常用聚类算法分析
1. 什么是聚类
1.1. 聚类的定义
聚类(Clustering)是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
1.2. 聚类和分类的区别
聚类(Clustering):是指把相似的数据划分到一起,具体划分的时候并不关心这一类的标签,目标就是把相似的数据聚合到一起,聚类是一种无监督学习(Unsupervised Learning)方法。分类(Classification):是把不同的数据划分开,其过程是通过训练数据集获得一个分类器,再通过分类器去预测未知数据,分类是一种监督学习(Supervised Learning)方法。
1.3. 聚类的一般过程
- 数据准备:特征标准化和降维
- 特征选择:从最初的特征中选择最有效的特征,并将其存储在向量中
- 特征提取:通过对选择的特征进行转换形成新的突出特征
- 聚类:基于某种距离函数进行相似度度量,获取簇
- 聚类结果评估:分析聚类结果,如
距离误差和(SSE)等
1.4. 数据对象间的相似度度量
对于数值型数据,可以使用下表中的相似度度量方法。

Minkowski距离就是范数(
),而
Manhattan 距离、Euclidean距离、Chebyshev距离分别对应时的情形。
1.5. cluster之间的相似度度量
除了需要衡量对象之间的距离之外,有些聚类算法(如层次聚类)还需要衡量cluster之间的距离 ,假设和
为两个
cluster,则前四种方法定义的和
之间的距离如下表所示。

Single-link定义两个cluster之间的距离为两个cluster之间距离最近的两个点之间的距离,这种方法会在聚类的过程中产生链式效应,即有可能会出现非常大的clusterComplete-link定义的是两个cluster之间的距离为两个``cluster之间距离最远的两个点之间的距离,这种方法可以避免链式效应`,对异常样本点(不符合数据集的整体分布的噪声点)却非常敏感,容易产生不合理的聚类UPGMA正好是Single-link和Complete-link方法的折中,他定义两个cluster之间的距离为两个cluster之间所有点距离的平均值- 最后一种
WPGMA方法计算的是两个cluster之间两个对象之间的距离的加权平均值,加权的目的是为了使两个cluster对距离的计算的影响在同一层次上,而不受cluster大小的影响,具体公式和采用的权重方案有关。
2. 数据聚类方法
数据聚类方法主要可以分为划分式聚类方法(Partition-based Methods)、基于密度的聚类方法(Density-based methods)、层次化聚类方法(Hierarchical Methods)等。
2.1. 划分式聚类方法
划分式聚类方法需要事先指定簇类的数目或者聚类中心,通过反复迭代,直至最后达到"簇内的点足够近,簇间的点足够远"的目标。经典的划分式聚类方法有k-means及其变体k-means++、bi-kmeans、kernel k-means等。
2.1.1. k-means算法
经典的k-means算法的流程如下:

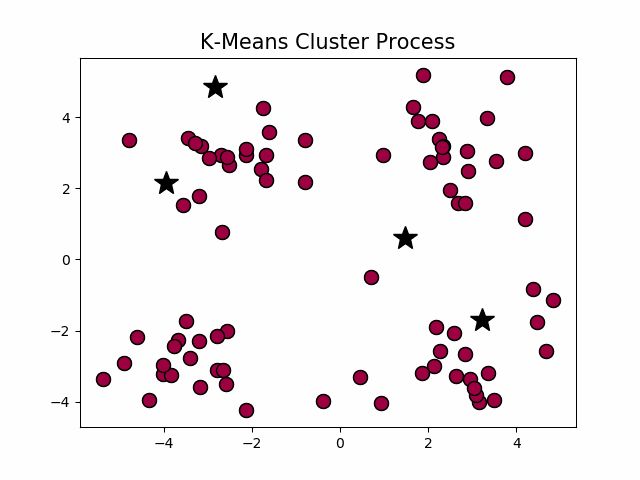
经典k-means源代码,下左图是原始数据集,通过观察发现大致可以分为4类,所以取k = 4,测试数据效果如下右图所示。


该函数的曲线如下图所示

可以发现该函数有两个局部最优点,当时初始质心点取值不同的时候,最终的聚类效果也不一样,接下来我们看一个具体的实例。

在这个例子当中,下方的数据应该归为一类,而上方的数据应该归为两类,这是由于初始质心点选取的不合理造成的误分。而k值的选取对结果的影响也非常大,同样取上图中数据集,取k = 2, 3,可以得到下面的聚类结果:

一般来说,经典k-means算法有以下几个特点:
- 需要提前确定k值
- 对初始质心点敏感
- 对异常数据敏感
2.1.2. k-means++算法
k-means++是针对k-means中初始质心点选取的优化算法。该算法的流程和k-means类似,改变的地方只有初始质心的选取,该部分的算法流程如下

k-means++源代码,使用k-means++对上述数据做聚类处理,得到的结果如下

K-means++ 能显著的改善分类结果的最终误差。尽管计算初始点时花费了额外的时间,但是在迭代过程中,k-mean 本身能快速收敛,因此算法实际上降低了计算时间。网上有人使用真实和合成的数据集测试了他们的方法,速度通常提高了 2 倍,对于某些数据集,误差提高了近 1000 倍。
2.1.3. bi-kmeans算法
一种度量聚类效果的指标是SSE(Sum of Squared Error),他表示聚类后的簇离该簇的聚类中心的平方和,SSE越小,表示聚类效果越好。 bi-kmeans是针对kmeans算法会陷入局部最优的缺陷进行的改进算法。该算法基于SSE最小化的原理,首先将所有的数据点视为一个簇,然后将该簇一分为二,之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否能最大程度的降低SSE的值。
该算法的流程如下:

bi-kmeans算法源代码,利用bi-kmeans算法处理上节中的数据得到的结果如下图所示。

这是一个全局最优的方法,所以每次计算出来的SSE值基本也是一样的(但是还是不排除有部分随机分错的情况),我们和前面的k-means、k-means++比较一下计算出来的SSE值
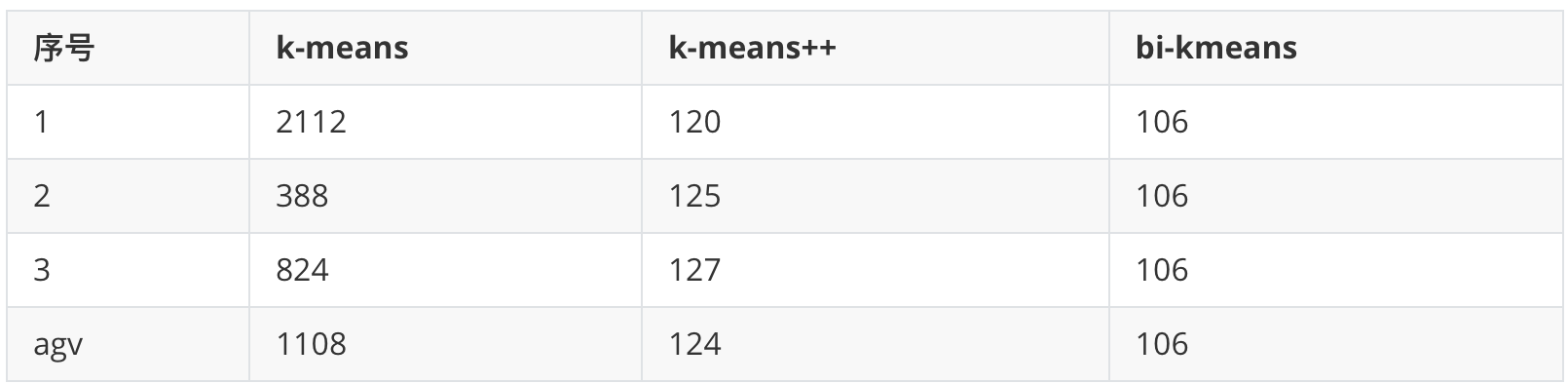
可以看到,k-means每次计算出来的SSE都较大且不太稳定,k-means++计算出来的SSE较稳定并且数值较小,而bi-kmeans 4次计算出来的SSE都一样,并且计算的SSE都较小,说明聚类的效果也最好。
2.2. 基于密度的方法
k-means算法对于凸性数据具有良好的效果,能够根据距离来讲数据分为球状类的簇,但对于非凸形状的数据点,就无能为力了,当k-means算法在环形数据的聚类时,我们看看会发生什么情况。

从上图可以看到,kmeans聚类产生了错误的结果,这个时候就需要用到基于密度的聚类方法了,该方法需要定义两个参数和M,分别表示密度的邻域半径和邻域密度阈值。
DBSCAN就是其中的典型。
2.2.1. DBSCAN算法
首先介绍几个概念,考虑集合,
表示定义密度的邻域半径,设聚类的邻域密度阈值为M,有以下定义:
邻域(
![]()
- 密度(desity)x的密度为
![]()
- 核心点(core-point)

- 边界点(border-point)

- 噪声点(noise-point)

该算法的流程如下:

构建邻域的过程可以使用
kd-tree进行优化,循环过程可以使用Numba、Cython、C进行优化,DBSCAN的源代码,使用该节一开始提到的数据集,聚类效果如下

聚类的过程示意图
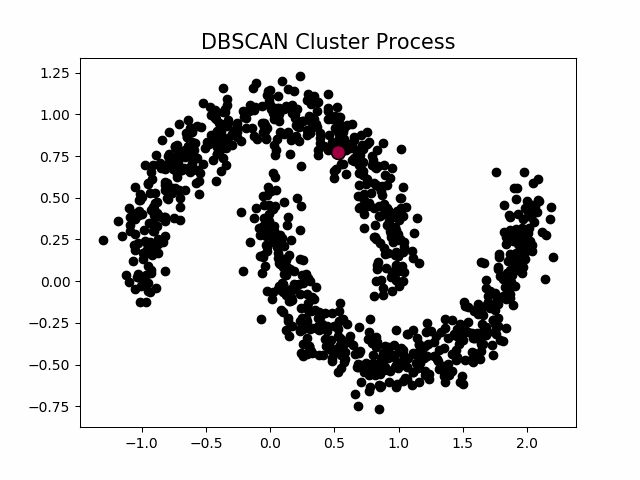
当设置不同的M时,会产生不同的结果,如下图所示

当设置不同的M时,会产生不同的结果,如下图所示

一般来说,DBSCAN算法有以下几个特点:
- 需要提前确定
- 不需要提前设置聚类的个数
- 对初值选取敏感,对噪声不敏感
- 对密度不均的数据聚合效果不好
2.2.2. OPTICS算法
在DBSCAN算法中,使用了统一的值,当数据密度不均匀的时候,如果设置了较小的值,则较稀疏的
cluster中的节点密度会小于,会被认为是边界点而不被用于进一步的扩展;如果设置了较大的值,则密度较大且离的比较近的
cluster容易被划分为同一个cluster,如下图所示。
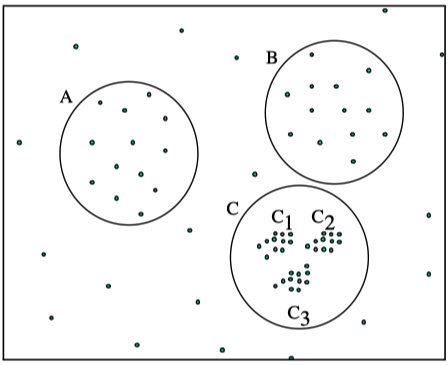
- 如果设置的
cluster - 如果设置的
cluster
对于密度不均的数据选取一个合适的是很困难的,对于高维数据,由于维度灾难(Curse of dimensionality),
的选取将变得更加困难。
怎样解决DBSCAN遗留下的问题呢?
The basic idea to overcome these problems is to run an algorithm which produces a special order of the database with respect to its density-based clustering structure containing the information about every clustering level of the data set (up to a "generating distance"
即能够提出一种算法,使得基于密度的聚类结构能够呈现出一种特殊的顺序,该顺序所对应的聚类结构包含了每个层级的聚类的信息,并且便于分析。
OPTICS(Ordering Points To Identify the Clustering Structure, OPTICS)实际上是DBSCAN算法的一种有效扩展,主要解决对输入参数敏感的问题。即选取有限个邻域参数进行聚类,这样就能得到不同邻域参数下的聚类结果。
在介绍OPTICS算法之前,再扩展几个概念。
- 核心距离(core-distance)

- 可达距离(reachability-distance)

可达距离的意义在于衡量所在的密度,密度越大,他从相邻节点直接密度可达的距离越小,如果聚类时想要朝着数据尽量稠密的空间进行扩张,那么可达距离最小是最佳的选择。
举个例子,下图中假设M = 3,半径是。那么点的核心距离是d(1, P),点2的可达距离是d(1, P),点3的可达距离也是d(1, P),点4的可达距离则是d(4, P)的距离。

OPTICS源代码,算法流程如下:

算法中有一个很重要的insert_list()函数,这个函数如下:

OPTICS算法输出序列的过程:
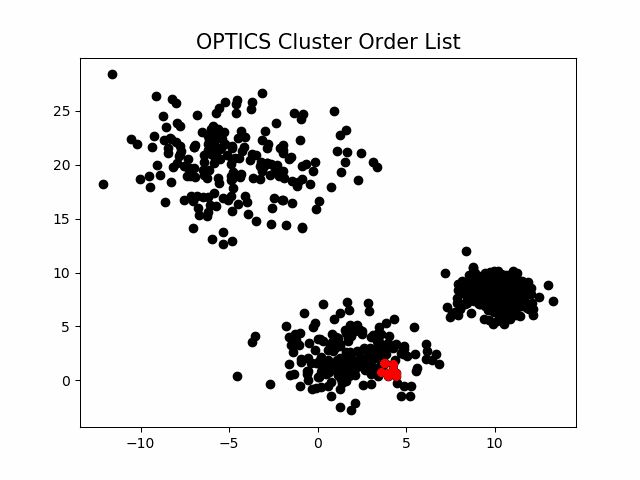
该算法最终获取知识是一个输出序列,该序列按照密度不同将相近密度的点聚合在一起,而不是输出该点所属的具体类别,如果要获取该点所属的类型,需要再设置一个参数
提取出具体的类别。这里我们举一个例子就知道是怎么回事了。
随机生成三组密度不均的数据,我们使用DBSCAN和OPTICS来看一下效果。


可见,OPTICS第一步生成的输出序列较好的保留了各个不同密度的簇的特征,根据输出序列的可达距离图,再设定一个合理的,便可以获得较好的聚类效果。
2.3. 层次化聚类方法
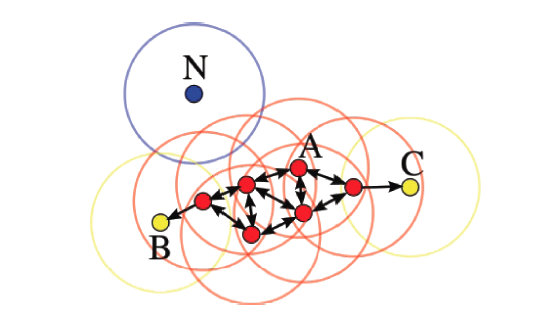
前面介绍的几种算法确实可以在较小的复杂度内获取较好的结果,但是这几种算法却存在一个链式效应的现象,比如:A与B相似,B与C相似,那么在聚类的时候便会将A、B、C聚合到一起,但是如果A与C不相似,就会造成聚类误差,严重的时候这个误差可以一直传递下去。为了降低链式效应,这时候层次聚类就该发挥作用了。
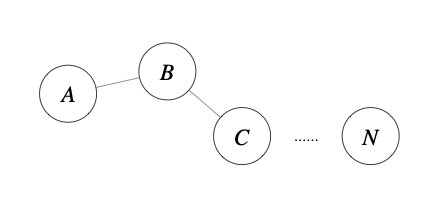
层次聚类算法 (hierarchical clustering) 将数据集划分为一层一层的 clusters,后面一层生成的 clusters 基于前面一层的结果。层次聚类算法一般分为两类:
- Agglomerative 层次聚类:又称自底向上(bottom-up)的层次聚类,每一个对象最开始都是一个
cluster,每次按一定的准则将最相近的两个cluster合并生成一个新的cluster,如此往复,直至最终所有的对象都属于一个cluster。这里主要关注此类算法。 - Divisive 层次聚类: 又称自顶向下(top-down)的层次聚类,最开始所有的对象均属于一个
cluster,每次按一定的准则将某个cluster划分为多个cluster,如此往复,直至每个对象均是一个cluster。

另外,需指出的是,层次聚类算法是一种贪心算法(greedy algorithm),因其每一次合并或划分都是基于某种局部最优的选择。
2.3.1. Agglomerative算法
给定数据集,
Agglomerative层次聚类最简单的实现方法分为以下几步:

Agglomerative算法源代码,可以看到,该 算法的时间复杂度为(由于每次合并两个
cluster 时都要遍历大小为的距离矩阵来搜索最小距离,而这样的操作需要进行n-1次),空间复杂度为
(由于要存储距离矩阵)。

上图中分别使用了层次聚类中4个不同的cluster度量方法,可以看到,使用single-link确实会造成一定的链式效应,而使用complete-link则完全不会产生这种现象,使用average-link和ward-link则介于两者之间。
2.4. 新发展的方法
2.4.1. 基于约束的方法
真实世界中的聚类问题往往是具备多种约束条件的 , 然而由于在处理过程中不能准确表达相应的约束条件、不能很好地利用约束知识进行推理以及不能有效利用动态的约束条件 , 使得这一方法无法得到广泛的推广和应用。这里的约束可以是对个体对象的约束 , 也可以是对聚类参数的约束 , 它们均来自相关领域的经验知识。该方法的一个重要应用在于对存在障碍数据的二维空间数据进行聚类。 COD (Clustering with Ob2structed Distance) 就是处理这类问题的典型算法 , 其主要思想是用两点之间的障碍距离取代了一般的欧氏距离来计算其间的最小距离。
2.4.2. 基于模糊的聚类方法
基于模糊集理论的聚类方法,样本以一定的概率属于某个类。比较典型的有基于目标函数的模糊聚类方法、基于相似性关系和模糊关系的方法、基于模糊等价关系的传递闭包方法、基于模 糊图论的最小支撑树方法,以及基于数据集的凸分解、动态规划和难以辨别关系等方法。
FCM模糊聚类算法流程:
标准化数据矩阵;
建立模糊相似矩阵,初始化隶属矩阵;
算法开始迭代,直到目标函数收敛到极小值;
根据迭代结果,由最后的隶属矩阵确定数据所属的类,显示最后的聚类结果。
2.4.3. 基于粒度的聚类方法
基于粒度原理,研究还不完善。
2.4.4. 量子聚类
受物理学中量子机理和特性启发,可以用量子理论解决聚类记过依赖于初值和需要指定类别数的问题。一个很好的例子就是基于相关点的 Pott 自旋和统计机理提出的量子聚类模型。它把聚类问题看做一个物理系统。并且许多算例表明,对于传统聚类算法无能为力的几种聚类问题,该算法都得到了比较满意的结果。
2.4.5. 核聚类
核聚类方法增加了对样本特征的优化过程,利用 Mercer 核 把输入空间的样本映射到高维特征空间,并在特征空间中进行聚类。核聚类方法是普适的,并在性能上优于经典的聚类算法,它通过非线性映射能够较好地分辨、提 取并放大有用的特征,从而实现更为准确的聚类;同时,算法的收敛速度也较快。在经典聚类算法失效的情况下,核聚类算法仍能够得到正确的聚类。代表算法有SVDD算法,SVC算法。
2.4.6. 谱聚类
首先根据给定的样本数据集定义一个描述成对数据点相似度的亲合矩阵,并计算矩阵的特征值和特征向量,然后选择合适的特征向量聚类不同的数据点。谱聚类算法最初用于计算机视觉、VLSI设计等领域,最近才开始用于机器学习中,并迅速成为国际上机器学习领域的研究热点。
谱聚类算法建立在图论中的谱图理论基础上,其本质是将聚类问题转化为图的最优划分问题,是一种点对聚类算法。
2.5. 聚类方法比较

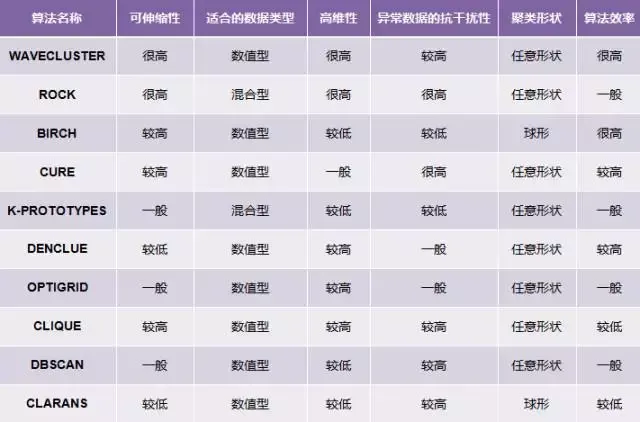
参考文献
常用聚类算法 - 知乎
用于数据挖掘的聚类算法有哪些,各有何优势? - 知乎
相关文章:
常用聚类算法分析
1. 什么是聚类 1.1. 聚类的定义 聚类(Clustering)是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起…...

OSG三维渲染引擎编程学习之五十八:“第五章:OSG场景渲染” 之 “5.16 简单光源”
目录 第五章 OSG场景渲染 5.16 简单光源 5.16.1 场景中使用光源 5.16.2 简单光源示例 第五章 OSG场景渲染 OSG存在场景树和渲染树,“场景数”的构建在第三章“OSG场景组...
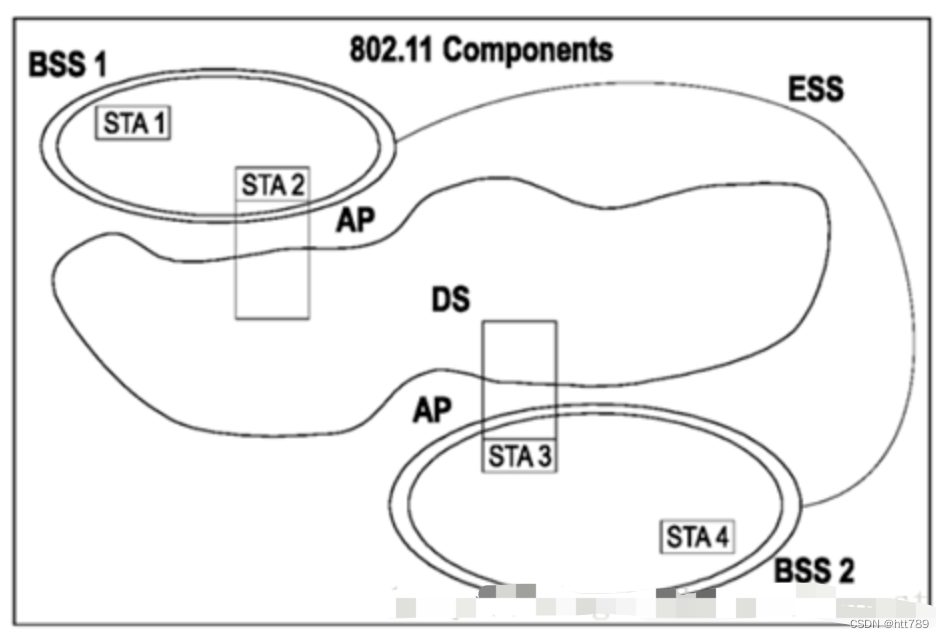
80211无线网络架构
无线网络架构物理组件BSS(Basic Service Set)基本服务集BSSID(BSS Identification)ssid(Service Set Identification)ESS(Extended Service Set)扩展服务集物理组件 无线网络包含四…...
基于springboot+vue的便利店库存管理系统
基于springbootvue的便利店库存管理系统 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景…...

3|物联网控制|计算机控制-刘川来胡乃平版|第1章:绪论|青岛科技大学课堂笔记|U1 ppt
目录绪论(2学时)常用仪表设备(3学时)计算机总线技术(4学时)过程通道与人机接口(6学时)数据处理与控制策略(6学时)网络与通讯技术(3学时࿰…...
js打印本地pdf(使用HttpPrinter打印插件)
js打印本地pdf(使用HttpPrinter打印插件)第一步:启动HttpPrinter打印插件第二步:用浏览器打开示例文件\调用示例\websocket协议示例\html\打印pdf.html输入pdf地址 点击 “下载并打印pdf文件”按钮,就可以静默打印了。…...
 | 机试题算法思路 【2023】)
华为OD机试 - 双十一(Python) | 机试题算法思路 【2023】
最近更新的博客 【新解法】华为OD机试 - 关联子串 | 备考思路,刷题要点,答疑,od Base 提供【新解法】华为OD机试 - 停车场最大距离 | 备考思路,刷题要点,答疑,od Base 提供【新解法】华为OD机试 - 任务调度 | 备考思路,刷题要点,答疑,od Base 提供【新解法】华为OD机试…...

2020年UML 秋季期末测试题
1.UML的全称是(B )。A.Unified Making LanguageB.Unified Modeling LanguageC.Unified Meodem languageD.Unify Modeling Language2.UML主要应用于( C)。A.基于螺旋模型的结构化开发方法B.基于数据的数据流开发方法C.基于对象的面…...
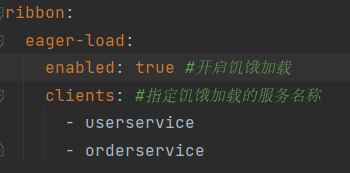
SpringCloud - Ribbon负载均衡
目录 负载均衡流程 负载均衡策略 Ribbon加载策略 负载均衡流程 Ribbon将http://userservice/user/1请求拦截下来,帮忙找到真实地址http://localhost:8081LoadBalancerInterceptor类对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表&…...

Spring Boot + Redis 实现分布式锁
一、业务背景有些业务请求,属于耗时操作,需要加锁,防止后续的并发操作,同时对数据库的数据进行操作,需要避免对之前的业务造成影响。二、分析流程使用 Redis 作为分布式锁,将锁的状态放到 Redis 统一维护&a…...

CAD二次开发 插件初始化接口IExtensionApplication
前言:在实际项目开发中,我们总会遇到一些问题。比如说在CAD打开之前,修改注册表的内容,或者解决CAD在没有完全加载想要的dll情况下,功能运行报错的bug。因此,下面和大家介绍一下IExtensionApplication接口 …...

kafka-11-kafka的监控工具和常用配置参数
kafka官方文档 参考Kafka三款监控工具比较 1 查看kafka的版本 进入kafka所在目录,通过查看libs目录下的jar包。 2.11是scala的版本,2.0.0是kafka的版本。 测试环境 #systemctl start zookeeper #systemctl start kafkka 2 kafka的常用配置 Kafka使用…...

前端PWA渐进式加载技术
1.什么是PWA? 渐进式网络应用(PWA)是谷歌在2015年底提出的概念。基本上算是web应用程序,但在外观和感觉上与原生app类似。支持PWA的网站可以提供脱机工作、推送通知和设备硬件访问等功能。 2.PWA有那些优点? 更小更…...

【ubuntu 22.04不识别ch340串口】
这个真是挺无语的,发现国内厂商普遍对开源环境不感兴趣,ch340官方linux驱动好像被厂家忘了,现在放出来的驱动还是上古内核版本: 于是,驱动居然要用户自己编译安装。。还好网上有不少大神:链接,…...

解决:eclipse绿化版Resource注解报Resource cannot be resolved to a type问题
如图: 网上解决教程很多,我的eclipse是绿化版的,不需要安装 解决办法如下: 1、在eclipse中,进入到Window->Preferences->Java->Installed JREs中 默认显示如下: 2、点击Add-->Standard VM--…...

初识Cookie和Session
Cookie和Session出于安全考虑,浏览器不让网页直接操作文件系统,而Cookie就是一个折中的方案,可以让网页暂存一些数据在本地,不能存复杂的对象,只能存字符串。Cookie是按照域名分类的,这个很好理解。如何理解…...

vue3的七种路由守卫使用
路由守卫有哪几种? 路由守卫(导航守卫)分为三种:全局守卫(3个)、路由独享守卫(1个)、组件的守卫(3个)。 路由守卫的三个参数 to:要跳转到的目标路由 from:…...
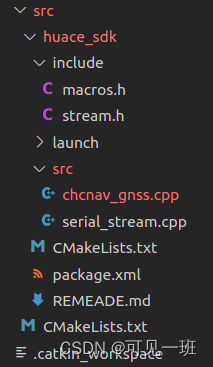
华测导航GPCHC协议ROS驱动包,CGI610、410接收机,NavSatStatus、GPSFix和普通格式
目录一、消息类型1.1 sensor_msgs/NavSatFix1.2 sensor_msgs/NavSatStatus1.3 gps_common::GPSFix1.4 sensor_msgs::Imu二、部分源码2.1 相关的依赖和库2.2 文件结构2.3 字段分割函数2.4 定义消息话题Ubuntu 20.04 noetic 华测CGI 610——RS232-C——GPCHC 一、消息类型 1.1 …...
)
算法实战应用案例精讲-【图像处理】Pillow图像处理(python代码实战)
目录 操作图像 计算机图像基础 颜色和RGBA值 坐标和 Box 元组 CMYK 和 RGB着色...

C语言通讯录【动态+文件】
目录定义结构体基础操作部分文件操作部分定义结构体 我们要做一个通讯录,里面的信息有一个人的名字,年龄,性别,地址和电话号 对于姓名,年龄等字符串,为了日后方便调整其长度,需要预定义一下它…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...

HTTPS证书一年多少钱?
HTTPS证书作为保障网站数据传输安全的重要工具,成为众多网站运营者的必备选择。然而,面对市场上种类繁多的HTTPS证书,其一年费用究竟是多少,又受哪些因素影响呢? 首先,HTTPS证书通常在PinTrust这样的专业平…...

GeoServer发布PostgreSQL图层后WFS查询无主键字段
在使用 GeoServer(版本 2.22.2) 发布 PostgreSQL(PostGIS)中的表为地图服务时,常常会遇到一个小问题: WFS 查询中,主键字段(如 id)莫名其妙地消失了! 即使你在…...

k8s从入门到放弃之Pod的容器探针检测
k8s从入门到放弃之Pod的容器探针检测 在Kubernetes(简称K8s)中,容器探测是指kubelet对容器执行定期诊断的过程,以确保容器中的应用程序处于预期的状态。这些探测是保障应用健康和高可用性的重要机制。Kubernetes提供了两种种类型…...