转 (GOTO)7. 退出 (EXIT)8. 其他常用命令四、 实战示例示例 1: 简单备份脚本示例 2:…...

告别硬编码:动态定位与安全调用游戏发包函数的思路与避坑指南
动态游戏封包处理:从特征定位到安全调用的工程实践 在游戏辅助开发领域,直接硬编码函数地址就像在流沙上建房——每次游戏更新都可能让精心构建的代码轰然倒塌。我曾见过一个项目因为游戏小版本更新导致80%的功能失效,开发者不得不通宵达旦地…...

运维工程师必看!我从11K到20K的网络安全转型之路,收藏这篇避免35岁危机
凌晨 1 点,我蹲在机房地上接服务器电源线,后背被空调外机吹得发凉。手机里老板的消息还在跳:“客户数据丢了,天亮前恢复不了你就别来了。” 那是我做运维的第 8 年,手里攥着 11K 的薪资条,看着监控屏上闪烁…...

安卓USB调试不显示问题
问题:原本安卓可以开启USB调试正常的,被修改设定后不再弹出USB连接的提示问题解决:发现的OTG连接被打开了,关闭了之后就恢复正常...

PowerShell脚本环境探测指南
在跨平台开发和脚本执行的过程中,了解脚本运行的环境是非常关键的。尤其是当脚本需要在不同类型的shell环境中运行时,如Bash和PowerShell,脚本行为可能需要根据环境进行调整。本文将通过一个具体的实例,探讨如何在PowerShell脚本中探测调用它的shell环境,并做出相应的响应…...
)
告别纯命令行:给OpenDaylight控制器装个Web管理界面(DLUX Apps配置详解)
从命令行到可视化:OpenDaylight控制器DLUX Web界面深度配置指南 当你第一次成功启动OpenDaylight控制器时,面对那个漆黑的Karaf控制台,可能会感到一丝迷茫——这与想象中的"美观完善的可视化管理界面"相去甚远。别担心,…...

基于Claude构建个人AI工作流:caliclaw智能体部署与实战指南
1. 项目概述:打造你的专属Claude智能体工作流如果你和我一样,厌倦了每次使用AI助手都要复制粘贴API密钥、配置繁琐的YAML文件,还得时刻担心账单超支,那么caliclaw的出现,绝对值得你花上十分钟了解一下。这不是又一个“…...

轻量级服务器控制面板ClawPanel:可视化Nginx与SSL证书管理实践
1. 项目概述:一个为开发者而生的轻量级控制面板最近在折腾自己的服务器时,总感觉传统的Web服务器管理方式有点“重”。无论是Nginx的配置文件,还是各种服务的状态监控,都得靠命令行敲来敲去,对于需要快速部署和演示的场…...

为什么 MCP 在协议层会有 prompt injection的问题:工具描述如何劫持 agent 上下文
MCP(Model Context Protocol)当初被设计成 AI agent 的通用集成层,但它的架构有一个根本缺陷: 你接入的每一个 MCP 服务器,都会把它的工具描述原样放进 agent 的上下文窗口,每加一个就扩大一次攻击的可能性…...